
神经网络实践:第一个神经元

概述
您可能想知道:您指的是什么缺陷?我没有发现任何异常。在我的测试中,神经元表现完美。让我们回到这一系列关于神经网络的文章中,了解一下我在说什么。
在关于神经网络的最初文章中,我演示了如何迫使机器制定一个线性方程。最初,该方程被约束为通过笛卡尔平面的原点,这意味着该线必然在点(0,0)相交。这是因为下面方程中的常数 < b > 被设置为零。
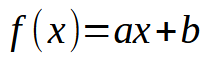
尽管我们采用最小二乘法推导出了一个合适的方程,确保数据库中存储的数据集或先验知识能够以数学形式得到适当的表示,但这种建模方法并没有帮助我们找到最合适的方程。出现这种限制是因为,根据知识库中的数据集,我们需要常数 <b> 的值不同于零。
如果你仔细阅读之前的文章,你会注意到我们不得不采用某些数学策略来确定表示斜率的常数 <a> 和表示截距的常数 <b> 的最佳值。这些调整使我们能够找到最合适的线性方程。我们探索了两种方法来实现这一点:一种通过导数计算,另一种通过矩阵计算。
然而,从现在开始,这样的计算将不再有用。这是因为我们需要设计一种替代方法来确定线性方程中的常数。在上一篇文章中,我演示了如何找到表示斜率的常数。我希望您喜欢尝试该代码,因为现在我们将要处理稍微复杂一些的问题。然而,尽管挑战性只增加了一点点,但下一步将释放无数的可能性。事实上,这可能是我们神经网络系列中最有趣的文章,因为接下来的一切都将变得更加简单和实用。
人们为什么把事情搞得这么复杂?
现在,亲爱的读者,在我们深入研究代码之前,我想帮助你理解一些关键概念。当你开始学习神经网络时,你可能会遇到大量的技术术语 — 实际上是雪崩。我不确定为什么那些解释神经网络的人倾向于将一些本质上简单的事情复杂化。在我看来,没有理由如此复杂。然而,我在这里的目的不是批评或贬低他人,而是澄清事情在幕后是如何运作的。
为了尽可能简化问题,让我们专注于与神经网络相关的一些重复出现的术语。首先是权重,该术语仅指线性方程中的斜率系数。不管别人如何描述,“权重”一词从根本上对应于斜率。另一个常用术语是偏差。这不是一个深奥的概念,也不是神经网络或人工智能所独有的。相反,偏差仅仅表示线性方程中的截距。由于我们处理的是割线,请不要混淆这些概念。
我这么说是因为很多人倾向于把事情搞得过于复杂。
