
외환 거래에서 포트폴리오 최적화: VaR와 마코위츠 이론의 결합

소개: 외환 시장에서의 포트폴리오 최적화 작업
저는 지난 3년간 외환 거래 로봇 개발에 매진해 왔습니다. 그리고 그거 아세요? 위험 관리는 정말 골칫거리입니다. 처음에 저는 몇 번 계좌를 날릴 때까지 고정된 손절매 주문을 설정했었습니다. 그러다가 더 깊이 파고들기 시작했고 마코위츠의 포트폴리오 최적화 이론을 접하게 되었습니다.
좋아 보였습니다 - 상관관계를 계산하고 가중치를 최적화하는군요... 하지만 현실적으로 외환 거래에는 그다지 효과적이지 않습니다. 왜 그럴까요? 외환 시장에서는 모든 통화쌍이 서로 연관되어 있기 때문입니다! EURUSD와 EURGBP를 동시에 거래해 보시면 제 말이 무슨 뜻인지 아시게 될 겁니다. 유로화의 급격한 변동과 함께 두 포지션이 동조화 됩니다. 아름다운 이론이 냉혹한 현실에 부딪혀 산산조각 났습니다.
진저리가 날 만큼의 시도 끝에 다른 접근법을 찾아보기 시작했습니다. 결국 저는 VaR(Value at Risk) 방법론을 접하게 되었습니다. 처음에는 그게 뭔지도 몰랐어요 - 그저 복잡한 방정식 같은 것으로 보였죠. 그런데 그때 문득 깨달었어요 - 바로 이게 내가 필요했던 거였구나! VaR는 주어진 확률에 대한 최대 손실을 나타냅니다. 다시 말해 하루/주/월 동안 얼마나 손실을 볼 수 있는지 직접적으로 추정할 수 있다는 뜻입니다.
결국 저는 VaR과 마코위츠를 결합하기로 결정했습니다. 말도 안 되는 소리 같죠? 그럴지도요. 하지만 다른 선택지는 보이지 않았습니다. 마코위츠는 최적의 자금 배분 방식을 제시하고 VaR는 마진콜 발생을 방지합니다. 이론상으로는 훌륭해 보였습니다.
그렇게 연구 프로그래머로서의 고된 일상이 시작되었습니다. 파이썬, МetaТrader 5 터미널, 방대한 히스토리 데이터... 쉽지는 않을 거라고 생각했지만 현실은 제 모든 예상을 뛰어넘었습니다. 제가 여러분께 말씀드리려고 하는 것은 단순히 백테스팅에서 보기 좋은 시스템이 아니라 실제로 작동하는 시스템을 어떻게 만들려고 노력했는지에 대한 것입니다.
여러분이 외환 거래 자동화를 시도해 본 적이 있으시다면 제 고충을 이해하실 겁니다. 그렇지 않더라도 제 경험이 여러분이 겪을 수 있는 어려움들을 최소한 몇 가지라도 피하는 데 도움이 될 수 있기를 바랍니다.
VaR 및 마코위츠 이론의 이론적 및 수학적 기초
그럼 이론부터 시작해 볼까요? 저는 첫 달에는 수학에 익숙해지려고 애썼습니다. 마코위츠의 이론은 복잡해 보입니다 - 방정식, 행렬, 2차 최적화 등 여러 가지 요소가 섞여 있죠. 하지만 실제로는 모든 것이 간단합니다: 자산 수익률을 가져와 상관관계를 계산하고 주어진 수익률에 대해 위험을 최소화하는 가중치를 찾으면 됩니다.
처음엔 기뻤습니다! 하지만 실제 외환 데이터를 가지고 테스트를 시작하면서 모든 것이 망가지기 시작했습니다... EURUSD의 1년치 히스토리를 살펴보면 수익률 분포가 전혀 정상이 아니었습니다. GBPUSD도 마찬가지였습니다. 이것이 마코위츠 이론의 핵심 가정입니다. 다시 말해 모든 계산이 헛수고가 된다는 뜻입니다.
저는 해결책을 찾느라 일주일을 보냈습니다. 과학 논문을 샅샅이 뒤지고 구글 검색도 하고 포럼도 읽어봤습니다. 저는 VaR - 위험 가치 와 관련한 제 기사를 다시 살펴보기 시작했습니다. 그럴듯하게 들리지만 사실 우리는 95% 확률(또는 그 외의 확률)로 얼마나 손실을 볼 수 있는지를 계산하는 것일 뿐입니다. 먼저 가장 간단한 방법을 시도해 봤습니다 - 매개변수적인 VaR. 이 공식은 간단합니다: 평균에서 분위수별 표준편차를 뺀 값입니다. 성능은 보통 수준입니다.
그 다음에는 히스토리 데이터에 기반한 VaR로 전환했습니다. 핵심은 실제 히스토리를 살펴보고 최악의 사례 중 5%에서 발생한 손실이 어떠했는지 알아보는 것입니다. 이는 실제에 훨씬 가깝지만 많은 데이터가 필요합니다. 끝판왕은 몬테카를로 메서드입니다. 우리는 통화쌍 사이의 상관관계를 고려하여 여러 가지 무작위 시나리오를 생성했습니다. 그리고 최종적으로 이렇게 그럴듯한 결과를 얻었습니다.
가장 어려웠던 점은 VaR와 마코위츠 최적화 기법을 어떻게 결합할지 그 방법을 찾아내는 것이었습니다. 그 결과 다음과 같은 것이 탄생했습니다: 우리는 표준 최적화 방식을 사용하되 VaR 제한을 추가합니다. 우리는 주어진 수익률에 대해 최소한의 위험을 추구합니다. 그러나 그 결과로 VaR이 특정 수준을 초과하지 않아야 합니다.
이론상으로는 모든 게 완벽하지만 우리는 실제로 프로그래밍을 해야 합니다... 다음 섹션에서 저는 이러한 방정식을 어떻게 동작하는 파이썬 코드로 변환하였는지 그 방법을 보여드리겠습니다.
