
Évaluation des systèmes de trading - l’efficacité d’ouverture, de clôture et de trades en général

Introduction
Il y a beaucoup de mesures qui déterminent l’efficacité d’un système de trading ; et les traders choisissent leurs favoris. Cet article parle des approches décrites dans le livre de S.V. « Statistika dlya traderov » (« Statistiques destinées aux traders »). Bulashev. Malheureusement, le nombre d’exemplaires de ce livre est trop minime et il n’a pas été réédité depuis longtemps; cependant, sa version électronique est toujours disponible sur de nombreux sites Web.
Prologue
Je vous rappelle que le livre a été publié en 2003. Et c’était l’époque de MetaTrader 3 avec le langage de programmation MQL-II. Et la plate-forme était plutôt progressiste pour cette époque. Ainsi, nous pouvons suivre les changements des conditions de trading elles-mêmes en les comparant au terminal client moderne MetaTrader 5. Il convient de noter que l’auteur du livre est devenu un gourou pour de nombreuses générations de traders (compte tenu du changement rapide de générations dans ce domaine). Mais le temps ne s’est pas arrêté; bien que les principes décrits dans le livre soient toujours applicables, les approches devraient être adaptées.
S.V. Bulashev a écrit son livre, tout d’abord, sur la base des conditions de trade en temps réel pour cette époque. C’est pourquoi nous ne pouvons pas utiliser les statistiques décrites par l’auteur sans une certaine transformation. Pour plus de clarté, rappelons-nous les possibilités de trading de cette époque: le trading marginal sur un marché au comptant implique que l’achat d’une devise pour obtenir un profit spéculatif se transforme en vente après un certain temps.
Ce sont les bases, et il vaut la peine de rappeler, que l’interprétation exacte a été utilisée lorsque le livre « Statistiques destinées aux traders » a été écrit. Chaque transaction de 1 lot devrait être clôturée par la transaction inverse du même volume. Toutefois, après deux ans (en 2005), l’utilisation de ces statistiques nécessitait une réorganisation. La raison en est que la clôture partielle des transactions est devenue possible dans MetaTrader 4. Ainsi, pour utiliser les statistiques décrites par Bulashev, nous devons améliorer le système d’interprétation, notamment l’interprétation devrait être faite par le fait de la clôture et non par l’ouverture.
Après 5 autres années, la situation a considérablement changé. Où est passé aujourd’hui le terme si habituel de l’Ordre ? Il a disparu. Compte tenu du flux de questions sur ce forum, il est préférable de décrire le système exact d’interprétation dans MetaTrader 5.
Donc, aujourd’hui, il n’y a plus de terme classique Ordre. Un ordre est maintenant une demande de transaction au serveur d’un courtier, qui est faite par un trader ou MTS pour ouvrir ou modifier une position de transaction. Maintenant, c’est une position; pour comprendre sa signification, j’ai mentionné le trading marginal. Le fait est que le trading marginal est effectué sur de l’argent emprunté ; et une position existe tant que cet argent existe.
Dès que vous réglez des comptes avec l’emprunteur en clôturant la position et en corrigeant ainsi un bénéfice/perte, votre position cesse d’exister. Soit dit en passant, ce fait explique la raison pour laquelle un renversement de position ne la clôture pas. Le fait est que l’emprunt reste de toute façon et qu’il n’y a pas de différence si vous avez emprunté de l’argent pour acheter ou pour vendre. Une transaction n’est qu’un historique d’un ordre exécuté.
Parlons maintenant des caractéristiques du trading. Actuellement, dans MetaTrader 5, nous pouvons à la fois clôturer partiellement une position de trading ou élever une position existante. Ainsi, le système classique d’interprétation, où chaque ouverture d’une position d’un certain volume est suivie de la clôture avec le même volume, appartient au passé. Mais est-il vraiment impossible de le récupérer à partir des informations stockées dans MetaTrader 5 ? Donc, tout d’abord, nous allons réorganiser l’interprétation.
L’efficacité de l’entrée
Ce n’est pas un secret. Beaucoup de gens veulent rendre leur trading plus efficace, mais comment décrire (formaliser) ce terme? Si vous supposez qu’une transaction est un chemin qui passe par le prix, alors il devient évident qu’il y a deux points extrêmes sur ce chemin: minimum et maximum de prix dans la section observée. Tout le monde s’efforce d’entrer sur le marché en étant le plus proche possible du minimum (lors de l'achat). Cela peut être considéré comme une règle principale de tout trading : acheter à moins cher, vendre à plus cher.
L’efficacité d’entrée détermine à quel point vous achetez au moins offrant. En d’autres termes, l’efficacité de l’entrée est le rapport de distance entre le maximum et le prix d’entrée sur l’ensemble du chemin. Pourquoi mesurons-nous la distance au minimum par la différence de maximum ? Nous avons besoin que l’efficacité soit égale à 1 lors de l’entrée par un minimum (et à 0 lors de l’entrée par un maximum).
C’est pourquoi pour notre ratio, nous prenons le reste de la distance, et non la distance entre le minimum et l’entrée elle-même. Ici, nous devons souligner que la situation de la vente se reflète par rapport à l’achat.
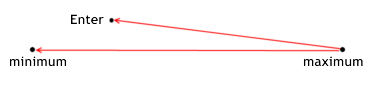
L’efficacité de l’entrée de position montre à quel point un MTS réalise le bénéfice potentiel par rapport au prix d’entrée pendant certaines transactions. Elle est calculé par les formules suivantes :
for long positions enter_efficiency=(max_price_trade-enter_price)/(max_price_trade-min_price_trade); for short positions enter_efficiency=(enter_price-min_price_trade)/(max_price_trade-min_price_trade); The effectiveness of entering can have a value within the range from 0 to 1.
L’efficacité lors de la sortie
La situation avec la sortie est similaire:
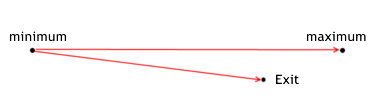
L’efficacité de la sortie d’une position montre à quel point un MTS réalise le bénéfice potentiel par rapport au prix de sortie de la position pendant certaines transactions. Elle est calculé par les formules suivantes :
for lone positions exit_efficiency=(exit_price - min_price_trade)/(max_price_trade - min_price_trade); for short positions exit_efficiency=(max_price_trade - exit_price)/(max_price_trade - min_price_trade); The effectiveness of exiting can have a value withing the range from 0 to 1.
L’efficacité d’un trade
Dans l’ensemble, l’efficacité d’un trade est déterminée à la fois par l’entrée et la sortie. Elle peut être calculée comme le rapport entre l’entrée et la sortie à la distance maximale pendant la transaction (c’est-à-dire la différence entre le minimum et le maximum). Ainsi, l’efficacité d’une transaction peut être calculée de deux manières - directement en utilisant les informations primaires sur la transaction, ou en utilisant les résultats déjà calculés des entrées et des sorties précédemment évaluées (avec un décalage d’intervalle).
L’efficacité du commerce montre à quel point un MTS réalise le profit potentiel total pendant certaines transactions. Elle est calculée par les formules suivantes:
for long positions trade_efficiency=(exit_price-enter_price)/(max_price_trade-min_price_trade); for short positions trade_efficiency=(enter_price-exit_price)/(max_price_trade-min_price_trade); general formula trade_efficiency=enter_efficiency+exit_efficiency-1; The effectiveness of trade can have a value within the range from -1 to 1. The effectiveness of trade must be greater than 0,2. The analysis of effectiveness visually shows the direction for enhancing the system, because it allows evaluating the quality of signals for entering and exiting a position separately from each other.
Transformation de l’interprétation
Tout d’abord, pour éviter toute forme de confusion, nous devons clarifier les noms des objets d’interprétation. Étant donné que les mêmes termes - ordre, transaction, position sont utilisés dans MetaTrader 5 et par Bulachev, nous devons les séparer. Dans mon article, je vais utiliser le nom « trade » pour l’objet d’interprétation de Bulachev, c’est-à-dire que le trade est une transaction ; il utilise également le terme « ordre » pour cela, dans ce contexte ces termes sont identiques. Bulachev appelle une transaction inachevée une position, et nous allons l’appeler trade non conclu.
Ici, vous pouvez voir que les 3 termes sont facilement adaptés en un seul mot « trade ». Et nous n’allons pas renommer l’interprétation dans MetaTrader 5, et la signification de ces trois termes reste la même que celle conçue par les développeurs du terminal client. En conséquence, nous avons 4 mots que nous allons utiliser - Position, Deal, Ordre et Trade.
Étant donné qu’un ordre est une commande au serveur pour ouvrir/modifier une position et qu’il ne concerne pas directement les statistiques, mais qu’il le fait indirectement par le biais d’une transaction (la raison en est que l’envoi d’un ordre n’entraîne pas toujours l’exécution de la transaction correspondante du volume et du prix spécifiés), il est alors juste de collecter les statistiques par transactions et non par ordres.
Prenons un exemple d’interprétation de la même position (pour rendre la description ci-dessus plus claire) :
interpretation in МТ-5 deal[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 deal[ 1 ] in/out 0.2 buy 1.22261 2010.06.14 13:36 deal[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 deal[ 3 ] out 0.2 sell 1.22310 2010.06.14 13:41
interpretation by Bulachev trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36 trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
Maintenant, je vais décrire la façon dont ces manipulations ont été menées. Deal[ 0 ] ouvre la position, nous l’écrivons comme le début de la nouvelle transaction :
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33
Vient ensuite l’inverse de la position; cela signifie que tous les trades antérieurs doivent être fermés. En conséquence, les informations sur la deal[ 1 ] inversée seront prises en compte à la fois lors de la clôture et de l’ouverture du nouveau trade. Une fois que tous les trades non clos avant la fermeture de la transaction avec la direction entrée/sortie sont fermés, il nous faut ouvrir le nouveau trade. C’est-à-dire que nous n’utilisons que les informations de prix et de temps sur la transaction sélectionnée pour la clôture, contrairement à l’ouverture d’un trade, lorsque le type et le volume sont également utilisés. Ici, nous devons clarifier un terme qui n’a pas été utilisé avant qu’il n’apparaisse dans la nouvelle interprétation - c’est la direction de transaction. Auparavant, en parlant d’un achat ou d’une vente, nous voulions parler de la « direction », c’était la même signification que le terme « type ». De temps en temps, le type et la direction sont des termes différents.
Type se réfère à un achat ou une vente, tandis que direction renvoie à une entrée ou une sortie d'une position. C’est pourquoi une position est toujours ouverte avec une transaction de la direction in, et est fermée avec une transaction out. Mais la direction n’est pas limitée avec seulement l’ouverture et la fermeture des positions. Ces termes comprennent également l’accroissement de volume d’une position (si la transaction « in » n’est pas la première de la liste) et la clôture partielle d’une position (les transactions « out » ne sont pas les dernières de la liste). Puisque la fermeture partielle est devenue disponible, il est logique d’introduire également l’inverse de la position; une inversion se produit lorsqu’une transaction opposée d’une taille supérieure à la position actuelle est effectuée, c’est-à-dire qu’il s’agit d’une transaction in/out.
Donc, nous avons fermé les trades précédemment ouverts (pour inverser la position) :
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36
Le volume de repos est de 0,1 lot, et il est utilisé pour ouvrir le nouveau trade :
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36
Puis vient la transaction[ 2 ] avec la direction in, pour ouvrir un autre trade :
trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39
Et enfin, la transaction qui ferme la position - deal[ 3 ] ferme tous les trades en positions non closes :
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
L’interprétation décrite ci-dessus montre l’essentiel de l’interprétation utilisée par Bulachev - chaque trade ouvert a un certain point d’entrée et un certain point de sortie, il a son volume et son type. Mais ce système d’interprétation ne tient pas compte d’une nuance - la fermeture partielle. Si vous regardez de plus près, vous verrez que le nombre de trades est égal au nombre de transactions in (compte tenu des transactions in/out). Dans ce cas, il vaut la peine d’interpréter par transactions in, mais il y aura plus de transactions out à la fermeture partielle (il peut y avoir une situation où le nombre de transactions in et out est le même, mais sans le même volume).
Pour traiter l’ensemble des transactions out, il nous faudrait interpréter par les transactions out. Et cette contradiction semble insoluble si nous effectuons un traitement séparé des transactions, dans un premier temps - toutes les transactions in, et toutes les transactions out (ou vice versa). Mais si nous traitons les transactions séquentiellement et appliquons une règle de traitement spéciale à chacune d’elles, il n’y a pas de contradictions.
Voici un exemple, où le nombre de transactions out est supérieur au nombre des transactions in (avec description) :
interpretation in МТ-5 deal[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00 deal[ 1 ] out 0.2 buy 1.22145 2010.06.15 08:01 deal[ 2 ] in/out 0.4 buy 1.22145 2010.06.15 08:02 deal[ 3 ] in/out 0.4 sell 1.22122 2010.06.15 08:03 deal[ 4 ] out 0.1 buy 1.2206 2010.06.15 08:06
interpretation by Bulachev trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:02 trade[ 2 ] in 0.3 buy 1.22145 2010.06.15 08:02 out 1.22122 2010.06.15 08:03 trade[ 3 ] in 0.1 sell 1.22122 2010.06.15 08:03 out 1.2206 2010.06.15 08:06
Nous avons une situation, quand une transaction de clôture intervient après l’ouverture, mais elle n’a pas tout le volume, mais seulement une partie de celui-ci, les lots (0,3 sont ouverts et 0,2 sont fermés). Comment gérer une telle situation? Si chaque trade est clôturé avec le même volume, la situation peut être considérée comme l’ouverture de plusieurs trades avec une seule transaction. Ainsi, ils auront les mêmes points d’ouverture et différents points de clôture (il est clair que le volume de chaque trade est déterminé par le volume de clôture). Par exemple, nous choisissons la transaction[ 0 ] pour traitement, ouvrons la transaction :
trade[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00
Ensuite, nous sélectionnons la transaction [ 1 ], fermons le trade ouvert, et pendant la clôture, nous découvrons que le volume de clôture n’est pas suffisant. Faites une copie du trade précédemment ouvert et spécifiez le manque de volume dans son paramètre « volume ». Après cette clôture, le trade initial avec le volume de transaction (c’est-à-dire que nous modifions le volume du trade initial spécifié à l’ouverture avec le volume de clôture):
trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00
Une telle transformation peut sembler ne pas convenir à un trader, car le trader peut vouloir fermer un autre trader, pas celui-ci. Mais quoi qu’il en soit, l’évaluation des systèmes ne sera pas affectée par une transformation correcte. La seule chose qui peut être affectée est la confiance du trader dans le trading sans perte en trades dans MetaTrader 4 ; ce système de recalcul révélera toutes les illusions.
Le système d’interprétation statistique décrit dans le livre de Bulachev n’a pas d’émotions et permet d’évaluer honnêtement les décisions à partir de la position d’entrée, de sortie et des deux taux au total. Et la possibilité de transformation de l’interprétation (l’une en l’autre sans perte de données) prouve qu’il est faux de dire qu’un MTS développé pour MetaTrader 4 ne peut pas être remodelé pour le système d’interprétation de MetaTrader 5. La seule perte lors de la transformation de l’interprétation peut être l’appartenance du volume à différents ordres (MetaTrader 4). Mais en fait, s’il n’y a plus d’ordres (dans l’ancien sens de ce terme) à manipuler, alors c’est juste l’estimation subjective d’un trader.
Code pour la transformation de l’interprétation
Jetons un coup d’œil au code lui-même. Pour préparer un traducteur, nous avons besoin de la fonction inheritance de la POO. C’est pourquoi je suggère à ceux qui ne la connaissent bien, d’ouvrir le MQL5 User Guide pour apprendre la théorie. Tout d’abord, décrivons une structure d’interprétation d’une transaction (nous pourrions accélérer le code en obtenant ces valeurs directement à l’aide des fonctions standard de MQL5, mais c’est moins lisible et peut vous causer de la confusion).
//+------------------------------------------------------------------+ //| structure of deal | //+------------------------------------------------------------------+ struct S_Stat_Deals { public: ulong DTicket; // ticket of deal ENUM_DEAL_TYPE deals_type; // type of deal ENUM_DEAL_ENTRY deals_entry; // direction of deal double deals_volume; // volume of deal double deals_price; // price of opening of deal datetime deals_date; // time of opening of deal S_Stat_Deals(){}; ~S_Stat_Deals(){}; };
Cette structure contient tous les détails principaux sur une transaction, les détails dérivés ne sont pas inclus car nous pouvons les calculer si nécessaire. Étant donné que les développeurs ont déjà implémenté de nombreuses méthodes de statistiques de Bulachev dans le testeur de stratégie, il ne nous reste plus qu’à le compléter avec des méthodes personnalisées. Mettons donc en œuvre des méthodes telles que l’efficacité d’un trade dans son ensemble et l’efficacité d’ouverture et de fermeture.
Et pour obtenir ces valeurs, nous devons mettre en œuvre l’interprétation des informations primaires telles que prix open/close, temps open/close, prix minimum/maximum pendant une transaction. Si nous avons de telles informations primaires, nous pouvons obtenir beaucoup d’informations dérivées. Aussi, je veux attirer votre attention sur la structure du trade décrit ci-dessous, c’est la structure principale, toutes les transformations de l’interprétation sont basées sur elle.
//+------------------------------------------------------------------+ //| structure of trade | //+------------------------------------------------------------------+ struct S_Stat_Trades { public: ulong OTicket; // ticket of opening deal ulong CTicket; // ticket of closing deal ENUM_DEAL_TYPE trade_type; // type of trade double trade_volume; // volume of trade double max_price_trade; // maximum price of trade double min_price_trade; // minimum price of trade double enter_price; // price of opening of trade datetime enter_date; // time of opening of trade double exit_price; // price of closing of trade/s22> datetime exit_date; // time of closing of trade double enter_efficiency;// effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency;// effectiveness of trade S_Stat_Trades(){}; ~S_Stat_Trades(){}; };
Maintenant, comme nous avons créé deux structures principales, nous pouvons définir la nouvelle classe C_Pos, qui transforme l’interprétation. Tout d’abord, déclarons les indications sur les structures d’interprétation des transactions et des trades. Puisque l’information peut être nécessaire dans les fonctions héritées, déclarez-la comme publique; et comme il peut y avoir beaucoup de transactions et de trades, utilisez un tableau comme pointeur sur la structure au lieu d’une variable. Ainsi, l’information sera structurée et disponible de n’importe quel endroit.
Ensuite, nous devons diviser l’historique en positions distinctes et effectuer toutes les transformations à l’intérieur d’une position comme dans un cycle de trading complet. Pour ce faire, déclarez les variables d’interprétation des attributs de position(id de position, symboles de position, nombre de transactions, nombre de trades).
//+------------------------------------------------------------------+ //| class for transforming deals into trades | //+------------------------------------------------------------------+ class C_Pos { public: S_Stat_Deals m_deals_stats[]; // structure of deals S_Stat_Trades m_trades_stats[]; // structure of trades long pos_id; // id of position string symbol; // symbol of position int count_deals; // number of deals int count_trades; // number of trades int trades_ends; // number of closed trades int DIGITS; // accuracy of minimum volume by the symbols of position C_Pos() { count_deals=0; count_trades=0; trades_ends=0; }; ~C_Pos(){}; void OnHistory(); // creation of history of position void OnHistoryTransform();// transformation of position history into the new system of interpretation void efficiency(); // calculation of effectiveness by Bulachev's method private: void open_pos(int c); void copy_pos(int x); void close_pos(int i,int c); double nd(double v){return(NormalizeDouble(v,DIGITS));};// normalization to minimum volume void DigitMinLots(); // accuracy of minimum volume double iHighest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); double iLowest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); };
La classe a trois méthodes publiques qui traitent les positions.
OnHistory() crée l’historique des positions ://+------------------------------------------------------------------+ //| filling the structures of history deals | //+------------------------------------------------------------------+ void C_Pos::OnHistory() { ArrayResize(m_deals_stats,count_deals); for(int i=0;i<count_deals;i++) { m_deals_stats[i].DTicket=HistoryDealGetTicket(i); m_deals_stats[i].deals_type=(ENUM_DEAL_TYPE)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TYPE); // type of deal m_deals_stats[i].deals_entry=(ENUM_DEAL_ENTRY)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_ENTRY);// direction of deal m_deals_stats[i].deals_volume=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_VOLUME); // volume of deal m_deals_stats[i].deals_price=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_PRICE); // price of opening m_deals_stats[i].deals_date=(datetime)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TIME); // time of opening } };
Pour chaque transaction, la méthode crée une copie de la structure et la remplit avec les informations sur le trade. C’est exactement ce que je voulais dire en disant plus haut que nous pouvons nous en passer, mais c’est plus pratique avec cela (ceux qui poursuivent les microsecondes de raccourcissement du temps peuvent remplacer l’appel de ces structures par la ligne qui se trouve à droite du signe d’égalité).
OnHistoryTransform() transforme l’historique des positions en un nouveau système d’interprétation :
- J’ai déjà décrit comment l’information devrait être transformée, considérons maintenant un exemple de cela. Pour la transformation, nous avons besoin d’une valeur précise de laquelle nous devrions calculer le volume d’une transaction (volume min.) ; DigitMinLots() s’en occupe ; toutefois, si un programmeur est sûr que ce code ne sera pas exécuté dans d’autres conditions, ce paramètre peut être spécifié dans le constructeur et la fonction peut être ignorée.
- Ensuite, remettez à zéro les compteurs count_trades et trades_ends. Après cela, ré-allouez la mémoire à la structure d’interprétation de trades. Comme nous ne connaissons pas avec certitude le nombre exact de transactions, nous devrions ré-allouer la mémoire en fonction du nombre de transactions en cours. S’il apparaît en outre qu’il y a plus de trades, alors nous ré-allouerons la mémoire plusieurs fois à nouveau; mais en même temps, la plupart des trades auront suffisamment de mémoire, et l’allocation de mémoire pour le tableau entier permet à notre machine d’économiser du temps de manière significative.
Je recommande d’utiliser cette méthode partout si nécessaire; allouez la mémoire chaque fois qu’un nouvel objet d’interprétation apparaît. S’il n’y a pas d’informations précises sur la quantité de mémoire requise, nous devons l’allouer à une valeur approximative. Dans tous les cas, c’est plus économique que de ré-allouer l’ensemble du tableau à chaque étape.
Vient ensuite la boucle où toutes les transactions d’une position sont filtrées à l’aide de trois filtres : si la transaction est in, in/out, out. Des actions spécifiques sont implémentées pour chaque variante. Les filtres sont séquentiels, et ils s'emboîtent. En d’autres termes, si un filtre renvoie false, alors seulement dans ce cas, nous vérifions le filtre suivant. Une telle construction est économique en ressources, car les actions inutiles sont éliminées. Pour rendre le code plus lisible, de nombreuses actions sont effectuées sur les fonctions déclarées dans la classe comme privées. Soit dit en passant, ces fonctions étaient publiques pendant le développement, mais en outre, je me suis rendu compte qu’elles n’étaient pas nécessaires dans les autres parties du code, elles ont donc été re-déclarées comme des fonctions privées. C’est ainsi qu’il est facile de manipuler la portée des données dans la POO.
Ainsi, dans le filtre in , la création d’un nouveau trade s’effectue (la fonction open_pos()), c'est pourquoi nous augmentons la taille du tableau de pointeurs par un et copions la structure transactionnelle dans les champs correspondants de la structure du trade. En outre, étant donné que la structure de trade a deux fois plus de champs prix et temps, seuls les champs d’ouverture sont remplis lorsqu’un trade est ouvert, de sorte que c’est pris en compte comme inachevé ; vous pouvez le comprendre par la différence de count_trades et trades_ends. Le problème est dans les compteurs qui ont des valeurs nulles au début. Dès qu’un trade apparaît, le compteur count_trades monte et, lorsque le trade est clos, le compteur trades_ends monte. Ainsi, la différence entrecount_trades et trades_ends peut vous indiquer à tout moment combien de trades ne sont pas clos .
La fonction open_pos() est assez simple, elle n’ouvre que les trades et déclenche le compteur correspondant ; d’autres fonctions similaires ne sont pas si simples. Donc, si une transaction n’est pas du type in, alors elle peut être soit in/out ou out. À partir de deux variantes, tout d’abord, vérifiez celle qui est exécutée plus facilement (ce n’est pas un problème fondamental, mais j’ai construit la vérification dans l’ordre de difficulté croissante d’exécution).
La fonction qui traite le filtre in/out additionne les positions ouvertes par toutes les transactions non fermées (j’ai déjà mentionné comment savoir quelles transactions ne sont pas fermées en utilisant la différence entre count_trades et trades_ends). Ainsi, nous calculons le volume total qui est clôturé par la transaction donnée (et le reste du volume sera rouvert mais avec le type de la transaction en cours). Ici, nous devons noter que la transaction a la direction in/out, ce qui signifie que son volume dépasse le volume total de la position précédemment ouverte. C’est pourquoi il est logique de calculer la différence entre la position et la transaction in/out pour connaître le volume de la nouvelle transaction à rouvrir.
Si une transaction a la direction out, alors tout est encore plus compliqué. Tout d’abord, la dernière transaction dans une position a toujours la direction out, donc ici nous devrions faire une exception - s’il s’agit de la dernière transaction, fermez tout ce que nous avons. Sinon (si la transaction n’est pas la dernière), deux variantes sont possibles. Puisque la transaction n’est pas in/out, mais out, alors les variantes sont : la première variante est le volume qui est exactement le même que celui d’ouverture, c’est-à-dire que le volume de l’opération d’ouverture est égal au volume de la transaction de clôture ; la deuxième variante est que ces volumes ne sont pas les mêmes.
La première variante est traitée en clôturant le deal. La deuxième variante est plus compliquée, deux variantes sont à nouveau possibles : lorsque le volume est supérieur et lorsque le volume est inférieur à celui de l’ouverture. Lorsque le volume est plus élevé, clôturez le trade suivant jusqu’à ce que le volume de clôture devienne égal ou inférieur au volume d’ouverture. Si le volume n’est pas suffisant pour clôturer l’ensemble du prochain trade (il y a moins de volume), il s’agit de la clôture partielle. Ici, nous devons clôturer le trade avec le nouveau volume (celui qui reste après les opérations précédentes), mais avant cela, faites une copie de trade avec le volume manquant. Et bien sûr, n’oubliez pas les compteurs.
Dans le trading, il peut y avoir une situation où il y a déjà une file d’attente de trades ultérieurs à la fermeture partielle après la réouverture d’un trade. Pour éviter toute confusion, tous devraient être décalés d’un trade, dans le souci de conserver la chronologie de la clôture.
//+------------------------------------------------------------------+ //| transformation of deals into trades (engine classes) | //+------------------------------------------------------------------+ void C_Pos::OnHistoryTransform() { DigitMinLots();// fill the DIGITS value count_trades=0;trades_ends=0; ArrayResize(m_trades_stats,count_trades,count_deals); for(int c=0;c<count_deals;c++) { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_IN) { open_pos(c); } else// else in { double POS=0; for(int i=trades_ends;i<count_trades;i++)POS+=m_trades_stats[i].trade_volume; if(m_deals_stats[c].deals_entry==DEAL_ENTRY_INOUT) { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades; open_pos(c); m_trades_stats[count_trades-1].trade_volume=m_deals_stats[c].deals_volume-POS; } else// else in/out { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_OUT) { if(c==count_deals-1)// if it's the last deal { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades-1; } else// if it's not the last deal { double out_vol=nd(m_deals_stats[c].deals_volume); while(nd(out_vol)>0) { if(nd(out_vol)>=nd(m_trades_stats[trades_ends].trade_volume)) { close_pos(trades_ends,c); out_vol-=nd(m_trades_stats[trades_ends].trade_volume); trades_ends++; } else// if the remainder of closed position is less than the next trade { // move all trades forward by one count_trades++; ArrayResize(m_trades_stats,count_trades); for(int x=count_trades-1;x>trades_ends;x--)copy_pos(x); // open a copy with the volume equal to difference of the current position and the remainder m_trades_stats[trades_ends+1].trade_volume=nd(m_trades_stats[trades_ends].trade_volume-out_vol); // close the current trade with new volume, which is equal to remainder close_pos(trades_ends,c); m_trades_stats[trades_ends].trade_volume=nd(out_vol); out_vol=0; trades_ends++; } }// while(out_vol>0) }// if it's not the last deal }// if out }// else in/out }// else in } };
Calcul d’efficacité
Une fois le système d’interprétation transformé, nous pouvons évaluer l’efficacité des trades par la méthodologie de Bulachev. Les fonctions nécessaires à une telle évaluation sont dans la méthode efficiency(), le remplissage de la structure de trade avec les données calculées y est également effectué. L’efficacité de l’entrée et de la sortie est mesurée de 0 à 1, et pour l’ensemble de trade, elle est mesurée de -3 à 1.
