Perceptrón multicapa y algoritmo de retropropagación (Parte 3): Integración con el simulador de estrategias - Visión general (I)

Introducción
En los últimos artículos, hemos tratado la construcción y el uso de modelos de aprendizaje automático de forma simplificada, mediante conexiones cliente-servidor. Sin embargo, estos modelos sólo funcionan en entornos "productivos", ya que el simulador no realiza funciones de red. Por ello, al iniciar este estudio, validé los modelos en el entorno Python, lo cual no está mal, pero implica hacer el modelo o modelos deterministas a la hora de decidir si comprar o vender un activo concreto, o implementar indicadores técnicos en Python, algunos no siempre aplicables debido al código personalizado y cerrado. Sin embargo, cuando se utiliza una estrategia que involucra indicadores personalizados como filtro, o se testea la estrategia con take and stop, trailing stop o break even, la ausencia de un simulador se hace sentir. Construir un simulador propio, incluso en lenguajes más accesibles como Python, representa todo un reto.
Visión general
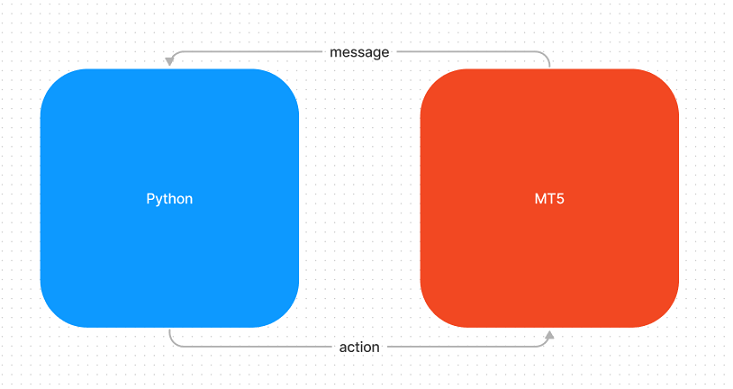
Necesitaba algo que fuera adaptable para modelos de regresión y clasificación que pudiera ser usado fácilmente en el lado Python, así que elegí construir un sistema de intercambio de mensajes. El sistema funcionará de forma sincrónica en el intercambio de mensajes, en el que Python representa el lado del servidor y MQL5 el lado del cliente.
Organización del desarrollo
En mi búsqueda de formas de integrar sistemas, inicialmente me planteé utilizar una API REST por su sencillez en cuanto a construcción y gestión. Sin embargo, al analizar la documentación de la función WebRequest, me di cuenta de que esta opción no sería viable, ya que la misma menciona explícitamente su imposibilidad.
"WebRequest() no puede ejecutarse en el Simulador de Estrategias".
Esta limitación de las funciones de red era frustrante, pero seguí explorando otras formas de realizar el intercambio de información. Inicialmente, pensé en utilizar un named pipe para transferir mensajes en ficheros binarios, pero en mi caso sólo serviría para experimentar y no era necesario en ese momento. No obstante, archivé esta idea para futuras actualizaciones.
Continuando con mi investigación, encontré textos que me aportaron una nueva solución:
"Muchos desarrolladores se enfrentan al mismo problema: cómo acceder al sandbox del terminal sin utilizar DLLs riesgosas.
Uno de los métodos más sencillos y seguros es utilizar pipes con nombre estándar que funcionan como operaciones de archivo normales. Permiten organizar la comunicación interprocesador cliente-servidor entre programas".
Al perfeccionar mi enfoque, me di cuenta de que podía utilizar mensajes de archivos CSV. Esto se debe al hecho de que, en el lado de Python, no habría ninguna preocupación con el manejo de datos CSV, y las clases estándar MQL5 que trabajan con archivos (CFile, CFileTxt, etc) permiten escribir datos de todo tipo y matrices, pero no incluyen la opción de escribir la cabecera de un archivo CSV. Sin embargo, esta limitación sería fácil de sortear.
Por lo tanto, decidí diseñar una arquitectura que permitiera el intercambio de archivos antes de desarrollar la solución en el lado MQL5. La comunicación entre procesos (del inglés Inter-Process-Communication, IPC) es el conjunto de mecanismos que permiten la transferencia de información entre procesos.
Tras planificar la implantación y los controles necesarios, elaboré la arquitectura que debía adoptarse. Aunque este proceso pueda parecer innecesario o incluso tonto, es crucial para el desarrollo, porque ofrece una visión general de lo que se va a hacer y de las actividades prioritarias.
Utilizando la herramienta Figma, elaboré la documentación y las referencias que utilizaría más adelante.
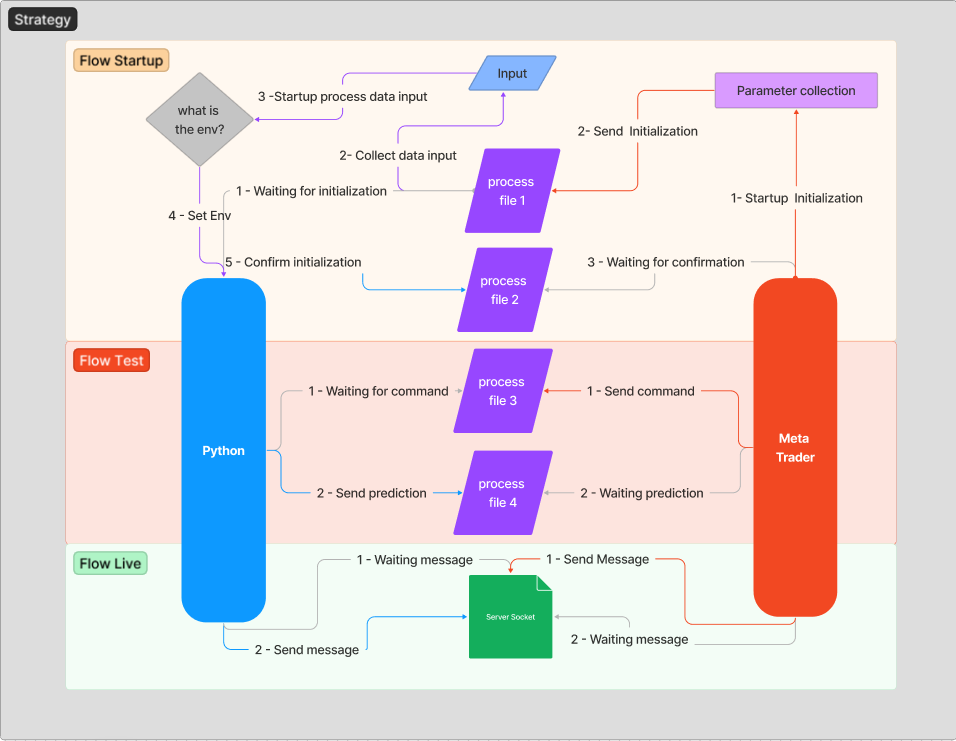
Para contextualizar mejor el hilo anterior, dejaré una explicación del flujo de mensajes que estableceremos para generar una comunicación estable y segura. La idea es no entrar inicialmente en algunas cuestiones técnicas, para facilitar la comprensión de la arquitectura que se utilizará.
Siempre que se inicialice el servidor (Python), éste esperará a que se le envíe un mensaje de inicialización, como se puede ver en el flujo "1 - Waiting for initialization". Sólo después de adjuntar el EA al gráfico, comenzará el proceso de intercambio de mensajes. MetaTrader tiene la tarea de enviar a Python en qué host, puerto y entorno se está ejecutando.
Las siguientes macros son responsables de la construcción de la cabecera del mensaje de inicialización.
#define HEADER_FILE_INIT {"host","port","typerun"} #define LINES_FILE_INT(HOST, PORT, TYPE) {{string(HOST), string(PORT), string(TYPE)}}
Cuando hablo de entorno, me refiero al lugar donde se ejecutando el EA, ya sea en el simulador de estrategias o en una cuenta real. Llamaremos al entorno de prueba "Test" y al entorno en vivo "Live".
A continuación puedes ver que el EA recibe los parámetros "Host" y "Port".
sinput group "General Configuration" sinput string InpHost = "127.0.0.1"; sinput int InpPort = 8081;
static EtypeRun typerun= (MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_VISUAL_MODE))?TEST:LIVE;
if(!monitor.OnInit(typerun, InpHost, InpPort)) return(INIT_FAILED);
bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... File.SetCommon(true); File.Open("TransferML/init.csv", FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); string header[3] = HEADER_FILE_INIT; string lines[1][3] = LINES_FILE_INT(host,port,type_run); if((File.WriteHeader(header)<1&File.WriteLine(lines)<1&!Strategy.Config(m_params))!=0) res=false; File.Close(); ... }
En el fragmento anterior, realizamos una lectura del archivo "init" y pasamos los datos del entorno y del host. En esta fase se realizan los pasos "1- Startup Initialization" y "2- Send Initialization".
A continuación vemos el fragmento de Python que recibirá la inicialización, procesará los datos, establecerá el entorno a utilizar y confirmará la inicialización al cliente. En esta fase se ejecutan los pasos "2- Collect data input", "3 -Startup process data input", "4 - Set Env" y "5 - Confirm initialization".
host, port, typerun = file.check_init_param(PATH_COMMON.format(INIT_ARCHIVE))
file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE))
Después de todos estos pasos, MetaTrader debería estar a la espera de recibir una confirmación para iniciar el Servidor. Este paso se denomina "3 - Waiting for confirmation".
bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... while(!File.IsExist("TransferML/init_checked.csv", FILE_COMMON)) { //waiting for startup Comment("waiting for startup"); } ... }
Pros y contras
Nuestra comunicación es clara y eficaz, porque al estandarizar los datos en cada paso, garantizamos la estabilidad del sistema. Además, la comprensión de los datos se simplifica tanto en el lado Python, utilizando la biblioteca pandas, como en el lado Mql5, utilizando matrices y vectores.
El intercambio de mensajes es el quid del problema, por lo que opté por normalizar el envío y la recepción en formato CSV. Para facilitar esta tarea, desarrollé una clase que abstrae el esfuerzo de crear líneas y cabeceras, y se utiliza como base para el intercambio de datos entre los entornos. A continuación se muestra la cabecera de la clase, con los principales métodos y atributos.
class CFileCSV : public CFile { private: template<typename T> string ToString(const int, const T &[][]); template<typename T> string ToString(const T &[]); short m_delimiter; public: CFileCSV(void); ~CFileCSV(void); //--- methods for working with files int Open(const string,const int, const short); template<typename T> uint WriteHeader(const T &values[]); template<typename T> uint WriteLine(const T &values[][]); string Read(void); };
Se puede observar que los métodos para guardar líneas y cabeceras aceptan vectores y matrices dinámicas, lo que posibilita construir el fichero en tiempo de ejecución, sin necesidad de concatenaciones de texto utilizando las funciones "StringAdd()" o "StringConcatenate()" en el código principal. Este trabajo lo realizan las funciones "ToString" que reciben un vector o una matriz y los convierten en texto compatible con formato CSV.
Ejemplo:
Imaginemos que tenemos un modelo que recibe el valor de las últimas 4 velas, y la información que se consideró necesario transmitir fue algo así como:
data;close;val_ma
10202022;10.55;10.49
10212022;10.95;11.09
10222022;11.55;11.29
10232022;11.15;11.29
Este ejemplo ilustra el uso de datos estáticos almacenados en variables globales, sin embargo, en un sistema real, estos datos se recogerían en función de las necesidades de cada estrategia, como puede verse en la imagen que muestra la arquitectura de integración. Es importante destacar que la estrategia es el elemento principal del sistema, ya que determina qué información es necesaria para que el modelo funcione. Por ejemplo, si se necesita añadir información sobre precios o indicadores, esa sería una posibilidad. Sin embargo, es importante recordar que si se producen cambios en el formato de los datos enviados o recibidos, será necesario realizar un mantenimiento del código. Aunque se trata de un problema fácil de evitar, es importante planificar el desarrollo del sistema. Como ya se ha dicho, se trata sólo de un ejemplo de prueba de concepto (POC) y, si es algo prometedor, puede mejorarse en el futuro.
Para crear manualmente el ejemplo anterior, necesitamos una matriz con tres valores que representarán la cabecera y una matriz [4][3] que contendrá los datos. Como se puede ver, escribir y leer este archivo CSV es sencillo.
#include "FileCSV.mqh" #define PATH(path) "Test/"+path+".csv" string H[3] = { "data", "close", "val_ma" }; string L[4][3] = {{"10202022", "10.55", "10.49"},{"10212022", "10.95", "11.09"},{"10222022", "11.55", "11.29"},{"10232022", "11.15", "11.29"}}; CFileCSV File; ulong start=0,time=0; void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
Una desventaja de este enfoque es que el almacenamiento de datos se produce en el disco, lo que puede repercutir en la velocidad media de procesamiento. Sin embargo, si se compara con la velocidad de procesamiento del sistema que utiliza sockets, se observa un rendimiento razonable.
Realización de una prueba de envío:
Enviaremos 100 archivos que contienen 3 columnas y 4 líneas de datos, y mediremos la velocidad a la que se transmiten los datos.
from Services import File PATH_COMMON = r'C:\Users\letha\AppData\Roaming\MetaQuotes\Terminal\B8C209507DCA35B09B2C3483BD67B706\MQL5\Files\Test\{}.csv' INIT_ARCHIVE = 'init' INIT_OK_ARCHIVE = 'init_checked' if __name__ == "__main__": file = File() file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_OK_ARCHIVE)) while True: receive = file.check_open_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE))
void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
Tenemos el resultado:
testeCSV (EURUSD,M1) Time to send 100 files, transfer message [ms]: 5578
Este sistema no es excepcional, pero tiene su valor porque enviaremos pequeñas cantidades de datos al servidor y este envío se realizará una vez cada nueva apertura de la vela, por lo que no tendremos que preocuparnos por ello. Sin embargo, si la intención fuera crear un sistema de streaming de cotizaciones, datos del libro o cualquier otra cosa, esta arquitectura no sería recomendable. Existe la posibilidad de convertir el sistema en algo más elaborado en el futuro.
Además, el proceso se limita a un único modelo/estrategia, pero esto puede mejorarse para dotar de mayor escalabilidad al sistema en el futuro.
Uso de la regresión lineal:
¿Qué es la regresión lineal?
La regresión lineal es una técnica estadística muy utilizada en el análisis financiero para predecir el comportamiento de activos financieros como acciones, bonos y divisas. Esta técnica permite a los analistas financieros identificar la relación entre distintas variables y "predecir" así el rendimiento futuro de un activo.
Para utilizar la regresión lineal en activos financieros, primero hay que recopilar los datos históricos pertinentes. Esto incluye información sobre el precio de cierre de un activo, el volumen negociado, el rendimiento y otros indicadores económicos relevantes. Estos datos pueden obtenerse de fuentes como la bolsa de valores o sitios web financieros.
Una vez recogidos los datos, es necesario elegir qué variable dependiente e independiente se utilizará en el análisis. La variable dependiente es la que se quiere predecir, mientras que las variables independientes son las que se utilizan para explicar el comportamiento de la variable dependiente. Por ejemplo, si el objetivo es predecir el precio de una acción, la variable dependiente sería el precio de la acción y las variables independientes podrían ser el volumen negociado, el rendimiento y otros indicadores económicos.
A continuación, hay que aplicar una técnica estadística para hallar la ecuación de la recta de regresión, que representa la relación entre las variables independiente y dependiente. Esta ecuación se utiliza para predecir el comportamiento futuro de un activo.
Tras aplicar la técnica de regresión lineal, es importante evaluar la calidad de la predicción realizada, comparando los resultados pronosticados con los datos históricos reales. Si la precisión de la predicción es baja, puede ser necesario ajustar la metodología o seleccionar variables independientes diferentes.
La regresión lineal es una técnica estadística muy utilizada en el análisis financiero para predecir el comportamiento de activos financieros como acciones, bonos y divisas. Permite a los analistas financieros identificar la relación entre distintas variables y predecir así el rendimiento futuro de un activo. La implementación de la regresión lineal en Python es fácil de hacer utilizando la biblioteca scikit-learn y puede ser una herramienta valiosa para predecir los precios de los activos financieros. Sin embargo, es importante recordar que la regresión lineal es una técnica básica y puede no ser apropiada para todos los tipos de activos financieros o situaciones específicas. Siempre es importante evaluar la calidad de la previsión y considerar otras técnicas de análisis financiero.Además, es importante recordar que la regresión lineal es una técnica estadística básica y puede no ser apropiada para todos los tipos de activos financieros o situaciones específicas. Otras técnicas, como el análisis de series temporales o los modelos de previsión basados en inteligencia artificial, también pueden utilizarse para prever el comportamiento de los activos financieros.
Implementación en Python:
import random import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score from sklearn.preprocessing import OneHotEncoder random.seed(42) encoder = OneHotEncoder() # Create an empty dataframe data = pd.DataFrame(columns=['ticker', 'price', 'volume', 'economic_indicator']) # Fill the dataframe with random values for i in range(500): row = { 'ticker': "FAKE3", 'price': round(random.uniform(100, 200), 2), 'volume': round(random.uniform(10000, 100000), 2), 'economic_indicator': round(random.uniform(1, 100), 2) } data = data.append(row, ignore_index=True) print(data) # aplica o one-hot encoding na coluna "ticker" onehot_encoded = encoder.fit_transform(data[['ticker']]) # adiciona as novas colunas one-hot encoded ao dataframe original data['tiker_encoder'] = onehot_encoded.toarray() # Selecionando as variáveis independentes e dependente X = data[['tiker_encoder', 'volume', 'economic_indicator']] y = data['price'] # Criando o modelo de regressão linear model = LinearRegression() # Treinando o modelo com os dados históricos model.fit(X, y) # Fazendo previsões com o modelo treinado y_pred = model.predict(X) # Avaliando a qualidade da previsão r2 = r2_score(y, y_pred) print("Coeficiente de determinação:", r2) # Fazendo previsões para novos dados new_data = [[1, 23228.17, 61.21]] new_price_pred = model.predict(new_data) print("Previsão de preço para novos dados:", new_price_pred)
Este código utiliza la biblioteca scikit-learn para crear un modelo de regresión lineal basado en datos históricos de precios, volumen negociado y un indicador económico. El modelo se entrena con los datos históricos y se utiliza para hacer previsiones de precios. También se calcula el coeficiente de determinación (R²) como medida de la calidad de la previsión. Además, el modelo también se utiliza para hacer previsiones con los nuevos datos proporcionados.
Cabe mencionar que este código es estático y sólo sirve como ejemplo. Puede adaptarse fácilmente para manejar datos actuales y dinámicos, y utilizarse en un entorno de producción. Además, es necesario obtener datos de mercado e indicadores económicos para entrenar el modelo.
Es importante tener en cuenta que esto es sólo una implementación básica de un modelo de regresión lineal para predecir el precio de una acción y puede que tenga que ajustar el modelo y los datos de acuerdo a su necesidad específica y no se recomienda reproducirlo en cuenta real.
El ejemplo proporcionado es sólo para fines ilustrativos y no debe considerarse como una implementación completa, una demostración detallada de la implementación completa se presentará en el próximo artículo.
Conclusión
La arquitectura propuesta resultó eficaz para superar las limitaciones a la hora de realizar pruebas con modelos Python, ofrecer diversas opciones de prueba y facilitar la validación y evaluación de la eficacia de los modelos. En el próximo artículo profundizaremos en la implementación de la Clase CFileCSV, que será la base para la transferencia de datos utilizada en MQL5.
Es importante destacar que la implementación de la Clase CFileCSV será fundamental para el intercambio de datos entre MQL5 y Python, permitiendo el uso de funciones avanzadas de análisis de datos y modelado en ambas plataformas, y será un componente clave para aprovechar al máximo esta arquitectura.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/9875
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso