Support and Resistance AI by K clustering MT4
- Indikatoren
-
Minh Truong Pham
 Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
I will try:
+ Provide best tools base on my 5 years experience as a trader and 10 years as a programmer. - Version: 1.3
- Aktivierungen: 5
"ÜBERBLICK
K-meansist ein Clustering-Algorithmus, der häufig beim maschinellen Lernen verwendet wird, um Datenpunkte auf der Grundlage ihrer Ähnlichkeiten in verschiedene Cluster einzuteilen. K-means wird zwar in der Regel nicht direkt zur Identifizierung von Unterstützungs- und Widerstandsniveaus auf den Finanzmärkten verwendet, kann aber als Werkzeug in einem umfassenderen Analyseansatz dienen.
Unterstützungs- und Widerstandsniveaus sind Kursniveaus auf den Finanzmärkten, auf denen der Kurs zu einer Reaktion oder Umkehr neigt. Bei der Unterstützung handelt es sich um ein Niveau, bei dem der Kurs tendenziell nicht mehr fällt und zu steigen beginnt, während der Widerstand ein Niveau ist, bei dem der Kurs tendenziell nicht mehr steigt und zu fallen beginnt. Händler und Analysten achten häufig auf diese Niveaus, da sie Aufschluss über potenzielle Kursbewegungen und Handelsmöglichkeiten geben können.
"HINTERGRUND
Den K-Means-Algorithmus gibt es seit den späten 1950er Jahren, er ist also mehr als sechs Jahrzehnte alt. Der Algorithmus wurde 1957 von Stuart Lloyd in seinem Forschungspapier "Least squares quantization in PCM" für Telekommunikationsanwendungen vorgestellt. Er wurde jedoch erst in James MacQueens Arbeit "Some Methods for Classification and Analysis of Multivariate Observations" aus dem Jahr 1967 bekannt und anerkannt, in der er den Algorithmus formalisierte und ihn als "K-means"-Clustermethode bezeichnete.
Obwohl es K-means schon seit geraumer Zeit gibt, ist es aufgrund seiner Einfachheit und Effektivität bei Clustering-Aufgaben nach wie vor ein weit verbreiteter und einflussreicher Algorithmus in den Bereichen maschinelles Lernen, Datenanalyse und Mustererkennung.
"VERGLEICH UND VERGLEICH VON UNTERSTÜTZUNGS- UND RESISTENZMETHODEN
1) K-means-Ansatz:
2) Traditioneller Ansatz:
Der Hauptunterschied liegt im Ansatz und in der Grundlage dieser Methoden. Traditionelle Methoden basieren auf bewährten Grundsätzen der technischen Analyse und der Marktpsychologie, während der K-Means-Ansatz eine Clusterung des Preisverhaltens beinhaltet, ohne notwendigerweise die Marktstimmung oder bestimmte Preismuster zu berücksichtigen.
Es ist wichtig, darauf hinzuweisen, dass der K-Means-Ansatz zwar eine interessante Möglichkeit zur Analyse von Preisdaten bieten kann, aber mit Vorsicht und in Verbindung mit anderen traditionellen Methoden verwendet werden sollte. Die Finanzmärkte werden von einer Vielzahl von Faktoren beeinflusst, die über das reine Preisverhalten hinausgehen, und die Wirksamkeit jeder Methode zur Ermittlung von Unterstützungs- und Widerstandsniveaus sollte gründlich getestet und validiert werden. Außerdem können sich seit meiner letzten Aktualisierung Entwicklungen bei den Handelsstrategien und Analysetechniken ergeben haben.
