
Секвента ДеМарка (TD SEQUENTIAL) с использованием искусственного интеллекта

1. Введение
Системы искусственного интеллекта паутиной окутывают повседневную деятельность человека. Одними из первых их приняли на вооружение трейдеры. Предлагаю поговорить о том, как можно использовать систему искусственного интеллекта на основе нейронных сетей в трейдинге.
Для начала определимся с тем, что нейронная сеть не может торговать сама по себе. То есть, если у нас есть сеть, то мы можем сколько угодно кормить ее ценой, индикаторами и другими вкусными вещами — конечного результата от нее мы не получим, можно сразу попрощаться с этой идеей. Нейронная сеть может быть только рядом со стратегией, "прислуживать" ей: помогать принимать решение, фильтровать, прогнозировать. Нейронная сеть, которая сама по себе представляет готовую стратегию — нонсенс (во всяком случае, лично я таких не встречал).
В этой статье я расскажу, как с помощью "скрещивания" одной очень известной стратегии и нейронной сети можно успешно заниматься трейдингом. Речь пойдет о стратегии Томаса Демарка "Секвента" с применением системы искусственного интеллекта. "Секвента" хорошо описана Демарком в книге "Технический анализ — новая наука", которая будет полезна к прочтению любому трейдеру. Ознакомиться с этим трудом можно, например, здесь.
Сперва несколько слов о стратегии. "Секвента" — контртрендовая стратегия. В ней появляющиеся сигналы не зависят друг от друга. Иными словами, подряд могут поступать сигналы на покупку и на продажу, что сильно усложняет использование "Секвенты". Как и любая стратегия, она имеет ложные сигналы, которые мы и будем искать. Сам же принцип построения сигнала по "Секвенте" хорошо описан самим автором, но мы внесем в его интерпретацию небольшие изменения. Работать будем ТОЛЬКО по первой части стратегии, используя сигналы "Установка" и "Пересечение". Я выбрал их по двум причинам: во-первых, эти сигналы находятся на вершинах и впадинах, а во-вторых, появляются гораздо чаще, чем "Отсчёт" и "Вход".
Сразу хочу оговориться: торговую стратегию для встраивания искусственного интеллекта можно выбрать абсолютно любую — даже обычное пересечение МА. В любом случае, главным в каждой стратегии будет момент принятия решения. Дело в том, что анализировать каждый бар — утопия, и поэтому нужно определиться, в какие моменты, на каких барах мы будем исследовать ситуацию на рынке. Именно для этого и служит торговая стратегия. Способы анализа, повторюсь, могут быть абсолютно любые — от пересечения МА до фрактальных построений, главное в нашем случае — получить сигнал. В нашем случае, в "Секвенте", нас интересует окно из зелёных точек, в течение которого мы и будем определять поведение рынка и делать вывод об истинности или ложности этого сигнала.
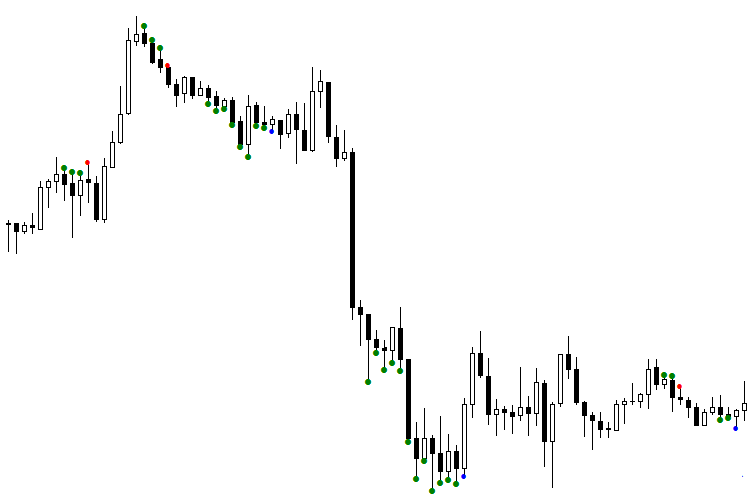
Рис. 1. Индикатор TDSEQUENTA by nikelodeon.mql5
Разберем рисунок работы торговой стратегии "Секвента" без использования нейронной сети. На рисунке вы можете наблюдать появление зелёных точек. Здесь показан адаптивный вариант построения стратегии — когда мы берём не конкретное количество баров (например, 9 баров подряд), а пока выполняется условие. Как только условие построения перестало выполняться, появляется сигнал. Таким образом, каждый сигнал появляется после собственного количества точек, в зависимости от текущего поведения рынка. Именно тут и происходит адаптация "Секвенты" к рынку. Этот эффект даёт возможность выбора для анализа окна, которое состоит из зелёных точек. Для каждого сигнала это окно имеет разную длительность. При использовании ИИ это даёт определённое преимущество. Я выбрал такую расцветку: синяя точка после зелёных означает сигнал к покупке, а красная — к продаже.
Видим, что первый сигнал на продажу (красная точка) оказался ложным, потому что следующий за ним сигнал оказался выше. При условии, что мы работаем от сигнала до сигнала, если бы мы вошли в рынок по этой красной точке, то обязательно потеряли бы средства. Первая синяя точка тоже обманула нас: купив по ней, мы получили бы ощутимый минус. Как же разделить сигналы на ложные и истинные? В этом нам и поможет искусственный интеллект, а точнее — нейронная сеть (НС).
2. Контекст рынка
Позавчера ваша торговая система работала отлично. Вчера — из рук вон плохо. Сегодня всё опять стало терпимо. Знакомая ситуация? Конечно, каждый трейдер сталкивается с тем, что качество работы торговой системы меняется день ото дня. Дело не в самой системе. Виноват так называемый контекст торгового дня. Он формируется на основании предыдущего изменения объёма торгов, открытого интереса и изменения цены. Проще говоря, фон торгов определяется именно этими данными, которые на момент закрытия каждого дня разные. Таким образом мы подходим к важной рекомендации: оптимизируйте своих роботов на днях, аналогичных по условиям тем, на которых он будет торговать. Самая сложная задача при оптимизации НС — сделать так, чтобы в обучающую выборку попали те паттерны, которые будут сформированы в текущем дне. Один из способов такого попадания и есть "Контекст дня"
Рассмотрим пример. Допустим, сегодня объём торгов и открытый интерес упали, при этом курс вырос. Судя по всему, рынок слабеет, и мы ожидаем разворота вниз. Натренировав НС ТОЛЬКО на таких днях, когда падал объём и открытый интерес при одновременном росте курса, мы с большей вероятностью представим на вход НС такие паттерны, которые имеем шанс увидеть в течение дня. То есть, получается, что НС натренировалась в рамках "Контекста рынка". Скорее всего, реакция рынка будет такой же, как и в день со схожими параметрами. Нетрудно посчитать, что глобальных вариантов сочетания объёма, цены и открытого интереса всего лишь девять. Натренировав сеть под каждый контекст отдельно, мы охватим весь рынок. Девять натренированных моделей в среднем работают недели две, а в отдельных случаях — еще дольше.
Организовать работу в рамках контекста дня очень просто с помощью индикатора eVOLution-dvoid.1.3 (1). По сути, этот индикатор читает данные из csv-файла, расположенного в директории ...\Files\evolution-dvoid\dvoid-BP.csv. Как видим, здесь используется котировка британского фунта по отношению к доллару США. Чтобы правильно отображать данные и впоследствии иметь возможность пользоваться ими именно в контексте дня, нужно каждое утро, примерно в 7:30 МСК, заходить на сайт Чикагской фондовой биржи. Там мы скачиваем дневной бюллетень (для фунта это бюллетень номер 27), в котором указан объём и открытый интерес на момент закрытия вчерашнего дня. Эти данные каждый день перед началом торгов мы заносим в файл "dvoid-BP.csv", и в течение дня индикатор будет отображать изменение объема по сравнению с предыдущим значением. То есть, нас интересует не фактическое значение рыночного объема, а его изменение. Точно так же и с открытым интересом: важно его относительное движение.
3. Подход к организации модели
Чтобы увеличить обучающую выборку и обеспечить должный уровень обобщения, введем важное условие. Делить сигналы на истинные и ложные мы будем отдельно для покупки и для продажи. Таким образом, ресурсы самой НС не будут затрачиваться на сортировку сигналов. Мы сами заранее разделим эти сигналы и построим две модели: одна будет отвечать за сигналы на покупку, другая — на продажу. Таким нехитрым путем мы вдвое увеличим размер обучающей выборки. При этом известно: чем больше обучающая выборка и чем выше ее уровень обобщения, тем дольше модель будет адекватна рынку.
Введем понятие доверительного интервала: это интервал, на котором мы доверяем модели и считаем её пригодной для использования. Предположим, что доверительный интервал для посчитанной модели — это 1/3 от интервала обучения. То есть, обучив модель на 30 сигналах, мы предполагаем, что период адекватной работы ее составит 10 сигналов. Однако случаи, когда модель отрабатывала в три раза дольше, чем интервал обучения — тоже не редкость.
Замечено (и это вполне естественно), что когда увеличивается интервал обучения, обобщающая способность модели снижается. Это подтверждает теорию о том, что граалей не существует. Ведь если представить, что мы смогли обучить НС на всей истории рынка, со 100% уровнем обобщения, то мы бы получили идеальную модель, которая работала бы всегда. Увы, практика показывает, что это утопия. Но вот построить хорошую долгоиграющую модель всё-таки можно. Секрет кроется в данных, которые подаются на вход сети. Если они отражают суть выходной переменной и являются для неё причиной, то построить модель будет несложно.
Кстати, о выходной переменной. Ее выбрать так же трудно, как и найти входные данные для построения сети. Глядя на исторические данные сигналов, мы можем точно определить, какой из них был истинным, а какой — ложным. И как правило, при построении выходной переменной мы однозначно интерпретируем каждый сигнал, делая выход сети идеальным. То есть, в нашем выходе нет ни одной ошибки, а это заставляет НС стремиться в обучении к таким же идеальным выходам. Естественно, что так получить модель с уровнем обобщения в 100% на длинном интервале практически невозможно. Ведь вряд ли найдутся такие данные, которые смогли бы безошибочно трактовать сигналы выходной переменной достаточно долго. Более того, при их наличии необходимость в использовании НС отпадает полностью.
В связи с этим формировать выходную переменную нужно с маленькими ошибками, когда небольшие убытки от сигналов перекрываются значимыми прибылями. В итоге мы имеем выходную переменную, которая не идеальная, но имеет потенциал увеличения депозита. Другими словами, ошибки приносят незначительные убытки, которые с лихвой перекрываются другими, прибыльными сигналами. Это даёт возможность получить модель с высоким уровнем обобщения к выходной переменной. Очень важно в данном случае то, что мы знаем степень ошибки такой модели. Следовательно доверие к сигналу будет содержать эту поправку.
