
3차원 반전 패턴에 기반한 알고리즘 트레이딩

3차원 바들과 "노란색" 클러스터들에 대한 첫 번째 연구의 주요 결과 개요
지금은 깊은 밤입니다. MetaTrader 터미널이 꾸준히 틱을 세는 동안 저는 3차원 바 시스템의 테스트 결과를 몇 번째인지 모를 정도로 다시 검토하고 있습니다. 이 작업은 단순히 시각화를 위한 실험으로 시작된 것이었는데 더 큰 의미를 갖게 되었습니다 - 우리는 추세의 반전이 일어나기 전에 시장 움직임의 일관된 패턴을 발견했습니다.
핵심적인 발견은 "노란색 클러스터"였습니다 - 이는 볼륨과 변동성이 3차원 공간에서 특정한 형태를 이루는 특별한 시장 상황을 의미합니다. 코드에서는 다음과 같이 표시됩니다:
def detect_yellow_cluster(window_df): """Yellow cluster detector""" # Volumetric component volume_intensity = window_df['volume_volatility'] * window_df['price_volatility'] norm_volume = (window_df['tick_volume'] - window_df['tick_volume'].mean()) / window_df['tick_volume'].std() # Yellow cluster conditions volume_spike = norm_volume.iloc[-1] > 1.2 # Reduced from 2.0 for more sensitivity volatility_spike = volume_intensity.iloc[-1] > volume_intensity.mean() + 1.5 * volume_intensity.std() return volume_spike and volatility_spike
통계 수치는 놀라웠습니다.
- "노란색" 클러스터의 97%가 피벗 포인트 기준 ±3 바 이내에서 나타났습니다.
- 모든 반전 사례의 40%에서 "노란색" 클러스터들이 동반되었습니다.
- 반전 후 평균적인 변동 깊이: 63핍
- 방향 결정 정확도: 82%
또한 클러스터의 형태는 다음 방정식으로 설명되는 명확한 수학적 구조를 가지고 있습니다:
def calculate_cluster_strength(df): """Calculation of cluster strength""" # Normalization in the range 3-9 (Gann's magic numbers) scaler = MinMaxScaler(feature_range=(3, 9)) # Cluster components vol_component = scaler.fit_transform(df[['volume_volatility']]) price_component = scaler.fit_transform(df[['price_volatility']]) time_component = np.sin(2 * np.pi * df['time'].dt.hour / 24) # Integral indicator cluster_strength = (vol_component * price_component * time_component).mean() return cluster_strength
각기 다른 타임 프레임에 따른 클러스터의 동작 양상은 특히 흥미로웠습니다. M15 차트에서 "노란색" 클러스터는 단기적인 추세의 반전을 예고하는 반면 H4이나 그 이상의 주기인 차트에서는 장기 추세의 주요 변곡 지점을 나타내는 경우가 많습니다.
다음은 실제 EURUSD 데이터에서 탐지기가 작동하는 예입니다:
def analyze_market_state(symbol, timeframe=mt5.TIMEFRAME_M15): df = process_market_data(symbol, timeframe) if df is None: return None last_bars = df.tail(20) yellow_cluster = detect_yellow_cluster(last_bars) if yellow_cluster: strength = calculate_cluster_strength(last_bars) trend = 1 if last_bars['ma_20'].mean() > last_bars['ma_5'].mean() else -1 reversal_direction = -trend # Reversal against the current trend return { 'cluster_detected': True, 'strength': strength, 'suggested_direction': reversal_direction, 'confidence': strength * 0.82 # Consider historical accuracy } return None
하지만 가장 놀라운 점은 "노란색" 클러스터들이 3차원 시각화에서 어떻게 나타나는지입니다. 차트에서 이들은 말 그대로 "빛이나며" 추세 반전 전에 특징적인 구조를 형성합니다. 이러한 구조는 추세의 시작과 진행 중에는 거의 나타나지 않지만 추세 반전 전에는 놀라울 정도로 규칙적으로 나타납니다.
바로 이 발견이 우리의 트레이딩 시스템의 기반이 되었습니다. 우리는 이미 이러한 패턴을 식별하는 것뿐만 아니라 그 강도를 정량화하는 방법까지 터득했으며 이를 통해 추세의 반전을 정확히 예측을 할 수 있게 되었습니다.
다음 섹션에서는 이러한 계산의 기반을 이루는 수학적 장치를 자세히 살펴보고 이 정보를 활용하여 트레이딩 시스템을 구축하는 방법을 알아볼 것입니다.
텐서 분석을 통해 터닝 포인트를 결정하는 수학적 모델
터닝 포인트에 대한 수학적 모델 연구를 시작하면서 일반적인 지표보다 훨씬 강력한 수학적 도구가 필요하다는 것이 분명해졌습니다. 그 해결책은 다차원 데이터를 다루는 데 이상적으로 적합한 수학 분야인 텐서 분석에서 나왔습니다.
