
您应当知道的 MQL5 向导技术(第 33 部分):高斯(Gaussian)进程核心
概述
高斯过程核心是高斯过程中使用的协方差函数,用于衡量数据点之间的关系,例如在时间序列之中。这些核心生成捕获数据内部关系的矩阵,从而允许高斯过程假设数据遵循正态分布来进行投影或预测。由于本系列旨在探索新思路,同时也研究如何践行这些想法,因此高斯过程(GP)核心正在成为我们构建自定义信号的主题。
在过去的五篇文章中,我们最近涵盖了许多与机器学习相关的文章,因此在本文中,我们“稍事休息”,看一些老旧的统计数据。在系统开发的本质当中,两者通常是结合在一起的,不过当开发专门的自定义信号时,我们不会补充或考虑任何机器学习算法。GP 核心因其灵活性而备受关注。
它们可用来就各种数据模式进行建模,这些形态的关注点范围从周期性到趋势,甚至非线性关系。不过,比这更重要的是,在预测时,它们不光提供单个值。代之,它们提供一个不确定性估测值,其中包括期望值,以及上、下边界值。这些边界范围往往提供置信度评级,当凭借预测值表决时,这进一步促进了交易者的决策过程。这些置信度评级也很有洞察力,有助于在比较标有不同置信度的不同预测区间时更好地了解所交易证券。
此外,它们擅长处理噪声数据,因为它们允许将噪声值提升到创建的 K 矩阵(见下文),并且它们还有能力将先验知识纳入其中使用,而且它们具有很强的可扩展性。市面上有很多不同的核心可供选择。该列表包括(但不限于:平方指数核心(RBF),线性核心,周期性核心,有理二次核心,母子核心,指数核心,多项式核心,白噪声核心,点积核心,频谱混合核心,常数核心,余弦核心,神经网络(反余弦)核心,以及乘积与合计核心。
至于本文,我们只看考察 RBF 核心,又名径向基函数核心。与大多数核一样,它通过专注于任意两个数据点之间的距离,来衡量它们之间的相似性,并依据一个基本假设,即点越远,它们的相似性就越低,反之亦然。这由以下方程监管:
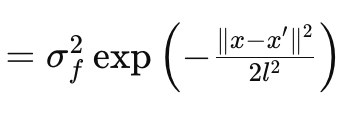
其中
- x 和 x‘:这些是输入空间中的输入向量或点。
- σ f 2:这是核心的变参,用作预判定、或可优化的参数。
- l 通常称为长度伸缩参数。它控制结果函数的平滑度。较小的 l(或较短的长度伸缩)会产生快速变化的函数,而较大的 l(较长的长度伸缩)会产生更平滑的函数。
- exp: 这是指数函数。
这个核心的 MQL5 编码可以很容易实现如下:
//+------------------------------------------------------------------+ // RBF Kernel Function //+------------------------------------------------------------------+ matrix CSignalGauss::RBF_Kernel(vector &Rows, vector &Cols) { matrix _rbf; _rbf.Init(Rows.Size(), Cols.Size()); for(int i = 0; i < int(Rows.Size()); i++) { for(int ii = 0; ii < int(Cols.Size()); ii++) { _rbf[i][ii] = m_variance * exp(-0.5 * pow(Rows[i] - Cols[ii], 2.0) / pow(m_next, 2.0)); } } return(_rbf); }
金融时间序列中的高斯过程
高斯过程是一个概率框架,其中做出的预测是根据分布,而非固定值。这就是为什么它也被称为非参数化框架。输出预测包括平均预测和围绕该预测的方差(或不确定性)。高斯过程的方差代表所做预测的不确定性或置信度。这种不确定性理论上是随机的,因为它基于高斯过程的正态分布。然而,因其意味着区间和置信度评级(通常基于 95%),因此不需要遵守其所有预测。与 ARIMA 等其它统计预测方法相比,GP 具有高度的灵活性,能够对复杂的非线性关系进行建模,并量化不确定性,而 ARIMA 更适合具有固定结构的平稳时间序列。GP 的主要缺点是计算成本高,而 ARIMA 等方法则不然。
RBF 核心
