
Avaliação de sistemas de negócio - A efetividade de entrada, saída e negócios em geral

Introdução
Existem várias medidas para determinar a efetividade de um sistema de Negócio; e os investidores escolhem as que eles gostem. Esse artigo fala sobre as abordagens descritas no livro "Statistika dlya traderov" ("Estatística para Negociadores") de S.V. Bulashev. Infelizmente, o número de cópias deste livro é muito pequena e não foi republicado por um longo tempo, entretanto, a sua versão eletrônica ainda está disponível em diversos sites.
Prólogo
Lembro a você que o livro foi publicado em 2003. Este era o tempo de MetaTrader 3 com a linguagem de programação MQL-II. E a plataforma era bastante progressiva para aquele tempo. Assim, nós podemos rastrear as mudanças das próprias condições de troca comparando-as com o moderno cliente final do MetaTrader 5 Deve ser notado que o autor do livro se tornou-se um guru para diversas gerações de comerciantes (considerando a rápida mudança de gerações nessa área). Mas o tempo não fica parado; apesar dos princípios descritos no livro ainda serem aplicáveis, as abordagens devem ser adaptadas.
S.V. Bulashev escreveu seu livro, primeiro de tudo, na base das condições de comércio atuais para aquele tempo. É por isto que nós não podemos usar as estatísticas descritas pelo autor sem uma transformação. Para tornar mais claro, vamos relembrar das possibilidades de negócio naquele tempo: comércio marginal em um mercado local implica que comprando uma moeda para obter um lucro especulativo decorre em vendê-la depois de um tempo.
Estes são os básicos, e são dignos de serem lembrados, que a exata interpretação foi usada quando o livro "Estatística para Comerciantes" foi escrito. Cada acordo de 1 lote deveria ser fechado pelo acordo reverso de volume igual. Entretanto, após dois anos (em 2005) o uso de tal estatística necessitava de uma reorganização. A razão é a concretização parcial de acordos se tornou possível em MetaTrader 4. Assim, para usar as estatísticas descritas por Bulashev, nós precisamos melhorar o sistema de interpretação; notavelmente, a interpretação deve ser feita sobre o ato de fechamento e não de abertura.
Após outros 5 anos, a situação mudou significativamente. Onde está o tão habitual termo de Encomenda? Se foi. Considerando o fluxo de questões neste fórum, é melhor descrever o exato sistema de interpretação no MetaTrader 5.
Então, hoje em dia não existe mais o termo de Encomenda clássico. Uma encomenda agora é um pedido de negócio para o servidor de um intermediário, o qual é feito por um comerciante ou MTS para a iniciação ou mudança de uma posição de negócio. Agora é uma posição; para entender o seu significado, eu mencionei o comércio marginal. O fato é que a negociação marginal é realizada com dinheiro emprestado; e uma posição existe até que o dinheiro exista.
Assim que você resolver suas contas com o mutuário, encerrando a posição e por resultado alcança um lucro/prejuízo, sua posição para de existir. A propósito, esse fato explica a razão pela qual a reversão de uma posição não a fecha. O fato é que o empréstimo se mantém de qualquer modo e não existe diferença se você pegou dinheiro emprestado para comprar ou vender. Um negócio é somente a história de um pedido executado.
Agora vamos falar sobre as características de comércio. Atualmente, no MetaTrader 5, nós podemos tanto encerrar a posição de um negócio parcialmente ou aumentar uma já existente. Assim, o sistema clássico de interpretação, no qual cada iniciação de uma posição de um certo volume é seguida pelo encerramento com o mesmo volume, ficou no passado. Mas é realmente impossível de recuperá-la da informação arquivada no MetaTrader 5? Então, primeiro de tudo, nós vamos reorganizar a interpretação.
A eficácia de entrada
Não é segredo que a maioria das pessoas querem fazer o seu negócio mais efetivo, mas como descrever (formalizar) este termo? Se você assumir que um negócio é um caminho que passa pelo preço, então se torna óbvio que existem dois pontos extremos no caminho; mínimo e máximo de preço dentro da seção observada. Todo mundo se esforça para entrar no mercado mais próximo do mínimo possível (quando comprando). Isto pode ser considerado como uma regra principal de qualquer negócio: comprar a preço baixo, vender a preço alto.
A eficácia de entrada determina o quão próximo do mínimo você compra. Em outras palavras, a eficácia de entrada é a taxa da distância entre o máximo o preço de entrada para todo o caminho. Porque nós medimos a distância para o mínimo pela diferença de máximo? Nós precisamos que a eficácia seja igual a 1 entrando no mínimo (e que seja igual a 0, entrando no máximo).
É por isto que para nossa razão, nos tomamos o resto da distância, e não a distância entre o mínimo e a entrada em si. Aqui nós precisamos assinalar que a situação para vender é espalhada em comparação com comprar.
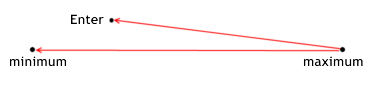
A eficácia da posição de entrada demonstra o quão bom um MTS compreende o potencial de lucro relativamente ao preço de entrada durante certo negócio. Ele é calculado pelas seguintes fórmulas:
for long positions enter_efficiency=(max_price_trade-enter_price)/(max_price_trade-min_price_trade); for short positions enter_efficiency=(enter_price-min_price_trade)/(max_price_trade-min_price_trade); The effectiveness of entering can have a value within the range from 0 to 1.
A eficácia de saída
A situação com a saída é similar:
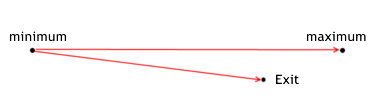
A eficácia da saída de uma posição demonstra o quão bom um MTS compreende o potencial de lucro relativamente ao preço de saída da posição durante certo negócio. Ele é calculado pelas seguintes fórmulas:
para posições longas exit_efficiency=(exit_price - min_price_trade)/(max_price_trade - min_price_trade); para posições curtas exit_efficiency=(max_price_trade - exit_price)/(max_price_trade - min_price_trade); A eficácia de saída pode ter um valor dentro de uma faixa de 0 a 1.
A eficácia de um negócio
No todo, a efetividade de um negócio é determinado por ambas entrada e saída. Ela pode ser calculada como a razão do caminho entre entrar e sair para a máxima distância durante o negócio (ou seja, a diferença entre minimo e máximo). Assim, a efetividade de um negócio pode ser calculado de duas maneiras - usando diretamente a informação primária sobre o negócio, ou usando resultados previamente calculados de entradas e saídas previamente avaliadas (com uma mudança de intervalo).
A eficácia de comércio demonstra o quão bom um MTS compreende o potencial total de lucro durante certo negócio. Ele é calculado pelas seguintes fórmulas:
for long positions trade_efficiency=(exit_price-enter_price)/(max_price_trade-min_price_trade); for short positions trade_efficiency=(enter_price-exit_price)/(max_price_trade-min_price_trade); general formula trade_efficiency=enter_efficiency+exit_efficiency-1; The effectiveness of trade can have a value within the range from -1 to 1. A eficácia do negócio deve ser maior que 0,2. A análise da eficácia visualmente mostra a direção para melhorar o sistema, porque permite avaliar a qualidade de sinais para entrar e sair uma posição separadamente uma da outra.