파이썬을 사용하여 MetaTrader 5에 연결하기
저의 시스템의 실제적인 구현은 거래 터미널과의 안정적인 연결을 구축하는 것에서부터 시작되었습니다. 여러 가지 접근 방식을 실험해 본 결과 파이썬용 MetaTrader 5 라이브러리를 통한 직접 연결 방식이 가장 안정적이고 빠른 것으로 나타났습니다.
import MetaTrader5 as mt5 import time def initialize_mt5(account=12345, server="MetaQuotes-Demo", password="abc123"): if not mt5.initialize(): print(f"initialize() failed, error code = {mt5.last_error()}") return False authorized = mt5.login(account, password=password, server=server) if not authorized: print(f"login failed, error code = {mt5.last_error()}") mt5.shutdown() return False return True
또 다른 골칫거리는 브로커 서버와 로컬 시스템 간의 시간을 동기화 하는 것이었습니다. VaR을 계산할 때는 단 몇 초의 시차만 있어도 심각한 문제를 야기할 수 있었습니다. 그러므로 특별한 보정 메커니즘을 구현해야 했습니다:
def get_time_correction(): server_time = mt5.symbol_info_tick("EURUSD").time local_time = int(time.time()) return server_time - local_time def get_corrected_time(): correction = get_time_correction() return int(time.time()) + correction
데이터 수집 최적화에 많은 시간이 소요되었습니다. 처음에는 각 통화쌍별로 개별적으로 요청하도록 했습니다. 그러나 일괄 처리를 구현한 후 속도가 몇 배 향상되었습니다:
def fetch_data_batch(symbols, timeframe, start_pos, count): data = {} for symbol in symbols: rates = mt5.copy_rates_from_pos(symbol, timeframe, start_pos, count) if rates is not None and len(rates) > 0: data[symbol] = rates else: print(f"Failed to get data for {symbol}") return None return data
예상외로 프로그램을 제대로 종료하는 것이 어려웠습니다. 따라서 특별한 '정상적인 종료' 절차를 개발해야 했습니다:
def safe_shutdown(): try: positions = mt5.positions_get() if positions: for position in positions: close_position(position.ticket) orders = mt5.orders_get() if orders: for order in orders: mt5.order_send(request={"action": mt5.TRADE_ACTION_REMOVE, "order": order.ticket}) finally: mt5.shutdown()
그 결과 전체 시스템을 위한 안정적인 기반이 마련되었고, 오류 없이 24시간 내내 작동할 수 있게 되었습니다. 이러한 기반 위에 더욱 복잡한 포트폴리오 최적화 로직을 구축하는 것이 가능했습니다. 하지만 이 부분은 다음 섹션에서 다룰 주제입니다.
히스토리 데이터 수집 및 사전 처리
수년간 시장 데이터를 다루면서 저는 한 가지 간단한 진실을 깨달었습니다: 바로 히스토리 데이터의 품질이 거래 시스템에 매우 중요하다는 것입니다. 특히 포트폴리오 최적화의 경우 데이터 오류가 연쇄적으로 발생할 수 있습니다.
저는 먼저 안정적인 히스토리 데이터 불러오기 시스템을 구축하는 것부터 시작했습니다. 첫 번째 버전은 상당히 간단했지만 실제로 사용해 보니 곧 단점이 드러났습니다. 호가에 갭, 급격한 변동, 심지어는 완전히 잘못된 값이 포함될 수 있습니다. 기본 유효성 검사를 포함하여 로딩되는 최종 코드는 다음과 같습니다:
def load_historical_data(symbols, timeframe, start_date, end_date): data_frames = {} for symbol in symbols: # Load with a reserve to compensate for gaps rates = mt5.copy_rates_range(symbol, timeframe, start_date - timedelta(days=30), end_date) if rates is None: print(f"Failed to load data for {symbol}") continue df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) # Basic anomaly check df = detect_and_remove_spikes(df) df = fill_gaps(df) data_frames[symbol] = df return data_frames
주말의 갭 처리 또한 별개의 문제였습니다. 처음에는 단순히 해당 날들을 제외했지만 이렇게 하니 변동성 계산이 왜곡되었습니다. 오랜 실험 끝에 각 통화쌍의 특성을 고려한 보간법이 탄생했습니다:
def fill_gaps(df, method='time'): if df.empty: return df # Check the intervals between points time_delta = df.index.to_series().diff() gaps = time_delta[time_delta > pd.Timedelta(hours=2)].index for gap_start in gaps: gap_end = df.index[df.index.get_loc(gap_start) + 1] # Create new points with interpolated values new_points = pd.date_range(gap_start, gap_end, freq='1H')[1:-1] for point in new_points: df.loc[point] = df.asof(point) return df.sort_index()
저는 수익율을 계산하기 위해 여러 가지 방법을 시도해 봤습니다. 단순한 백분율 변경의 경우 너무 많은 노이즈가 나타났습니다. 로그 수익율이 VaR 추정시 가장 안정적이었습니다:
def calculate_returns(df): df['returns'] = np.log(df['close'] / df['close'].shift(1)) df['rolling_std'] = df['returns'].rolling(window=20).std() df['rolling_mean'] = df['returns'].rolling(window=20).mean() # Clean out emissions using the 3-sigma rule mean = df['returns'].mean() std = df['returns'].std() df = df[abs(df['returns'] - mean) <= 3 * std] return df
데이터 검증 시스템 개발은 중요한 이정표가 되었습니다. 각 데이터 세트는 계산에 사용되기 전에 여러 단계의 검사를 거칩니다:
def verify_data_quality(df, symbol): checks = { 'missing_values': df.isnull().sum().sum() == 0, 'price_continuity': (df['close'] > 0).all(), 'timestamp_uniqueness': df.index.is_unique, 'reasonable_returns': abs(df['returns']).max() < 0.1 } if not all(checks.values()): failed_checks = [k for k, v in checks.items() if not v] print(f"Data quality issues for {symbol}: {failed_checks}") return False return True
저는 비정상적 시장 현상 처리에 특별히 신경을 썼습니다. 뉴스 보도로 인한 급격한 변동이나 갑작스러운 사고 발생과 같은 다양한 사건들이 위험 평가를 크게 왜곡할 수 있습니다. 저는 이러한 문제들을 정확하게 식별하고 처리하기 위한 특별한 알고리즘을 개발했습니다:
def detect_market_anomalies(df, window=20, threshold=3): volatility = df['returns'].rolling(window=window).std() typical_range = volatility.mean() + threshold * volatility.std() anomalies = df[abs(df['returns']) > typical_range].index if len(anomalies) > 0: print(f"Detected {len(anomalies)} market anomalies") return anomalies
그 결과 모든 후속 계산의 기반이 되는 신뢰할 수 있는 데이터 처리 파이프라인이 구축되었습니다. 질 높은 히스토리 데이터는 효율적인 포트폴리오 관리 시스템을 구축하는 데 필수적인 기반이 됩니다. 다음 절에서는 이 데이터를 사용하여 VaR를 계산하는 방법을 살펴보겠습니다.
