
시간, 가격 및 볼륨을 기반으로 3차원 바 생성하기

소개
제가 이 프로젝트를 시작한 지 6개월이 지났습니다. 저는 제 아이디어가 어리석어 보여서 반년 동안 신경 쓰지 않았고 친분 있는 트레이더들과 이야기하는 정도였습니다.
모든 것은 간단한 질문에서 시작되었습니다 - 왜 트레이더들은 3차원인 시장을 2차원 차트로 분석하려고 하는 걸까요? 가격 움직임, 기술적 분석, 파동 이론 - 이 모든 것은 시장을 평면상에 투영하는 것을 기반으로 합니다. 하지만 우리가 가격, 볼륨, 시간의 실제의 구조를 파악하려고 하면 어떠할까요?
저는 알고리즘 시스템을 연구하면서 전통적인 지표들이 가격과 볼륨 사이의 중요한 관계를 놓치는 경우가 많다는 사실을 꾸준히 접하게 되었습니다.
3차원 바라는 아이디어는 바로 떠오른 것이 아닙니다. 첫째, 시장 심도를 3차원로 시각화 하는 실험이 있었습니다. 그러자 처음으로 볼륨-가격을 묶어서 나타내는 도표들이 등장했습니다. 그리고 시간 요소를 추가하고 최초의 3차원 바를 만들었을 때 이것이야 말로 시장을 바라보는 근본적으로 새로운 방식이라는 것이 분명해졌습니다.
오늘 저는 이 연구의 결과를 여러분과 공유하고자 합니다. 파이썬과 MetaTrader 5를 이용하여 실시간으로 볼륨 바를 생성하는 방법을 보여드리겠습니다. 계산을 하는 바탕이 되는 수학적 원리와 이 정보를 실제 거래에 활용하는 방법에 대해 이야기하겠습니다.
3차원 바는 무엇이 다를까요?
우리가 시장을 2차원적인 차트라는 틀로만 바라보는 한 가장 중요한 것, 즉 시장의 진정한 구조를 놓치게 됩니다. 전통적인 기술적 분석은 가격-시간, 볼륨-시간을 기반으로 하지만 이러한 구성 요소들 상호 작용하여 어떻게 돌아가는지 그 전체적인 그림을 보여주지는 못합니다.
3차원 분석은 시장 전체를 조망할 수 있게 해준다는 점에서 근본적으로 다릅니다. 볼륨 바를 만드는 것은 시장 상황의 "스냅샷"을 만들어내는 것이며 각 차원은 매우 중요한 정보를 담고 있습니다.
- 바의 높이는 가격 변동의 진폭을 나타냅니다.
- 너비는 시간 척도를 반영합니다.
- 깊이는 볼륨 분포를 시각화 합니다.
이것이 왜 중요할까요? 차트에서 두 개의 동일한 가격 변동을 상상해 보세요. 평면도에서는 둘이 똑같아 보인다. 하지만 볼륨 요소를 추가하면 상황이 완전히 달라집니다 - 어떤 움직임은 대규모 볼륨에 힘입어 깊고 안정적인 캔들을 형성하는 반면 다른 움직임은 실제의 거래가 거의 없는 표면적인 반등에 그칠 수 있습니다.
3차원 바를 활용한 통합적 접근 방식은 기술 분석의 고전적인 문제인 신호 지연이란 문제를 해결합니다. 바의 체적적인 구조는 첫 번째 틱부터 형성되기 시작합니다. 그러므로 강한 움직임이 발생하는 경우 우리는 이를 일반 차트보다 훨씬 전에 파악할 수 있습니다. 본질적으로 우리는 과거의 패턴이 아닌 현재 거래의 실제적인 역학에 기반한 예측 분석 도구를 얻게 됩니다.
다변량 데이터 분석은 단순히 보기 좋은 시각화 이상의 의미를 지닙니다: 이는 시장의 미시구조를 이해하는 근본적으로 새로운 방식입니다. 각각의 3차원 바에는 다음과 같은 정보가 포함되어 있습니다:
- 가격 범위 내 볼륨 분포
- 포지션 누적 속도
- 매수와 매도 간의 불균형
- 미시적 수준의 변동성
- 움직임의 추진력
이 모든 구성 요소는 하나의 메커니즘으로 작동하고 이를 통해 가격 변동의 진정한 본질을 파악할 수 있도록 해줍니다. 고전적인 기술적 분석은 단순히 캔들이나 바만을 보지만 3차원 분석은 수요와 공급의 상호 작용이라는 복잡한 구조를 보여줍니다.
주요 지표 계산 공식. 7D 바를 생성하는 기본 원리. 서로 다른 차원을 하나의 시스템으로 결합하는 로직
3차원 바의 수학적 모델은 실제 시장의 미세 구조를 분석하는 것을 바탕으로 하여 개발되었습니다. 시스템 내 각각의 바는 3차원의 도형으로 표현될 수 있습니다:
class Bar3D: def __init__(self): self.price_range = None # Price range self.time_period = None # Time interval self.volume_profile = {} # Volume profile by prices self.direction = None # Movement direction self.momentum = None # Impulse self.volatility = None # Volatility self.spread = None # Average spread
핵심은 바 내부의 체적 분포를 계산하는 것입니다. 기존의 바와 달리 우리는 가격 수준별로 볼륨의 분포를 분석하는 것입니다.
def calculate_volume_profile(self, ticks_data): volume_by_price = defaultdict(float) for tick in ticks_data: price_level = round(tick.price, 5) volume_by_price[price_level] += tick.volume # Normalize the profile total_volume = sum(volume_by_price.values()) for price in volume_by_price: volume_by_price[price] /= total_volume return volume_by_price
모멘텀은 가격과 볼륨의 변화율을 조합하여 계산됩니다.
def calculate_momentum(self): price_velocity = (self.close - self.open) / self.time_period volume_intensity = self.total_volume / self.time_period self.momentum = price_velocity * volume_intensity * self.direction
특히 각각의 바 안의 변동성 분석에 중점을 둡니다. 우리는 움직임의 미세한 구조를 고려한 수정된 ATR 방정식을 사용합니다.
def calculate_volatility(self, tick_data): tick_changes = np.diff([tick.price for tick in tick_data]) weighted_std = np.std(tick_changes * [tick.volume for tick in tick_data[1:]]) time_factor = np.sqrt(self.time_period) self.volatility = weighted_std * time_factor
기존 바와의 근본적인 차이점은 모든 메트릭이 실시간으로 계산되어 바 구조의 형성 과정을 확인할 수 있다는 점입니다.
def update_bar(self, new_tick): self.update_price_range(new_tick.price) self.update_volume_profile(new_tick) self.recalculate_momentum() self.update_volatility(new_tick) # Recalculate the volumetric center of gravity self.volume_poc = self.calculate_poc()
모든 측정은 특정 기기에 맞춰 조정된 가중치 시스템을 통해 결합됩니다.
def calculate_bar_strength(self): return (self.momentum_weight * self.normalized_momentum + self.volatility_weight * self.normalized_volatility + self.volume_weight * self.normalized_volume_concentration + self.spread_weight * self.normalized_spread_factor)
실제 거래에서 이 수학적 모델을 통해 우리는 시장의 다음과 같은 측면들을 파악할 수 있습니다:
- 볼륨 축적의 불균형
- 가격 형성 속도의 이상
- 횡보 구간 및 돌파 구간
- 볼륨 특성을 통해 드러나는 추세의 진정한 강도
각각의 3차원 바는 차트상의 한 점에 그치는 것이 아니라 특정 시점의 시장 상황을 나타내는 완전한 상태 지표가 됩니다.
3차원 바 생성 알고리즘 상세 분석. MetaTrader 5 사용 시 특징. 데이터 처리 세부 사항
저는 메인 알고리즘을 디버깅한 후 마침내 가장 흥미로운 부분인 다차원 바를 실시간으로 구현하는 단계에 이르렀습니다. 솔직히 처음에는 꽤 부담스러운 일처럼 보였습니다. MetaTrader 5는 외부 스크립트에 그다지 친화적이지 않으며 문서도 때때로 제대로 된 설명을 제공하지 못합니다. 제가 결국 어떻게 이 어려움을 극복했는지 말씀드리겠습니다.
저는 데이터를 저장하기 위한 기본적인 구조부터 시작했습니다. 여러 번의 반복 작업을 거쳐 다음과 같은 클래스가 탄생했습니다:
class Bar7D: def __init__(self): self.time = None self.open = None self.high = None self.low = None self.close = None self.tick_volume = 0 self.volume_profile = {} self.direction = 0 self.trend_count = 0 self.volatility = 0 self.momentum = 0
가장 어려웠던 점은 블록 크기를 정확하게 계산하는 방법을 알아내는 것이었습니다. 수많은 실험 끝에 저는 다음과 같은 방정식을 도출해 냈습니다:
def calculate_brick_size(symbol_info, multiplier=45): spread = symbol_info.spread point = symbol_info.point min_price_brick = spread * multiplier * point # Adaptive adjustment for volatility atr = calculate_atr(symbol_info.name) if atr > min_price_brick * 2: min_price_brick = atr / 2 return min_price_brick
볼륨 조절에 많은 어려움을 겪었습니다. 처음에는 고정 크기인 volume_brick을 사용하려고 했지만 곧 작동하지 않는다는 것을 깨달었습니다. 해결책은 적응형 알고리즘의 형태였습니다.
def adaptive_volume_threshold(tick_volume, history_volumes): median_volume = np.median(history_volumes) std_volume = np.std(history_volumes) if tick_volume > median_volume + 2 * std_volume: return median_volume + std_volume return max(tick_volume, median_volume / 2)
하지만 제가 통계 지표 계산에 너무 과하게 몰두했던 것 같습니다.
def calculate_stats(df): df['ma_5'] = df['close'].rolling(5).mean() df['ma_20'] = df['close'].rolling(20).mean() df['volume_ma_5'] = df['tick_volume'].rolling(5).mean() df['price_volatility'] = df['price_change'].rolling(10).std() df['volume_volatility'] = df['tick_volume'].rolling(10).std() df['trend_strength'] = df['trend_count'] * df['direction'] # This is probably too much df['zscore_price'] = stats.zscore(df['close'], nan_policy='omit') df['zscore_volume'] = stats.zscore(df['tick_volume'], nan_policy='omit') return df
재밌는 건 가장 어려웠던 부분은 코드를 작성하는 것이 아니라 실제 환경에서 디버깅하는 것이었다는 점입니다.
다음은 3~9 범위에서 정규화를 적용한 함수의 최종 결과입니다. 왜 3-9일까요? 간과 테슬라 모두 이 숫자들에 어떤 마법이 숨겨져 있다고 주장했습니다. 저는 어느 유명한 플랫폼에서 활동하는 한 트레이더가 이러한 수치를 기반으로 성공적인 반전 스크립트를 만들었다는 것을 목격했습니다. 하지만 음모론이나 신비주의에 대해서는 깊이 파고들지 맙시다. 대신 이렇게 해보세요:
def create_true_3d_renko(symbol, timeframe, min_spread_multiplier=45, volume_brick=500, lookback=20000): """ Creates 3D Renko bars with extended analytics """ rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, lookback) if rates is None: print(f"Error getting data for {symbol}") return None, None df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') if df.isnull().any().any(): print("Missing values detected, cleaning...") df = df.dropna() if len(df) == 0: print("No data for analysis after cleaning") return None, None symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get symbol info for {symbol}") return None, None try: min_price_brick = symbol_info.spread * min_spread_multiplier * symbol_info.point if min_price_brick <= 0: print("Invalid block size") return None, None except AttributeError as e: print(f"Error getting symbol parameters: {e}") return None, None # Convert time to numeric and scale everything scaler = MinMaxScaler(feature_range=(3, 9)) # Convert datetime to numeric (seconds from start) df['time_numeric'] = (df['time'] - df['time'].min()).dt.total_seconds() # Scale all numeric data together columns_to_scale = ['time_numeric', 'open', 'high', 'low', 'close', 'tick_volume'] df[columns_to_scale] = scaler.fit_transform(df[columns_to_scale]) renko_blocks = [] current_price = float(df.iloc[0]['close']) current_tick_volume = 0 current_time = df.iloc[0]['time'] current_time_numeric = float(df.iloc[0]['time_numeric']) current_spread = float(symbol_info.spread) current_type = 0 prev_direction = 0 trend_count = 0 try: for idx, row in df.iterrows(): if pd.isna(row['tick_volume']) or pd.isna(row['close']): continue current_tick_volume += float(row['tick_volume']) volume_bricks = int(current_tick_volume / volume_brick) price_diff = float(row['close']) - current_price if pd.isna(price_diff) or pd.isna(min_price_brick): continue price_bricks = int(price_diff / min_price_brick) if volume_bricks > 0 or abs(price_bricks) > 0: direction = np.sign(price_bricks) if price_bricks != 0 else 1 if direction == prev_direction: trend_count += 1 else: trend_count = 1 renko_block = { 'time': current_time, 'time_numeric': float(row['time_numeric']), 'open': float(row['open']), 'close': float(row['close']), 'high': float(row['high']), 'low': float(row['low']), 'tick_volume': float(row['tick_volume']), 'direction': float(direction), 'spread': float(current_spread), 'type': float(current_type), 'trend_count': trend_count, 'price_change': price_diff, 'volume_intensity': float(row['tick_volume']) / volume_brick, 'price_velocity': price_diff / (volume_bricks if volume_bricks > 0 else 1) } if volume_bricks > 0: current_tick_volume = current_tick_volume % volume_brick if price_bricks != 0: current_price += min_price_brick * price_bricks prev_direction = direction renko_blocks.append(renko_block) except Exception as e: print(f"Error processing data: {e}") if len(renko_blocks) == 0: return None, None if len(renko_blocks) == 0: print("Failed to create any blocks") return None, None result_df = pd.DataFrame(renko_blocks) # Scale derived metrics to same range derived_metrics = ['price_change', 'volume_intensity', 'price_velocity', 'spread'] result_df[derived_metrics] = scaler.fit_transform(result_df[derived_metrics]) # Add analytical metrics using scaled data result_df['ma_5'] = result_df['close'].rolling(5).mean() result_df['ma_20'] = result_df['close'].rolling(20).mean() result_df['volume_ma_5'] = result_df['tick_volume'].rolling(5).mean() result_df['price_volatility'] = result_df['price_change'].rolling(10).std() result_df['volume_volatility'] = result_df['tick_volume'].rolling(10).std() result_df['trend_strength'] = result_df['trend_count'] * result_df['direction'] # Scale moving averages and volatility ma_columns = ['ma_5', 'ma_20', 'volume_ma_5', 'price_volatility', 'volume_volatility', 'trend_strength'] result_df[ma_columns] = scaler.fit_transform(result_df[ma_columns]) # Add statistical metrics and scale them result_df['zscore_price'] = stats.zscore(result_df['close'], nan_policy='omit') result_df['zscore_volume'] = stats.zscore(result_df['tick_volume'], nan_policy='omit') zscore_columns = ['zscore_price', 'zscore_volume'] result_df[zscore_columns] = scaler.fit_transform(result_df[zscore_columns]) return result_df, min_price_brick그리고 이것이 우리가 싱글 스케일에서 얻은 일련의 바의 모습입니다. 가만히 있지는 않네요, 그렇죠?
당연히 저는 그런 시리즈에 만족하지 못했습니다. 제 목표는 시간, 볼륨, 가격 면에서 정상 시계열을 만드는 것이었기 때문입니다. 이후 제가 한 일은 다음과 같습니다:
변동성 측정 소개
create_stationary_4d_features 함수를 구현하는 과정에서 저는 근본적으로 다른 접근 방식을 택했습니다. 기존의 3차원 바에서는 단순히 데이터를 3~9 범위로 스케일링 했지만 여기서는 진정한 정상 시계열을 만드는 데 중점을 두었습니다.
이 함수의 핵심 아이디어는 정상 피처들을 통해 시장을 4차원적으로 표현하는 것입니다. 단순히 크기를 조정하는 대신 각 차원을 특별한 방식으로 변환하여 정상 상태를 달성합니다.
- 시간 차원: 여기서 저는 삼각 함수 변환을 적용하여 시간을 사인파와 코사인파로 변환했습니다. sin(2π * 시간/24) 및 cos(2π * 시간/24) 방정식은 주기적인 피처를 생성하여 일일 계절성 문제를 완전히 해결합니다.
- 가격 측정 방식: 절대 가격 대신 상대적 가격 변동률을 사용합니다. 코드에서는 이를 구현하기 위해 평균 가격(고가 + 저가 + 종가)/3을 계산한 다음 그 결과와 결과의 가속도를 계산합니다. 이러한 접근 방식은 가격 수준에 관계없이 시계열을 안정적으로 유지합니다.
- 체적 측정: 여기서 흥미로운 점이 있습니다 - 볼륨의 변화 뿐만 아니라 볼륨의 상대적인 증가량까지 측정한다는 것입니다. 이는 중요합니다. 왜냐하면 볼륨이 매우 불균등하게 분포되는 경우가 많기 때문입니다. 코드에서는 pct_change()와 diff()를 순차적으로 적용하여 이를 구현합니다.
- 변동성 측정: 여기서는 두 단계의 변환을 구현했습니다 - 첫 번째 단계는 수익률의 표준 편차를 통해 변동성을 계산하는 것이고 두 번째 단계는 해당 변동성에서의 상대적 변화를 구하는 것입니다. 결과적으로 우리는 "변동성의 변동성"을 얻게 되는 것입니다.
각각의 데이터 블록은 20기간의 슬라이딩 윈도우 방식으로 생성됩니다. 이 숫자는 임의의 숫자가 아닙니다 - 데이터의 지역적 구조를 보존하는 것과 계산의 통계적 유의성을 확보하는 것 사이의 절충안으로 선택된 숫자입니다.
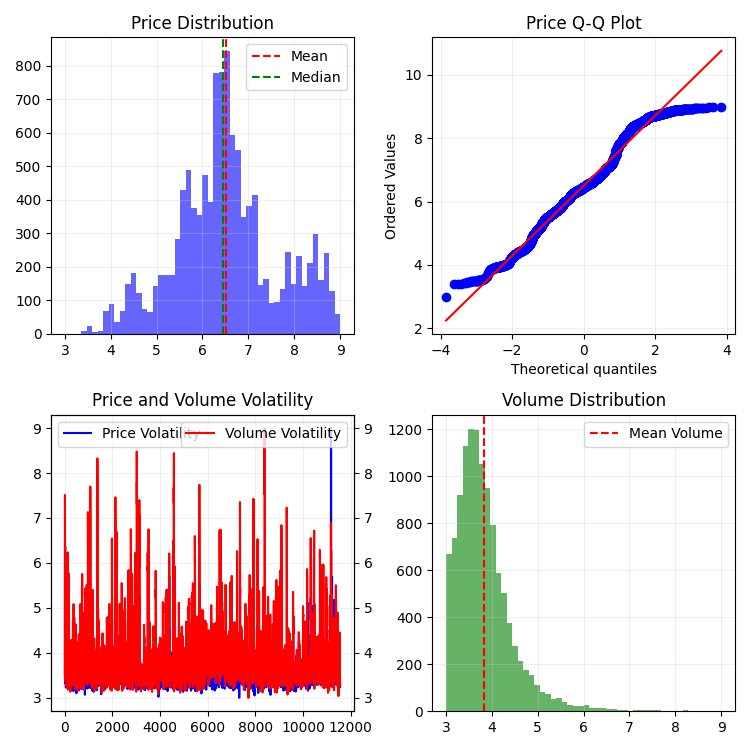
계산된 모든 특징은 최종적으로 3~9 범위로 스케일링 되지만 이는 이미 정상성을 갖는 시계열에 적용되는 2차 변환입니다. 이를 통해 데이터 우리는 전처리 방식에 근본적으로 다른 접근법을 사용하면서도 3차원 바를 구현한 기존의 방식과의 호환성을 유지할 수 있습니다.
특히 중요한 점은 원래 함수의 핵심 지표를 모두 유지하는 것입니다 - 이동 평균, 변동성, z-점수. 이를 통해 이 새로운 구현 방식은 기존 함수를 직접 대체하여 사용할 수 있으며 더 높은 품질의 정상 데이터를 얻을 수 있습니다.
그 결과 우리는 통계적으로 안정적일 뿐만 아니라 시장 구조에 대한 모든 중요한 정보를 유지하는 피처 집합을 얻게 됩니다. 이러한 접근 방식을 통해 데이터는 원래의 거래 맥락과의 연관성을 유지하면서도 머신러닝 및 통계 분석 방법을 적용하기에 훨씬 더 적합해지게 됩니다.
다음은 함수입니다:
def create_true_3d_renko(symbol, timeframe, min_spread_multiplier=45, volume_brick=500, lookback=20000): """ Creates 4D stationary features with same interface as 3D Renko """ rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, lookback) if rates is None: print(f"Error getting data for {symbol}") return None, None df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') if df.isnull().any().any(): print("Missing values detected, cleaning...") df = df.dropna() if len(df) == 0: print("No data for analysis after cleaning") return None, None symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get symbol info for {symbol}") return None, None try: min_price_brick = symbol_info.spread * min_spread_multiplier * symbol_info.point if min_price_brick <= 0: print("Invalid block size") return None, None except AttributeError as e: print(f"Error getting symbol parameters: {e}") return None, None scaler = MinMaxScaler(feature_range=(3, 9)) df_blocks = [] try: # Time dimension df['time_sin'] = np.sin(2 * np.pi * df['time'].dt.hour / 24) df['time_cos'] = np.cos(2 * np.pi * df['time'].dt.hour / 24) df['time_numeric'] = (df['time'] - df['time'].min()).dt.total_seconds() # Price dimension df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['price_acceleration'] = df['price_return'].diff() # Volume dimension df['volume_change'] = df['tick_volume'].pct_change() df['volume_acceleration'] = df['volume_change'].diff() # Volatility dimension df['volatility'] = df['price_return'].rolling(20).std() df['volatility_change'] = df['volatility'].pct_change() for idx in range(20, len(df)): window = df.iloc[idx-20:idx+1] block = { 'time': df.iloc[idx]['time'], 'time_numeric': scaler.fit_transform([[float(df.iloc[idx]['time_numeric'])]]).item(), 'open': float(window['price_return'].iloc[-1]), 'high': float(window['price_acceleration'].iloc[-1]), 'low': float(window['volume_change'].iloc[-1]), 'close': float(window['volatility_change'].iloc[-1]), 'tick_volume': float(window['volume_acceleration'].iloc[-1]), 'direction': np.sign(window['price_return'].iloc[-1]), 'spread': float(df.iloc[idx]['time_sin']), 'type': float(df.iloc[idx]['time_cos']), 'trend_count': len(window), 'price_change': float(window['price_return'].mean()), 'volume_intensity': float(window['volume_change'].mean()), 'price_velocity': float(window['price_acceleration'].mean()) } df_blocks.append(block) except Exception as e: print(f"Error processing data: {e}") if len(df_blocks) == 0: return None, None if len(df_blocks) == 0: print("Failed to create any blocks") return None, None result_df = pd.DataFrame(df_blocks) # Scale all features features_to_scale = [col for col in result_df.columns if col != 'time' and col != 'direction'] result_df[features_to_scale] = scaler.fit_transform(result_df[features_to_scale]) # Add same analytical metrics as in original function result_df['ma_5'] = result_df['close'].rolling(5).mean() result_df['ma_20'] = result_df['close'].rolling(20).mean() result_df['volume_ma_5'] = result_df['tick_volume'].rolling(5).mean() result_df['price_volatility'] = result_df['price_change'].rolling(10).std() result_df['volume_volatility'] = result_df['tick_volume'].rolling(10).std() result_df['trend_strength'] = result_df['trend_count'] * result_df['direction'] # Scale moving averages and volatility ma_columns = ['ma_5', 'ma_20', 'volume_ma_5', 'price_volatility', 'volume_volatility', 'trend_strength'] result_df[ma_columns] = scaler.fit_transform(result_df[ma_columns]) # Add statistical metrics and scale them result_df['zscore_price'] = stats.zscore(result_df['close'], nan_policy='omit') result_df['zscore_volume'] = stats.zscore(result_df['tick_volume'], nan_policy='omit') zscore_columns = ['zscore_price', 'zscore_volume'] result_df[zscore_columns] = scaler.fit_transform(result_df[zscore_columns]) return result_df, min_price_brick
