Support and Resistance AI by K clustering MT4
- Indicadores
-
Minh Truong Pham
 Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
I will try:
+ Provide best tools base on my 5 years experience as a trader and 10 years as a programmer. - Versión: 1.3
- Activaciones: 5
"VISIÓN GENERAL
K-meanses un algoritmo de agrupación utilizado habitualmente en el aprendizaje automático para agrupar puntos de datos en distintos conglomerados en función de sus similitudes. Aunque K-means no suele utilizarse directamente para identificar niveles de soporte y resistencia en los mercados financieros, puede servir como herramienta en un enfoque de análisis más amplio.
Los niveles de soporte y resistencia son niveles de precios en los mercados financieros en los que el precio tiende a reaccionar o a invertirse. El soporte es un nivel en el que el precio tiende a dejar de caer y podría empezar a subir, mientras que la resistencia es un nivel en el que el precio tiende a dejar de subir y podría empezar a bajar. Los operadores y analistas a menudo buscan estos niveles, ya que pueden proporcionar información sobre los posibles movimientos de precios y oportunidades de negociación.
"BACKGROUND
El algoritmo K-means ha existido desde finales de 1950, por lo que tiene más de seis décadas de antigüedad. Stuart Lloyd lo introdujo en 1957 en su trabajo de investigación "Least squares quantization in PCM" para aplicaciones de telecomunicaciones. Sin embargo, no fue ampliamente conocido o reconocido hasta el artículo de James MacQueen de 1967 "Some Methods for Classification and Analysis of Multivariate Observations", donde formalizó el algoritmo y se refirió a él como el método de agrupación "K-means".
Así pues, aunque K-means existe desde hace bastante tiempo, sigue siendo un algoritmo muy utilizado e influyente en los campos del aprendizaje automático, el análisis de datos y el reconocimiento de patrones, debido a su sencillez y eficacia en las tareas de agrupación.
"COMPARA Y CONTRASTA MÉTODOS DE APOYO Y RESISTENCIA
1) Enfoque K-means:
2) Enfoque tradicional:
La diferencia clave radica en el enfoque y el fundamento de estos métodos. Los métodos tradicionales se basan en principios bien establecidos de análisis técnico y psicología del mercado, mientras que el enfoquede K-meansconsiste en agrupar el comportamiento de los precios sin incorporar necesariamente el sentimiento del mercado o patrones de precios específicos.
Es importante señalar que, si bien el enfoque de K-means puede proporcionar una forma interesante de analizar los datos de precios, debe utilizarse con precaución y junto con otros métodos tradicionales. Los mercados financieros están influidos por una amplia gama de factores que van más allá del comportamiento de los precios, y la eficacia de cualquier método para identificar niveles de soporte y resistencia debe probarse y validarse a fondo. Además, es posible que se hayan producido avances en las estrategias de negociación y en las técnicas de análisis desde mi última actualización.
"ALGORITMODE K MEDIAS
El algoritmo de K medias es el siguiente:
"LIMITACIONES DE K MEANS
Existen 3 limitaciones principales de este algoritmo:
"LIMITACIONES EN LA APLICACIÓN DE K MEANS EN EL COMERCIO
Los datos del comercio suelen presentar características que pueden plantear dificultades a la hora de aplicar indicadores y técnicas de análisis. He aquí cómo las limitaciones de los valores atípicos, las escalas variables y la varianza desigual pueden afectar al uso de indicadores en el trading:
APLICACIÓN DE ESTE INDICADOR
Este indicador puede utilizarse de 2 maneras:
1) Realizar una operación direccional:
Ajustes generales:
Características:
Además de los niveles de soporte y resistencia y las bandas de desviación estándar, este indicador ofrece una tabla en la esquina superior derecha para mostrar la densidad de cada cluster (nivel de soporte y resistencia) y está codificado por colores a la línea del cluster en el gráfico. Los clusters de mayor densidad significan que el precio ha estado allí previamente más que los clusters de menor densidad y podrían significar una mayor probabilidad de una reversión cuando el precio alcanza estas áreas.