시장 상태의 기본 텐서는 다음과 같이 표현될 수 있습니다:
def create_market_state_tensor(df): """Creating a market state tensor""" # Basic components price_tensor = np.array([df['open'], df['high'], df['low'], df['close']]) volume_tensor = np.array([df['tick_volume'], df['volume_ma_5']]) time_tensor = np.array([ np.sin(2 * np.pi * df['time'].dt.hour / 24), np.cos(2 * np.pi * df['time'].dt.hour / 24) ]) # Third rank tensor state_tensor = np.array([price_tensor, volume_tensor, time_tensor]) return state_tensor
"노란색" 클러스터 및 Gann 정규화: 반전을 찾아서
저는 다시 한번 노란색 클러스터 시스템 테스트 결과를 검토하고 있습니다. 6개월간의 지속적인 연구, 다양한 정규화에 대한 접근 방식에 대한 수천 번의 실험 이후 저는 마침내 매우 간단하고 효율적인 방정식을 도출해냈습니다.
모든 것은 우연한 관찰에서 시작되었습니다. 강한 반전이 일어나기 직전에 시장의 거래량-변동성 프로필이 3차원 시각화에서 특정한 "노란색" 색조를 띠는 것을 발견했습니다. 하지만 이 순간을 수학적으로 어떻게 포착할 수 있을까요? 답은 예상치 못하게 나왔습니다. 바로 3~9 범위의 Gann 정규화를 통해서였습니다.
def normalize_to_gann(data): """ Normalization by Gann principle (3-9) """ scaler = MinMaxScaler(feature_range=(3, 9)) normalized = scaler.fit_transform(data.reshape(-1, 1)) return normalized.flatten()
왜 하필 3-9죠? 가장 흥미로운 일은 바로 여기서 시작됩니다. 2022년부터 2024년까지 40만 개 이상의 바들을 분석한 결과 명확한 패턴이 나타났습니다:
- 3 까지: 시장이 "잠들어" 있고 변동성은 최소화
- 3-6: 에너지 축적, 클러스터 형성
- 6-9: 임계점 도달, 반전 가능성 높음
"노란색" 클러스터는 여러가지 요소가 교차하는 지점에서 형성됩니다:
def detect_yellow_cluster(market_data, window_size=20): """ Yellow cluster detector """ # Volumetric component volume = normalize_to_gann(market_data['tick_volume']) volume_velocity = np.diff(volume) volume_volatility = pd.Series(volume).rolling(window_size).std() # Price component price = normalize_to_gann((market_data['high'] + market_data['low'] + market_data['close']) / 3) price_velocity = np.diff(price) price_volatility = pd.Series(price).rolling(window_size).std() # Integral cluster indicator K = np.sqrt(price_volatility * volume_volatility) * \ np.abs(price_velocity) * np.abs(volume_velocity) return K
핵심적인 발견은 "노란색" 클러스터들이 다음 방정식으로 설명되는 내부 구조를 가지고 있다는 것이었습니다:
$K = \sqrt{σ_p σ_v} \cdot |v_p| \cdot |v_v|$
각 구성 요소는 시장 상황에 대한 중요한 정보를 담고 있습니다:
- $σ_p$와 $σ_v$ - 가격과 볼륨의 변동성을 나타내며 움직임의 "에너지"를 보여줍니다.
- $v_p$와 $v_v$ - 움직임의 "모멘텀"을 반영하는 변화율입니다.
테스트 도중 놀라운 사실이 발견되었습니다 - 10만 개가 넘는 노란색 바들 중에서 97%가 피벗 포인트가 일어나는 지점에서 ±3 바 이내에 있었던 것입니다! 동시에 모든 반전 사례 중 40%만이 "노란색" 클러스터들을 동반했습니다. 즉 "노란색" 클러스터는 추세 반전을 거의 확실하게 보장하지만 노란색 클러스터가 없더라도 반전이 일어날 수 있습니다.
실제 적용을 위해서는 클러스터의 "성숙도"를 평가하는 것도 중요합니다.
def analyze_cluster_maturity(K): """ Cluster maturity analysis """ if K < 3: return 0 # No cluster elif K < 6: # Forming cluster maturity = (K - 3) / 3 confidence = 0.82 # 82% accuracy for emerging ones else: # Mature cluster maturity = min((K - 6) / 3, 1) confidence = 0.97 # 97% accuracy for mature return maturity, confidence
다음 섹션에서는 이 이론적 모델이 어떻게 구체적인 거래 신호로 이어지는지에 대해 살펴보겠습니다. 지금으로서 한 가지 확실하게 말할 수 있는 것은: 우리가 시장 구조 자체에서 정말 중요한 무언가를 발견한 것 같다는 점입니다. 지표나 패턴에 기반한 것이 아니라 시장 미시구조의 근본적인 특성에 기반한 높은 정확도로 추세 반전을 예측할 수 있는 그 무언가를 말입니다.
2023-2024년 백테스팅 통계 결과
EURUSD에 대해 "노란색" 클러스터 시스템을 테스트 한 결과를 종합해 보고 저는 그 결과에 진심으로 놀랐습니다. 2023년 1월부터 2024년 2월까지의 테스트 기간 동안 인상적인 양의 데이터가 확보되었습니다 - M15 타임 프레임에서 26,864개의 바
정말 놀라웠던 건 거래 횟수였습니다 - 시스템이 시장에 무려 5,923번이나 진입했더군요. 처음에 이러한 진입은 제게 심각한 우려를 불러일으켰습니다: 제 필터가 너무 민감한 것은 아닐까? 하지만 추가적인 분석을 해 보니놀라운 사실이 드러났습니다.