Transformação de interpretação
Primeiro de tudo, para evitar qualquer tipo de confusão, nós precisamos esclarecer os nomes dos objetos de interpretação. Uma vez que os mesmo termos - pedido, acordo, posição são usados no MetaTrader 5 e por Bulachev, nós precisamos separá-los No meu artigo, eu vou usar o termo "negócio" para o objeto de interpretação de Bulachev, ou seja, negócio é um acordo; ele também usa o termo "pedido" para tal, neste contexto, estes termos são idênticos. Bulachev chama um acordo não terminado de uma posição, e nós o chamaremos de um negócio em aberto.
Aqui você pode ver que todos os 3 termos são facilmente encaixados na palavra "negócio". E nós não renomearemos a interpretação no MetaTrader 5, e o significado destes três termos permanecem como designados pelos desenvolvedores do terminal do cliente. Como resultado, nós temos 4 palavras que nós usaremos - Posição, Acordo, Pedido e Negócio.
Visto que, um Pedido é um comando ao servidor para iniciar/alterar uma posição e não importa a estatística diretamente, mas sim indiretamente através de um acordo (a razão é que enviar um pedido nem sempre resulta na execução do acordo correspondente de volume e preço específicos), então é correto coletar as estatísticas pelos acordos e não pelos pedidos.
Vamos considerar um exemplo de interpretação da mesma posição (para esclarecer a descrição acima):
interpretação no МТ-5 deal[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 deal[ 1 ] in/out 0.2 buy 1.22261 2010.06.14 13:36 deal[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 deal[ 3 ] out 0.2 sell 1.22310 2010.06.14 13:41
interpretação por Bulachev trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36 trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
Agora eu vou descrever a maneira que estas manipulações foram conduzidas. Deal[ 0 ] abre a posição, nós escrevemos ele como o início de um novo negócio:
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33
Então vem o reverso da posição; isto significa que todos os negócios prévios devem ser encerrados. Correspondentemente, a informação sobre o deal[ 1 ] reverso será considerada tanto encerrando quanto iniciando o novo negócio. Uma vez que todos os negócios abertos antes do acordo, com a direção dentro/fora, estiverem fechados, nós precisamos abrir o novo negócio. ou seja, nós usamos somente a informação de price e time sobre o acordo selecionado para encerramento, como oposto a iniciar um negócio, quando são usados adicionalmente o type e volume. Aqui nos precisamos esclarecer um termo que não foi usado antes que este aparecesse na nova interpretação - é a direção do acordo. Anteriormente, nós denotamos uma compra ou venda dizendo a "direção", o mesmo significado tinha o termo "tipo". De agora em diante tipo e direção são termos diferentes.
Tipo é uma compra ou venda, enquanto direção é a entrada ou saída de uma posição. É por isso que uma posição é sempre aberta com um acordo da direção entrada, e é fechada com um acordo de saída. Mas a direção não é limitada apenas a abertura e fechamento de situações. Este termo também inclui o aumento de volume de uma posição (se os acordos de "entrada" não forem os primeiros da lista) e o fechamento parcial de uma posição (os acordo de "saída" não são os últimos da lista). Uma vez que o fechamento parcial se tornou disponível, é lógico introduzir também o reverso de uma posição; uma reversão acontece quanto um acordo oposto de um tamanho maior que a atual posição é realizada, ou seja, é um acordo de entrada/saída.
Então, nós fechamos os negócios previamente abertos (para reverter a posição):
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36
O volume de repouso é 0.1 lotes e é usado para abrir um novo negócio:
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36
Depois, vem o deal[ 2 ] com na direção, abre outro negócio:
trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39
E finalmente, o acordo que fecha a posição - deal [3] fecha todos os negócios na posição que não foram encerrados ainda:
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
A interpretação descrita acima, mostra a essência da interpretação usada por Bulachev - cada negócio em aberto tem um certo ponto de entrada e um certo ponto de saída, tem seu volume e tipo. Mas esse sistema de interpretação não considera uma nuance: encerramento parcial. Se você olhar de perto, você verá que o número de negócios é igual ao número de acordos de entrada (considerando os acordos de entrada/saída). Neste caso, é válido interpretar por acordos de entrada, mas terão mais acordos de saída em encerramento parcial (talvez exista uma situação na qual o número de acordos de entrada e saída seja o mesmo, mas elas não correspondem um ao outro em volume).
Para processar todos os acordos de saída, nós devemos interpretar pelos acordos de saída: E esta contradição parece ser insolúvel se nós realizarmos um processamento separado de acordos, a princípio - todos os acordos de entrada,e todos os acordos de saída (ou vice e versa). Mas se nós processarmos os acordos sequencialmente e aplicarmos uma regra especial de processamento a cada um, então não há nenhuma contradição.
Aqui esta um exemplo, onde o número de acordos de saída é maior que o número de acordos de entrada (com descrição):
interpretação no МТ-5 deal[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00 deal[ 1 ] out 0.2 buy 1.22145 2010.06.15 08:01 deal[ 2 ] in/out 0.4 buy 1.22145 2010.06.15 08:02 deal[ 3 ] in/out 0.4 sell 1.22122 2010.06.15 08:03 deal[ 4 ] out 0.1 buy 1.2206 2010.06.15 08:06
interpretação por Bulachev trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:02 trade[ 2 ] in 0.3 buy 1.22145 2010.06.15 08:02 out 1.22122 2010.06.15 08:03 trade[ 3 ] in 0.1 sell 1.22122 2010.06.15 08:03 out 1.2206 2010.06.15 08:06
Nós temos uma situação, quando um acordo em encerramento vem antes de uma abertura, mas não tem o volume total, porém somente uma parte deste (0,3 lotes são abertos e 0,2 são fechados). Como lidar com tal situação? Se cada negócio é encerrado com o mesmo volume, então a situação pode ser considerada como iniciação de diversos negócios com um único acordo. Assim, eles terão os mesmos pontos de abertura e diferentes pontos de fechamento (é claro que o volume de cada negócio é determinado pelo volume de encerramento). Por exemplo, nós escolhemos o deal[ 0 ] para processamento, abre o negócio:
trade[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00
Então nós selecionamos o deal[ 1 ], fecha o negócio aberto, e durante o encerramento nós descobrimos que o volume de fechamento não é suficiente. Faça uma cópia do negócio previamente aberto e especifique a falta de volume no seu parâmetro "volume". Após fechar o negócio inicial com o volume do acordo (ou seja, nós trocamos o volume do negócio inicial especificado na abertura com o volume de encerramento):
trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00
Tal transformação pode não parecer adequada para um comerciante, uma vez que o comerciante pode querer fechar outro negócio, e não este. Mas de qualquer modo, a avaliação dos sistemas não sera prejudicada como resultado de uma transformação correta. A única coisa que pode ser prejudicada é a confiança do comerciante em negociar sem acordos com prejuízo no MetaTrader 4; este sistema de recalculamento revelará todas as desilusões.
O sistema de interpretação de estatística descrito no livro de Bulachev não tem emoções e permite avaliar honestamente decisões da posição de entrada, saída e ambas as taxas no total. E a possibilidade de transformação de interpretação (um para dentro do outro sem perda de dados) prova que é errado dizer que um MTS, desenvolvido para MetaTrader 4 não pode ser refeito para o sistema de interpretação do MetaTrader 5. A única perda ao transformar a interpretação pode ser no volume pertencente a a diferentes pedidos (MetaTrader 4). Mas de fato, se não houverem mais pedidos (no velho significado deste termo) para serem considerados, então é apenas uma estimação subjetiva do comerciante.
Código para transformação de interpretação
Vamos dar uma olhada no código em si. Para preparar um tradutor nós precisamos do atributo de herança do OOP. É por isso que eu sugiro aos que ainda não sejam familiarizados com isto ainda, a abrir o Guia do Usuário MQL5 e aprender a teoria. Primeiro de tudo, vamos descrever uma estrutura de interpretação de um acordo (nós poderíamos acelerar o código obtendo estes valores diretamente, usando as funções básicas do MQL5, mas seria menos legível e poderia confundir você).
//+------------------------------------------------------------------+ //| structure of deal | //+------------------------------------------------------------------+ struct S_Stat_Deals { public: ulong DTicket; // ticket of deal ENUM_DEAL_TYPE deals_type; // type of deal ENUM_DEAL_ENTRY deals_entry; // direction of deal double deals_volume; // volume of deal double deals_price; // price of opening of deal datetime deals_date; // time of opening of deal S_Stat_Deals(){}; ~S_Stat_Deals(){}; };
Esta estrutura contém todos os detalhes principais sobre um acordo, detalhes derivados não são inclusos, já que podemos calculá-los se necessário. Uma vez que os desenvolvedores já implementaram vários métodos da estatística de Bulachev no testador de estratégia, nos sobrou somente suplementar com os métodos personalizados. Então vamos implementar tais métodos como a eficácia de um negócio como todo, e a eficácia de abertura e encerramento.
E para obter estes valores, nós precisamos implementar a interpretação de informações primárias como preço de abertura/encerramento, tempo de abertura/encerramento, preço mínimo/máximo durante um negócio. Se nós tivermos tal informação primária, nós podemos tirar várias informações derivadas. Eu também gostaria de chamar sua atenção para a estrutura de negócio descrita abaixo, é a estrutura principal, todas as transformações de interpretação são baseadas nela.
//+------------------------------------------------------------------+ //| structure of trade | //+------------------------------------------------------------------+ struct S_Stat_Trades { public: ulong OTicket; // ticket of opening deal ulong CTicket; // ticket of closing deal ENUM_DEAL_TYPE trade_type; // type of trade double trade_volume; // volume of trade double max_price_trade; // maximum price of trade double min_price_trade; // minimum price of trade double enter_price; // price of opening of trade datetime enter_date; // time of opening of trade double exit_price; // price of closing of trade/s22> datetime exit_date; // time of closing of trade double enter_efficiency;// effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency;// effectiveness of trade S_Stat_Trades(){}; ~S_Stat_Trades(){}; };
Agora, como nós criamos duas estruturas principais, nós podemos definir a nova classe C_Pos, a qual transforma a interpretação. Primeiro de tudo, vamos declarar os indicadores para a estrutura de interpretação de acordos e trocas. Uma vez que a informação pode ser necessária em funções herdadas, declare ela como pública; e como podem existir diversos acordos e negócios, use um ensaio como um indicador para a estrutura ao invés de uma variável. Assim, a informação será estruturada e disponível para qualquer lugar.
Em seguida, nós precisamos dividir o histórico em posições separadas e realizar todas as transformações dentro de uma posição em um ciclo completo de negociação. Para fazer isto, declare as variáveis para interpretação dos atributos de posição (id da posição, símbolos da posição, número de acordos, número de negócios).
//+------------------------------------------------------------------+ //| class for transforming deals into trades | //+------------------------------------------------------------------+ class C_Pos { public: S_Stat_Deals m_deals_stats[]; // structure of deals S_Stat_Trades m_trades_stats[]; // structure of trades long pos_id; // id of position string symbol; // symbol of position int count_deals; // number of deals int count_trades; // number of trades int trades_ends; // number of closed trades int DIGITS; // accuracy of minimum volume by the symbols of position C_Pos() { count_deals=0; count_trades=0; trades_ends=0; }; ~C_Pos(){}; void OnHistory(); // creation of history of position void OnHistoryTransform();// transformation of position history into the new system of interpretation void efficiency(); // calculation of effectiveness by Bulachev's method private: void open_pos(int c); void copy_pos(int x); void close_pos(int i,int c); double nd(double v){return(NormalizeDouble(v,DIGITS));};// normalization to minimum volume void DigitMinLots(); // accuracy of minimum volume double iHighest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); double iLowest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); };
A classe tem três métodos públicos que processam situações.
OnHistory() cria histórico da posição:
//+------------------------------------------------------------------+ //| filling the structures of history deals | //+------------------------------------------------------------------+ void C_Pos::OnHistory() { ArrayResize(m_deals_stats,count_deals); for(int i=0;i<count_deals;i++) { m_deals_stats[i].DTicket=HistoryDealGetTicket(i); m_deals_stats[i].deals_type=(ENUM_DEAL_TYPE)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TYPE); // type of deal m_deals_stats[i].deals_entry=(ENUM_DEAL_ENTRY)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_ENTRY);// direction of deal m_deals_stats[i].deals_volume=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_VOLUME); // volume of deal m_deals_stats[i].deals_price=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_PRICE); // price of opening m_deals_stats[i].deals_date=(datetime)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TIME); // time of opening } };
Para cada acordo, o método cria uma cópia de estrutura e a preenche com as informações acerca do acordo. Isto é exatamente o que eu quis dizer quando disse acima que nós podemos fazer sem isso, mas é mais conveniente com (os que buscarem o encurtamento de microssegundos de tempo podem substituir a nomeação destas estruturas pela linha que se apresenta a direita do sinal e igual).
OnHistoryTransform() transforma o histórico da posição no novo sistema de interpretação:
- Eu descrevi anteriormente como a informação deve ser transformada, agora vamos considerar um exemplo disto: Para a transformação nós necessitamos de um valor de precisão para qual nós devemos calcular o volume do acordo (min. volume); DigitMinLots() resolve isto; entretanto se um programador tem certeza que o código não será executado sob qualquer outra condição, então este parâmetro pode ser especificado no construtor e a função pode ser saltada.
- Então zere os contadores counter_traders e o trades_ends. Após isto, realoque a memória da estrutura de interpretação de negócios. Desde que nós não saibamos com certeza o número exato de negócios, nós devemos realocar a memória de acordo com o número de acordos em posição. Se mais a frente, aparecer que existem mais negócios, então nós realocaremos a memória novamente por várias vezes; mas ao mesmo tempo, a maioria dos negócios terão memória suficiente, e a alocação de memória para o todo o ensaio economiza significativamente nosso tempo de máquina.
Eu recomendo o uso deste método em todos os lugares quando necessário; alocar a memória toda vez que um novo objeto de interpretação aparecer. Se não houver informação precisa sobre a quantidade de memória necessária, então nós devemos alocá-la a um valor aproximado. Em todo caso, isto é mais econômico que realocar a cada passo todo o ensaio.
Então vem o o ciclo aonde todos os acordos de uma posição são filtrados usando três filtros: se o acordo é entrada, entrada/saída, saída. Ações específicas são implementadas para cada variante. Os filtros são sequenciais, agrupados. Em outras palavras, se um filtro se mostra false, então somente neste caso nós checamos o próximo filtro. Tal construção é econômica com os recursos, porque as ações desnecessárias são eliminadas. Para tornar o código mais legível, várias ações são tomadas em relação as funções declaradas como privadas na classe. A propósito, estas funções eram públicas durante o desenvolvimento, mas depois eu percebi que não existe necessidade delas em outras partes do código, assim elas foram redeclaradas como privadas. É simples assim como alguém pode manipular o escopo de dados no OOP.
Então no filtro entrada a criação de um novo negócio é realizada (a função open_pos()), e é por isso que nós aumentamos o tamanho do arranjo de indicadores em um e copiamos a estrutura de acordo para o campo correspondente de estrutura de negócio. Além disto, como a estrutura de negócio tem duas vezes mais campos de preço e tempo, então apenas campos de abertura são preenchidos quando um negócio é iniciado, então são contados como incompletos; você pode entender isto pela diferença de count_trade e trade_ends. A questão está nos contadores tendo valor zero no início. Assim que um negócio surge, aumenta o contador count_trades, e quando um negócio é encerrado, aumenta o contador trades_end. Assim, a diferença entre count_trades e trades_end pode lhe dizer quantos negócios não estão encerrados em qualquer momento.
A função open_pos() é bastante simples, ela somente inicia negócios e engatilha o contador correspondente; outras funções semelhantes não são tão simples. Então se um acordo não é do tipoentrada, então ele pode ser tanto entrada/saída quanto saída. A partir de duas variantes, primeiro de tudo, cheque a que seja executada mais facilmente (isso não é uma questão fundamental, mas eu construí a checagem em ordem de dificuldade crescente de execução).
A função que processa o filtro entrada/saída some as situações em aberto por todos os negócios não encerrados (eu já mencionei como saber quais negócios não estão fechados usando a diferença entre count_trades e trades_end). Assim, nós calculamos o volume total que é fechado por certo acordo (e o resto do volume será reaberto, mas com o tipo do acordo atual). Aqui nós necessitamos notar que o acordo tem a direção entrada/saída, o que significa que o o seu volume não excede o volume total da posição previamente aberta. É por isso que é lógico calcular as diferenças entre a posição e o acordo entrada/saída para saber o volume de novos negócios a serem reabertos.
Se um acordo tem a direção de saída, então tudo é ainda mais complicado. Primeiro de tudo, o último acordo em uma posição sempre tem a direção saída, então aqui nós devemos fazer uma exceção - se é o último acordo, feche tudo que nós temos. Caso contrário (se o acordo não é o último), duas variáveis são possíveis. Já que o acordo não é de entrada/saída, mas sim de saída, então as variantes são: a primeira variante, é o volume exatamente o mesmo que o de abertura, ou seja, o volume do acordo em iniciação é igual ao volume do acordo de encerramento; a segunda variante é estes volumes não serem os mesmos.
A primeira variante é processada pelo encerramento. A segunda variante é mais complicada, duas variáveis são possíveis novamente: quando o volume é maior e quando o volume é menor do volume inicial. Quando o volume é maior, feche o próximo acordo até que o volume de encerramento seja igual ou menor que o volume inicial. Se o volume não é suficiente para fechar totalmente o próximo negócio (tem menos volume), significa o fechamento parcial. Aqui nós precisamos fechar o negócio com o novo volume (o que sobra após as operações anteriores), mas antes disso, faça uma cópia do negócio com o volume faltando. E, é claro, não esqueça dos contadores.
Em negociações, pode haver uma situação aonde após reabrir um negócio, já exista uma fila de próximos negócios em encerramento parcial. Para evitar confusão, todos eles devem ser transferidos um a um, para manter a cronologia de encerramento.
//+------------------------------------------------------------------+ //| transformation of deals into trades (engine classes) | //+------------------------------------------------------------------+ void C_Pos::OnHistoryTransform() { DigitMinLots();// fill the DIGITS value count_trades=0;trades_ends=0; ArrayResize(m_trades_stats,count_trades,count_deals); for(int c=0;c<count_deals;c++) { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_IN) { open_pos(c); } else// else in { double POS=0; for(int i=trades_ends;i<count_trades;i++)POS+=m_trades_stats[i].trade_volume; if(m_deals_stats[c].deals_entry==DEAL_ENTRY_INOUT) { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades; open_pos(c); m_trades_stats[count_trades-1].trade_volume=m_deals_stats[c].deals_volume-POS; } else// else in/out { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_OUT) { if(c==count_deals-1)// if it's the last deal { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades-1; } else// if it's not the last deal { double out_vol=nd(m_deals_stats[c].deals_volume); while(nd(out_vol)>0) { if(nd(out_vol)>=nd(m_trades_stats[trades_ends].trade_volume)) { close_pos(trades_ends,c); out_vol-=nd(m_trades_stats[trades_ends].trade_volume); trades_ends++; } else// if the remainder of closed position is less than the next trade { // move all trades forward by one count_trades++; ArrayResize(m_trades_stats,count_trades); for(int x=count_trades-1;x>trades_ends;x--)copy_pos(x); // open a copy with the volume equal to difference of the current position and the remainder m_trades_stats[trades_ends+1].trade_volume=nd(m_trades_stats[trades_ends].trade_volume-out_vol); // close the current trade with new volume, which is equal to remainder close_pos(trades_ends,c); m_trades_stats[trades_ends].trade_volume=nd(out_vol); out_vol=0; trades_ends++; } }// while(out_vol>0) }// if it's not the last deal }// if out }// else in/out }// else in } };
Cálculo de eficácia
Uma vez que o sistema de interpretação seja transformado, nós podemos avaliar a eficácia de negócios pela metodologia de Bulachev. Se encontra no método efficiency() as funções necessárias para tal avaliação, preenchimento de estrutura de negócio com os dados calculados é realizado aí também. A eficácia de entrada e saída é medida de 0 a 1 e para o negócio como um todo, é medido de -1 a 1.
//+------------------------------------------------------------------+ //| calculation of effectiveness | //+------------------------------------------------------------------+ void C_Pos::efficiency() { for(int i=0;i<count_trades;i++) { m_trades_stats[i].max_price_trade=iHighest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // maximal price of trade m_trades_stats[i].min_price_trade=iLowest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // minimal price of trade double minimax=0; minimax=m_trades_stats[i].max_price_trade-m_trades_stats[i].min_price_trade;// difference between maximum and minimum if(minimax!=0)minimax=1.0/minimax; if(m_trades_stats[i].trade_type==DEAL_TYPE_BUY) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].enter_price)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].enter_price)*minimax; } else { if(m_trades_stats[i].trade_type==DEAL_TYPE_SELL) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].exit_price)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].exit_price)*minimax; } } } }
O método usa dois métodos privados iHighest() e iLowest(), eles são similares e a única diferença são os dados necessários e a função de pesquisa fmin e fmax.
//+------------------------------------------------------------------+ //| searching maximum within the period start_time --> stop_time | //+------------------------------------------------------------------+ double C_Pos::iHighest(string symbol_name,// symbols name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ) { double buf[]; datetime start_t=(start_time/60)*60;// normalization of time of opening datetime stop_t=(stop_time/60+1)*60;// normaliztion of time of closing int period=CopyHigh(symbol_name,timeframe,start_t,stop_t,buf); double res=buf[0]; for(int i=1;i<period;i++) res="fmax(res,buf[i]); return(res); }
O método procura o máximo dentro de um período entre duas datas específicas. As datas são passadas para a função como os parâmetros start_time e stop_time. Assim que as datas dos negócios forem passadas para a função e uma requisição de negócio mesmo no meio da barra de 1 minuto, a normalização da data para o valor mais próximo de barra é realizada dentro da função. O mesmo é feito na função iLowest(). Com o método efficiency() desenvolvido, nós temos toda a funcionalidade para trabalhar com uma situação, mas não há tratamento da posição em si por enquanto. Vamos atingir isto pela determinação de uma nova classe, para qual todos os métodos anteriores estarão disponíveis, em outras palavras, declare isto como uma derivação de C_Pos.
Classe derivadas (classes de mecanismo)
class C_PosStat:public C_Pos
Para considerar a informação estatística, crie uma estrutura que será dada a nova classe.
//+------------------------------------------------------------------+ //| structure of effectiveness | //+------------------------------------------------------------------+ struct S_efficiency { double enter_efficiency; // effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency; // effectiveness of trade S_efficiency() { enter_efficiency=0; exit_efficiency=0; trade_efficiency=0; }; ~S_efficiency(){}; };
E o corpo da classe em si.
//+------------------------------------------------------------------+ //| class of statistics of trade in whole | //+------------------------------------------------------------------+ class C_PosStat:public C_Pos { public: int PosTotal; // number of positions in history C_Pos pos[]; // array of pointers to positions int All_count_trades; // total number of trades in history S_efficiency trade[]; // array of pointers to the structure of effectiveness of entering, exiting and trades S_efficiency avg; // pointer to the structure of average value of effectiveness of entering, exiting and trades S_efficiency stdev; // pointer to the structure of standard deviation from // average value of effectiveness of entering, exiting and trades C_PosStat(){PosTotal=0;}; ~C_PosStat(){}; void OnPosStat(); // engine classes void OnTradesStat(); // gathering information about trades into the common array // functions of writing information to a file void WriteFileDeals(string folder="deals"); void WriteFileTrades(string folder="trades"); void WriteFileTrades_all(string folder="trades_all"); void WriteFileDealsHTML(string folder="deals"); void WriteFileDealsHTML2(string folder="deals"); void WriteFileTradesHTML(string folder="trades"); void WriteFileTradesHTML2(string folder="trades"); string enum_translit(ENUM_DEAL_ENTRY x,bool latin=true);// transformation of enumeration into string string enum_translit(ENUM_DEAL_TYPE x,bool latin=true); // transformation of enumeration into string (overloaded) private: S_efficiency AVG(int count); // arithmetical mean S_efficiency STDEV(const S_efficiency &mo,int count); // standard deviation S_efficiency add(const S_efficiency &a,const S_efficiency &b); //add S_efficiency take(const S_efficiency &a,const S_efficiency &b); //subtract S_efficiency multiply(const S_efficiency &a,const S_efficiency &b); //multiply S_efficiency divided(const S_efficiency &a,double b); //divide S_efficiency square_root(const S_efficiency &a); //square root string Head_style(string title); };
Eu sugiro analisar esta classe em sentido inverso, partindo do fim para o começo. Tudo termina com a escrita de uma tabela de acordos e negócios em arquivos. Uma diversidade de funções foi escrita com esse propósito (você pode entender o objetivo de cada uma a partir do nome). As funções fazem um relatório csv sobre acordos e trocas, assim como relatórios em html de dois tipos (eles diferem apenas visualmente, mas tem o mesmo conteúdo).
void WriteFileDeals(); // writing csv report on deals void WriteFileTrades(); // writing csv report on trade void WriteFileTrades_all(); // writing summary csv report of fitness functions void WriteFileDealsHTML2(); // writing html report on deals, 1 variant void WriteFileTradesHTML2();// writing html report on trades, 2 variant
A função enum_translit é planejada para transformação de valores de enumerações em tipo de cadeia (string) para escrevê-los no arquivo de registro. A sessão privada contém várias funções da estrutura S_efficiency. Todas as funções compensam a desvantagem da linguagem, notavelmente as operações aritméticas com estruturas. Visto que as opiniões sobre implementação destes métodos variam, eles podem ser percebidos de maneiras diferentes. Eu os percebi como métodos de operações aritméticas com os campos de estrutura. Alguém pode dizer que é melhor processar cada campo de estrutura usando um método individual. Resumindo, eu diria que existem tantas opiniões quanto programadores. Eu espero que no futuro nós tenhamos a possibilidade de efetuar tais operações utilizando métodos embutidos.
O método AVG() calcula o valor da média aritmética do ensaio passado, mas não mostra totalmente o quadro de distribuição, é por isto que é complementado com outro método que calcula o desvio padrão, STDEV(). A função OnTradeStat() pega os valores de eficácia (previamente calculados no OnPosStat()) e os processa com métodos estatísticos. E finalmente, a função principal da classe - OnPosStat().
Esta função deve ser considerada em detalhes. Ela consiste de duas partes, então pode ser facilmente dividida. A primeira parte procura por todas as situações e processa as suas id salvado-as no ensaio temporário id_pos. Passo a passo: selecione todo o histórico disponível, calcule o número de acordos, rode o ciclo de acordos em processamento. O ciclo: se o tipo do acordo é balans, pule-o (não há necessidade de interpretar o acordo inicial), caso contrário- salve a id da posição em variáveis e realize a busca. Se a mesma id já existe na base de dados (o ensaio id_pos), vá para o próximo acordo, caso contrário, escreva a id na base de dados. De certo modo, após processar todos os acordos nós temos o ensaio preenchido com todas as ids de situações existentes e o número de situações.
long id_pos[];// auxiliary array for creating the history of positions if(HistorySelect(0,TimeCurrent())) { int HTD=HistoryDealsTotal(); ArrayResize(id_pos,PosTotal,HTD); for(int i=0;i<HTD;i++) { ulong DTicket=(ulong)HistoryDealGetTicket(i); if((ENUM_DEAL_TYPE)HistoryDealGetInteger(DTicket,DEAL_TYPE)==DEAL_TYPE_BALANCE) continue;// if it's a balance deal, skip it long id=HistoryDealGetInteger(DTicket,DEAL_POSITION_ID); bool present=false; // initial state, there's no such position for(int j=0;j<PosTotal;j++) { if(id==id_pos[j]){ present=true; break; } }// if such position already exists break if(!present)// write id as a new position appears { PosTotal++; ArrayResize(id_pos,PosTotal); id_pos[PosTotal-1]=id; } } } ArrayResize(pos,PosTotal);
Na segunda parte, nós percebemos todos os métodos descritos previamente na classe base C_Pos. Isto consiste de um ciclo que vai sobre as situações e conduz o método de processamento de situações correspondente. A descrição do método é dada no código abaixo.
for(int p=0;p<PosTotal;p++) { if(HistorySelectByPosition(id_pos[p]))// select position { pos[p].pos_id=id_pos[p]; // assigned id of position to the corresponding field of the class C_Pos pos[p].count_deals=HistoryDealsTotal();// assign the number of deal in position to the field of the class C_Pos pos[p].symbol=HistoryDealGetString(HistoryDealGetTicket(0),DEAL_SYMBOL);// the same actions with symbol pos[p].OnHistory(); // start filling the structure sd with the history of position pos[p].OnHistoryTransform(); // transformation of interpretation, filling the structure st. pos[p].efficiency(); // calculation of the effectiveness of obtained data All_count_trades+=pos[p].count_trades;// save the number of trades for displaying the total number } }
Nomeando métodos da classe
Deste modo, nós consideramos toda a classe. Falta dar um exemplo de nomeação. Para manter as possibilidades de construção, eu não declarei explicitamente a nomeação em uma função. Além disto, você pode aumentar a classe para suas necessidades, executar novos métodos de processamento estatístico de dados. Aqui está um exemplo de nomeação de método da classe a partir de um roteiro:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ #include void OnStart() { C_PosStat start; start.OnPosStat(); start.OnTradesStat(); start.WriteFileDeals(); start.WriteFileTrades(); start.WriteFileTrades_all(); start.WriteFileDealsHTML2(); start.WriteFileTradesHTML2(); Print("cko tr ef=" ,start.stdev.trade_efficiency); Print("mo tr ef=" ,start.avg.trade_efficiency); Print("cko out ef=",start.stdev.exit_efficiency); Print("mo out ef=",start.avg.exit_efficiency); Print("cko in ef=" ,start.stdev.enter_efficiency); Print("mo in ef=" ,start.avg.enter_efficiency); }
O roteiro cria 5 arquivos de relatório conforme a quantidade de funções que escrevem dados no arquivo no diretório Files\OnHistory. As seguintes funções principais são presentes aqui - OnPosStat() e OnTradeStat(), elas são usadas para nomeação de todos os métodos necessários. O roteiro termina com a impressão do valor de eficácia obtido da negociação como um todo. Cada um destes valores pode ser usado para otimização genética.
Uma vez que não há necessidade de escrever cada relatório em um arquivo durante a otimização, a chamada da classe em um Consultor Especialista parece um pouco diferente. Primeiramente, oposto a um roteiro, um Consultor Especialista pode ser executado no testador (é para isso que nós o preparamos. Trabalhar no testador de estratégia tem suas peculiaridades. Quando otimizando, nós temos o acesso a função OnTester(), nela, a sua execução é realizada previamente a execução da função OnDeinit(). Assim, a nomeação dos métodos principais de transformação pode ser separada. Para a conveniência da modificação da função de capacidade a partir dos parâmetros do Consultor Especialista, eu declarei uma enumeração globalmente, não como uma parte de uma classe. Em que a enumeração está na mesma planilha com os métodos da classe C_PosStat.
//+------------------------------------------------------------------+ //| enumeration of fitness functions | //+------------------------------------------------------------------+ enum Enum_Efficiency { avg_enter_eff, stdev_enter_eff, avg_exit_eff, stdev_exit_eff, avg_trade_eff, stdev_trade_eff };
Isto é o que deve ser adicionado ao cabeçalho do Consultor Especialista.
#include input Enum_Efficiency result=0;// Fitness function
Agora nós podemos descrever a passagem dos parâmetros necessários usando o operador troca (switch).
//+------------------------------------------------------------------+ //| Expert optimization function | //+------------------------------------------------------------------+ double OnTester() { start.OnPosStat(); start.OnTradesStat(); double res; switch(result) { case 0: res=start.avg.enter_efficiency; break; case 1: res=-start.stdev.enter_efficiency; break; case 2: res=start.avg.exit_efficiency; break; case 3: res=-start.stdev.exit_efficiency; break; case 4: res=start.avg.trade_efficiency; break; case 5: res=-start.stdev.trade_efficiency; break; default : res=0; break; } return(res); }
Eu gostaria de chamar sua atenção para o fato de que a função OnTester() é usada para maximização da função personalizada. Se você necessitar achar o mínimo da função personalizada, então é melhor reverter a função em si, multiplicando por -1. Assim como no exemplo com o desvio padrão, todos entendem que quanto menor é o desvio padrão, menor é a diferença entre a eficácia dos negócios, portanto a estabilidade dos negócios é maior. É por isto que o desvio padrão deve ser minimizado. Agora, como nós lidamos com a nomeação dos métodos de classe, vamos considerar escrever o relatório em um arquivo.
Previamente, eu mencionei que os métodos de classe que criam um relatório. Agora veremos aonde e quando eles devem ser nomeados. Os relatórios devem ser criados apenas quando o Consultor Especialista é iniciado para uma operação simples. Caso contrário, o Consultor Especialista criará os arquivos no modo de otimização; ou seja, ao invés de um arquivo, ele criará diversos arquivos (caso diferentes nomes de arquivos passem a cada vez), ou um, mas o último com o mesmo nome para todas as operações, o que é absolutamente sem sentido, uma vez que ele gasta os recursos para a informação que será futuramente apagada.
De qualquer modo, você não deve criar arquivos de relatório durante a otimização. Se você obtiver vários arquivos com nomes diferentes, provavelmente não abrirá a maioria deles. A segunda variante tem um desperdício de recursos pela obtenção de informação que é apagada logo em seguida.
É por isso que a melhor variante é para fazer filtro (comece o relatório apenas no modo Optimization[disabled]). Deste modo o HDD não será cheio com relatórios que nunca são visualizados. Além disso, a velocidade de otimização aumenta (não é segredo que as operações mais lentas são as operações de arquivo); além disto, a possibilidade de obter rapidamente um relatório com os parâmetros necessários é mantida. Na verdade, não importa aonde colocar o filtro, nas funções OnTester ou OnDeinit. O importante são que os métodos de classe, que criam um relatório, devem ser nomeados a partir do método principal que realiza a transformação. Eu coloquei o filtro ao OnDeinit() para não sobrecarregar o código:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(!(bool)MQL5InfoInteger(MQL5_OPTIMIZATION)) { start.WriteFileDeals(); // writing csv report on deals start.WriteFileTrades(); // writing csv report on trades start.WriteFileTrades_all(); // writing summary csv report on fitness functions start.WriteFileDealsHTML2(); // writing html report on deals start.WriteFileTradesHTML2();// writing html report on trades } } //+------------------------------------------------------------------+
A sequência de nomeação dos métodos não é importante. Tudo que é necessário para fazer relatórios é preparado nos métodos OnPosStat e OnTradeStat. Também, não importa se você nomeia todos os métodos de escrever relatórios ou somente algum deles; operação de cada um deles é individual; é uma interpretação de informação que já se encontra armazenada na classe.
Dar entrada ao testador de estratégia
O resultado de uma única operação no testador de estratégia é dado abaixo:
Relatório de negócios mudando estatísticas comuns. | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # | Ingresso | tipo | volume | Abrir | Fechar | Preço | Eficácia | ||||||
| abrir | fechar | preço | tempo | preço | tempo | máximo | mínimo | entrar | sair | negócio | |||
| pos[0] | id 2 | EURUSD | |||||||||||
| 0 | 2 | 3 | comprar | 0,1 | 1,37203 | 2010.03.15 13:00:00 | 1,37169 | 2010.03.15 14:00:00 | 1,37236 | 1,37063 | 0,19075 | 0,61272 | -0,19653 |
| pos[1] | id 4 | EURUSD | |||||||||||
| 1 | 4 | 5 | vender | 0,1 | 1,35188 | 2010.03.23 08:00:00 | 1,35243 | 2010.03.23 10:00:00 | 1,35292 | 1,35025 | 0,61049 | 0,18352 | -0,20599 |
| pos[2] | id 6 | EURUSD | |||||||||||
| 2 | 6 | 7 | vender | 0,1 | 1,35050 | 2010.03.23 12:00:00 | 1,35343 | 2010.03.23 16:00:00 | 1,35600 | 1,34755 | 0,34911 | 0,30414 | -0,34675 |
| pos[3] | id 8 | EURUSD | |||||||||||
| 3 | 8 | 9 | vender | 0,1 | 1,35167 | 2010.03.23 18:00:00 | 1,33343 | 2010.03.26 05:00:00 | 1,35240 | 1,32671 | 0,97158 | 0,73842 | 0,71000 |
| pos[4] | id 10 | EURUSD | |||||||||||
| 4 | 10 | 11 | vender | 0,1 | 1,34436 | 2010.03.30 16:00:00 | 1,33616 | 2010.04.08 23:00:00 | 1,35904 | 1,32821 | 0,52384 | 0,74213 | 0,26597 |
| pos[5] | id 12 | EURUSD | |||||||||||
| 5 | 12 | 13 | comprar | 0,1 | 1,35881 | 2010.04.13 08:00:00 | 1,35936 | 2010.04.15 10:00:00 | 1,36780 | 1,35463 | 0,68261 | 0,35915 | 0,04176 |
| pos[6] | id 14 | EURUSD | |||||||||||
| 6 | 14 | 15 | vender | 0,1 | 1,34735 | 2010.04.20 04:00:00 | 1,34807 | 2010.04.20 10:00:00 | 1,34890 | 1,34492 | 0,61055 | 0,20854 | -0,18090 |
| pos[7] | id 16 | EURUSD | |||||||||||
| 7 | 16 | 17 | vender | 0,1 | 1,34432 | 2010.04.20 18:00:00 | 1,33619 | 2010.04.23 17:00:00 | 1,34491 | 1,32016 | 0,97616 | 0,35232 | 0,32848 |
| pos[8] | id 18 | EURUSD | |||||||||||
| 8 | 18 | 19 | vender | 0,1 | 1,33472 | 2010.04.27 10:00:00 | 1,32174 | 2010.04.27 05:00:00 | 1,33677 | 1,31141 | 0,91916 | 0,59267 | 0,51183 |
| pos[9] | id 20 | EURUSD | |||||||||||
| 9 | 20 | 21 | vender | 0,1 | 1,32237 | 2010.05.03 04:00:00 | 1,27336 | 2010.05.07 20:00:00 | 1,32525 | 1,25270 | 0,96030 | 0,71523 | 0,67553 |
E o gráfico de balanço é:
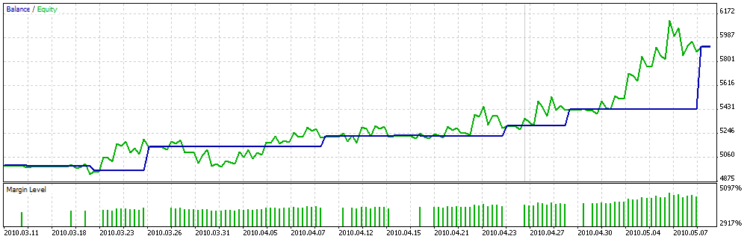
Você pode ver claramente na tabela que a função personalizada de otimização não tenta escolher os parâmetros com o maior número de acordos, mas os acordos de maior duração, nos acordos que tem lucro igual, ou seja a dispersão não é alta.
Uma vez que o código das Médias Móveis não contém os atributos de volume aumentado de posição ou fechamento parcial, o resultado da transformação não parece ser próximo ao descrito acima. Abaixo, você pode ver outro resultado de utilizar o roteiro na conta aberta especialmente para testar códigos:
| pos[286] | id 1019514 | EURUSD | |||||||||||
| 944 | 1092288 | 1092289 | comprar | 0,1 | 1,26733 | 2010.07.08 21:14:49 | 1,26719 | 2010.07.08 21:14:57 | 1,26752 | 1,26703 | 0,38776 | 0,32653 | -0,28571 |
| pos[287] | id 1019544 | EURUSD | |||||||||||
| 945 | 1092317 | 1092322 | vender | 0,2 | 1,26761 | 2010.07.08 21:21:14 | 1,26767 | 2010.07.08 21:22:29 | 1,26781 | 1,26749 | 0,37500 | 0,43750 | -0,18750 |
| 946 | 1092317 | 1092330 | vender | 0,2 | 1,26761 | 2010.07.08 21:21:14 | 1,26792 | 2010.07.08 21:24:05 | 1,26782 | 1,26749 | 0,36364 | -0,30303 | -0,93939 |
| 947 | 1092319 | 1092330 | vender | 0,3 | 1,26761 | 2010.07.08 21:21:37 | 1,26792 | 2010.07.08 21:24:05 | 1,26782 | 1,26749 | 0,36364 | -0,30303 | -0,93939 |
| pos[288] | id 1019623 | EURUSD | |||||||||||
| 948 | 1092394 | 1092406 | comprar | 0,1 | 1,26832 | 2010.07.08 21:36:43 | 1,26843 | 2010.07.08 21:37:38 | 1,26882 | 1,26813 | 0,72464 | 0,43478 | 0,15942 |
| pos[289] | id 1019641 | EURUSD | |||||||||||
| 949 | 1092413 | 1092417 | comprar | 0,1 | 1,26847 | 2010.07.08 21:38:19 | 1,26852 | 2010.07.08 21:38:51 | 1,26910 | 1,26829 | 0,77778 | 0,28395 | 0,06173 |
| 950 | 1092417 | 1092433 | vender | 0,1 | 1,26852 | 2010.07.08 21:38:51 | 1,26922 | 2010.07.08 21:39:58 | 1,26916 | 1,26829 | 0,26437 | -0,06897 | -0,80460 |
| pos[290] | id 1150923 | EURUSD | |||||||||||
| 951 | 1226007 | 1226046 | comprar | 0,2 | 1,31653 | 2010.08.05 16:06:20 | 1,31682 | 2010.08.05 16:10:53 | 1,31706 | 1,31611 | 0,55789 | 0,74737 | 0,30526 |
| 952 | 1226024 | 1226046 | comprar | 0,3 | 1,31632 | 2010.08.05 16:08:31 | 1,31682 | 2010.08.05 16:10:53 | 1,31706 | 1,31611 | 0,77895 | 0,74737 | 0,52632 |
| 953 | 1226046 | 1226066 | vender | 0,1 | 1,31682 | 2010.08.05 16:10:53 | 1,31756 | 2010.08.05 16:12:49 | 1,31750 | 1,31647 | 0,33981 | -0,05825 | -0,71845 |
| 954 | 1226046 | 1226078 | vender | 0,2 | 1,31682 | 2010.08.05 16:10:53 | 1,31744 | 2010.08.05 16:15:16 | 1,31750 | 1,31647 | 0,33981 | 0,05825 | -0,60194 |
| pos[291] | id 1155527 | EURUSD | |||||||||||
| 955 | 1230640 | 1232744 | vender | 0,1 | 1,31671 | 2010.08.06 13:52:11 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,31648 | 0,01370 | 0,24062 | -0,74568 |
| 956 | 1231369 | 1232744 | vender | 0,1 | 1,32584 | 2010.08.06 14:54:53 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32518 | 0,08158 | 0,49938 | -0,41904 |
| 957 | 1231455 | 1232744 | vender | 0,1 | 1,32732 | 2010.08.06 14:58:13 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32539 | 0,24492 | 0,51269 | -0,24239 |
| 958 | 1231476 | 1232744 | vender | 0,1 | 1,32685 | 2010.08.06 14:59:47 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32539 | 0,18528 | 0,51269 | -0,30203 |
| 959 | 1231484 | 1232744 | vender | 0,2 | 1,32686 | 2010.08.06 15:00:20 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32539 | 0,18655 | 0,51269 | -0,30076 |
| 960 | 1231926 | 1232744 | vender | 0,4 | 1,33009 | 2010.08.06 15:57:32 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32806 | 0,38964 | 0,77543 | 0,16507 |
| 961 | 1232591 | 1232748 | vender | 0,4 | 1,33123 | 2010.08.06 17:11:29 | 1,32850 | 2010.08.06 17:40:40 | 1,33129 | 1,32806 | 0,98142 | 0,86378 | 0,84520 |
| 962 | 1232591 | 1232754 | vender | 0,4 | 1,33123 | 2010.08.06 17:11:29 | 1,32829 | 2010.08.06 17:42:14 | 1,33129 | 1,32796 | 0,98198 | 0,90090 | 0,88288 |
| 963 | 1232591 | 1232757 | vender | 0,2 | 1,33123 | 2010.08.06 17:11:29 | 1,32839 | 2010.08.06 17:43:15 | 1,33129 | 1,32796 | 0,98198 | 0,87087 | 0,85285 |
| pos[292] | id 1167490 | EURUSD | |||||||||||
| 964 | 1242941 | 1243332 | vender | 0,1 | 1,31001 | 2010.08.10 15:54:51 | 1,30867 | 2010.08.10 17:17:51 | 1,31037 | 1,30742 | 0,87797 | 0,57627 | 0,45424 |
| 965 | 1242944 | 1243333 | vender | 0,1 | 1,30988 | 2010.08.10 15:55:03 | 1,30867 | 2010.08.10 17:17:55 | 1,31037 | 1,30742 | 0,83390 | 0,57627 | 0,41017 |
| pos[293] | id 1291817 | EURUSD | |||||||||||
| 966 | 1367532 | 1367788 | vender | 0,4 | 1,28904 | 2010.09.06 00:24:01 | 1,28768 | 2010.09.06 02:53:21 | 1,28965 | 1,28710 | 0,76078 | 0,77255 | 0,53333 |
É assim que a informação transformada se parece; para dar aos leitores a possibilidade de considerar deliberativamente tudo (e conhecimento vem através de comparação), eu salvei o histórico de acordos original em um arquivo separado; este é o histórico que agora não é compreendido por vários negociadores, que estavam acostumados a vê-lo na seção [Resultados] do MetaTrader 4.
Conclusão
Em conclusão, eu gostaria de sugerir aos desenvolvedores para adicionar uma possibilidade de otimizar os Consultores Especialistas, não apenas por um parâmetro personalizado, mas fazer isto em combinação com os padrões assim como é feito com as outras funções de otimização. Resumindo este artigo, eu posso dizer que ele contém apenas o básico, o potencial inicial; e eu espero que os leitores sejam capazes de aprimorar a classe de acordo com suas próprias necessidades. Boa sorte!
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/137
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Expert Advisor baseado em "New Trading Dimensions" por Bill Williams
Expert Advisor baseado em "New Trading Dimensions" por Bill Williams
 Diversas maneiras de se encontrar uma tendência no MQL5
Diversas maneiras de se encontrar uma tendência no MQL5
 O Histograma de preço (Perfil de mercado) e sua implementação no MQL5
O Histograma de preço (Perfil de mercado) e sua implementação no MQL5
 Criando indicadores multicoloridos no MQL5
Criando indicadores multicoloridos no MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Resta resolver o problema de pesquisa sobre a média dourada.
Gostaria de saber de onde vem esse amor pelo TF?
Qual é o atrativo da quantificação da série inicial {Price, Time} pelo tempo?
Gostaria de saber de onde vem esse amor pelo TF?
Qual é o desejo de quantificar a série inicial {Price, Time} por tempo?
Hi,
Estou tentando usar seu código há meses. O problema é que ele só escreve o cabeçalho para o html. E para o Excel, só aparece "yb" na primeira célula. Repeti seu artigo várias vezes e não consegui resolver esse problema. Considero seu artigo muito útil. Você pode me ajudar com esse problema. Sou um novato aqui. Sua ajuda seria muito importante para mim. Muito obrigado.
Onde posso abrir o arquivo html? Não vi como ele é gerado