"WORKS CITED
K-meanses un algoritmo de agrupación utilizado habitualmente en el aprendizaje automático para agrupar puntos de datos en distintos conglomerados en función de sus similitudes. Aunque K-means no suele utilizarse directamente para identificar niveles de soporte y resistencia en los mercados financieros, puede servir como herramienta en un enfoque de análisis más amplio.
Los niveles de soporte y resistencia son niveles de precios en los mercados financieros en los que el precio tiende a reaccionar o a invertirse. El soporte es un nivel en el que el precio tiende a dejar de caer y podría empezar a subir, mientras que la resistencia es un nivel en el que el precio tiende a dejar de subir y podría empezar a bajar. Los operadores y analistas a menudo buscan estos niveles, ya que pueden proporcionar información sobre los posibles movimientos de precios y oportunidades de negociación.
"BACKGROUND
El algoritmo K-means ha existido desde finales de 1950, por lo que tiene más de seis décadas de antigüedad. Stuart Lloyd lo introdujo en 1957 en su trabajo de investigación "Least squares quantization in PCM" para aplicaciones de telecomunicaciones. Sin embargo, no fue ampliamente conocido o reconocido hasta el artículo de James MacQueen de 1967 "Some Methods for Classification and Analysis of Multivariate Observations", donde formalizó el algoritmo y se refirió a él como el método de agrupación "K-means".
Así pues, aunque K-means existe desde hace bastante tiempo, sigue siendo un algoritmo muy utilizado e influyente en los campos del aprendizaje automático, el análisis de datos y el reconocimiento de patrones, debido a su sencillez y eficacia en las tareas de agrupación.
"COMPARA Y CONTRASTA MÉTODOS DE APOYO Y RESISTENCIA
1) Enfoque K-means:
- Formación de clusters: Tras aplicar el algoritmo de K-means a los datos históricos de cambios de precios y visualizar los clusters resultantes, los operadores pueden identificar distintas regiones en el gráfico de precios donde se forman los clusters. Cada conglomerado representa un grupo de patrones de cambio de precios similares.
- Análisis de conglomerados: Analice los conglomerados para identificar las zonas en las que tienden a formarse. Estas zonas podrían corresponder a regiones de comportamiento de precios que se repiten a lo largo del tiempo y podrían ser indicativas de niveles de soporte y resistencia.
- Niveles potenciales de soporte y resistencia: Basándose en las zonas identificadas de formación de conglomerados, los operadores pueden considerar estas regiones como niveles potenciales de soporte y resistencia. La formación de un cluster en un nivel de precios específico podría sugerir que este nivel ha sido históricamente significativo, causando un comportamiento similar de los precios en el pasado.
- Desviación estándar de los conglomerados: Además de observar las medias (centroides) de los conglomerados, los operadores también pueden calcular la desviación estándar de los cambios de precios dentro de cada conglomerado. La desviación estándar es una medida de la dispersión o volatilidad de los puntos de datos en torno a la media. Una desviación estándar más alta indica una mayor volatilidad de los precios dentro de un grupo.
- Desviación estándar baja: Si una agrupación tiene una desviación estándar baja, sugiere que los precios dentro de esa agrupación son relativamente estables y menos propensos a mostrar movimientos de precios repentinos y grandes. Los operadores podrían considerar colocar órdenes stop-loss más ajustadas para las operaciones dentro de estos conglomerados.
- Desviación estándar alta: Por el contrario , si un grupo tiene una desviación estándar alta, indica una mayor volatilidad de los precios dentro de ese grupo. Los operadores pueden optar por órdenes stop-loss más amplias para tener en cuenta las posibles fluctuaciones de los precios sin ser detenidos prematuramente.
- Densidad de los conglomerados: Cada punto de datos se asigna a un conglomerado, de modo que un conglomerado más denso actuará más como la gravedad y el peso.
2) Enfoque tradicional:
- Líneas detendencia: Dibuje líneas de tendencia que conecten máximos o mínimos significativos en un gráfico de precios para identificar posibles niveles de soporte y resistencia.
- Patrones gráficos: Identifique patrones gráficos como dobles máximos, dobles mínimos, cabeza y hombros, y triángulos que a menudo indican posibles puntos de reversión.
- Medias móviles: Utilice las medias móviles para identificar los niveles en los que el precio podría encontrar soporte o resistencia basándose en el precio medio durante un periodo específico.