통화쌍에 대한 VaR 계산 구현
히스토리 데이터를 처리하는 데에 오랜 시간을 투입하고 이후 저는 VaR 계산 구현에 몰두했습니다. 처음에는 기성 방정식을 가져와 코드로 변환하는 것만으로 충분해 보였습니다. 그러나 현실은 외환 거래의 특성상 표준적인 접근 방식을 크게 수정해야 했기 때문에 훨씬 더 복잡했습니다.
저는 먼저 세 가지 고전적인 VaR 계산 메서드를 구현하는 것부터 시작했습니다. 여기서 매개변수적 접근 방식은 다음과 같습니다:
def parametric_var(returns, confidence_level=0.95, holding_period=1): mu = returns.mean() sigma = returns.std() z_score = norm.ppf(1 - confidence_level) daily_var = -(mu + z_score * sigma) return daily_var * np.sqrt(holding_period)
하지만 외환 시장에서 수익률이 정규 분포를 따른다는 가정이 항상 성립하는 것은 아니라는 사실이 곧 명확 해졌습니다. 히스토리 데이터에 기반한 접근 방식이 더 신뢰할 만하다는 것이 입증되었습니다:
def historical_var(returns, confidence_level=0.95, holding_period=1): sorted_returns = np.sort(returns) index = int((1 - confidence_level) * len(sorted_returns)) daily_var = -sorted_returns[index] return daily_var * np.sqrt(holding_period)
하지만 가장 흥미로운 결과는 몬테카를로 메서드를 통해 얻어졌습니다. 저는 외환 시장의 특성을 고려하여 수정했습니다:
def monte_carlo_var(returns, confidence_level=0.95, holding_period=1, simulations=10000): mu = returns.mean() sigma = returns.std() # Consider auto correlation of returns corr = returns.autocorr() simulated_returns = [] for _ in range(simulations): daily_returns = [] last_return = returns.iloc[-1] for _ in range(holding_period): # Generate the next value taking auto correlation into account innovation = np.random.normal(0, 1) next_return = mu + corr * (last_return - mu) + sigma * np.sqrt(1 - corr**2) * innovation daily_returns.append(next_return) last_return = next_return total_return = sum(daily_returns) simulated_returns.append(total_return) return -np.percentile(simulated_returns, (1 - confidence_level) * 100)
저는 결과 검증에 특별히 신경을 썼습니다: VaR 정확도를 검증하기 위한 백테스팅 시스템도 개발했습니다.
def backtest_var(returns, var, confidence_level=0.95): violations = (returns < -var).sum() expected_violations = len(returns) * (1 - confidence_level) z_score = (violations - expected_violations) / np.sqrt(expected_violations) p_value = 1 - norm.cdf(abs(z_score)) return { 'violations': violations, 'expected': expected_violations, 'z_score': z_score, 'p_value': p_value }
통화쌍 간의 관계를 고려하기 위해서는 포트폴리오 VaR 계산을 구현해야 했습니다:
def portfolio_var(returns_df, weights, confidence_level=0.95, method='historical'): if method == 'parametric': portfolio_returns = returns_df.dot(weights) return parametric_var(portfolio_returns, confidence_level) elif method == 'historical': portfolio_returns = returns_df.dot(weights) return historical_var(portfolio_returns, confidence_level) elif method == 'monte_carlo': # Use the covariance matrix to generate # correlated random variables cov_matrix = returns_df.cov() L = np.linalg.cholesky(cov_matrix) means = returns_df.mean().values simulated_returns = [] for _ in range(10000): Z = np.random.standard_normal(len(weights)) R = means + L @ Z portfolio_return = weights @ R simulated_returns.append(portfolio_return) return -np.percentile(simulated_returns, (1 - confidence_level) * 100)
그 결과 외환 시장의 특성에 맞춰 조정된 유연한 VaR 계산 시스템이 탄생했습니다. 다음 섹션에서는 이러한 계산이 포트폴리오 최적화를 위한 마코위츠 이론과 어떻게 통합되는지 알아보겠습니다.
마코위츠 메서드를 이용한 포트폴리오 최적화
신뢰할 수 있는 VaR 계산법을 구현한 후 저는 포트폴리오 최적화에 집중하기 시작했습니다. 마코위츠의 고전적 이론을 외환 시장의 현실에 맞추기 위해 상당한 수정을 해야 했습니다. 수개월에 걸친 실험과 테스트 끝에 저는 몇 가지 중요한 발견을 하게 되었습니다.
