
Ottimizzazione del portafoglio nel Forex: Integrazione tra VaR e teoria di Markowitz

Introduzione: Attività di ottimizzazione del portafoglio nel Forex
Negli ultimi tre anni mi sono dedicato allo sviluppo di robot di trading per il Forex. E sapete una cosa? La gestione del rischio è una vera seccatura. All'inizio, ho semplicemente impostato degli stop loss fissi finché non ho perso un paio di depositi. Poi ho iniziato ad approfondire la questione e mi sono imbattuto nella teoria dell'ottimizzazione del portafoglio di Markowitz.
Sembrava una buona idea - calcolare le correlazioni, ottimizzare i pesi... Ma in realtà questo non funziona molto bene nel Forex. Perché? Perché nel Forex tutte le coppie di valute sono interconnesse! Provate a fare trading contemporaneamente su EURUSD e EURGBP e capirete cosa intendo. Un brusco movimento dell'EUR e le due posizioni si muovono in modo sincronizzato. Una splendida teoria viene infranta dalla dura realtà.
Stanco di questa situazione, ho iniziato a cercare altri approcci. Alla fine, mi sono imbattuto nella metodologia Value at Risk (VaR). All'inizio non capivo nemmeno di cosa si trattasse - una specie di equazioni complicate. Ma poi ho capito - era proprio quello di cui avevo bisogno! Il VaR indica la perdita massima per una data probabilità. In altre parole, possiamo stimare direttamente quanti soldi potremmo perdere in un giorno/settimana/mese.
Alla fine, ho deciso di incrociare Markowitz con VaR. Sembra una follia? Forse. Ma non ho visto altre opzioni. Markowitz fornisce l'allocazione ottimale dei fondi e il VaR evita di andare in margin call. Sulla carta sembrava un'ottima idea.
Poi ebbe inizio la dura vita quotidiana di un programmatore ricercatore. Python, terminale MetaTrader 5, tonnellate di dati storici... Sapevo che non sarebbe stato facile, ma la realtà ha superato ogni aspettativa. Ecco di cosa vi parlerò - di come ho cercato di creare un sistema che funzionasse davvero e non che fosse solo bello da vedere nei test.
Se avete mai provato ad automatizzare il trading sul Forex, capirete la mia difficoltà. E se così non fosse, forse la mia esperienza vi aiuterà ad evitare almeno alcune delle insidie in cui potreste imbattervi.
Fondamenti teorici e matematici del VaR e della teoria di Markowitz
Cominciamo quindi dalla teoria. Il primo mese ho cercato solo di capire la matematica. La teoria di Markowitz sembra complicata - un insieme di equazioni, matrici, ottimizzazione quadratica... Ma in realtà è tutto semplice - si prendono i rendimenti degli asset, si calcolano le correlazioni e si trovano i pesi in modo che il rischio sia minimo per un dato rendimento.
Inizialmente ero contento! Poi però ho iniziato a fare test su dati Forex reali, ed è lì che è iniziato tutto... Utilizzando i dati storici del cambio EURUSD relativi a un anno, la distribuzione dei rendimenti non è risultata affatto normale. Lo stesso valeva per la coppia GBPUSD. Questo è il presupposto fondamentale della teoria di Markowitz. In altre parole, tutti i calcoli vanno a farsi benedire.
Ho passato una settimana a cercare una soluzione. Ho esaminato articoli scientifici, ho cercato su Google e ho letto forum. Sono tornato al mio articolo sul VaR - Value at Risk. Sembra una strategia intelligente, ma in realtà calcoliamo semplicemente quanto possiamo perdere con una probabilità del 95% (o qualsiasi altra percentuale). Per prima cosa ho provato l'opzione più semplice - il VaR parametrico. L'equazione è elementare - media meno deviazione standard per quantile. La qualità del suo funzionamento è mediocre.
Poi sono passato al VaR storico. L'idea è di prendere dati storici reali e analizzare le perdite registrate nel 5% dei casi peggiori. Questo è molto più vicino alla realtà, ma sono necessari molti dati. Il boss finale è il metodo Monte Carlo. Generiamo una serie di scenari casuali tenendo conto delle correlazioni tra le coppie e finalmente ecco qualcosa di sensato.
La parte più difficile è stata capire come combinare il VaR con l'ottimizzazione di Markowitz. Di conseguenza, è nata la seguente idea: prendiamo l'ottimizzazione standard, ma aggiungiamo una limitazione VaR. Cerchiamo di minimizzare il rischio per un dato rendimento, ma in modo che il VaR non superi un certo livello.
Sulla carta è tutto perfetto, ma dobbiamo programmarlo... Nelle sezioni seguenti, mostrerò come ho trasformato queste equazioni in un codice Python funzionante.
Connessione a MetaTrader 5 da Python
L'implementazione pratica del mio sistema è iniziata con la creazione di una connessione stabile con il terminale di trading. Dopo aver sperimentato diversi approcci, ho optato per una connessione diretta tramite la libreria MetaTrader 5 per Python, che si è rivelata la più affidabile e veloce.