"K MEANS ALGORITHM
Der Algorithmus für K-Mittelwerte lautet wie folgt:
"EINSCHRÄNKUNGEN VON K MEANS
Es gibt 3 wesentliche Einschränkungen dieses Algorithmus:
"EINSCHRÄNKUNGEN BEI DER ANWENDUNG VON K MEANS IM HANDEL
Handelsdaten weisen oft Merkmale auf, die bei der Anwendung von Indikatoren und Analysetechniken eine Herausforderung darstellen können. Im Folgenden wird erläutert, wie sich die Einschränkungen durch Ausreißer, unterschiedliche Skalen und ungleiche Varianz auf die Verwendung von Indikatoren im Handel auswirken können:
"ANWENDUNG DIESES INDIKATORS
Dieser Indikator kann auf 2 Arten verwendet werden:
1) Richtungsweisender Handel:
Allgemeine Einstellungen:
Funktionen:
Neben den Unterstützungs- und Widerstandsniveaus und den Standardabweichungsbändern zeigt dieser Indikator in einer Tabelle in der oberen rechten Ecke die Dichte der einzelnen Cluster (Unterstützungs- und Widerstandsniveaus) an, die farblich an die Clusterlinie im Diagramm angepasst sind. Cluster mit höherer Dichte bedeuten, dass der Kurs zuvor häufiger dort war als Cluster mit geringerer Dichte und könnten eine höhere Wahrscheinlichkeit für eine Umkehr bedeuten, wenn der Kurs diese Bereiche erreicht.
"WORKS CITED
K-meansist ein Clustering-Algorithmus, der häufig beim maschinellen Lernen verwendet wird, um Datenpunkte auf der Grundlage ihrer Ähnlichkeiten in verschiedene Cluster einzuteilen. K-means wird zwar in der Regel nicht direkt zur Identifizierung von Unterstützungs- und Widerstandsniveaus auf den Finanzmärkten verwendet, kann aber als Werkzeug in einem umfassenderen Analyseansatz dienen.
Unterstützungs- und Widerstandsniveaus sind Kursniveaus auf den Finanzmärkten, auf denen der Kurs zu einer Reaktion oder Umkehr neigt. Bei der Unterstützung handelt es sich um ein Niveau, bei dem der Kurs tendenziell nicht mehr fällt und zu steigen beginnt, während der Widerstand ein Niveau ist, bei dem der Kurs tendenziell nicht mehr steigt und zu fallen beginnt. Händler und Analysten achten häufig auf diese Niveaus, da sie Aufschluss über potenzielle Kursbewegungen und Handelsmöglichkeiten geben können.
"HINTERGRUND
Den K-Means-Algorithmus gibt es seit den späten 1950er Jahren, er ist also mehr als sechs Jahrzehnte alt. Der Algorithmus wurde 1957 von Stuart Lloyd in seinem Forschungspapier "Least squares quantization in PCM" für Telekommunikationsanwendungen vorgestellt. Er wurde jedoch erst in James MacQueens Arbeit "Some Methods for Classification and Analysis of Multivariate Observations" aus dem Jahr 1967 bekannt und anerkannt, in der er den Algorithmus formalisierte und ihn als "K-means"-Clustermethode bezeichnete.
Obwohl es K-means schon seit geraumer Zeit gibt, ist es aufgrund seiner Einfachheit und Effektivität bei Clustering-Aufgaben nach wie vor ein weit verbreiteter und einflussreicher Algorithmus in den Bereichen maschinelles Lernen, Datenanalyse und Mustererkennung.
"VERGLEICH UND VERGLEICH VON UNTERSTÜTZUNGS- UND RESISTENZMETHODEN
1) K-means-Ansatz:
- Clusterbildung: Nach der Anwendung des K-means-Algorithmus auf historische Preisänderungsdaten und der Visualisierung der sich ergebenden Cluster können Händler eindeutige Regionen auf dem Preisdiagramm identifizieren, in denen sich Cluster bilden. Jeder Cluster stellt eine Gruppe ähnlicher Kursänderungsmuster dar.
- Cluster-Analyse: Analysieren Sie die Cluster, um Bereiche zu identifizieren, in denen sich tendenziell Cluster bilden. Diese Bereiche könnten Regionen entsprechen, in denen sich das Preisverhalten im Laufe der Zeit wiederholt und die auf Unterstützungs- und Widerstandsniveaus hinweisen könnten.
- Potenzielle Unterstützungs- und Widerstandsniveaus: Auf der Grundlage der identifizierten Bereiche, in denen sich Cluster bilden, können Händler diese Regionen als potenzielle Unterstützungs- und Widerstandsniveaus betrachten. Ein Cluster, der sich auf einem bestimmten Kursniveau bildet, könnte darauf hindeuten, dass dieses Niveau historisch bedeutsam war und in der Vergangenheit ein ähnliches Kursverhalten verursacht hat.