И, наконец, самый важный момент при построении моделей — выбор смысловой нагрузки на выходную переменную. Естественно, в первую очередь мы вспомним профит. Прибыльные в прошлом сигналы обозначим как 1, а убыточные — как 0. Однако существует масса других семантических переменных для выхода, которые будут давать дополнительную ценную информацию о рынке. Например: будет ли откат после сигнала, дойдёт ли дело до определённого профита, будет ли следующий за сигналом бар медвежьим или бычьим? Так что наделить смыслом выходную переменную можно по разным направлениям, при этом используются одни и те же входные данные. Так мы получаем больше информации о рынке, и если несколько моделей подтверждают друг друга, то вероятность профита растет.
Нередко я встречал трейдеров, которые пытаются получить 100 и более сигналов на длинном интервале. Так вот, это стремление я не разделяю. По моему мнению, для заработка достаточно 10-15 сигналов, но ошибка их не должна быть выше 20%. Это связано с тем, что даже если два сигнала из десяти дадут максимальный убыток, правильных сигналов у нас будет восемь. Хотя бы два из них принесут прибыль, перекрывающую потери.
Так как же всё-таки сделать модель, которая проработает достаточно долго? Скажем, нас интересует стабильная работа системы на 5М в течение одной или двух недель — хороший результат, если работать без переоптимизации. Предположим что наш основной индикатор, основная торговая система (в нашем случае это "Секвента") даёт в среднем по 5 сигналов каждый день. Для каждой из девяти моделей контекста рынка мы будем брать по 10 сигналов. При этом торговых дней в неделе всего пять. То есть, получается, что какие-то модели вообще не отработают, а какие-то отработают. Как показывает практика, каждая модель за неделю срабатывает не более двух, и очень редко — трёх раз. Выходит, Обобщённая ТС будет в целом работать даже дольше, чем одну неделю, с учётом доверительного интервала на периоде вне выборки в размере 10 сигналов.
4. Теория нейронных сетей
Теперь перейдем к теории нейронных сетей. Вы, конечно же, подумали что я буду учить вас топологиям, названиям и методам обучения? Вы ошибаетесь.
Речь пойдет о следующем. Существует два направления в использовании нейронных сетей, разных по топологии. Одна из них — прогнозирующая, а вторая классификационная.
Прогнозирующая сеть выдаёт будущее значение выходной переменной. Считается, что, помимо направления курса (вверх или вниз), она выдает еще и степень этого направления. Например, сейчас курс евро 1.0600, а сеть выдаёт, что через час он вырастет до 1.0700 — она предугадывает эти +100 пунктов. Сразу оговорюсь, что такой подход к нейронным сетям я не разделяю, поскольку будущее не определено. Лично мне этого философского аргумента достаточно для того, чтобы отказаться от этого метода работы с НС. Разумеется, я понимаю, что это всего лишь дело вкуса, и справедливости ради отмечу, что прогнозирующие сети хорошо справляются с поставленными задачами.
Однако же я использую классификационные сети. Они дают нам представление о текущем состоянии рынка, и чем точнее мы его определим, тем удачней сложится наша торговля. Получение отклика сети в обоих случаях приводит нас к совершению какого-либо действия. В первом случае мы покупаем в точке 1.0600 и продаем, когда цена достигает 1.0700. Во втором случае — просто покупаем и выходим из сделки по следующему сигналу, но мы не можем предугадать, на каком уровне цены это будет.
Чтобы раскрыть суть этого подхода, приведу один исторический анекдот. Однажды чемпиона мира по шахматам Гарри Каспарова спросили, на сколько ходов вперед в партии он думает, планируя следующий ход. Все думали, что сейчас Каспаров скажет какую-то огромную цифру. Однако то, что сказал шахматист, доказывает, что далеко не все понимают даже суть игры: "Главное в шахматах — не то, на сколько ходов вперед ты думаешь, а то, насколько хорошо ты анализируешь текущую ситуацию”. Так же и на валютном рынке: чтобы понимать суть игры, не обязательно заглядывать на несколько баров вперёд. Достаточно определить текущее состояние рынка в определённый момент и сделать правильный ход.
Именно эта идеология мне ближе всего по духу, но повторюсь, это дело вкуса. Прогнозирующие нейронные сети тоже пользуются популярностью, им нельзя отказывать в праве на существование.
5. Внутренняя организация системы искусственного интеллекта
Наряду с существованием двух подходов к построению и использованию нейронных сетей (прогнозирования и классификации), в этой предметной области есть и два типа специалистов — разработчики систем ИИ и их пользователи. Я уверен, что Страдивари очень хорошо играл на своих скрипках, однако как великий виртуоз он не прославился. Безусловно, создатель инструмента умеет им пользоваться, но не всегда мастер может полностью раскрыть потенциал того, что создал. К сожалению, я так и не смог связаться с автором прилагаемого здесь оптимизатора: он не отвечает на письма. Однако многим завсегдатаям форума он известен. Это Юрий Решетов.
Я использовал его подход в работе и по итогам общения с ним выяснил внутреннюю структуру оптимизатора, о которой и хочу рассказать Вам. Надеюсь, автор будет не против: продукт был выложен в режиме открытого источника. Мне, как пользователю систем ИИ, не обязательно разбираться в программном коде, но знать внутреннюю структуру оптимизатора необходимо. Я обратил внимание именно на этот продукт, в первую очередь, потому что в оптимизаторе использовался метод обучения, отличный от классических. Ахиллесова пята при обучении нейронных сетей — их переобучение. Произошло ли оно и какова его степень — вычислить практически невозможно. В оптимизаторе Решетова используется другой подход: переобучить сеть невозможно, можно только недообучить. Этот подход позволяет оценивать качество обучения сети в процентном соотношении. Мы имеем верхнюю границу обучения в 100%, к которой стремимся (такого результата очень тяжело добиться). Получив сеть, обученную, предположим, на уровне 80%, мы будем знать, что в 20% случаев сеть выдаст ошибку, и можем быть к ней готовы. В этом состоит одно из главных преимуществ метода.
Результат работы оптимизатора — файл с кодом. В нем находятся две сети, каждая из них является нелинейным уравнением. В каждой из функций вначале используется нормирование данных, которые впоследствии поступают на вход нелинейного уравнения. Для увеличения обобщающей способности был реализован "комитет" из двух сетей. Если обе говорят "да", то сигнал истинный, если обе говорят "нет" — ложный. Если показания двух сетей разнятся, то мы получаем ответ "не знаю". Обратите внимание: в прошлом не существует состояния "не знаю", ведь на прошедших данных мы всегда можем определить, какой был сигнал. Таким образом, здесь "не знаю" подразумевает одновременное наличие возможности и ложного, и истинного сигнала. Мы получаем некий переход от двумерных вычислений к квантовым. В качестве аналогии можно привести пример с кубитом: он может принимать значения 1 и 0. Так и с "не знаю": этот ответ может быть и единицей, и нулем на страницах истории. Небольшую хитрость, которая здесь кроется, мы используем в торговле, поговорим о ней чуть позже.
Перейдем к подготовке данных. Сами данные представлены в виде таблицы Excel. Столбцами здесь будут входы сети. Последний столбец — выходная переменная. В соответствии с ее смыслом, в этом столбце записаны единицы и нули. В моем случае сигнал, получивший профит, обозначен 1, а получивший убыток — 0. Строки этой таблицы — данные, которые мы сохраняем в момент появления сигнала. При загрузке в оптимизатор таблица разделяется на две выборки — обучающую и тестовую, причём две сети обучаются перекрёстно. Но подсчёт и оптимизация идут с комитетом этих сетей. Таким образом, обучение каждой сети проходит отдельно, но с учётом общего результата.
В завершение раздела подчеркну: неважно, какую вы используете систему ИИ или среду программирования. Даже самый примитивный персептрон можно обучить методом обратного распространения ошибки и не переобучить, благодаря хорошим данным на входе сети. Суть состоит не в системе ИИ, а в качестве используемых данных. Именно поэтому в оптимизаторе данные сначала нормализуются, а далее всё подаётся на самое обычное нелинейное уравнение. И если входные данные являются причиной для выходной переменной, то это простое уравнение с какими-то 20 коэффициентами выдаст вам в ближайшем будущем 10 сигналов с ошибкой 20%. Неоднократно замечено, правда, что любое преобразование цены ведёт к запаздыванию. Поэтому, как правило, любой индикатор дает запаздывание, что сказывается на работе систем ИИ. О входных и выходных переменных подробнее поговорим с вами в следующей статье.
6. ТД "Секвента" и НС
Теперь перейдем к практическому использованию вышеописанной теории.
Проведем анализ на участке реальной торговли. Работу НС будут демонстрировать синие стрелки. Когда стрелка показывает вниз на красной точке, это означает что сигнал на продажу истинный, когда стрелка показывает вверх — ложный. Если стрелка отсутствует, то получаем ответ "Не знаю". С сигналами на покупку (синяя точка) всё наоборот: стрелка вверх — покупка истинная, стрелка вниз — ложная.
Рассмотрим работу модели в течение дня. На первый взгляд заработать было бы сложно, но это только на первый взгляд. Нам на помощь приходит понимание сути разделения. Допустим, мы имеем два сигнала, которые отличаются друг от друга. Один них, по мнению ИИ, ложный на продажу, но по факту принес профит. Получив следующий "ложный" сигнал на продажу от ИИ, нужно отследить, относятся ли оба этих сигнала к одной области разделения, или попросту являются ли они одинаковыми. Если это так — чтобы сигнал привел к профиту, нам нужно ориентировать индикатор так, чтобы стрелка была по направлению рынка, то есть, в сторону прибыли сигнала.
Взгляните на рисунок. Первый сигнал на продажу (красная точка) оказался убыточным, но когда мы перевернули стрелку вниз, он оказался прибыльным, поскольку сигнал №2 на продажу попал в одну область с сигналом №1. Перевернув стрелку, мы сделали прибыльным и второй сигнал, на котором уже можно было торговать. Теперь рассмотрим сигнал на покупку. Как видим, в этом случае ИИ опять ошибся и записал прибыльный сигнал в ложный. Нам осталось только исправить ситуацию и перевернуть стрелку сигнала №3 на покупку. В итоге сигнал №4 стал указывать правильное направление. А вот сигнал №5 попал в другую область, отличную от предыдущего сигнала, и привёл к перевороту рынка в целом.
Другими словами, мы получили хорошо сливающую антимодель, перевернули ее — и получили профитную модель! Этот метод я называю "Ориентация модели". Как правило, он реализуется в течение одного сигнала. Достаточно дождаться появления одного сигнала в начале дня на покупку и одного сигнала на продажу, ориентировать их — и можно работать. Таким образом за день мы получим как минимум 3 — 4 сигнала. Смысл состоит не в том, чтобы смотреть, какие сигналы были в прошлом и как они шли. Сравнивать между собой нужно два последних сигнала и делать выводы, относятся они к одной группе или нет, и какой нужно делать ход, если известен результат предыдущего сигнала. При этом нельзя забывать о том, что сеть может выдать ошибку.