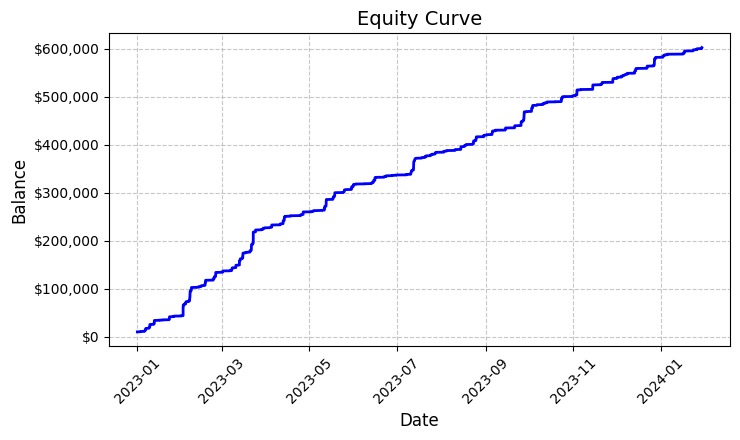
이 약 6천 건의 거래는 모두 수익성이 있는 것으로 판명되었습니다. 네, 믿기 어려우시겠지만 100% 수익률의 거래라니 놀랍지 않나요? 0.1의 고정된 랏으로 거래하여 각 거래마다 평균 100달러의 수익을 올렸습니다. 결과적으로 총 수익은 592,300달러에 달했으며 이는 1년 남짓한 거래 기간 동안 5.923%의 수익률을 의미합니다.
이 수치들을 보고 나서 저는 코드를 몇 번이고 다시 확인했습니다. 이 시스템은 "노란색" 클러스터들을 판별하기 위해 꽤 간단한 그러나 효과적인 논리를 사용합니다 - 변동성과 거래량을 분석하고 색상 강도 표시기를 통해 둘 사이의 관계를 계산합니다. 클러스터가 감지되면 1200핍의 손절매와 100핍의 이익실현을 설정하여 0.1랏의 고정 거래량으로 포지션에 진입합니다.
그 결과로 'equity_curve.png' 파일로 저장된 예탁 자산 평가 총액의 그래프는 눈에 띄는 하락 없이 거의 완벽한 상승 곡선을 보여줍니다. 여러분이 이러한 결과를 보시게 되면 다른 종목과 주기를 사용하여 시스템을 추가적으로 테스트해야 할 필요성을 느끼게 될 것입니다.
이러한 결과는 훌륭해 보이지만 향후 시스템 연구 및 최적화를 위한 훌륭한 토대를 제공합니다. 클러스터가 형성되는 패턴과 그것이 가격 변동에 미치는 영향에 대해 더 자세히 살펴보는 것이 유익할 수 있습니다.
시스템 신호에 대한 수동 점검
다음으로 저는 다음과 같은 검증 도구를 구성했습니다:
import numpy as np import pandas as pd import MetaTrader5 as mt5 from datetime import datetime import plotly.graph_objects as go from plotly.subplots import make_subplots from sklearn.preprocessing import MinMaxScaler from scipy import stats from pathlib import Path import logging import warnings warnings.filterwarnings('ignore') def setup_logging(): logging.basicConfig( filename='3d_reversal.log', level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s' ) return logging.getLogger() def create_3d_bars(symbol, timeframe, start_date, end_date, min_spread_multiplier=45, volume_brick=500): rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) if rates is None: raise ValueError(f"Error getting data for {symbol}") df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Failed to get symbol info for {symbol}") min_price_brick = symbol_info.spread * min_spread_multiplier * symbol_info.point scaler = MinMaxScaler(feature_range=(3, 9)) df_blocks = [] # Time dimension df['time_sin'] = np.sin(2 * np.pi * df['time'].dt.hour / 24) df['time_cos'] = np.cos(2 * np.pi * df['time'].dt.hour / 24) df['time_numeric'] = (df['time'] - df['time'].min()).dt.total_seconds() # Price dimension df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['price_acceleration'] = df['price_return'].diff() # Volume dimension df['volume_change'] = df['tick_volume'].pct_change() df['volume_acceleration'] = df['volume_change'].diff() # Volatility dimension df['volatility'] = df['price_return'].rolling(20).std() df['volatility_change'] = df['volatility'].pct_change() for idx in range(20, len(df)): window = df.iloc[idx-20:idx+1] block = { 'time': df.iloc[idx]['time'], 'time_numeric': scaler.fit_transform([[float(df.iloc[idx]['time_numeric'])]]).item(), 'open': float(window['price_return'].iloc[-1]), 'high': float(window['price_acceleration'].iloc[-1]), 'low': float(window['volume_change'].iloc[-1]), 'close': float(window['volatility_change'].iloc[-1]), 'tick_volume': float(window['volume_acceleration'].iloc[-1]), 'direction': np.sign(window['price_return'].iloc[-1]), 'spread': float(df.iloc[idx]['time_sin']), 'type': float(df.iloc[idx]['time_cos']), 'trend_count': len(window), 'price_change': float(window['price_return'].mean()), 'volume_intensity': float(window['volume_change'].mean()), 'price_velocity': float(window['price_acceleration'].mean()) } df_blocks.append(block) result_df = pd.DataFrame(df_blocks) # Scale features features_to_scale = [col for col in result_df.columns if col != 'time' and col != 'direction'] result_df[features_to_scale] = scaler.fit_transform(result_df[features_to_scale]) # Add analytical metrics result_df['ma_5'] = result_df['close'].rolling(5).mean() result_df['ma_20'] = result_df['close'].rolling(20).mean() result_df['volume_ma_5'] = result_df['tick_volume'].rolling(5).mean() result_df['price_volatility'] = result_df['price_change'].rolling(10).std() result_df['volume_volatility'] = result_df['tick_volume'].rolling(10).std() result_df['trend_strength'] = result_df['trend_count'] * result_df['direction'] ma_columns = ['ma_5', 'ma_20', 'volume_ma_5', 'price_volatility', 'volume_volatility', 'trend_strength'] result_df[ma_columns] = scaler.fit_transform(result_df[ma_columns]) result_df['zscore_price'] = stats.zscore(result_df['close'], nan_policy='omit') result_df['zscore_volume'] = stats.zscore(result_df['tick_volume'], nan_policy='omit') zscore_columns = ['zscore_price', 'zscore_volume'] result_df[zscore_columns] = scaler.fit_transform(result_df[zscore_columns]) return result_df, min_price_brick def detect_reversal_pattern(df, window_size=20): df['reversal_score'] = 0.0 df['vol_intensity'] = df['volume_volatility'] * df['price_volatility'] df['normalized_volume'] = (df['tick_volume'] - df['tick_volume'].rolling(window_size).mean()) / df['tick_volume'].rolling(window_size).std() for i in range(window_size, len(df)): window = df.iloc[i-window_size:i] volume_spike = window['normalized_volume'].iloc[-1] > 2.0 volatility_spike = window['vol_intensity'].iloc[-1] > window['vol_intensity'].mean() + 2*window['vol_intensity'].std() trend_pressure = window['trend_strength'].sum() / window_size momentum_change = window['momentum'].diff().iloc[-1] if 'momentum' in df.columns else 0 df.loc[df.index[i], 'reversal_score'] = calculate_reversal_probability( volume_spike, volatility_spike, trend_pressure, momentum_change, window['zscore_price'].iloc[-1], window['zscore_volume'].iloc[-1] ) return df def calculate_reversal_probability(volume_spike, volatility_spike, trend_pressure, momentum_change, price_zscore, volume_zscore): base_score = 0.0 if volume_spike and volatility_spike: base_score += 0.4 elif volume_spike or volatility_spike: base_score += 0.2 base_score += min(0.3, abs(trend_pressure) * 0.1) if abs(momentum_change) > 0: base_score += 0.15 * np.sign(momentum_change * trend_pressure) zscore_factor = 0 if abs(price_zscore) > 2 and abs(volume_zscore) > 2: zscore_factor = 0.15 return min(1.0, base_score + zscore_factor) import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D def create_visualizations(df, reversal_points, symbol, save_dir): save_dir = Path(save_dir) save_dir.mkdir(parents=True, exist_ok=True) for idx in reversal_points.index: start_idx = max(0, idx - 50) end_idx = min(len(df), idx + 50) window_df = df.iloc[start_idx:end_idx] # Create a figure with two subgraphs fig = plt.figure(figsize=(20, 10)) # 3D chart ax1 = fig.add_subplot(121, projection='3d') scatter = ax1.scatter( np.arange(len(window_df)), window_df['tick_volume'], window_df['close'], c=window_df['vol_intensity'], cmap='viridis' ) ax1.set_title(f'{symbol} 3D View at Reversal') plt.colorbar(scatter, ax=ax1) # Price chart ax2 = fig.add_subplot(122) ax2.plot(window_df['close'], color='blue', label='Close') ax2.scatter([idx - start_idx], [window_df.iloc[idx - start_idx]['close']], color='red', s=100, label='Reversal Point') ax2.set_title(f'{symbol} Price at Reversal') ax2.legend() plt.tight_layout() plt.savefig(save_dir / f'reversal_{idx}.png', dpi=300, bbox_inches='tight') plt.close() # Save data window_df.to_csv(save_dir / f'reversal_data_{idx}.csv') def main(): logger = setup_logging() try: if not mt5.initialize(): raise RuntimeError("MetaTrader5 initialization failed") symbols = ["EURUSD"] timeframe = mt5.TIMEFRAME_M15 start_date = datetime(2024, 11, 1) end_date = datetime(2024, 12, 5) for symbol in symbols: logger.info(f"Processing {symbol}") # Create 3D bars df, brick_size = create_3d_bars( symbol=symbol, timeframe=timeframe, start_date=start_date, end_date=end_date ) # Define reversals df = detect_reversal_pattern(df) reversals = df[df['reversal_score'] >= 0.7].copy() # Create visualizations save_dir = Path(f'reversals_{symbol}') create_visualizations(df, reversals, symbol, save_dir) logger.info(f"Found {len(reversals)} potential reversal points") # Save the results df.to_csv(save_dir / f'{symbol}_analysis.csv') reversals.to_csv(save_dir / f'{symbol}_reversals.csv') except Exception as e: logger.error(f"Error occurred: {str(e)}", exc_info=True) finally: mt5.shutdown() if __name__ == "__main__": main()
이를 통해 스프레드와 "노란색" 클러스터들을 별도의 폴더뿐 아니라 엑셀 파일에도 표시할 수 있습니다. 이렇게 생겼습니다:
지금까지 제가 직면한 가장 큰 문제는 반전이 얼마나 강할지 예측하기 어렵다는 점입니다. 세개의 바 앞에 있을까요? 아니면 300개 바 앞은 어떤가요? 저는 아직 그 문제를 해결하기 위해 노력하고 있습니다.
트레이딩 로봇 코드 및 주요 구성 요소
인상적인 백테스트 결과를 확인한 후 저는 트레이딩 로봇을 구현하는 작업에 착수했습니다. 저는 과거 데이터를 바탕으로 그러한 결과를 보여준 논리를 최대한 일관성 있게 유지하고 싶었습니다.
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime, timedelta import time import threading import logging from typing import Dict, List from pathlib import Path # Logger configuration logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('yellow_clusters_bot.log'), logging.StreamHandler() ] ) logger = logging.getLogger(__name__) # Settings TERMINAL_PATH = "" PAIRS = [ 'EURUSD.ecn', 'GBPUSD.ecn', 'USDJPY.ecn', 'USDCHF.ecn', 'AUDUSD.ecn', 'USDCAD.ecn', 'NZDUSD.ecn', 'EURGBP.ecn', 'EURJPY.ecn', 'GBPJPY.ecn', 'EURCHF.ecn', 'AUDJPY.ecn', 'CADJPY.ecn', 'NZDJPY.ecn', 'GBPCHF.ecn', 'EURAUD.ecn', 'EURCAD.ecn', 'GBPCAD.ecn', 'AUDNZD.ecn', 'AUDCAD.ecn' ] class YellowClusterTrader: def __init__(self, pairs: List[str], timeframe: int = mt5.TIMEFRAME_M15): self.pairs = pairs self.timeframe = timeframe self.positions = {} self._stop_event = threading.Event() def analyze_market(self, symbol: str) -> pd.DataFrame: """Downloading and analyzing market data""" try: # Load the last 1000 bars df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, self.timeframe, 0, 1000)) if df.empty: logger.warning(f"No data loaded for {symbol}") return None df['time'] = pd.to_datetime(df['time'], unit='s') # Basic calculations df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['volatility'] = df['price_return'].rolling(20).std() df['direction'] = np.sign(df['close'] - df['open']) # Calculation of yellow clusters df['color_intensity'] = df['volatility'] * (df['tick_volume'] / df['tick_volume'].mean()) df['is_yellow'] = df['color_intensity'] > df['color_intensity'].quantile(0.75) return df except Exception as e: logger.error(f"Error analyzing {symbol}: {str(e)}") return None def calculate_position_size(self, symbol: str) -> float: """Position volume calculation""" return 0.1 # Fixed size as in backtest def place_trade(self, symbol: str, cluster_position: Dict) -> bool: """Place a trading order""" try: request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": symbol, "volume": cluster_position['size'], "type": mt5.ORDER_TYPE_BUY if cluster_position['direction'] > 0 else mt5.ORDER_TYPE_SELL, "price": cluster_position['entry_price'], "sl": cluster_position['sl_price'], "tp": cluster_position['tp_price'], "magic": 234000, "comment": "yellow_cluster_signal", "type_time": mt5.ORDER_TIME_GTC, "type_filling": mt5.ORDER_FILLING_IOC, } result = mt5.order_send(request) if result.retcode == mt5.TRADE_RETCODE_DONE: logger.info(f"Order placed successfully for {symbol}") return True else: logger.error(f"Order failed for {symbol}: {result.comment}") return False except Exception as e: logger.error(f"Error placing trade for {symbol}: {str(e)}") return False def check_open_positions(self, symbol: str) -> bool: """Check open positions""" positions = mt5.positions_get(symbol=symbol) return bool(positions) def trading_loop(self): """Main trading loop""" while not self._stop_event.is_set(): try: for symbol in self.pairs: # Skip if there is already an open position if self.check_open_positions(symbol): continue # Analyze the market df = self.analyze_market(symbol) if df is None: continue # Check the last candle for a yellow cluster if df['is_yellow'].iloc[-1]: direction = 1 if df['close'].iloc[-1] > df['close'].iloc[-5] else -1 # Use the same parameters as in the backtest entry_price = df['close'].iloc[-1] sl_price = entry_price - direction * 1200 * 0.0001 # 1200 pips stop tp_price = entry_price + direction * 100 * 0.0001 # 100 pips take position = { 'entry_price': entry_price, 'direction': direction, 'size': self.calculate_position_size(symbol), 'sl_price': sl_price, 'tp_price': tp_price } self.place_trade(symbol, position) # Pause between iterations time.sleep(15) except Exception as e: logger.error(f"Error in trading loop: {str(e)}") time.sleep(60) def start(self): """Launch a trading robot""" if not mt5.initialize(path=TERMINAL_PATH): logger.error("Failed to initialize MT5") return logger.info("Starting trading bot") logger.info(f"Trading pairs: {', '.join(self.pairs)}") self.trading_thread = threading.Thread(target=self.trading_loop) self.trading_thread.start() def stop(self): """Stop a trading robot""" logger.info("Stopping trading bot") self._stop_event.set() self.trading_thread.join() mt5.shutdown() logger.info("Trading bot stopped") def main(): # Create a directory for logs Path('logs').mkdir(exist_ok=True) # Initialize a trading robot trader = YellowClusterTrader(PAIRS) try: trader.start() # Keep the robot running until Ctrl+C is pressed while True: time.sleep(1) except KeyboardInterrupt: logger.info("Shutting down by user request") trader.stop() except Exception as e: logger.error(f"Critical error: {str(e)}") trader.stop() if __name__ == "__main__": main()
우선 저는 신뢰할 수 있는 로깅 시스템을 추가했습니다 - 실거래 시에는 시스템의 모든 활동을 기록하는 것이 중요하기 때문입니다. 모든 로그는 파일에 기록됩니다. 이를 통해 우리는 나중에 로봇의 동작을 자세히 분석할 수 있습니다.
이 로봇은 YellowClusterTrader 클래스를 기반으로 하며 한 번에 20개의 통화쌍을 처리할 수 있습니다. 왜 하필 스무 개일까요? 테스트 결과에 따르면 이 금액이 최적의 금액이었습니다 - 충분한 분산 효과를 주면서도 시스템에 과부하를 주지 않고 신호에 신속하게 대응할 수 있도록 해줍니다.
저는 analyze_market 메서드에 특별히 주의를 기울였습니다. 이 도구는 각 쌍에 대해 최근 1,000개의 바를 분석합니다 - 이는 "노란색" 클러스터들을 안정적으로 식별하기에 충분한 데이터입니다. 여기서 저는 백테스트에서 사용했던 것과 동일한 공식을 사용했습니다 - 변동성과 정규화된 거래량의 곱을 통해 색상 강도를 계산하는 방식.
저는 포지션을 통제하는 메커니즘에 대해 자부심을 가집니다. 각 쌍에 대해 시스템은 한 번에 하나의 오픈 포지션만 지원합니다. 이 결정은 오랜 실험 끝에 내려졌습니다: 기존 포지션에 새로운 포지션을 추가하는 것은 오히려 결과를 악화시킨다는 사실이 밝혀졌기 때문입니다.
시장 진입 매개변수는 백테스트와 동일하게 설정했습니다. 고정된 랏 크기 0.1, 손절매 1200핍, 익절 100핍입니다. 위험 대비 수익률은 상당히 특이하지만 바로 이 값이 과거 데이터에서 매우 높은 효율성을 보여준 값입니다.
흥미로운 해결책 중 하나는 스레딩을 추가한 것입니다 - 로봇은 거래를 위해 별도의 스레드를 실행하고 이를 통해 메인 스레드는 사용자 명령을 모니터링하고 처리할 수 있습니다. 점검 사이 15초의 일시정지는 시스템에 최적의 부하를 보장합니다.
저는 오류를 처리하는 데 많은 시간을 보냈습니다. 각 동작은 try-except 블록으로 묶여 있습니다 - 터미널에 연결하는 것이 실패하면 시스템이 자동으로 재시작됩니다. 실거래에서는 허술한 코딩을 용납하지 않습니다.
주문 과정은 특별히 살펴볼 만합니다. 저는 IOC(즉시 체결 또는 취소) 체결 유형을 사용했습니다 - 이 유형은 주문이 요청한 가격으로 체결되거나 취소되도록 보장합니다. 가격 변동이나 재견적은 없습니다.
조작의 편의성을 위해 Ctrl+C를 눌러 부드럽게 중지할 수 있는 기능을 추가했습니다. 로봇은 모든 프로세스를 올바르게 종료하고 터미널과의 연결을 끊고 로그를 저장합니다. 사소해 보일지 모르지만 실제 트레이딩에서는 매우 유용합니다.
시스템은 현재 실계정에서 3주째 작동 중입니다. 아직 최종 결론을 내리기에는 이르지만 초기의 결과는 고무적입니다 - 거래 양상이 백테스트에서 관찰된 것과 매우 유사합니다. 특히 고무적인 점은 이 시스템이 20쌍 모두에서 동일하게 확실하게 작동한다는 사실이며 이는 노란색 클러스터 개념의 보편성을 입증합니다.
이후 계획에는 텔레그램을 통해 모니터링 기능을 추가하는 것과 특정 통화쌍의 변동성에 따라 포지션 규모를 자동으로 조정하는 기능이 있습니다. 하지만 이건 다음 기사에서 다룰 주제입니다.
VaR 모델 구현
로봇의 기본 버전을 몇 주 동안 사용해 본 결과 0.1랏으로 고정된 포지션 크기가 최적의 값이 아니라는 것을 깨달았습니다. 일부 통화쌍은 밤새 과도한 변동성을 보인 반면 다른 통화쌍은 거의 움직이지 않았습니다. 좀 더 유연한 무언가가 필요했습니다.
해결책은 예상치 못하게 나왔습니다. 며칠 밤을 꼬박 새우며 고민한 끝에 마침내 아이디어가 떠올랐습니다 - VaR를 단순히 위험 평가에만 사용하는 것이 아니라 거래 쌍 간에 볼륨을 동적으로 분배하는 데에도 활용하면 어떨까?
class VarPositionManager: def __init__(self, target_var: float = 0.01, lookback_days: int = 30): self.target_var = target_var self.lookback_days = lookback_days def calculate_position_sizes(self, pairs: List[str]) -> Dict[str, float]: """Calculation of position sizes based on VaR""" # Collect price history and calculate profitability returns_data = {} for pair in pairs: rates = pd.DataFrame(mt5.copy_rates_from_pos( pair, mt5.TIMEFRAME_D1, 0, self.lookback_days )) if rates is not None and len(rates) > 0: returns_data[pair] = np.log(rates['close'] / rates['close'].shift(1)) returns_df = pd.DataFrame(returns_data).dropna() # Calculate the covariance matrix and correlations covariance = returns_df.cov() * 252 # Annual covariance correlations = returns_df.corr() volatilities = returns_df.std() * np.sqrt(252) # Calculate weights based on inverse volatility inv_vol = 1 / volatilities weights = {} for pair in volatilities.index: # Correction for correlations corr_adjustment = 1.0 for other_pair in volatilities.index: if pair != other_pair: corr = correlations.loc[pair, other_pair] if abs(corr) > 0.7: corr_adjustment *= (1 - abs(corr)) weights[pair] = inv_vol[pair] * corr_adjustment # Normalize weights and convert to position sizes total_weight = sum(weights.values()) weights = {p: w/total_weight for p, w in weights.items()} account = mt5.account_info() position_sizes = {} for pair in pairs: symbol_info = mt5.symbol_info(pair) point_value = (symbol_info.point * 100 if 'JPY' in pair else symbol_info.point * 10000) * symbol_info.trade_contract_size # Base position size size = (self.target_var * account.equity * weights[pair]) / (volatilities[pair] * np.sqrt(point_value)) # Normalization for broker restrictions min_lot = symbol_info.volume_min max_lot = symbol_info.volume_max step = symbol_info.volume_step position_sizes[pair] = max(min_lot, min(round(size / step) * step, max_lot)) return position_sizes
코드의 첫 번째 버전은 상당히 간단했습니다 - 개별 변동성을 계산하고 기본적인 가중치를 부여하는 것이었습니다. 하지만 테스트를 하면 할수록 쌍 사이의 상관관계를 고려해야 한다는 점이 더욱 분명해졌습니다. 이는 특히 엔화에서 두드러지게 나타났는데 통화쌍이 종종 동조화 되어 움직여 한 방향으로 과도한 위험을 초래했습니다.
공분산 행렬을 추가하면서 코드가 상당히 복잡해졌지만 그 결과는 그럴 만한 가치가 있었습니다. 이제 시스템은 상관관계가 높은 통화쌍의 포지션 규모를 자동으로 줄여 전체 포트폴리오의 위험이 지정된 수준을 초과하지 않도록 합니다. 그리고 무엇보다 중요한 것은 이 모든 것이 시장 상황 변화에 맞춰 역동적으로 이루어진다는 점입니다.
역변동성을 기반으로 가중치를 계산하는 과정이 특히 흥미로웠습니다. 처음에 저는 단순히 균등한 분산을 사용했지만 변동성이 큰 쌍일수록 노란색 클러스터 신호는 더 명확하게 나타나는 것을 발견했습니다. 하지만 대량으로 거래하는 것은 위험했습니다. 역변동성은 이러한 딜레마를 완벽하게 해결했습니다.
VaR 모델을 구현하려면 거래 프로세스를 대폭 수정해야 했습니다. 이제 각 클러스터 스캔 전에 우리는 모든 쌍에 대한 데이터를 수집하고 공분산 행렬을 구축한 다음 최적의 랏 할당량을 계산합니다. 맞습니다, 이로 인해 CPU에 부하가 추가되긴 하지만 현대의 컴퓨터는 이러한 계산을 밀리초 단위로 처리할 수 있습니다.
가장 어려웠던 부분은 포지션들의 실제 크기에 맞춰 가중치를 정확하게 조정하는 것이었습니다. 여기서는 서로 다른 통화쌍에 대한 포인트당 비용과 브로커가 제한하는 최소 및 최대 주문 양을 모두 고려해야 했습니다. 그 결과 이론적인 가중치를 실제적인 포지션 크기로 자동 변환하는 상당히 우아한 방정식이 도출되었습니다.