import MetaTrader5 as mt5 import time def initialize_mt5(account=12345, server="MetaQuotes-Demo", password="abc123"): if not mt5.initialize(): print(f"initialize() failed, error code = {mt5.last_error()}") return False authorized = mt5.login(account, password=password, server=server) if not authorized: print(f"login failed, error code = {mt5.last_error()}") mt5.shutdown() return False return True
Un ulteriore problema era rappresentato dalla sincronizzazione dell'ora tra il server del broker e il sistema locale. Una differenza di pochi secondi potrebbe causare seri problemi nel calcolo del VaR. È stato necessario implementare uno speciale meccanismo di correzione:
def get_time_correction(): server_time = mt5.symbol_info_tick("EURUSD").time local_time = int(time.time()) return server_time - local_time def get_corrected_time(): correction = get_time_correction() return int(time.time()) + correction
È stato dedicato molto tempo all'ottimizzazione dell'acquisizione dei dati. Inizialmente, effettuavo richieste separate per ogni coppia di valute, ma dopo aver implementato l'elaborazione in batch, la velocità è incrementata di diverse volte:
def fetch_data_batch(symbols, timeframe, start_pos, count): data = {} for symbol in symbols: rates = mt5.copy_rates_from_pos(symbol, timeframe, start_pos, count) if rates is not None and len(rates) > 0: data[symbol] = rates else: print(f"Failed to get data for {symbol}") return None return data
Si è rivelato sorprendentemente difficile terminare correttamente il programma. È stato necessario sviluppare una speciale procedura di "arresto controllato":
def safe_shutdown(): try: positions = mt5.positions_get() if positions: for position in positions: close_position(position.ticket) orders = mt5.orders_get() if orders: for order in orders: mt5.order_send(request={"action": mt5.TRADE_ACTION_REMOVE, "order": order.ticket}) finally: mt5.shutdown()
Il risultato è stato una base affidabile per l'intero sistema, in grado di funzionare 24 ore su 24 senza problemi. Era già possibile costruire, sulla sua base, una logica di ottimizzazione del portafoglio più complessa. Ma questo è già l'argomento della prossima sezione.
Acquisizione dei dati storici e loro pre-elaborazione
Nel corso degli anni di lavoro con i dati di mercato, ho imparato una semplice verità: la qualità dei dati storici è fondamentale per qualsiasi sistema di trading. Soprattutto quando si tratta di ottimizzazione del portafoglio, dove gli errori nei dati possono propagarsi a cascata.
Ho iniziato creando un sistema affidabile per il caricamento dello storico. La prima versione era piuttosto semplice, ma la pratica ne rivelò presto i limiti. Le quotazioni potrebbero contenere gap, spike e talvolta persino valori completamente errati. Ecco come appare il codice finale per il caricamento con convalida di base:
def load_historical_data(symbols, timeframe, start_date, end_date): data_frames = {} for symbol in symbols: # Load with a reserve to compensate for gaps rates = mt5.copy_rates_range(symbol, timeframe, start_date - timedelta(days=30), end_date) if rates is None: print(f"Failed to load data for {symbol}") continue df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) # Basic anomaly check df = detect_and_remove_spikes(df) df = fill_gaps(df) data_frames[symbol] = df return data_frames
Un problema a parte era quello di gestire i gap durante i fine settimana. Inizialmente ho semplicemente rimosso questi giorni, ma ciò ha falsato i calcoli della volatilità. Dopo lunghi esperimenti, è nato un metodo di interpolazione che tiene conto delle specificità di ciascuna coppia di valute:
def fill_gaps(df, method='time'): if df.empty: return df # Check the intervals between points time_delta = df.index.to_series().diff() gaps = time_delta[time_delta > pd.Timedelta(hours=2)].index for gap_start in gaps: gap_end = df.index[df.index.get_loc(gap_start) + 1] # Create new points with interpolated values new_points = pd.date_range(gap_start, gap_end, freq='1H')[1:-1] for point in new_points: df.loc[point] = df.asof(point) return df.sort_index()
Ho provato diversi approcci per calcolare i rendimenti. Le semplici variazioni percentuali si sono rivelate troppo imprecise. I rendimenti logaritmici hanno fornito i risultati migliori nella stima del VaR:
def calculate_returns(df): df['returns'] = np.log(df['close'] / df['close'].shift(1)) df['rolling_std'] = df['returns'].rolling(window=20).std() df['rolling_mean'] = df['returns'].rolling(window=20).mean() # Clean out emissions using the 3-sigma rule mean = df['returns'].mean() std = df['returns'].std() df = df[abs(df['returns'] - mean) <= 3 * std] return df
Lo sviluppo del sistema di verifica dei dati si è rivelato un passo fondamentale. Ciascun set viene sottoposto a una verifica in più fasi prima di essere utilizzato nei calcoli:
def verify_data_quality(df, symbol): checks = { 'missing_values': df.isnull().sum().sum() == 0, 'price_continuity': (df['close'] > 0).all(), 'timestamp_uniqueness': df.index.is_unique, 'reasonable_returns': abs(df['returns']).max() < 0.1 } if not all(checks.values()): failed_checks = [k for k, v in checks.items() if not v] print(f"Data quality issues for {symbol}: {failed_checks}") return False return True
Ho prestato particolare attenzione alla gestione delle anomalie di mercato. Diversi eventi, come bruschi movimenti dovuti alle notizie o crolli improvvisi, possono distorcere notevolmente la valutazione del rischio. Ho sviluppato un algoritmo speciale per identificarli e gestirli correttamente:
def detect_market_anomalies(df, window=20, threshold=3): volatility = df['returns'].rolling(window=window).std() typical_range = volatility.mean() + threshold * volatility.std() anomalies = df[abs(df['returns']) > typical_range].index if len(anomalies) > 0: print(f"Detected {len(anomalies)} market anomalies") return anomalies
Il risultato è stato una pipeline affidabile per la gestione dei dati, che è diventata la base per tutti i calcoli successivi. Dati storici di qualità sono il fondamento, senza i quali è impossibile costruire un sistema efficiente di gestione del portafoglio. Nella prossima sezione, prenderò in esame come questi dati vengono utilizzati per calcolare il VaR.
Implementazione del calcolo del VaR per le coppie di valute
Dopo aver lavorato a lungo con dati storici, mi sono dedicato all'implementazione del calcolo del VaR. Inizialmente, sembrava sufficiente prendere equazioni già pronte e tradurle in codice. La realtà si è rivelata più complessa, poiché le specificità del Forex hanno richiesto modifiche sostanziali agli approcci standard.