//+------------------------------------------------------------------+ //| calculation of effectiveness | //+------------------------------------------------------------------+ void C_Pos::efficiency() { for(int i=0;i<count_trades;i++) { m_trades_stats[i].max_price_trade=iHighest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // maximal price of trade m_trades_stats[i].min_price_trade=iLowest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // minimal price of trade double minimax=0; minimax=m_trades_stats[i].max_price_trade-m_trades_stats[i].min_price_trade;// difference between maximum and minimum if(minimax!=0)minimax=1.0/minimax; if(m_trades_stats[i].trade_type==DEAL_TYPE_BUY) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].enter_price)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].enter_price)*minimax; } else { if(m_trades_stats[i].trade_type==DEAL_TYPE_SELL) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].exit_price)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].exit_price)*minimax; } } } }
La méthode utilise deux méthodes privées iHighest() et iLowest(), elles sont similaires et la seule différence réside sur les données demandées et la fonction de recherche fmin ou fmax.
//+------------------------------------------------------------------+ //| searching maximum within the period start_time --> stop_time | //+------------------------------------------------------------------+ double C_Pos::iHighest(string symbol_name,// symbols name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ) { double buf[]; datetime start_t=(start_time/60)*60;// normalization of time of opening datetime stop_t=(stop_time/60+1)*60;// normaliztion of time of closing int period=CopyHigh(symbol_name,timeframe,start_t,stop_t,buf); double res=buf[0]; for(int i=1;i<period;i++) res=fmax(res,buf[i]); return(res); }
La méthode recherche le maximum dans la période entre deux dates spécifiées. Les dates sont transmises à la fonction commestart_time et stop_time. Étant donné que les dates des trades sont transmises à la fonction et qu’une demande de trade peut survenir même au milieu de la barre de 1 minute, la normalisation de la date à la valeur la plus proche de la barre est effectuée à l’intérieur de la fonction. La même chose est faite dans la fonction iLowest(). Avec la méthode efficiency() développée, nous disposons de toute la fonctionnalité pour travailler avec une position ; mais sans le traitement de la position elle-même. Dépassons cela en déterminant une nouvelle classe, à laquelle toutes les méthodes précédentes seront disponibles ; en d’autres termes, déclarez-le comme un dérivé de C_Pos.
Classe dérivée (classes de moteurs)
class C_PosStat:public C_Pos
Pour considérer les informations statistiques, créez une structure qui sera attribuée à la nouvelle classe.
//+------------------------------------------------------------------+ //| structure of effectiveness | //+------------------------------------------------------------------+ struct S_efficiency { double enter_efficiency; // effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency; // effectiveness of trade S_efficiency() { enter_efficiency=0; exit_efficiency=0; trade_efficiency=0; }; ~S_efficiency(){}; };
Et le corps de la classe elle-même :
//+------------------------------------------------------------------+ //| class of statistics of trade in whole | //+------------------------------------------------------------------+ class C_PosStat:public C_Pos { public: int PosTotal; // number of positions in history C_Pos pos[]; // array of pointers to positions int All_count_trades; // total number of trades in history S_efficiency trade[]; // array of pointers to the structure of effectiveness of entering, exiting and trades S_efficiency avg; // pointer to the structure of average value of effectiveness of entering, exiting and trades S_efficiency stdev; // pointer to the structure of standard deviation from // average value of effectiveness of entering, exiting and trades C_PosStat(){PosTotal=0;}; ~C_PosStat(){}; void OnPosStat(); // engine classes void OnTradesStat(); // gathering information about trades into the common array // functions of writing information to a file void WriteFileDeals(string folder="deals"); void WriteFileTrades(string folder="trades"); void WriteFileTrades_all(string folder="trades_all"); void WriteFileDealsHTML(string folder="deals"); void WriteFileDealsHTML2(string folder="deals"); void WriteFileTradesHTML(string folder="trades"); void WriteFileTradesHTML2(string folder="trades"); string enum_translit(ENUM_DEAL_ENTRY x,bool latin=true);// transformation of enumeration into string string enum_translit(ENUM_DEAL_TYPE x,bool latin=true); // transformation of enumeration into string (overloaded) private: S_efficiency AVG(int count); // arithmetical mean S_efficiency STDEV(const S_efficiency &mo,int count); // standard deviation S_efficiency add(const S_efficiency &a,const S_efficiency &b); //add S_efficiency take(const S_efficiency &a,const S_efficiency &b); //subtract S_efficiency multiply(const S_efficiency &a,const S_efficiency &b); //multiply S_efficiency divided(const S_efficiency &a,double b); //divide S_efficiency square_root(const S_efficiency &a); //square root string Head_style(string title); };
Je suggère d’analyser cette classe dans le sens inverse, de la fin au début. Tout se termine par l’écriture d’un tableau des transactions et des trades dans des fichiers. Une plage de fonctions est écrite à cet effet (vous pouvez comprendre le but de l’un et de l’autre à partir du nom). Les fonctions font un rapport csv sur les transactions et les trades ainsi que des rapports html de deux types (ils ne diffèrent que visuellement, mais ont le même contenu).
void WriteFileDeals(); // writing csv report on deals void WriteFileTrades(); // writing csv report on trade void WriteFileTrades_all(); // writing summary csv report of fitness functions void WriteFileDealsHTML2(); // writing html report on deals, 1 variant void WriteFileTradesHTML2();// writing html report on trades, 2 variant
Les enum_translit() sont destinées à transformer les valeurs des énumérations en type de chaîne pour les écrire dans un fichier journal. La section privée contient plusieurs fonctions de la structure S_efficiency. Toutes les fonctions constituent les inconvénients du langage, notamment les opérations arithmétiques avec des structures. Étant donné que les opinions sur la mise en œuvre de ces méthodes varient, elles peuvent être réalisées de différentes manières. Je les ai réalisées comme des méthodes d’opérations arithmétiques avec les champs des structures. Quelqu’un peut argumenter qu’il est préférable de traiter chaque champ de structure en utilisant une méthode individuelle. En résumé, je dirais qu’il y a autant d’opinions que les programmeurs. J’espère qu’à l’avenir, nous aurons la possibilité d’effectuer de telles opérations en utilisant des méthodes intégrées.
La méthode AVG() calcule la valeur moyenne arithmétique du tableau passé, mais elle ne montre pas l’image complète de la distribution, c’est pourquoi elle est fournie avec une autre méthode qui calcule l’écart type STDEV(). La fonction OnTradesStat() obtient les valeurs d’efficacité (précédemment calculées dans OnPosStat()) et les traite avec des méthodes statistiques. Et enfin, la fonction principale de la classe - OnPosStat().
