
윌리엄 간 메서드(3부): 점성술은 맞는 건가요?

소개
금융 시장의 참여자들은 끊임없이 새롭고 새로운 시장 분석 및 예측 방법을 찾고 있습니다. 믿기 힘든 개념도 빠뜨리지 않습니다. 이 중 비 표준적이고 완전히 독특한 접근 방식 중 하나는 유명한 트레이더인 윌리엄 간이 대중화시킨 점성술을 트레이딩에 사용하는 것입니다.
이전 글에서 이미 간의 도구에 대해 다룬 바 있습니다. 첫 번째와 두 번째 파트는 다음과 같습니다. 우리는 이제 행성과 별의 위치가 세계 시장에 미치는 영향을 살펴보는 데 초점을 맞춰 볼 것입니다.
가장 현대적인 기술과 고대의 지식을 결합해 보겠습니다. 천문 현상과 EURUSD 쌍의 움직임 사이의 연관성을 찾기 위해 파이썬 프로그래밍 언어와 MetaTrader 5 플랫폼을 사용할 것입니다. 금융에서의 점성술에 대한 이론적인 부분을 다루고 예측 시스템 개발의 실제적인 부분을 직접 시도해 보겠습니다.
또한 천문학적 데이터와 재무 데이터를 수집하고 동기화하고 상관관계 매트릭스를 만들고 결과를 시각화 하는 방법을 살펴봅니다.
금융에서 점성술의 이론적 근거
저는 오랫동안 이 주제에 관심을 가져왔습니다. 오늘은 점성술이 금융 시장에 미치는 영향에 대한 저의 생각을 공유하고자 합니다. 논란의 여지가 있긴 하지만 이 분야는 정말 매력적인 분야입니다.
제가 이해하는 금융 점성술의 기본 개념은 천체의 움직임이 시장 사이클과 어떤 식으로 든 관련이 있다는 것입니다. 이 개념은 길고 풍부한 역사를 가지고 있습니다. 특히 지난 세기의 유명한 트레이더인 윌리엄 간이 대중화했습니다.
저는 이 이론의 기본 원리에 대해 많은 생각을 해왔습니다. 예를 들어 별과 행성의 움직임이 본질적으로 주기적이라는 순환론처럼 시장 움직임도 마찬가지로 주기적으로 움직인다는 개념입니다. 행성적인 측면에서는 특정 행성의 위치가 시장에 큰 영향을 미친다고 생각하는 분들도 있습니다. 조디악 판은 어떨까요? 다른 황도 별자리를 통과하는 행성의 통과도 시장에 어떤 식으로 든 영향을 미친다고 믿어집니다.
달의 주기와 태양의 활동도 고려해 볼 가치가 있습니다. 저는 달의 위상은 시장의 단기 변동과 관련이 있고 태양 플레어는 장기적인 추세와 관련이 있다는 의견을 본 적이 있습니다. 흥미로운 가설이죠?
윌리엄 간은 이 분야의 진정한 선구자로 천문학, 기하학, 수열을 기반으로 유명한 9의 정사각형과 같은 여러 도구를 개발했습니다. 그러나 간의 도구들은 여전히 열띤 논쟁을 불러일으킵니다.
물론 과학계 전체가 점성술에 대해 회의적이라는 점을 무시할 수는 없습니다. 많은 국가에서 사이비 과학으로 공식적으로 인정받고 있기도 합니다. 솔직히 말해서 금융에서 점성술을 사용하는 것이 효율적인지에 대한 엄격한 증거는 아직 없습니다. 종종 관찰된 특정 상관관계는 단순히 인지적인 편견의 결과인 것으로 밝혀 지기도 합니다.
그럼에도 불구하고 금융 점성술이란 아이디어를 열렬히 옹호하는 트레이더가 많습니다.
그래서 직접 조사를 해보기로 했습니다. 저는 통계적 방법과 빅데이터를 활용해 점성술이 금융시장에 미치는 영향에 대해 객관적인 평가를 내려보고자 합니다. 무언가 흥미로운 것을 발견하게 될지 누가 알겠습니까? 어느 쪽이든 스타와 주식 차트가 교차하는 세계로의 매혹적인 여행이 될 것입니다.
적용된 Python 라이브러리 개요
파이썬 라이브러리 전체가 필요합니다.
우선 천문 데이터를 얻기 위해 Skyfield 패키지를 사용하기로 했습니다. 올바른 도구를 선택하기 위해 오랜 시간 고민했는데, 저는 Skyfield의 정확성에 깊은 인상을 받았습니다. 덕분에 천체의 위치와 달의 위상 등 데이터 세트에 필요한 모든 정보를 소수점 이하까지 매우 정밀하게 수집할 수 있게 되었습니다.
시장 데이터의 경우에는 파이썬용 공식 MetaTrader 5 라이브러리를 선택했습니다. 통화쌍의 과거 데이터를 다운로드할 수 있으며 필요한 경우 거래도 가능합니다.
Pandas는 데이터 작업의 충실한 동반자가 될 것입니다. 저는 과거에 이 라이브러리를 많이 사용했습니다. 시계열 작업에 없어서는 안 될 필수 요소로 수집된 모든 데이터의 전처리 및 동기화에 사용될 것입니다.
통계 분석을 위해 저는 SciPy 라이브러리를 사용하기로 결정했습니다. 다양한 기능, 특히 상관관계 및 회귀 분석 도구가 인상적입니다. 흥미로운 패턴을 찾는 데 도움이 되길 기대합니다.
결과를 시각화하기 위해 저는 오랜 친구인 Matplotlib과 Seaborn을 사용하기로 결정했습니다. 저는 그래프를 유연하게 만들 수 있는 이 라이브러리를 좋아합니다. 모든 결과를 시각화 하는 데 도움이 될 것이라고 확신합니다.
이제 전체 세트가 준비되었습니다. 이는 마치 우수한 부품으로 강력한 PC를 조립하는 것과 같습니다. 이제 우리는 점성술적 요인이 금융 시장에 미치는 영향에 대한 종합적인 연구를 수행하는 데 필요한 모든 것을 갖추게 되었습니다. 빨리 데이터에 뛰어들어 가설을 테스트하고 싶습니다!
천문학 데이터 수집
import pandas as pd import numpy as np from skyfield.api import load, wgs84, utc from skyfield.data import mpc from datetime import datetime, timedelta import requests # Loading planet ephemerides planets = load('de421.bsp') earth = planets['earth'] ts = load.timescale() def get_planet_positions(date): t = ts.from_datetime(date.replace(tzinfo=utc)) planet_positions = {} planet_ids = { 'mercury': 'MERCURY BARYCENTER', 'venus': 'VENUS BARYCENTER', 'mars': 'MARS BARYCENTER', 'jupiter': 'JUPITER BARYCENTER', 'saturn': 'SATURN BARYCENTER', 'uranus': 'URANUS BARYCENTER', 'neptune': 'NEPTUNE BARYCENTER' } for planet, planet_id in planet_ids.items(): planet_obj = planets[planet_id] astrometric = earth.at(t).observe(planet_obj) ra, dec, _ = astrometric.radec() planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees} return planet_positions def get_moon_phase(date): t = ts.from_datetime(date.replace(tzinfo=utc)) eph = load('de421.bsp') moon, sun, earth = eph['moon'], eph['sun'], eph['earth'] e = earth.at(t) _, m, _ = e.observe(moon).apparent().ecliptic_latlon() _, s, _ = e.observe(sun).apparent().ecliptic_latlon() phase = (m.degrees - s.degrees) % 360 return phase def get_solar_activity(date): # Get solar activity data from NOAA API url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json" response = requests.get(url) data = response.json() # Convert date to 'YYYY-MM' format target_date = date.strftime("%Y-%m") # Find the closest date in the data closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m"))) return { 'sunspot_number': closest_data.get('ssn', None), 'f10.7_flux': closest_data.get('f10.7', None) } def calculate_aspects(positions): aspects = {} planets = list(positions.keys()) for i in range(len(planets)): for j in range(i+1, len(planets)): planet1 = planets[i] planet2 = planets[j] ra1 = positions[planet1]['ra'] ra2 = positions[planet2]['ra'] angle = abs(ra1 - ra2) % 24 angle = min(angle, 24 - angle) * 15 # Convert to degrees if abs(angle - 0) <= 10 or abs(angle - 180) <= 10: aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition" elif abs(angle - 90) <= 10: aspects[f"{planet1}_{planet2}"] = "square" elif abs(angle - 120) <= 10: aspects[f"{planet1}_{planet2}"] = "trine" return aspects start_date = datetime(2024, 4, 1, tzinfo=utc) end_date = datetime(2024, 5, 31, tzinfo=utc) current_date = start_date astronomical_data = [] while current_date <= end_date: planet_positions = get_planet_positions(current_date) moon_phase = get_moon_phase(current_date) try: solar_activity = get_solar_activity(current_date) except Exception as e: print(f"Error getting solar activity for {current_date}: {e}") solar_activity = {'sunspot_number': None, 'f10.7_flux': None} aspects = calculate_aspects(planet_positions) data = { 'date': current_date, 'moon_phase': moon_phase, 'sunspot_number': solar_activity.get('sunspot_number'), 'f10.7_flux': solar_activity.get('f10.7_flux'), **planet_positions, **aspects } astronomical_data.append(data) current_date += timedelta(days=1) print(f"Processed: {current_date}") # Convert data to DataFrame df = pd.DataFrame(astronomical_data) # Save data to CSV file df.to_csv('astronomical_data_2018_2024.csv', index=False) print("Data saved to astronomical_data_2018_2024.csv")
이 Python 코드는 향후 시장 분석에 사용할 천문학 데이터를 수집합니다.
이 코드는 2018년 1월 1일부터 2024년 5월 31일까지의 기간을 사용하며 다음과 같은 다양한 데이터를 수집합니다:
- 행성의 위치 - 금성, 수성, 화성, 목성, 토성, 천왕성, 해왕성
- 달의 위상
- 태양 활동
- 행성 각(행성이 서로 어떻게 정렬되는지)
이 스크립트에는 라이브러리 가져오기 메인 루프, Excel 형식의 데이터 저장이 포함되어 있습니다. 이 코드는 이미 언급한 Skyfield 라이브러리를 사용하여 행성 위치, 데이터용 Pandas, 태양 활동 데이터 가져오기 요청을 계산합니다.
주목할 만한 함수에는 행성의 위치(오른쪽 상승 및 하강)를 가져오는 get_planet_positions(), 현재 달의 위상을 찾는 get_moon_phase(), NOAA API에서 태양 활동 데이터를 직접 제공하는 get_solar_activity(), 행성의 서로에 대한 위치인 측면을 계산하는 calculate_aspects()가 있습니다.
우리는 매일 모든 데이터를 수집하고 나중에 사용할 수 있도록 모든 내용을 하나의 Excel 파일에 저장합니다.
MetaTrader 5를 통한 금융 데이터 가져오기
금융 데이터를 얻기 위해 파이썬용 MetaTrader 5 라이브러리를 사용합니다. 라이브러리를 통해 직접 금융 데이터를 다운로드하고 모든 상품에 대한 시계열 가격을 받을 수 있습니다. 다음은 과거 데이터를 로드 하는 코드입니다:
import MetaTrader5 as mt5
import pandas as pd
from datetime import datetime
# Connect to MetaTrader5
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
# Set query parameters
symbol = "EURUSD"
timeframe = mt5.TIMEFRAME_D1
start_date = datetime(2018, 1, 1)
end_date = datetime(2024, 12, 31)
# Request historical data
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
# Convert data to DataFrame
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
# Save data to CSV file
df.to_csv(f'{symbol}_data.csv', index=False)
# Terminate the connection to MetaTrader5
mt5.shutdown()
이 스크립트는 트레이딩 터미널에 연결하여 EURUSD D1의 데이터를 수신한 다음 데이터 프레임을 생성하고 단일 CSV 파일에 저장합니다.
천문학적 데이터와 재무 데이터 동기화하기
그래서 우리는 천문학에 대한 데이터도 가지고 있고 EURUSD에 대한 데이터도 가지고 있습니다. 이제 동기화해야 합니다. 데이터를 날짜별로 결합하여 단일 데이터 집합이 재무와 천문학의 필요한 모든 정보를 포함하도록 해 보겠습니다.
import pandas as pd
# Load data
astro_data = pd.read_csv('astronomical_data_2018_2024.csv')
financial_data = pd.read_csv('EURUSD_data.csv')
# Convert date columns to datetime
astro_data['date'] = pd.to_datetime(astro_data['date'])
financial_data['time'] = pd.to_datetime(financial_data['time'])
# Merge data
merged_data = pd.merge(financial_data, astro_data, left_on='time', right_on='date', how='inner')
# Save merged data
merged_data.to_csv('merged_astro_financial_data.csv', index=False)
스크립트는 저장된 모든 데이터를 로드하고 날짜 열의 형식을 날짜/시간 형식으로 만들고 날짜별로 데이터 집합을 결합합니다. 그 결과로 우리는 이후의 분석에 필요한 모든 데이터가 포함된 CSV 파일을 얻게 됩니다.
상관관계에 대한 통계 분석
계속 진행하겠습니다. 우리는 공통 집합, 공통 데이터 세트를 가지고 있으며 이제 천문학과 시장 움직임 사이에 데이터에 어떤 관계가 있는지 알아볼 때입니다. 우리는 pandas 라이브러리의 corr() 함수를 사용할 것입니다. 또한 두 코드를 하나로 통합할 예정입니다.
다음은 그 최종 스크립트입니다:
import pandas as pd
import numpy as np
from skyfield.api import load, wgs84, utc
from skyfield.data import mpc
from datetime import datetime, timedelta
import requests
import MetaTrader5 as mt5
import seaborn as sns
import matplotlib.pyplot as plt
# Part 1: Collecting astronomical data
# Loading planetary ephemerides
planets = load('de421.bsp')
earth = planets['earth']
ts = load.timescale()
def get_planet_positions(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
planet_positions = {}
planet_ids = {
'mercury': 'MERCURY BARYCENTER',
'venus': 'VENUS BARYCENTER',
'mars': 'MARS BARYCENTER',
'jupiter': 'JUPITER BARYCENTER',
'saturn': 'SATURN BARYCENTER',
'uranus': 'URANUS BARYCENTER',
'neptune': 'NEPTUNE BARYCENTER'
}
for planet, planet_id in planet_ids.items():
planet_obj = planets[planet_id]
astrometric = earth.at(t).observe(planet_obj)
ra, dec, _ = astrometric.radec()
planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees}
return planet_positions
def get_moon_phase(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
eph = load('de421.bsp')
moon, sun, earth = eph['moon'], eph['sun'], eph['earth']
e = earth.at(t)
_, m, _ = e.observe(moon).apparent().ecliptic_latlon()
_, s, _ = e.observe(sun).apparent().ecliptic_latlon()
phase = (m.degrees - s.degrees) % 360
return phase
def get_solar_activity(date):
url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json"
response = requests.get(url)
data = response.json()
target_date = date.strftime("%Y-%m")
closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m")))
return {
'sunspot_number': closest_data.get('ssn', None),
'f10.7_flux': closest_data.get('f10.7', None)
}
def calculate_aspects(positions):
aspects = {}
planets = list(positions.keys())
for i in range(len(planets)):
for j in range(i+1, len(planets)):
planet1 = planets[i]
planet2 = planets[j]
ra1 = positions[planet1]['ra']
ra2 = positions[planet2]['ra']
angle = abs(ra1 - ra2) % 24
angle = min(angle, 24 - angle) * 15 # Convert to degrees
if abs(angle - 0) <= 10 or abs(angle - 180) <= 10:
aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition"
elif abs(angle - 90) <= 10:
aspects[f"{planet1}_{planet2}"] = "square"
elif abs(angle - 120) <= 10:
aspects[f"{planet1}_{planet2}"] = "trine"
return aspects
# Collecting astronomical data
start_date = datetime(2024, 3, 1, tzinfo=utc)
end_date = datetime(2024, 7, 30, tzinfo=utc)
current_date = start_date
astronomical_data = []
while current_date <= end_date:
planet_positions = get_planet_positions(current_date)
moon_phase = get_moon_phase(current_date)
try:
solar_activity = get_solar_activity(current_date)
except Exception as e:
print(f"Error getting solar activity for {current_date}: {e}")
solar_activity = {'sunspot_number': None, 'f10.7_flux': None}
aspects = calculate_aspects(planet_positions)
data = {
'date': current_date,
'moon_phase': moon_phase,
'sunspot_number': solar_activity.get('sunspot_number'),
'f10.7_flux': solar_activity.get('f10.7_flux'),
**planet_positions,
**aspects
}
astronomical_data.append(data)
current_date += timedelta(days=1)
print(f"Processed: {current_date}")
# Convert data to DataFrame and save
astro_df = pd.DataFrame(astronomical_data)
astro_df.to_csv('astronomical_data_2018_2024.csv', index=False)
print("Astronomical data saved to astronomical_data_2018_2024.csv")
# Part 2: Retrieving financial data via MetaTrader5
# Initialize connection to MetaTrader5
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
# Set request parameters
symbol = "EURUSD"
timeframe = mt5.TIMEFRAME_D1
start_date = datetime(2024, 3, 1)
end_date = datetime(2024, 7, 30)
# Request historical data
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
# Convert data to DataFrame
financial_df = pd.DataFrame(rates)
financial_df['time'] = pd.to_datetime(financial_df['time'], unit='s')
# Save financial data
financial_df.to_csv(f'{symbol}_data.csv', index=False)
print(f"Financial data saved to {symbol}_data.csv")
# Shutdown MetaTrader5 connection
mt5.shutdown()
# Part 3: Synchronizing astronomical and financial data
# Load data
astro_df = pd.read_csv('astronomical_data_2018_2024.csv')
financial_df = pd.read_csv('EURUSD_data.csv')
# Convert date columns to datetime
astro_df['date'] = pd.to_datetime(astro_df['date']).dt.tz_localize(None)
financial_df['time'] = pd.to_datetime(financial_df['time'])
# Merge data
merged_data = pd.merge(financial_df, astro_df, left_on='time', right_on='date', how='inner')
# Save merged data
merged_data.to_csv('merged_astro_financial_data.csv', index=False)
print("Merged data saved to merged_astro_financial_data.csv")
# Part 4: Statistical analysis of correlations
# Select numeric columns for correlation analysis
numeric_columns = merged_data.select_dtypes(include=[np.number]).columns
# Create lags for astronomical data
for col in numeric_columns:
if col not in ['open', 'high', 'low', 'close', 'tick_volume', 'spread', 'real_volume']:
for lag in range(1, 6): # Create lags from 1 to 5
merged_data[f'{col}_lag{lag}'] = merged_data[col].shift(lag)
# Update list of numeric columns
numeric_columns = merged_data.select_dtypes(include=[np.number]).columns
# Calculate correlation matrix
correlation_matrix = merged_data[numeric_columns].corr()
# Create heatmap of correlations
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm', vmin=-1, vmax=1, center=0)
plt.title('Correlation Matrix of Astronomical Factors (with Lags) and EURUSD Prices')
plt.tight_layout()
plt.savefig('correlation_heatmap_with_lags.png')
plt.close()
# Output the most significant correlations with the closing price
significant_correlations = correlation_matrix['close'].sort_values(key=abs, ascending=False)
print("Most significant correlations with the closing price:")
print(significant_correlations)
# Create a separate correlation matrix for astronomical data with lags and the current price
astro_columns = [col for col in numeric_columns if col not in ['open', 'high', 'low', 'tick_volume', 'spread', 'real_volume']]
astro_columns.append('close') # Add the current closing price
astro_correlation_matrix = merged_data[astro_columns].corr()
# Create heatmap of correlations for astronomical data with lags and the current price
import seaborn as sns
import matplotlib.pyplot as plt
# Increase the header and axis label font
plt.figure(figsize=(18, 14))
sns.heatmap(astro_correlation_matrix, annot=False, cmap='coolwarm', vmin=-1, vmax=1, center=0, cbar_kws={'label': 'Correlation'})
plt.title('Correlation matrix of astronomical factors (with lags) and current EURUSD price', fontsize=24)
plt.xlabel('X-axis Label', fontsize=30)
plt.ylabel('Y-axis Label', fontsize=30)
plt.xticks(fontsize=30)
plt.yticks(fontsize=30)
plt.tight_layout()
plt.savefig('astro_correlation_heatmap_with_lags.png')
plt.close()
print("Analysis completed. Results saved in CSV and PNG files.")
이 스크립트는 데이터 집합의 모든 숫자 간의 상관관계 맵과 모든 상관관계의 행렬을 히트맵 형식으로 표시하고 종가와 함께 가장 중요한 상관관계 목록을 생성합니다.
상관관계의 유무가 인과관계의 유무를 의미하지는 않습니다. 천문학적 데이터와 가격 변동 사이에 강한 상관관계가 있다고 하더라도 이것이 한 요인이 다른 요인을 결정한다는 의미는 아니며 그 반대의 경우도 마찬가지입니다. 상관관계 맵은 가장 기본적인 것일 뿐입니다. 새로운 연구가 필요합니다.
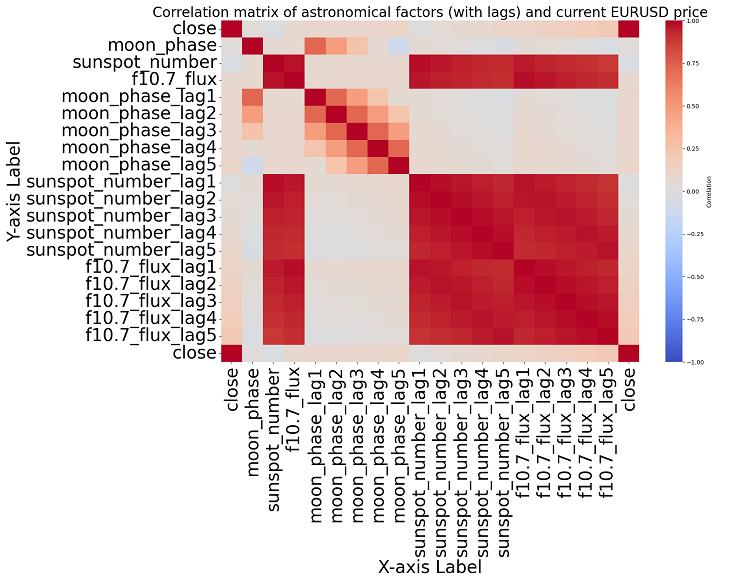
주제에 더 가까이 다가가면 우리는 데이터에서 유의미한 상관관계를 찾을 수 없습니다. 과거 천문학 데이터와 시장 지표 사이에는 명확한 상관관계가 없습니다.
구원자인 머신 러닝
다음에 무엇을 할까 고민하다가 머신러닝 모델을 적용하기로 결정했습니다. 저는 데이터 세트의 데이터를 피처로 사용하여 미래 가격을 예측하는 CatBoost 라이브러리를 사용하여 두 개의 스크립트를 만들었습니다. 다음은 회귀 모델 중 첫 번째 모델입니다:
import pandas as pd
import numpy as np
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
# Loading data
data = pd.read_csv('merged_astro_financial_data.csv')
# Converting date to datetime
data['date'] = pd.to_datetime(data['date'])
# Creating lags for financial data
for col in ['open', 'high', 'low', 'close']:
for lag in range(1, 6): # Creating lags from 1 to 5
data[f'{col}_lag{lag}'] = data[col].shift(lag)
# Creating lags for astronomical data
astro_cols = ['mercury', 'venus', 'mars', 'jupiter', 'saturn', 'uranus', 'neptune']
for col in astro_cols:
data[f'{col}_ra'] = data[col].apply(lambda x: eval(x)['ra'] if pd.notna(x) else np.nan)
data[f'{col}_dec'] = data[col].apply(lambda x: eval(x)['dec'] if pd.notna(x) else np.nan)
for lag in range(1, 6): # Lags from 1 to 5
data[f'{col}_ra_lag{lag}'] = data[f'{col}_ra'].shift(lag)
data[f'{col}_dec_lag{lag}'] = data[f'{col}_dec'].shift(lag)
data.drop(columns=[col, f'{col}_ra', f'{col}_dec'], inplace=True)
# Converting aspects to numerical features
aspect_cols = ['mercury_saturn', 'venus_mars', 'venus_jupiter', 'venus_uranus',
'mars_jupiter', 'mars_uranus', 'jupiter_uranus', 'mercury_neptune',
'venus_saturn', 'venus_neptune', 'mars_saturn', 'mercury_venus',
'mars_neptune', 'mercury_uranus', 'saturn_neptune', 'mercury_jupiter',
'mercury_mars', 'jupiter_saturn']
# Using LabelEncoder for encoding aspects
label_encoders = {}
for col in aspect_cols:
label_encoders[col] = LabelEncoder()
data[col] = label_encoders[col].fit_transform(data[col].astype(str))
# Filling missing values with mean values for numeric columns
numeric_cols = data.select_dtypes(include=[np.number]).columns
data[numeric_cols] = data[numeric_cols].fillna(data[numeric_cols].mean())
# Removing rows with missing values
data = data.dropna()
# Preparing features and target variable
features = [col for col in data.columns if col not in ['date', 'time', 'close']]
X = data[features]
y = data['close']
# Splitting data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Creating and training the CatBoost model
model = CatBoostRegressor(iterations=500, learning_rate=0.1, depth=9, random_state=1)
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=200, verbose=100)
# Evaluating the model
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"Mean Absolute Error: {mae}")
print(f"R-squared Score: {r2}")
# Visualizing feature importance
feature_importance = model.feature_importances_
feature_names = X.columns
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
plt.figure(figsize=(12, 6))
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(feature_names)[sorted_idx])
plt.xlabel('Feature Importance')
plt.title('Feature Importance')
plt.show()
# Predicting the next value
def predict_next():
# Selecting the last row of data
last_data = data.iloc[-1]
input_features = last_data[features].values.reshape(1, -1)
# Prediction
prediction = model.predict(input_features)
print(f"Prediction for the next closing price: {prediction[0]}")
# Example of using the function to predict the next value
predict_next()

두 번째 모델은 분류입니다:
import pandas as pd
import numpy as np
from skyfield.api import load, utc
from datetime import datetime, timedelta
import requests
import MetaTrader5 as mt5
import seaborn as sns
import matplotlib.pyplot as plt
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.preprocessing import LabelEncoder
# Part 1: Collecting astronomical data
planets = load('de421.bsp')
earth = planets['earth']
ts = load.timescale()
def get_planet_positions(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
planet_positions = {}
planet_ids = {
'mercury': 'MERCURY BARYCENTER',
'venus': 'VENUS BARYCENTER',
'mars': 'MARS BARYCENTER',
'jupiter': 'JUPITER BARYCENTER',
'saturn': 'SATURN BARYCENTER',
'uranus': 'URANUS BARYCENTER',
'neptune': 'NEPTUNE BARYCENTER'
}
for planet, planet_id in planet_ids.items():
planet_obj = planets[planet_id]
astrometric = earth.at(t).observe(planet_obj)
ra, dec, _ = astrometric.radec()
planet_positions[planet] = {'ra': ra.hours, 'dec': dec.degrees}
return planet_positions
def get_moon_phase(date):
t = ts.from_datetime(date.replace(tzinfo=utc))
eph = load('de421.bsp')
moon, sun, earth = eph['moon'], eph['sun'], eph['earth']
e = earth.at(t)
_, m, _ = e.observe(moon).apparent().ecliptic_latlon()
_, s, _ = e.observe(sun).apparent().ecliptic_latlon()
phase = (m.degrees - s.degrees) % 360
return phase
def get_solar_activity(date):
url = f"https://services.swpc.noaa.gov/json/solar-cycle/observed-solar-cycle-indices.json"
response = requests.get(url)
data = response.json()
target_date = date.strftime("%Y-%m")
closest_data = min(data, key=lambda x: abs(datetime.strptime(x['time-tag'], "%Y-%m") - datetime.strptime(target_date, "%Y-%m")))
return {
'sunspot_number': closest_data.get('ssn', None),
'f10.7_flux': closest_data.get('f10.7', None)
}
def calculate_aspects(positions):
aspects = {}
planets = list(positions.keys())
for i in range(len(planets)):
for j in range(i+1, len(planets)):
planet1 = planets[i]
planet2 = planets[j]
ra1 = positions[planet1]['ra']
ra2 = positions[planet2]['ra']
angle = abs(ra1 - ra2) % 24
angle = min(angle, 24 - angle) * 15 # Convert to degrees
if abs(angle - 0) <= 10 or abs(angle - 180) <= 10:
aspects[f"{planet1}_{planet2}"] = "conjunction" if abs(angle - 0) <= 10 else "opposition"
elif abs(angle - 90) <= 10:
aspects[f"{planet1}_{planet2}"] = "square"
elif abs(angle - 120) <= 10:
aspects[f"{planet1}_{planet2}"] = "trine"
return aspects
# Part 2: Obtaining financial data through MetaTrader5
def get_financial_data(symbol, start_date, end_date):
if not mt5.initialize():
print("initialize() failed")
mt5.shutdown()
return None
timeframe = mt5.TIMEFRAME_D1
rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date)
mt5.shutdown()
financial_df = pd.DataFrame(rates)
financial_df['time'] = pd.to_datetime(financial_df['time'], unit='s')
return financial_df
# Part 3: Synchronizing astronomical and financial data
def sync_data(astro_df, financial_df):
astro_df['date'] = pd.to_datetime(astro_df['date']).dt.tz_localize(None)
financial_df['time'] = pd.to_datetime(financial_df['time'])
merged_data = pd.merge(financial_df, astro_df, left_on='time', right_on='date', how='inner')
return merged_data
# Part 4: Training the model and making predictions
def train_and_predict(merged_data):
# Converting aspects to numerical features
aspect_cols = [col for col in merged_data.columns if '_' in col and col not in ['date', 'time']]
label_encoders = {}
for col in aspect_cols:
label_encoders[col] = LabelEncoder()
merged_data[col] = label_encoders[col].fit_transform(merged_data[col].astype(str))
# Creating lags for financial data
for col in ['open', 'high', 'low', 'close']:
for lag in range(1, 6):
merged_data[f'{col}_lag{lag}'] = merged_data[col].shift(lag)
# Creating lags for astronomical data
astro_cols = ['mercury', 'venus', 'mars', 'jupiter', 'saturn', 'uranus', 'neptune']
for col in astro_cols:
merged_data[f'{col}_ra'] = merged_data[col].apply(lambda x: eval(x)['ra'] if pd.notna(x) else np.nan)
merged_data[f'{col}_dec'] = merged_data[col].apply(lambda x: eval(x)['dec'] if pd.notna(x) else np.nan)
for lag in range(1, 6):
merged_data[f'{col}_ra_lag{lag}'] = merged_data[f'{col}_ra'].shift(lag)
merged_data[f'{col}_dec_lag{lag}'] = merged_data[f'{col}_dec'].shift(lag)
merged_data.drop(columns=[col, f'{col}_ra', f'{col}_dec'], inplace=True)
# Filling missing values with mean values for numeric columns
numeric_cols = merged_data.select_dtypes(include=[np.number]).columns
merged_data[numeric_cols] = merged_data[numeric_cols].fillna(merged_data[numeric_cols].mean())
merged_data = merged_data.dropna()
# Creating binary target variable
merged_data['price_change'] = (merged_data['close'].shift(-1) > merged_data['close']).astype(int)
# Removing rows with missing values in the target variable
merged_data = merged_data.dropna(subset=['price_change'])
features = [col for col in merged_data.columns if col not in ['date', 'time', 'close', 'price_change']]
X = merged_data[features]
y = merged_data['price_change']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
model = CatBoostClassifier(iterations=500, learning_rate=0.1, depth=9, random_state=1)
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=200, verbose=100)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
clf_report = classification_report(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Classification Report:")
print(clf_report)
print("Confusion Matrix:")
print(conf_matrix)
# Visualizing feature importance
feature_importance = model.feature_importances_
feature_names = X.columns
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
plt.figure(figsize=(12, 6))
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(feature_names)[sorted_idx])
plt.xlabel('Feature Importance')
plt.title('Feature Importance')
plt.show()
# Predicting the next value
def predict_next():
last_data = merged_data.iloc[-1]
input_features = last_data[features].values.reshape(1, -1)
prediction = model.predict(input_features)
print(f"Price change prediction (0: will decrease, 1: will increase): {prediction[0]}")
predict_next()
# Main program
start_date = datetime(2023, 3, 1)
end_date = datetime(2024, 7, 30)
astro_data = []
current_date = start_date
while current_date <= end_date:
planet_positions = get_planet_positions(current_date)
moon_phase = get_moon_phase(current_date)
try:
solar_activity = get_solar_activity(current_date)
except Exception as e:
print(f"Error getting solar activity for {current_date}: {e}")
solar_activity = {'sunspot_number': None, 'f10.7_flux': None}
aspects = calculate_aspects(planet_positions)
astro_data.append({
'date': current_date,
'mercury': str(planet_positions['mercury']),
'venus': str(planet_positions['venus']),
'mars': str(planet_positions['mars']),
'jupiter': str(planet_positions['jupiter']),
'saturn': str(planet_positions['saturn']),
'uranus': str(planet_positions['uranus']),
'neptune': str(planet_positions['neptune']),
'moon_phase': moon_phase,
**solar_activity,
**aspects
})
current_date += timedelta(days=1)
astro_df = pd.DataFrame(astro_data)
symbol = "EURUSD"
financial_data = get_financial_data(symbol, start_date, end_date)
if financial_data is not None:
merged_data = sync_data(astro_df, financial_data)
train_and_predict(merged_data) 안타깝게도 두 모델 모두 정확도가 높지 않습니다. 분류 정확도는 50%보다 약간 높으며 이는 동전 던지기로도 쉽게 예측할 수 있다는 의미입니다.
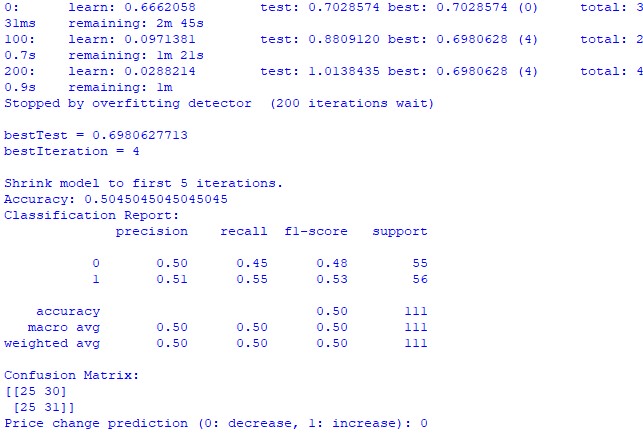
결과는 개선될 수 있을 것입니다. 회귀 모델에 거의 관심을 기울이지 않았고 실제로 행성의 위치와 달과 태양의 활동을 사용하여 가격을 예측할 수 있기 때문입니다. 추후 이 주제에 대한 다른 기사를 작성하겠습니다.
결과
이제 결과를 요약할 차례입니다. 간단한 분석을 수행하고 두 가지 예측 모델을 작성한 후 점성술이 시장에 미칠 잠재적 영향에 대한 연구 결과를 확인했습니다.
상관관계 분석. 우리가 얻은 상관관계 맵에서는 행성별 포지션과 EURUSD 종가 사이에 강한 상관관계가 발견되지 않았습니다. 모든 상관관계가 0.3보다 약하기 때문에 별이나 행성의 위치가 금융 시장과 전혀 관련이 없다고 볼 수 있습니다.
CatBoost 회귀 모델. 회귀 모형의 최종 결과는 천문학적인 데이터를 기반으로 하면 정확한 미래의 종가를 예측하는 능력이 매우 떨어진다는 것을 보여주었습니다.
결과 모델 성능 지표(예: MSE, MAE, R 제곱)는 매우 약하며 데이터를 잘 설명하지 못하고 행성 위치보다는 시차와 이전 가격값이 가장 중요한 특징임을 보여줍니다. 그렇다면 가격이 태양계 내 어떤 행성의 위치보다 더 나은 지표라는 뜻일까요?
CatBoost 분류 모델. 이 분류 모델은 미래의 가격 상승 또는 하락을 예측하는 데 매우 취약합니다. 정확도는 50%를 간신히 넘기며 이는 천문학이 실제 시장에서 작동하지 않는다는 것을 확인시켜줍니다.
결론
결과는 명확합니다 - 점성술과 천문학적 데이터를 기반으로 실제 시장의 가격을 예측하려는 시도는 완전히 쓸모가 없습니다. 다시 이 주제로 돌아가겠지만 현재로서는 윌리엄 간의 테크닉은 책과 트레이딩 코스를 판매하기 위해 만들어진 작동하지 않는 솔루션을 위장하려는 시도처럼 보입니다.
간의 각도 값, 9의 정사각형, 간 격자 값 등을 사용하는 개선된 모델이 더 나은 성능을 낼 수 있을까요? 아직은 알 수 없습니다. 저는 연구 결과에 조금 실망했습니다.
하지만 저는 여전히 간의 각도가 어떤 식으로 든 가격의 예측을 하는 데 사용될 수 있다고 생각합니다. 가격은 어떤 식으로 든 각도에 영향을 미치며 이전 연구 결과에서 알 수 있듯이 가격은 각도에 반응합니다. 각도를 모델 학습을 위한 훈련을 위한 피처로 사용할 수도 있습니다. 저는 그런 데이터 집합을 만들어서 어떤 결과가 나오는지 확인해 볼 예정입니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/15625
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

가나의 발자취를 따라 순수한 경험을 위해 EURUSD가 아니라 예를 들어 면화 선물을 선택했어야 했습니다. 그리고 그 상품은 거의 동일하며 결국 농업이라는 천문학적 주기가 그 안에 있을 수 있습니다.