
미래 트렌드의 추세를 파악하기 위한 핵심인 볼륨 기반의 신경망 분석

모든 거래가 점점 자동화되는 시대에 과거에 트레이더들이 받아들였던 격언들을 되새겨보는 것은 도움이 될 것입니다. 그 중 하나로 ‘거래량이 모든 것의 핵심’이라는 말이 있습니다. 실제로 기술적 분석과 볼륨 분석은 머신 러닝에 피처로 입력하기에 유용하고 매우 흥미로운 요소입니다. 어쩌면 올바른 해석을 통해 어떤 결과를 얻을 수 있을지도 모릅니다. 이글에서 우리는 LSTM 아키텍처를 이용하여 트레이딩 볼륨 및 볼륨 기반의 피처를 분석하는 접근 방식에 대해 알아볼 것입니다.
우리의 시스템은 볼륨에서 이상 현상을 분석하고 향후의 가격 변동을 예측합니다. 이 시스템의 주요 특징으로는 비정상 볼륨 감지, 볼륨 클러스터링, 그리고 Python과 MetaTrader 5 번들을 통해 직접 모델을 학습하는 것을 들 수 있습니다.
또한 우리는 결과를 시각화 하는 포괄적인 백테스팅을 진행할 예정입니다. 이 모델은 러시아 증시의 매시간 차트 주기의 차트에서 특히 높은 효율성을 보이며 이는 지난 1년간 스베르방크 주식의 과거 데이터를 이용한 테스트 결과에서도 확인되었습니다. 이 글에서는 시스템의 아키텍처, 작동 원리 및 실제 적용 결과를 자세히 살펴보겠습니다.
코드 분석: 데이터에서 예측까지
심층적으로 분석해보고 현재 볼륨에서 어떤 일이 일어나고 있는지 이해할 수 있는 시스템을 구축해 봅시다. 간단한 것부터 시작해 봅시다 - 바로 우리가 데이터를 수신하고 처리하는 방식입니다. 한편으로는 전혀 복잡하지 않습니다 - 데이터를 다운로드하고 바로 작업하면 됩니다. 하지만 언제나 그렇듯 문제는 세부적인 것에 있습니다.
데이터 출처: 더 자세히 알아보기
아래는 데이터 로딩 함수입니다.
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"MT5 data request: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
꽤 간단해 보입니다. 저는 더 쉬운 copy_rates_from 대신 일부러 copy_rates_range를 사용합니다. 왜냐하면 유동성이 낮은 상품을 거래할 때 0 값인 구간을 놓치지 않으려면 이것이 필요하기 때문입니다.
이후 우리는 피처와 지표를 다루기 시작할 것입니다.
전처리: 데이터 준비의 기술
피처를 하나하나 고르느라 시간을 낭비할 필요는 없습니다. 우선 가장 눈에 띄는 몇 가지 피처에 집중해 봅시다.
def preprocess_data(self, df): # Basic volume indicators df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # ML indicators df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
피처 선택을 다루는 것은 오케스트라를 조율하는 것과 같습니다. 각 피처는 데이터라는 교향곡 속에서 고유한 역할과 특정한 소리를 가지고 있습니다. 이제 기본 구성 요소를 살펴보겠습니다.
첫 번째 방법은 가장 간단합니다: 볼륨의 이동평균을 구하는 것입니다. 주기 5를 사용한 평균 볼륨은 아주 미세한 변동까지 포착하는 반면 주기 20을 사용한 평균 볼륨은 훨씬 더 강력한 볼륨 추세에 반응합니다.
볼륨과 평균 볼륨의 비율 또한 흥미로울 수 있습니다. 미래에 급격한 변동이 있을 때에는 강력한 가격 충격이 발생하는 경우가 매우 흔합니다.
또한 최근 24개 캔들 동안의 가격 모멘텀과 볼륨 모멘텀을 살펴봅니다.
볼륨 변동성이라는 더욱 흥미로운 피처가 있습니다. 저는 이것을 시장의 불안감을 나타내는 지표라고 부를 것입니다. 볼륨 변동성이 증가하는 경우 이는 주요 시장 참여자들이 시장에 대규모 자금을 투입하고 있다는 것을 나타낼 수 있습니다.
우리의 모델은 가격과 볼륨의 상관관계도 고려합니다. 마지막으로 우리는 이 모든 징후들을 직접 확인하고 새롭게 만든 지표들을 시각화해 볼 것입니다.
성능 병목 현상
시스템 과부하를 방지하기 위해 데이터 일괄 처리 및 병렬 컴퓨팅을 구현할 수 있습니다. 다른 말로 하면 데이터를 작은 조각으로 나누어 병렬로 처리하는 것입니다.
이 간단한 기술은 데이터 처리 속도를 몇 배로 높여줄 뿐만 아니라 대용량 데이터 처리 시 발생하는 메모리 누수 문제도 방지해 줍니다.
이 글의 다음 부분에서는 가장 흥미로운 부분인 시스템이 비정상적인 볼륨을 감지하는 방법과 그 이후에 발생하는 상황에 대해 알아보겠습니다.
'검은 백조'를 찾아서: 비정상적인 볼륨을 어떻게 알아볼 수 있을까요?
여러분 모두 비정상적인 볼륨이 무엇인지 그리고 차트에서 어떻게 확인하는지에 대해 들어봤을 것이고 아마 경험 많은 트레이더라면 누구나 알아챌 수 있을 겁니다. 하지만 이를 어떻게 코드에 반영할 수 있을까요? 이러한 자료들을 검색하는 논리를 어떻게 형식화 할 수 있을까요?
이상 현상 탐색
일련의 실험 끝에 이 부분에 대해 저는 아이솔레이션 포레스트(Isolation Forest) 방법을 채택하게 되었습니다. 왜 이 방법을 사용하게 되었을까요? 그건 z-점수나 백분위수 점수 같은 고전적인 방법은 국소적인 이상치, 즉 작은 이상치를 놓칠 수 있지만 중요한 것은 절대값이나 백분율이 아니라 다른 볼륨들과는 확연히 구분되는, 즉 일반적인 맥락에서 벗어난 볼륨들입니다.
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
물론 매개변수를 조정해 보는 것이 더 좋겠지만 BGA와 같은 알고리즘을 사용하여 모든 모델 설정을 선택하는 것이 훨씬 더 나은 해결책일 것입니다. 저는 교과서적으로 권장하는 값인 0.05로 설정했는데 이는 5%의 이상치에 해당합니다. 하지만 실제 시장은 상상보다 훨씬 더 시끄럽습니다. 따라서 기준이 조금 높아졌습니다. 또한 가격 변동과 함께 이상 징후를 직접 눈으로 확인하는 것도 유용할 것입니다(이 주제는 아래에서 다시 다루겠습니다).
클러스터링: 패턴 찾기
이상치만으로는 정확한 예측이 불가능합니다. 볼륨 클러스터링도 필요합니다. 우리는 다음과 같은 클러스터링 옵션에 집중할 것입니다.
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
클러스터링에 선택된 피처는 매우 간단합니다. 실제 볼륨만을 기준으로 클러스터링 하는 것은 이상할 것 같습니다. 그렇지 않다면 우리가 왜 피처와 지표를 만들겠습니까? 하지만 피처의 수와 볼륨 지표는 개선될 여지가 있습니다.
제가 세 개의 클러스터를 선택한 이유는 모든 볼륨을 조건에 따라 "배경 또는 축적" 볼륨, "실행 및 움직임" 볼륨, "극단적인 움직임" 볼륨으로 나누기 위해서입니다.
예상치 못한 발견
데이터를 분석한 결과 몇 가지 패턴과 순서가 나타났습니다. 예를 들어 비정상적인 볼륨 다음에 세 번째 볼륨 클러스터가 나타나고 그 다음에는 활성 볼륨이 나타나며 그제서야 시세가 한 방향 또는 다른 방향으로 움직입니다.
이는 특히 주식 시장 개장 후 첫 몇 시간 동안 두드러지게 나타납니다. 여기서는 클러스터와 그에 따른 가격 변동을 보여주는 히트맵을 만드는 것이 유용할 거 같습니다.
신경망: 머신이 시장을 읽도록 훈련시키는 방법
저는 신경망을 오랫동안 사용해 왔습니다. 따라서 볼륨 분석에 신경망을 적용하는 것이 당연할 것입니다. 제가 아직 LSTM 아키텍처를 사용해 본 적은 없지만 다른 분야에서 이 아키텍처의 사례를 보고 나서 드디어 한번 시도해 보기로 했습니다.
좀 더 자세히 살펴보겠습니다.
아키텍쳐: 적을수록 좋다
간단할수록 좋다. 저는 놀랍도록 간단한 아키텍처를 고안해냈습니다.