他们把一些简单的事情开始添加复杂性、修饰和不必要的元素,最终使任何人都能理解的东西看起来很复杂。在编程和精确科学中,简单性是关键。当事情开始被不必要的添加、分心和过多的细节弄得一团糟时,最好停下来,去掉所有不必要的复杂性,揭示潜在的真相。许多人会坚持认为,这个主题很复杂,必须是该领域的专家才能理解或实现神经网络,而且只能使用特定的语言或工具来完成。然而,亲爱的读者,到目前为止,你应该已经意识到神经网络并不复杂。事实上它非常简单。
第一个神经元的诞生
为了使我们的第一个神经元成形 — 一旦成形,我们就不再需要对其进行修改,正如你很快就会看到的那样 — 我们必须首先了解我们正在使用什么。我们当前的神经元的行为如下图所示。
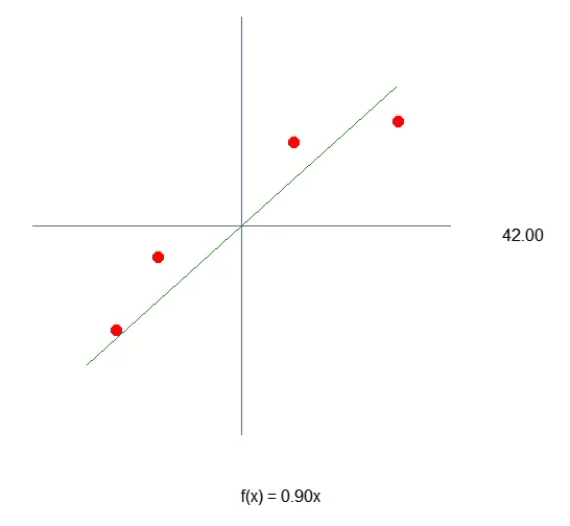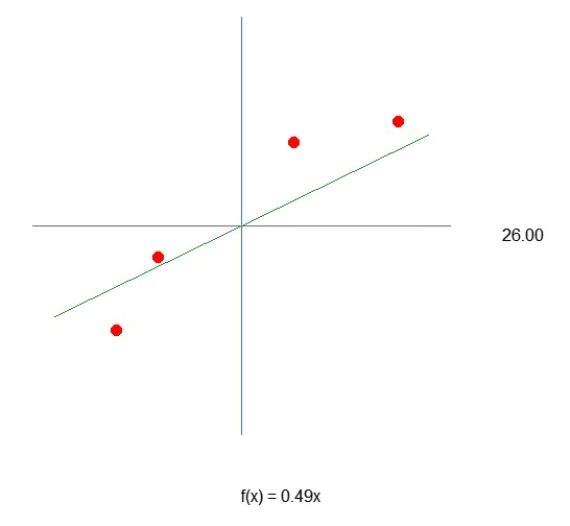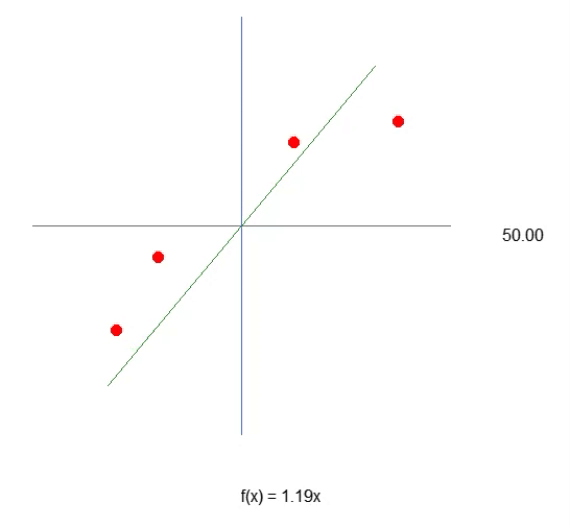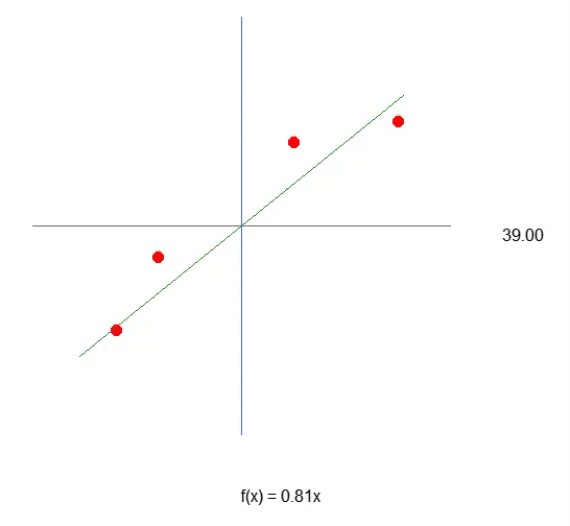
这是文章神经网络实践:割线中展示的相同动画。换句话说,我们刚刚迈出了构建神经元的第一步,该神经元能够执行以前使用方向键手动完成的任务。然而,您可能已经注意到,仅凭这一点是不够的。我们需要包括交点常数来进一步细化方程。你可能会认为这样做非常复杂,但事实并非如此。事实上,它太简单了,几乎感觉微不足道。请参阅下面我们如何将交点常数添加到神经元中。通过阅读以下代码片段可以最好地理解这一点。
01. //+------------------------------------------------------------------+ 02. double Cost(const double w, const double b) 03. { 04. double err, fx, x; 05. 06. err = 0; 07. for (uint c = 0; c < nTrain; c++) 08. { 09. x = Train[c][0]; 10. fx = a * w + b; 11. err += MathPow(fx - Train[c][1], 2); 12. } 13. 14. return err / nTrain; 15. } 16. //+------------------------------------------------------------------+
我想把代码分解成更小的片段,这样亲爱的读者就可以详细了解正在做什么。然后,你可以告诉我:这真的很复杂吗?或者,它是否需要许多人在讨论神经网络时喜欢添加的所有不必要的复杂性?