제가 처음으로 깨달은 것은 표준적인 위험 및 수익률 메트릭이 외환 시장에서는 주식 시장에서 작동하는 것과는 다르게 작동한다는 점이었습니다. 통화쌍은 시간이 지남에 따라 변화하는 복잡한 관계를 가지고 있습니다. 수많은 실험 끝에 저는 수정된 예상 수익률 계산 함수를 개발했습니다:
def calculate_expected_returns(returns_df, method='ewma', halflife=30): if method == 'ewma': # Exponentially weighted average gives more weight to recent data return returns_df.ewm(halflife=halflife).mean().iloc[-1] elif method == 'capm': # Modified CAPM for Forex risk_free_rate = 0.02 # annual risk-free rate market_returns = returns_df.mean(axis=1) # market returns proxy betas = calculate_currency_betas(returns_df, market_returns) return risk_free_rate + betas * (market_returns.mean() - risk_free_rate)
공분산 행렬 계산에도 일부 수정이 필요했습니다. 단순히 히스토리 데이터에 기반한 접근 방식은 너무 불안정한 결과를 가져왔습니다. 저는 축소 추정 기법을 구현하였고 최적화의 견고성은 크게 향상 되었습니다:
def shrinkage_covariance(returns_df, shrinkage_factor=None): sample_cov = returns_df.cov() n_assets = len(returns_df.columns) # The target matrix is diagonal with average variance target = np.diag(np.repeat(sample_cov.values.trace() / n_assets, n_assets)) if shrinkage_factor is None: # Estimation of the optimal 'shrinkage' ratio shrinkage_factor = estimate_optimal_shrinkage(returns_df, sample_cov, target) shrunk_cov = (1 - shrinkage_factor) * sample_cov + shrinkage_factor * target return pd.DataFrame(shrunk_cov, index=sample_cov.index, columns=sample_cov.columns)
가장 어려운 부분은 포트폴리오 비중을 최적화하는 것입니다. 여러 차례 테스트 끝에 수정된 이차 프로그래밍 알고리즘을 선택했습니다:
def optimize_portfolio(returns_df, expected_returns, covariance, target_return=None, constraints=None): n_assets = len(returns_df.columns) # Risk minimization function def portfolio_volatility(weights): return np.sqrt(weights.T @ covariance @ weights) # Limitations constraints = [] # The sum of the weights is 1 constraints.append({'type': 'eq', 'fun': lambda x: np.sum(x) - 1}) if target_return is not None: # Target income limit constraints.append({ 'type': 'eq', 'fun': lambda x: x @ expected_returns - target_return }) # Add leverage restrictions for Forex constraints.append({ 'type': 'ineq', 'fun': lambda x: 20 - np.sum(np.abs(x)) # max leverage 20 }) # Initial approximation - equal weights initial_weights = np.repeat(1/n_assets, n_assets) # Optimization result = minimize( portfolio_volatility, initial_weights, method='SLSQP', constraints=constraints, bounds=tuple((0, 1) for _ in range(n_assets)) ) if not result.success: raise OptimizationError("Failed to optimize portfolio: " + result.message) return result.x
저는 솔루션의 안정성 문제에 특별히 주의를 기울였습니다: 입력 데이터의 작은 변화가 포트폴리오의 근본적인 수정을 야기하면 안 됩니다. 이를 위해 저는 정규화 절차를 개발했습니다:
def regularized_optimization(returns_df, current_weights, lambda_reg=0.1): # Add a penalty for deviation from the current weights def objective(weights): volatility = portfolio_volatility(weights) turnover_penalty = lambda_reg * np.sum(np.abs(weights - current_weights)) return volatility + turnover_penalty
그 결과 우리는 외환 시장의 특성을 고려하는 그러면서 잦은 리밸런싱이 필요 없는 신뢰할 수 있는 포트폴리오 최적화 도구를 갖게 되었습니다. 하지만 가장 중요한 것은 아직 남아 있었습니다 - 바로 이러한 접근 방식을 VaR 기반 위험 관리 시스템과 결합하는 것이었습니다.
VaR와 마코위츠를 하나의 모델로 결합
두 가지 접근 방식을 결합하는 것이 가장 어려운 부분이었습니다. 저는 두 방법의 장점을 모두 활용하면서도 서로 모순되지 않는 방법을 찾아야 했습니다. 수개월간의 실험 끝에 저는 아주 깔끔한 해결책을 생각해냈습니다.
핵심 아이디어는 VaR를 마코위츠 최적화 문제에 추가적인 제약 조건으로 사용하는 것이었습니다. 코드에서는 다음과 같이 표시됩니다:
def integrated_portfolio_optimization(returns_df, target_return, max_var_limit, current_weights=None): n_assets = len(returns_df.columns) # Calculation of basic metrics exp_returns = calculate_expected_returns(returns_df) covariance = shrinkage_covariance(returns_df) def objective_function(weights): # Portfolio standard deviation (Markowitz) portfolio_std = np.sqrt(weights.T @ covariance @ weights) # component VaR portfolio_var = calculate_portfolio_var(returns_df, weights) var_penalty = max(0, portfolio_var - max_var_limit) return portfolio_std + 100 * var_penalty # Penalty for exceeding VaR
저는 시장의 역동적인 특성을 고려하기 위해 매개변수를 재계산하는 적응형 시스템을 개발했습니다.
def adaptive_risk_limits(returns_df, base_var_limit, window=60): # Adapting VaR limits to current volatility recent_vol = returns_df.tail(window).std() long_term_vol = returns_df.std() vol_ratio = recent_vol / long_term_vol adjusted_var_limit = base_var_limit * np.sqrt(vol_ratio) return min(adjusted_var_limit, base_var_limit * 1.5) # Limit growth
솔루션의 안정성 문제에 특별한 주의가 필요했습니다. 저는 포트폴리오 상태 간의 원활한 전환을 위한 메커니즘을 구현했습니다:
def smooth_rebalancing(old_weights, new_weights, max_change=0.1): weight_diff = new_weights - old_weights excess_change = np.abs(weight_diff) - max_change where_excess = excess_change > 0 if where_excess.any(): # Limit changes in weights adjustment = np.sign(weight_diff) * np.minimum( np.abs(weight_diff), np.where(where_excess, max_change, np.abs(weight_diff)) ) return old_weights + adjustment return new_weights
저는 결합된 접근 방식의 효율성을 평가하기 위한 특별한 메트릭을 개발했습니다:
def evaluate_integrated_model(returns_df, weights, var_limit): # Calculation of performance metrics portfolio_returns = returns_df.dot(weights) realized_var = historical_var(portfolio_returns) sharpe = calculate_sharpe_ratio(portfolio_returns) var_efficiency = abs(realized_var - var_limit) / var_limit return { 'sharpe_ratio': sharpe, 'var_efficiency': var_efficiency, 'max_drawdown': calculate_max_drawdown(portfolio_returns), 'turnover': calculate_turnover(weights) }
테스트 동안 해당 모델은 변동성이 커지는 시기에 특히 효과적으로 작동하는 것으로 나타났습니다. VaR 구성 요소는 위험을 효과적으로 제한하는 반면 마코위츠 최적화는 수익성 확보의 기회를 지속적으로 모색합니다.
시스템의 최종 버전에는 매개변수를 자동으로 조정하는 메커니즘도 포함되어 있습니다:
def auto_tune_parameters(returns_df, initial_params, optimization_window=252): best_params = initial_params best_score = float('-inf') for var_limit in np.arange(0.01, 0.05, 0.005): for shrinkage in np.arange(0.2, 0.8, 0.1): params = {'var_limit': var_limit, 'shrinkage': shrinkage} score = backtest_model(returns_df, params, optimization_window) if score > best_score: best_score = score best_params = params return best_params
다음 섹션에서 저는 이 결합 모델이 실거래에서 동적 포지션 관리에 어떻게 적용되는지 설명하겠습니다.
동적 포지션 크기 관리
이론적 모델을 실용적인 거래 시스템으로 전환하기 위해서 저는 많은 기술적 문제를 해결해야 했습니다. 가장 중요한 점은 현재 시장 상황을 고려하여 포지션 규모를 역동적으로 관리하고 최적의 포트폴리오 가중치를 계산하는 것이었습니다.