Ho iniziato implementando tre metodi classici di calcolo del VaR. Ecco come si presenta l'approccio parametrico:
def parametric_var(returns, confidence_level=0.95, holding_period=1): mu = returns.mean() sigma = returns.std() z_score = norm.ppf(1 - confidence_level) daily_var = -(mu + z_score * sigma) return daily_var * np.sqrt(holding_period)
Tuttavia, è apparso subito chiaro che l'assunzione di una distribuzione normale dei rendimenti nel Forex spesso non è valida. L'approccio storico si è dimostrato più affidabile:
def historical_var(returns, confidence_level=0.95, holding_period=1): sorted_returns = np.sort(returns) index = int((1 - confidence_level) * len(sorted_returns)) daily_var = -sorted_returns[index] return daily_var * np.sqrt(holding_period)
Ma i risultati più interessanti sono stati ottenuti con il metodo Monte Carlo. L'ho modificato per tenere conto delle specificità del mercato dei cambi:
def monte_carlo_var(returns, confidence_level=0.95, holding_period=1, simulations=10000): mu = returns.mean() sigma = returns.std() # Consider auto correlation of returns corr = returns.autocorr() simulated_returns = [] for _ in range(simulations): daily_returns = [] last_return = returns.iloc[-1] for _ in range(holding_period): # Generate the next value taking auto correlation into account innovation = np.random.normal(0, 1) next_return = mu + corr * (last_return - mu) + sigma * np.sqrt(1 - corr**2) * innovation daily_returns.append(next_return) last_return = next_return total_return = sum(daily_returns) simulated_returns.append(total_return) return -np.percentile(simulated_returns, (1 - confidence_level) * 100)
Ho prestato particolare attenzione alla validazione dei risultati. Ho inoltre sviluppato un sistema di backtesting per verificare l'accuratezza del VaR:
def backtest_var(returns, var, confidence_level=0.95): violations = (returns < -var).sum() expected_violations = len(returns) * (1 - confidence_level) z_score = (violations - expected_violations) / np.sqrt(expected_violations) p_value = 1 - norm.cdf(abs(z_score)) return { 'violations': violations, 'expected': expected_violations, 'z_score': z_score, 'p_value': p_value }
Per tenere conto delle relazioni tra le coppie di valute, è stato necessario implementare il calcolo del VaR di portafoglio:
def portfolio_var(returns_df, weights, confidence_level=0.95, method='historical'): if method == 'parametric': portfolio_returns = returns_df.dot(weights) return parametric_var(portfolio_returns, confidence_level) elif method == 'historical': portfolio_returns = returns_df.dot(weights) return historical_var(portfolio_returns, confidence_level) elif method == 'monte_carlo': # Use the covariance matrix to generate # correlated random variables cov_matrix = returns_df.cov() L = np.linalg.cholesky(cov_matrix) means = returns_df.mean().values simulated_returns = [] for _ in range(10000): Z = np.random.standard_normal(len(weights)) R = means + L @ Z portfolio_return = weights @ R simulated_returns.append(portfolio_return) return -np.percentile(simulated_returns, (1 - confidence_level) * 100)
Il risultato è stato un sistema di calcolo del VaR flessibile, adattato alle specificità del Forex. Nella prossima sezione, analizzerò come questi calcoli si integrano con la teoria di Markowitz per l'ottimizzazione del portafoglio.
Ottimizzazione del portafoglio tramite il metodo di Markowitz
Dopo aver implementato un calcolo VaR affidabile, ho iniziato a concentrarmi sull'ottimizzazione del portafoglio. La teoria classica di Markowitz necessitava di un serio adattamento alle realtà del Forex. Mesi di sperimentazione e test mi hanno portato a diverse scoperte importanti.
La prima cosa che ho capito è che le metriche standard di rischio e rendimento funzionano in modo diverso nel Forex rispetto al mercato azionario. Le coppie di valute presentano relazioni complesse che cambiano nel tempo. Dopo numerose sperimentazioni, ho sviluppato una funzione modificata per il calcolo del rendimento atteso:
def calculate_expected_returns(returns_df, method='ewma', halflife=30): if method == 'ewma': # Exponentially weighted average gives more weight to recent data return returns_df.ewm(halflife=halflife).mean().iloc[-1] elif method == 'capm': # Modified CAPM for Forex risk_free_rate = 0.02 # annual risk-free rate market_returns = returns_df.mean(axis=1) # market returns proxy betas = calculate_currency_betas(returns_df, market_returns) return risk_free_rate + betas * (market_returns.mean() - risk_free_rate)
Anche il calcolo della matrice di covarianza ha richiesto alcune revisioni. Il semplice approccio storico ha prodotto risultati troppo instabili. Ho implementato una stima shrinkage della covarianza, che ha migliorato significativamente la robustezza dell'ottimizzazione:
def shrinkage_covariance(returns_df, shrinkage_factor=None): sample_cov = returns_df.cov() n_assets = len(returns_df.columns) # The target matrix is diagonal with average variance target = np.diag(np.repeat(sample_cov.values.trace() / n_assets, n_assets)) if shrinkage_factor is None: # Estimation of the optimal 'shrinkage' ratio shrinkage_factor = estimate_optimal_shrinkage(returns_df, sample_cov, target) shrunk_cov = (1 - shrinkage_factor) * sample_cov + shrinkage_factor * target return pd.DataFrame(shrunk_cov, index=sample_cov.index, columns=sample_cov.columns)
La parte più difficile è ottimizzare i pesi del portafoglio. Dopo numerosi test, ho optato per un algoritmo di programmazione quadratica modificato:
def optimize_portfolio(returns_df, expected_returns, covariance, target_return=None, constraints=None): n_assets = len(returns_df.columns) # Risk minimization function def portfolio_volatility(weights): return np.sqrt(weights.T @ covariance @ weights) # Limitations constraints = [] # The sum of the weights is 1 constraints.append({'type': 'eq', 'fun': lambda x: np.sum(x) - 1}) if target_return is not None: # Target income limit constraints.append({ 'type': 'eq', 'fun': lambda x: x @ expected_returns - target_return }) # Add leverage restrictions for Forex constraints.append({ 'type': 'ineq', 'fun': lambda x: 20 - np.sum(np.abs(x)) # max leverage 20 }) # Initial approximation - equal weights initial_weights = np.repeat(1/n_assets, n_assets) # Optimization result = minimize( portfolio_volatility, initial_weights, method='SLSQP', constraints=constraints, bounds=tuple((0, 1) for _ in range(n_assets)) ) if not result.success: raise OptimizationError("Failed to optimize portfolio: " + result.message) return result.x
Ho prestato particolare attenzione al problema della stabilità della soluzione. Piccole modifiche ai dati di input non dovrebbero comportare una revisione radicale del portafoglio. A tale scopo, ho sviluppato la seguente procedura di regolarizzazione:
def regularized_optimization(returns_df, current_weights, lambda_reg=0.1): # Add a penalty for deviation from the current weights def objective(weights): volatility = portfolio_volatility(weights) turnover_penalty = lambda_reg * np.sum(np.abs(weights - current_weights)) return volatility + turnover_penalty
Come risultato, disponiamo di un ottimizzatore di portafoglio affidabile che tiene conto delle specificità del Forex e non richiede frequenti ribilanciamenti. Ma la cosa più importante doveva ancora venire - combinare questo approccio con un sistema di controllo del rischio basato sul VaR.
Combinazione di VaR e Markowitz in un unico modello
Combinare i due approcci si è rivelata la parte più impegnativa. Dovevo trovare un modo per sfruttare i vantaggi di entrambi i metodi senza creare contraddizioni tra di loro. Dopo diversi mesi di sperimentazione, sono giunto ad una soluzione elegante.
L'idea principale era quella di utilizzare il VaR come vincolo aggiuntivo nel problema di ottimizzazione di Markowitz. Ecco come appare nel codice:
def integrated_portfolio_optimization(returns_df, target_return, max_var_limit, current_weights=None): n_assets = len(returns_df.columns) # Calculation of basic metrics exp_returns = calculate_expected_returns(returns_df) covariance = shrinkage_covariance(returns_df) def objective_function(weights): # Portfolio standard deviation (Markowitz) portfolio_std = np.sqrt(weights.T @ covariance @ weights) # component VaR portfolio_var = calculate_portfolio_var(returns_df, weights) var_penalty = max(0, portfolio_var - max_var_limit) return portfolio_std + 100 * var_penalty # Penalty for exceeding VaR
Per tenere conto della natura dinamica del mercato, ho sviluppato un sistema adattivo per il ricalcolo dei parametri:
def adaptive_risk_limits(returns_df, base_var_limit, window=60): # Adapting VaR limits to current volatility recent_vol = returns_df.tail(window).std() long_term_vol = returns_df.std() vol_ratio = recent_vol / long_term_vol adjusted_var_limit = base_var_limit * np.sqrt(vol_ratio) return min(adjusted_var_limit, base_var_limit * 1.5) # Limit growth
Particolare attenzione doveva essere prestata al problema della stabilità della soluzione. Ho implementato un meccanismo per una transizione fluida tra i diversi stati del portafoglio:
def smooth_rebalancing(old_weights, new_weights, max_change=0.1): weight_diff = new_weights - old_weights excess_change = np.abs(weight_diff) - max_change where_excess = excess_change > 0 if where_excess.any(): # Limit changes in weights adjustment = np.sign(weight_diff) * np.minimum( np.abs(weight_diff), np.where(where_excess, max_change, np.abs(weight_diff)) ) return old_weights + adjustment return new_weights
Ho sviluppato una metrica specifica per valutare l'efficacia dell'approccio combinato:
def evaluate_integrated_model(returns_df, weights, var_limit): # Calculation of performance metrics portfolio_returns = returns_df.dot(weights) realized_var = historical_var(portfolio_returns) sharpe = calculate_sharpe_ratio(portfolio_returns) var_efficiency = abs(realized_var - var_limit) / var_limit return { 'sharpe_ratio': sharpe, 'var_efficiency': var_efficiency, 'max_drawdown': calculate_max_drawdown(portfolio_returns), 'turnover': calculate_turnover(weights) }
Durante la fase di test, è emerso che il modello funziona particolarmente bene nei periodi di maggiore volatilità. La componente VaR limita efficacemente i rischi, mentre l'ottimizzazione di Markowitz continua a ricercare opportunità di redditività.
La versione finale del sistema include anche un meccanismo per la regolazione automatica dei parametri:
def auto_tune_parameters(returns_df, initial_params, optimization_window=252): best_params = initial_params best_score = float('-inf') for var_limit in np.arange(0.01, 0.05, 0.005): for shrinkage in np.arange(0.2, 0.8, 0.1): params = {'var_limit': var_limit, 'shrinkage': shrinkage} score = backtest_model(returns_df, params, optimization_window) if score > best_score: best_score = score best_params = params return best_params
Nella prossima sezione, analizzerò come questo modello combinato viene applicato alla gestione dinamica delle posizioni nel trading reale.
Gestione dinamica del dimensionamento delle posizioni
La traduzione del modello teorico in un sistema di trading pratico ha richiesto la risoluzione di numerosi problemi tecnici. L'aspetto principale consisteva nella gestione dinamica delle dimensioni delle posizioni, tenendo conto delle condizioni di mercato attuali e calcolando i pesi ottimali del portafoglio.
Il sistema si basava su una classe per la gestione delle posizioni:
class PositionManager: def __init__(self, account_balance, risk_limit=0.02): self.balance = account_balance self.risk_limit = risk_limit self.positions = {} def calculate_position_size(self, symbol, weight, var_estimate): symbol_info = mt5.symbol_info(symbol) pip_value = symbol_info.trade_tick_value * 10 # Calculate the position size taking into account VaR max_risk_amount = self.balance * self.risk_limit * abs(weight) position_size = max_risk_amount / (abs(var_estimate) * pip_value) # Round to minimum lot return round(position_size / symbol_info.volume_step) * symbol_info.volume_step
Per cambiare posizione in modo fluido, ho sviluppato un meccanismo di ordini parziali:
def adjust_positions(self, target_positions): for symbol, target_size in target_positions.items(): current_size = self.get_current_position(symbol) if abs(target_size - current_size) > self.min_adjustment: # Break big changes into pieces steps = min(5, int(abs(target_size - current_size) / self.min_adjustment)) step_size = (target_size - current_size) / steps for i in range(steps): next_size = current_size + step_size self.execute_order(symbol, next_size - current_size) current_size = next_size time.sleep(1) # Prevent order flooding
Ho prestato particolare attenzione al controllo del rischio durante la modifica delle posizioni:
def execute_order(self, symbol, size_delta, max_slippage=10): if size_delta > 0: order_type = mt5.ORDER_TYPE_BUY else: order_type = mt5.ORDER_TYPE_SELL # Get current prices tick = mt5.symbol_info_tick(symbol) # Set VaR-based stop loss if order_type == mt5.ORDER_TYPE_BUY: stop_loss = tick.bid - (self.var_estimates[symbol] * tick.bid) take_profit = tick.bid + (self.var_estimates[symbol] * 2 * tick.bid) else: stop_loss = tick.ask + (self.var_estimates[symbol] * tick.ask) take_profit = tick.ask - (self.var_estimates[symbol] * 2 * tick.ask) request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": symbol, "volume": abs(size_delta), "type": order_type, "price": tick.ask if order_type == mt5.ORDER_TYPE_BUY else tick.bid, "sl": stop_loss, "tp": take_profit, "deviation": max_slippage, "magic": 234000, "comment": "var_based_adjustment", "type_time": mt5.ORDER_TIME_GTC, "type_filling": mt5.ORDER_FILLING_IOC, } result = mt5.order_send(request) return self.handle_order_result(result)
Ho aggiunto un sistema di monitoraggio della volatilità per proteggere da forti oscillazioni di mercato:
def monitor_volatility(self, returns_df, threshold=2.0): # Current volatility calculation current_vol = returns_df.tail(20).std() * np.sqrt(252) historical_vol = returns_df.std() * np.sqrt(252) if current_vol > historical_vol * threshold: # Reduce positions in case of increased volatility self.reduce_exposure(current_vol / historical_vol) return False return True
Il sistema include anche un meccanismo per la chiusura automatica delle posizioni al raggiungimento di livelli di rischio critici:
def emergency_close(self, max_loss_percent=5.0): total_loss = sum(pos.profit for pos in mt5.positions_get()) if total_loss < -self.balance * max_loss_percent / 100: print("Emergency closure triggered!") for position in mt5.positions_get(): self.close_position(position.ticket)
Il risultato è un sistema di gestione delle posizioni robusto, in grado di operare efficacemente in diverse condizioni di mercato. La sezione successiva si concentrerà sul sistema di controllo del rischio basato sul VaR.
Sistema di controllo del rischio di portafoglio
Dopo aver implementato la gestione dinamica delle posizioni, mi sono trovato di fronte alla necessità di creare un sistema completo di controllo del rischio a livello di portafoglio. L'esperienza ha dimostrato che il controllo locale del rischio sulle singole posizioni non è sufficiente - è necessario un approccio olistico.
Ho iniziato creando una classe per monitorare i rischi del portafoglio:
class PortfolioRiskManager: def __init__(self, max_portfolio_var=0.03, max_correlation=0.7, max_drawdown=0.1): self.max_portfolio_var = max_portfolio_var self.max_correlation = max_correlation self.max_drawdown = max_drawdown self.current_drawdown = 0 self.peak_balance = 0 def update_portfolio_metrics(self, positions, returns_df): # Calculation of current portfolio weights total_exposure = sum(abs(pos.volume) for pos in positions) weights = {pos.symbol: pos.volume/total_exposure for pos in positions} # Update portfolio VaR self.current_var = self.calculate_portfolio_var(returns_df, weights) # Check correlations self.check_correlations(returns_df, weights)
Ho prestato particolare attenzione al monitoraggio delle correlazioni tra gli strumenti:
def check_correlations(self, returns_df, weights): corr_matrix = returns_df.corr() high_corr_pairs = [] for i in returns_df.columns: for j in returns_df.columns: if i < j and abs(corr_matrix.loc[i,j]) > self.max_correlation: if weights.get(i, 0) > 0 and weights.get(j, 0) > 0: high_corr_pairs.append((i, j, corr_matrix.loc[i,j])) if high_corr_pairs: self.handle_high_correlations(high_corr_pairs, weights)
Ho implementato una gestione dinamica del rischio in base alle condizioni di mercato:
def adjust_risk_limits(self, market_state): volatility_factor = market_state.get('volatility_ratio', 1.0) trend_strength = market_state.get('trend_strength', 0.5) # Adapt limits to market conditions self.max_portfolio_var *= np.sqrt(volatility_factor) if trend_strength > 0.7: # Strong trend self.max_drawdown *= 1.2 # Allow a big drawdown elif trend_strength < 0.3: # Weak trend self.max_drawdown *= 0.8 # Reduce the acceptable drawdown
Il sistema di monitoraggio del drawdown si è rivelato particolarmente interessante:
def monitor_drawdown(self, current_balance): if current_balance > self.peak_balance: self.peak_balance = current_balance self.current_drawdown = (self.peak_balance - current_balance) / self.peak_balance if self.current_drawdown > self.max_drawdown: return self.handle_excessive_drawdown() elif self.current_drawdown > self.max_drawdown * 0.8: return self.reduce_risk_exposure(0.8) return True
Ho aggiunto un sistema di stress test per proteggermi da eventi estremi:
def stress_test_portfolio(self, returns_df, weights, scenarios=1000): results = [] for _ in range(scenarios): # Simulate extreme conditions stress_returns = returns_df.copy() # Increase volatility vol_multiplier = np.random.uniform(1.5, 3.0) stress_returns *= vol_multiplier # Add random shocks shock_magnitude = np.random.uniform(-0.05, 0.05) stress_returns += shock_magnitude # Calculate losses in a stress scenario portfolio_return = (stress_returns * weights).sum(axis=1) results.append(portfolio_return.min()) return np.percentile(results, 1) # 99% VaR in case of a stress
Il risultato è un sistema di protezione del capitale multilivello che previene efficacemente i rischi eccessivi e aiuta a sopravvivere a periodi di elevata volatilità. Nella prossima sezione, analizzerò come tutti questi componenti interagiscono nel trading reale.
Visualizzazione dei risultati dell'analisi
La visualizzazione è diventata una fase importante della mia ricerca. Dopo aver implementato tutti i moduli di calcolo, è stato necessario creare una rappresentazione visiva dei risultati. Ho sviluppato diversi componenti grafici chiave che aiutano a monitorare le prestazioni del sistema in tempo reale.
Ho iniziato visualizzando la struttura del portafoglio e la sua evoluzione:
def plot_portfolio_composition(weights_history): plt.figure(figsize=(15, 8)) ax = plt.gca() # Create a graph of weight changes over time dates = weights_history.index bottom = np.zeros(len(dates)) for symbol in weights_history.columns: plt.fill_between(dates, bottom, bottom + weights_history[symbol], label=symbol, alpha=0.6) bottom += weights_history[symbol] plt.title('Evolution of portfolio structure') plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left') plt.grid(True, alpha=0.3)
Particolare attenzione è stata dedicata alla visualizzazione dei rischi. Ho inoltre sviluppato una mappa di calore del VaR per diverse coppie di valute:
def plot_var_heatmap(var_matrix): plt.figure(figsize=(12, 8)) sns.heatmap(var_matrix, annot=True, cmap='RdYlBu_r', fmt='.2%', center=0) plt.title('Portfolio risk map (VaR)') # Add a timestamp plt.annotate(f'Last update: {datetime.now().strftime("%Y-%m-%d %H:%M")}', xy=(0.01, -0.1), xycoords='axes fraction')
Per analizzare la redditività, ho creato un grafico interattivo con gli eventi importanti evidenziati:
def plot_performance_analytics(returns_df, var_values, significant_events): fig = plt.figure(figsize=(15, 10)) gs = GridSpec(2, 1, height_ratios=[3, 1]) # Returns graph ax1 = plt.subplot(gs[0]) cumulative_returns = (1 + returns_df).cumprod() ax1.plot(cumulative_returns.index, cumulative_returns, label='Portfolio returns') # Mark important events for date, event in significant_events.items(): ax1.axvline(x=date, color='r', linestyle='--', alpha=0.3) ax1.annotate(event, xy=(date, ax1.get_ylim()[1]), xytext=(10, 10), textcoords='offset points', rotation=45) # VaR graph ax2 = plt.subplot(gs[1]) ax2.fill_between(var_values.index, -var_values, color='lightblue', alpha=0.5, label='Value at Risk')
Ho aggiunto una dashboard interattiva per monitorare lo stato del portafoglio:
class PortfolioDashboard: def __init__(self): self.fig = plt.figure(figsize=(15, 10)) self.setup_subplots() def setup_subplots(self): gs = self.fig.add_gridspec(3, 2) self.ax_returns = self.fig.add_subplot(gs[0, :]) self.ax_weights = self.fig.add_subplot(gs[1, 0]) self.ax_risk = self.fig.add_subplot(gs[1, 1]) self.ax_metrics = self.fig.add_subplot(gs[2, :]) def update(self, portfolio_data): self._plot_returns(portfolio_data['returns']) self._plot_weights(portfolio_data['weights']) self._plot_risk_metrics(portfolio_data['risk']) self._update_metrics_table(portfolio_data['metrics']) plt.tight_layout() plt.show()
Ho sviluppato una visualizzazione dinamica per analizzare le correlazioni:
def plot_correlation_dynamics(returns_df, window=60): # Calculation of dynamic correlations correlations = returns_df.rolling(window=window).corr() # Create an animated graph fig, ax = plt.subplots(figsize=(10, 10)) def update(frame): ax.clear() sns.heatmap(correlations.loc[frame], vmin=-1, vmax=1, center=0, cmap='RdBu', ax=ax) ax.set_title(f'Correlations on {frame.strftime("%Y-%m-%d")}')
Tutte queste visualizzazioni aiutano a valutare rapidamente lo stato del portafoglio e a prendere decisioni di trading. Nella prossima sezione, testerò il sistema.
Backtesting della strategia
Dopo aver completato lo sviluppo di tutti i componenti del sistema, mi sono trovato di fronte alla necessità di testarlo a fondo. Il processo si è rivelato molto più complicato del semplice funzionamento su dati storici. Era necessario tenere conto di molti fattori: lo slippage, le commissioni e le specificità dell'esecuzione degli ordini presso i diversi broker.
I primi backtest hanno dimostrato che l'approccio classico con spread fissi produce risultati eccessivamente ottimistici. Era necessario creare un modello più realistico che tenesse conto della variazione degli spread in base alla volatilità e all'ora del giorno.
Ho prestato particolare attenzione alla modellazione dei gap nei dati e dei problemi di liquidità. Nel trading reale, si verificano spesso situazioni in cui un ordine non può essere eseguito al prezzo stimato. Questi scenari devono essere gestiti correttamente durante la fase di test.
Ecco l'implementazione completa del sistema di backtesting:
class PortfolioBacktester: def __init__(self, initial_capital=100000, commission=0.0001): self.initial_capital = initial_capital self.commission = commission self.positions = {} self.trades_history = [] self.balance_history = [] self.var_history = [] self.metrics = {} def run_backtest(self, returns_df, optimization_params): self.current_capital = self.initial_capital portfolio_returns = [] # Preparing sliding windows for calculations window = 252 # Trading yesr for i in range(window, len(returns_df)): # Receive historical data for calculation historical_returns = returns_df.iloc[i-window:i] # Optimize the portfolio weights = self.optimize_portfolio( historical_returns, optimization_params['target_return'], optimization_params['max_var'] ) # Calculate VaR for the current distribution current_var = self.calculate_portfolio_var( historical_returns, weights, optimization_params['confidence_level'] ) # Check the need for rebalancing if self.should_rebalance(weights, current_var): self.execute_rebalancing(weights, returns_df.iloc[i]) # Update positions and calculate profitability portfolio_return = self.update_positions(returns_df.iloc[i]) portfolio_returns.append(portfolio_return) # Update metrics self.update_metrics(portfolio_return, current_var) # Check stop losses triggering self.check_stop_losses(returns_df.iloc[i]) # Calculate the final metrics self.calculate_final_metrics(portfolio_returns) def optimize_portfolio(self, returns, target_return, max_var): # Using our hybrid optimization model opt = HybridOptimizer(returns, target_return, max_var) weights = opt.optimize() return self.apply_position_limits(weights) def execute_rebalancing(self, target_weights, current_prices): for symbol, target_weight in target_weights.items(): current_weight = self.get_position_weight(symbol) if abs(target_weight - current_weight) > self.REBALANCING_THRESHOLD: # Simulate execution with slippage slippage = self.simulate_slippage(symbol, current_prices[symbol]) trade_price = current_prices[symbol] * (1 + slippage) # Calculate the deal size trade_volume = self.calculate_trade_volume( symbol, current_weight, target_weight ) # Consider commissions commission = abs(trade_volume * trade_price * self.commission) self.current_capital -= commission # Set a deal to history self.record_trade(symbol, trade_volume, trade_price, commission) def update_metrics(self, portfolio_return, current_var): self.balance_history.append(self.current_capital) self.var_history.append(current_var) # Updating performance metrics self.metrics['max_drawdown'] = self.calculate_drawdown() self.metrics['sharpe_ratio'] = self.calculate_sharpe() self.metrics['var_efficiency'] = self.calculate_var_efficiency() def calculate_final_metrics(self, portfolio_returns): returns_series = pd.Series(portfolio_returns) self.metrics['total_return'] = (self.current_capital / self.initial_capital - 1) self.metrics['volatility'] = returns_series.std() * np.sqrt(252) self.metrics['sortino_ratio'] = self.calculate_sortino(returns_series) self.metrics['calmar_ratio'] = self.calculate_calmar() self.metrics['var_breaches'] = self.calculate_var_breaches() def simulate_slippage(self, symbol, price): # Simulate realistic slippage base_slippage = 0.0001 # Basic slippage time_factor = self.get_time_factor() # Time dependency volume_factor = self.get_volume_factor(symbol) # Volume dependency return base_slippage * time_factor * volume_factorI risultati del test sono stati piuttosto rivelatori. Il modello ibrido ha dimostrato una resilienza significativamente maggiore agli shock di mercato rispetto agli approcci classici. Ciò è risultato particolarmente evidente durante i periodi di elevata volatilità, quando il limite del VaR ha di fatto protetto il portafoglio dai rischi eccessivi.
Debug finale
Dopo molti mesi di sviluppo e test, sono finalmente giunto alla versione finale del sistema. A dire il vero, è molto diverso da quello che avevo pianificato inizialmente. La pratica ha imposto molti cambiamenti, alcuni dei quali del tutto inaspettati.
Il primo grande cambiamento ha riguardato il modo in cui gestivo i dati. Mi sono reso conto che testare il sistema solo con dati storici non era sufficiente - era necessario verificarne il comportamento in un'ampia varietà di condizioni di mercato. Ho quindi sviluppato un sistema per generare dati sintetici. Sembra semplice, ma in realtà ci sono volute diverse settimane.
Ho iniziato suddividendo tutte le coppie di valute in gruppi in base alla liquidità. Il primo gruppo comprendeva le principali coppie di valute, come EURUSD e GBPUSD. Il secondo conteneva coppie di valute legate alle materie prime, come AUDUSD e USDCAD. Successivamente sono arrivati i cross: EURJPY, GBPJPY e altre. Infine, c'erano coppie esotiche, come CADJPY e EURAUD. Per ciascun gruppo, imposto i miei parametri di volatilità e correlazione, cercando di avvicinarmi il più possibile a quelli reali.
Ma la cosa più interessante è iniziata quando ho aggiunto diverse modalità di mercato. Immaginate: per un terzo del tempo il mercato è calmo, la volatilità è bassa. Un altro terzo è costituito da scambi normali. E il tempo rimanente è caratterizzato da una maggiore volatilità, in cui tutto impazzisce. Inoltre, ho aggiunto i trend a lungo termine e le fluttuazioni cicliche. Si è rivelato molto simile al mercato reale.
Anche l'ottimizzazione del portafoglio ha richiesto un certo impegno. Inizialmente pensavo di cavarmela con semplici restrizioni sui pesi delle posizioni, ma mi sono presto reso conto che non era sufficiente. Ho quindi aggiunto premi di rischio dinamici - maggiore è la volatilità della coppia, maggiore dovrebbe essere il rendimento potenziale. Restrizioni introdotte: minimo - 4% per posizione, massimo - 25%. Sembra tanto, ma se hai leva finanziaria, è normale.