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
언뜻 보면 전체 아키텍처는 매우 원시적으로 보입니다. LTSM 레이어 두 개와 선형 레이어 하나로 구성되어 있습니다. 하지만 진정한 힘은 단순함에 있습니다. 왜냐하면 안타깝게도 딥러닝을 통해 더 광범위한 네트워크를 구축할 경우 과적합이 발생하기 때문입니다. 처음에 저는 LSTM 레이어 3개, 추가적인 완전 연결 레이어, 그리고 복잡한 드롭아웃 구조를 갖춘 훨씬 더 복잡한 네트워크를 구축했었습니다. 결과는 놀라웠습니다... 테스트 데이터에 따르면 말입니다. 하지만 그 네트워크가 실제 장기 시장에 직면하자마자 모든 것이 무너졌습니다. 과적합 현상이 관찰된 것입니다.
과적합과의 전쟁
과적합은 현대 신경망의 가장 큰 문제입니다. 신경망은 테스트 데이터 영역에서 관계를 찾는 학습에는 탁월하지만 실제 시장 상황에서는 완전히 쓸모 없어집니다. 제시된 아키텍처에서 이 문제를 해결하기 위해 제가 시도한 구체적인 방법은 다음과 같습니다.
- 단일 계층으로는 볼륨과 가격 간의 복잡한 관계를 처리할 수 없습니다.
- 세 개의 계층은 실제로는 존재하지 않는 연결 고리를 찾아낼 수 있습니다.
은닉층의 크기는 일반적인 방식대로 64개의 뉴런으로 선택되었습니다. 더 많은 뉴런을 사용하는 것이 더 나을 수도 있습니다. 향후 과적합 문제를 해결할 수 있는 효과적인 솔루션이 나오게 되면 더 많은 뉴런을 가진 더욱 복잡한 아키텍처를 사용할 수 있을 것입니다.
입력 데이터: 피처 선택의 기술
훈련에 사용할 입력 피처들을 살펴보겠습니다:
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
우리는 다양한 피처들을 가지고 많은 실험을 해볼 수 있습니다. 기술적 지표 그리고 가격, 볼륨에서 파생되는 우리가 원하는 무엇이든 추가할 수 있습니다. 하지만 피처가 많다고 해서 항상 예측의 정확도가 향상되는 것은 아니라는 점을 기억하세요. 겉보기에 가장 논리적인 피처처럼 보이는 것조차 사실은 데이터 속의 단순한 노이즈일 수 있습니다.
여기서 'volume_cluster'와 'is_anomaly'의 조합이 흥미로워 보입니다. 개별적으로 피처는 평범하지만 이 둘을 같이 고려하면 매우 흥미롭습니다. 특정 클러스터에 비정상적인 볼륨이 집중적으로 나타날 경우 이는 예측에 특이한 영향을 미칩니다.
예상치 못한 발견
우리의 시스템은 가격 변동폭이 큰 시기에 가장 효과적인 것으로 나타났습니다. 또한 대부분의 트레이더들이 찾아내기 어렵다고 여기는 횡보장이나 조정장에서도 뛰어난 성능을 발휘합니다. 바로 이런 순간에 이상 징후 및 볼륨 클러스터를 분석하는 시스템은 우리의 시각으로는 볼 수 없는 것을 포착합니다.
다음 섹션에서는 이 시스템이 실제 거래에서 어떻게 작동했는지 알아보고 신호의 구체적인 사례를 공유하겠습니다.
예측부터 거래까지: 신호를 수익으로 전환하기
알고리즘 트레이더라면 누구나 알고 있습니다: 단순한 예측 모델만으로는 충분하지 않습니다. 이를 실제의 거래 전략으로 발전시켜야 합니다. 하지만 우리의 모델을 실제로 어떻게 적용할까요? 이 문제를 해결해 봅시다. 이 글의 다음 부분에서는 딱딱한 이론뿐 아니라 실제 테스트 거래를 통해 알고리즘을 강화하고 과적합 문제를 해결하는 실질적인 내용을 다룰 예정입니다 그러나 지금은 연구의 일반적인 이론적인 부분을 먼저 살펴보겠습니다.
거래 신호 분석
거래 전략을 개발할 때 핵심 요소 중 하나는 거래 신호를 생성하는 것입니다. 제 전략에서는 다음 기간의 예상 수익률을 반영하는 모델 예측을 기반으로 신호를 생성합니다.
def backtest_prediction_strategy(self, df, lookback=24): # Generating signals based on predictions df['signal'] = 0 signal_threshold = 0.001 # Threshold 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1
신호 기준값 선택
한편으로는 기준값을 단순히 0보다 높게 설정할 수 있습니다. 그럴 경우 많은 신호가 생성되지만, 스프레드, 수수료 및 시장 잡음으로 인해 신호에 노이즈가 포함될 것입니다. 이러한 접근 방식은 수많은 가짜 신호를 발생시켜 전략 효율성에 부정적인 영향을 미칠 수 있습니다.
따라서 가장 합리적인 결정은 예상 수익성 기준치를 0.1%~0.2%로 높이는 것으로 보입니다. 이를 통해 대부분의 잡음을 제거하고 수수료를 줄일 수 있습니다. 중요한 가격 변동이 예측될 때만 신호가 생성되기 때문입니다.
signal_threshold = 0.001 # Threshold 0.1%
쉬프트를 고려한 신호 적용
신호가 생성되면 24기간 전진 쉬프트 변동을 고려하여 가격에 적용됩니다. 이를 통해 우리는 거래 결정과 실행 사이의 시간차를 고려할 수 있습니다.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
24주기의 쉬프트는 생성된 신호의 시간이 t 일 경우 t + 24 시간의 가격에 적용됩니다. 이는 거래 결정이 실제로는 즉시 실행될 수 없기 때문에 중요합니다. 이러한 접근 방식은 거래 전략의 효율성을 보다 현실적으로 평가할 수 있도록 해줍니다.
전략 수익성 계산
전략의 수익성은 쉬프트된 신호와 가격 변동의 곱으로 계산됩니다.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
신호가 1.과 같으면 전략 수익성은 가격 변동(price_change)과 같을 것입니다. 신호가 -1과 같으면 전략 수익성은 음수의 가격 변동(-price_change)과 같을 것입니다. 신호가 0과 같으면 전략의 수익성은 0이 될 것입니다.
따라서 신호를 24기간만큼 이동시켜 우리가 거래 결정과 실행 사이의 시차를 고려할 수 있게 되면 전략 효율성의 평가를 더욱 현실적으로 할 수 있습니다.
황금비율
수주간의 테스트 끝에 저는 0.1%라는 기준값을 선택했습니다. 이유는 다음과 같습니다:
- 이 기준값에서 시스템은 상당히 빈번하게 신호를 생성합니다.
- 거래의 약 52~63%가 수익성이 있습니다.
- 거래당 평균 수익은 수수료의 약 2.5배입니다.
가장 특이한 발견은 대부분의 가짜 신호 또한 특정 시간대에 집중될 수 있다는 점입니다. 원하신다면 여러분 또한 그러한 시간 필터를 고려해 볼 수 있으며 이는 이 글의 다음 부분에서 자세히 살펴볼 것입니다.
def apply_time_filter(self, df): # We trade only during active hours trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
위험 관리
포지션 확보의 로직과 진입한 거래를 관리하는 로직(거래 중 거래 지원)는 별개의 이야기입니다. 한편으로 가장 확실한 해결책은 고정된 손절매 및 이익 실현 가격을 사용하는 것이지만 시장은 너무 예측 불가능하고 역동적이어서 손익의 제한을 일반적인 정형화된 논리로 설명하기는 쉽지 않습니다.
우리의 해결책은 아주 간단합니다 - 예측된 변동성을 이용하여 손절매를 동적으로 설정하는 것입니다.
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
이 접근 방식 또한 추가적인 검증이 필요합니다. 또한 VaR 위험 분석 모델을 적용하여 이 오래되었지만 신뢰할 수 있는 효과적인 시스템에 따라 손절 혹은 익절의 시점을 선택할 수도 있습니다.
예상치 못한 발견
흥미로운 점은 연속적인 신호들이 매우 큰 변동을 예측할 수 있다는 것입니다. 또한 시장 변동성이 평균적으로 매우 급격하게 상승할 경우 우리의 기준치는 더 이상 효과적인 거래를 위한 충분한 근거가 되지 못하게 되는 문제가 발생하기도 합니다. 차트를 자세히 살펴보면 하락세가 나타나는 기간은 높은 변동성과 정확히 일치합니다. 하지만 우리에게는 이것이 문제가 되지 않습니다! 우리는 다음 섹션에서 이 문제를 해결하고 제거할 것입니다.
시각화 및 로깅: 데이터의 홍수에 파묻히지 않는 방법
로깅 시스템을 잊지 않는 것 또한 매우 중요합니다. 일반적으로 디버깅 단계에서는 출력, 로그, 출력 결과 및 프로그램 주석과 관련된 모든 것이 중요합니다. 이렇게 하면 코드의 문제점을 매우 빠르고 효율적으로 찾아낼 수 있습니다.
로깅 시스템: 세부 사항이 중요합니다
로깅 시스템은 간단하지만 효율적인 형식을 기반으로 합니다.
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG)
그게 왜 그렇게 어렵냐고 물으실 수도 있겠죠. 저는 시스템이 특정 시점에 포지션을 보유하는 이유를 이해하지 못해 여러 번 고생한 끝에 이 형식을 발견했습니다.
이제 시스템의 모든 동작은 로그에 명확한 흔적을 남깁니다. 또한 비정상적인 볼륨과 관련된 순간들도 꼼꼼히 기록합니다:
self.logger.info(f"Abnormal volume detected: {volume:.2f}") self.logger.debug(f"Context: cluster {cluster}, volatility {volatility:.4f}")
시각화도 필요합니다. 수동 거래 경험을 통해 모든 것을 시각적으로 관찰하는 습관이 생겼습니다. 마치 가장 일반적인 차트를 보는 것처럼 데이터를 살펴보는 것입니다. 다음은 시각화 코드입니다:
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # Price and signal chart plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Price', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Buy')
첫 번째 그래프는 획득한 모델 신호가 포함된 Sber 가격의 가장 일반적인 차트입니다. 또한 비정상적인 볼륨을 보이는 캔들을 강조 표시하여 신호를 보완합니다. 이를 통해 우리는 시스템이 마치 펼쳐진 책처럼 시장을 완벽하게 읽어내는 순간을 알 수 있습니다.
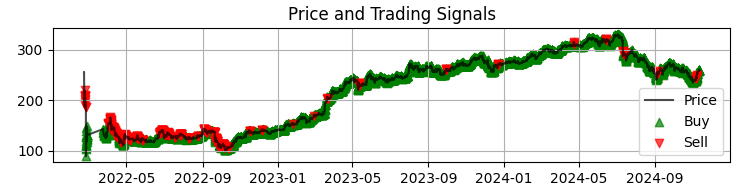
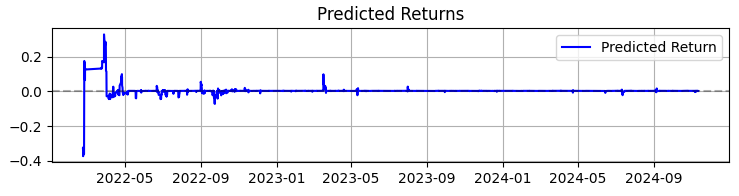
두 번째 그래프는 예상 수익률입니다. 여기서 우리는 선택한 자산의 호가의 급격한 변동이 일어나기 전에 매우 강력한 일련의 예측들이 시작되는 것을 분명히 알 수 있습니다. 따라서 이는 이러한 특정한 관찰 결과를 바탕으로 시스템을 구축하는 것이 우리가 고려해 볼 만한 아이디어라는 것을 보여줍니다. 물론 거래 건수는 줄어들겠지만 우리는 양을 쫓는 게 아니라 질을 추구하는 것 아닙니까?
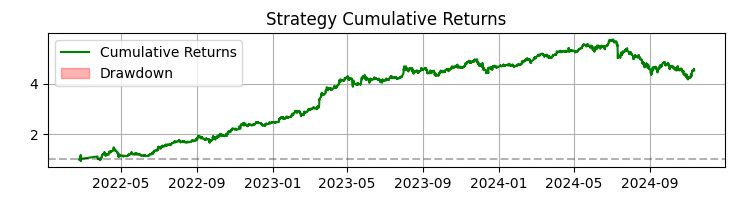
세 번째 차트는 누적 수익률을 나타내며 최저 손실 구간이 강조 표시되어 있습니다.
이론에서 실전으로: 결과 및 전망
시스템 운영 결과를 요약해 보겠습니다 - 단순히 수치만 나열하는 것이 아니라 볼륨 분석에 관심 있는 모든 사람에게 도움이 될 만한 유용한 정보들이 드러납니다.
첫째 시장은 거래 회전율과 볼륨을 통해 우리에게 메시지를 전달합니다. 하지만 이는 여러분이 상상하는 것보다 훨씬 더 복잡합니다. 제 개인적인 생각으로는 VSA와 같은 고전적인 방법들은 시장의 빠른 발전 속도를 따라가지 못하고 빠르게 구식으로 전락하고 있습니다. 패턴은 점점 더 복잡해지고 있으며 볼륨은 육안으로는 거의 알아볼 수 없을 정도로 매우 복잡한 패턴을 형성합니다.