Cette fonction doit être examinée en détail. Elle se compose de deux parties, de sorte qu’elle peut être facilement divisée. La première partie recherche toutes les positions et traite leur ID en l’enregistrant dans le tableau temporaire id_pos. Étape par étape : sélectionnez l’ensemble de l’historique disponible, calculez le nombre de transactions, exécutez le cycle de traitement des transactions. Le cycle : si le type de transaction est balans, sautez-le (il n’est pas nécessaire d’interpréter la transaction de départ), sinon - enregistrez id de position dans la variable et effectuez la recherche. Si le même ID existe déjà dans la base (le tableau id_pos), passez au trade suivant, sinon écrivez id dans la base. De cette manière, après avoir traité toutes les transactions, nous avons le tableau rempli de tous les IDexistants de positions et du nombre de positions.
long id_pos[];// auxiliary array for creating the history of positions if(HistorySelect(0,TimeCurrent())) { int HTD=HistoryDealsTotal(); ArrayResize(id_pos,PosTotal,HTD); for(int i=0;i<HTD;i++) { ulong DTicket=(ulong)HistoryDealGetTicket(i); if((ENUM_DEAL_TYPE)HistoryDealGetInteger(DTicket,DEAL_TYPE)==DEAL_TYPE_BALANCE) continue;// if it's a balance deal, skip it long id=HistoryDealGetInteger(DTicket,DEAL_POSITION_ID); bool present=false; // initial state, there's no such position for(int j=0;j<PosTotal;j++) { if(id==id_pos[j]){ present=true; break; } }// if such position already exists break if(!present)// write id as a new position appears { PosTotal++; ArrayResize(id_pos,PosTotal); id_pos[PosTotal-1]=id; } } } ArrayResize(pos,PosTotal);
Dans la deuxième partie, nous réalisons toutes les méthodes décrites dans la classe de base C_Pos précédemment. Cela consiste en un cycle qui passe en revue les positions et exécute les méthodes correspondantes de traitement des positions. La description de la méthode est donnée dans le code ci-dessous.
for(int p=0;p<PosTotal;p++) { if(HistorySelectByPosition(id_pos[p]))// select position { pos[p].pos_id=id_pos[p]; // assigned id of position to the corresponding field of the class C_Pos pos[p].count_deals=HistoryDealsTotal();// assign the number of deal in position to the field of the class C_Pos pos[p].symbol=HistoryDealGetString(HistoryDealGetTicket(0),DEAL_SYMBOL);// the same actions with symbol pos[p].OnHistory(); // start filling the structure sd with the history of position pos[p].OnHistoryTransform(); // transformation of interpretation, filling the structure st. pos[p].efficiency(); // calculation of the effectiveness of obtained data All_count_trades+=pos[p].count_trades;// save the number of trades for displaying the total number } }
Méthodes d’appel de la classe
Donc, nous avons considéré toute la classe. Il reste à donner un exemple d’appel. Pour conserver les possibilités de construction, je n’ai pas déclaré l’appel explicitement dans une fonction. En outre, vous pouvez améliorer la classe pour vos besoins, mettre en œuvre de nouvelles méthodes de traitement statistique des données. Voici un exemple d’appel de la méthode de la classe à partir d’un script :
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ #include <Bulaschev_Statistic.mqh> void OnStart() { C_PosStat start; start.OnPosStat(); start.OnTradesStat(); start.WriteFileDeals(); start.WriteFileTrades(); start.WriteFileTrades_all(); start.WriteFileDealsHTML2(); start.WriteFileTradesHTML2(); Print("cko tr ef=" ,start.stdev.trade_efficiency); Print("mo tr ef=" ,start.avg.trade_efficiency); Print("cko out ef=",start.stdev.exit_efficiency); Print("mo out ef=",start.avg.exit_efficiency); Print("cko in ef=" ,start.stdev.enter_efficiency); Print("mo in ef=" ,start.avg.enter_efficiency); }
Le script crée 5 fichiers de rapport en fonction de la quantité de fonctions qui écrivent des données dans le fichier sous le répertoire Files\OnHistory. Les fonctions principales suivantes sont présentes ici - OnPosStat() et OnTradesStat(), elles sont utilisées pour appeler toutes les méthodes nécessaires. Le script se termine par l’impression de la valeur obtenue de l’efficacité du trading dans son ensemble. Chacune de ces valeurs peut être utilisée pour l’optimisation génétique.
Comme il n’est pas nécessaire d’écrire chaque rapport dans un fichier pendant l’optimisation, l’appel de la classe dans un Expert Advisor est un peu différent. Tout d’abord, contrairement à un script, un Expert Advisor peut être exécuté dans le testeur (c’est ce à quoi nous le préparons). Le travail dans le testeur de stratégie a ses particularités. Lors de l’optimisation, nous avons accès à la fonction OnTester(), à savoir que son exécution est effectuée avant l’exécution de la fonction OnDeinit(). Ainsi, l’appel des principales méthodes de transformation peut être séparé. Pour l’aisance de la modification de la fonction fitness à partir des paramètres d’un Expert Advisor, j’ai déclaré une énumération globalement, non pas comme une partie intégrante de la classe. Cette énumération se trouve sur la même fiche que les méthodes de la classe C_PosStat.
//+------------------------------------------------------------------+ //| enumeration of fitness functions | //+------------------------------------------------------------------+ enum Enum_Efficiency { avg_enter_eff, stdev_enter_eff, avg_exit_eff, stdev_exit_eff, avg_trade_eff, stdev_trade_eff };
C’est ce qu’il convient d’ajouter à l’en-tête de l’Expert Advisor.
#include <Bulaschev_Statistic.mqh> input Enum_Efficiency result=0;// Fitness function
Maintenant, nous pouvons simplement décrire le passage du paramètre nécessaire à l’aide de l’opérateur de commutation.
//+------------------------------------------------------------------+ //| Expert optimization function | //+------------------------------------------------------------------+ double OnTester() { start.OnPosStat(); start.OnTradesStat(); double res; switch(result) { case 0: res=start.avg.enter_efficiency; break; case 1: res=-start.stdev.enter_efficiency; break; case 2: res=start.avg.exit_efficiency; break; case 3: res=-start.stdev.exit_efficiency; break; case 4: res=start.avg.trade_efficiency; break; case 5: res=-start.stdev.trade_efficiency; break; default : res=0; break; } return(res); }
Je tiens à attirer votre attention sur le fait que la fonction OnTester() est utilisée pour maximiser la fonction personnalisée. Si vous devez trouver le minimum de la fonction personnalisée, il est préférable d’inverser la fonction elle-même en la multipliant par -1. Comme dans l’exemple avec l’écart-type, tout le monde comprend que plus le stdev est petit, plus la différence entre l’efficacité des trades est petite, donc la stabilité des trades est plus élevée. C’est pourquoi stdev doit être minimisé. Maintenant, comme nous avons traité de l’appel de la méthode de classe, envisageons d’écrire les rapports dans un fichier.
Précédemment, j’ai mentionné les méthodes de classe qui créent le rapport. Maintenant, nous allons voir où et quand ils devraient être appelés. Les rapports ne doivent être créés que lorsque l’Expert Advisor est lancé pour une seule exécution. Sinon, l’Expert Advisor créera les fichiers en mode optimisation ; c’est-à-dire qu’au lieu d’un fichier, il créera beaucoup de fichiers (si des noms de fichiers différents sont transmis à chaque fois) ou un, mais le dernier avec le même nom pour toutes les exécutions, ce qui n’a absolument aucun sens, car cela serait un gaspillage de ressources pour les informations qui seront par la suite effacées.
Quoi qu’il en soit, vous ne devez pas créer de fichiers de rapport pendant l’optimisation. Si vous obtenez beaucoup de fichiers avec des noms différents, vous n’ouvrirez probablement pas la plupart d’entre eux. La deuxième variante a un gaspillage de ressources pour obtenir les informations qui sont supprimées immédiatement.