请密切关注,因为这里的复杂性几乎是荒谬的。(笑)在第九行,我们获取训练值并将其分配给变量 X。然后,在第十行,我们执行因式分解。哇!这是一个多么复杂的计算啊!但是等一下,这不是我们一开始看到的方程式吗?直线方程?你一定是在开玩笑吧!这个东西不可能作为人工智能程序中使用的神经元。
放松,亲爱的读者。你会看到,这会像任何其他人工智能或神经网络程序一样奏效。无论人们试图让它听起来多么复杂,你都会意识到,这基本上是每个神经网络中实现的相同概念。区别在于下一步,我们很快就会探讨。然而,变化并不像你想象的那么剧烈。让我们一步一步来吧。
一旦更新了误差计算,我们就可以在成本函数中修改负责调整这两个参数的片段。这将逐步完成,以便您能够掌握一些关键细节。第一步是修改上一篇文章中的原始代码,并用下面显示的新版本替换它。
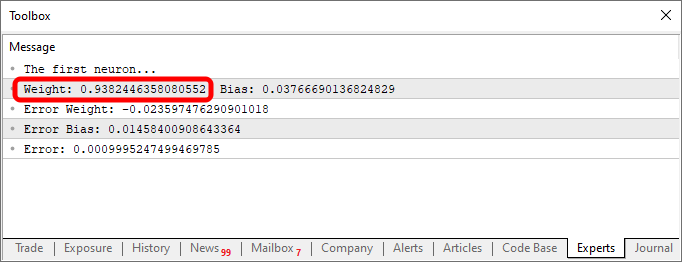
01. //+------------------------------------------------------------------+ 02. void OnStart() 03. { 04. double weight, ew, eb, e1, bias; 05. int f = FileOpen("Cost.csv", FILE_COMMON | FILE_WRITE | FILE_CSV); 06. 07. Print("The first neuron..."); 08. MathSrand(512); 09. weight = (double)macroRandom; 10. bias = (double)macroRandom; 11. 12. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight, bias)) > eps); c++) 13. { 14. ew = (Cost(weight + eps, bias) - e1) / eps; 15. eb = (Cost(weight, bias + eps) - e1) / eps; 16. weight -= (ew * eps); 17. bias -= (eb * eps); 18. if (f != INVALID_HANDLE) 19. FileWriteString(f, StringFormat("%I64u;%f;%f;%f;%f;%f\n", c, weight, ew, bias, eb, e1)); 20. } 21. if (f != INVALID_HANDLE) 22. FileClose(f); 23. Print("Weight: ", weight, " Bias: ", bias); 24. Print("Error Weight: ", ew); 25. Print("Error Bias: ", eb); 26. Print("Error: ", e1); 27. } 28. //+------------------------------------------------------------------+
在执行了这些修改后的脚本后,您将看到与下图类似的内容。
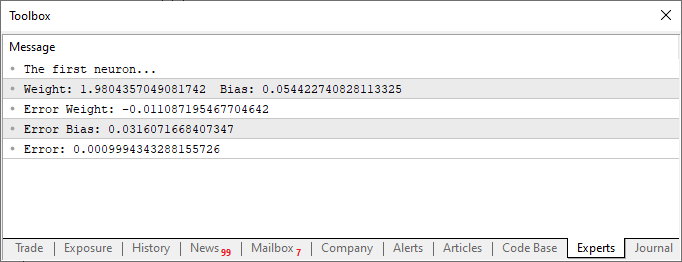
现在,让我们只关注第二段代码。在第四行中,我们添加和修改了一些变量 — 并不复杂。然后,在第十行,我们指示应用程序为偏差或交点常数分配一个随机值。请注意,我们还需要将这个值传递给 Cost 函数。这是在第 12、14 和 15 行完成的。然而,有趣的是,我们生成了两种类型的聚合误差:一种是权重值,另一种是偏差值。重要的是要明白,尽管两者都是同一个方程式的一部分,但必须以不同的方式进行调整。因此,我们需要确定每个误差在整个系统中代表的具体误差。
考虑到这一点,在第 16 行和第 17 行,我们适当调整了 for 循环下一次迭代的值。此外,正如我们在上一篇文章中所做的那样,我们还将这些值记录在 CSV 文件中。这使我们能够生成一个图表,并分析这些值是如何随时间调整的。
