
Prévision de séries chronologiques à l'aide du lissage exponentiel (suite)

Introduction
L'article "Time Series Forecasting Using Exponential Smoothing" [1] a donné un bref résumé des modèles de lissage exponentiel, a illustré une des approches possibles pour optimiser les paramètres du modèle et a finalement proposé l'indicateur de prévision élaboré sur la base du modèle de croissance linéaire avec amortissement. . Cet article représente une tentative d'augmenter quelque peu la précision de cet indicateur de prévision.
Il est difficile de prédire les cotations des devises ou d'obtenir une prévision assez fiable même pour trois ou quatre longueurs d’avance. Néanmoins, comme dans l'article précédent de cette série, nous créerons des prévisions à 12 longueurs d'avance, sachant bien qu'il sera impossible d'obtenir des résultats satisfaisants sur un si long horizon. Les premières étapes de la prévision avec les intervalles de confiance les plus étroits doivent donc être privilégiées.
Une prévision à 10 à 12 longueurs d'avance est principalement destinée à la démonstration des caractéristiques comportementales de divers modèles et méthodes de prévision. Dans tous les cas, la précision de la prévision obtenue pour n'importe quel horizon peut être évaluée en utilisant les limites de l'intervalle de confiance. Cet article vise essentiellement à la démonstration de certaines méthodes qui peuvent aider à mettre à niveau l'indicateur comme indiqué dans l'article [1].
L'algorithme pour trouver le minimum d'une fonction de plusieurs variables qui est appliqué dans l'élaboration des indicateurs a été traité dans l'article précédent et ne sera donc pas décrit à plusieurs reprises ici. Pour ne pas surcharger l'article, les apports théoriques seront réduits au minimum.
1. Indicateur Initial
L'indicateur IndicatorES.mq5 (voir article [1]) sera utilisé comme point de départ.
Pour la compilation de l'indicateur, nous aurons besoin de IndicatorES.mq5, CIndicatorES.mqh et PowellsMethod.mqh, tous situés dans le même répertoire. Les fichiers peuvent être disponibles dans l'archive files2.zip à la fin de l'article.
Rafraîchissons les équations qui définissent le modèle de lissage exponentiel utilisé pour élaborer cet indicateur - le modèle de croissance linéaire avec amortissement.
![]()
![]()
![]()
Ou:
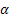 - paramètre de lissage pour le niveau de la séquence [0,1] ;
- paramètre de lissage pour le niveau de la séquence [0,1] ;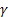 - paramètre de lissage pour la tendance [0,1] ;
- paramètre de lissage pour la tendance [0,1] ;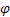 - paramètre d'amortissement [0,1];
- paramètre d'amortissement [0,1];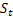 - niveau lissé de la séquence calculé à l'instant t après avoir été
- niveau lissé de la séquence calculé à l'instant t après avoir été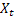 observé ;
observé ;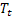 - tendance additive lissée calculée à l'instant t ;
- tendance additive lissée calculée à l'instant t ;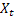 - valeur de la séquence à l'instant t ;
- valeur de la séquence à l'instant t ;
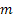 - nombre de pas en avant pour lesquels la prévision est faite ;
- nombre de pas en avant pour lesquels la prévision est faite ;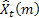 - prévision m- de longueur d’avance réalisée à l'instant t ;
- prévision m- de longueur d’avance réalisée à l'instant t ;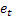 - erreur de prévision d'un pas à l'instant t,
- erreur de prévision d'un pas à l'instant t,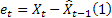 .
.
Le seul paramètre d'entrée de l'indicateur est la valeur déterminant la longueur de l'intervalle selon laquelle les paramètres du modèle seront optimisés et les valeurs initiales (intervalle d'étude) sélectionnées. Suite à la détermination des valeurs optimales des paramètres du modèle à un intervalle donné et aux calculs nécessaires, la prévision, l'intervalle de confiance et la ligne correspondant à la prévision à une longueur d'avance sont créés. A chaque nouvelle barre, les paramètres sont optimisés et la prévision est faite.
Puisque l'indicateur en question va être mis à niveau, l'effet des changements que nous allons apporter sera évalué à l'aide des séquences de test de l'archive Files2.zip situées à la fin de l'article. Le répertoire d'archive \Dataset2 comporte des fichiers avec les cotations EURUSD, USDCHF, USDJPY et US sauvegardées. Indice du Dollar DXY. Chacune d'entre elles est prévue pour trois périodes, à savoir M1, H1 et D1. Les valeurs "ouvertes" sauvegardées dans les fichiers sont situées de manière à ce que la valeur la plus récente soit à la fin du fichier. Chaque fichier comporte 1200 éléments.