C’est pourquoi la meilleure variante est de faire un filtre (démarrez le rapport uniquement en mode Optimisation[désactivé]). Ainsi, le disque dur ne sera pas jonché de rapports qui ne sont jamais vus. De plus, la vitesse d’optimisation augmente (ce n’est pas un secret que les opérations les plus lentes sont les opérations de fichier) ; de plus, la possibilité d’obtenir rapidement un rapport avec les paramètres nécessaires est conservée. En fait, peu importe où placer le filtre, que ce soit dans le OnTester ou dans la fonction OnDeinit. L’important est que les méthodes de classe, qui créent le rapport, doivent être appelées après les principales méthodes qui effectuent la transformation. J’ai placé le filtre sur OnDeinit() pour ne pas surcharger le code :
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(!(bool)MQL5InfoInteger(MQL5_OPTIMIZATION)) { start.WriteFileDeals(); // writing csv report on deals start.WriteFileTrades(); // writing csv report on trades start.WriteFileTrades_all(); // writing summary csv report on fitness functions start.WriteFileDealsHTML2(); // writing html report on deals start.WriteFileTradesHTML2();// writing html report on trades } } //+------------------------------------------------------------------+
La séquence d’appel des méthodes n’est pas importante. Tout ce qui est nécessaire pour créer les rapports est préparé dans les méthodes OnPosStat et OnTradesStat. En outre, peu importe si vous appelez toutes les méthodes de rédaction de rapports ou seulement certaines d’entre elles ; le fonctionnement de chacun d’eux est individuel ; c’est une interprétation des informations qui sont déjà stockées dans la classe.
Vérification dans le testeur de stratégie
Le résultat d’une seule exécution dans le testeur de stratégie est donné ci-dessous :
Statistiques sur les moyennes mobiles des trades | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # | Ticket | type | volume | Ouvrir | Fermer | Prix | Efficacité | ||||||
| Ouvrir | Fermer | prix | temps | prix | temps | max | min | Entrer | sortie | trade | |||
| pos[0] | id 2 | EURUSD | |||||||||||
| 0 | 2 | 3 | buy | 0,1 | 1,37203 | 2010.03.15 13:00:00 | 1,37169 | 2010.03.15 14:00:00 | 1,37236 | 1,37063 | 0,19075 | 0,61272 | -,19653 |
| pos[1] | ID | EURUSD | |||||||||||
| 1 | 4 | 5 | sell | 0,1 | 1,35188 | 2010.03.23 08:00:00 | 1,35243 | 2010.03.23 10:00:00 | 1,35292 | 1,35025 | 0,61049 | 0,18352 | -0,20599 |
| pos[2] | id 6 | EURUSD | |||||||||||
| 2 | 6 | 7 | sell | 0,1 | 1,35050 | 2010.03.23 12:00:00 | 1,35343 | 2010.03.23 16:00:00 | 1,35600 | 1,34755 | 0,34911 | 0,30414 | -0,34675 |
| pos[3] | id 8 | EURUSD | |||||||||||
| 3 | 8 | 9 | sell | 0,1 | 1,35167 | 2010.03.23 18:00:00 | 1,33343 | 2010.03.26 05:00:00 | 1,35240 | 1,32671 | 0,97158 | 0,73842 | 0,71000 |
| pos[4] | ID | EURUSD | |||||||||||
| 4 | 10 | 11 | sell | 0,1 | 1,34436 | 2010.03.30 16:00:00 | 1,33616 | 2010.04.08 23:00:00 | 1,35904 | 1,32821 | 0,52384 | 0,74213 | 0,26597 |
| pos[5] | ID | EURUSD | |||||||||||
| 5 | 12 | 13 | buy | 0,1 | 1,35881 | 2010.04.13 08:00:00 | 1,35936 | 2010.04.15 10:00:00 | 1,36780 | 1,35463 | 0,68261 | 0,35915 | 0,04176 |
| pos[6] | id 14 | EURUSD | |||||||||||
| 6 | 14 | 15 | sell | 0,1 | 1,34735 | 2010.04.20 04:00:00 | 1,34807 | 2010.04.20 10:00:00 | 1,34890 | 1,34492 | 0,61055 | 0,20854 | -0,18090 |
| pos[7] | ID | EURUSD | |||||||||||
| 7 | 16 | 17 | sell | 0,1 | 1,34432 | 2010.04.20 18:00:00 | 1,33619 | 2010.04.23 17:00:00 | 1,34491 | 1,32016 | 0,97616 | 0,35232 | 0,32848 |
| pos[8] | id 18 | EURUSD | |||||||||||
| 8 | 18 | 19 | sell | 0,1 | 1,33472 | 2010.04.27 10:00:00 | 1,32174 | 2010.04.29 05:00:00 | 1,33677 | 1,31141 | 0,91916 | 0,59267 | 0,51183 |
| pos[9] | ID | EURUSD | |||||||||||
| 9 | 20 | 21 | sell | 0,1 | 1,32237 | 2010.05.03 04:00:00 | 1,27336 | 2010.05.07 20:00:00 | 1,32525 | 1,25270 | 0,96030 | 0,71523 | 0,67553 |
Rapport d’efficacité | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fitness Func | Valeur moyenne | Écart Standard | |||||||||||
| Entrer | 0,68 | 0,26 | |||||||||||
| Sortie | 0,48 | 0,21 | |||||||||||
| Trades | 0,16 | 0,37 | |||||||||||
Et le graphique d’équilibre est :
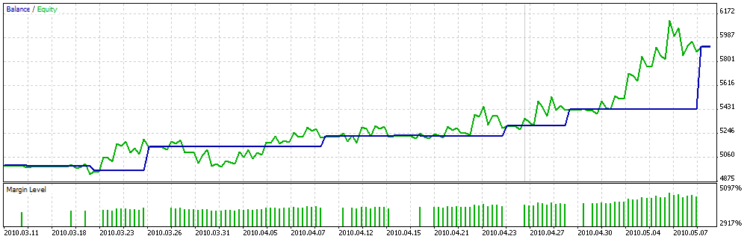
Vous pouvez clairement voir sur le graphique que la fonction personnalisée d’optimisation n’essaie pas de choisir les paramètres avec le plus grand nombre de transactions, mais les transactions de longue durée, à savoir que les transactions ont presque le même profit, c’est-à-dire que la dispersion n’est pas élevée.