Parlando della leva finanziaria. Questa è una storia a parte. All'inizio, ho preferito non rischiare e ho lavorato quasi senza. Tuttavia, le analisi hanno dimostrato che una leva finanziaria moderata, intorno a 10 a 1, migliorava significativamente i risultati. La cosa principale è tenere conto di tutti i costi in modo corretto. E ce ne sono parecchi: commissioni di negoziazione (due punti base), interessi per il mantenimento della leva finanziaria (0,01% al giorno), slippage di esecuzione. Tutto ciò doveva essere integrato nell'ottimizzatore.
Un altro problema, da mal di testa, è la protezione dalle richieste di margine (margin call). Dopo diversi esperimenti infruttuosi, ho optato per una soluzione semplice: se il drawdown supera il 10%, chiudere tutte le posizioni e salvare almeno una parte del capitale. Può sembrare una scelta prudente, ma a lungo termine si rivela vincente.
La parte più difficile è stata la generazione dei report. Quando il tuo sistema lavora con decine di coppie di valute e compra e vende costantemente qualcosa, è semplicemente impossibile tenere traccia di tutto. Ho dovuto sviluppare un intero sistema di monitoraggio: report annuali con una serie di metriche, grafici di ogni genere: dal semplice valore del portafoglio alle mappe di calore della distribuzione dei pesi.
Ho condotto i test finali per un lungo periodo - dal 2000 al 2024. Ho investito un milione di dollari come capitale iniziale e l'ho ribilanciato trimestralmente. Sono rimasto soddisfatto dei risultati. Il sistema si adatta bene alle diverse condizioni di mercato e mantiene i rischi sotto controllo. Anche nelle crisi più gravi, riesce a preservare la maggior parte del suo capitale.
Ma c'è ancora molto lavoro da fare. Vorrei integrare l'apprendimento automatico per prevedere la volatilità. Attualmente, il sistema funziona solo con dati storici. Inoltre, sto riflettendo su come rendere più flessibile la gestione della leva finanziaria. Anche la frequenza di ribilanciamento potrebbe essere ottimizzata. A volte un trimestre è troppo lungo, mentre altre volte si possono lasciare le posizioni invariate per sei mesi.
In generale, è andata completamente diversamente da come l'avevo pianificata inizialmente. Ma, come si suol dire, il meglio è nemico del bene. Il sistema funziona, controlla i rischi e genera profitto. E questa è la cosa principale.
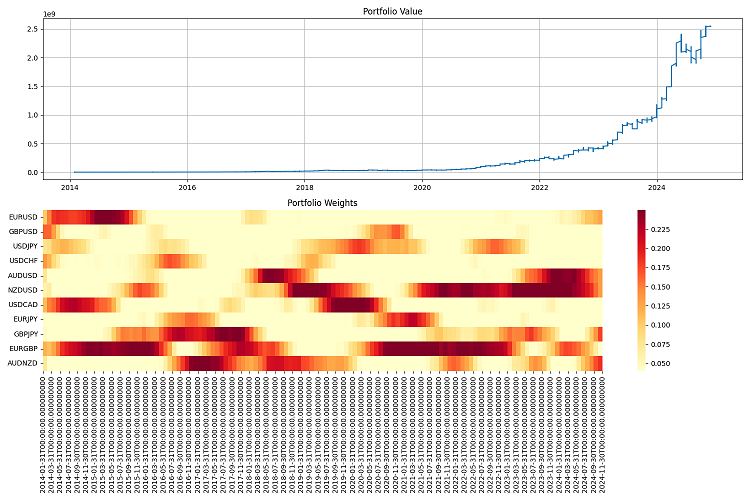
Conclusioni
È stato un bel percorso. Quando ho iniziato a cimentarmi con la teoria di Markowitz, non riuscivo nemmeno a immaginare cosa ne sarebbe venuto fuori. Volevo semplicemente applicare un approccio convenzionale al Forex, ma alla fine ho dovuto inventare una sorta di mostro di Frankenstein combinando diversi approcci alla gestione del rischio.
La cosa più incredibile è che sono riuscito a incrociare Markowitz con VaR, e funziona davvero! La cosa curiosa è che entrambi i metodi, presi singolarmente, si sono rivelati mediocri, ma insieme danno risultati eccellenti. Sono rimasto particolarmente soddisfatto di come il sistema si sia comportato in un mercato instabile. Il VaR è semplicemente straordinario come limitatore nell'ottimizzazione.
Certo, ho avuto molti problemi con la parte tecnica. Ma ora tutto viene preso in considerazione: slippage, commissioni e caratteristiche di esecuzione.
Ho testato il sistema su dati storici dal 2000 al 2024. I risultati sono stati piuttosto buoni. Si adatta bene alle diverse condizioni di mercato e non crolla nemmeno durante le crisi. Con una leva finanziaria di 10 a 1, funziona come un orologio svizzero. La cosa principale è controllare i rischi in modo rigoroso.
Ma c'è ancora tantissimo lavoro da fare. Vorrei:
- aggiungere l'apprendimento automatico alle previsioni di volatilità (questo sarà l'argomento del prossimo articolo);
- sistemare la frequenza di ribilanciamento - forse si può ottimizzare;
- rendere più intelligente la gestione della leva finanziaria (la leva dinamica e il caricamento dinamico "intelligente" dei depositi saranno implementati negli articoli futuri);
- addestrare il sistema ad adattarsi ancora meglio ai diversi regimi di mercato.
In generale, la conclusione principale è questa: un buon sistema di trading non si limita a essere un insieme di equazioni tratte da un libro di testo. Qui è necessario comprendere il mercato, essere esperti di tecnologia ed è soprattutto importante saper tenere sotto controllo i rischi. Tutti questi sviluppi possono ora essere applicati ad altri mercati, non solo al Forex. Sebbene ci sia ancora margine di miglioramento, le basi sono già presenti e funzionano.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/16604
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.


- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso