Mehrschichtiges Perzeptron und Backpropagation-Algorithmus (Teil 3): Integration mit dem Strategy Tester - Überblick (I).

Einführung
In früheren Artikeln haben wir die Erstellung und Verwendung von Modellen für maschinelles Lernen auf vereinfachte Weise anhand einer Client-Server-Verbindung erörtert. Diese Modelle funktionieren jedoch nur in Produktionsumgebungen, da der Tester keine Netzwerkfunktionen ausführt. Deshalb habe ich zu Beginn dieser Studie Modelle in der Python-Umgebung getestet. Das ist nicht weiter schlimm, bedeutet aber, dass das Modell (oder die Modelle) bei der Entscheidung über den Kauf oder Verkauf eines bestimmten Vermögenswerts oder bei der Implementierung technischer Indikatoren in Python deterministisch sein muss. Letzteres ist aufgrund von nutzerdefiniertem oder geschlossenem Quellcode nicht immer möglich. Das Fehlen des Strategy Testers ist besonders wichtig, wenn Sie Strategien verwenden, die nutzerdefinierte Indikatoren als Filter nutzen, oder wenn Sie Strategien mit Take-Profit und Stop-Loss, Trailing-Stop oder Breakeven testen. Die Entwicklung eines eigenen Testers, selbst in zugänglicheren Sprachen wie Python, ist eine ziemliche Herausforderung.
Übersicht
Ich brauchte etwas, das sich für Regressions- und Klassifikationsmodelle eignet und leicht in Python verwendet werden kann, also beschloss ich, ein Nachrichtensystem zu entwickeln. Das System arbeitet synchron beim Austausch von Nachrichten. Python wird die Serverseite darstellen, während MQL5 die Clientseite darstellt.
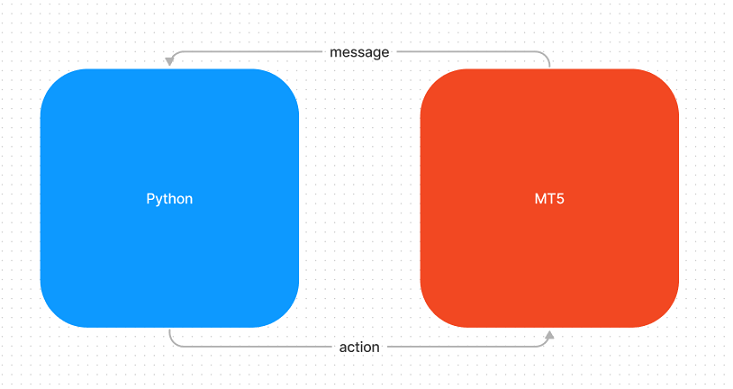
Organisation der Entwicklung
Bei der Suche nach einer Möglichkeit, das System zu integrieren, dachte ich zunächst an die Verwendung einer REST-API, die in Bezug auf Aufbau und Verwaltung recht einfach ist. Nach Durchsicht der Dokumentation für die Funktion WebRequest habe ich jedoch festgestellt, dass diese Option nicht anwendbar ist, da in der Dokumentation ausdrücklich angegeben ist, dass sie nicht verwendet werden kann.
„WebRequest() läuft nicht im Strategietester“.
Ich fand diese Einschränkung der Netzwerkfunktionen ziemlich frustrierend, aber ich suchte weiter nach anderen Möglichkeiten, Informationen auszutauschen. Ich habe darüber nachgedacht, eine Named Pipe zu verwenden, um Nachrichten in Binärdateien zu senden, aber in meinem Fall würde das nur zum Experimentieren dienen und war zu diesem Zeitpunkt nicht notwendig. Ich habe diese Idee jedoch für künftige Aktualisierungen zurückgestellt.
Als ich meine Nachforschungen fortsetzte, stieß ich auf einige Nachrichten, die mir eine neue Lösung boten:
„Viele Entwickler stehen vor demselben Problem: Wie kann man die Sandbox des Handelsterminals erreichen, ohne unsichere DLLs zu verwenden?
Eine der einfachsten und sichersten Methoden ist die Verwendung von standardmäßigen Named Pipes, die wie normale Dateioperationen funktionieren. Sie ermöglichen es, die prozessübergreifende Client-Server-Kommunikation zwischen Programmen zu organisieren.“
Bei näherem Nachdenken wurde mir klar, dass ich den Nachrichtenaustausch über CSV-Dateien nutzen könnte. Das liegt daran, dass es in Python keine Probleme mit der Verarbeitung von CSV-Daten gibt und die Standard-MQL5-Klassen, die mit Dateien arbeiten (CFile, CFileTxt usw.), das Schreiben von Daten aller Typen und Arrays erlauben, aber sie enthalten nicht die Option, den Header in eine CSV-Datei zu schreiben. Diese Einschränkung kann jedoch leicht behoben werden.
Also beschloss ich, eine Architektur zu entwickeln, die die gemeinsame Nutzung von Dateien ermöglicht, bevor ich eine Lösung auf der MQL5-Seite entwickelte. Inter-Process-Communication (IPC) ist eine Gruppe von Mechanismen, die es Prozessen ermöglichen, Informationen untereinander zu übertragen.
Nachdem ich darüber nachgedacht hatte, wie die erforderlichen Kontrollen implementiert werden können, entwarf ich die Architektur für die Bereitstellung. Auch wenn dieser Prozess unnötig oder sogar absurd erscheinen mag, ist er für die Entwicklung sehr wichtig, da er eine Vorstellung davon vermittelt, was zu tun ist und welche Aktivitäten zuerst durchgeführt werden müssen.
Mit Figma habe ich das entworfen, was ich später als Dokumentation und Referenz verwenden würde.
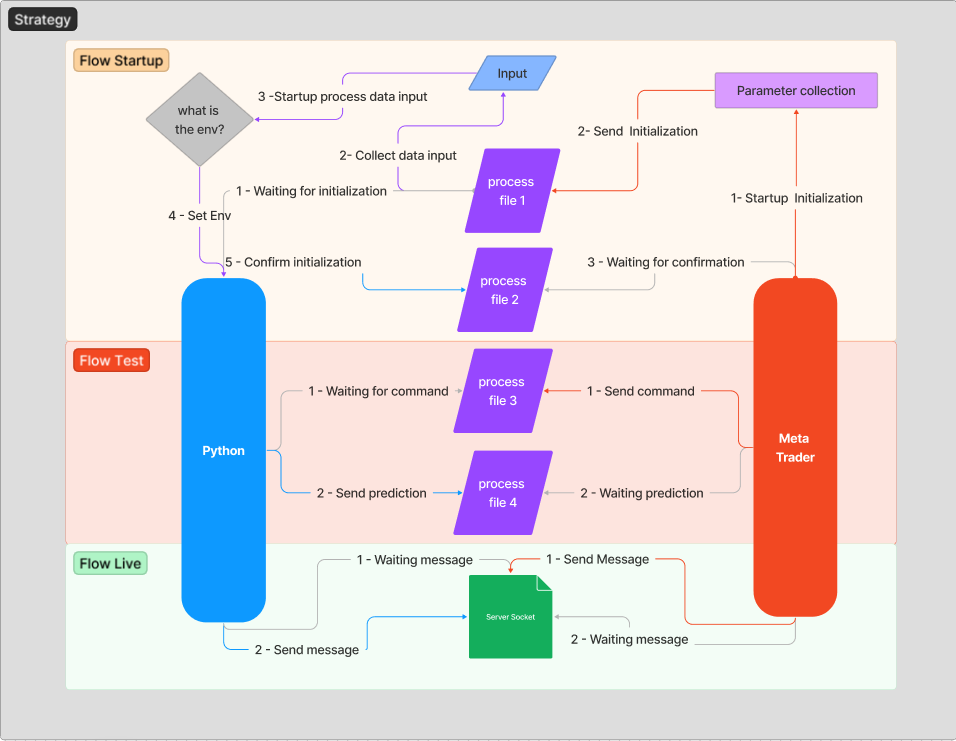
Zum besseren Verständnis des Kontextes des vorangegangenen Themas möchte ich den Nachrichtenfluss erläutern, den wir für eine stabile und sichere Kommunikation einrichten werden. Die Idee ist, zunächst nicht auf einige technische Fragen einzugehen, um die Architektur leichter verständlich zu machen.
Wenn der Server (Python) initialisiert wird, wartet er auf das Senden einer Initialisierungsnachricht, d.h. auf den Fluss „1 - Warten auf Initialisierung“. Der Nachrichtenaustausch beginnt erst, wenn der Expert Advisor an den Chart angehängt ist. Die Aufgabe von MetaTrader ist es, Python mitzuteilen, auf welchem Host, Port und in welcher Umgebung es läuft.
Die folgenden Makros sind für die Generierung des Kopfes der Initialisierungsnachricht zuständig.
#define HEADER_FILE_INIT {"host","port","typerun"} #define LINES_FILE_INT(HOST, PORT, TYPE) {{string(HOST), string(PORT), string(TYPE)}}
Wenn ich von der Umgebung spreche, meine ich den Ort, an dem der EA ausgeführt wird, entweder den Strategy Tester oder das Live-Konto. Wir werden also „Test“ für die Testumgebung und „Live“ für die Live-Umgebung verwenden.
Wie Sie unten sehen können, erhält der EA die Parameter „Host“ und „Port“.
sinput group "General Configuration" sinput string InpHost = "127.0.0.1"; sinput int InpPort = 8081;
static EtypeRun typerun= (MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_VISUAL_MODE))?TEST:LIVE;
if(!monitor.OnInit(typerun, InpHost, InpPort)) return(INIT_FAILED); bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... File.SetCommon(true); File.Open("TransferML/init.csv", FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); string header[3] = HEADER_FILE_INIT; string lines[1][3] = LINES_FILE_INT(host,port,type_run); if((File.WriteHeader(header)<1&File.WriteLine(lines)<1&!Strategy.Config(m_params))!=0) res=false; File.Close(); ... }
Im obigen Code lesen wir die Datei „init“ und übergeben die Umgebungs- und Hostdaten. Hier werden die Schritte „1- Initialisierung beim Start“ und „2- Initialisierung beim Senden“ durchgeführt.
Nachfolgend finden Sie den Python-Code, der die Initialisierung empfängt, die Daten verarbeitet, die zu verwendende Umgebung festlegt und die Initialisierung dem Client bestätigt. Hier werden die Schritte „2 - Dateneingabe sammeln“, „3 - Prozessdateneingabe starten“, „4 - Env einstellen“ und „5 - Initialisierung bestätigen“ durchgeführt.
host, port, typerun = file.check_init_param(PATH_COMMON.format(INIT_ARCHIVE))
file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE))
Nach all diesen Schritten sollte MetaTrader darauf warten, eine Bestätigung für den Serverstart zu erhalten. Dieser Schritt ist „3 - Warten auf Bestätigung“.
bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... while(!File.IsExist("TransferML/init_checked.csv", FILE_COMMON)) { //waiting for startup Comment("waiting for startup"); } ... }
Pro und Kontra
Unsere Kommunikation ist klar und effizient, denn die Standardisierung der Daten in jeder Phase sorgt für Systemstabilität. Darüber hinaus wird das Datenverständnis sowohl auf der Python-Seite durch die Verwendung der Pandas-Bibliothek als auch auf der MQL5-Seite durch die Verwendung von Matrizen und Vektoren vereinfacht.
Der Nachrichtenaustausch ist der Kern des Problems, daher habe ich mich entschieden, das Senden und Empfangen von Daten im CSV-Format zu standardisieren. Um diese Aufgabe zu vereinfachen, habe ich eine Klasse entwickelt, die den Aufwand für die Erstellung von Strings und Headern abstrahiert. Es wird als Grundlage für den Datenaustausch zwischen Umgebungen verwendet. Es folgt der Klassenkopf mit den wichtigsten Methoden und Attributen.
class CFileCSV : public CFile { private: template<typename T> string ToString(const int, const T &[][]); template<typename T> string ToString(const T &[]); short m_delimiter; public: CFileCSV(void); ~CFileCSV(void); //--- methods for working with files int Open(const string,const int, const short); template<typename T> uint WriteHeader(const T &values[]); template<typename T> uint WriteLine(const T &values[][]); string Read(void); };
Wie Sie sehen können, akzeptieren die Methoden, die Zeilen und Kopfzeilen schreiben, dynamische Vektoren und Matrizen, die es Ihnen ermöglichen, eine Datei zur Laufzeit zu erstellen, ohne dass Sie den Text mit den Funktionen „StringAdd()“ oder „StringConcatenate()“ im Hauptcode verketten müssen. Diese Arbeit wird von den „ToString“-Funktionen übernommen, die einen Vektor oder eine Matrix empfangen und in das CSV-Format konvertieren.
Zum Beispiel:
Stellen Sie sich vor, dass wir ein Modell haben, das die Werte der letzten 4 Kerzen empfängt, und die Informationen, die wir als notwendig erachten, um übermittelt zu werden, sind etwa so:
data;close;val_ma
10202022;10.55;10.49
10212022;10.95;11.09
10222022;11.55;11.29
10232022;11.15;11.29
Dieses Beispiel veranschaulicht die Verwendung von statischen Daten, die in globalen Variablen gespeichert sind. In einem realen System werden diese Daten jedoch je nach den Anforderungen der einzelnen Strategien gesammelt, wie in der Abbildung der Integrationsarchitektur zu sehen ist. Es ist wichtig zu betonen, dass die Strategie das Hauptelement des Systems ist, da sie bestimmt, welche Informationen benötigt werden, damit das Modell korrekt funktioniert. Wenn wir zum Beispiel Informationen über Preise oder Indikatoren hinzufügen müssen, wäre dies eine der Optionen. Beachten Sie jedoch, dass eine Änderung des Formats der gesendeten oder empfangenen Daten eine entsprechende Codeunterstützung erfordert. Dieses Problem kann zwar leicht behoben werden, aber es ist wichtig, die Entwicklung des Systems zu planen. Wie bereits erwähnt, handelt es sich hier nur um ein Proof-of-Concept (POC)-Beispiel, und wenn es vielversprechend aussieht, könnte es in Zukunft verbessert werden.
Um das obige Beispiel manuell zu erstellen, benötigen wir ein Array mit drei Werten für die Kopfzeile, und ein Array [4][3], das die Daten enthält. Wie Sie sehen können, ist das Schreiben und Lesen dieser CSV-Datei einfach.
#include "FileCSV.mqh" #define PATH(path) "Test/"+path+".csv" string H[3] = { "data", "close", "val_ma" }; string L[4][3] = {{"10202022", "10.55", "10.49"},{"10212022", "10.95", "11.09"},{"10222022", "11.55", "11.29"},{"10232022", "11.15", "11.29"}}; CFileCSV File; ulong start=0,time=0; void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
Der Nachteil dieses Ansatzes ist, dass die Daten auf die Festplatte geschrieben werden, was die durchschnittliche Verarbeitungsgeschwindigkeit beeinträchtigen kann. Vergleicht man sie jedoch mit der Verarbeitungsgeschwindigkeit eines Systems, das Sockets verwendet, erscheint die Leistung angemessen.
Durchführung einer Testsendung:
Wir senden 100 Dateien mit 3 Datenspalten und 4 Datenzeilen und messen dann die Geschwindigkeit der Datenübertragung.
from Services import File PATH_COMMON = r'C:\Users\letha\AppData\Roaming\MetaQuotes\Terminal\B8C209507DCA35B09B2C3483BD67B706\MQL5\Files\Test\{}.csv' INIT_ARCHIVE = 'init' INIT_OK_ARCHIVE = 'init_checked' if __name__ == "__main__": file = File() file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_OK_ARCHIVE)) while True: receive = file.check_open_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE)) void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
Hier ist das Ergebnis:
testeCSV (EURUSD,M1) Time to send 100 files, transfer message [ms]: 5578
Dieses System ist nicht außergewöhnlich, aber es hat seinen Wert, da wir kleine Datenmengen an den Server senden werden. Und die Daten werden einmal für jede neue Kerzeneröffnung gesendet, sodass wir uns darüber keine Gedanken machen müssen. Wenn Sie jedoch ein System für das Streaming von Kursen, Auftragsbuchdaten oder etwas anderem erstellen wollen, ist diese Architektur nicht zu empfehlen. Es besteht die Möglichkeit, das System in der Zukunft zu etwas Ausgefeilterem weiterzuentwickeln.
Außerdem ist der Prozess auf ein Modell/eine Strategie beschränkt, was jedoch verbessert werden kann, um in Zukunft eine bessere Skalierbarkeit zu gewährleisten.
Verwendung der linearen Regression:
Was ist lineare Regression?
Die lineare Regression ist eine in der Finanzanalyse weit verbreitete statistische Technik zur Vorhersage des Verhaltens von Finanzanlagen wie Aktien, Anleihen und Währungen. Diese Technik ermöglicht es Finanzanalysten, die Beziehung zwischen verschiedenen Variablen zu ermitteln und so die künftige Wertentwicklung eines Vermögenswerts „vorherzusagen“.
Um eine lineare Regression für Finanzanlagen anwenden zu können, müssen wir zunächst die entsprechenden historischen Daten sammeln. Dazu gehören Informationen über den Schlusskurs des Vermögenswerts, das Handelsvolumen, den Gewinn und andere relevante wirtschaftliche Variablen. Diese Daten können aus Quellen wie der Börse oder Finanzwebseiten bezogen werden.
Nach der Datenerhebung müssen wir die abhängige und die unabhängige Variable auswählen, die wir für die Analyse verwenden wollen. Die abhängige Variable ist diejenige, die vorhergesagt werden muss, während die unabhängigen Variablen diejenigen sind, die zur Erklärung des Verhaltens der abhängigen Variable verwendet werden. Wenn es zum Beispiel darum geht, den Kurs einer Aktie vorherzusagen, wäre die abhängige Variable der Kurs der Aktie, während die unabhängigen Variablen das Handelsvolumen, der Gewinn usw. sein könnten.
Anschließend muss ein statistisches Verfahren angewandt werden, um die Gleichung der Regressionslinie zu finden, die die Beziehung zwischen den unabhängigen und abhängigen Variablen darstellt. Diese Gleichung wird verwendet, um das zukünftige Verhalten eines Vermögenswertes vorherzusagen.
Nach Anwendung der linearen Regressionstechnik ist es wichtig, die Qualität der getroffenen Vorhersage zu bewerten. Zu diesem Zweck können wir die prognostizierten Ergebnisse mit den tatsächlichen historischen Daten vergleichen. Wenn die Vorhersagegenauigkeit gering ist, kann es notwendig sein, die Methodik oder die Auswahl anderer unabhängiger Variablen anzupassen.
Die lineare Regression ist eine in der Finanzanalyse weit verbreitete statistische Technik zur Vorhersage des Verhaltens von Finanzanlagen wie Aktien, Anleihen und Währungen. Diese Technik ermöglicht es Finanzanalysten, die Beziehung zwischen verschiedenen Variablen zu ermitteln und so die künftige Wertentwicklung eines Vermögenswerts vorherzusagen. Die Implementierung der linearen Regression in Python ist mit der Bibliothek scikit-learn einfach zu bewerkstelligen und kann ein wertvolles Instrument für die Vorhersage von Finanzanlagenpreisen sein. Es ist jedoch zu beachten, dass es sich bei der linearen Regression um eine grundlegende Technik handelt, die möglicherweise nicht für alle Arten von Finanzanlagen oder für bestimmte Situationen geeignet ist. Es ist immer wichtig, die Qualität der Vorhersagen zu bewerten und andere Finanzanalysetechniken zu berücksichtigen.Sie können also auch andere Techniken in Betracht ziehen, z. B. die Zeitreihenanalyse oder Prognosemodelle auf der Grundlage künstlicher Intelligenz, die ebenfalls zur Vorhersage des Verhaltens von Finanzanlagen eingesetzt werden können.