Étant donné que le code des moyennes mobiles ne contient pas les caractéristiques d’augmentation du volume de position ou de fermeture partielle de celui-ci, le résultat de la transformation ne semble pas être proche de celui décrit ci-dessus. Ci-dessous, vous pouvez trouver un autre résultat du lancement du script sur le compte ouvert spécialement pour tester les codes :
| pos+=286; | id 1019514 | EURUSD | |||||||||||
| 944 | 1092288 | 1092289 | buy | 0,1 | 1,26733 | 2010.07.08 21:14:49 | 1,26719 | 2010.07.08 21:14:57 | 1,26752 | 1,26703 | 0,38776 | 0,32653 | -0,28571 |
| pos+=287; | id 1019544 | EURUSD | |||||||||||
| 945 | 1092317 | 1092322 | sell | 0,2 | 1,26761 | 2010.07.08 21:21:14 | 1,26767 | 2010.07.08 21:22:29 | 1,26781 | 1,26749 | 0,37500 | 0,43750 | -0,18750 |
| 946 | 1092317 | 1092330 | sell | 0,2 | 1,26761 | 2010.07.08 21:21:14 | 1,26792 | 2010.07.08 21:24:05 | 1,26782 | 1,26749 | 0,36364 | -0,30303 | -0,93939 |
| 947 | 1092319 | 1092330 | sell | 0,3 | 1,26761 | 2010.07.08 21:21:37 | 1,26792 | 2010.07.08 21:24:05 | 1,26782 | 1,26749 | 0,36364 | -0,30303 | -0,93939 |
| pos+=288; | id 1019623 | EURUSD | |||||||||||
| 948 | 1092394 | 1092406 | buy | 0,1 | 1,26832 | 2010.07.08 21:36:43 | 1,26843 | 2010.07.08 21:37:38 | 1,26882 | 1,26813 | 0,72464 | 0,43478 | 0,15942 |
| pos+=289; | id 1019641 | EURUSD | |||||||||||
| 949 | 1092413 | 1092417 | buy | 0,1 | 1,26847 | 2010.07.08 21:38:19 | 1,26852 | 2010.07.08 21:38:51 | 1,26910 | 1,26829 | 0,77778 | 0,28395 | 0,06173 |
| 950 | 1092417 | 1092433 | sell | 0,1 | 1,26852 | 2010.07.08 21:38:51 | 1,26922 | 2010.07.08 21:39:58 | 1,26916 | 1,26829 | 0,26437 | -0,06897 | -0,80460 |
| pos+=290; | id 1150923 | EURUSD | |||||||||||
| 951 | 1226007 | 1226046 | buy | 0,2 | 1,31653 | 2010.08.05 16:06:20 | 1,31682 | 2010.08.05 16:10:53 | 1,31706 | 1,31611 | 0,55789 | 0,74737 | 0,30526 |
| 952 | 1226024 | 1226046 | buy | 0,3 | 1,31632 | 2010.08.05 16:08:31 | 1,31682 | 2010.08.05 16:10:53 | 1,31706 | 1,31611 | 0,77895 | 0,74737 | 0,52632 |
| 953 | 1226046 | 1226066 | sell | 0,1 | 1,31682 | 2010.08.05 16:10:53 | 1,31756 | 2010.08.05 16:12:49 | 1,31750 | 1,31647 | 0,33981 | -0,05825 | -0,71845 |
| 954 | 1226046 | 1226078 | sell | 0,2 | 1,31682 | 2010.08.05 16:10:53 | 1,31744 | 2010.08.05 16:15:16 | 1,31750 | 1,31647 | 0,33981 | 0,05825 | -0,60194 |
| pos+=291; | id 1155527 | EURUSD | |||||||||||
| 955 | 1230640 | 1232744 | sell | 0,1 | 1,31671 | 2010.08.06 13:52:11 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,31648 | 0,01370 | 0,24062 | -0,74568 |
| 956 | 1231369 | 1232744 | sell | 0,1 | 1,32584 | 2010.08.06 14:54:53 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32518 | 0,08158 | 0,49938 | -0,41904 |
| 957 | 1231455 | 1232744 | sell | 0,1 | 1,32732 | 2010.08.06 14:58:13 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32539 | 0,24492 | 0,51269 | -0,24239 |
| 958 | 1231476 | 1232744 | sell | 0,1 | 1,32685 | 2010.08.06 14:59:47 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32539 | 0,18528 | 0,51269 | -0,30203 |
| 959 | 1231484 | 1232744 | sell | 0,2 | 1,32686 | 2010.08.06 15:00:20 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32539 | 0,18655 | 0,51269 | -0,30076 |
| 960 | 1231926 | 1232744 | sell | 0,4 | 1,33009 | 2010.08.06 15:57:32 | 1,32923 | 2010.08.06 17:39:50 | 1,33327 | 1,32806 | 0,38964 | 0,77543 | 0,16507 |
| 961 | 1232591 | 1232748 | sell | 0,4 | 1,33123 | 2010.08.06 17:11:29 | 1,32850 | 2010.08.06 17:40:40 | 1,33129 | 1,32806 | 0,98142 | 0,86378 | 0,84520 |
| 962 | 1232591 | 1232754 | sell | 0,4 | 1,33123 | 2010.08.06 17:11:29 | 1,32829 | 2010.08.06 17:42:14 | 1,33129 | 1,32796 | 0,98198 | 0,90090 | 0,88288 |
| 963 | 1232591 | 1232757 | sell | 0,2 | 1,33123 | 2010.08.06 17:11:29 | 1,32839 | 2010.08.06 17:43:15 | 1,33129 | 1,32796 | 0,98198 | 0,87087 | 0,85285 |
| pos+=292; | id 1167490 | EURUSD | |||||||||||
| 964 | 1242941 | 1243332 | sell | 0,1 | 1,31001 | 2010.08.10 15:54:51 | 1,30867 | 2010.08.10 17:17:51 | 1,31037 | 1,30742 | 0,87797 | 0,57627 | 0,45424 |
| 965 | 1242944 | 1243333 | sell | 0,1 | 1,30988 | 2010.08.10 15:55:03 | 1,30867 | 2010.08.10 17:17:55 | 1,31037 | 1,30742 | 0,83390 | 0,57627 | 0,41017 |
| pos+=293; | id 1291817 | EURUSD | |||||||||||
| 966 | 1367532 | 1367788 | sell | 0,4 | 1,28904 | 2010.09.06 00:24:01 | 1,28768 | 2010.09.06 02:53:21 | 1,28965 | 1,28710 | 0,76078 | 0,77255 | 0,53333 |
Voilà à quoi ressemble l’information transformée ; pour donner aux lecteurs la possibilité de tout considérer délibérément (et la connaissance vient par comparaison), je sauvegarde l’historique original des transactions dans un fichier séparé ; c’est l’histoire qui manque maintenant à de nombreux traders, qui ont l’habitude de le voir dans la section [Résultats] de MetaTrader 4.
Conclusion
En conclusion, je veux suggérer aux développeurs d’ajouter une possibilité d’optimiser les Expert Advisors non seulement par un paramètre personnalisé, mais de le faire en combinaison avec la norme comme c’est le cas avec les autres fonctions d’optimisation. En résumant cet article, je peux dire qu’il ne contient que les principes fondamentaux, le potentiel initial ; et j’espère que les lecteurs pourront améliorer la classe en fonction de leurs propres besoins. Bonne chance !
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/137
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Expert Advisor basé sur les « Nouvelles dimensions en trading » livre écrit par Bill Williams
Expert Advisor basé sur les « Nouvelles dimensions en trading » livre écrit par Bill Williams
 Plusieurs modes de recherche de tendance dans MQL5
Plusieurs modes de recherche de tendance dans MQL5
 Systèmes de trading adaptatifs et leur utilisation dans le terminal client MetaTrader 5
Systèmes de trading adaptatifs et leur utilisation dans le terminal client MetaTrader 5
 Création d'indicateurs multicolores dans MQL5
Création d'indicateurs multicolores dans MQL5
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Il reste à résoudre le problème de la recherche sur la moyenne d'or.
Je me demande d'où vient cet amour pour la TF ?
Quel est l'attrait pour la quantification de la série initiale {Prix, Temps} par le temps ?
Je me demande d'où vient un tel amour pour la TF ?
Quelle est l'envie de quantifier les séries initiales {Prix, Temps} par le temps ?
Bonjour,
J'essaie d'utiliser votre code depuis des mois. Le problème est qu'il n'écrit que l'en-tête pour le html. Et pour excel il ne sort que "yb" sur la première cellule. J'ai répété votre article plusieurs fois et je n'ai pas pu résoudre ce problème. Je trouve votre article très utile. Pouvez-vous m'aider à résoudre ce problème ? Je suis assez novice en la matière. Votre aide me serait très utile. Je vous remercie de votre aide.
Où puis-je ouvrir le fichier html ? Je n'ai pas vu comment il est généré