
외환 데이터 분석에서 연관 규칙 사용하기

연관 규칙 개념 소개
현대 알고리즘 거래는 새로운 분석 접근 방식을 필요로합니다. 시장은 끊임없이 변화하고 있으며 고전적인 기술적 분석 방법으로 복잡한 시장 관계를 파악하는 것은 더 이상 적합하지 않습니다.
저는 오랫동안 데이터 관련 업무를 해오면서 많은 성공적인 아이디어가 관련 분야에서 나온다는 것을 알게 되었습니다. 오늘은 거래에서 연관 규칙을 사용한 저의 경험을 공유하고자 합니다. 이 방법은 리테일 분석 분야에서 그 효과가 입증되었으며 우리로 하여금 구매, 거래, 가격 변동 및 미래의 수급 간의 연관성을 파악할 수 있게 해줍니다. 이를 외환 시장에 적용하면 어떨까요?
기본적인 아이디어는 간단합니다 - 가격 변동의 안정적인 패턴, 지표 및 그 조합을 찾는 것입니다. 예를 들어 EURUSD 환율 상승 후 USDJPY 환율이 하락하는 경우는 얼마나 자주 발생할까요? 강한 움직임에 앞서 가장 흔히 나타나는 조건은 무엇일까요?
이 글에서 저는 이러한 아이디어를 바탕으로 트레이딩 시스템을 구축하는 전체 과정을 보여드리겠습니다. 우리는 다음과 같이 할 것입니다:
- MQL5에서 과거 데이터를 수집합니다
- 파이썬으로 분석합니다
- 의미 있는 패턴을 찾습니다
- 그것들을 거래 신호로 전환합니다
왜 하필 이러한 과정으로 할까요? MQL5는 주식 시장 데이터 및 거래 자동화 작업에 매우 적합합니다. 파이썬은 분석을 위한 강력한 도구를 제공합니다. 제 경험상 이러한 조합은 거래 시스템 개발에 매우 효과적입니다.
코드에는 흥미로운 내용이 많이 포함될 것입니다. 특히 외환 거래에 연관 규칙을 적용하는 부분에서 그럴 것입니다.
과거 외환 데이터 수집 및 준비
우리에게 필요한 모든 데이터를 수집하고 준비하는 것은 매우 중요합니다. 지난 2년(2022년 이후) 주요 통화쌍의 H1 데이터를 기준으로 살펴보겠습니다.
이제 필요한 데이터를 수집하고 CSV 형식으로 내보내는 MQL5 스크립트를 작성해 보겠습니다.
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Python을 이용한 데이터 처리
데이터셋을 구성한 후에는 데이터를 올바르게 처리하는 것이 중요합니다.
이를 위해 저는 모든 번거로운 작업을 처리하는 특별한 ForexDataProcessor 클래스를 만들었습니다. 주요 구성 요소를 살펴보겠습니다.
데이터 로딩부터 시작하겠습니다. 우리의 함수는 주요 통화쌍인 EURUSD, GBPUSD, USDJPY 및 USDCHF의 매시간별 데이터를 사용하여 작동합니다. 데이터는 주요 가격 특성이 포함된 CSV 형식이어야 합니다.
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
데이터 로딩이 성공적으로 완료되면 가장 흥미로운 부분이 시작됩니다 - 기술 지표 계산. 여기서 저는 오랜 시간 검증된 다양한 도구들을 활용합니다. 이동평균은 다양한 기간의 추세를 파악하는 데 도움이 됩니다. SMA(50)은 종종 동적 지지 또는 저항의 역할을 합니다. 주기가 14인 RSI 오실레이터는 시장의 과매수 및 과매도 영역을 판단하는 데 유용합니다. MACD는 모멘텀과 반전의 지점을 파악하는 데 필수적입니다. 볼린저 밴드는 현재 시장의 변동성을 명확하게 보여줍니다.