전반적으로 제가 약 3년간의 머신 러닝 경험을 바탕으로 간략하게 요약하자면 시장은 매년 더욱 복잡해지고 있으며 그 시장에서 작동하는 알고리즘, 특히 추세를 형상하고 주문 흐름(OrderFlow)을 통해 축적되는 알고리즘 또한 더욱 복잡해지고 있다는 것입니다. 우리 앞에는 신경망 전쟁 즉 기계들간의 전쟁이 벌어지고 있으며 시장은 어느 기계가 더 효율적일지를 결정하고 있는 것입니다.
이 시스템에 대한 연구 결과를 요약하면서 저는 수치뿐 아니라 볼륨 분석 분야에 종사하는 모든 분들에게 유용할 수 있는 주요 발견 사항들을 공유하고 자합니다.
SBER 주식에 대해 365일 이상 동안 해당 시스템은 인상적인 결과를 보여주었습니다.
- 총 수익률: 연 365.0% (레버리지 미사용 시)
- 수익성 있는 거래 비중: 50.73%
하지만 이러한 수치는 그렇게 중요한 것이 아닙니다. 더욱 중요한 것은 이 시스템이 다양한 시장 상황에 대해 회복력을 입증했다는 점입니다. 추세장과 횡보장세 모두에서 똑같이 잘 작동하지만 신호의 성격은 눈에 띄게 달라집니다.
변동성이 높은 기간 동안 시스템의 동작 방식은 특히 흥미로운 것으로 나타났습니다. 대부분의 거래자들이 시장에 참여하지 않는 시간에 신경망은 볼륨 흐름에서 가장 명확한 패턴을 찾아냅니다. 아마도 이는 그러한 시간에 기관들이 자신들의 행동에 대한 더 명확한 "흔적"을 남기기 때문일 것입니다.
이 프로젝트를 통해 배운 점- 트레이딩에서 머신 러닝은 만병통치약이 아닙니다. 성공은 오직 시장에 대한 깊은 이해와 세심한 피처 설계에서 나오는 것입니다.
- 단순함이 지속가능성의 핵심입니다. 새로운 레이어나 기능을 추가하여 모델을 복잡하게 만들려고 할 때마다 시스템은 점점 더 약해졌습니다.
- 볼륨은 맥락 속에서 분석해야 합니다. 비정상적인 볼륨이나 클러스터만으로는 큰 의미가 없습니다. 다른 요인들과의 상호작용을 살펴보면 진정한 마법이 시작됩니다.
다음 단계는 무엇일까요?
시스템은 계속해서 진화하고 있습니다. 저는 현재 몇 가지 개선 작업을 진행 중입니다.
- 시장 상황에 따른 적응형 파라미터 조정
- 보다 정확한 분석을 위한 스트리밍 주문 통합
- 러시아 시장의 다른 금융 상품으로의 확장
시스템 소스 코드는 첨부 파일에서 확인할 수 있습니다. 시스템 개선을 위한 여러분의 제안을 환영합니다. 특히 이 시스템을 다른 도구에 적용해 보려는 분들의 경험을 들어보는 것은 흥미로울 것 같습니다.
결론
최근 몇 달 동안 저에게 가장 가치 있는 발견은 오늘 논의한 볼륨 분석과 같은 고전적인 접근 방식을 머신 러닝, 신경망, 빅 데이터와 같은 새로운 기술에 적용한 것입니다.
다시 보니 이전 세대의 경험은 여전히 생생하게 살아 숨 쉬고 있었습니다. 우리의 과제는 이러한 경험을 분석하고 핵심을 파악하고 최신 기술을 활용하여 우리 세대 트레이더의 관점에서 개선하는 것입니다. 물론 우리는 현대 시대에 뒤처질 수 없습니다: 양자 머신 러닝, 가격 및 볼륨 예측을 위한 양자 알고리즘, 그리고 머신 러닝을 위한 다차원적 피처 등이 우리 앞에 놓여 있습니다. 저는 이미 IBM의 20큐비트 양자 슈퍼컴퓨터를 이용한 시장 분석을 시도해 봤습니다. 결과가 흥미롭네요. 앞으로 나올 기사에서 자세히 알려드리겠습니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/16062
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