计算 GP 核心主要涉及 6 个矩阵和 2 个向量。这些矩阵和向量都在我们的 'GetOutput' 函数中所用,其代码汇总如下:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CSignalGauss::GetOutput(double BasisMean, vector &Output) { ... matrix _k = RBF_Kernel(_past_time, _past_time); matrix _noise; _noise.Init(_k.Rows(), _k.Cols()); _noise.Fill(fabs(0.05 * _k.Min())); _k += _noise; matrix _norm; _norm.Init(_k.Rows(), _k.Cols()); _norm.Identity(); _norm *= 0.0005; _k += _norm; vector _next_time; _next_time.Init(m_next); for(int i = 0; i < m_next; i++) { _next_time[i] = _past_time[_past_time.Size() - 1] + i + 1; } matrix _k_s = RBF_Kernel(_next_time, _past_time); matrix _k_ss = RBF_Kernel(_next_time, _next_time); // Compute K^-1 * y matrix _k_inv = _k.Inv(); if(_k_inv.Rows() > 0 && _k_inv.Cols() > 0) { vector _alpha = _k_inv.MatMul(_past); // Compute mean predictions: mu_* = K_s * alpha vector _mu_star = _k_s.MatMul(_alpha); vector _mean; _mean.Init(_mu_star.Size()); _mean.Fill(BasisMean); _mu_star += _mean; // Compute covariance: Sigma_* = K_ss - K_s * K_inv * K_s^T matrix _v = _k_s.MatMul(_k_inv); matrix _sigma_star = _k_ss - (_v.MatMul(_k_s.Transpose())); vector _variances = _sigma_star.Diag(); //Print(" sigma star: ",_sigma_star); Print(" pre variances: ",_variances); Output = _mu_star; SetOutput(Output); SetOutput(_variances); Print(" variances: ",_variances); } }
逐项列出,它们是:
- _k
- _k_s
- _k_ss
- _k_inv
- _v
- 以及 _sigma_star
_k 是锚点和主协方差矩阵。它捕获输入向量对与正在使用的核心函数之间的关系。我们使用的是径向基函数(RBF)核心,其源代码已在上面分享。鉴于我们正在针对时间序列进行预测,因此 RBF 核心的输入将是两个相似的时间向量,它们记录了我们要预测的数据序列的时间索引。通过对记录的时间点之间的相似性进行编码,作为判定整体结构的基础。请记住,从上面列出的 14 种核心格式中可以看出,还有很多其它的核心格式,在以后的文章中,我们可将这些备选方案视为自定义信号类。
这令我们想到了协方差矩阵 _k_s。这个矩阵也通过 RBF 核心(如 _k 矩阵)充当通往下一次索引的桥梁。这些时间索引的长度或数量,设定了要进行的投影数量,它由输入参数 length-scale 定义。我们在自定义信号类中将该参数称为 m_next。通过将消遣指数和下一次时间指数联系起来 _k_s,用于预测已知数据和下一个未知数据之间的关系,正如人们所期望的那样,这在预测中很实用。这个特定的矩阵对所做的投影高度敏感,故它的准确性需要精准,很高兴我们的代码和 RBF 核心函数可以无缝地处理这个问题。无论如何,需要小心微调方差和长度尺度这两个可调参数,以确保投影的准确性最大化。
该矩阵可以定义为:
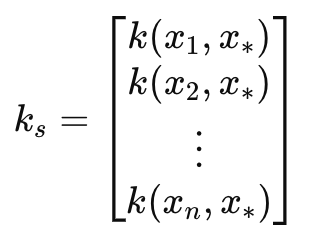
其中
- k(x i , y i ) 是向量 x 和 y 中索引 i 处两个值之间的径向基函数。在我们的例子中,x 和 y 是相同的输入时间向量,因此两个向量都标记为 x。x 通常是训练数据,而 y 是测试数据的占位符。
- k s 是训练数据与测试点 x∗ 之间的协方差向量(或偶数长度矩阵、或投影数超过 1 的矩阵)。
- x 1 、 x 2 ,..., xn 是输入训练数据点。
- x∗ 是要进行预测的输入测试数据点。
这导致 _k_ss 矩阵本质上是 _k 矩阵的镜像,主要区别在于它是预测时间指数的协方差。因此,其维度与长度伸缩输入参数相匹配。它是计算预测的不确定性估测部分的有效工具。它衡量在合并数据之前预测时间指数的方差。这可在公式中捕获,如:
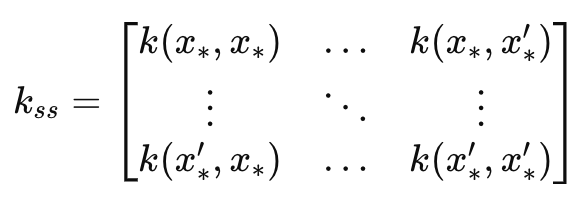
其中
- k ss 是测试数据点的协方差矩阵。
- x∗、x∗' 是要进行预测的输入测试数据点。
- k(x∗,x∗′) 是应用于测试点对 x∗ 和 x∗' 的核心函数。
顾名思义,_k_inv 矩阵是 k 矩阵的逆矩阵。矩阵的倒置由内置函数处理,但它并非没有败绩,因为通常可能无法进行倒置。这就是为什么在我们的代码中,我们检查倒置矩阵是否有任何行或列。如果不存在,则表示倒置失败。该倒置对于在预测期间计算应用于训练数据的权重非常重要。可以考虑执行该倒置的替代自定义方法,例如 Cholesky(假设它不是内置方法),不过为它们编码的选择权取决于读者。
权重向量用于基于协方差结构组合训练的输出。_alpha 判定新数据点对测试/长度伸缩点的预测有多大影响。我们从倒置 k 矩阵的矩阵乘积,及我们寻求预测的原始旧数据中获得 alpha。这就引出了我们的目标,即 _mu_star 向量。最后,基于之前数据记录输入长度伸缩周期内的预测,其大小由自定义信号类中的输入参数 m_past 定义。故此,预测均值的数量由长度伸缩判定,我们在类中称为 m_next,并且由于 MQL5 中的向量不是按序列排序的(在复制和处理汇率时),因此该预测向量的最高指数预计最后出现,就是即将发生的零索引。这意味着,除了估测序列中接下来将出现的数值外,我们还可以根据长度伸缩参数的大小来预测将要遵循的趋势。这些投影值也称为测试点。
一旦我们有了指示性均值,GP 过程还会通过 _sigma_star 矩阵提供围绕这些数值的不确定性感应。它捕获的是未来不同点、或跨测试点不同预测之间的协方差。因为我们正在进行特定数量的预测,每个测试点一个,所以我们只对这个矩阵的对角线值感兴趣。我们对预测之间的协方差不感兴趣。该矩阵的公式由下式给出:
其中
- k ss 是上述 _k_ss 新数据点的协方差矩阵。
- k s 是新数据点和训练数据之间的协方差矩阵,同上,也如前所述 _k_s。
- K 是训练数据的协方差矩阵,这是我们定义的第一个矩阵。
从我们上面的方程式中,_v 矩阵表示为 _k_s 和倒置 K-1 之间的乘积。我们正在测试 95% 置信度,且幸好有正态分布表,这意味着对于每个测试点,上边际值是预测平均值加上矩阵中相应方差值的 1.96 倍。相较之,下边际值是预测均值减去 _sigma_star 矩阵中方差值的 1.96 倍。该方差有助于量化我们对平均预测的置信度,这一点很重要,值越大表示不确定性越大。故此,置信度范围越宽(从上边际值到下边际值),置信度就越低!
旁注,但要点是,GP 核心计算涉及查找矩阵倒置,如上所述,读者可以通过参考 Cholesky 分解等方法来进一步定制,以便最大限度地减少错误和无效数字(NaNs)。除此之外,早期在 GP 核心过程中应用 _k 矩阵的常见归一化技术,是在其对角线上添加一个小的非零值,从而避免、或防止负值出现在 _sigma_star 矩阵之中。回想一下,这个矩阵具有标准差值的平方或方差值,因此它的所有值都需要为正。很奇怪,在 _k 矩阵对角线上省略这个小的添加可能会导致这个矩阵具有负值!故此这是一个重要的步骤,其在上面的 GetOutput 函数清单中已指出。
故此,我们的预测为我们提供了两件事,即预测、以及我们应该对这一预测的“信心”。至于本文,如下所示,我们仅依靠原始预测来执行测试,而不参考 _sigma_star 矩阵所隐含的置信度。这在许多方面都是 GP 核心的代表性严重缺乏,那么,我们如何在自定义信号中参考预测的隐含置信度呢?有多种方法可以实现这一点,但即使在研究这些方法之前,通过使用置信度的大小来指导持仓规模,快速解决方案通常位于自定义信号类之外。
这意味着,除了在自定义信号类中有一个 GP 核心之外,我们还会在自定义资金管理类中拥有另一个 GP 核心。在这种状况下,信号类和资金管理类都必须使用类似的输入数据集、以及方差、长度尺度参数。然而,在自定义信号类中,一个简单的合作是创建一个方差向量,复制_sigma_star 矩阵的对角线,调用我们的 'SetOutput' 函数对其进行归一化,然后检测含有最低值的索引。然后,该索引将在 _mu_star 向量中用于判定自定义信号的条件。由于 _mu_star 也调用相同的函数进行归一化,那么任何低于 0.5 的数值都将映射到看跌的负变化,而任何高于 0.5 的数值都表示看涨。
在自定义信号类中使用预测的量化不确定性的另一种方法是,我们取所有测试点上所有预测或预测的加权平均值,但使用标准化方差值作为逆转权重。它应当是逆反的,这意味着我们从 1 中减去它、或逆转它,同时在分母上添加一个小值。这种倒置很重要,因为如上所述,更大的方差意味着更多的不确定性。这种运用不确定性的方式在此处略微提及,且未在代码中、或在我们的测试运行期间实现。欢迎读者进一步来自行运作独立测试。
数据预处理和归一化
GP 核心可以用于各种金融时间序列数据,广义上讲,这些数据可以是绝对格式,比如绝对价格,也可以是增量格式,比如价格变化。至于本文,我们将使用后者测试 GP 核心 RBF。有终于此,如上面的 'GetOutput' 列表所示,我们首先用另外两个向量的差值填充 '_past' 向量,这两个向量都从不同的点位复制收盘价,相隔 1 根柱线。
除此之外,我们还要归一化这些价格变化,从原始点位转换这些价格变化,并将其置于 -1.0 到 +1.0 的范围内。用于后归一化或其他自定义方法的 'SetOutput' 函数也可用于此数据预处理。不过,就我们的测试,我们使用浮点(double)数据格式的原始价格变化,并且仅对预测值(我们上面称为测试点)应用归一化。这是调用 'SetOutput' 函数执行的,其代码如下所示:
//+------------------------------------------------------------------+ //| //+------------------------------------------------------------------+ void CSignalGauss::SetOutput(vector &Output) { vector _copy; _copy.Copy(Output); if(Output.HasNan() == 0 && _copy.Max() - _copy.Min() > 0.0) { for (int i = 0; i < int(Output.Size()); i++) { if(_copy[i] >= 0.0) { Output[i] = 0.5 + (0.5 * ((_copy[i] - _copy.Min()) / (_copy.Max() - _copy.Min()))); } else if(_copy[i] < 0.0) { Output[i] = (0.5 * ((_copy[i] - _copy.Min()) / (_copy.Max() - _copy.Min()))); } } } else { Output.Fill(0.5); } }
我们在本系列之前几篇文章中已经用过这种归一化,我们正做的只是将投影的向量值重新缩放到 0.0 到 +1.0 的范围内,要注意的重点是,在逆归一化序列中,任何小于 0.5 的值都是负的,而任何高于 0.5 的值都是正的。
测试和评测
为了我们依据 GP 核心 RBF 上测试运行,我们正在做的测试依据 EURUSD 货币对,2023 年日线时间帧。通常情况下,但非始终如此,这些设置是从非常短的优化阶段获得的,且尚未经向前遍历来验证。将我们的向导组装的智能系统应用于真实市场条件,需要读者进行更多的独立且尽职的调研,从确保依据更多历史记录、和前向遍历(交叉验证)进行广泛测试。我们的运行结果如下:


结束语
总之,我们将高斯过程核心视为交易系统的潜在信号。“高斯”往往涉及随机或假设,即所用系统假设其环境是随机的,因此它是靠押注 50-50 的赔率来赚钱。不过,它们的支持者指出,他们采用所提供数据样本,遵照概率框架来预测覆盖预定义区间。有种论调,该方法允许更大的灵活性,在于其没有对研究数据所遵循的内容做出假设(即它是非参数的)。唯一的总体假设是数据服从高斯分布。因此,为什么在过程和结果中加入不确定性,争议在于该过程不是以随机为中心的。
此外,从我们对高斯过程内核的编码和测试中,我们没有探索不确定性的量化,有争议认为这是它与其他预测方法的不同之处。话虽如此,对正态分布的使用和依赖性提出了一个问题,即高斯过程核心是应该独立使用、亦或与替代信号配对时效果最更佳。MQL5 向导,新读者可以在这里和这里找到指导,它可轻松地在单个智能系统中测试多个信号,因为每个选定的信号都可以优化到合适的权重。哪些备选信号值得与这些核心搭配?好吧,这个问题的最佳答案只能由读者从他自己的测试中提供,不过如果我要建议,那么它应该是像 RSI 这样的振荡器,或者随机振荡器、或能量潮,甚至一些新闻情绪指标。此外,简单移动平均线、移动平均线交叉、价格通道、和通常具有大量滞后的指标,在与高斯过程核心搭配时可能无法很好地工作。
我们还只研究了一种类型的核心,即径向基函数,其它格式将在以后的文章中以替代设置进行研究。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/15615
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。