2D로 보면 이런 모습입니다:
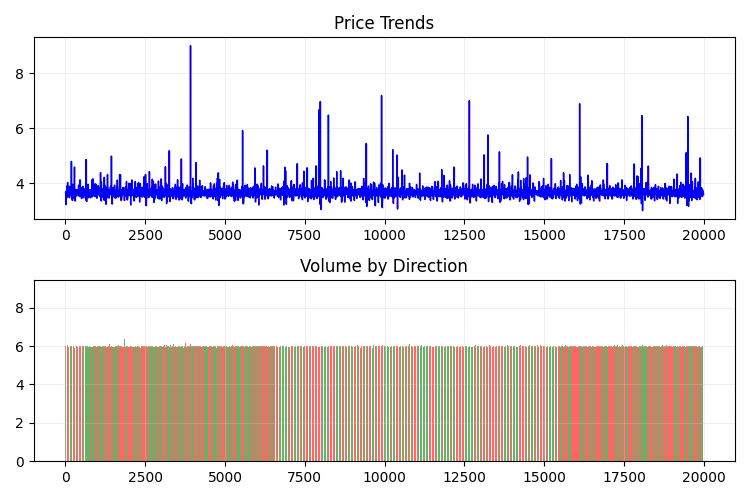
이제 plotly를 사용하여 3차원 가격 정보를 보여주는 인터랙티브 3차원 모델을 만들어 보겠습니다. 근처에 일반적인 2차원 도표가 보여야 합니다. 코드는 다음과 같습니다:
import plotly.graph_objects as go from plotly.subplots import make_subplots def create_interactive_3d(df, symbol, save_dir): """ Creates interactive 3D visualization with smoothed data and original price chart """ try: save_dir = Path(save_dir) # Smooth all series with MA(100) df_smooth = df.copy() smooth_columns = ['close', 'tick_volume', 'price_volatility', 'volume_volatility'] for col in smooth_columns: df_smooth[f'{col}_smooth'] = df_smooth[col].rolling(window=100, min_periods=1).mean() # Create subplots: 3D view and original chart side by side fig = make_subplots( rows=1, cols=2, specs=[[{'type': 'scene'}, {'type': 'xy'}]], subplot_titles=(f'{symbol} 3D View (MA100)', f'{symbol} Original Price'), horizontal_spacing=0.05 ) # Add 3D scatter plot fig.add_trace( go.Scatter3d( x=np.arange(len(df_smooth)), y=df_smooth['tick_volume_smooth'], z=df_smooth['close_smooth'], mode='markers', marker=dict( size=5, color=df_smooth['price_volatility_smooth'], colorscale='Viridis', opacity=0.8, showscale=True, colorbar=dict(x=0.45) ), hovertemplate= "Time: %{x}<br>" + "Volume: %{y:.2f}<br>" + "Price: %{z:.5f}<br>" + "Volatility: %{marker.color:.5f}", name='3D View' ), row=1, col=1 ) # Add original price chart fig.add_trace( go.Candlestick( x=np.arange(len(df)), open=df['open'], high=df['high'], low=df['low'], close=df['close'], name='OHLC' ), row=1, col=2 ) # Add smoothed price line fig.add_trace( go.Scatter( x=np.arange(len(df_smooth)), y=df_smooth['close_smooth'], line=dict(color='blue', width=1), name='MA100' ), row=1, col=2 ) # Update 3D layout fig.update_scenes( xaxis_title='Time', yaxis_title='Volume', zaxis_title='Price', camera=dict( up=dict(x=0, y=0, z=1), center=dict(x=0, y=0, z=0), eye=dict(x=1.5, y=1.5, z=1.5) ) ) # Update 2D layout fig.update_xaxes(title_text="Time", row=1, col=2) fig.update_yaxes(title_text="Price", row=1, col=2) # Update overall layout fig.update_layout( width=1500, # Double width to accommodate both plots height=750, showlegend=True, title_text=f"{symbol} Combined Analysis" ) # Save interactive HTML fig.write_html(save_dir / f'{symbol}_combined_view.html') # Create additional plots with smoothed data (unchanged) fig2 = make_subplots(rows=2, cols=2, subplot_titles=('Smoothed Price', 'Smoothed Volume', 'Smoothed Price Volatility', 'Smoothed Volume Volatility')) fig2.add_trace( go.Scatter(x=np.arange(len(df_smooth)), y=df_smooth['close_smooth'], name='Price MA100'), row=1, col=1 ) fig2.add_trace( go.Scatter(x=np.arange(len(df_smooth)), y=df_smooth['tick_volume_smooth'], name='Volume MA100'), row=1, col=2 ) fig2.add_trace( go.Scatter(x=np.arange(len(df_smooth)), y=df_smooth['price_volatility_smooth'], name='Price Vol MA100'), row=2, col=1 ) fig2.add_trace( go.Scatter(x=np.arange(len(df_smooth)), y=df_smooth['volume_volatility_smooth'], name='Volume Vol MA100'), row=2, col=2 ) fig2.update_layout( height=750, width=750, showlegend=True, title_text=f"{symbol} Smoothed Data Analysis" ) fig2.write_html(save_dir / f'{symbol}_smoothed_analysis.html') print(f"Interactive visualizations saved in {save_dir}") except Exception as e: print(f"Error creating interactive visualization: {e}") raise
이것이 우리의 새롭게 구성된 가격 범위입니다:
전반적으로 매우 흥미로워 보입니다: 시간 경과에 따른 가격 그룹화의 어떠한 순서와 볼륨에 따른 가격 그룹화에서 이상치들을 확인할 수 있습니다. 그래서 시장이 불안정하고 엄청난 볼륨이 쏟아져 나오고 변동성이 급증할 때 우리는 통계를 초월하는 위험한 돌발 상황에 직면하고 있다는 느낌을 가지게 됩니다(뛰어난 트레이더들은 경험을 통해 바로 확인합니다) - 악명 높은 꼬리의 위험 따라서 이러한 좌표에서 우리는 가격의 "비정상적인" 이탈을 즉시 감지할 수 있습니다. 이것 만으로도 저는 다변량 가격 차트라는 아이디어가 정말 좋습니다!
참고사항:
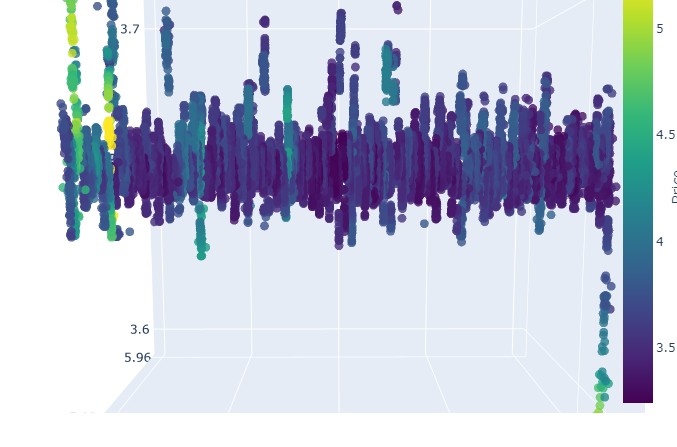
환자 진찰 (3차원 그래픽)
다음으로 저는 시각화를 제안합니다. 하지만 우리를 기다리는 것은 야자수 아래에서의 평안한 삶이 아니라 3차원 가격 차트입니다. 상황을 네 가지 범주로 나누어 보겠습니다: 상승 추세, 하락 추세, 상승 추세에서 하락 추세로의 반전, 하락 추세에서 상승 추세로의 반전 이를 위해 우리는 코드를 약간 수정해야 합니다: 더 이상 바 인덱스가 필요하지 않습니다. 우리는 특정 날짜의 데이터를 불러올 것입니다. 사실 이렇게 하려면 mt5.copy_rates_range를 사용하기만 하면 됩니다.
def create_true_3d_renko(symbol, timeframe, start_date, end_date, min_spread_multiplier=45, volume_brick=500): """ Creates 4D stationary features with same interface as 3D Renko """ rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) if rates is None: print(f"Error getting data for {symbol}") return None, None df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') if df.isnull().any().any(): print("Missing values detected, cleaning...") df = df.dropna() if len(df) == 0: print("No data for analysis after cleaning") return None, None symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get symbol info for {symbol}") return None, None try: min_price_brick = symbol_info.spread * min_spread_multiplier * symbol_info.point if min_price_brick <= 0: print("Invalid block size") return None, None except AttributeError as e: print(f"Error getting symbol parameters: {e}") return None, None scaler = MinMaxScaler(feature_range=(3, 9)) df_blocks = [] try: # Time dimension df['time_sin'] = np.sin(2 * np.pi * df['time'].dt.hour / 24) df['time_cos'] = np.cos(2 * np.pi * df['time'].dt.hour / 24) df['time_numeric'] = (df['time'] - df['time'].min()).dt.total_seconds() # Price dimension df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['price_acceleration'] = df['price_return'].diff() # Volume dimension df['volume_change'] = df['tick_volume'].pct_change() df['volume_acceleration'] = df['volume_change'].diff() # Volatility dimension df['volatility'] = df['price_return'].rolling(20).std() df['volatility_change'] = df['volatility'].pct_change() for idx in range(20, len(df)): window = df.iloc[idx-20:idx+1] block = { 'time': df.iloc[idx]['time'], 'time_numeric': scaler.fit_transform([[float(df.iloc[idx]['time_numeric'])]]).item(), 'open': float(window['price_return'].iloc[-1]), 'high': float(window['price_acceleration'].iloc[-1]), 'low': float(window['volume_change'].iloc[-1]), 'close': float(window['volatility_change'].iloc[-1]), 'tick_volume': float(window['volume_acceleration'].iloc[-1]), 'direction': np.sign(window['price_return'].iloc[-1]), 'spread': float(df.iloc[idx]['time_sin']), 'type': float(df.iloc[idx]['time_cos']), 'trend_count': len(window), 'price_change': float(window['price_return'].mean()), 'volume_intensity': float(window['volume_change'].mean()), 'price_velocity': float(window['price_acceleration'].mean()) } df_blocks.append(block) except Exception as e: print(f"Error processing data: {e}") if len(df_blocks) == 0: return None, None if len(df_blocks) == 0: print("Failed to create any blocks") return None, None result_df = pd.DataFrame(df_blocks) # Scale all features features_to_scale = [col for col in result_df.columns if col != 'time' and col != 'direction'] result_df[features_to_scale] = scaler.fit_transform(result_df[features_to_scale]) # Add same analytical metrics as in original function result_df['ma_5'] = result_df['close'].rolling(5).mean() result_df['ma_20'] = result_df['close'].rolling(20).mean() result_df['volume_ma_5'] = result_df['tick_volume'].rolling(5).mean() result_df['price_volatility'] = result_df['price_change'].rolling(10).std() result_df['volume_volatility'] = result_df['tick_volume'].rolling(10).std() result_df['trend_strength'] = result_df['trend_count'] * result_df['direction'] # Scale moving averages and volatility ma_columns = ['ma_5', 'ma_20', 'volume_ma_5', 'price_volatility', 'volume_volatility', 'trend_strength'] result_df[ma_columns] = scaler.fit_transform(result_df[ma_columns]) # Add statistical metrics and scale them result_df['zscore_price'] = stats.zscore(result_df['close'], nan_policy='omit') result_df['zscore_volume'] = stats.zscore(result_df['tick_volume'], nan_policy='omit') zscore_columns = ['zscore_price', 'zscore_volume'] result_df[zscore_columns] = scaler.fit_transform(result_df[zscore_columns]) return result_df, min_price_brick
다음은 수정된 코드입니다.
def main(): try: # Initialize MT5 if not mt5.initialize(): print("MetaTrader5 initialization error") return # Analysis parameters symbols = ["EURUSD", "GBPUSD"] timeframes = { "M15": mt5.TIMEFRAME_M15 } # 7D analysis parameters params = { "min_spread_multiplier": 45, "volume_brick": 500 } # Date range for data fetching start_date = datetime(2017, 1, 1) end_date = datetime(2018, 2, 1) # Analysis for each symbol and timeframe for symbol in symbols: print(f"\nAnalyzing symbol {symbol}") # Create symbol directory symbol_dir = Path('charts') / symbol symbol_dir.mkdir(parents=True, exist_ok=True) # Get symbol info symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get symbol info for {symbol}") continue print(f"Spread: {symbol_info.spread} points") print(f"Tick: {symbol_info.point}") # Analysis for each timeframe for tf_name, tf in timeframes.items(): print(f"\nAnalyzing timeframe {tf_name}") # Create timeframe directory tf_dir = symbol_dir / tf_name tf_dir.mkdir(exist_ok=True) # Get and analyze data print("Getting data...") df, brick_size = create_true_3d_renko( symbol=symbol, timeframe=tf, start_date=start_date, end_date=end_date, min_spread_multiplier=params["min_spread_multiplier"], volume_brick=params["volume_brick"] ) if df is not None and brick_size is not None: print(f"Created {len(df)} 7D bars") print(f"Block size: {brick_size}") # Basic statistics print("\nBasic statistics:") print(f"Average volume: {df['tick_volume'].mean():.2f}") print(f"Average trend length: {df['trend_count'].mean():.2f}") print(f"Max uptrend length: {df[df['direction'] > 0]['trend_count'].max()}") print(f"Max downtrend length: {df[df['direction'] < 0]['trend_count'].max()}") # Create visualizations print("\nCreating visualizations...") create_visualizations(df, symbol, tf_dir) # Save data csv_file = tf_dir / f"{symbol}_{tf_name}_7d_data.csv" df.to_csv(csv_file) print(f"Data saved to {csv_file}") # Results analysis trend_ratio = len(df[df['direction'] > 0]) / len(df[df['direction'] < 0]) print(f"\nUp/Down bars ratio: {trend_ratio:.2f}") volume_corr = df['tick_volume'].corr(df['price_change'].abs()) print(f"Volume-Price change correlation: {volume_corr:.2f}") # Print warnings if anomalies detected if df['price_volatility'].max() > df['price_volatility'].mean() * 3: print("\nWARNING: High volatility periods detected!") if df['volume_volatility'].max() > df['volume_volatility'].mean() * 3: print("WARNING: Abnormal volume spikes detected!") else: print(f"Failed to create 3D bars for {symbol} on {tf_name}") print("\nAnalysis completed successfully!") except Exception as e: print(f"An error occurred: {e}") import traceback print(traceback.format_exc()) finally: mt5.shutdown()
첫 번째 데이터 섹션인 EURUSD를 살펴보겠습니다. 기간은 2017년 1월 1일부터 2018년 2월 1일까지입니다. 실제로 매우 강력한 상승 추세입니다. 3차원 바로 보면 어떤 모습일지 궁금하지 않으세요?
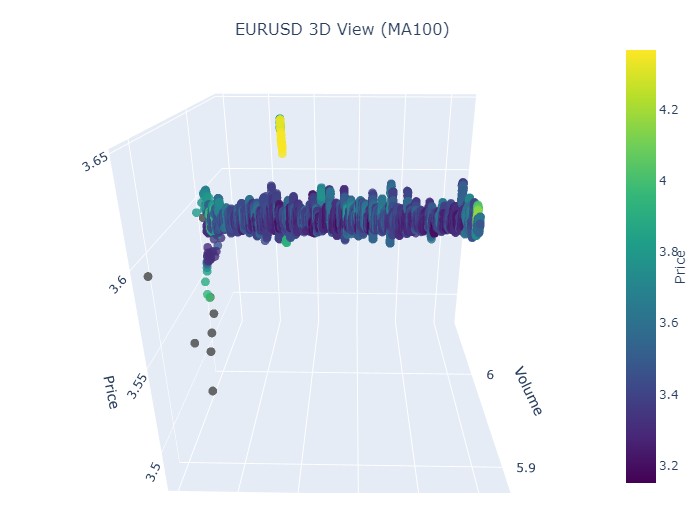
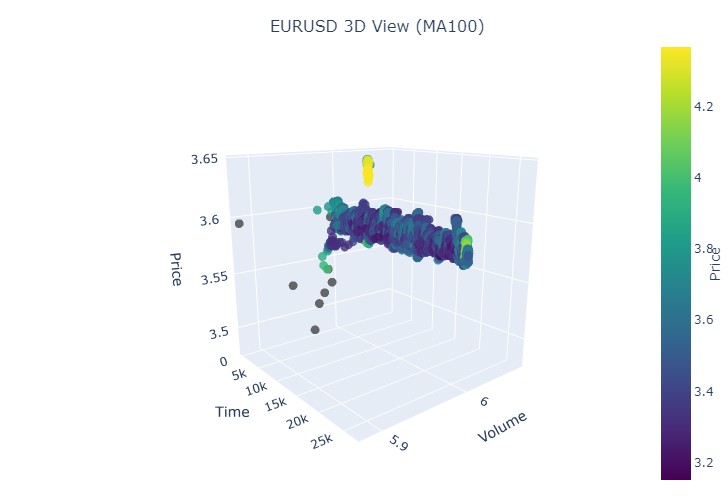
다음은 또 다른 시각화의 예시입니다:
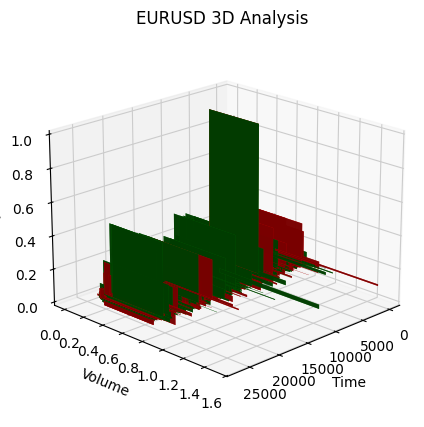
상승 추세의 시작 부분을 주목해 봅시다:
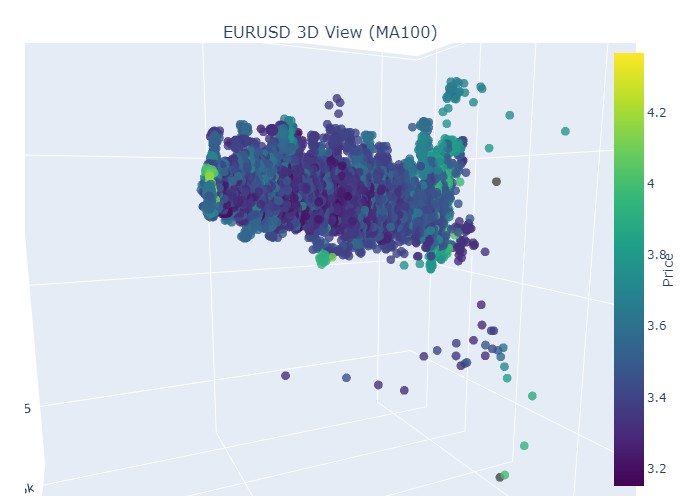
그리고 마지막으로:
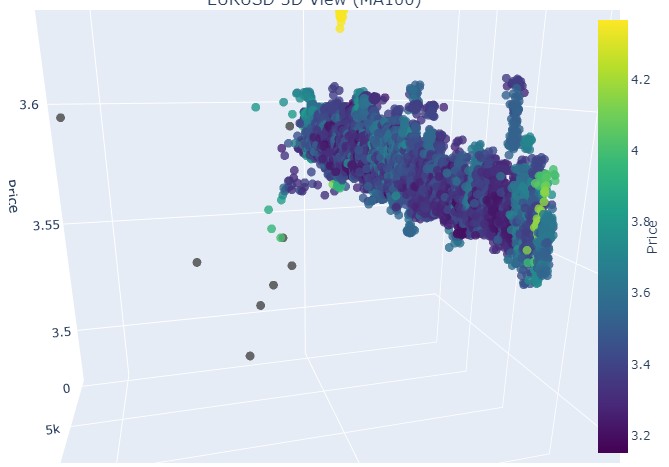
이제 하락 추세를 살펴보겠습니다. 2018년 2월 1일부터 2020년 3월 20일까지:
하락 추세의 시작은 바로 여기입니다:
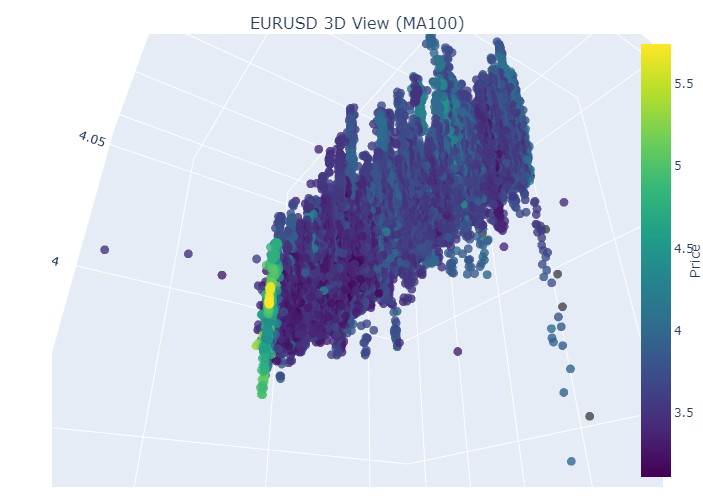
이것으로 끝입니다:
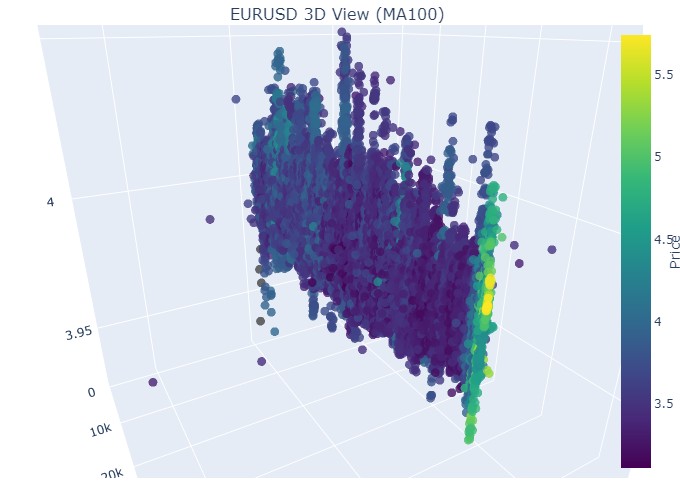
이제 3차원 표현에서 볼 수 있는 것은 하락 추세와 상승 추세 모두 3차원 점 밀도 아래의 점 영역에서 시작되었다는 것입니다. 두 경우 모두 트렌드의 끝은 밝은 노란색 색상 구성으로 표시되었습니다.
이 현상과 EURUSD 가격의 상승 및 하락 추세에서의 움직임을 설명하기 위해 우리는 다음과 같은 일반적인 방정식을 사용할 수 있습니다:
P(t) = P_0 + \int_{t_0}^{t} A \cdot e^{k(tu)} \cdot V(u) \, du + N(t)
설명:
- P(t) — 특정 시점의 통화 가격.
- P_0 — 특정 시점의 초기 가격.
- A — 추세 진폭, 즉 가격 변동의 규모를 나타내는 지표입니다.
- k — 변화율을 결정하는 계수(k > 0은 상승 추세, k < 0은 하락 추세를 의미합니다).
- V(u) — 특정 시점의 볼륨인데 시장 활동에 영향을 미치며 가격 변동의 중요성을 높일 수 있습니다.
- N(t) — 예측할 수 없는 시장 변동을 반영하는 랜덤 노이즈.
설명
이 방정식은 여러 요인에 따라 시간이 지남에 따라 통화 가격이 어떻게 변하는지를 설명합니다. 초기 가격은 출발점이며 이후 적분은 추세의 진폭과 변화율의 영향을 고려하여 그 크기에 따라 가격이 지수적으로 증가하거나 감소하도록 합니다. 함수로 표현되는 볼륨은 시장 활동이 가격 변동에도 영향을 미친다는 것을 보여주는 또 다른 차원을 보여줍니다.
이 모델은 다양한 추세 하에서의 가격 변동을 시각화 하여 3차원 공간에 표시할 수 있도록 하며 시간, 가격 및 볼륨을 축으로 하여 시장 활동에 대한 풍부한 그림을 제공합니다. 이 패턴에서 색상의 밝기는 추세의 강도를 나타낼 수 있으며 밝은 색상은 v파생되는 가격과 볼륨 값이 높다는 것을 의미하고 시장에 강한 볼륨의 변동이 있음을 나타냅니다.
반전 표시
해당 기간은 11월 14일부터 11월 28일까지입니다. 이 기간의 중간쯤에 환율 변동이 반전될 것으로 예상됩니다. 이것을 3차원 좌표로 나타내면 어떤 모습일까요? 다음과 같습니다:
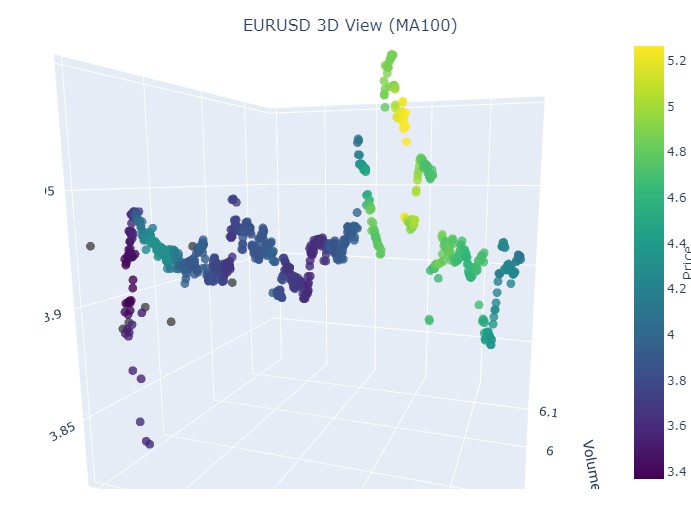
정규화 된 가격 좌표에서 반전과 상승이 일어나는 순간에 이미 익숙한 노란색이 나타나는 것을 볼 수 있습니다. 이제 2024년 9월 13일부터 같은 해 10월 10일까지의 추세 반전이 나타난 또 다른 가격 구간을 살펴보겠습니다:
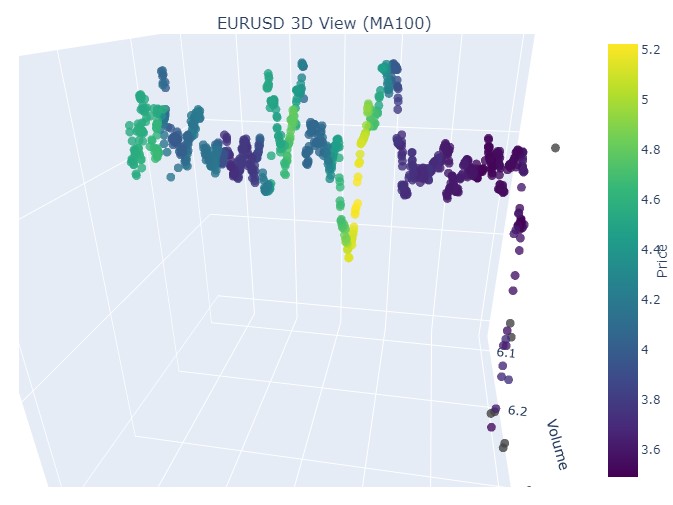
같은 그림을 다시 볼 수 있는데 이번에는 오직 노란색과 그 축적이 아래쪽에 있습니다. 흥미로워 보이네요.
2024년 8월 19일부터 2024년 8월 30일까지의 기간 중간에 추세가 정확히 반전되는 것을 볼 수 있습니다. 우리의 좌표를 살펴봅시다.
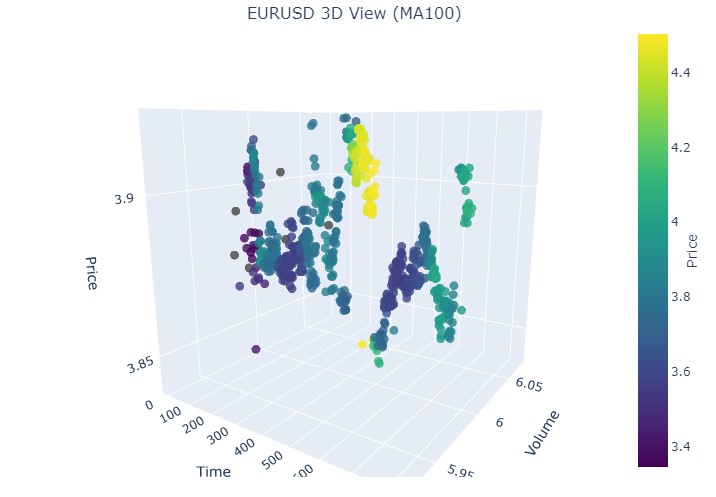
또다시 완전히 똑같은 사진입니다. 2024년 7월 17일부터 2024년 8월 8일까지의 기간을 살펴보겠습니다. 해당 모델이 곧 반전의 조짐을 보일까요?
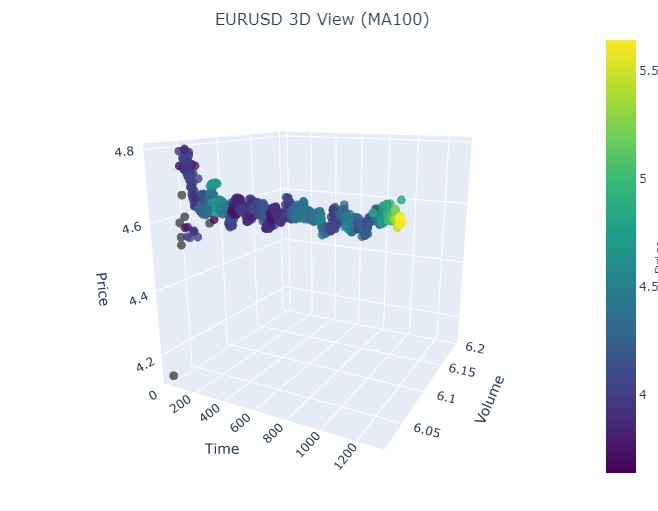
마지막 기간은 2023년 4월 21일부터 8월 10일까지입니다. 상승세는 거기서 끝났습니다.
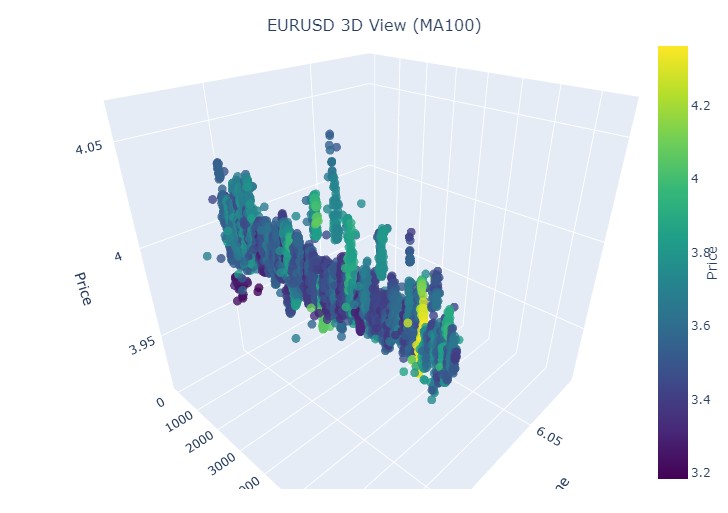
우리는 익숙한 노란색을 다시 보게 됩니다.