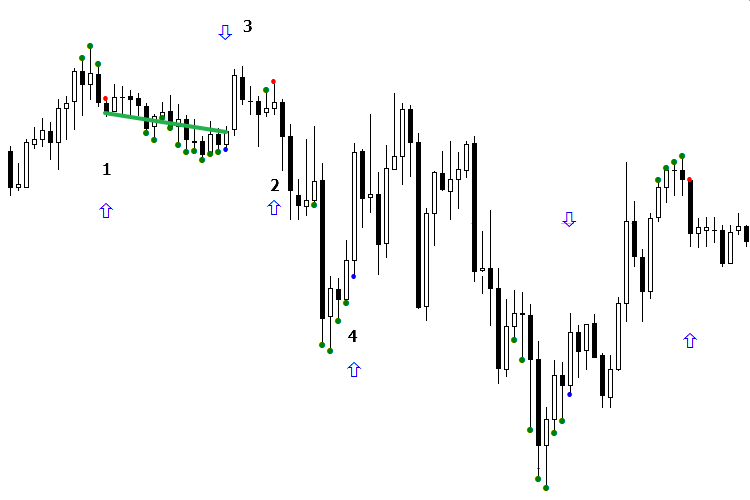
Рис. 2. Индикаторы BuyVOLDOWNOPNDOWN.mq5 и SellVOLDOWNOPNDOWN.mq5
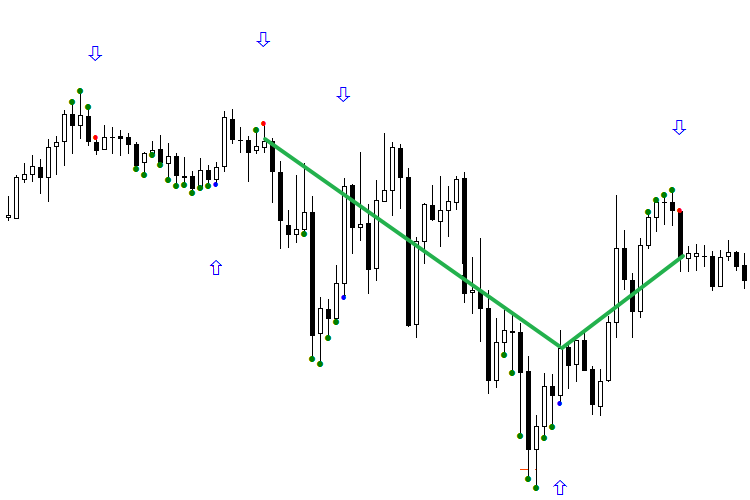
Рис. 3. Ориентированные индикаторы BuyVOLDOWNOPNDOWN.mq5 и SellVOLDOWNOPNDOWN.mq5
На следующих двух картинках показана работа сети за 4 дня. Нужно учесть, что только второй сигнал в день идёт в работу. Все сигналы, получившие прибыль, обозначены зелёной линией, убыточные — красной. Первый рисунок демонстрирует чистую работу сети, второй — с ориентацией по первому сигналу в день. Согласитесь, первая картинка впечатления не производит. Но если взглянуть на второй рисунок и начать отрабатывать сделки со второго сигнала каждого дня, ориентировав ТС, то картинка заметно похорошеет. Не забывайте, что методику переворачивания нужно применять с осторожностью.
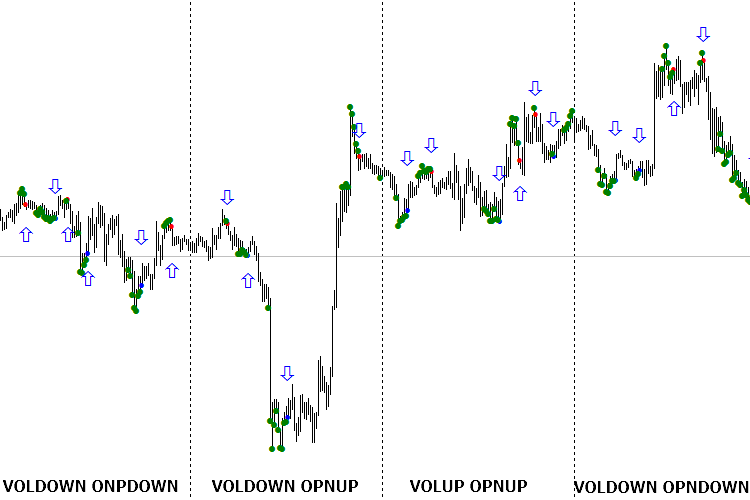
Рис. 4 Индикаторы в соответствии с названием для каждого дня, не ориентированные в нужном направлении
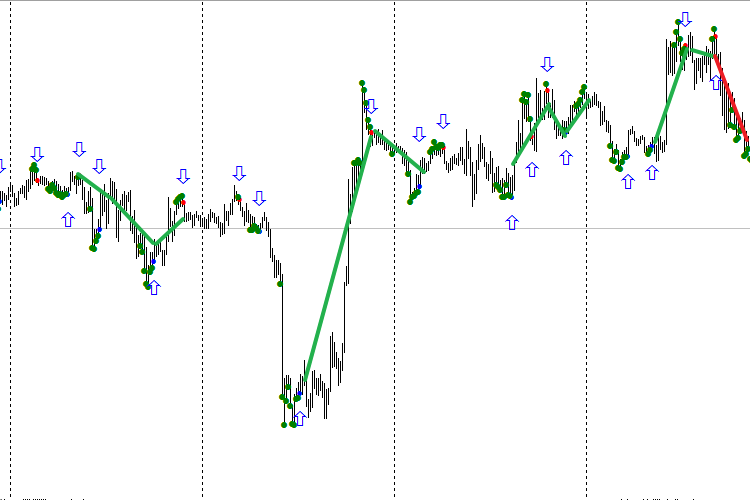
Рис. 5. Индикаторы для каждого дня, ориентированные по первому дневному сигналу (для покупки и для продажи по отдельности)
В таком виде модели уже не выглядят провальными, а кажутся вполне дееспособными. Поскольку они еще не выработали свой ресурс доверительного интервала, думаю, их срок действия — еще несколько дней.