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
데이터 이산화에는 특별한 주의를 기울여야 합니다. 모든 연속형 값은 명확한 범주로 분류되어야 합니다. 이 문제에 있어서는 황금률을 찾는 것이 중요합니다 - 너무 가파르게 나누면 패턴을 찾기가 어려워지고 너무 가깝게 나누면 중요한 시장 동향을 놓치게 됩니다. 예를 들어 추세를 파악하려면 간단한 방법이 더 효과적입니다 - 가격이 평균에 비해 어느 위치에 있는지로 나누는 방법:
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
캔들 패턴에도 역시 특별한 접근 방식이 필요합니다. 통계 분석을 바탕으로 저는 캔들 몸통의 크기가 가장 작은 경우를 도지(Doji)로, 극단적인 가격 변동을 보이는 경우를 Long_Bullish 또는 Long_Bearish로 구분합니다. 이러한 분류 체계를 통해 우리는 시장의 불확실한 움직임과 강한 충동적인 움직임을 명확하게 파악할 수 있습니다.
처리 과정이 끝나면 모든 통화쌍이 공통의 시간 척도를 가진 단일 데이터 배열로 결합됩니다. 이 단계는 기본적으로 중요합니다 - 왜냐하면 이를 통해 서로 다른 상품들 간의 복잡한 관계를 탐색할 가능성이 열리기 때문입니다. 이제 우리는 한 통화쌍의 추세가 다른 통화쌍의 변동성에 어떻게 영향을 미치는지 또는 캔들스틱 패턴이 전체 시장의 거래량과 어떻게 관련되는지 알 수 있습니다.
파이썬으로 Apriori 알고리즘 구현하기
데이터 준비를 마친 후 가장 중요한 단계로 넘어갑니다 - 금융 데이터에서 연관 규칙을 찾기 위한 Apriori 알고리즘 구현 단계입니다. 우리는 통화쌍 시계열 데이터를 사용하기 위해 원래 시장 바스켓 분석을 위해 개발된 Apriori 알고리즘을 적용합니다.
외환 시장에서 "거래"란 특정 시점의 다양한 지표와 통화쌍의 상태 집합을 의미합니다. 예를 들어:- EURUSD_Trend = 상승 추세
- GBPUSD_RSI_Zone = 과매수
- USDJPY_Volatility_Zone = 높음
이 알고리즘은 이러한 상태들이 빈번히 나타나는 조합을 찾아내고 이를 기반으로 거래 규칙을 생성합니다.
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
통화쌍 분석을 위한 연관 규칙 적용
저는 외환 시장에 맞게 Apriori 알고리즘을 적용하는 작업을 진행하면서 흥미로운 도전 과제들을 접하게 되었습니다. 이 방법은 원래 매장 내 구매 분석을 위해 개발되었지만 저에게는 외환 거래에 적용할 수 있는 잠재력이 충분히 있는것으로 보였습니다.
그러나 가장 큰 어려움은 외환 시장이 상점에서 일반적으로 쇼핑하는 것과는 근본적으로 다르다는 점이었습니다. 저는 금융 시장에서 수년간 일하면서 끊임없이 변하는 가격과 지표를 다루는 데에 익숙해져 있었습니다. 하지만 슈퍼마켓 영수증에서 그저 바나나와 우유 사이의 연관성을 찾는 알고리즘을 어떻게 적용할까요?
제 연구의 결과 다섯 가지 측정 기준으로 이루어진 시스템이 탄생했습니다. 저는 각각의 측정 기준을 꼼꼼하게 테스트했습니다.
'Support'라는 기준은 매우 까다로운 것으로 드러났습니다. 저는 이전에 실적이 매우 좋은 규칙을 거래 시스템에 포함시키려 했지만 support가 0.02에 불과했습니다. 다행히 제때 알아차렸어요 - 실제로 그런 규칙은 100년에 한 번밖에 적용되지 않거든요!
'Confidence'이라는 단어가 훨씬 더 간단하다는 것이 밝혀졌습니다. 만약 여러분이 시장에서 일하신다면 70%의 확률만으로도 훌륭한 지표라는 것을 바로 아실겁니다. 가장 중요한 것은 나머지 30%의 위험을 현명하게 관리하는 것입니다. 우리는 항상 위험 관리를 염두에 두어야 합니다. 그렇지 못할 경우 비록 성배를 손에 넣었다 하더라도 자금이 고갈되거나 심지어 완전히 날아갈 수도 있습니다.
'Lift'는 제가 가장 좋아하는 지표가 되었습니다. 수백 시간의 테스트 끝에 저는 한 가지 패턴을 발견했습니다. Lift 값이 1.5 이상인 규칙이 실제 시장에서 효과가 있다는 것입니다. 이 발견은 신호 분류에 대한 저의 접근 방식에 지대한 영향을 미쳤습니다.