노란색 클러스터들
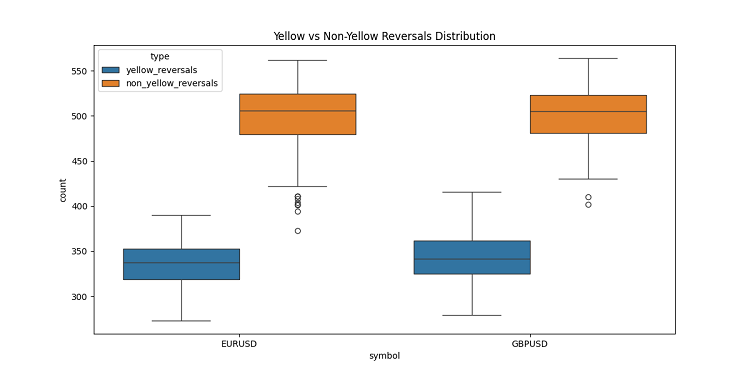
3차원 바를 개발하던 중 저는 매우 흥미로운 피처를 발견했습니다 - 노란색 볼륨-변동성 클러스터들 차트에서 이 클러스터들의 행동에 완전히 매료되었어요! 엄청난 양의 과거 데이터(정확히는 2022년부터 2024년까지 40만 개 이상의 바)를 분석한 결과 놀라운 사실을 발견했습니다.
처음에는 제 눈을 믿을 수 없었습니다 - 약 10만 개의 노란색 바 중 거의 전부(97%!)가 가격 반전 직전의 신호였기 때문입니다. 게다가 이는 플러스 마이너스 3바 범위 내에서였습니다. 흥미롭게도 반전 사례(총 약 16만 9천 건) 중 40%만이 노란색 바를 표시했습니다. 노란색 바가 나타나면 거의 확실하게 추세 반전이 일어나지만 노란색 바 없이도 반전이 발생할 수 있습니다.
이러한 추세를 더 자세히 살펴보니 명확한 패턴이 눈에 띄었습니다. 추세 초반과 추세 지속 기간 동안에는 노란색 바가 거의 없고 일반적인 3차원 바가 밀집되어 뭉쳐 나타납니다. 하지만 반전이 일어나기 전에는 노란색 크러스터들이 차트에서 밝게 빛납니다.
이는 특히 장기적인 추세에서 확연히 드러납니다. 예를 들어 2017년 초부터 2018년 2월까지 EURUSD의 상승세와 그 이후 2020년 3월까지의 하락세가 그러합니다. 두 경우 모두 이러한 노란색 크러스터들은 추세 반전 전에 나타났으며 그 3차원 배치는 말 그대로 가격이 어디로 갈지를 예측하게 해주었습니다!
저는 짧은 기간에 대해서도 테스트해 봤습니다 - 2024년에 2~3주씩 여러 번 이용해 봤습니다. 마치 시계처럼 정확하게 작동했어요! 추세 반전 직전에는 마치 경고처럼 노란색 바가 나타났습니다. "이봐, 이 추세가 곧 역전될 거야!"
이것은 단순한 지표가 아닙니다. 저는 우리가 시장 구조 자체에서 정말 중요한 부분을 발견했다고 생각합니다 - 바로 볼륨이 분배되는 방식과 추세 변화가 일어나기 전에 변동성이 변하는 방식. 이제 저는 3차원 차트에서 노란색 클러스터들이 보이면 추세 반전을 준비해야 할 때라는 걸 알게 됐습니다!
결론
3차원 바에 대한 탐구를 마무리하면서 이번 분석이 시장 미시구조에 대한 저의 이해를 얼마나 깊이 바꿔 놓았는지 말하지 않을 수 없습니다. 시각화 실험으로 시작된 것이 시장을 보고 이해하는 근본적으로 새로운 방식으로 발전했습니다.
저는 이 프로젝트를 진행하면서 전통적인 2차원적인 가격 표현 방식이 얼마나 많은 한계를 가지고 있는지를 계속해서 깨달었습니다. 3차원 분석으로의 전환은 가격, 볼륨 및 시간 간의 관계를 이해하는 데 완전히 새로운 지평을 열었습니다. 저는 중요한 시장 사건에 앞서 나타나는 패턴이 3차원 공간에서 얼마나 명확하게 드러나는지에 특히 깊은 인상을 받았습니다.
가장 중요한 발견은 잠재적인 추세 반전을 조기에 감지할 수 있다는 점이었습니다. 3차원 표현에서 나타나는 특징적인 볼륨의 축적과 색 구성의 변화는 향후 트렌드 변화를 예측하는 데 놀라울 정도로 신뢰할 수 있는 지표임이 입증되었습니다. 이는 단순한 이론적 관찰이 아니라 수많은 역사적 사례를 통해 확인된 사실입니다.
우리가 개발한 수학적 모델은 시장의 역학을 시각화 할 뿐만 아니라 정량적으로 평가할 수 있도록 해줍니다. 최신의 시각화 기술과 소프트웨어 도구의 통합으로 이 방법을 실제 거래에 적용하는 것이 가능해졌습니다. 저는 이러한 도구들을 매일 사용하고 있으며 이 도구들 덕분에 시장 분석에 대한 접근 방식이 크게 달라졌습니다.
하지만 저는 우리가 이제 막 여정의 시작점에 서 있다고 믿습니다. 이 프로젝트는 다변량 시장 미세구조 분석의 세계로 가는 문을 열어주었으며 이에 대한 추가적인 연구를 통해 더욱 흥미로운 발견들이 많이 나올 것이라고 확신합니다. 아마도 다음 단계는 3차원 패턴을 자동으로 인식하기 위해 머신러닝을 통합하거나 다변량 분석에 기반한 새로운 거래 전략을 개발하는 것이 될 것입니다.
궁극적으로 이 연구의 진정한 가치는 보기 좋은 도표나 복잡한 방정식에 있는 것이 아니라 시장에 대한 새로운 통찰력을 제공한다는 점에 있습니다. 연구자로서 저는 기술적 분석의 미래는 시장 데이터를 분석하는 다변량 접근 방식에 있다고 굳게 믿습니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/16555
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

왜 그럴까요? 평면 그래프만으로는 정확한 분석에 충분하지 않나요? 이것이 바로 일반 고등학교 기하학이 작동하는 방식입니다.
모든 알고리즘은 기본적으로 공간 차원을 탐구합니다. 알고리즘을 만들면서 우리는 다차원 탐색을 통해 조합 폭발이라는 근본적인 문제를 해결하려고 합니다. 이것이 바로 무한한 가능성의 바다를 항해하는 우리의 방식입니다.
(번역이 완벽하지 않다면 사과드립니다)
모든 알고리즘은 기본적으로 공간 차원을 탐색합니다. 우리는 알고리즘을 만들어 다차원 검색을 통해 조합 폭발이라는 근본적인 문제를 해결하려고 합니다. 이것이 바로 무한한 가능성의 바다를 항해하는 우리의 방식입니다.
(번역이 완벽하지 않다면 사과드립니다.)
이해했습니다. 단순한 학교 기하학 공식으로 트렌드 예측을 해결할 수 없다면, 사람들은 터보 슈퍼차저를 장착하고 스마트폰으로 제어하며 웃는 얼굴과 기타 반짝이가 달린 리사페드를 발명하기 시작합니다! 바퀴가 없다는 것만 빼면, 바퀴가 있어서는 안 되죠. 바퀴가 없으면 한 프레임으로 멀리 갈 수 없으니까요.
알겠습니다. 단순한 학교 기하학 공식으로 트렌드 예측을 해결할 수 없다면, 사람들은 스마트폰으로 제어할 수 있고 웃는 얼굴과 반짝이가 달린 터보 슈퍼차저를 장착한 리사페를 발명하기 시작합니다! 바퀴가 없다는 것만 빼면, 바퀴가 있어서는 안 되죠. 그리고 바퀴가 없으면 한 프레임으로는 멀리 갈 수 없습니다.