Суть классификации — том, что многомерное пространство данных разделено универсальной линией, которая определяет сигналы в группу "истинных" и в группу "ложных". "Истинные" сигналы находятся выше нуля, а "ложные" — ниже. Главное здесь — стабильность в отделении одних сигналов от других. Вводится понятие ориентации ТС. Важно определить, когда сеть начинает стабильно "сливать", выдавая перевёрнутые сигналы. Как правило, направляющим в этом случае является первый сигнал за день. Торговать на таком сигнале можно, но крайне осторожно, опираясь на другие факторы анализа. Мой совет: чтобы избавить сеть от перекосов, постарайтесь сделать так, чтобы количество 0 и 1 в выходной переменной было равным. Для уравнивания смело удаляйте из обучающей выборки лишние нули или единицы, начиная с самых дальних сигналов.
Неважно, как именно происходит деление: важно, чтобы оно было стабильным. Вернемся к нашему примеру: еще до переориентации мы получили две ошибки подряд на рисунке №2 и воспользовались ситуацией. Как видим, при работе Секвенты на 15 минутах в течение дня мы получаем от 2 до 5 сигналов. И если два сигнала, например, на покупку попадают в разные классы (один — истинный, другой — ложный), то, зная результат предыдущего, первого сигнала, нетрудно определить каким будет текущий — ложным или истинным. Однако методом ориентирования нужно работать очень аккуратно. Сеть может выдать ошибку, а потом продолжить работать правильно. В любом случае, всё приходит с опытом — и механические реакции, и чутье на модель. Вопрос о пригодности полученной модели я планирую осветить шире в последующих статьях, потому что в этом вопросе есть много нюансов.
Организационный момент: прикреплённые файлы относятся к рисункам, которые вы видите выше. Вы можете загрузить их и проверить на
указанной дате. ТС нечувствительна к котировкам, однако были случаи, когда "Секвента" не выдавала сигнал у другого брокера, потому что в
ключевой момент котировки отличались. Но такие случаи редки, а входные данные и вовсе должны быть одинаковыми у всех, поскольку поставляются из
одного источника и изменению не подлежат. При этом я не гарантирую что
загрузив приложенные файлы у себя на компьютере, вы получите такой же
результат в тот же период времени. Но использовать модели для разделения текущего и предыдущего сигнала, думаю, сможете.
В заключение главы рассмотрим ещё один вопрос, который мы уже затронули выше. Что делать, когда сеть выдаёт нам сигнал "НЕ ЗНАЮ", и что это означает? Повторюсь: на страницах истории такого понятия, как "не знаю", не может быть в принципе. Это лишь говорит о том, что в обучающей выборке не было подобного паттерна, и мнения двух сетей в комитете по этому поводу разделились. "НЕ ЗНАЮ" подразумевает, что перед нами может быть как истинный, так и ложный сигнал. Вполне возможно, что если бы мы взяли чуть более широкий участок истории, то необходимый паттерн нашелся бы, и сеть смогла бы его определить. Но глубина обучения невелика — порядка 30 сигналов, что соответствует примерно 8-10 дням. Естественно, что периодически появляются сигналы, которых не было во время обучения, незнакомые модели. По моим наблюдениям, чем дольше работает модель — тем чаще она отвечает "не знаю". Это хорошо вписывается в теорию "живого рынка", когда прошлое не означает будущее. Недавние паттерны могут повториться в ближайшее время, а могут — в далёком будущем. Суть рынка такова, что значимость бара плавно снижается после его закрытия по мере ухода вглубь истории. Это общее правило для любой информации: чем она старше, тем менее она значима.
Есть два пути решения проблемы классификации состояния "Не знаю". Взглянем на следующий рисунок. У нас есть сигналы, на которых отсутствие стрелки и есть наше пресловутое "не знаю" — две сети в комитете по-разному их интерпретировали. На рисунке эти сигналы обозначены как 1 и 2, причём первый сигнал должен быть ложным, чтобы на нём можно было заработать.