'Leverage'를 다루는 일은 생각보다 재밌었습니다. 저는 처음에는 쓸모없다고 생각해서 시스템에서 아예 제외시키려고 했습니다. 하지만 시장 변동성이 특히 심했던 시기에 레버리지는 많은 잘못된 신호를 걸러내는 데 도움이 되었습니다.
포럼을 조사한 후 'Conviction'이 마지막으로 추가되었습니다. 이 지표는 제가 발견된 패턴의 실제 의미를 평가하고 이해하는 데 도움이 되었습니다.
제게 가장 놀라웠던 점은 알고리즘이 서로 다른 통화 쌍 사이에서 예상치 못한 연결고리를 찾아내는 방식이었습니다. 예를 들어 EURUSD의 특정 패턴이 USDJPY의 움직임을 그토록 정확하게 예측할 수 있을 거라고 누가 생각이나 했겠습니까? 저는 시장에서 9년간 일했지만 알고리즘이 발견한 관계들 중 상당수를 알아차리지 못했습니다. 페어 트레이딩, 바스켓 트레이딩, 차익거래가 한때 제 전문 분야였지만 cmillion이 통화쌍 간의 상호 움직임을 기반으로 로봇을 개발하기 시작했던 때를 아직도 기억납니다.
현재 저는 새로운 지표와 기간 사이의 조합을 시험하며 연구를 계속하고 있습니다. 시장은 끊임없이 변화하고 있으며 매일 새로운 발견이 이루어지고 있습니다. 다음 주에 저는 연간 데이터를 이용한 시스템 테스트 결과와 실제 데모 거래에서 알고리즘을 적용한 첫 번째 결과를 공개할 예정이며 거기에는 매우 흥미로운 발견들이 몇 가지 있습니다.
솔직히 말해 저는 이 프로젝트가 이렇게까지 발전할 줄은 전혀 예상하지 못했습니다. 이 모든 것은 데이터 마이닝을 활용한 간단한 실험과 분류 알고리즘의 요구 사항에 맞춰 시장의 모든 움직임을 엄격하게 분류하려는 시도에서 시작되었고 결국 완전한 거래 시스템으로 발전했습니다. 저는 이 접근 방식의 진정한 잠재력을 이제 막 이해하기 시작한 것 같습니다.
외환 거래를 위한 구현의 특징
이제 코드 자체로 돌아가 보겠습니다. 우리의 코드에는 금융 데이터 처리를 위해 차용한 알고리즘이 포함되어 있습니다:
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
이러한 그룹화는 보다 의미 있는 지표 조합을 찾는 데 도움이 되며 계산의 복잡성을 줄여줍니다.
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
우리는 통계적으로 유의미한 규칙(lift > 1.5)과 추세 지표 또는 RSI를 필수적으로 포함한 규칙만 선택합니다.
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
가중 점수는 거래에 대한 잠재적 유용성을 기준으로 규칙의 순위를 매기는 데 도움이 됩니다.
발견된 연관성의 시각화
연관 규칙을 찾은 후에는 이를 올바르게 시각화하고 분석해야 합니다. 이를 위해 저는 발견된 패턴을 시각적으로 분석할 수 있는 여러 가지 방법을 제공하는 특별한 ForexRulesVisualizer 클래스를 개발했습니다.
규칙 측정 지표의 분포
분석의 첫 번째 단계는 발견된 규칙의 주요 지표 분포를 이해하는 것입니다. 'support', 'confidence', 'lift' and 'leverage'의 분포 그래프는 발견된 규칙의 품질을 평가하고 필요한 경우 알고리즘의 매개변수를 조정하는 데 도움이 됩니다.
특히 유용했던 도구는 다양한 시장 상황 간의 연관성을 명확하게 보여주는 대화형 네트워크 그래프였습니다. 이 그래프에서 노드는 지표 상태이고(예: "EURUSD_Trend=Uptrend" 또는 "USDJPY_RSI_Zone=Overbought") 테두리는 발견된 규칙을 나타내며 테두리의 두께는 'lift’' 값에 비례합니다.
통화쌍 상호작용 히트맵 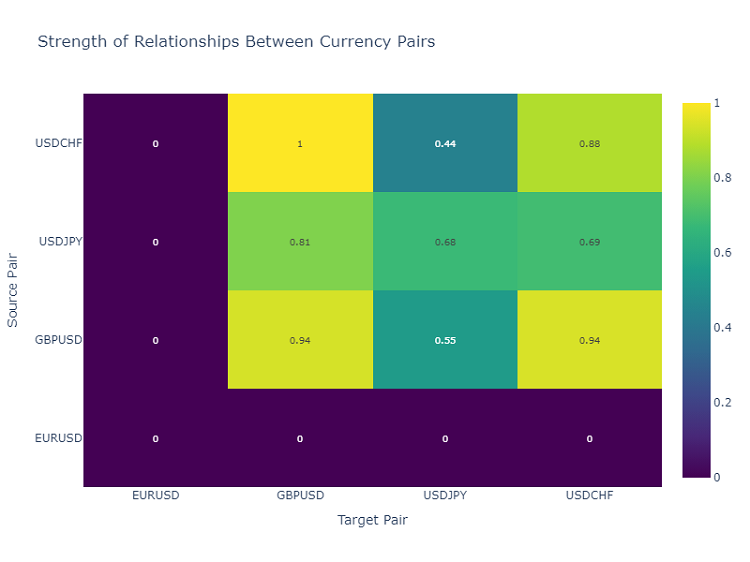
통화쌍 간의 관계를 분석하기 위해 저는 히트맵을 사용합니다. 히트맵은 다양한 금융 상품 간의 관계의 강도를 보여주며 서로에게 가장 자주 영향을 미치는 쌍을 식별하는 데 도움이 되고 이는 분산된 거래 포트폴리오를 구축하는 데 매우 중요합니다.
거래 신호 생성
연관 규칙을 찾아내고 시각화했다면 다음으로 중요한 단계는 이를 거래 신호로 변환하는 것입니다. 이를 위해 저는 시장의 현재 상태를 분석하고 발견된 규칙에 따라 거래 신호를 생성하는 ForexSignalGenerator 클래스를 개발했습니다.
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
규칙의 강도 평가
오랜 시간 동안 규칙을 시각화하는 실험을 거친 후 이제 가장 어려운 부분에 접어들었습니다 - 실제 거래 신호를 생성하는 단계 솔직히 저는 이 일 때문에 땀을 꽤 많이 흘렸습니다. 차트에서 아름다운 패턴을 발견하는 것과 그것을 실제로 작동하는 거래 시스템으로 바꾸는 것은 완전히 다른 얘기입니다.
저는 ForexSignalGenerator라는 별도의 모듈을 만들기로 결정했습니다. 처음에는 가장 강력한 규칙에 따라 신호를 생성하려고 했습니다. 그러나 곧 모든 것이 훨씬 더 복잡하다는 것을 깨달았습니다. 시장은 끊임없이 변화하며 어제 효과적이었던 규칙이 오늘은 통하지 않을 수도 있는 것이었습니다.
저는 규칙의 효력을 평가하는 데에 진지한 접근 방식을 취해야 했습니다. 여러 차례의 실험을 실패한 끝에 저는 스케일 시스템을 개발했습니다. 비율을 정하는 게 제일 어려웠습니다 - 아마 수십 가지의 조합을 시도해 봤을 겁니다. 결론적으로 저는 최종 평가에서 'lift'에 40%(이는 정말 중요한 지표입니다), 'confidence'에 30%, 'support'에 20%, ‘leverage'에 10%를 부여하기로 했습니다.
흥미롭게도 가장 강력한 신호가 얻어지는 경우는 규칙에 추세 요소가 포함되어 있을 때가 많았습니다. 저는 이러한 규칙의 효력에 특별히 20% 보너스를 추가했고 실제로 이것이 타당하다는 것이 입증되었습니다.
또한 저는 현재 시장 상황 분석을 처리하는데에 많은 노력을 기울여야 했습니다. 처음에는 단순히 지표의 현재 값과 규칙의 조건을 비교했습니다. 하지만 이후 저는 더 넓은 맥락을 고려해야 한다는 것을 깨달았습니다. 예를 들어 최근 몇 기간 동안의 일반적인 추세, 변동성 상태, 심지어 시간대까지 검증 항목에 추가했습니다.
현재 시스템은 각 통화 쌍에 대해 약 20개의 서로 다른 매개변수를 분석합니다. 제가 발견한 패턴 중 일부는 정말 놀라웠습니다.
물론 이 시스템은 아직 완벽하지는 않습니다. 가끔씩은 기본적인 요소들을 추가해야겠다는 생각이 들 때가 있습니다. 하지만 이 문제는 나중으로 미뤄두었습니다. 먼저 현재 버전을 마무리하고 싶습니다.
신호 정렬 및 집계
시스템 개발 과정에서 저는 단순히 규칙을 찾는 것만으로는 충분하지 않다는 것을 금방 깨달았습니다 - 우리는 신호의 품질을 엄격하게 관리해야 합니다. 몇 번의 실패한 거래 끝에 패턴을 찾는 것보다는 분류하는 것이 훨씬 더 중요하다는 사실이 분명해졌습니다.
저는 최소 규칙 강도에 대한 간단한 기준값부터 시작했습니다. 처음에는 0.5로 설정했는데 계속해서 지나친 긍적의 오탐이 발생했습니다. 2주간의 테스트 후 해당 값을 0.7로 올렸더니 상황이 눈에 띄게 개선되었습니다. 신호 수는 약 3분의 1로 줄었지만 신호의 질은 크게 향상되었습니다.
두 번째 분류 단계는 특히 불쾌감을 주는 한 사건 이후에 등장했습니다. 실적이 매우 좋은 규칙이 있었습니다. 그래서 그 규칙에 따라 포지션을 잡았는데 시장이 정반대 방향으로 움직였습니다. 조사해 보니 당시 다른 규칙들이 정반대의 신호를 보내고 있었다는 것을 알게 되었습니다. 그 이후로 저는 여러 규칙이 같은 방향을 가리킬 때만 일관성 검사를 진행하고 있습니다.
변동성에 대처하는 것은 흥미로운 일이었습니다. 저는 시장이 안정된 시기에는 시스템이 매우 안정적으로 작동하지만 시장이 활발해지기 시작하면 문제가 발생하기 시작한다는 것을 알게 되었습니다. 그래서 ATR을 기준으로 동적 필터를 추가했습니다. 지난 20일 동안 변동성이 75번째 백분위수를 초과하는 경우 우리는 규칙의 강도에 대한 요구 조건을 20% 높이는 것입니다.
가장 어려웠던 부분은 상충되는 신호들을 확인하는 것이었습니다. 어떤 규칙은 매수하라고 하고 어떤 규칙은 매도하라고 합니다. 그러나 모든 규칙에는 나름의 타당한 기준이 있습니다. 저는 여러 가지 접근 방식을 시도해 봤지만 결국 간단한 해결책에 도달했습니다: 신호에 중대한 모순이 있는 경우 해당 상황을 건너뛰는 것입니다. 그렇게 하면 우리는 몇 가지 기회를 놓치게 되지만 위험을 크게 줄일 수 있습니다.
저는 다음 달에 시간순 정렬 기능을 추가할 예정입니다. 특정 시간대에 규칙이 눈에 띄게 제대로 작동하지 않는다는 것을 알게 되었습니다. 이는 특히 유동성이 낮은 시기나 중요한 뉴스가 발표되는 시기에 두드러지게 나타납니다. 이렇게 하면 거래 성공률이 더욱 높아질 것으로 생각합니다.
테스트 결과
수개월에 걸쳐 시스템을 개발한 후 저는 중요한 질문에 직면했습니다 - 발견된 각 규칙의 강도를 어떻게 정확하게 평가할 것인가 하는 문제였습니다. 겉보기에는 간단해 보였지만 실제의 시장은 초기 접근 방식의 모든 약점을 빠르게 드러냈습니다.
오랜 실험 끝에 저는 여러 요소에 대한 가중치 시스템을 개발했습니다. 저는 'Lift'를 핵심 요소(영향력 40%)로 설정했습니다. 실제 경험에 비추어 볼 때 이는 매우 중요한 지표입니다. 'Confidence'는 30%를 차지합니다. 결국, 규칙에 대한 신뢰도 또한 매우 중요하기 때문입니다. 'Support'와 'leverage'에는 더 작은 가중치가 부여되었습니다 - 이들은 필터의 역할을 하는 것입니다.
신호 정렬은 별개의 문제였습니다. 처음에는 모든 규칙을 순서대로 지키면서 거래하려고 했지만 곧 저의 실수를 깨달았습니다. 그래서 저는 다단계 정렬 시스템을 도입해야 했습니다. 먼저 우리는 최소 강도 기준값을 기준으로 약한 규칙들을 걸러냅니다. 그런 다음 신호가 여러 규칙에 의해 확인되는지를 확인합니다. 일반적으로 단일 규칙만으로는 신뢰도가 떨어집니다.
변동성을 고려하는 것이 특히 중요한 것으로 드러났습니다. 시장이 안정된 시기에는 시스템이 완벽하게 작동했지만 변동성이 급증하자 잘못된 신호의 수가 급격히 증가했습니다. 저는 변동성이 증가함에 따라 더욱 엄격해지는 동적 필터를 추가해야 했습니다.
시스템 테스트에는 거의 석 달이 걸렸습니다. 저는 4개의 주요 쌍에 대해 2년간의 데이터를 분석해 보았습니다. 결과는 예상 밖이었습니다. 예를 들어 USDJPY는 RR 1.6으로 65%의 수익성 있는 거래를 기록하며 최고의 성과를 보였습니다. 하지만 GBPUSD는 실망스러웠습니다. 수익률은 58%에 불과했고 RR은 1.4였습니다.
흥미롭게도 'lift' 값이 2.0 이상이고 '신뢰도' 값이 0.8 이상인 규칙이 모든 쌍에 대해 일관되게 가장 좋은 결과를 보였습니다. 이러한 수치들은 외환 시장에서 일종의 자연적인 중요 기준값 의 역할을 하는 것으로 보입니다.
추가 개선 사항
현재의 시점에서 시스템 개선을 위한 몇 가지 방향이 보입니다. 첫째 규칙의 매개변수를 더욱 유연하게 만들어야 합니다 - 시장은 변화하고 있으며 시스템도 이에 맞춰 적응해야 합니다. 둘째로 거시경제 상황과 뉴스의 배경에 대한 고려가 명백히 부족합니다. 맞습니다, 시스템이 복잡해지겠지만 잠재적인 이점을 생각하면 그럴 만한 가치가 있습니다.
적응형 필터를 적용하는 것은 특히 흥미로워 보입니다. 시장의 각 단계에는 분명히 다른 시스템 설정이 필요합니다. 현재 구현 방식은 다소 미흡하지만 저는 벌써 개선할 수 있는 여러 가지 방법을 찾을 수 있습니다.
다음 주에는 포지션 크기를 동적으로 최적화하는 새로운 버전을 테스트할 계획입니다. 과거 데이터를 기반으로 한 예비적인 결과는 고무적이지만 언제나 그렇듯이 실제 시장은 자체적인 조정을 거칠 것입니다.
결론
알고리즘 거래에서 연관 규칙을 활용하면 명확하지 않은 시장 패턴을 발견할 수 있는 흥미로운 기회가 열립니다. 여기서 성공의 열쇠는 적절한 데이터 준비, 신중한 규칙 선택, 그리고 잘 설계된 신호 생성 시스템입니다.
모든 거래 시스템에는 지속적인 모니터링과 변화하는 시장 상황에 대한 적응이 요구되어진다는 점을 기억하는 것이 중요합니다. 연관 규칙은 강력한 분석 도구이지만 다른 기술적 분석 및 기본적 분석 방법과 함께 사용해야 합니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/16061
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

분명히 독자는 이미 그러한 방법에 대한 지식이 있어야한다고 가정하고 그렇지 않은 경우?
특히 언급 된 메트릭을 이해하지 못합니다:
리프트는 제가 가장 좋아하는 지표가되었습니다. 수백 시간의 테스트 끝에 저는 상승도가 1.5 이상인 규칙이 실제 시장에서 실제로 작동한다는 패턴을 발견했습니다. 이 발견은 신호 필터링에 대한 제 접근 방식에 심각한 영향을 미쳤습니다.
제가 이 방법을 올바르게 이해했다면 상관관계가 있는 신호는 양자 세그먼트에서 검색됩니다. 하지만 다음 단계는 이해하지 못했습니다. 그 다음 단계는 무엇인가요? 결과 규칙이 목표에 대해 확인되고 메트릭에 대해 평가된다고 가정합니다.
그렇다면 제 방식과 비슷하고 성능과 효율성을 평가하는 것이 흥미롭습니다.