- Cluster-Standardabweichung: Zusätzlich zur Betrachtung der Mittelwerte (Zentroide) der Cluster können Händler auch die Standardabweichung der Preisänderungen innerhalb jedes Clusters berechnen. Die Standardabweichung ist ein Maß für die Streuung oder Volatilität der Datenpunkte um den Mittelwert. Eine höhere Standardabweichung deutet auf eine größere Preisvolatilität innerhalb eines Clusters hin.
- Niedrige Standardabweichung: Wenn ein Cluster eine niedrige Standardabweichung aufweist, deutet dies darauf hin, dass die Kurse innerhalb dieses Clusters relativ stabil sind und weniger wahrscheinlich plötzliche und große Kursbewegungen aufweisen. Händler könnten in Erwägung ziehen, engere Stop-Loss-Orders für Trades innerhalb dieser Cluster zu platzieren.
- Hohe Standardabweichung: Wenn ein Cluster eine hohe Standardabweichung aufweist, deutet dies auf eine größere Preisvolatilität innerhalb dieses Clusters hin. Händler könnten sich für breitere Stop-Loss-Orders entscheiden, um potenziellen Kursschwankungen Rechnung zu tragen, ohne vorzeitig ausgestoppt zu werden.
- Cluster-Dichte: Jeder Datenpunkt wird einem Cluster zugeordnet, so dass ein dichteres Cluster mehr wie die Schwerkraft wirkt und
2) Traditioneller Ansatz:
- Trendlinien: Zeichnen Sie Trendlinien, die signifikante Hochs oder Tiefs auf einem Preisdiagramm verbinden, um potenzielle Unterstützungs- und Widerstandsniveaus zu identifizieren.
- Chart-Muster: Erkennen Sie Chart-Muster wie Doppel-Tops, Doppel-Bottoms, Kopf und Schultern und Dreiecke, die oft auf potenzielle Umkehrpunkte hinweisen.
- Gleitende Durchschnitte: Verwenden Sie gleitende Durchschnitte, um auf der Grundlage des Durchschnittspreises über einen bestimmten Zeitraum Niveaus zu ermitteln, auf denen der Kurs Unterstützung oder Widerstand finden könnte.
- Psychologische Niveaus: Ermitteln Sie runde Zahlen oder Niveaus, die von Händlern häufig beachtet werden und als Unterstützung und Widerstand dienen können.
- Frühere Höchst- und Tiefststände: Identifizierung signifikanter früherer Kurshöchst- und -tiefststände, die als Unterstützung oder Widerstand dienen können.
Der Hauptunterschied liegt im Ansatz und in der Grundlage dieser Methoden. Traditionelle Methoden basieren auf bewährten Grundsätzen der technischen Analyse und der Marktpsychologie, während der K-Means-Ansatz eine Clusterung des Preisverhaltens beinhaltet, ohne notwendigerweise die Marktstimmung oder bestimmte Preismuster zu berücksichtigen.
Es ist wichtig, darauf hinzuweisen, dass der K-Means-Ansatz zwar eine interessante Möglichkeit zur Analyse von Preisdaten bieten kann, aber mit Vorsicht und in Verbindung mit anderen traditionellen Methoden verwendet werden sollte. Die Finanzmärkte werden von einer Vielzahl von Faktoren beeinflusst, die über das reine Preisverhalten hinausgehen, und die Wirksamkeit jeder Methode zur Ermittlung von Unterstützungs- und Widerstandsniveaus sollte gründlich getestet und validiert werden. Außerdem können sich seit meiner letzten Aktualisierung Entwicklungen bei den Handelsstrategien und Analysetechniken ergeben haben.
"K MEANS ALGORITHM
Der Algorithmus für K-Mittelwerte lautet wie folgt:
- Initialisierung der Clusterzentren
- Zuweisung der Daten zu den Clustern auf der Grundlage des Mindestabstands
- Berechnung des Clusterzentrums durch Ermittlung des Durchschnitts oder Medians der Cluster
- Schritte 1-3 wiederholen, bis sich die Clusterzentren nicht mehr verschieben
"EINSCHRÄNKUNGEN VON K MEANS
Es gibt 3 wesentliche Einschränkungen dieses Algorithmus:
- Empfindlich gegenüber Initialisierungen: K-means ist empfindlich gegenüber der anfänglichen Platzierung der Zentren. Unterschiedliche Initialisierungen können zu unterschiedlichen Clusterzuordnungen und Endergebnissen führen.