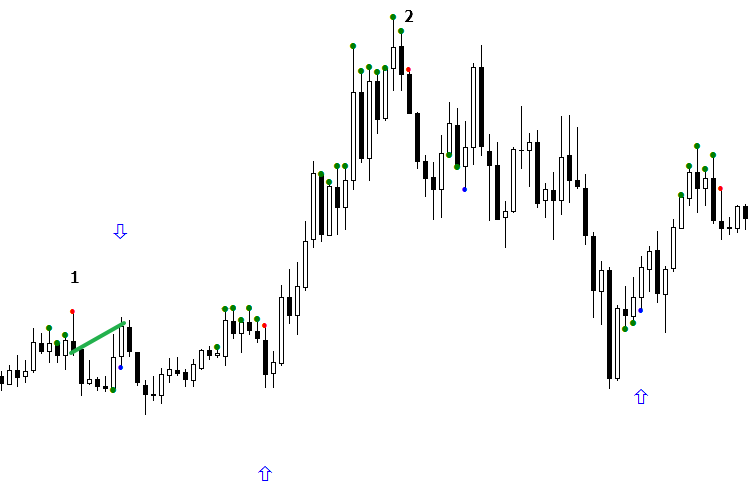
Рис. 6. Метод организации ориентирования сигнала в соответствии с контекстом дня
Существует два способа доклассификации состояния "Не знаю". Первый способ очень простой (см. рис. 7). Мы определили, что состояние "Не знаю" стало ложным для первой продажи. То есть, сигнал "Не знаю" на продажу мы расцениваем как ложный. Сигнал №2 тоже считаем ложным, предполагая продолжать покупки. Фактически сеть совершила ошибку, но практически эту ошибку можно свести на нет, зайдя в рынок по лучшей цене. Поэтому появление стрелки вверх сильно нам не навредит, хотя фактически сигнал получился отрицательным. Сигнал "Не знаю" на покупку (синяя точка) тоже расцениваем как ложный, потому как в прошлый раз при состоянии "не знаю" сигнал на покупку был ложным. Метод этот очень старый, но, по опыту, он неплохо работает.
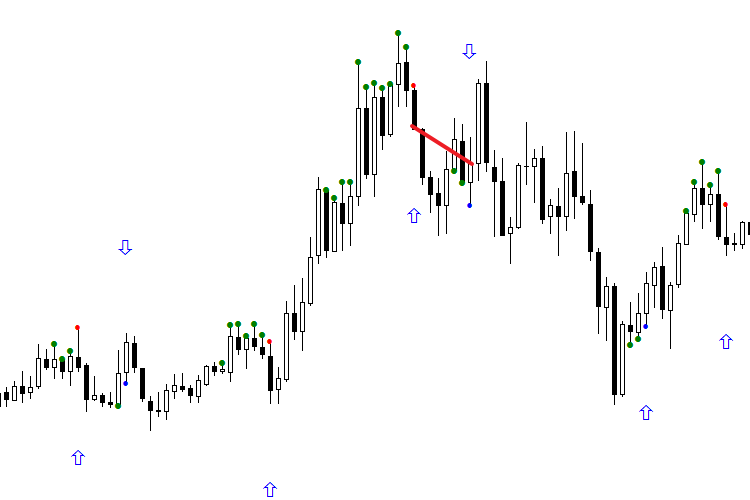
Рис. 7. Доклассификация сигнала "Не знаю", когда он расценивается как альтернативный класс
Второй метод классификации состояния "Не знаю" взывает к внутренней организации оптимизатора и опирается на его основу. Итак, состояние "не знаю" появляется, когда одна сеть в комитете показывает 1, другая — 0. Суть метода в том, что мы выбираем из комитета ту сеть, которая показывает правильно. Вернемся к нашему примеру. Сигнал №1 оказался ложным, когда сеть А была выше нуля, а сеть Б — меньше. Поэтому если сеть Б выше нуля, а сеть А — меньше, то это состояние "Не знаю" является истинным. В случае же с сигналом на покупку, всё наоборот: предыдущий сигнал (его нет на картинке) был ложным, когда ответ сети А был отрицательным, а сети Б — положительным. В текущем сигнале на покупку ситуация противоположна, поэтому мы предположим, что этот сигнал истинный, и покупка на нем рекомендована.
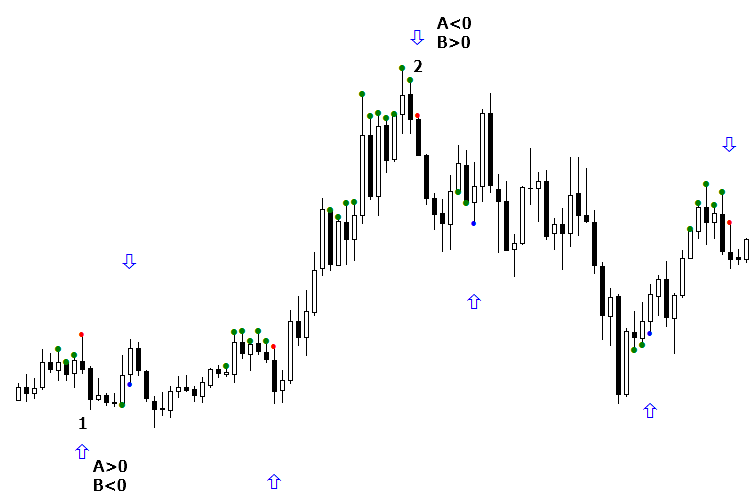
Рис. 8. Доклассификация сигнала "Не знаю" в соответствии с показаниями каждой из сетей комитета
Из двух методов классификации состояния "Не знаю" лично мне больше по душе первый, и на то есть вполне логическое объяснение. При использовании комитетов из двух сетей мы получаем три класса — "Да", "Нет" и "Не знаю", по этим трем группам распределяются наши данные. Важно не то, что у нас три группы, а то, что они принципиально разные. И получив сигнал "Не знаю", выяснив впоследствии его направление, мы считаем, что последующие сигналы в этой группе будут иметь одно и то же направление. Текущий опыт показывает, что этот метод надёжнее второго.
Прогнозировать финансовые рынки сложно: они представляют собой живой и непредсказуемый организм, на котором работают живые люди. В течение дня ситуация на рынках может измениться так, что никто и предположить не может — ни маркетмейкер, ни крупный игрок, ни, тем более, мы с вами. Режим этих изменений складывается из двух составляющих. Первая — это контекст рынка, о котором мы уже говорили. Вторая — причина активность покупателей и продавцов в режиме реального времени, здесь и сейчас. Поэтому главное в трейдинге — вовремя ориентироваться и быть начеку!
Использование ИИ не панацея, не грааль. Конечно, при торговле с использованием нейронных сетей безусловно стоит прислушиваться к советам искусственного интеллекта. Но торговать нужно своей головой. Получив сигнал от ИИ, нужно дождаться его подтверждения, правильно выбрать уровень, оценить вероятность отката и т.д. Об этом я хотел поговорить уже в третьей статье, которая будет посвящена практическим особенностям торговли по стратегии "Секвента" с иcпользованием нейронных сетей.
7. Заключение
В очередной раз хочу подчеркнуть, что эта статья носит исключительно методологический характер. Все методы, которые я описываю, могут быть использованы в ваших ТС, и я надеюсь, что мои советы будут полезными для вас.
Уверен что найдутся как сторонники, так и противники описанного метода. Если вы дочитали до этих строк, значит, вы как минимум заинтересовались. Мне очень важно ваше мнение о том, с чем вы не согласны, особенно в том случае, если у вас есть конструктивное решение, доработка, изменение. Другими словами, критикуя, предлагай! Доказательством работоспособности данного подхода может стать совместное со мной построение системы искусственного интеллекта. Я был бы рад поработать вместе с профессиональным программистом на эту тему и приглашаю вас к сотрудничеству.
К статье прилагается код индикатора ТД "Секвента", а также индикаторы, которые фильтруют или классифицируют сигналы на покупку и на продажу с учётом контекста дня и ориентации в начале торгов. Сразу скажу, что индикаторы были переписаны с MQL4 и не дают полной функциональности, чтобы полностью воспроизвести все то, что показано в статье. Причина в том, что входные данные для НС требуют для своей работы набор индикаторов проекта ClusterDelta, которые доступны только по платной подписке.
Всем желающим я готов предоставить подготовленный файл для работы индикаторов. Было бы интересно переписать все необходимые индикаторы на MQL5 для того, чтобы полностью повторить алгоритм работы. Своей задачей я ставил показать, как использовать в известной торговой стратегии Демарка лежащий в открытом доступе код для создания и обучения нейронных сетей. Готов выслушать замечания и ответить на ваши вопросы.
Программы, используемые в статье:
| # | Имя |
Тип |
Описание |
|---|---|---|---|
| 1 | TDSEQUENTA_by_nikelodeon.mq5 | Индикатор | Базовая стратегия, которая выдаёт сигналы на покупку или продажу в виде синих и красных точек соответственно. Зелёные точки означают, что условия для формирования сигнала созданы и необходимо дождаться появления самого сигнала. Стратегия удобна тем, что трейдер готов к появлению сигнала: об этом его предупреждает зеленая точка. |
| 2 | eVOLution-dvoid.1.3 (1).mq5 | Индикатор | Загружает текстовый файл с данными об объёме и открытом интересе за предыдущие дни, вычисляет разницу между данными и заносит всё это в буфер индикатора для последующего обращения при сохранении данных, а также при выборе, какая модель должна работать сегодня. Другими словами, организует контекст рынка. |
| 3 | dvoid-BP.csv | Текстовый файл |
Предназначен для записи информации о объёме и открытом интересе каждое утро в 7:30 МСК с сайта Чикагской Фондовой биржи. Запись данных производится вручную, каждое утро. Файл загружен с расширением txt. После скачивания расширение нужно изменить на csv и поместить файл в папку ..\Files\evolution-dvoid\dvoid-BP.csv |
| 4 | BuyVOLDOWNOPNDOWN.mq5 | Индикатор | Сеть для классификации сигналов на покупку в дни, когда упали объем и открытый интерес. |
| 5 | BuyVOLDOWNOPNUP.mq5 | Индикатор | Сеть для классификации сигналов на покупку в дни, когда объём упал, а открытый интерес вырос. |
| 6 | BuyVOLUPOPNDOWN.mq5 | Индикатор | Сеть для классификации сигналов на покупку в дни, когда объём вырос, а открытый интерес упал. |
| 7 | BuyVOLUPOPUP.mq5 | Индикатор | Сеть для классификации сигналов на покупку в дни, когда выросли объём и открытый интерес. |
| 8 | SellVOLDOWNOPNDOWN.mq5 | Индикатор |
Сеть для классификации сигналов на продажу в дни, когда упали объём и открытый интерес. |
| 9 | SellVOLDOWNOPNUP.mq5 | Индикатор | Сеть для классификации сигналов на продажу в дни, когда объём упал, а открытый интерес вырос. |
| 10 | SellVOLUPOPNDOWN.mq5 | Индикатор |
Сеть для классификации сигналов на продажу в дни, когда объём вырос, а открытый интерес упал. |
| 11 | SellVOLUPOPNUP.mq5 | Индикатор |
Сеть для классификации сигналов на продажу в дни, когда выросли объём и открытый интерес |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Спасибо за прекрасные предложения.
Я немедленно опробую различные цвета, представленные здесь.
Если у нас появятся мнения о том, как его использовать, мы снова свяжемся с вами.
Большое спасибо.
Опубликована новая статья Thomas DeMark Subsequent Order (TD SEQUENTIAL), реализованная с помощью искусственного интеллекта:
Михаил Марчукайтес
ЗДОРОВО!!!
Почему нет комментариев к такому замечательному посту?