在这个阶段,我们的第一个神经元现在已经完全构建完成。然而,通过检查下面提供的该神经元的完整代码,您仍然可以掌握一些细节。以下是我的完整代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w, const double b) 18. { 19. double err, fx, a; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. { 24. a = Train[c][0]; 25. fx = a * w + b; 26. err += MathPow(fx - Train[c][1], 2); 27. } 28. 29. return err / nTrain; 30. } 31. //+------------------------------------------------------------------+ 32. void OnStart() 33. { 34. double weight, ew, eb, e1, bias; 35. int f = FileOpen("Cost.csv", FILE_COMMON | FILE_WRITE | FILE_CSV); 36. 37. Print("The first neuron..."); 38. MathSrand(512); 39. weight = (double)macroRandom; 40. bias = (double)macroRandom; 41. 42. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight, bias)) > eps); c++) 43. { 44. ew = (Cost(weight + eps, bias) - e1) / eps; 45. eb = (Cost(weight, bias + eps) - e1) / eps; 46. weight -= (ew * eps); 47. bias -= (eb * eps); 48. if (f != INVALID_HANDLE) 49. FileWriteString(f, StringFormat("%I64u;%f;%f;%f;%f;%f\n", c, weight, ew, bias, eb, e1)); 50. } 51. if (f != INVALID_HANDLE) 52. FileClose(f); 53. Print("Weight: ", weight, " Bias: ", bias); 54. Print("Error Weight: ", ew); 55. Print("Error Bias: ", eb); 56. Print("Error: ", e1); 57. } 58. //+------------------------------------------------------------------+
请注意上图中显示的代码和结果中有一些有趣的地方。在第六行中,您可以看到用于训练神经元的值。显然,你可以观察到乘法因子是 2。然而,神经元将其报告为 1.9804357049081742。同样,我们可以看到交点应该是零,但神经元将其表示为 0.054422740828113325。现在,考虑到第 15 行,我们接受 0.001 的误差幅度,这个结果还不错。毕竟,神经元报告的最终误差为 0.0009994343288155726,低于我们设定的可接受阈值。
这些细微的差异,你可以清楚地观察到,代表了概率指数,表明信息离正确有多近。这通常表示为百分比。然而,你永远不会看到它达到 100%。这个数字可能会非常接近,但由于不可避免的近似误差,它永远不会精确到 100%。
也就是说,这个概率指数与关于信息的确定性指数不同。在这个阶段,我们还没有着手生成这样一个指数。我们只是训练神经元,并验证它是否可以在训练数据之间建立相关性。但此时,您可能会想:整个神经元都是无用的。按照你构建它的方式,它没有任何实际用途。它只是找到一个我们已经知道的数字。我真正想要的是一个可以告诉我事情、生成文本甚至编写代码的系统。也许甚至是一个可以在金融市场运行的程序,只要我需要,就可以为我赚钱。
很公平,你确实有很大的野心。但是,亲爱的读者,如果你纯粹把神经网络或人工智能看作是赚钱的一种方式,我有一些坏消息要告诉你:你不会那样成功的。唯一真正从这一领域获利的人是那些销售人工智能和神经网络系统的人。他们试图说服其他人,人工智能可以超越熟练的专业人士。除了这些人,他们将利用销售这些解决方案获利,没有人会单独从中赚钱。如果真的那么简单,我为什么要写这些文章来解释一切是如何运作的?或者为什么其他专家会公开分享这些机制是如何运作的?这完全不合理。他们可以保持沉默并从训练好的神经网络中获利。但现实情况并非如此。所以,忘记这个想法吧,你可以把一个神经网络拼凑在一起,在这里和那里抓取一些代码片段,在没有任何真正知识的情况下立即开始赚钱。