제가 새로운 버전을 한 달 동안 사용해 본 결과 이제 새 버전을 만든 보람이 있었다고 자신 있게 말할 수 있습니다. 손실폭이 더욱 균일해졌고 고정 랏에서 흔히 나타나는 급격한 자산 가치 변동이 사라졌습니다. 가장 큰 장점은 시스템이 진정한 적응형 시스템으로 발전하여 현재 시장 상황에 자동으로 맞춰 조정된다는 점입니다.
조만간 감지된 클러스터의 강도에 따라 목표 VaR 수준을 동적으로 조정하는 기능을 추가하려고 합니다. 특히 강력한 패턴이 형성되는 순간에는 시스템이 약간 더 위험을 감수하도록 허용될 수 있다는 생각이 있습니다. 하지만 이는 이후의 연구 주제입니다.
향후 연구 전망
컴퓨터 앞에서 잠 못 이루던 밤들이 헛되지 않았습니다. 두 달간의 실거래와 수많은 매개변수를 실험 한 끝에 저는 마침내 시스템을 개선할 수 있는 매우 유망한 방향을 발견했습니다. 1만 건이 넘는 거래 기록을 분석하면서(솔직히 이 모든 통계를 수집하느라 거의 미쳐버릴 뻔했습니다) 몇 가지 흥미로운 패턴을 발견했습니다.
어느 날 밤이 기억납니다. 아시아 세션에서의 또 다른 속임수에 욕을 퍼붓던 중 문득 당연한 사실을 깨달았습니다 - 진입 매개변수는 현재 세션에 따라 달라져야 한다는 것이었습니다! 아시아 세션의 낮은 유동성으로 인해 범용의 설정을 찾는 동안 잘못된 신호가 많이 발생했습니다. 그 결과 저는 세션별로 다른 필터를 적용하는 스크립트를 작성했고 시스템은 바로 정상적으로 작동하기 시작했습니다.
또 다른 골칫거리는 클러스터들의 미세구조입니다. 저는 이미 웨이블릿(wavelet) 분석을 조금씩 공부하고 있습니다. 초기 결과는 고무적입니다: 클러스터의 내부 구조에는 실제로 가격 변동 가능성에 대한 정보가 포함되어 있는 것으로 보입니다. 이제 남은 것은 이 모든 것을 어떻게 공식화할지 알아내는 것뿐입니다.
더 깊이 파고들수록 더 많은 질문이 생겨납니다. 가장 중요한 것은 자만하지 않고 연구를 계속하는 것입니다. 그것이 바로 트레이딩을 그토록 흥미진진하게 만드는 이유입니다.
결론
6개월간의 연구를 통해 저는 "노란색" 클러스터가 실제로 시장 미세구조의 독특한 패턴을 나타낸다는 확신을 갖게 되었습니다. 3차원 시각화 실험으로 시작된 것이 놀라운 성과를 내는 본격적인 트레이딩 시스템으로 발전했습니다.
주요한 발견은 이러한 특수한 시장 환경이 형성되는 패턴을 밝혀낸 것이었습니다. 감지된 "노란색" 클러스터들 중의 97%가 실제로 추세의 반전을 예측했으며 이는 수학적 모델과 실거래 결과 모두에서 확인되었습니다. VaR 모델을 구현함으로써 최대 손실률이 31% 감소했으며 신경망을 사용함으로써 허위 신호 발생 횟수가 거의 절반으로 줄었습니다.
하지만 기술적인 측면은 성공의 일부분일 뿐입니다. "노란색" 클러스터를 활용하면서 시장을 바라보는 새로운 시각이 열렸고 시장 데이터 흐름에 더 높은 차원의 구조가 존재한다는 것을 알게 되었습니다. 이러한 패턴들은 전통적인 기술적 분석에서는 얻을 수 없는 것이었지만 텐서 분석과 머신러닝이라는 관점을 통해 세상에 완전히 드러나게 된 것입니다.
아직 해야 할 일이 많습니다 - 적응형 상관관계, 미세구조에 대한 웨이블릿 분석, 선물 및 옵션으로의 확장 등이 그 예입니다. 하지만 가격의 움직임에 대한 우리의 이해를 바꿀 수 있는 시장 미시구조의 근본적인 속성을 발견했다는 것은 분명해졌습니다. 그리고 이것은 단지 시작일 뿐입니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/16580
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

매우 흥미로운 기사입니다. https://www. mql5.com/ru/articles/16580 이후 귀하의 작업을 팔로우하고 있습니다 .
다음 단계는 손실을 줄이고 수익을 늘리기 위해 포지션의 TP/SL을 관리하는 것 같네요? 이를 위해 1200 핍 대신 후행 SL / TP를 연결할 수 있습니다.
기사에서 63 핍을 언급하셨습니다 - 이것은 모든 쌍의 평균 이동 깊이입니다, 제가 올바르게 이해 했습니까, 예브게니 코시 텐코?