- Annahme gleicher Größen und Varianzen: K-means geht davon aus, dass die Cluster ungefähr gleich groß und kugelförmig sind. Dies trifft jedoch nicht auf alle Datentypen zu. Es kann Probleme bei der Identifizierung von Clustern mit ungleicher Dichte, Größe oder Form geben.
- Auswirkung von Ausreißern: K-means ist empfindlich gegenüber Ausreißern, da ein einziger Ausreißer die Position der Clusterschwerpunkte erheblich beeinflussen kann. Ausreißer können zur Bildung von falschen Clustern oder zur Verzerrung der wahren Clusterstruktur führen.
"EINSCHRÄNKUNGEN BEI DER ANWENDUNG VON K MEANS IM HANDEL
Handelsdaten weisen oft Merkmale auf, die bei der Anwendung von Indikatoren und Analysetechniken eine Herausforderung darstellen können. Im Folgenden wird erläutert, wie sich die Einschränkungen durch Ausreißer, unterschiedliche Skalen und ungleiche Varianz auf die Verwendung von Indikatoren im Handel auswirken können:
- Ausreißer sind Datenpunkte, die erheblich vom Rest des Datensatzes abweichen. Beim Handel können Ausreißer extreme Kursbewegungen darstellen, die durch seltene Ereignisse, Nachrichten oder Marktanomalien verursacht werden. Ausreißer können erhebliche Auswirkungen auf Handelsindikatoren und Analysen haben:
Indikatorverzerrung: Ausreißer können die Berechnungen von Indikatoren verzerren und zu irreführenden Signalen führen. Beispielsweise kann eine einzige extreme Kursspitze dazu führen, dass Indikatoren wie gleitende Durchschnitte oder RSI (Relative Strength Index) falsche Signale geben.
Risikomanagement: Ausreißer können zu übermäßig aggressiven Handelsentscheidungen führen, wenn sie nicht richtig berücksichtigt werden. Das Ignorieren von Ausreißern kann zu unerwarteten Verlusten oder verpassten Gelegenheiten zur Anpassung von Handelsstrategien führen. - Unterschiedliche Skalen: Handelsdaten enthalten oft mehrere Indikatoren mit unterschiedlichen Einheiten und Skalen. So werden beispielsweise Kurse in der Regel in Dollar angegeben, das Volumen in gehandelten Einheiten, und Oszillatoren haben ihre eigene Skala. Das Mischen von Indikatoren mit unterschiedlichen Skalen kann die Analyse erschweren:
Normalisierung: Indikatoren auf unterschiedlichen Skalen müssen normalisiert oder standardisiert werden, um sicherzustellen, dass sie gleichermaßen zur Analyse beitragen. Geschieht dies nicht, kann ein Indikator die Analyse aufgrund seines größeren Umfangs dominieren.
Vergleichbarkeit: Ohne Normalisierung ist es schwierig, die Bedeutung von Indikatoren direkt zu vergleichen. Einige Indikatoren haben möglicherweise einen größeren Zahlenbereich und könnten andere überschatten. - Ungleiche Varianz: Ungleiche Varianz in Handelsdaten bezieht sich auf die Tatsache, dass einige Indikatoren eine höhere Volatilität aufweisen können als andere. Dies kann sich auf die Interpretation von Signalen und die Leistung von Handelsstrategien auswirken:
Volatilitätsanpassung: Bei der Kombination von Indikatoren mit unterschiedlicher Volatilität ist es wichtig, deren relative Volatilität zu berücksichtigen. Geschieht dies nicht, kann dies dazu führen, dass die Bedeutung bestimmter Indikatoren in der Handelsstrategie überbetont oder unterschätzt wird.
Risikobewertung: Ungleiche Varianz kann sich auf die Risikobewertung auswirken. Indikatoren mit höherer Volatilität können zu riskanteren Handelsentscheidungen führen, wenn sie nicht angemessen berücksichtigt werden.
"ANWENDUNG DIESES INDIKATORS
Dieser Indikator kann auf 2 Arten verwendet werden:
1) Richtungsweisender Handel:
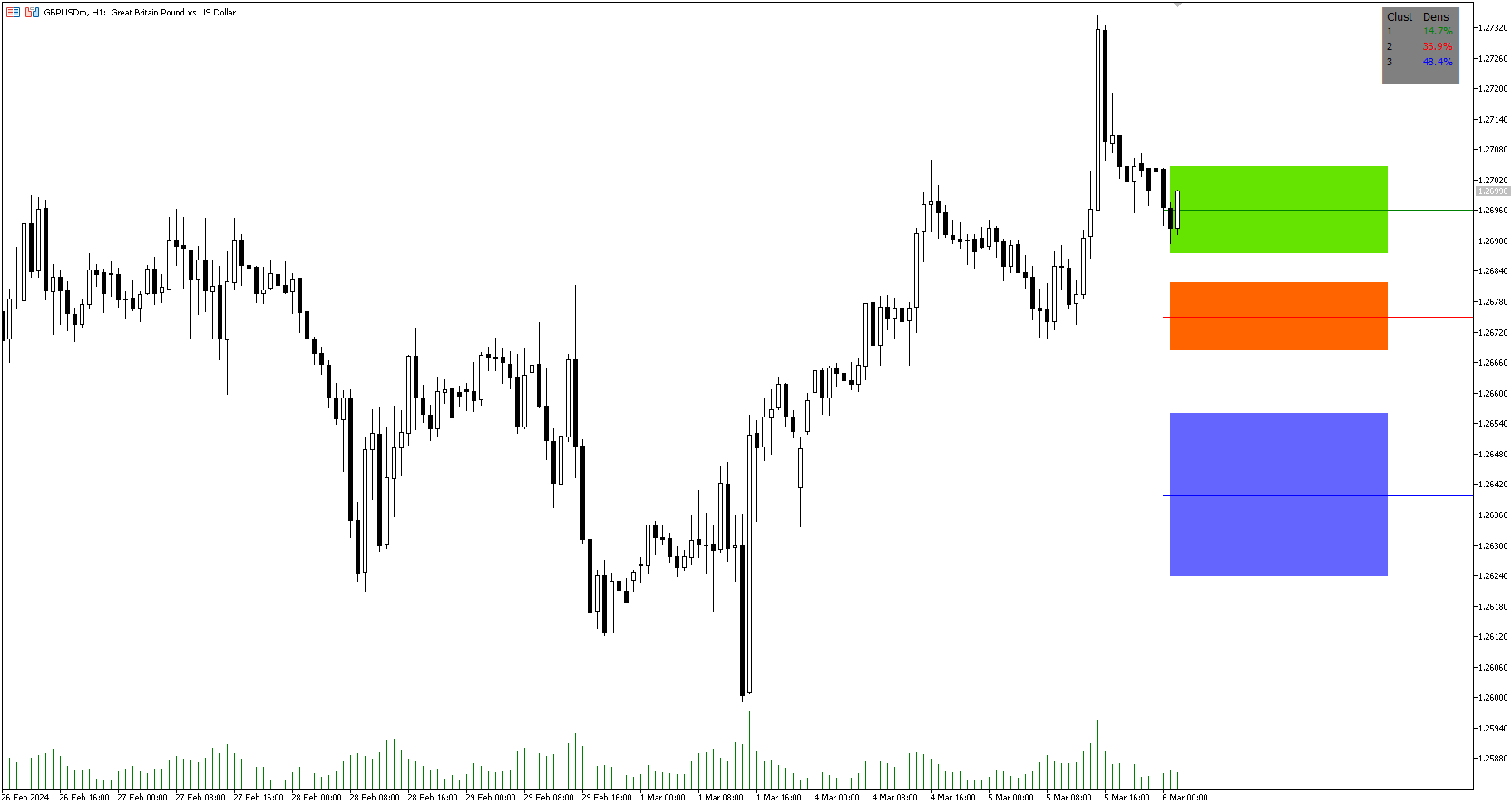
- Wenn ein Händler glaubt, dass der Preis höher oder niedriger gehen wird und der Preis innerhalb einer Cluster-Zone liegt, kann der Händler eine Position einnehmen und einen Stop auf dem 1 sd Band um den Cluster platzieren. Wie unten zu sehen ist, kann der Händler mit dem grünen Pfeil eine Long-Position eingehen und einen Stopp bei der Standardabweichungsmarke für diesen Cluster unterhalb des roten Pfeils platzieren.
- Berechnung des Chance-Risiko-Verhältnisses: Bei einem Chance-Risiko-Verhältnis von 2:1 könnte der Händler eindeutig einsteigen, wenn der nächste Widerstandsbereich oberhalb des orangefarbenen Clusters dieses Chance-Risiko-Verhältnis überschreitet.
Bild 1
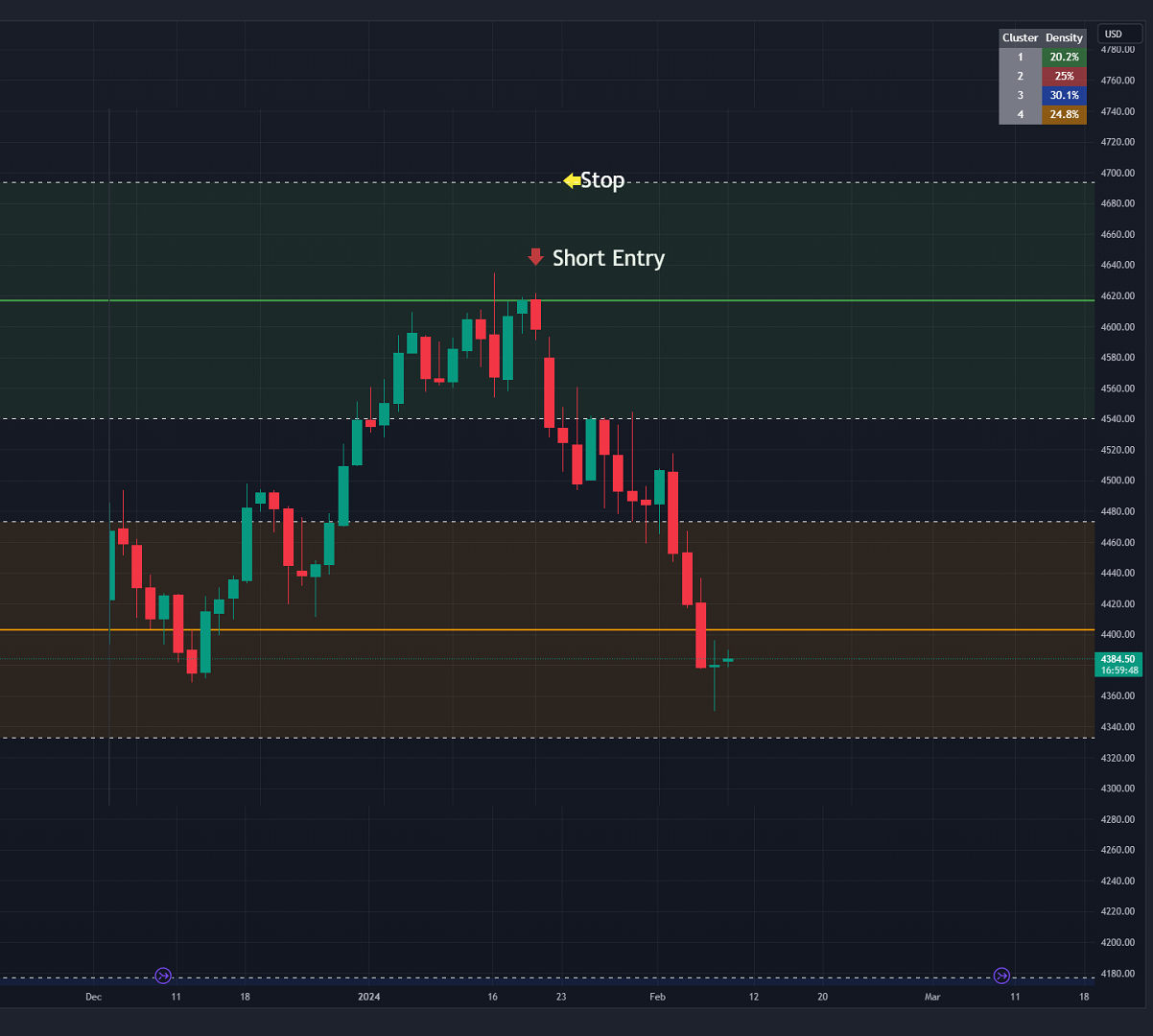
2) Einen Umkehrhandel eingehen:- Wir können die Cluster-Zentren (Unterstützungs- und Widerstandsniveaus) nutzen, um in die entgegengesetzte Richtung zu gehen, in die sich der Preis derzeit bewegt, in der Hoffnung, dass der Preis einen Drehpunkt bildet und sich von diesem Niveau aus umkehrt.
- Ähnlich wie beim direktionalen Handel können wir die Standardabweichung des Clusters nutzen, um einen Stopp zu setzen, nur für den Fall, dass wir falsch liegen.
- In diesem Beispiel unten sehen wir, dass ein Leerverkauf auf den roten Pfeil und ein Stopp bei einer Standardabweichung oberhalb dieses Clusters einen profitablen Handel mit minimalem Risiko ermöglichen würde.
- Anhand der Tabelle mit der Clusterdichte oben rechts kann der Händler erkennen, wie dicht der Cluster ist. Bei Clustern mit höherer Dichte ist die Wahrscheinlichkeit höher, dass sich auf diesen Niveaus ein Pivot bildet und der Preis zurückgewiesen wird und mit einer größeren Bewegung die Richtung wechselt.
Abbildung 2
"FEATURES & SETTINGSAllgemeine Einstellungen:
- Anzahl der Cluster: Der Benutzer kann zwischen 3 und fünf Clustern wählen. Eine gute Faustregel ist, dass beim Intraday-Handel weniger mehr ist (denken Sie eher an 3 als an 5). Für den täglichen Handel sind 4 bis 5 Cluster gut geeignet.
- Clustermethode: Um die Ausreißer-Beschränkung der k-Mittelwert-Clustermethode zu umgehen, wurde der Median hinzugefügt. Damit hat der Benutzer die Möglichkeit, entweder die k-Mittelwert- oder die k-Median-Clustermethode zu wählen. K-Mittelwerte sind die bevorzugte Methode, wenn der Benutzer davon ausgeht, dass es keine großen Ausreißer gibt, und wenn es große Ausreißer zu geben scheint oder angenommen wird, dass es welche gibt, wird K-Median bevorzugt.
- Bars back To train on: Dies ist die Anzahl der Balken, die in das Clustering einbezogen werden sollen. Diese Zahl ist wichtig, damit der Benutzer Balken einbezieht, die zwar jüngeren Datums sind, aber nicht so weit zurückliegen, dass sie nicht mehr in den Bereich fallen, in dem sich der Preis befinden kann. In den letzten 2 Jahren befanden wir uns beispielsweise in einer Spanne auf dem sp500, so dass 505 Tage in dieser Einstellung relevanter wären als z. B. eine Betrachtung von vor 5 Jahren, da sich der Kurs weit zurückbewegen müsste, um dorthin zu gelangen.
- SD-Bänder anzeigen: Wählen Sie diese Option, um die 1-Standardabweichung-Bänder um die Unterstützungs- und Widerstandsniveaus anzuzeigen, oder deaktivieren Sie diese Option, um nur die Unterstützungs- und Widerstandsniveaus selbst anzuzeigen.
- Panel anzeigen: Zeigt ein Panel an , um Informationen zu den Zonen anzuzeigen.
Funktionen:
Neben den Unterstützungs- und Widerstandsniveaus und den Standardabweichungsbändern zeigt dieser Indikator in einer Tabelle in der oberen rechten Ecke die Dichte der einzelnen Cluster (Unterstützungs- und Widerstandsniveaus) an, die farblich an die Clusterlinie im Diagramm angepasst sind. Cluster mit höherer Dichte bedeuten, dass der Kurs zuvor häufiger dort war als Cluster mit geringerer Dichte und könnten eine höhere Wahrscheinlichkeit für eine Umkehr bedeuten, wenn der Kurs diese Bereiche erreicht.
"WORKS CITED
- Victor Sim, "Using K-means Clustering to Create Support and Resistance", 2020,towardsdatascience.c...sistance-b13fdeeba12
- Chris Piech, "K-Mittel",stanford.edu/~cpiech...handouts/kmeans.html