也就是说,没有什么能阻止你,我尊敬的读者,开发一个小型神经网络来帮助你做出决策,无论是购买、出售,还是仅仅为了更好地可视化金融市场的某些趋势。有可能实现这个吗?是的。通过研究所有必要的东西,即使速度很慢,也要付出巨大的努力和奉献精神,你可以为此目的训练一个神经网络。但正如我刚才提到的,你需要付出努力。这是完全可以实现的,但并非没有工作量。
现在,我们已经成功构建了第一个神经元。但在你过于兴奋并开始思考使用它的方法之前,让我们仔细看看它的结构。为了让事情更清楚,请看下面的图片。
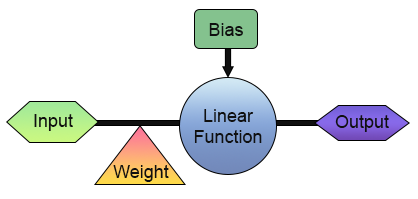
在上图中,我们可以看到我们的神经元是如何实现的。请注意,它由一个输入和一个输出组成。其中的单一输入具有权重。乍一看,这似乎没什么用。只有一个输入和一个输出有什么意义?我了解您对我们刚刚构建的事物的怀疑。然而,根据你在不同领域的背景和知识,你可能没有意识到,在数字电子中,有些电路的工作方式完全是这样的:只有一个输入和一个输出。事实上,有两种这样的电路:逆变器和缓冲器。两者都是更复杂系统的组成部分,我们的神经元实际上可以被训练来复制它们的行为。要实现这一点,您需要做的就是修改训练矩阵,如下所示。
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][2] { {0, 1}, {1, 0}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 2; const double eps = 1e-3; //+------------------------------------------------------------------+
使用此代码,您将得到类似于下图所示的内容:
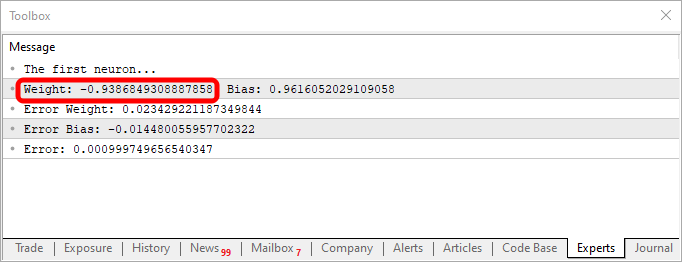
请注意,权重值为负,这意味着我们将投资于输入值。换句话说,我们有一个逆变器。使用下面的代码,我们可以得到不同的输出。
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][2] { {0, 0}, {1, 1}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 2; const double eps = 1e-3; //+------------------------------------------------------------------+
在这种情况下,输出如下图所示。
改变知识库中的数据的简单行为,在我们的例子中,知识库是一个二维数组,允许相同的代码生成一个表示不同行为的方程。这正是为什么每个对编程感兴趣的人都喜欢使用神经网络的原因。进行实验非常有趣。
Sigmoid 函数
从现在开始,我介绍的一切都只是冰山一角。无论编程看起来多么令人兴奋、复杂或有趣,从现在开始,一切都只会是可能性的一小部分。所以,亲爱的读者,在这个阶段,你应该开始更独立地研究这个课题。我的目标只是引导你沿着一条道路前进,为进一步的发现提供灵感。请随意探索、实验和享受我接下来要展示的内容。正如我之前提到的,唯一真正的限制是你的想象力。
为了让我们的单个神经元能够通过多个输入进行学习,你只需要理解一个简单但至关重要的细节。如下图所示。
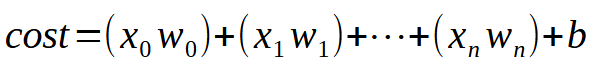
简而言之,下面给出了相同的方程式。
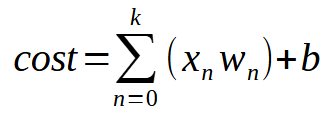
值 <k> 表示我们的神经元可以拥有的输入数量。这意味着,无论需要多少输入,我们所要做的就是添加所需数量的输入,让神经元学习如何处理每种新情况。然而,一旦我们引入第二个输入,函数就不再是线性方程(直线)。相反,它变成了一个能够表示任何可能形状的方程。这种变化是必要的,这样神经元才能适应各种训练场景。
现在,事情变得越来越严重。通过这种调整,单个神经元现在可以学习多种不同的模式。然而,超越简单的线性方程会带来一个小挑战。为了理解这一点,让我们修改我们的程序,如下所示:
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][3] { {0, 0, 0}, {0, 1, 1}, {1, 0, 1}, {1, 1, 1}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 3; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w0, const double w1, const double b) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow(((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2], 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double w0, w1, err, ew0, ew1, eb, bias; Print("The Mini Neuron..."); MathSrand(512); w0 = (double)macroRandom; w1 = (double)macroRandom; bias = (double)macroRandom; for (ulong c = 0; (c < 3000) && ((err = Cost(w0, w1, bias)) > eps); c++) { ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; eb = (Cost(w0, w1, bias + eps) - err) / eps; w0 -= (ew0 * eps); w1 -= (ew1 * eps); bias -= (eb * eps); PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", c, w0, ew0, w1, ew1, bias, eb, err); } Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); Print("Error Weight 0: ", ew0); Print("Error Weight 1: ", ew1); Print("Error Bias: ", eb); Print("Error: ", err); } //+------------------------------------------------------------------+
运行此代码时,您将得到与下图类似的结果:
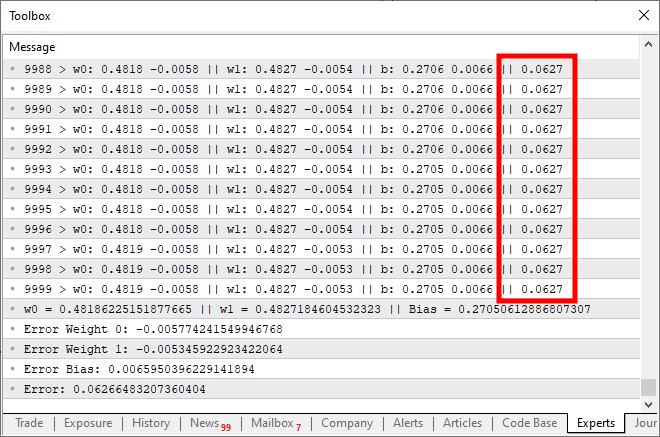
现在,这里出了什么问题?查看代码,您可以看到我们只添加了多个输入的可能性,这是正确的。然而,观察一件有趣的事情:大约一万次迭代后,成本函数停止下降。或者,如果它还在下降,它的下降速度也非常慢。为什么呢?原因是我们的神经元缺少了一些东西。当我们只有一个输入时不需要的东西,但当我们引入多个输入时变得必不可少。这种缺失的元素也用于处理神经元层,这是一种应用于深度学习的技术。然而,我们稍后将对此进行探讨。现在,让我们专注于主要问题。我们的神经元正在达到一个停滞点,在那里它根本无法进一步降低成本。解决这个问题的方法是在输出端添加一个激活函数。具体的激活函数及其行为方式取决于我们正在解决的问题的类型。没有一个通用的解决方案,我们可以使用许多不同的激活函数。然而,sigmoid 函数是最常用的函数之一。原因很简单。sigmoid 函数将负无穷到正无穷范围内的值转换为 0 到 1 之间的有界范围。在某些情况下,我们修改它以映射 -1 和 1 之间的值,但现在,我们将使用基本版本。sigmoid 函数定义如下:
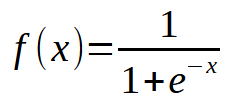
现在,我们如何将其应用于我们的代码?乍一看可能有点复杂。但是,亲爱的读者,这比看起来简单得多。事实上,我们只需要对现有代码进行一些细微的更改,如下所示:
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) #define macroSigmoid(a) (1.0 / (1 + MathExp(-a))) //+------------------------------------------------------------------+ double Train[][3] { {0, 0, 0}, {0, 1, 1}, {1, 0, 1}, {1, 1, 1}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 3; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w0, const double w1, const double b) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double w0, w1, err, ew0, ew1, eb, bias; Print("The Mini Neuron..."); MathSrand(512); w0 = (double)macroRandom; w1 = (double)macroRandom; bias = (double)macroRandom; for (ulong c = 0; (c < ULONG_MAX) && ((err = Cost(w0, w1, bias)) > eps); c++) { ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; eb = (Cost(w0, w1, bias + eps) - err) / eps; w0 -= (ew0 * eps); w1 -= (ew1 * eps); bias -= (eb * eps); PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", c, w0, ew0, w1, ew1, bias, eb, err); } Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); Print("Error Weight 0: ", ew0); Print("Error Weight 1: ", ew1); Print("Error Bias: ", eb); Print("Error: ", err); } //+------------------------------------------------------------------+
运行上述代码后,输出将类似于下图:
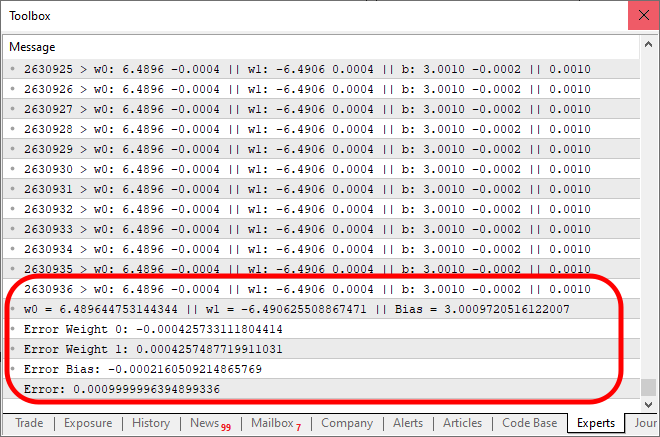
请注意:结果需要 2630936 次迭代才能收敛到预期的误差范围内。这一点也不坏。此时,您可能会觉得程序有点慢,尤其是在 CPU 上运行时。然而,这种放缓主要是由于我们在每次迭代中都会打印一条消息。加快速度的一个简单方法是修改我们呈现输出的方式。同时,让我们添加一个小测试来评估我们的神经元能力。代码的最终版本如下:
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) #define macroSigmoid(a) (1.0 / (1 + MathExp(-a))) //+------------------------------------------------------------------+ double Train[][3] { {0, 0, 0}, {0, 1, 1}, {1, 0, 1}, {1, 1, 1}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 3; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w0, const double w1, const double b) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow((macroSigmoid((Train[c][0] * w0) + (Train[c][1] * w1) + b) - Train[c][2]), 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double w0, w1, err, ew0, ew1, eb, bias; ulong count; Print("The Mini Neuron..."); MathSrand(512); w0 = (double)macroRandom; w1 = (double)macroRandom; bias = (double)macroRandom; for (count = 0; (count < ULONG_MAX) && ((err = Cost(w0, w1, bias)) > eps); count++) { ew0 = (Cost(w0 + eps, w1, bias) - err) / eps; ew1 = (Cost(w0, w1 + eps, bias) - err) / eps; eb = (Cost(w0, w1, bias + eps) - err) / eps; w0 -= (ew0 * eps); w1 -= (ew1 * eps); bias -= (eb * eps); } PrintFormat("%I64u > w0: %.4f %.4f || w1: %.4f %.4f || b: %.4f %.4f || %.4f", count, w0, ew0, w1, ew1, bias, eb, err); Print("w0 = ", w0, " || w1 = ", w1, " || Bias = ", bias); Print("Error Weight 0: ", ew0); Print("Error Weight 1: ", ew1); Print("Error Bias: ", eb); Print("Error: ", err); Print("Testing the neuron..."); for (uchar p0 = 0; p0 < 2; p0++) for (uchar p1 = 0; p1 < 2; p1++) PrintFormat("%d OR %d IS %f", p0, p1, macroSigmoid((p0 * w0) + (p1 * w1) + bias)); } //+------------------------------------------------------------------+
当您执行此更新的代码时,您将在终端中看到一条与下图所示类似的消息:
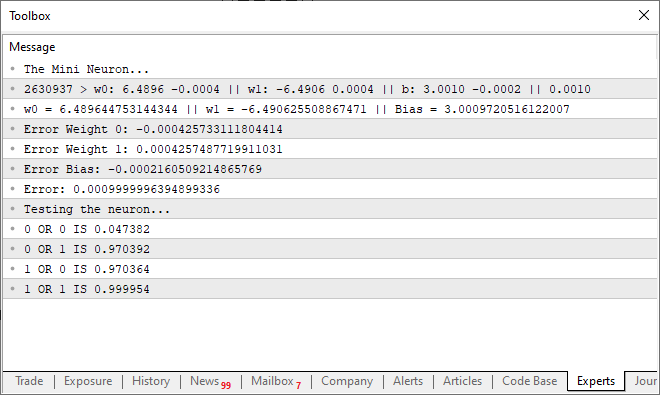
换句话说,我们成功地训练了简单的神经元来理解或门的功能。在这一点上,我们已经走上了一条不归路。我们的单个神经元现在能够学习更复杂的关系,而不仅仅是检测两个值是否相关。
最后的探讨
在这篇文章中,我们构建了一个经常让人们在看到它的实际应用时感到惊讶的东西。在 MQL5 中只需几行代码,我们就创建了一个功能齐全的人工神经元。许多人认为你需要无数的资源来实现这一点,但亲爱的读者,我希望你现在能看到事情是如何一步步发展的。在几篇文章中,我总结了许多科学家花了数年时间才完成的研究。虽然这个神经元很简单,但设计其工作原理背后的逻辑需要很长时间。即使在今天,研究仍在继续使这些计算更高效、更快。在这里,我们只使用了一个具有两个输入、五个参数和一个输出的神经元。然而,你可以看到,找到正确的方程式仍然需要一些时间。
当然,我们可以使用 OpenCL 通过 GPU 加速计算。然而,在我看来,引入这样的优化还为时过早。在我们真正需要 GPU 加速进行计算之前,我们可以进一步发展。也就是说,如果你真的想更深入地研究神经网络,我强烈建议投资 GPU。它将显著加快神经网络训练中的某些过程。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/13745
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

是的,没错,我刚在 YouTube 上看到一个视频,用 N.E.A.T 方法训练人工智能玩 flappy bird 和其他游戏,我就萌生了用 N.E.A.T 训练人工智能进行交易的想法,我刚刚学习了神经网络 的基础知识,并在 chat GPT 的帮助下创建了一个模型,因为我不会编程。我花了两周时间对数据进行归一化处理,花了两天时间创建模型,但只用了一个小时就完成了训练,1300 代,每代 20 个基因组,我那台 5 年前的二手笔记本电脑都快着火了,当我将模型连接到 MT5 时,模型非常激进,预测下一根蜡烛非常准确,但却无法盈利。但学习和看到模型预测很有趣,这也是我来这里学习更多人工智能知识的原因,这就是 NEAT 人工智能的代码。
和 MT5
和 MT5神经网络是一个非常有趣和好玩的课题。不过,由于我决定先完成重放/模拟器,所以我暂时不做解释。不过,一旦我完成了关于模拟器的文章发布,我们就会重新发布关于神经网络的新文章。我们的目标始终是展示它们在引擎盖下是如何工作的。大多数人认为神经网络是神奇的代码,其实不然。但它们仍然是一个有趣的主题。我甚至在考虑建立一些模型,让每个人都能看到神经网络是如何在没有监督或先验数据的情况下学习的。这非常有趣,有助于理解某些事情。详情:我的所有代码都将用 MQL5 编写。既然你说你不是程序员。学习 MQL5 并开始实施自己的解决方案如何?我正在写一系列针对您这样的人的文章。最新的一篇可以在这里看到:https://www.mql5.com/zh/articles/15833。 在这一系列文章中,我从最基础的东西开始讲解。因此,如果你对编程一无所知,请回到本系列的第一篇文章。文章开头都有指向前几篇文章的链接。