
주식시장 예측을 위한 비선형 회귀 모델

소개
어제 저는 또다시 저의 회귀 분석 기반 트레이딩 시스템의 보고서를 검토하고 있었습니다. 창밖으로는 습설이 내리고 있었고 머그잔 속 커피는 식어가고 있었지만 저는 여전히 그 강박적인 생각을 떨쳐낼 수 없었습니다. 아시다시피 저는 끝없이 쏟아지는 RSI, 스토캐스틱, MACD 등의 지표들에 오랫동안 짜증을 느껴왔습니다. 어떻게 하면 살아 숨 쉬는 역동적인 시장을 이러한 원시적인 방정식에 끼워 맞출 수 있을까요? 유튜브에서 자신만의 "신성한" 지표 세트를 내세우는 사람들을 볼 때마다 저는 그저 이렇게 묻고 싶어집니다 - "도대체 당신은 70년대나 쓰이던 그런 계산기들이 현대 시장의 복잡한 역학을 포착할 수 있다고 진심으로 믿는 겁니까?"
저는 지난 3년 동안 실제로 작동하는 무언가를 만들려고 노력해 왔습니다. 저는 가장 간단한 회귀 분석부터 정교한 신경망에 이르기까지 다양한 방법을 시도해 봤습니다. 그리고 어떻게 되었는지 아세요? 분류에서는 결과를 얻었지만 회귀에서는 아직 얻지 못했습니다.
매번 똑같은 이야기가 반복됐습니다 - 과거 히스토리 데이터에서 시험하면 모든게 시계처럼 정확하게 돌아가지만 막상 실제 시장에 내놓으면 손실을 봅니다. 처음 합성곱 신경망을 접했을 때 제가 얼마나 흥분했는지 기억납니다. 훈련 시 R2는 1.00%이었습니다. 이후 2주간 거래를 하고는 예치금의 30%를 손실했습니다. 과적합의 전형이었습니다. 회귀 분석 기반 예측치가 시간이 지남에 따라 실제 가격과 점점 더 멀어지는 것을 지켜보면서 저는 전방 시각화 기능을 계속 활성화했습니다.
하지만 저는 한다면 하는 사람입니다. 또 한 번의 패배를 겪은 후 저는 더 깊이 파고들어 과학 논문들을 샅샅이 뒤지기 시작했다. 그리고 제가 묵혀둔 자료실에서 뭘 발견했는지 아세요? 알고 보니 만델브로트는 이미 시장의 프랙탈적 성질에 대해 끊임없이 이야기하고 있었습니다. 우리 모두는 선형 모델을 사용하여 트레이딩을 하려고 노력하고 있습니다! 이는 마치 자로 해안선의 길이를 재는 것과 같습니다. 정확하게 재면 잴수록 길이가 더 길어지는 것처럼 말이죠.
어느 순간 저는 이런 생각이 떠올랐습니다: 고전적인 기술적 분석과 비선형적 역학을 결합해 보면 어떨까? 이런 조잡한 지표들이 아니라 미분방정식이나 적응 계수 같은 훨씬 더 진지한 분석들로 말입니다. 복잡하게 들리실지 모르지만 이러한 시도는 본질적으로는 시장의 언어로 소통하는 법을 배우려는 시도일 뿐입니다.
저는 파이썬을 가지고 머신러닝 라이브러리를 연결한 후 실험을 시작했습니다. 저는 곧바로 결심했습니다 - 학문적인 화려함은 필요 없고 실제로 쓸 수 있는 것만 있으면 된다. 슈퍼 컴퓨터는 필요 없습니다. 일반 에이서 노트북과 초강력 VPS, 그리고 MetaTrader 5 터미널만 있으면 됩니다. 이 모든 것을 바탕으로 제가 여러분께 소개드리고 싶은 모델이 탄생했습니다.
그것은 성배가 아닙니다. 성배는 존재하지 않는다는 걸 저는 오래전에 깨달았어요. 저는 현대 수학을 실제 트레이딩에 적용한 경험을 공유하고 있을 뿐입니다. 불필요한 과장도 없고 그렇다고 "추세 지표"에 대한 원시적인 접근도 없습니다. 그 결과는 그 중간쯤 되는 것이었습니다: 작동할 만큼 충분히 똑똑하지만 첫 번째 블랙 스완에 직면했을 때 무너지지 않을 정도로 너무 복잡하지는 않았습니다.
수학적 모델
저는 이 방정식을 어떻게 생각해냈는지 기억합니다. 저는 2022년부터 이 코드를 작업해 왔습니다. 그러나 꾸준히 해온 것은 아닙니다: 접근 방식을 말씀드리자면 여러분들은 여러 가지 개발할 것들이 있을 것입니다. 그러니 주기적으로 (다소 무질서하게) 하나씩 검토하고 결과를 도출해내면 되는 것입니다. EURUSD 차트를 분석하면서 패턴을 포착하려고 했던 기억이 납니다. 그리고 제 눈길을 사로잡은 게 뭔지 아세요? 시장은 마치 숨을 쉬는 것 같습니다 - 때로는 추세를 따라 부드럽게 흐르다가 때로는 갑자기 급격하게 요동치고 때로는 어떤 마법 같은 리듬에 들어가기도 합니다. 이것을 수학적으로 어떻게 설명할 수 있을까요? 이러한 역동성을 방정식으로 어떻게 포착할 수 있을까요?
이렇게 저는 방정식의 첫 번째 버전을 스케치했습니다. 바로 이것이 그 영광스런 모습입니다:
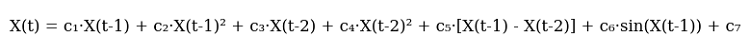
코드는 다음과 같습니다.
def equation(self, x_prev, coeffs): x_t1, x_t2 = x_prev[0], x_prev[1] return (coeffs[0] * x_t1 + # trend coeffs[1] * x_t1**2 + # acceleration coeffs[2] * x_t2 + # market memory coeffs[3] * x_t2**2 + # inertia coeffs[4] * (x_t1 - x_t2) + # impulse coeffs[5] * np.sin(x_t1) + # market rhythm coeffs[6]) # basic level
모든 게 얼마나 뒤틀려 있는지 봐 보세요. 처음 두 용어는 현재 시장 움직임을 포착하려는 시도입니다. 자동차가 가속하는 원리를 아시나요? 처음에는 부드럽게 그러다 점점 더 빠르게. 그래서 이 식에는 선형항과 이차항이 모두 있는 것입니다. 가격이 안정적으로 움직일 때는 선형적인 부분이 작용합니다. 하지만 시장이 가속화되는 순간 이차항이 그 움직임을 포착합니다.
이제 가장 흥미로운 부분이 나옵니다. 세 번째와 네 번째 항목은 과거를 좀 더 깊이 들여다봅니다. 마치 시장의 기억과 같습니다. 시장이 과거 수준을 기억한다는 다우 이론을 기억하시나요? 여기도 마찬가지입니다. 2차 가속도를 특징으로 합니다 - 시장이 급커브를 할 때를 대비해서 말입니다.
이제 모멘텀 컴포넌트를 살펴보겠습니다. 현재 가격에서 이전 가격을 빼면 됩니다. 원시적으로 보일 것입니다. 하지만 트렌드 변화에는 아주 효과적입니다! 시장이 과열되어 한 방향으로 흐를 때 이 용어는 예측을 하는 주요 원동력이 됩니다.
사인(Sine)은 거의 우연히 추가되었습니다. 차트를 살펴보던 중 저는 어떤 주기성을 발견했습니다. 특히 H1 기간에 그렇습니다. 횔동적이던 기간과 평온한 기간이 번갈아 이어졌습니다... 사인파처럼 보이죠? 제가 사인파를 방정식에 대입하자 모델은 마치 깨달음을 얻은 듯 이러한 리듬을 포착하기 시작했습니다.
마지막 계수은 일종의 안전망입니다. 다시 말해 기본 레벨입니다. 이 용어는 모델이 예측으로 시장을 크게 놀라게 하는 것을 허용하지 않습니다.
저는 다른 여러 가지 방법을 시도해 봤습니다. 저는 거기에 지수, 로그, 그리고 온갖 복잡한 삼각 함수들을 마구 집어넣었습니다. 의미 있는 일이 아닙니다. 모델은 괴물로 변해버립니다. 아시다시피 오컴이 말했습니다: 필요한 것 이상으로 개체를 늘리지 마십시오. 현재 버전은 예상대로 간단하고 제대로 작동하는 것으로 나타났습니다.
물론 이러한 모든 계수들은 어떤 식으로든 선택되어야 합니다. 이럴 때 바로 예전부터 전해 내려오는 넬더-미드(Nelder-Mead) 메서드가 유용하게 쓰입니다. 하지만 그건 완전히 다른 이야기입니다. 다음 편에서 밝히겠습니다. 믿으세요. 할 이야기가 정말 많습니다 - 최적화 과정에서 제가 저지른 실수만으로도 따로 한 편의 글을 쓸 수 있을 정도입니다.
선형 컴포넌트선형 부분부터 시작해 봅시다. 가장 중요한 게 뭔지 아세요? 이 모델은 이전 두 가격 값들을 서로 다른 방식으로 분석합니다. 첫 번째 계수는 보통 0.3~0.4 정도로 나타납니다 - 이는 마지막 변경에 대한 즉각적인 반응입니다. 하지만 두 번째 경우가 더 흥미롭습니다. 두번째 경우는 종종 0.7에 근접하는데 이것은 바로 앞 가격의 영향력이 더 강하다는 것을 나타냅니다. 재밌죠? 시장은 최근의 변동을 신뢰하지 않고 다소 오래된 레벨에 의존하는 것으로 보입니다.
이차 컴포넌트이차항과 관련해서 흥미로운 일이 벌어졌습니다. 처음에는 단순히 비선형성을 고려하기 위해 추가했는데 그 후 놀라운 사실을 발견했습니다. 시장이 안정된 상황에서는 이들의 기여도는 미미합니다. 계수는 0.01~0.02 레벨에서 변동합니다. 하지만 강력한 움직임이 시작되면 이 구성원들은 깨어나는 것 같습니다. 이는 특히 EURUSD 일봉 차트에서 명확하게 드러납니다. 추세가 강해지면 이차항이 지배적인 역할을 하기 시작하며 모델이 가격과 함께 "가속"될 수 있도록 합니다.
운동량 컴포넌트운동량 컴포넌트는 실제로 매우 중요한 발견인 것이었습니다. 별거 아닌 가격 차이처럼 보일 수 있지만 이는 시장 분위기를 매우 정확하게 반영합니다! 안정된 시기에는 그 계수가 0.2~0.3 정도를 유지하지만 강한 움직임이 발생하기 전에는 종종 0.5까지 급증합니다. 이것은 제게 일종의 돌파가 임박했음을 알리는 신호가 되었습니다. 최적화 프로그램이 모멘텀 가중치를 높이기 시작하면 변화를 기대해도 좋다는 뜻입니다.
주기적 컴포넌트주기적 컴포넌트에는 약간의 수정이 필요했습니다. 처음에는 사인파의 다양한 주기를 시도해 봤지만 저는 결국 시장 자체가 리듬을 결정한다는 것을 깨달았습니다. 모델이 계수를 통해 진폭을 조정하도록 하는 것으로 충분하며 주파수는 가격 자체에서 자연스럽게 얻어집니다. 유럽과 미국 트레이딩 세션 사이에 이 계수가 어떻게 변하는지 보는 것은 재미있습니다. 마치 시장이 서로 다른 리듬으로 숨을 쉬는 것 같습니다.
마지막으로 자유항입니다. 이것의 역할은 내가 처음 생각했던 것보다 훨씬 더 중요한 것으로 드러났습니다. 변동성이 큰 시기에는 예측치가 엉뚱한 방향으로 치닫는 것을 막아주는 기준점 역할을 합니다. 그리고 안정기에는 전반적인 가격 수준을 더욱 정확하게 파악하는 데 도움이 됩니다. 종종 그 값은 추세의 강도와 상관관계가 있습니다 - 추세가 강할수록 자유항은 0에 가까워집니다.
가장 흥미로운 게 뭔지 아세요? 모델을 복잡하게 만들려고 할 때마다(새로운 항을 추가하거나 더 복잡한 함수를 사용하는 등) 결과는 오히려 더 나빠졌습니다. 마치 시장이 이렇게 말하는 것 같았습니다: "이봐, 똑똑한 척하지 마. 이미 핵심은 파악했잖아." 현재 버전의 방정식은 복잡성과 효율성 사이에서 진정으로 적절한 균형을 이루고 있습니다. 계수는총 7개이며 그 이상도 이하도 아닙니다. 각 계수는 전체 예측 메커니즘에서 고유한 역할을 수행합니다.
덧붙여 말하자면 이러한 계수의 최적화는 그 자체로 매우 흥미로운 이야기입니다. 넬더-미드 메서드가 최적값을 찾는 과정을 관찰하기 시작하면 여러분 자신도 모르게 카오스 이론이 떠오를 것입니다. 하지만 이 부분은 다음 편에서 자세히 다루겠습니다. 정말 볼 만한 게 있거든요.
넬더-미드 알고리즘을 이용한 모델 최적화
여기서는 가장 흥미로운 부분 - 우리 모델이 실제 데이터에서 작동하도록 만드는 방법에 대해 살펴보겠습니다. 수개월에 걸친 최적화 실험과 수십 밤의 잠 못 이루는 밤, 그리고 수많은 커피에 의지한 끝에 저는 마침내 효과적인 접근 방식을 찾아냈습니다.
모든 것은 여느 때와 마찬가지였습니다 - 경사 하강법입니다. 이 분야의 고전이자 데이터 과학자라면 누구나 가장 먼저 떠올리는 것입니다. 구현에 3일, 디버깅에 또 1주일을 썼습니다... 그래서 결과는 어땠을까요? 해당 모델은 수렴을 단호히 거부했습니다. 그것은 무한으로 날아가거나 지역 최소값에 갇히게 될 것이었습니다. 기울기가 미친 듯이 요동쳤습니다.
그다음 주에는 유전 알고리즘이었습니다. 이 아이디어는 겉보기에는 훌륭해 보입니다 - 진화가 최적의 계수를 찾아내도록 하자는 것입니다. 제가 구현하고 실행해 봤는데... 실행 시간에 깜짝 놀랐습니다. 컴퓨터는 일주일치 과거 데이터를 처리하느라 밤새도록 윙윙거렸습니다. 결과가 너무 불안정했습니다.
그러다가 넬더-미드 방법을 떠오르게 되었습니다. 1965년에 개발된, 오래된 심플렉스 메서드입니다. 미분도, 고등 수학도 필요 없습니다 - 단지 해법 공간을 영리하게 탐색하면 됩니다. 실행해 보고 나서 저는 제 눈을 믿을 수가 없었습니다. 그 알고리즘은 마치 시장과 춤을 추듯 부드럽게 최적값에 접근하는 듯했습니다.
다음은 기본 손실 함수입니다. 단순하지만 흠잡을데 없이 작동합니다.
def loss_function(self, coeffs, X_train, y_train): y_pred = np.array([self.equation(x, coeffs) for x in X_train]) mse = np.mean((y_pred - y_train)**2) r2 = r2_score(y_train, y_pred) # Save progress for analysis self.optimization_progress.append({ 'mse': mse, 'r2': r2, 'coeffs': coeffs.copy() }) return mse
처음에 저는 손실 함수를 복잡하게 만들려고 큰 계수에 대한 페널티를 추가하고 MAPE 및 기타 메트릭을 포함시키려고 했습니다. 개발자들이 흔히 저지르는 전형적인 실수는 무언가가 제대로 작동하면 완전히 작동하지 않을 때까지 계속해서 개선해야 한다고 생각하는 것입니다. 결국 저는 다시 간단한 MSE로 돌아갔고 그 결과가 어땟는지 아시나요? 알고 보니 단순함이 곧 천재성이었습니다.
실시간으로 최적화 과정을 지켜보는 것은 특별한 스릴을 선사합니다. 초기 반복 과정에서는 계수와 MSE가 미친 듯이 요동치고 R² 값은 0에 가깝습니다. 그다음부터 가장 흥미로운 부분이 시작됩니다 - 알고리즘이 올바른 방향을 찾아내고 메트릭들은 점차 개선됩니다. 100번째 반복쯤 되면 이점이 있을지 없을지가 이미 명확해지고 300번째쯤 되면 시스템은 대개 안정적인 수준에 도달합니다.
참고로 메트릭에 대해 몇 마디 말씀드리겠습니다. 저희 R² 값은 보통 0.996을 넘는데 이는 모델이 가격 변동의 99.6% 이상을 설명한다는 의미입니다. MSE는 약 0.0000007입니다 - 즉 예측 오차가 0.7핍을 넘는 경우는 드뭅니다. MAPE에 관해서 말하자면... MAPE는 일반적으로 만족스런 수준입니다 - 보통 0.1% 미만입니다. 이 모든 것이 과거 데이터를 기반으로 한다는 것은 분명하지만 미래 예측용의 결과도 크게 나쁘지는 않습니다.
하지만 중요한 것은 숫자가 아닙니다. 중요한 것은 결과의 안정성입니다. 여러분은 최적화 작업을 열 번을 연속으로 실행할수 있습니다. 그리고 매번 매우 유사한 계수 값을 얻게 될 것입니다. 이는 제가 다른 최적화 방법들을 사용하면서 겪었던 어려움을 고려하면 매우 가치 있는 결과입니다.
또 멋있는 것이 무엇인지 아니사요? 최적화 과정을 관찰함으로써 여러분은 시장 자체에 대해 많은 것을 이해할 수 있습니다. 예를 들어 알고리즘이 모멘텀 컴포넌트의 가중치를 지속적으로 높이려고 시도한다면 이는 시장에서 강한 움직임이 끌어 오르고 있음을 의미합니다. 또는 알고리즘이 주기적 컴포넌트를 적용하기 시작하면 변동성이 커지는 시기가 올 것으로 예상됩니다.
다음 섹션에서는 이러한 수학적 구조가 어떻게 실제 거래 시스템으로 전환되는지 설명하겠습니다. 저를 한번 믿어보세요. 그 부분에 대해서도 생각해 볼 거리가 많습니다. MetaTrader 5와 관련한 어려움들만 해도 별도의 기사로 다룰 만합니다.
훈련 과정 특징
훈련용의 데이터를 준비하는 것은 별개의 문제였습니다. 시스템 초기 버전에서 제가 전체 데이터셋을 sklearn.train_test_split 함수에 즐겁게 입력했던 기억이 나네요... 그리고 나중에 의심스러울 정도로 좋은 결과를 살펴보고 나서야 미래의 데이터가 과거로 유출되고 있다는 사실을 깨달았습니다!
문제점이 뭔지 아시겠어요? 재무 데이터를 일반적인 Kaggle 스프레드시트처럼 다룰 수는 없습니다. 여기서 각각의 데이터는 특정 시점을 나타내며 이들을 섞는 것은 마치 내일의 날씨를 바탕으로 어제의 날씨를 예측하려는 것과 같습니다. 그 결과 간단하지만 효율적인 다음과 같은 코드가 탄생했습니다:
def prepare_training_data(prices, train_ratio=0.67): # Cut off a piece for training n_train = int(len(prices) * train_ratio) # Forming prediction windows X = np.array([[prices[i], prices[i-1]] for i in range(2, len(prices)-1)]) y = prices[3:] # Fair time sharing X_train, y_train = X[:n_train], y[:n_train] X_test, y_test = X[n_train:], y[n_train:] return X_train, y_train, X_test, y_test보기에는 간단한 코드처럼 보입니다. 하지만 이러한 단순함 뒤에는 수많은 고난과 역경이 숨어 있습니다. 처음에 저는 창 크기를 다양하게 바꿔가며 실험해 봤습니다. 역사적 사실이 많을수록 예측이 더 정확해질 거라고 생각했습니다. 제가 틀린것이었습니다! 앞서 제시된 두 값이 충분했던 것으로 밝혀졌습니다. 시장은 과거를 오래 기억하지 않는다는 걸 아시잖아요.
훈련 샘플의 크기는 별개의 문제입니다. 저는 50/50, 80/20, 심지어 90/10까지 다양한 비율을 시도해 봤습니다. 결국 저는 황금계수를 사용하기로 결정했습니다 - 대략 훈련 데이터의 약 67% 정도입니다. 왜일까요? 이게 제일 효과적이에요! 분명히 피보나치는 시장의 본질에 대해 뭔가 알고 있었던 것 같습니다...
다양한 데이터를 사용하여 모델이 학습하는 과정을 지켜보는 것은 재미있습니다. 안정기를 거치면 계수가 자연스럽게 선택되고 지표가 점진적으로 개선됩니다. 만약 훈련 샘플에 브렉시트나 연방준비제도 의장의 연설 같은 내용이 포함된다면 상황은 완전히 엉망이 됩니다. 계수가 급등하고 최적화 프로그램이 오작동을 일으키고 오류 그래프는 롤러코스터처럼 요동칩니다.
그건 그렇고 지표에 대해 다시 한번 몇 마디 하겠습니다. 훈련 샘플의 R² 값이 0.98보다 높으면 데이터에 어떤 문제가 있었을 가능성이 매우 높다는 것을 알게 되었습니다. 실제 시장은 그렇게 예측 가능지 않습니다. 그건 마치 너무나 뛰어난 학생에 대한 이야기 같군요. 부정행위를 하거나 천재이거나 둘 중 하나죠. 우리 경우에는 대개 전자의 경우입니다.
또 하나 중요한 점은 데이터 전처리입니다. 저는 처음에는 가격을 정규화하고 규모를 조정하고 이상치를 제거하려고 했습니다... 머신 러닝 강좌에서 가르치는 모든 내용을 다 해봤습니다. 하지만 점차 원본 데이터를 건드리지 않을수록 좋다는 결론에 도달했습니다. 시장은 저절로 정상화될 것입니다. 모든 것을 제대로 준비하기만 하면 됩니다.
이제 훈련 과정은 자동화된 반응을 한다고 부를 정도로 합리적으로 되었습니다. 우리는 일주일에 한 번씩 새로운 데이터를 불러와 학습을 실행하고 지표를 과거 값과 비교합니다. 모든 수치가 정상 범위 내에 있다면 실시간 시스템에서 계수를 업데이트 합니다. 뭔가 의심스러우면 더 자세히 조사해 보세요. 다행히도 우리는 이미 경험을 통해 문제의 원인을 어디에서 찾아야 하는지 알고 있습니다.
최적화 계수
def fit(self, prices): # Prepare data for training X_train, y_train = self.prepare_training_data(prices) # I found these initial values by trial and error initial_coeffs = np.array([0.5, 0.1, 0.3, 0.1, 0.2, 0.1, 0.0]) result = minimize( self.loss_function, initial_coeffs, args=(X_train, y_train), method='Nelder-Mead', options={ 'maxiter': 1000, # More iterations does not improve the result 'xatol': 1e-8, # Accuracy by ratios 'fatol': 1e-8 # Accuracy by loss function } ) self.coefficients = result.x return result
가장 어려웠던 점이 뭔지 아세요? 그 빌어먹을 초기 확률. 처음에는 난수를 사용해 봤습니다 - 결과가 너무 들쭉날쭉해서 포기할 뻔했습니다. 그다음엔 1부터 시작해 봤습니다 - 최적화 프로그램이 첫 번째 반복 과정에서 어디론가 사라져 버렸습니다. 0을 사용해도 지역 최소값에 갇혀 제대로 작동하지 않았습니다.
첫 번째 계수 0.5는 선형 구성 컴포넌트의 가중치입니다. 값이 작으면 모델의 추세가 무너지고 값이 크면 마지막 가격에 지나치게 의존하게 됩니다. 이차항의 경우 0.1이 완벽한 시작점으로 밝혀졌습니다 - 비선형성을 포착하기에는 충분하지만 갑작스러운 변화에 모델이 오작동하지 않을 정도의 값입니다. 운동량 값 0.2는 실험적으로 얻은 값이었습니다: 단지 이 값에서 시스템이 가장 안정적인 결과를 보였을 뿐입니다.
최적화 과정에서 넬더-미드 7차원 계수 공간에 심플렉스를 구성합니다. 마치 뜨거움과 차가움의 게임과 같은데 단지 7차원에서 동시에 벌어지는 게임일 뿐입니다. 프로세스 편차를 방지하는 것이 중요하기 때문에 정확도에 대한 요구 사항이 매우 엄격합니다(1e-8). 값이 작으면 불안정한 결과가 나오고 값이 크면 최적화 과정이 지역 최소값에 갇히게 됩니다.
1,000번의 반복은 과도해 보일 수 있지만 실제로는 최적화 프로그램이 보통 300~400단계 안에 수렴합니다. 다만 특히 변동성이 큰 시기에는 최적의 해결책을 찾는 데 더 많은 시간이 필요할 뿐입니다. 반복 횟수가 늘어나도 성능에는 큰 영향을 미치지 않습니다. 최신 하드웨어에서는 전체 과정이 보통 1분도 채 걸리지 않습니다.
덧붙여 말씀드리자면 제가 최적화 과정을 시각화하는 아이디어를 떠올리게 된 것은 바로 이 코드를 디버깅하는 과정 중이었습니다. 확률 변화를 실시간으로 확인하면 모델의 작동 방식과 향후의 방향을 훨씬 쉽게 이해할 수 있습니다.
품질 메트릭 및 해석
예측 모델의 품질을 평가하는 것은 별개의 문제이며 미묘한 차이들로 가득 차 있습니다. 알고리즘 트레이딩 분야에서 수년간 일하면서 저는 메트릭 때문에 너무나 고생해서 그 내용을 다룬 책을 따로 쓸 정도될 것입니다. 하지만 가장 중요한 것을 말씀드리겠습니다.
결과는 다음과 같습니다:

먼저 R제곱부터 살펴보겠습니다. EURUSD 환율이 0.9를 넘는 것을 처음 봤을때 저는 제 눈을 믿을 수 없었습니다. 데이터 유출이나 계산 오류가 없는지 확인하기 위해 코드를 열 번이나 검토했습니다. 그런데 아무런 문제가 없었습니다 - 해당 모델은 가격 변동의 90% 이상을 설명합니다. 하지만 나중에 이것이 양날의 검이라는 것을 깨달았습니다. R² 값이 너무 높으면(0.95 이상) 일반적으로 과적합이란 것을 나타냅니다. 시장은 그렇게 예측 가능하지 않습니다.
MSE는 우리의 핵심 업무 도구입니다. 다음은 일반적인 평가 코드입니다:
def evaluate_model(self, y_true, y_pred): results = { 'R²': r2_score(y_true, y_pred), 'MSE': mean_squared_error(y_true, y_pred), 'MAPE': mean_absolute_percentage_error(y_true, y_pred) * 100 } # Additional statistics that often save the day errors = y_pred - y_true results['max_error'] = np.max(np.abs(errors)) results['error_std'] = np.std(errors) # Look separately at error distribution "tails" results['error_quantiles'] = np.percentile(np.abs(errors), [50, 90, 95, 99]) return results
추가 통계 자료를 참고하시기 바랍니다. 저는 한 번의 불미스러운 사건 이후 max_error와 error_std를 추가했습니다 - 모델은 MSE가 매우 우수했지만 때때로 예측에서 너무 큰 이상치가 발생하여 시도조차 하지 않고 바로 예치금을 해지해야 하는 경우가 있었습니다. 제가 제일 먼저 살펴보는 것은 오차 분포의 "꼬리" 부분입니다. 하지만 꼬리는 여전히 존재합니다.
MAPE는 트레이더들에게 집과 같은 곳입니다. R제곱에 대해 설명하면 트레이더들의 눈빛이 흐릿해지지만 "모델이 평균적으로 0.05% 오차가 있다"라고 말하면 즉시 이해합니다. 하지만 함정이 있습니다. MAPE는 작은 가격 변동 시에는 실제보다 훨씬 낮게 나타날 수 있고 급격한 변동 시에는 급격히 상승할 수 있습니다.
하지만 제가 깨달은 가장 중요한 점은 과거 데이터에 기반한 어떤 메트릭도 현실에서 성공을 보장하지 않는다는 것입니다. 그래서 제가 철저한 검증 시스템을 갖추고 있는것입니다:
def validate_model_performance(self): # Check metrics on different timeframes timeframes = ['H1', 'H4', 'D1'] for tf in timeframes: metrics = self.evaluate_on_timeframe(tf) if not self._check_metrics_thresholds(metrics): return False # Look at behavior at important historical events stress_periods = self.get_stress_periods() stress_metrics = self.evaluate_on_periods(stress_periods) if not self._check_stress_performance(stress_metrics): return False # Check the stability of forecasts stability = self.check_prediction_stability() if stability < self.min_stability_threshold: return False return True
이 모델은 실거래에 투입하기 전에 이러한 모든 테스트를 통과해야 합니다. 그리고 그 후에도 저는 처음 2주 동안은 최소 거래량으로 거래합니다 - 실제 시장에서 어떻게 움직이는지 확인합니다.
사람들은 종종 어떤 메트릭이 좋은 값으로 간주되는지 묻습니다. 제 경험상 R² 값이 0.9 이상이면 훌륭하고 MSE가 0.00001 미만이면 허용 가능하며 MAPE가 0.05% 이하이면 매우 우수합니다. 하지만! 이러한 더욱 중요한 것은 이들 지표들의 시간 경과에 따른 안정성을 살펴보는 것입니다. 정확도는 매우 높지만 불안정한 시스템보다는 지표가 약간 떨어지더라도 안정적인 모델을 갖는 것이 더 낫습니다.
기술적 구현
트레이딩 시스템 개발에서 가장 어려운 점이 뭔지 아세요? 수학이나 알고리즘이 아니라 운영의 신뢰성이 중요합니다. 아름다운 방정식을 세우는 것과 그 방정식이 실제 돈으로 매일 24시간 내내 작동하도록 만드는 것은 완전히 다른 문제입니다. 저는 실제 프로젝트에서 몇 번의 뼈아픈 실수를 겪고 나서야 깨달았습니다: 건축은 단순히 좋은 것만으로는 부족하고 완벽해야 한다는 것을요.
저는 시스템 코어를 이렇게 구성했습니다:
class PriceEquationModel: def __init__(self): # Model status self.coefficients = None self.training_scores = [] self.optimization_progress = [] # Initializing the connection self._setup_logging() self._init_mt5() def _init_mt5(self): """Initializing connection to MT5""" try: if not mt5.initialize(): raise ConnectionError( "Unable to connect to MetaTrader 5. " "Make sure the terminal is running" ) self.log.info("MT5 connection established") except Exception as e: self.log.critical(f"Critical initialization error: {str(e)}") raise
여기 있는 모든 문자열은 슬픈 경험의 결과물입니다. 예를 들어 재연결을 시도하는데 연결이 실패하는 동안 MetaTrader 5를 초기화하는 별도의 메서드가 나타났습니다. 그리고 저는 시스템이 한밤중에 다운될 때를 위해 로그를 추가했는데 아침에는 무슨 일이 일어났는지 짐작해야 했습니다.
오류 처리는 완전히 별개의 문제입니다.
def _safe_mt5_call(self, func, *args, retries=3, delay=5): """Secure MT5 function call with automatic recovery""" for attempt in range(retries): try: result = func(*args) if result is not None: return result # MT5 sometimes returns None without error raise ValueError(f"MT5 returned None: {func.__name__}") except Exception as e: self.log.warning(f"Attempt {attempt + 1}/{retries} failed: {str(e)}") if attempt < retries - 1: time.sleep(delay) # Trying to reinitialize the connection self._init_mt5() else: raise RuntimeError(f"Call attempts exhausted {func.__name__}")
이 코드는 MetaTrader 5 경험의 핵심을 담고 있습니다. 문제가 발생하면 재연결을 시도하고 지연 시간을 두고 반복적으로 시도하며 가장 중요한 것은 시스템이 불확실한 상태에서 계속 작동하는 것을 허용하지 않는 코드라는 점입니다. 일반적으로 MetaTrader 5 라이브러리에는 문제가 거의 없습니다 - 완벽합니다!
저는 모델을 아주 단순한 상태로 유지합니다. 모델은 가장 필수적인 요소만 담고 있습니다. 복잡한 데이터 구조도 까다로운 최적화도 필요 없습니다. 하지만 모든 상태 변화는 기록되고 확인됩니다:
def _update_model_state(self, new_coefficients): """Safely updating model ratio""" if not self._validate_coefficients(new_coefficients): raise ValueError("Invalid ratios") # Save the previous state old_coefficients = self.coefficients try: self.coefficients = new_coefficients if not self._check_model_consistency(): raise ValueError("Model consistency broken") self.log.info("Model successfully updated") except Exception as e: # Roll back to the previous state self.coefficients = old_coefficients self.log.error(f"Model update error: {str(e)}") raise
여기서 모듈성은 단순히 멋진 단어에 그치는 것이 아닙니다. 각 구성 컴포넌트는 개별적으로 테스트, 교체 및 수정할 수 있습니다. 새로운 메트릭을 추가하시겠습니까? 새로운 메서드를 생성합니다. 데이터 소스를 변경해야 합니까? 동일한 인터페이스를 가진 다른 커넥터를 구현하는 것으로 충분합니다.
과거 데이터 처리
MetaTrader 5에서 데이터를 가져오는 것은 상당히 힘든 일이었습니다. 간단해 보이는 코드지만 언제나 그렇듯 문제는 세부적인 것에 있습니다. 수개월 동안 갑작스러운 연결 끊김과 데이터 손실 문제로 고생한 끝에 단말기 사용을 위한 다음과 같은 구조가 탄생했습니다.
def fetch_data(self, symbol="EURUSD", timeframe=mt5.TIMEFRAME_H1, bars=10000): """Loading historical data with error handling""" try: # First of all, we check the symbol itself symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Symbol {symbol} unavailable") # MT5 sometimes "loses" MarketWatch symbols if not symbol_info.visible: mt5.symbol_select(symbol, True) # Collect data rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) if rates is None: raise ValueError("Unable to retrieve historical data") # Convert to pandas df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return self._preprocess_data(df['close'].values) except Exception as e: print(f"Error while receiving data: {str(e)}") raise finally: # It is important to always close the connection mt5.shutdown()
모든 것이 어떻게 구성되어 있는지 살펴보겠습니다. 먼저 해당 심볼이 존재하는지 확인합니다. 당연해 보이지만 설정 오류로 인해 시스템이 존재하지 않는 통화쌍을 거래하려고 몇 시간 동안 시도한 사례가 있었습니다. 그 후 symbol_info를 통해 엄격한 검사를 추가했습니다.
다음으로 '보이는'이라는 단어와 관련하여 흥미로운 점이 있습니다. 해당 심볼은 있는 것 같지만 MarketWatch에는 나타나지 않습니다. symbol_select를 호출하지 않으면 데이터를 가져올 수 없습니다. 더욱이 터미널은 거래 도중에 해당 종목 코드를 "잊어버릴" 수도 있습니다. 재밌죠?
데이터를 얻는 것 또한 쉽지 않습니다. copy_rates_from_pos 함수는 서버 연결 문제, 서버 과부하, 데이터 부족 등 여러 가지 이유로 None을 반환할 수 있습니다... 따라서 우리는 즉시 결과를 확인하고 문제가 발생할 경우에는 예외를 발생시켜야 합니다.
pandas로의 변환은 별개의 문제입니다. 시간은 유닉스 형식으로 도착하므로 일반 타임스탬프로 변환해야 합니다. 그렇지 않으면 궁극적인 시계열 분석이 훨씬 더 어려워집니다.
그리고 가장 중요한 것은 '마침내' 연결을 끊는 것입니다. 이렇게 하지 않으면 MetaTrader 5에서 데이터 유출 징후가 나타나기 시작합니다. 처음에는 데이터 수신 속도가 떨어지고 그 다음에는 무작위로 시간 초과 오류가 발생하며 결국에는 터미널이 완전히 멈출 수 있습니다. 믿으세요 이건 제가 직접 경험하고 배운 거예요.
전반적으로 이 기능은 데이터를 다루는 데 있어 마치 스위스 칼과 같습니다. 겉보기에는 단순해 보이지만 내부에는 발생할 수 있는 모든 문제에 대비하는 수많은 보호 장치가 숨겨져 있습니다. 제 말을 믿어보세요. 조만간 이러한 메커니즘들이 모두 유용하다는 것이 입증될 것입니다.
결과 분석. 전방 테스트 결과의 품질 메트릭
시험 결과를 처음 봤을 때가 기억납니다. 저는 컴퓨터 앞에 앉아 차가운 커피를 홀짝이고 있었는데 눈앞에 펼쳐진 광경을 도저히 믿을 수 없었습니다. 테스트를 다섯 번이나 다시 실행하고 코드 한 줄 한 줄을 모두 확인했지만 오류는 아니었습니다. 그 모델은 정말 판타지의 경계선에 서 있었습니다.
넬더-미드 알고리즘은 마치 시계처럼 정확하게 작동했습니다 - 단 408번의 반복에 일반 노트북에서 1분도 채 걸리지 않았습니다. R제곱 값 0.9958은 좋은 수준을 넘어 기대 이상입니다. 가격 분산 99.58%! 제가 이 수치들을 동료 트레이더들에게 보여줬을 때 동료들은 처음에는 믿지 않다가 나중에는 뭔가 함정이 있는 건 아닌지 따지기 시작했습니다. 저는 그들의 말을 이해합니다. 저도 처음에는 믿지 않았으니까요.
MSE는 극히 작은 값으로 나타났습니다 - 0.00000094. 이는 평균 예측 오차가 1핍 미만임을 의미합니다. 어떤 트레이더에게 물어봐도 이는 상상조차 할 수 없는 일이라고 말할 겁니다. MAPE가 0.06%라는 점은 놀라운 정확도를 입증할 뿐입니다. 대부분의 상용 시스템은 1~2%의 오차 범위 내이면 만족하지만 이 시스템은 그보다 훨씬 더 우수한 정확도를 보여줍니다.
모델들의 계수가 조화를 이루어 아름다운 그림을 완성한 것입니다. 이전 가격인 0.5517은 시장이 단기 기억력이 강하다는 것을 나타냅니다. 이차항 값이 작으므로(0.0105 및 0.0368) 운동은 대부분 직선 운동임을 의미합니다. 0.1484의 계수를 갖는 주기적 컴포넌트는 완전히 다른 이야기입니다. 이는 거래자들이 수년간 말해왔던 바를 확인시켜 줍니다 - 시장은 파동처럼 움직인다.
하지만 가장 흥미로운 일은 전방 시험 중에 일어났습니다. 일반적으로 모델은 새로운 데이터가 들어올수록 성능이 저하됩니다. 이는 머신러닝의 전형적인 특징입니다. 여기는요? R²는 0.9970으로 상승했고 MSE는 19% 더 하락하여 0.00000076이 되었으며 MAPE는 0.05%로 떨어졌습니다. 솔직히 처음에는 제가 코드 어딘가를 잘못 작성한 줄 알았습니다. 너무 믿기 힘든 상황이었거든요. 하지만 모든 것이 정확했습니다.
저는 결과를 시각화할 수 있는 특별한 도구를 도입했습니다.
def plot_model_performance(self, predictions, actuals, window=100): fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12)) # Forecast vs. real price chart ax1.plot(actuals, 'b-', label='Real prices', alpha=0.7) ax1.plot(predictions, 'r--', label='Forecast', alpha=0.7) ax1.set_title('Comparing the forecast with the market') ax1.legend() # Error graph errors = predictions - actuals ax2.plot(errors, 'g-', alpha=0.5) ax2.axhline(y=0, color='k', linestyle=':') ax2.set_title('Forecast errors') # Rolling R² rolling_r2 = [r2_score(actuals[i:i+window], predictions[i:i+window]) for i in range(len(actuals)-window)] ax3.plot(rolling_r2, 'b-', alpha=0.7) ax3.set_title(f'Rolling R² (window {window})') plt.tight_layout() return fig
그래프는 흥미로운 사실을 보여주었습니다. 평온한 시기에는 이 모델이 스위스 시계처럼 정확하게 작동합니다. 하지만 함정도 있습니다 - 중요한 뉴스가 나오거나 상황이 갑자기 반전될 때는 정확도가 떨어집니다. 이는 해당 모델이 기본적인 요인을 고려하지 않고 가격만을 기반으로 작동하기 때문에 예상할 수 있는 결과입니다. 다음 편에서 우리는 물론 이 내용도 추가할 것입니다.
저는 개선할 수 있는 부분이 여러 가지 보입니다. 첫 번째는 적응 계수입니다. 모델이 시장 상황에 맞춰 스스로 적응하도록 하십시오. 두 번째는 볼륨과 주문량에 대한 데이터를 추가하는 것입니다. 세 번째이자 가장 야심찬 목표는 우리의 다른 알고리즘들과 우리의 접근 방식이 함께 작동하는 모델 앙상블을 만드는 것입니다.
하지만 현재 형태만으로도 그 결과는 인상적입니다. 지금 가장 중요한 것은 개선에 너무 몰두하지 않고 이미 잘 작동하는 것을 망치지 않는 것입니다.
실용적인 사용
지난주에 있었던 재미있는 일이 생각나네요. 저는 제가 제일 좋아하는 커피숍에 노트북을 켜놓고 라떼를 마시면서 시스템이 작동하는 모습을 지켜보고 있었습니다. 그날은 평온했고 EURUSD는 순조롭게 상승하고 있었는데 갑자기 모델에서 숏 포지션을 잡을 준비를 하라는 알림이 왔습니다. 처음에는 '말도 안 돼, 추세는 분명히 상승세잖아!'라는 생각이 들었습니다. 하지만 알고리즘 트레이딩을 2년간 경험하면서 저는 가장 중요한 규칙을 배웠습니다 - 바로 시스템과 절대 논쟁하지 말라는 것입니다. 40분 후 유로는 35핍 하락했습니다. 모델은 제가 인간의 눈으로는 도저히 알아차릴 수 없는 가격 구조의 미세한 변화에 반응했습니다.
알림 얘기가 나왔으니 말인데... 몇 번의 거래 기회를 놓친 후 이 간단하지만 효과적인 알림 모듈이 탄생했습니다:
def notify_signal(self, signal_type, message): try: # Format the message timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') formatted_msg = f"[{timestamp}] {signal_type}: {message}" # Send to Telegram if self.use_telegram and self.telegram_token: self.telegram_bot.send_message( chat_id=self.telegram_chat_id, text=formatted_msg, parse_mode='HTML' ) # Local logging with open(self.log_file, 'a', encoding='utf-8') as f: f.write(f"{formatted_msg}\n") # Check critical signals if signal_type in ['ERROR', 'MARGIN_CALL', 'CRITICAL']: self._emergency_notification(formatted_msg) except Exception as e: # If the notification failed, send the message to the console at the very least print(f"Error sending notification: {str(e)}\n{formatted_msg}")
_emergency_notification 메서드에 주의하세요. 시스템에 메모리 오류가 발생해서 포지션에 계속 하나씩 진입한 "웃긴" 사건 이후에 해당 기능을 추가했습니다. 이제 위급 상황이 발생하면 SMS 알림이 도착하고 제가 개입할 때까지 봇이 자동으로 거래를 중단합니다.
저는 포지션의 크기 때문에도 많은 어려움을 겪었습니다. 처음에는 고정된 거래량인 0.1랏을 사용했습니다. 하지만 점차 이는 발레 슈즈를 신고 외줄타기를 하는 것과 같다는 것을 깨닫게 되었습니다. 가능해 보이긴 하는데, 왜 그럴까요? 결국 저는 다음과 같은 적응형 볼륨 계산 시스템을 도입했습니다.
def calculate_position_size(self): """Calculating the position size taking into account volatility and drawdown""" try: # Take the total balance and the current drawdown account_info = mt5.account_info() current_balance = account_info.balance drawdown = (account_info.equity / account_info.balance - 1) * 100 # Basic risk - 1% of the deposit base_risk = current_balance * 0.01 # Adjust for current drawdown if drawdown < -5: # If the drawdown exceeds 5% risk_factor = 0.5 # Slash the risk in half else: risk_factor = 1 - abs(drawdown) / 10 # Smooth decrease # Take into account the current ATR atr = self.calculate_atr() pip_value = self.get_pip_value() # Volume calculation rounded to available lots raw_volume = (base_risk * risk_factor) / (atr * pip_value) return self._normalize_volume(raw_volume) except Exception as e: self.notify_signal('ERROR', f"Volume calculation error: {str(e)}") return 0.1 # Minimum safety volume
_normalize_volume 메서드는 정말 골칫거리였습니다. 알고 보니 브로커마다 최소 거래량 변경 단계가 다르더군요. 어떤 곳에서는 0.010랏 단위로 거래할 수 있고 어떤 곳에서는 정수 단위로만 거래할 수 있습니다. 저는 각 브로커마다 별도의 설정을 추가해야 했습니다.
변동성이 큰 시기에 일하는 것은 별개의 문제입니다. 아시다시피 시장이 완전히 미쳐 돌아가는 날도 있죠. 연준 의장의 연설, 예상치 못한 정치 뉴스, 혹은 단순히 "13일의 금요일"이라는 이유만으로도 주가는 마치 술 취한 선원처럼 요동치기 시작합니다. 이전에는 그런 상황이 발생하면 단순히 시스템을 끄곤 했는데 이제 좀 더 세련된 해결책을 생각해냈습니다.
def check_market_conditions(self): """Checking the market status before a deal""" # Check the calendar of events if self._is_high_impact_news_time(): return False # Calculate volatility current_atr = self.calculate_atr(period=5) # Short period normal_atr = self.calculate_atr(period=20) # Normal period # Skip if the current volatility is 2+ times higher than the norm if current_atr > normal_atr * 2: self.notify_signal( 'INFO', f"Increased volatility: ATR(5)={current_atr:.5f}, " f"ATR(20)={normal_atr:.5f}" ) return False # Check the spread current_spread = mt5.symbol_info(self.symbol).spread if current_spread > self.max_allowed_spread: return False return True
이 함수는 예치금을 지켜내는 진정한 수호자가 되었습니다. 특히 뉴스 확인 기능이 마음에 들었습니다. 경제 캘린더 API를 연결한 후 시스템이 중요한 이벤트 30분 전에는 자동으로 "잠시 중단"되었다가 30분 후에 다시 작동하는 것이었습니다. 제 MQL5 로봇들 중 상당수에서 이 아이디어가 사용됩니다. 나이스!
유동적 스톱 레벨
실제 거래 알고리즘을 개발하면서 저는 몇 가지 재미있는 교훈을 얻었습니다. 테스트 첫 달에 고정된 스탑 기능을 갖춘 시스템을 동료들에게 자랑스럽게 보여줬던 기억이 납니다. "봐, 모든 게 간단하고 투명하잖아!"라고 내가 말했다. 늘 그렇듯 시장은 순식간에 저를 곤경에 빠뜨렸습니다. 불과 일주일 만에 시장 변동성이 너무 심해서 제가 설정해둔 손절매 레벨의 절반이 날아가 버렸습니다.
그 해결책은 게르치크 노인이 제시한 것이었습니다 - 당시 저는 그의 책을 다시 읽고 있었거든요. ATR에 대한 그의 생각을 접하게 되었는데 마치 전구에 불이 켜진 것처럼 '바로 이거야!'라는 생각이 들었습니다. 시스템을 현재 시장 상황에 맞추는 간단하고 우아한 방법이었습니다. 급격한 가격 변동 시에는 가격 변동폭을 넓게 두고 안정적인 시기에는 손절매 수준을 더 낮게 설정합니다.
시장 진입의 기본 논리는 다음과 같습니다 - 불필요한 것 없이 가장 필수적인 것들만 있으면 됩니다.
def open_position(self): try: atr = self.calculate_atr() predicted_price = self.get_model_prediction() current_price = mt5.symbol_info_tick(self.symbol).ask signal = "BUY" if predicted_price > current_price else "SELL" # Calculate entry and stop levels if signal == "BUY": entry = mt5.symbol_info_tick(self.symbol).ask sl_level = entry - atr tp_level = entry + (atr / 3) else: entry = mt5.symbol_info_tick(self.symbol).bid sl_level = entry + atr tp_level = entry - (atr / 3) # Send an order request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": self.symbol, "volume": self.lot_size, "type": mt5.ORDER_TYPE_BUY if signal == "BUY" else mt5.ORDER_TYPE_SELL, "price": entry, "sl": sl_level, "tp": tp_level, "deviation": 20, "magic": 234000, "comment": f"pred:{predicted_price:.6f}", "type_filling": mt5.ORDER_FILLING_FOK, } result = mt5.order_send(request) if result.retcode != mt5.TRADE_RETCODE_DONE: raise ValueError(f"Error opening position: {result.retcode}") print(f"Position opened {signal}: price={entry:.5f}, SL={sl_level:.5f}, " f"TP={tp_level:.5f}, ATR={atr:.5f}") return result.order except Exception as e: print(f"Position opening failed: {str(e)}") return None디버깅 과정에서 재미있는 순간들이 몇 번 있었습니다. 예를 들어 해당 시스템은 말 그대로 몇 분마다 서로 모순되는 신호를 연속적으로 생성하기 시작했습니다. 사고, 팔고, 또 사고... 알고리즘 트레이딩 초보들이 흔히 저지르는 실수는 시장에 너무 자주 진입하는 것입니다. 해결책은 놀랍도록 간단했습니다 - 거래 사이에 15분 타임아웃을 추가하고 미결제 포지션 필터를 적용한 것입니다.
저도 위험 관리 때문에 많은 어려움을 겪었습니다. 저는 여러 가지 방법을 시도해 봤지만 결국 핵심은 간단한 규칙으로 귀결되었습니다: 바로 거래당 예치금의 1% 이상을 위험에 노출시키지 않는 것입니다. 별거 아니게 들리실지 모르지만 완벽하게 작동합니다. ATR이 50포인트일 경우 최대 거래량은 0.2랏으로 합니다 - 거래하기에 상당히 안정적인 수치입니다.
이 시스템은 EURUSD가 실제로 거래되고 횡보세를 보이지 않는 유럽 세션에서 가장 좋은 성능을 보였습니다. 하지만 중요한 뉴스가 나올 때는... 거래를 잠시 중단하는 것이 더 좋습니다. 아무리 최첨단 모델이라도 뉴스의 혼란을 따라잡을 수는 없습니다.
현재 포지션 관리 시스템 개선 작업을 진행 중입니다 - 진입 사이즈를 예측 모델의 신뢰도와 연동시키고 싶습니다. 대략적으로 말하면 강한 신호는 전체 볼륨을 거래한다는 의미이고 약한 신호는 일부만 거래한다는 의미입니다. 켈리 기준과 비슷한 것이지만 우리 모델의 특성에 맞게 조정한 것입니다.
이 프로젝트를 통해 얻은 가장 중요한 교훈은 알고리즘 트레이딩에서는 완벽주의가 통하지 않는다는 것입니다. 시스템이 복잡할수록 약점도 많아집니다. 간단한 해결책이 특히 장기적으로 볼 때 정교한 알고리즘보다 훨씬 더 효율적인 경우가 많습니다.
MetaTrader 5용 MQL5 버전
때로는 가장 간단한 해결책이 가장 효율적일 수 있다는 것을 아시잖아요. 수학적 도구 전체를 MQL5로 정확하게 옮기려고 며칠 동안 노력을 했습니다. 그리고 문득 이것이 전형적인 책임 분담 문제라는 것을 깨달았습니다.
솔직히 말해서 파이썬은 과학 라이브러리 덕분에 데이터 분석과 계수 최적화에 이상적입니다. MQL5는 트레이딩 로직을 실행하는 데 매우 유용한 도구입니다. 그렇다면 왜 드라이버로 망치를 만들려고 하는 걸까요?
그 결과 간단하고 우아한 해결책이 탄생했습니다 - 바로 계수 선택에는 Python을 사용하고 거래에는 MQL5를 사용하는 것입니다. 어떻게 작동하는지 살펴보겠습니다.
double g_coeffs[7] = {0.2752466, 0.01058082, 0.55162082, 0.03687016, 0.27721318, 0.1483476, 0.0008025};
이 일곱 숫자는 우리 수학 모델 전체의 핵심입니다. 여기에는 수 주간의 최적화 작업, 수천 번의 넬더-미드 알고리즘 반복, 그리고 수 시간의 과거 데이터 분석이 포함되어 있습니다. 무엇보다 중요한 건 효과가 있다는 겁니다!
double GetPrediction(double price_t1, double price_t2) { return g_coeffs[0] * price_t1 + // Linear t-1 g_coeffs[1] * MathPow(price_t1, 2) + // Quadratic t-1 g_coeffs[2] * price_t2 + // Linear t-2 g_coeffs[3] * MathPow(price_t2, 2) + // Quadratic t-2 g_coeffs[4] * (price_t1 - price_t2) + // Price change g_coeffs[5] * MathSin(price_t1) + // Cyclic g_coeffs[6]; // Constant }
예측 방정식 자체는 실질적으로 변경 없이 MQL5로 옮겨졌습니다.
시장 진입 메커니즘은 특별히 주목할 만한 가치가 있습니다. 테스트용 파이썬 버전과 달리 여기서는 더욱 발전된 포지션 관리 로직을 구현했습니다. 이 시스템은 여러 포지션을 동시에 유지할 수 있으며 신호가 확인되면 볼륨을 늘립니다.
void OpenPosition(bool buy_signal, double lot) { MqlTradeRequest request; MqlTradeResult result; ZeroMemory(request); request.action = TRADE_ACTION_DEAL; request.symbol = Symbol(); request.volume = lot; request.type = buy_signal ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; request.price = buy_signal ? SymbolInfoDouble(Symbol(), SYMBOL_ASK) : SymbolInfoDouble(Symbol(), SYMBOL_BID); // ... other parameters }
목표 수익 달성 시 모든 포지션이 자동으로 청산됩니다.
if(total_profit >= ProfitTarget) { CloseAllPositions(); return; }
저는 새로운 바 처리 과정에 특별히 신경을 썼습니다 - 매 틱마다 의미 없는 떨림이 없도록 했습니다:
bool isNewBar() { datetime lastbar_time = datetime(SeriesInfoInteger(Symbol(), PERIOD_CURRENT, SERIES_LASTBAR_DATE)); if(last_time == 0) { last_time = lastbar_time; return(false); } if(last_time != lastbar_time) { last_time = lastbar_time; return(true); } return(false); }
그 결과 작지만 기능적인 트레이딩 로봇이 탄생했습니다. 불필요한 장식은 없습니다 - 실제로 업무를 완수하는 데 필요한 기능만 담았습니다. 전체 코드는 필요한 모든 검사 및 보호 기능을 포함하면서도 300줄도 채 되지 않습니다.
가장 좋은 점이 뭔지 알세요? 파이썬과 MQL5 간의 문제를 분리하는 이러한 접근 방식은 놀라울 정도로 유연하다는 것이 입증되었습니다. 새로운 계수로 실험해보고 싶으신가요? 파이썬에서 해당 값들을 다시 계산하고 MQL5에서 배열을 업데이트하기만 하면 됩니다. 새로운 거래 조건을 추가해야 하시나요? MQL5의 거래 로직은 수학적 부분을 다시 작성할 필요 없이 쉽게 확장될 수 있습니다.
다음은 로봇 테스트 결과입니다:
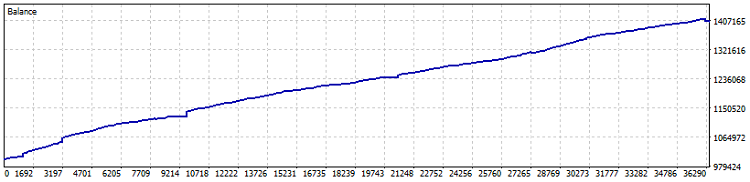
네팅 계좌 테스트 결과 2015년 이후 40%의 수익률을 기록했습니다 (지난 1년간 계수 최적화가 진행되었습니다). 수치상 손실은 0.82%이고, 월간 수익은 4%를 넘습니다. 하지만 그런 시스템은 레버리지 없이 가동하는 것이 더 낫습니다 - 채권이나 미 달러 예금보다 약간 높은 수익률로 수익을 창출하도록 하는 것이죠. 그건 그렇고 테스트 기간 동안 7800건의 거래가 이루어졌습니다. 이는 최소한 1.5%의 추가 수익성 증가를 의미합니다.
제가 보기에 계수를 옮기는 아이디어는 일반적으로 좋은 생각이라고 생각합니다. 결론적으로 알고리즘 거래에서 가장 중요한 것은 시스템의 복잡성이 아니라 신뢰성과 예측 가능성입니다. 때로는 현대 수학을 이용하여 올바르게 선택된 7개의 숫자만으로도 충분합니다.
중요! 이 EA는 DCA 포지션 평균화(비유적으로 말하면 시간 평균화) 방식을 사용하기 때문에 매우 위험합니다. 보수적인 설정으로 네팅 테스트를 진행했을 때 뛰어난 결과가 나타났지만 포지션 평균화의 위험성을 항상 명심해야 하며 이러한 EA는 한 번에 예치금을 0으로 만들 수도 있다는 점을 잊지 마세요!
개선을 위한 아이디어
지금은 깊은 밤입니다. 저는 지금 커피를 마시면서 모니터에 나타난 차트를 보고 이 시스템으로 얼마나 더 많은 일을 할 수 있을지 생각하며 이 기고를 마무리하고 있습니다. 알고리즘 트레이딩에서는 흔히 이런 일이 벌어집니다: 모든 게 준비된 것 같은데 곧 개선할 만한 새로운 아이디어가 수십 개씩 떠오르죠.
그리고 가장 흥미로운 점이 뭔지 아세요? 이러한 모든 개선 사항은 하나의 유기체처럼 작동해야 합니다. 단순히 멋진 기능들을 잔뜩 추가하는 것만으로는 충분하지 않습니다 - 기능들이 서로 조화롭게 보완하여 진정으로 신뢰할 수 있는 트레이딩 시스템을 만들어야 합니다.
궁극적으로 우리의 목표는 완벽한 시스템을 만드는 것이 아닙니다 - 그런 시스템은 애초에 존재하지 않기 때문입니다. 목표는 수익을 창출할 만큼 시스템을 똑똑하게 만들되 최악의 순간에 무너지지 않을 만큼 단순하게 만드는 것입니다. 속담에 "최고는 좋은 것의 적이다"라는 말이 있습니다.
| Include | 파일 설명 |
|---|---|
| MarketSolver.py | 계수 선택 및 필요한 경우 온라인 거래를 위한 파이썬 코드 |
| MarketSolver.mql5 | 선택된 계수를 이용한 거래를 위한 MQL5 EA 코드 |
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/16473
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

게시된 전문가 조언에는 누락된 내용이 없습니다. 이것은 분명히 실제 계정의 코드가 아니며 여기에 언급된 필터가 없습니다.
아이디어의 데모일 뿐이며 나쁘지 않습니다.
동의합니다.
그냥 카펫(죄송합니다)! 몇 시간 동안 10번째로 자료를 공부하면서 우리가 같은 길(생각)을 걷고 있다는 것을 알았습니다.
저는 당신의 공식이 제가 이미 보거나 사용하는 것을 수학적으로 공식화하는 데 도움이되기를 정말로 바랍니다. 제가 이해한다면 한 가지 경우에만 일어날 것입니다. 어머니는 "공부해라, 아들아"라고 말씀하시곤 하셨어요. 저는 수학에서 쓴 눈물을 흘립니다. 많은 것들이 단순하다는 것을 알지만 방법을 모르겠어요. 포물선, 회귀, 편차에 들어가려고합니다.... 65세에 6학년이 되기는 어렵습니다.
// 멋진 기능을 많이 던지는 것만으로는 충분하지 않습니다. 서로 조화롭게 보완하여 정말 신뢰할 수있는 거래 시스템을 만들어야합니다.
예. 기능 선택과 후속 최적화는 자전거 바퀴의 8자 모양을 곧게 펴는 것과 같습니다. 일부 스포크는 느슨하게, 다른 스포크는 조여야 하며 이 과정의 법칙을 엄격하게 준수해야 합니다. 그러면 바퀴가 수평을 이루지만 잘못된 접근 방식을 취하면 스포크가 잘못된 방식으로 조여지면 일반 바퀴에서 "10"을 만들 수 있습니다.
우리 비즈니스에서 "스포크"는 서로를 도와야 하며, 다른 "스포크"에 해를 끼치면서까지 스스로 담요를 당겨서는 안 됩니다.
마지막 두 데이터 포인트만을 기준으로 가격을 예측하는 것은 효과적이지 않다고 생각합니다.
동의하시나요?
마지막 두 데이터 포인트만을 기준으로 가격을 예측하는 것은 효과적이지 않다고 생각합니다.
동의하시나요?