Les erreurs de prévision seront estimées en calculant le coefficient "Mean Absolute Percentage Error" (MAPE)
![]()
Divisons chacune des douze séquences de test en 50 sections superposées comprenant chacune 80 éléments et calculons la valeur MAPE pour chacune d'elles. La moyenne des estimations ainsi obtenue servira d'indice d'erreur de prévision par rapport aux indicateurs soumis à comparaison. Les valeurs MAPE pour les erreurs de prévision à deux et trois étapes seront calculées de la même manière. Ces estimations moyennées seront également désignées comme suit :
- MAPE1 – estimation moyennée de l'erreur de prévision en une longueur d’avance;
- MAPE2 – estimation moyenne de l'erreur de prévision en deux longueurs d’avance ;
- MAPE3 – estimation moyenne de l'erreur de prévision en trois longueurs d’avance ;
- MAPE1-3 – moyenne (MAPE1+MAPE2+MAPE3)/3.
Lors du calcul de la valeur MAPE, la valeur d'erreur de prévision absolue est à chaque étape divisée par la valeur actuelle de la séquence. Afin d'éviter la division par zéro ou l'obtention de valeurs négatives ainsi, les séquences d'entrée doivent prendre uniquement des valeurs positives non-nulles, comme dans notre cas.
Les valeurs estimées de notre indicateur initial sont présentées dans le tableau 1.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0.2099 | 0.2925 | 0.3564 | 0.2863 |
Tableau 1. Estimations initiales de l'erreur de prévision de l'indicateur
Les données affichées dans le Tableau 1 sont obtenues à l'aide du script Errors_IndicatorES.mq5 (à partir de l'archive files2.zip située à la fin de l'article). Pour compiler et exécuter le script, il est nécessaire que CIndicatorES.mqh et PowellsMethod.mqh se trouvent dans le même répertoire que Errors_IndicatorES.mq5 et que les séquences d'entrée se trouvent dans le répertoire Files\Dataset2\.
Après avoir obtenu les premières estimations des erreurs de prévision, nous pouvons maintenant procéder à la mise à niveau de l'indicateur à l’étude.
2. Critère d'Optimisation
Les paramètres du modèle de l’indicateur initial présentés dans l’article "Time Series Forecasting Using Exponential Smoothing"étaient déterminés par la minimisation de la somme des carrés de l’erreur de prévision d’une longueur d’avance. Il semble logique que les paramètres du modèle optimaux pour une prévision à une longueur d'avance puissent ne pas produire d'erreurs minimales pour une prévision à une longueur d’avance. Il serait bien entendu souhaitable de minimiser les erreurs de prévision à 10 à 12 longueurs d'avance, mais obtenir un résultat de prévision satisfaisant sur la plage donnée pour les séquences à l’étude serait une mission impossible.
Étant réaliste, lors de l'optimisation des paramètres du modèle, nous utiliserons la somme des carrés des erreurs de prévision à un, deux et trois longueurs d’avance comme première mise à niveau de notre indicateur. Nous pouvons s'attendre à ce que le nombre moyen d'erreurs diminue quelque peu au cours des trois premiers stades de la prévision.
Il est clair qu'une telle mise à niveau de l'indicateur initial ne concerne pas ses grands principes structurels mais modifie uniquement le critère d'optimisation du paramètre. Par conséquent, nous ne pouvons pas nous attendre à ce que la précision des prévisions augmente plusieurs fois, bien que le nombre d'erreurs de prévision à deux et trois longueurs d’avance devrait diminuer un peu.
Afin de comparer les résultats des prévisions, nous avons créé la classe CMod1 similaire à la classe CIndicatorES introduite dans l'article précédent avec la fonction objective modifiée func.
La fonction func de la classe CIndicatorES initiale :
double CIndicatorES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 sse=0; for(i=0;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(Dlen*MathLog(k1*k2*k3*sse)); }
Suite à quelques modifications, la fonction func se présente désormais comme suit
double CMod1::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95; // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*k3*err); }
Maintenant, lors du calcul de la fonction objective, la somme des carrés des erreurs de prévision à un, deux et trois longueurs d’avance est utilisée.
De plus, sur la base de cette classe, le script Errors_Mod1.mq5 a été élaboré, permettant d'estimer les erreurs de prévision, comme le fait le script Errors_IndicatorES.mq5 déjà mentionné. CMod1.mqh et Errors_Mod1.mq5 se trouvent dans l'archive files2.zip à la fin de l'article.
Le tableau 2 présente les estimations d'erreur de prévision pour les versions initiales et mises à niveau.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0.2099 | 0.2925 | 0.3564 | 0.2863 |
| Mod1 | 0.2144 | 0.2898 | 0.3486 | 0.2842 |
Tableau 2. Comparaison des estimations d'erreur de prévision
Comme on peut le voir, les coefficients d'erreur MAPE2 et MAPE3 et la valeur moyenne MAPE1-3 se sont en effet avérés légèrement inférieurs pour les séquences à l’étude. Alors sauvegardons cette version et procédons à une autre modification de notre indicateur.
3. Ajustement des paramètres dans le processus de lissage
L'idée de modifier les paramètres de lissage en fonction des valeurs courantes de la séquence d'entrée n'est ni nouvelle ni originale et émane de la volonté d'ajuster les coefficients de lissage pour qu'ils demeurent optimaux compte tenu de toute modification dans la nature de la séquence d'entrée. Certaines manières d'ajuster les coefficients de lissage sont décrites dans la bibliographie [2], [3].
Pour mettre à niveau davantage l'indicateur, nous utiliserons le modèle avec un coefficient de lissage changeant dynamiquement, en espérant que l'utilisation du modèle de lissage exponentiel adaptatif nous permettra d'augmenter la précision des prévisions de notre indicateur.
Malheureusement, lorsqu'elles sont utilisées dans des algorithmes de prévision, la majorité des méthodes adaptatives ne donnent pas toujours les résultats escomptés. La sélection de la méthode adaptative adéquate peut sembler trop lourde et chronophage ; par conséquent, dans notre cas, nous exploiterons les résultats fournis dans la bibliographie [4] et essayerons d'employer l'approche "Smooth Transition Exponential Smoothing" (STES) présentée dans l'article [5].
L'essence de l'approche est clairement décrite dans l'article spécifié, nous la laisserons donc de côté ici et passerons directement aux équations de notre modèle (voir le début de l'article spécifié) en tenant compte de l'utilisation du coefficient de lissage adaptatif.
![]()
![]()
![]()
![]()
Comme on peut maintenant le voir, la valeur du coefficient de lissage alpha est calculée à chaque étape de l'algorithme et dépend du carré de l'erreur de prévision. Les valeurs des coefficients b et g déterminent l'effet de l'erreur de prévision sur la valeur alpha. À tous autres égards, les équations du modèle employé sont restées inchangées. Des informations supplémentaires concernant l'utilisation de l'approche STES peuvent être disponibles dans l'article [6].
Alors que dans les versions précédentes, nous devions déterminer la valeur optimale du coefficient alpha sur la séquence d'entrée donnée, il y a maintenant deux coefficients adaptatifs b et g qui sont soumis à optimisation et la valeur alpha sera déterminée dynamiquement dans le processus de lissage la séquence d'entrée.
Cette mise à niveau est implémentée sous la forme de la classe CMod2. Les changements majeurs (comme la fois précédente) concernaient principalement la fonction func qui se présente désormais comme suit.
double CMod2::func(const double &p[]) { int i; double s,t,alp,gam,phi,sb,sg,k1,k2,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; gam=p[2]; phi=p[3]; sb=p[4]; sg=p[5]; k1=1; k2=1; if (gam>0.95){k1+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k1+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k2+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k2+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*err); }
Lors de l’élaboration de cette fonction, l'équation définissant la valeur du coefficient alpha a été légèrement modifiée. Cela a été fait pour définir la limite de la valeur maximale et minimale admissible de ce coefficient à 0,05 et 0,95, respectivement.
Pour estimer les erreurs de prévision, comme cela se faisait auparavant, le script Errors_Mod2.mq5 a été écrit sur la base de la classe CMod2. CMod2.mqh et Errors_Mod2.mq5 se trouvent dans l'archive files2.zip à la fin de l'article.
Les résultats du script sont présentés dans le tableau 3.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0.2099 | 0.2925 | 0.3564 | 0.2863 |
| Mod1 | 0.2144 | 0.2898 | 0.3486 | 0.2842 |
| Mod2 | 0.2145 | 0.2832 | 0.3413 | 0.2797 |
Tableau 3. Comparaison des estimations d'erreur de prévision
Comme le suggère le tableau 3, l'utilisation du coefficient de lissage adaptatif a permis en moyenne de diminuer encore légèrement les erreurs de prévision pour nos séquences de test. Ainsi, après deux mises à niveau, nous avons réussi à diminuer le coefficient d'erreur MAPE1-3 d'environ deux pour cent.
Malgré un résultat de mise à niveau plutôt modeste, nous nous en tiendrons à la version résultante et laisserons les mises à jour supplémentaires hors de la portée de l'article. Dans une prochaine étape, il serait intéressant d'essayer d'utiliser la transformation de Box-Cox. Cette transformation est principalement utilisée pour rapprocher la distribution de séquence initiale de la distribution normale.
Dans notre cas, il pourrait être utilisé pour transformer la séquence initiale, calculer la prévision et inverser la prévision. Le coefficient de transformation appliqué à cette fin doit être sélectionné de sorte à minimiser l'erreur de prévision résultante. Un exemple d'utilisation de la transformation de Box-Cox dans des séquences de prévision peut être disponible dans l'article [7].
4. Intervalle de Confiance des Prévisions
L'intervalle de confiance de prévision dans l'indicateur initial IndicatorES.mq5 (énoncé dans l'article précédent) a été calculé selon les expressions analytiques dérivées pour le modèle de lissage exponentiel sélectionné [8]. Les modifications apportées dans notre cas ont conduit à des changements dans le modèle à l’étude. Le coefficient de lissage variable rend inapproprié l'utilisation des expressions analytiques mentionnées ci-dessus pour l'estimation de l'intervalle de confiance.
Le fait que les expressions analytiques précédemment utilisées aient été dérivées sur la base de l'hypothèse que la distribution des erreurs de prévision est symétrique et normale peut constituer une raison supplémentaire pour changer la méthode d'estimation de l'intervalle de confiance. Ces exigences ne sont pas remplies pour notre classe de séquences et la distribution des erreurs de prévision peut ne pas être ni normale ni symétrique.
Lors de l'estimation de l'intervalle de confiance dans l'indicateur initial, la variance de l'erreur de prévision d'une longueur d’avance a été calculée en premier lieu à partir de la séquence d'entrée, suivie du calcul de la variance pour deux , trois longueurs d’avance et plus. prévision sur la base de la valeur de variance de l'erreur de prévision obtenue avec une longueur d'avance à l'aide des expressions analytiques.
Afin d'éviter l'utilisation d'expressions analytiques, il existe une solution simple par laquelle la variance pour une prévision à deux, trois longueurs d’avance et plus est calculée directement à partir de la séquence d'entrée ainsi que la variance pour une prévision à une longueur d’avance. Cependant, cette approche présente un inconvénient important : dans des séquences d'entrée courtes, les estimations d'intervalle de confiance seront largement dispersées et le calcul de la variance et de l'erreur quadratique moyenne ne permettra pas de lever les contraintes sur la normalité attendue des erreurs.
Une solution dans ce cas peut être disponible dans l'utilisation de l’amorce non paramétrique (ré-échantillonnage) [9]. La base de l’idée simplement exprimée : lors d'un échantillonnage de manière aléatoire (distribution uniforme) avec remplacement à partir de la séquence initiale, la distribution de la séquence artificielle ainsi générée sera la même que celle de la séquence initiale.
Admettons que nous ayons une séquence d'entrée de N membres ; en générant une séquence pseudo-aléatoire uniformément répartie sur la plage de [0,N-1] et en utilisant ces valeurs comme indices lors de l'échantillonnage à partir du tableau initial, nous pouvons générer une séquence artificielle d'une longueur sensiblement plus grande que la séquence initiale. Cela dit, la distribution de la séquence générée sera la même (presque la même) que celle de la séquence initiale.
La procédure d’amorce pour l'estimation des intervalles de confiance peut être la suivante :
- Déterminez les valeurs initiales optimales des paramètres du modèle, ses coefficients et coefficients adaptatifs à partir de la séquence d'entrée pour le modèle de lissage exponentiel obtenu à la suite d'une modification. Les paramètres optimaux sont, comme précédemment, déterminés à l'aide de l'algorithme qui emploie la méthode de recherche de Powell ;
- À l'aide des paramètres de modèle optimaux déterminés, « parcourez » la séquence initiale et formez un tableau d'erreurs de prévision d'une longueur d’avance. Le nombre d'éléments du tableau sera égal à la longueur de séquence d'entrée N ;
- Alignez les erreurs en soustrayant de chaque élément du tableau d'erreurs la valeur moyenne de celui-ci ;
- En utilisant le générateur de séquences pseudo-aléatoires, générez des indices dans la plage de [0,N-1] et utilisez-les pour former une séquence artificielle d'erreurs d'une longueur de 9999 éléments (ré-échantillonnage) ;
- Formez un tableau comprenant 9999 valeurs de la séquence de pseudo-entrée en insérant les valeurs du tableau d'erreurs générées artificiellement dans les équations qui définissent le modèle actuellement utilisé. En d'autres termes, alors que nous devions auparavant insérer les valeurs de séquence d'entrée dans les équations du modèle, calculant ainsi l'erreur de prévision, les calculs inverses sont maintenant effectués. Pour chaque élément du tableau, la valeur d'erreur est insérée pour calculer la valeur d'entrée. En conséquence, nous obtenons le tableau de 9999 éléments contenant la séquence avec la même distribution que la séquence d'entrée tout en étant de longueur suffisante pour estimer directement les intervalles de confiance de prévision.
Estimez ensuite les intervalles de confiance en utilisant la séquence générée de longueur adéquate. Pour cela, nous exploiterons le fait que si le tableau d'erreur de prévision généré est trié par ordre croissant, les cellules du tableau d'indices 249 et 9749 pour le tableau comprenant 9999 valeurs auront les valeurs correspondant aux limites de l'intervalle de confiance à 95% [10].
Afin d'obtenir une estimation plus précise des intervalles de prédiction, la longueur du tableau doit être impaire. Dans notre cas, les limites des intervalles de confiance de prévision sont estimées comme suit :
- En utilisant les paramètres de modèle optimaux tels que déterminés précédemment, "parcourez" la séquence générée et formez un tableau de 9999 erreurs de prévision d'une longueur d’avance ;
- Trier le tableau résultant ;
- Dans le tableau d'erreurs triées, sélectionnez les valeurs avec les indices 249 et 9749 qui représentent les limites de l'intervalle de confiance à 95 % ;
- Refaites les étapes 1, 2 et 3 pour les erreurs de prévision à deux, trois longueurs d’avance et plus.
Cette approche d'estimation des intervalles de confiance a ses avantages et ses inconvénients.
Parmi ses avantages figure l'absence d'hypothèses sur la nature de la distribution des erreurs de prévision. Ils n'ont pas besoin d'être distribués normalement ou symétriquement. En outre, cette approche peut être utile lorsqu'il est impossible de dériver des expressions analytiques pour le modèle utilisé.
Une augmentation spectaculaire de la portée requise des calculs et de la dépendance des estimations vis-à-vis de la qualité du générateur de séquences pseudo-aléatoires utilisé peut être considérée comme ses inconvénients.
L'approche proposée pour estimer les intervalles de confiance à l'aide du ré-échantillonnage et des quantiles est plutôt primitive et il doit y avoir des moyens de l'améliorer. Mais comme les intervalles de confiance dans notre cas ne sont destinés qu'à une évaluation visuelle, la précision fournie par l'approche ci-dessus peut sembler tout à fait suffisante.
5. Version Modifiée de l'Indicateur
Compte tenu des mises à niveau introduites dans l'article, l'indicateur ForecastES.mq5 a été élaboré. Pour le ré-échantillonnage, nous avons utilisé le générateur de séquences pseudo-aléatoires proposé précédemment dans l'article [11]. Le générateur MathRand() standard a donné des résultats légèrement plus maigres, probablement en raison du fait que la plage de valeurs qu'il a générée [0,32767] n'était pas assez large.
Lors de la compilation de l'indicateur ForecastES.mq5, PowellsMethod.mqh, CForeES.mqh et RNDXor128.mqh doivent se trouver dans le même répertoire que celui-ci. Tous ces fichiers sont disponibles dans l'archive fore.zip.
Vous trouverez ci-dessous le code source de l'indicateur ForecastES.mq5.
//+------------------------------------------------------------------+ //| ForecastES.mq5 | //| Copyright 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg." #property link "https://www.mql5.com" #property version "1.02" #property description "Forecasting based on the exponential smoothing." #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" // Forecast #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "ConfUp" // Confidence interval #property indicator_type3 DRAW_LINE #property indicator_color3 clrCrimson #property indicator_style3 STYLE_DOT #property indicator_width3 1 #property indicator_label4 "ConfDn" // Confidence interval #property indicator_type4 DRAW_LINE #property indicator_color4 clrCrimson #property indicator_style4 STYLE_DOT #property indicator_width4 1 input int nHist=80; // History bars, nHist>=24 #include "CForeES.mqh" #include "RNDXor128.mqh" #define NFORE 12 #define NBOOT 9999 double Hist[],Fore[],Conf1[],Conf2[]; double Data[],Err[],BSDat[],Damp[NFORE],BSErr[NBOOT]; int NDat; CForeES Es; RNDXor128 Rnd; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { NDat=nHist; if(NDat<24)NDat=24; MqlRates rates[]; CopyRates(NULL,0,0,NDat,rates); // Load missing data ArrayResize(Data,NDat); ArrayResize(Err,NDat); ArrayResize(BSDat,NBOOT+NFORE); SetIndexBuffer(0,Hist,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,Fore,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFORE); SetIndexBuffer(2,Conf1,INDICATOR_DATA); // Confidence interval PlotIndexSetString(2,PLOT_LABEL,"ConfUp"); PlotIndexSetInteger(2,PLOT_SHIFT,NFORE); SetIndexBuffer(3,Conf2,INDICATOR_DATA); // Confidence interval PlotIndexSetString(3,PLOT_LABEL,"ConfDN"); PlotIndexSetInteger(3,PLOT_SHIFT,NFORE); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,j,k,start; double s,t,alp,gam,phi,sb,sg,e,f,a,a1,a2; if(rates_total<NDat){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated==rates_total)return(rates_total); // New tick but not new bar start=rates_total-NDat; //----------------------- PlotIndexSetInteger(0,PLOT_DRAW_BEGIN,rates_total-NDat); PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFORE); for(i=0;i<NDat;i++)Data[i]=open[rates_total-NDat+i]; // Input data Es.CalcPar(Data); // Optimization of parameters s=Es.GetPar(0); t=Es.GetPar(1); gam=Es.GetPar(2); phi=Es.GetPar(3); sb=Es.GetPar(4); sg=Es.GetPar(5); //---- a=phi; Damp[0]=phi; for(j=1;j<NFORE;j++){a=a*phi; Damp[j]=Damp[j-1]+a;} // Phi table //---- f=s+phi*t; for(i=0;i<NDat;i++) // History { e=Data[i]-f; Err[i]=e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); Hist[start+i]=f; // History } for(j=0;j<NFORE;j++)Fore[rates_total-NFORE+j]=s+Damp[j]*t; // Forecast //---- a=0; for(i=0;i<NDat;i++)a+=Err[i]; a/=NDat; for(i=0;i<NDat;i++)Err[i]-=a; // alignment of the array of errors //---- f=Es.GetPar(0)+phi*Es.GetPar(1); for(i=0;i<NBOOT+NFORE;i++) // Resampling { j=(int)(NDat*Rnd.Rand_01()); if(j>NDat-1)j=NDat-1; e=Err[j]; BSDat[i]=f+e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=s+phi*t; } //---- for(j=0;j<NFORE;j++) // Prediction intervals { s=Es.GetPar(0); t=Es.GetPar(1); f=s+phi*t; for(i=0,k=0;i<NBOOT;i++,k++) { BSErr[i]=BSDat[i+j]-(s+Damp[j]*t); e=BSDat[i]-f; a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); } ArraySort(BSErr); Conf1[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[249]; Conf2[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[9749]; } return(rates_total); } //-----------------------------------------------------------------------------------
Pour une meilleure démonstration, l'indicateur a été exécuté, dans la mesure du possible, sous la forme d'un code linéaire. Aucune optimisation n'était prévue lors de son codage.
Les figures 1 et 2 montrent les résultats de fonctionnement de l'indicateur pour deux cas différents.

Figure 1. Premier exemple de fonctionnement de l'indicateur ForecastES.mq5

Figure 2. Exemple de second fonctionnement de l'indicateur ForecastES.mq5
La figure 2 montre clairement que l'intervalle de confiance de prévision à 95 % est asymétrique. Cela est dû au fait que la séquence d'entrée contient des valeurs aberrantes considérables qui ont entraîné une distribution asymétrique des erreurs de prévision.
Les sites Web www.mql4.com et www.mql5.com fournissaient auparavant des indicateurs d'extrapolation. Prenons l’un de ceux-ci - ar_extrapolator_of_price.mq5 et définissons leur valeurs de paramètre telles que montrées dans la Figure 3 et comparons ses résultats avec ceux obtenus à l’aide de l’indicateur que nous avons élaboré.

Figure 3. Paramètres de l'indicateur ar_extrapolator_of_price.mq5
Le fonctionnement de ces deux indicateurs a été comparé visuellement sur différentes échelles de temps pour l'EURUSD et l'USDCHF. En surface, il semble que la direction de la prévision par les deux indicateurs coïncide dans la majorité des cas. Cependant, dans des observations plus longues,nous pouvons croiser de sérieuses divergences. Cela étant dit, ar_extrapolator_of_price.mq5 produira toujours une ligne de prévision plus discontinue.
Un exemple de fonctionnement simultané des indicateurs ForecastES.mq5 et ar_extrapolator_of_price.mq5 est illustré à la figure 4.

Figure 4. Comparaison des résultats prévisionnels
La prévision créée par l'indicateur ar_extrapolator_of_price.mq5 est affichée dans la figure 4 sous la forme d'une ligne solide orange-rouge.
Conclusion
Récapitulatif des résultats relatifs à cet article et à l'article précédent :
- Les modèles de lissage exponentiel utilisés dans la prévision des séries chronologiques ont été introduits;
- Des solutions de programmation pour l’implémentation des modèles ont été proposées ;
- Un aperçu rapide des problèmes liés à la sélection des valeurs initiales optimales et des paramètres du modèle a été donné ;
- Une implémentation de programmation de l'algorithme pour trouver le minimum d'une fonction de plusieurs variables en utilisant la méthode de Powell a été fournie ;
- Des solutions de programmation pour l'optimisation des paramètres du modèle de prévision à l'aide de la séquence d'entrée ont été proposées ;
- Quelques exemples simples de mise à niveau de l'algorithme de prévision ont été démontrés ;
- Une méthode d'estimation des intervalles de confiance des prévisions à l'aide du lancement et des quantiles a été brièvement décrite ;
- L'indicateur de prévision ForecastES.mq5 a été élaboré comprenant toutes les méthodes et algorithmes décrits dans les articles ;
- Quelques liens vers des articles, des revues et des livres ont été fournis sur ce sujet.
Concernant l'indicateur résultant ForecastES.mq5, il est à noter que l'algorithme d'optimisation employant la méthode de Powell peut dans certains cas ne pas réussir à déterminer le minimum de la fonction objective avec une précision donnée. Ceci étant le cas, le nombre maximum d'itérations admissible sera atteint et un message pertinent apparaîtra dans le journal. Cette situation n'est cependant en aucun cas traitée dans le code de l'indicateur ce qui est tout à fait acceptable pour la démonstration des algorithmes présentés dans l'article. Cependant, lorsqu'il s'agit d'applications sérieuses, ces instances doivent être surveillées et traitées d'une manière ou d'une autre.
Pour élaborer davantage et améliorer l'indicateur de prévision, nous pourrions suggérer l’utilisation de plusieurs modèles de prévision différents simultanément à chaque stade en vue de sélectionner davantage l'un d'entre eux en utilisant par exemple le critère d'information d' Akaike. Ou en cas d'utilisation de plusieurs modèles de nature similaire, pour calculer la valeur moyenne pondérée de leurs résultats prévisionnels. Les coefficients de pondération dans ce cas peuvent être choisis en fonction du coefficient d'erreur de prévision de chaque modèle.
Le sujet de prévision des séries chronologiques est si vaste que, malheureusement, ces articles ont à peine effleuré la surface de certains des problèmes qui s'y rapportent. Espérant que ces publications contribueront à attirer l'attention du lecteur sur les questions de la prospective et des travaux futurs dans ce domaine.
Les références
- "Prévision de Séries Chronologiques Utilisant le Lissage Exponentiel".
- Yu. P. Lukashin. Méthodes Adaptatives pour la Prévision à Court Terme des Séries Chronologiques : Manuel-M.: Finansy i Statistika, 2003.-416 p.
- S.V. Bulachev. Statistiques pour les Traders. - . : Kompania Spoutnik +, 2003. - 245 p.
- Everette S. Gardner Jr., Exponential Smoothing: The State of the Art – Partie II. 3 juin 2005.
- James W. Taylor, Smooth Transition Exponential Smoothing. Journal of Forecasting, 2004, Vol. 23, pp. 385-394.
- James W. Taylor, Volatility Forecasting with Smooth Transition Exponential Smoothing. International Journal of Forecasting, 2004, Vol. 20, pp. 273-286.
- Alysha M De Livera. Prévision Automatique avec un Cadre d'Espace d’ Etat de Lissage Exponentiel Modifié. 28 avril 2010, Département d'économétrie et de statistiques commerciales, Université Monash, VIC 3800 Australie.
- Rob J Hyndman et al. Intervalles de prédiction pour le lissage exponentiel à l'aide de deux nouvelles classes de modèles d'espace d'état. 30 janvier 2003.
- The Quantile Journal. issue No. 3 septembre 2007.
- http://ru.wikipedia.org/wiki/Квантиль
- « Analyse des Principales Caractéristiques des Séries Chronologiques ».
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/346
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Création d'Expert Advisors à l'aide de l'Assistant visuel d'Expert Advisor
Création d'Expert Advisors à l'aide de l'Assistant visuel d'Expert Advisor
 Utiliser l'Analyse Discriminante pour Élaborer des Systèmes de Trading
Utiliser l'Analyse Discriminante pour Élaborer des Systèmes de Trading
 Trademinator 3 : Montée des Machines de Trading
Trademinator 3 : Montée des Machines de Trading
 Analyse des Paramètres Statistiques des Indicateurs
Analyse des Paramètres Statistiques des Indicateurs
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Victor, n'avez-vous pas modifié les indicateurs avec le décalage de l'historique ? Pas seulement pour la dernière barre. J'aimerais estimer grossièrement l'efficacité des méthodes que vous avez mises en œuvre.
Non, je n'ai pas fait d'indicateurs décalés.
Dans le fichier ForecastES.mq5, les erreurs détectées ont été corrigées. Le fichier ForecastES.mq5 mis à jour se trouve dans l'archive Fore.zip comme précédemment.
Un nouvel article Prévision des séries temporelles par lissage exponentiel (suite) est publié :
Auteur : Victor
J'ai essayé plusieurs fois de chercher ce nouvel indicateur modifié dans la section Code base du MT5 mais je ne l'ai pas trouvé.
Pouvez-vous l'ajouter dans la base de code du MT5 pour que je puisse le télécharger facilement et le tester ? Ou bien pouvez-vous me fournir l'indicateur modifié et me dire comment le télécharger dans mon MT5 ?
Avez-vous la même chose pour MT4 ?
Si vous avez besoin d'aide, n'hésitez pas à m'en faire part.
Je vous remercie de votre aide.
Forum sur le trading, les systèmes de trading automatisés et les tests de stratégies de trading
Discussion de l'article "Prévision des séries temporelles à l'aide du lissage exponentiel"
newdigital, 2014.06.06 21:48
Devenir un trader Forex sans peur
- Faut-il savoir ce qui va se passer ensuite ?
- Existe-t-il une meilleure façon de procéder ?
- Stratégies quand on sait qu'on ne sait pas
"Un bon investissement est un équilibre particulier entre la conviction de suivre ses idées et la flexibilité de reconnaître quand on a fait une erreur.Michael Steinhardt
"95 % des erreurs de trading que vous êtes susceptible de commettre découlent de votre attitude face à l'idée de vous tromper, de perdre de l'argent, de rater quelque chose et de laisser de l'argent sur la table - les quatre peurs du trading"
-Mark Douglas, Trading In the Zone
De nombreux traders s'entichent de l'idée de faire des prévisions. La nécessité de faire des prévisions semble être inhérente à la réussite du trading. Après tout, vous vous dites que je dois savoir ce qui va se passer pour gagner de l'argent, n'est-ce pas ? Heureusement, ce n'est pas le cas et cet article explique comment vous pouvez réaliser de bonnes opérations sans savoir ce qui va se passer.
Faut-il savoir ce qui va se passer ?
Bien qu'il soit utile de savoir ce qui va se passer ensuite, personne ne peut le savoir avec certitude. La raison pour laquelle le délit d'initié est un crime souvent testé sur les marchés boursiers peut vous aider à comprendre que certains traders sont si désespérés de connaître l'avenir qu'ils sont prêts à tricher et à payer une amende sévère lorsqu'ils sont pris en flagrant délit. En bref, il est dangereux de penser en termes d'avenir certain lorsque votre argent est en jeu et il est préférable de penser aux limites plutôt qu'aux certitudes lorsque vous prenez une position.
Le problème de penser que vous devez savoir ce que l'avenir réserve à votre position, c'est que lorsque quelque chose de négatif se produit dans votre position par rapport à vos attentes, la peur s'installe. La peur n'est pas mauvaise en soi. Cependant, la plupart des traders qui mettent leur argent en jeu se figent souvent et ne parviennent pas à clôturer la transaction.
Si vous n'avez pas besoin de savoir ce qui va se passer ensuite, de quoi avez-vous besoin ? La liste est étonnamment courte et simple, mais le plus important est que vous ne pensiez pas savoir ce qui va se passer, car si c'est le cas, vous risquez de vous surendetter et de minimiser les risques qui sont omniprésents dans le monde du trading.
- Un bord net sur lequel vous êtes à l'aise pour entamer une transaction
- Un point d'invalidation bien défini où la configuration de votre transaction ne peut plus être utilisée comme point d'entrée pour un renversement potentiel.
- Un point d'entrée potentiel d'inversion
- Une taille de transaction appropriée / une gestion de l'argent
Existe-t-il une meilleure solution ?Hier, la Banque centrale européenne a décidé de réduire son taux de refinancement et son taux de dépôt. De nombreux traders ont abordé cette réunion à découvert, mais la paire EURUSD a couvert ~250% de sa fourchette ATR quotidienne et a clôturé près des plus hauts, ce qui indique la force de la paire EURUSD. En d'autres termes, le résultat était hors de portée de la plupart des traders et si vous avez pris une position courte et avez été frappé par la peur, vous n'avez probablement pas liquidé cette position courte et avez été une autre "victime du marché", ce qui est une autre façon de dire une victime de vos propres peurs de perdre.
Quelle est donc la meilleure façon de procéder ? Croyez-le ou non, il s'agit d'aborder le marché en comprenant à quel point les marchés peuvent être émotionnels et qu'il est préférable de ne pas s'attacher à la direction que le marché "doit prendre". De nombreux traders s'accrocheront à une transaction perdante, non pas au bénéfice de leur compte, mais plutôt pour protéger leur ego. Bien entendu, la meilleure façon de négocier est de se concentrer sur la protection des fonds propres de son compte et de laisser son ego à la porte de sa salle de marché afin qu'il n'ait pas d'incidence négative sur ses opérations.
Stratégies lorsque vous savez que vous ne savez pas
Il y a un point commun entre les traders qui peuvent trader sans crainte. Ils intègrent les transactions perdantes dans leur approche. C'est un peu comme un gambit aux échecs et cela enlève l'avantage et l'emprise que la peur a sur de nombreux traders. Pour les non-joueurs d'échecs, un gambit est un jeu qui consiste à sacrifier une pièce de faible valeur, comme un pion, afin d'obtenir un avantage. Dans le domaine du trading, le gambit peut être votre première transaction qui vous permet de mieux goûter à l'avantage que vous ressentez au moment où la transaction est effectuée.
L'USD Hedge de James Stanley est un excellent exemple de stratégie qui part du principe qu'une opération sera perdante. Qu'est-ce que cela signifie ? Il s'agit d'une pré-supposition de perte qui vous permettra de négocier sans la peur qui tourmente tant de traders. Un autre outil que vous pouvez utiliser pour vous aider à déterminer si la tendance vous est favorable ou défavorable est une fractale.
Si vous regardez en dehors du monde du trading et des échecs, il existe d'autres entreprises qui supposent une perte et qui sont donc capables d'agir en toute sérénité lorsqu'une perte survient. Il s'agit des casinos et des compagnies d'assurance. Ces deux entreprises supposent une perte et ne travaillent qu'en fonction d'un risque calculé, elles fonctionnent sans peur et vous pouvez en faire autant si vous supposez que votre stratégie comporte de petites pertes.
Une autre belle citation de Mark Douglas :
"Moins je me souciais de savoir si j'avais tort ou non, plus les choses devenaient claires, ce qui rendait beaucoup plus facile d'entrer et de sortir de positions, en coupant court à mes pertes pour me rendre mentalement disponible pour saisir la prochaine opportunité." -Mark Douglas
Bon Trading !
La source