이 시스템의 기반은 포지션 관리를 위한 클래스였습니다:
class PositionManager: def __init__(self, account_balance, risk_limit=0.02): self.balance = account_balance self.risk_limit = risk_limit self.positions = {} def calculate_position_size(self, symbol, weight, var_estimate): symbol_info = mt5.symbol_info(symbol) pip_value = symbol_info.trade_tick_value * 10 # Calculate the position size taking into account VaR max_risk_amount = self.balance * self.risk_limit * abs(weight) position_size = max_risk_amount / (abs(var_estimate) * pip_value) # Round to minimum lot return round(position_size / symbol_info.volume_step) * symbol_info.volume_step
포지션을 원활하게 변경하기 위해 저는 분할 주문 메커니즘을 개발했습니다:
def adjust_positions(self, target_positions): for symbol, target_size in target_positions.items(): current_size = self.get_current_position(symbol) if abs(target_size - current_size) > self.min_adjustment: # Break big changes into pieces steps = min(5, int(abs(target_size - current_size) / self.min_adjustment)) step_size = (target_size - current_size) / steps for i in range(steps): next_size = current_size + step_size self.execute_order(symbol, next_size - current_size) current_size = next_size time.sleep(1) # Prevent order flooding
포지션을 바꿀 때 위험 관리에 특별히 신경을 썼습니다:
def execute_order(self, symbol, size_delta, max_slippage=10): if size_delta > 0: order_type = mt5.ORDER_TYPE_BUY else: order_type = mt5.ORDER_TYPE_SELL # Get current prices tick = mt5.symbol_info_tick(symbol) # Set VaR-based stop loss if order_type == mt5.ORDER_TYPE_BUY: stop_loss = tick.bid - (self.var_estimates[symbol] * tick.bid) take_profit = tick.bid + (self.var_estimates[symbol] * 2 * tick.bid) else: stop_loss = tick.ask + (self.var_estimates[symbol] * tick.ask) take_profit = tick.ask - (self.var_estimates[symbol] * 2 * tick.ask) request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": symbol, "volume": abs(size_delta), "type": order_type, "price": tick.ask if order_type == mt5.ORDER_TYPE_BUY else tick.bid, "sl": stop_loss, "tp": take_profit, "deviation": max_slippage, "magic": 234000, "comment": "var_based_adjustment", "type_time": mt5.ORDER_TIME_GTC, "type_filling": mt5.ORDER_FILLING_IOC, } result = mt5.order_send(request) return self.handle_order_result(result)
급격한 시장 변동에 대비하기 위해 변동성 모니터링 시스템을 추가했습니다:
def monitor_volatility(self, returns_df, threshold=2.0): # Current volatility calculation current_vol = returns_df.tail(20).std() * np.sqrt(252) historical_vol = returns_df.std() * np.sqrt(252) if current_vol > historical_vol * threshold: # Reduce positions in case of increased volatility self.reduce_exposure(current_vol / historical_vol) return False return True
이 시스템에는 위험 수준이 임계점에 도달하면 자동으로 포지션을 청산하는 메커니즘도 포함되어 있습니다:
def emergency_close(self, max_loss_percent=5.0): total_loss = sum(pos.profit for pos in mt5.positions_get()) if total_loss < -self.balance * max_loss_percent / 100: print("Emergency closure triggered!") for position in mt5.positions_get(): self.close_position(position.ticket)
그 결과 다양한 시장 상황에서 효과적으로 작동할 수 있는 견고한 포지션 관리 시스템이 구축되었습니다. 다음 섹션에서는 VaR 기반 위험 관리 시스템에 대해 자세히 살펴보겠습니다.
포트폴리오 위험 관리 시스템
동적 포지션 관리를 도입한 후 저는 포트폴리오 차원에서 포괄적인 위험 관리 시스템을 구축해야 할 필요성에 직면했습니다. 경험에 따르면 개별 포지션에 대한 개별 포지션 단위의 위험 관리만으로는 충분하지 않습니다 - 전체적인 접근 방식이 필요합니다.
저는 포트폴리오 위험을 모니터링하는 클래스를 만드는 것부터 시작했습니다:
class PortfolioRiskManager: def __init__(self, max_portfolio_var=0.03, max_correlation=0.7, max_drawdown=0.1): self.max_portfolio_var = max_portfolio_var self.max_correlation = max_correlation self.max_drawdown = max_drawdown self.current_drawdown = 0 self.peak_balance = 0 def update_portfolio_metrics(self, positions, returns_df): # Calculation of current portfolio weights total_exposure = sum(abs(pos.volume) for pos in positions) weights = {pos.symbol: pos.volume/total_exposure for pos in positions} # Update portfolio VaR self.current_var = self.calculate_portfolio_var(returns_df, weights) # Check correlations self.check_correlations(returns_df, weights)
저는 금융 상품들 간의 상관관계를 모니터링하는 데 특별히 주의를 기울였습니다:
def check_correlations(self, returns_df, weights): corr_matrix = returns_df.corr() high_corr_pairs = [] for i in returns_df.columns: for j in returns_df.columns: if i < j and abs(corr_matrix.loc[i,j]) > self.max_correlation: if weights.get(i, 0) > 0 and weights.get(j, 0) > 0: high_corr_pairs.append((i, j, corr_matrix.loc[i,j])) if high_corr_pairs: self.handle_high_correlations(high_corr_pairs, weights)
시장 상황에 따라 달라지는 동적 위험 관리 시스템을 구현했습니다:
def adjust_risk_limits(self, market_state): volatility_factor = market_state.get('volatility_ratio', 1.0) trend_strength = market_state.get('trend_strength', 0.5) # Adapt limits to market conditions self.max_portfolio_var *= np.sqrt(volatility_factor) if trend_strength > 0.7: # Strong trend self.max_drawdown *= 1.2 # Allow a big drawdown elif trend_strength < 0.3: # Weak trend self.max_drawdown *= 0.8 # Reduce the acceptable drawdown
드로다운 모니터링 시스템은 특히 흥미로운 것으로 드러났습니다:
def monitor_drawdown(self, current_balance): if current_balance > self.peak_balance: self.peak_balance = current_balance self.current_drawdown = (self.peak_balance - current_balance) / self.peak_balance if self.current_drawdown > self.max_drawdown: return self.handle_excessive_drawdown() elif self.current_drawdown > self.max_drawdown * 0.8: return self.reduce_risk_exposure(0.8) return True
극단적인 상황에 대비하기 위해 스트레스 테스트 시스템을 추가했습니다.