- Niveles psicológicos: Identifique números redondos o niveles a los que los operadores suelen prestar atención y que pueden actuar como soporte y resistencia.
- Máximos y mínimos anteriores: Identificar máximos y mínimos de precios anteriores significativos que puedan actuar como soporte o resistencia.
La diferencia clave radica en el enfoque y el fundamento de estos métodos. Los métodos tradicionales se basan en principios bien establecidos de análisis técnico y psicología del mercado, mientras que el enfoquede K-meansconsiste en agrupar el comportamiento de los precios sin incorporar necesariamente el sentimiento del mercado o patrones de precios específicos.
Es importante señalar que, si bien el enfoque de K-means puede proporcionar una forma interesante de analizar los datos de precios, debe utilizarse con precaución y junto con otros métodos tradicionales. Los mercados financieros están influidos por una amplia gama de factores que van más allá del comportamiento de los precios, y la eficacia de cualquier método para identificar niveles de soporte y resistencia debe probarse y validarse a fondo. Además, es posible que se hayan producido avances en las estrategias de negociación y en las técnicas de análisis desde mi última actualización.
"ALGORITMODE K MEDIAS
El algoritmo de K medias es el siguiente:
- Inicializar los centros de los clusters
- asignar los datos a los clusters basándose en la distancia mínima
- calcular el centro del cluster tomando la media o mediana de los clusters
- repetir los pasos 1-3 hasta que los centros de los clusters dejen de moverse
"LIMITACIONES DE K MEANS
Existen 3 limitaciones principales de este algoritmo:
- Sensible a las Inicializaciones: K-means es sensible a la colocación inicial de los centroides. Diferentes inicializaciones pueden llevar a diferentes asignaciones de clusters y resultados finales.
- Suposición de tamaños y varianzas iguales: K-means asume que los conglomerados tienen aproximadamente el mismo tamaño y forma esférica. Esto puede no ser cierto para todos los tipos de datos. Puede tener problemas para identificar conglomerados con densidades, tamaños o formas desiguales.
- Impacto de los valores atípicos: K-means es sensible a los valores atípicos, ya que un solo valor atípico puede afectar significativamente a la posición de los centroides de los conglomerados. Los valores atípicos pueden conducir a la creación de conglomerados espurios o a la distorsión de la verdadera estructura de conglomerados.
"LIMITACIONES EN LA APLICACIÓN DE K MEANS EN EL COMERCIO
Los datos del comercio suelen presentar características que pueden plantear dificultades a la hora de aplicar indicadores y técnicas de análisis. He aquí cómo las limitaciones de los valores atípicos, las escalas variables y la varianza desigual pueden afectar al uso de indicadores en el trading:
- Los valores atípicos son puntos de datos que se desvían significativamente del resto del conjunto de datos. En el comercio, los valores atípicos pueden representar movimientos extremos de los precios causados por acontecimientos poco frecuentes, noticias o anomalías del mercado. Los valores atípicos pueden tener un impacto significativo en los indicadores y análisis de las operaciones:
Distorsión de los indicadores: Los valores atípicos pueden sesgar los cálculos de los indicadores, dando lugar a señales engañosas. Por ejemplo, un solo pico extremo en el precio puede hacer que indicadores como las medias móviles o el RSI (Índice de Fuerza Relativa) den señales falsas.
Gestión del riesgo: Los valores atípicos pueden llevar a decisiones de negociación demasiado agresivas si no se tienen en cuenta adecuadamente. Ignorar los valores atípicos puede dar lugar a pérdidas inesperadas o a la pérdida de oportunidades para ajustar las estrategias de negociación. - Diferentes escalas: Los datos de negociación suelen incluir múltiples indicadores con diferentes unidades y escalas. Por ejemplo, los precios suelen expresarse en dólares, el volumen en unidades negociadas y los osciladores tienen su propia escala. Mezclar indicadores con escalas diferentes puede complicar el análisis:
Normalización: Los indicadores con escalas diferentes deben normalizarse o estandarizarse para garantizar que contribuyen por igual al análisis. Si no se hace así, un indicador puede dominar el análisis debido a su mayor magnitud.
Comparabilidad: Sin normalización, es difícil comparar directamente la importancia de los indicadores. Algunos indicadores pueden tener un rango numérico mayor y eclipsar a otros. - Varianzadesigual: La varianza desigual en los datos de negociación se refiere al hecho de que algunos indicadores pueden mostrar mayor volatilidad que otros. Esto puede afectar a la interpretación de las señales y al rendimiento de las estrategias de negociación:
Ajuste de la volatilidad: Cuando se combinan indicadores con volatilidad variable, es esencial ajustar sus volatilidades relativas. De lo contrario, se podría sobrevalorar o infravalorar la importancia de determinados indicadores en la estrategia de negociación.
Evaluación del riesgo: La varianza desigual puede afectar a la evaluación del riesgo. Los indicadores con mayor volatilidad pueden llevar a decisiones de negociación más arriesgadas si no se tienen en cuenta adecuadamente.
APLICACIÓN DE ESTE INDICADOR
Este indicador puede utilizarse de 2 maneras:
1) Realizar una operación direccional:
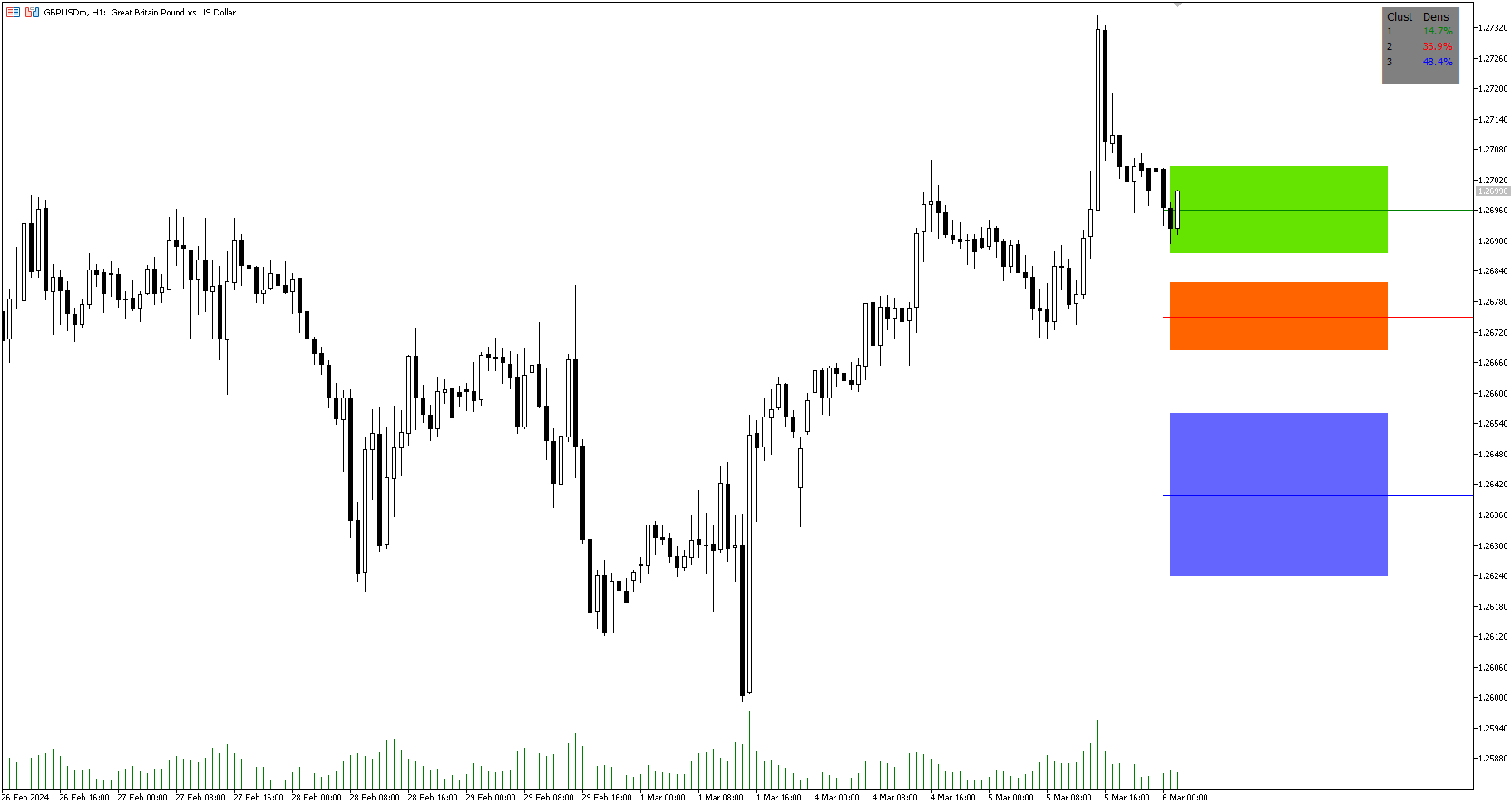
- Si un trader piensa que el precio subirá o bajará y el precio está dentro de una zona de cluster, El trader puede tomar una posición y colocar un stop en la banda de 1 sd alrededor del cluster. Como se puede ver a continuación, el operador puede ir largo de la flecha verde y colocar una parada en la marca de una desviación estándar para ese grupo por debajo de ella en la flecha roja. usando esto podemos calcular una relación riesgo-recompensa.
- Cálculo de la relación riesgo/recompensa: con un objetivo de relación riesgo/recompensa de 2:1, el inversor podría hacerlo claramente dado que la siguiente zona de resistencia por encima de la del clúster naranja supera esta relación riesgo/recompensa.
Imagen 1
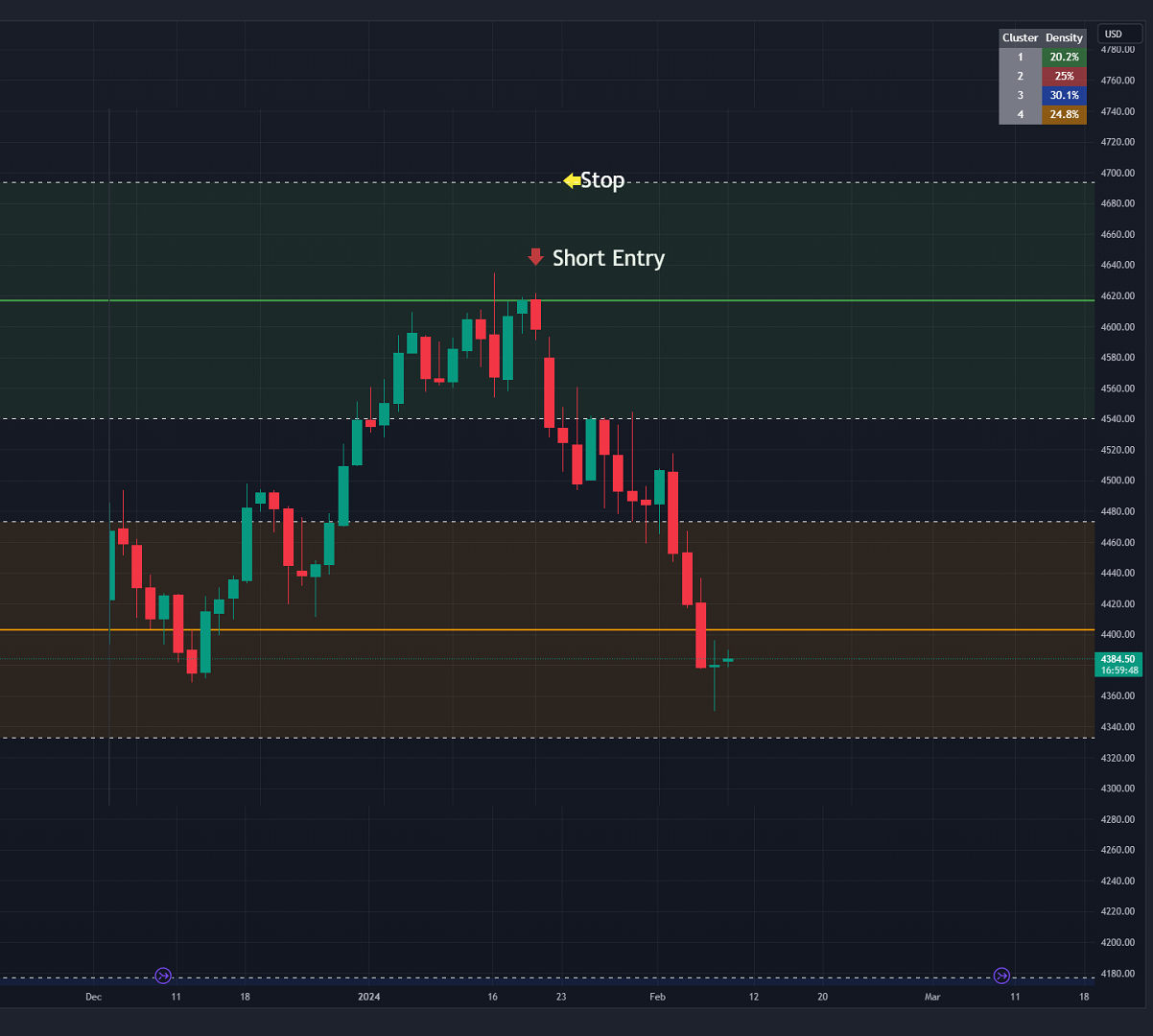
2) Realizar una operación de inversión:- Podemos utilizar los centros de clúster (niveles de soporte y resistencia) para ir en la dirección opuesta a la que el precio se está moviendo actualmente con la esperanza de que el precio forme un pivote y revierta desde este nivel.
- De forma similar a la operación direccional, podemos utilizar la desviación estándar del cluster para colocar un stop en caso de que nos equivoquemos.
- En este ejemplo de abajo podemos ver que la venta en la flecha roja y la colocación de una parada en la desviación estándar por encima de este grupo nos daría una operación rentable con un riesgo mínimo.
- La tabla de densidad de conglomerados de la parte superior derecha informa al operador de la densidad del conglomerado. Los clusters de mayor densidad darán una mayor probabilidad de que se forme un pivote en estos niveles y que el precio sea rechazado y cambie de dirección con un movimiento mayor.
Imagen 2
"CARACTERÍSTICAS Y AJUSTESAjustes generales:
- Número de clusters: El usuario puede seleccionar de 3 a cinco clusters. Una buena regla general es que si opera intradía, menos es más (piense en 3 en lugar de 5). Para operar a diario, de 4 a 5 clusters está bien.
- Método de cluster: Para evitar la limitación de los valores atípicos del clustering de k medias, se añadió la mediana. Esto ofrece al usuario la posibilidad de elegir entre la agrupación por k medias o por k medianas. K media es el método preferido si el usuario considera que no hay grandes valores atípicos, y si parece que hay grandes valores atípicos o se asume que los hay, entonces se prefiere K mediana.
- Bars back To train on: Esta será la cantidad de barras a incluir en el clustering. Este número es importante para que el usuario incluya barras que son recientes pero no tan atrás que estén fuera del alcance de donde puede estar el precio. Por ejemplo, los últimos 2 años hemos estado en un rango en el sp500, por lo que 505 días en esta configuración serían más relevantes que, por ejemplo, mirar 5 años atrás porque el precio tendría que moverse mucho para llegar allí.
- Mostrar bandas de desviaciónestándar: Seleccione esta opción para mostrar las bandas de 1 desviación estándar alrededor del nivel de soporte y resistencia o deseleccione esta opción para mostrar sólo el nivel de soporte y resistencia.
- Mostrar Panel: Muestra el panel para mostrar información de las zonas.
Características:
Además de los niveles de soporte y resistencia y las bandas de desviación estándar, este indicador ofrece una tabla en la esquina superior derecha para mostrar la densidad de cada cluster (nivel de soporte y resistencia) y está codificado por colores a la línea del cluster en el gráfico. Los clusters de mayor densidad significan que el precio ha estado allí previamente más que los clusters de menor densidad y podrían significar una mayor probabilidad de una reversión cuando el precio alcanza estas áreas.
"WORKS CITED
- Victor Sim, "Using K-means Clustering to Create Support and Resistance", 2020,towardsdatascience.c...sistance-b13fdeeba12
- Chris Piech, "K means",stanford.edu/~cpiech...handouts/kmeans.html