Implementierung in Python:
import random import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score from sklearn.preprocessing import OneHotEncoder random.seed(42) encoder = OneHotEncoder() # Create an empty dataframe data = pd.DataFrame(columns=['ticker', 'price', 'volume', 'economic_indicator']) # Fill the dataframe with random values for i in range(500): row = { 'ticker': "FAKE3", 'price': round(random.uniform(100, 200), 2), 'volume': round(random.uniform(10000, 100000), 2), 'economic_indicator': round(random.uniform(1, 100), 2) } data = data.append(row, ignore_index=True) print(data) # apply one-hot encoding of the column "ticker" onehot_encoded = encoder.fit_transform(data[['ticker']]) # add a new one-hot encoded column to the original dataframe data['tiker_encoder'] = onehot_encoded.toarray() # Selecting independent and dependent variables X = data[['tiker_encoder', 'volume', 'economic_indicator']] y = data['price'] # Creating the linear regression model model = LinearRegression() # Training the model on historical data model.fit(X, y) # Making predictions with the trained model y_pred = model.predict(X) # Evaluating prediction quality r2 = r2_score(y, y_pred) print("Determination coefficient:", r2) # Making predictions for new data new_data = [[1, 23228.17, 61.21]] new_price_pred = model.predict(new_data) print("Price prediction for new data:", new_price_pred)
Dieser Code verwendet die Bibliothek scikit-learn, um ein lineares Regressionsmodell auf der Grundlage von historischen Kursdaten, Handelsvolumen und einem Indikator zu erstellen. Das Modell wird anhand historischer Daten trainiert und zur Preisvorhersage verwendet. Das Bestimmtheitsmaß (R²) wird ebenfalls als Maß für die Qualität der Vorhersage berechnet. Darüber hinaus wird das Modell auch dazu verwendet, Vorhersagen anhand der neu bereitgestellten Daten zu treffen.
Bitte beachten Sie, dass dieser Code statisch ist und nur als Beispiel dient. Es lässt sich leicht an die Arbeit mit Live- und dynamischen Daten anpassen und in einer Produktionsumgebung einsetzen. Außerdem ist es notwendig, Marktdaten und Wirtschaftsindikatoren zu erhalten, um das Modell zu trainieren.
Es ist wichtig zu beachten, dass dies nur eine grundlegende Implementierung des linearen Regressionsmodells ist, das zur Vorhersage des Aktienkurses verwendet wird, und dass es notwendig sein kann, das Modell und die Daten an Ihre spezifischen Bedürfnisse anzupassen. Die Verwendung des Modells auf einem Live-Konto wird nicht empfohlen.
Das angegebene Beispiel dient nur zur Veranschaulichung und sollte nicht als vollständige Implementierung betrachtet werden. Eine detaillierte Demonstration der vollständigen Implementierung wird im nächsten Artikel vorgestellt.
Schlussfolgerung
Mit der vorgeschlagenen Architektur konnten die Beschränkungen beim Testen von Python-Modellen überwunden, eine Vielzahl von Testoptionen bereitgestellt und die Validierung und Bewertung der Effizienz von ML-Modellen unterstützt werden. Im nächsten Artikel werden wir die Implementierung der Klasse CFileCSV, die als Grundlage für den Datentransfer in MQL5 verwendet wird, näher erläutern.
Es ist wichtig anzumerken, dass die Implementierung der Klasse CFileCSV von grundlegender Bedeutung für den Datenaustausch zwischen MQL5 und Python sein wird. Sie ermöglicht die Nutzung fortgeschrittener Datenanalyse- und Modellierungsfunktionen auf beiden Plattformen und ist eine grundlegende Komponente, um die Vorteile dieser Architektur voll auszuschöpfen.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/9875
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.