def stress_test_portfolio(self, returns_df, weights, scenarios=1000): results = [] for _ in range(scenarios): # Simulate extreme conditions stress_returns = returns_df.copy() # Increase volatility vol_multiplier = np.random.uniform(1.5, 3.0) stress_returns *= vol_multiplier # Add random shocks shock_magnitude = np.random.uniform(-0.05, 0.05) stress_returns += shock_magnitude # Calculate losses in a stress scenario portfolio_return = (stress_returns * weights).sum(axis=1) results.append(portfolio_return.min()) return np.percentile(results, 1) # 99% VaR in case of a stress
그 결과로 과도한 위험을 효과적으로 방지하고 높은 변동성 시기에도 생존할 수 있도록 돕는 다단계 자금 보호 시스템이 만들어졌습니다. 다음 섹션에서는 이러한 모든 구성 요소가 실거래에서 어떻게 함께 작동하는지 설명하도록 하겠습니다.
분석 결과 시각화
시각화는 제 연구에서 중요한 단계가 되었습니다. 모든 계산 모듈을 구현한 후에는 결과를 시각적으로 표현할 필요가 있었습니다. 저는 시스템 성능을 실시간으로 모니터링하는 데 도움이 되는 몇 가지 중요한 그래픽 구성 요소를 개발했습니다.
저는 포트폴리오 구조와 그 변화 과정을 시각화 하는 것부터 시작했습니다:
def plot_portfolio_composition(weights_history): plt.figure(figsize=(15, 8)) ax = plt.gca() # Create a graph of weight changes over time dates = weights_history.index bottom = np.zeros(len(dates)) for symbol in weights_history.columns: plt.fill_between(dates, bottom, bottom + weights_history[symbol], label=symbol, alpha=0.6) bottom += weights_history[symbol] plt.title('Evolution of portfolio structure') plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left') plt.grid(True, alpha=0.3)
위험 요소를 시각화 하는 데에 특히 중점을 두었습니다. 또한 저는 다양한 통화쌍에 대한 VaR 히트맵을 개발했습니다:
def plot_var_heatmap(var_matrix): plt.figure(figsize=(12, 8)) sns.heatmap(var_matrix, annot=True, cmap='RdYlBu_r', fmt='.2%', center=0) plt.title('Portfolio risk map (VaR)') # Add a timestamp plt.annotate(f'Last update: {datetime.now().strftime("%Y-%m-%d %H:%M")}', xy=(0.01, -0.1), xycoords='axes fraction')
수익성을 분석하기 위해 중요한 사건들을 강조 표시한 인터랙티브 차트를 만들었습니다:
def plot_performance_analytics(returns_df, var_values, significant_events): fig = plt.figure(figsize=(15, 10)) gs = GridSpec(2, 1, height_ratios=[3, 1]) # Returns graph ax1 = plt.subplot(gs[0]) cumulative_returns = (1 + returns_df).cumprod() ax1.plot(cumulative_returns.index, cumulative_returns, label='Portfolio returns') # Mark important events for date, event in significant_events.items(): ax1.axvline(x=date, color='r', linestyle='--', alpha=0.3) ax1.annotate(event, xy=(date, ax1.get_ylim()[1]), xytext=(10, 10), textcoords='offset points', rotation=45) # VaR graph ax2 = plt.subplot(gs[1]) ax2.fill_between(var_values.index, -var_values, color='lightblue', alpha=0.5, label='Value at Risk')
포트폴리오 현황을 모니터링할 수 있는 대화형 대시보드를 추가했습니다:
class PortfolioDashboard: def __init__(self): self.fig = plt.figure(figsize=(15, 10)) self.setup_subplots() def setup_subplots(self): gs = self.fig.add_gridspec(3, 2) self.ax_returns = self.fig.add_subplot(gs[0, :]) self.ax_weights = self.fig.add_subplot(gs[1, 0]) self.ax_risk = self.fig.add_subplot(gs[1, 1]) self.ax_metrics = self.fig.add_subplot(gs[2, :]) def update(self, portfolio_data): self._plot_returns(portfolio_data['returns']) self._plot_weights(portfolio_data['weights']) self._plot_risk_metrics(portfolio_data['risk']) self._update_metrics_table(portfolio_data['metrics']) plt.tight_layout() plt.show()
상관관계를 분석하기 위해 동적 시각화 도구를 개발했습니다:
def plot_correlation_dynamics(returns_df, window=60): # Calculation of dynamic correlations correlations = returns_df.rolling(window=window).corr() # Create an animated graph fig, ax = plt.subplots(figsize=(10, 10)) def update(frame): ax.clear() sns.heatmap(correlations.loc[frame], vmin=-1, vmax=1, center=0, cmap='RdBu', ax=ax) ax.set_title(f'Correlations on {frame.strftime("%Y-%m-%d")}')
이러한 시각화 자료들은 모두 포트폴리오의 상태를 신속하게 평가하고 거래 결정을 내리는 데 도움이 됩니다. 다음 섹션에서는 시스템을 테스트하겠습니다.
전략 백테스팅
시스템의 모든 구성 요소 개발을 완료한 후 시스템에 대한 철저한 테스트가 필요했습니다. 그 과정은 단순히 히스토리 데이터를 분석하는 것보다 훨씬 더 복잡한 것이었습니다. 여러 요소를 고려해야 했습니다: 슬리피지, 수수료, 그리고 각 브로커별 주문 체결 방식의 특수성 등이 그것입니다.
초기 백테스팅 결과 고정 스프레드를 사용하는 기존의 방식은 지나치게 낙관적인 결과를 나타내는 것으로 밝혀졌습니다. 변동성과 시간대에 따른 스프레드 변화를 고려한 보다 현실적인 모델을 개발할 필요가 있었습니다.
저는 데이터 갭 현상과 유동성 문제를 모델링하는 데 특별히 주의를 기울였습니다. 실거래에서는 예상 가격으로 주문이 체결되지 않는 상황이 종종 발생합니다. 이러한 시나리오들은 테스트에서 올바르게 처리되어야 합니다.
다음은 백테스팅 시스템 전체를 구현한 코드입니다:
class PortfolioBacktester: def __init__(self, initial_capital=100000, commission=0.0001): self.initial_capital = initial_capital self.commission = commission self.positions = {} self.trades_history = [] self.balance_history = [] self.var_history = [] self.metrics = {} def run_backtest(self, returns_df, optimization_params): self.current_capital = self.initial_capital portfolio_returns = [] # Preparing sliding windows for calculations window = 252 # Trading yesr for i in range(window, len(returns_df)): # Receive historical data for calculation historical_returns = returns_df.iloc[i-window:i] # Optimize the portfolio weights = self.optimize_portfolio( historical_returns, optimization_params['target_return'], optimization_params['max_var'] ) # Calculate VaR for the current distribution current_var = self.calculate_portfolio_var( historical_returns, weights, optimization_params['confidence_level'] ) # Check the need for rebalancing if self.should_rebalance(weights, current_var): self.execute_rebalancing(weights, returns_df.iloc[i]) # Update positions and calculate profitability portfolio_return = self.update_positions(returns_df.iloc[i]) portfolio_returns.append(portfolio_return) # Update metrics self.update_metrics(portfolio_return, current_var) # Check stop losses triggering self.check_stop_losses(returns_df.iloc[i]) # Calculate the final metrics self.calculate_final_metrics(portfolio_returns) def optimize_portfolio(self, returns, target_return, max_var): # Using our hybrid optimization model opt = HybridOptimizer(returns, target_return, max_var) weights = opt.optimize() return self.apply_position_limits(weights) def execute_rebalancing(self, target_weights, current_prices): for symbol, target_weight in target_weights.items(): current_weight = self.get_position_weight(symbol) if abs(target_weight - current_weight) > self.REBALANCING_THRESHOLD: # Simulate execution with slippage slippage = self.simulate_slippage(symbol, current_prices[symbol]) trade_price = current_prices[symbol] * (1 + slippage) # Calculate the deal size trade_volume = self.calculate_trade_volume( symbol, current_weight, target_weight ) # Consider commissions commission = abs(trade_volume * trade_price * self.commission) self.current_capital -= commission # Set a deal to history self.record_trade(symbol, trade_volume, trade_price, commission) def update_metrics(self, portfolio_return, current_var): self.balance_history.append(self.current_capital) self.var_history.append(current_var) # Updating performance metrics self.metrics['max_drawdown'] = self.calculate_drawdown() self.metrics['sharpe_ratio'] = self.calculate_sharpe() self.metrics['var_efficiency'] = self.calculate_var_efficiency() def calculate_final_metrics(self, portfolio_returns): returns_series = pd.Series(portfolio_returns) self.metrics['total_return'] = (self.current_capital / self.initial_capital - 1) self.metrics['volatility'] = returns_series.std() * np.sqrt(252) self.metrics['sortino_ratio'] = self.calculate_sortino(returns_series) self.metrics['calmar_ratio'] = self.calculate_calmar() self.metrics['var_breaches'] = self.calculate_var_breaches() def simulate_slippage(self, symbol, price): # Simulate realistic slippage base_slippage = 0.0001 # Basic slippage time_factor = self.get_time_factor() # Time dependency volume_factor = self.get_volume_factor(symbol) # Volume dependency return base_slippage * time_factor * volume_factor시험 결과는 상당히 많은 것을 보여주었습니다. 하이브리드 모델은 기존 접근 방식에 비해 시장 충격에 대한 회복력이 훨씬 뛰어난 것으로 나타났습니다. 이는 특히 변동성이 높은 시기에 VaR 한도가 포트폴리오를 과도한 위험으로부터 효과적으로 보호해 주었다는 점에서 두드러졌습니다.
최종 디버깅
수개월에 걸친 개발과 테스트 끝에 저는 마침내 시스템의 최종 버전을 완성했습니다. 솔직히 말하면 제가 처음 계획했던 것과는 많이 다릅니다. 실전을 통해 많은 변화가 일어났고 그중 일부는 전혀 예상치 못한 것이었습니다.
가장 큰 변화는 데이터를 다루는 방식에 있었습니다. 히스토리 데이터만으로 시스템을 테스트하는 것은 충분치 않다는 것을 깨달었습니다 - 다양한 시장 상황에서 시스템의 동작을 확인하는 것이 필요했습니다. 그래서 저는 합성 데이터를 생성하는 시스템을 개발했습니다. 간단해 보이지만 실제로는 몇 주가 걸렸습니다.
저는 먼저 모든 통화쌍을 유동성을 기준으로 하여 그룹으로 나누었습니다. 첫 번째 그룹에는 EURUSD와 GBPUSD와 같은 주요 통화쌍이 포함되었습니다. 두 번째 그룹에는 AUDUSD와 USDCAD와 같은 통화쌍이 포함되어 있었습니다. 다음으로는 EURJPY, GBPJPY 등의 교차 통화쌍이었습니다. 마지막으로 CADJPY와 EURAUD 같은 이색적인 통화쌍도 있었습니다. 각 그룹에 대해 저는 실제 값에 최대한 가깝게 저만의 변동성 및 상관관계 매개변수를 설정했습니다.
하지만 가장 흥미로운 일은 제가 다양한 시장 모드를 추가했을 때 시작되었습니다. 상상해 보세요: 시장의 3분의 1은 안정적이고 변동성이 낮습니다. 나머지 3분의 1은 평상시의 거래입니다. 그리고 남은 기간은 변동성이 더욱 커지는 시기로 모든 것이 미친 듯이 요동칠 것입니다. 이에 더해 저는 장기적인 추세와 경기 순환적 변동도 추가했고 이는 실제 시장과 매우 유사한 것으로 드러났습니다.
포트폴리오 최적화에도 어느 정도 노력이 필요했습니다. 처음에는 포지션의 가중치에 간단한 제한을 두는 것으로 충분할 거라고 생각했지만 곧 그것만으로는 부족하다는 것을 깨달었습니다. 그래서 저는 동적 위험 프리미엄을 추가했습니다 - 통화쌍의 변동성이 높을수록 잠재적 수익률도 높아야 한다는 것입니다. 도입한 제한: 최소 - 포지션 당 4%, 최대 - 25%. 많은것처럼 보일 수 있지만 레버리지를 사용하는 사람이라면 이는 정상입니다.
레버리지에 대해 말하자면. 이건 별개의 이야기입니다. 처음에 저는 안전하게 가려고 거의 사용하지 않았습니다. 하지만 분석 결과 10 대 1 정도에 해당하는 적절한 레버리지 비율이 결과를 크게 향상시키는 것으로 나타났습니다. 가장 중요한 것은 모든 비용을 정확하게 고려하는 것입니다. 그 중에는 꽤 많은 요소들이 있습니다: 거래 수수료(2bp), 레버리지 유지 이자(일일 0.01%), 체결 슬리피지 등이 있습니다. 이 모든 것이 최적화 프로그램에 내장되어야 했습니다.
또 다른 골칫거리는 마진콜로부터의 보호입니다. 몇 번의 실패 끝에 저는 간단한 해결책을 찾아냈습니다. 손실률이 10%를 초과하면 모든 포지션을 청산하고 최소한 자본의 일부라도 보존하는 것입니다. 보수적으로 들리실지 모르지만 장기적으로 보면 아주 효과적입니다.
가장 어려웠던 점은 리포트였습니다. 시스템이 수십 개의 통화 쌍을 다루고 끊임없이 매매를 진행하는 경우 모든 것을 추적하는 것은 사실상 불가능합니다. 저는 모니터링 시스템 전체를 개발해야 했습니다: 다양한 메트릭이 포함된 연간 보고서, 포트폴리오의 단순 가치부터 가중치 분포의 히트맵에 이르기까지 모든 것을 보여주는 그래프까지 말이죠.
저는 2000년부터 2024년까지 장기간에 걸쳐 최종 테스트를 진행했습니다. 저는 초기 자본금으로 100만 달러를 확보했고 분기별로 리밸런싱을 했습니다. 그리고 결과에 만족했습니다. 이 시스템은 다양한 시장 상황에 잘 적응하고 위험을 효과적으로 관리합니다. 가장 심각한 위기 상황에서도 자본의 대부분을 보존하는 능력을 보여줍니다.
하지만 아직 해야 할 일이 많습니다. 저는 변동성을 예측하기 위해 머신러닝을 추가하고 싶습니다. 현재 이 시스템은 히스토리 데이터에만 적용한 것입니다. 또한 레버리지 관리를 더욱 유연하게 만드는 방법에 대해서도 고민하고 있습니다. 리밸런싱 빈도 또한 최적화할 수 있습니다. 때로는 한 분기가 너무 길게 느껴질 수 있지만 때로는 6개월 동안 포지션을 그대로 두어도 괜찮을 수 있습니다.
전반적으로 결과는 제가 당초 계획했던 것과는 완전히 달랐습니다. 하지만 흔히들 말하듯 최고는 좋은 것의 적입니다. 이 시스템은 효과적이고 위험을 관리하며 수익을 창출합니다. 그리고 이것이 가장 중요한 점입니다.
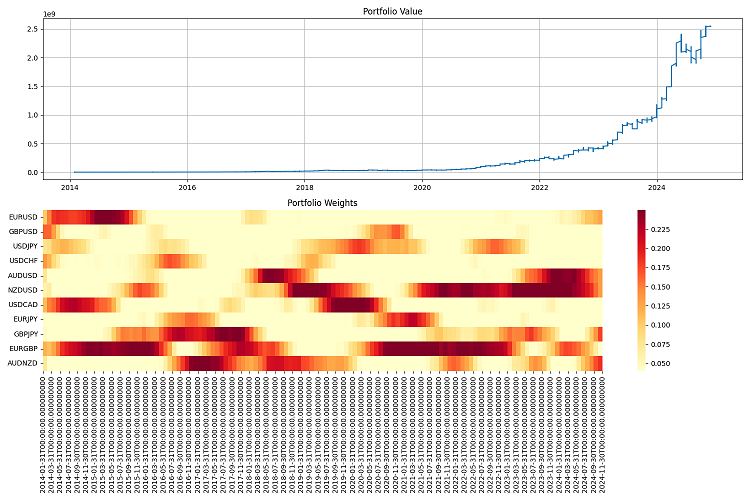
결론
정말 멋진 경험이었습니다. 처음에 마코위츠의 이론을 알아보기 시작했을 때는 저는 그것이 어떤 방향으로 발전할지 상상조차 할 수 없었습니다. 저는 그저 외환 거래에 전통적인 접근 방식을 적용하고 싶었을 뿐인데 결국에는 다양한 위험 관리 접근 방식을 짜깁기한 일종의 프랑켄슈타인 같은 것을 만들어내야 했습니다.
가장 멋진 점은 VaR과 마코위츠를 결합할 수 있었다는 것인데 정말 효과가 있었습니다! 재밌는 점은 두 방법 모두 개별적으로는 그다지 효과적이지 않았지만 함께 사용하니 탁월한 결과를 보여 주었다는 것입니다. 저는 특히 시장이 불안정한 상황에서도 시스템이 잘 작동하는 점이 마음에 들었습니다. VaR는 최적화 과정에서 제한을 가하는 데에 정말 놀라운 성능을 보여줍니다.
물론 저는 기술적인 부분에서 많은 어려움을 겪었습니다. 하지만 이제는 모든 것이 고려됩니다: 슬리피지, 수수료, 거래 실행 특성.
저는 2000년부터 2024년까지의 히스토리 데이터를 사용하여 시스템을 테스트했습니다. 결과는 꽤 좋았습니다. 이 시스템은 다양한 시장 상황에 잘 적응하며 위기 상황에서도 무너지지 않습니다. 10 대 1의 레버리지 덕분에 마치 시계처럼 정확하게 작동합니다. 가장 중요한 것은 위험을 엄격하게 관리하는 것입니다.
하지만 아직 해야 할 일이 산더미처럼 많습니다. 저는 다음과 같이 하고 싶습니다:
- 머신러닝을 변동성 예측에 추가(이것은 다음 기고글의 주제입니다).
- 리밸런싱의 빈도 조정 - 최적화될 수 있을지도 모릅니다;
- 레버리지 관리를 더욱 스마트하게 (동적 레버리지 및 동적 증거금 활용 방식은 이후 기고글에서 구현될 예정입니다).
- 시스템이 다양한 시장 환경에 더욱 잘 적응하도록 훈련.
요컨대 핵심 결론은 다음과 같습니다: 훌륭한 거래 시스템은 단순히 교과서에 나오는 공식만으로 만들어지는 것이 아닙니다. 이 분야에서는 시장을 이해하고 기술에 정통해야 하며 특히 위험을 잘 관리할 수 있어야 합니다. 이러한 모든 발전은 이제 외환 시장 뿐만 아니라 다른 시장에도 적용될 수 있습니다. 아직 발전의 여지는 있지만 기반은 이미 마련되어 있고 제대로 작동하고 있습니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/16604
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

