
使用指数平滑法进行时间序列预测(续)

简介
《使用指数平滑法进行时间序列预测》 [1] 一文对指数平滑模型进行了简要总结,举例阐明了一种用于优化模型参数的可能方案,并最终提出了基于呈线性衰减的增长模型开发的预测指标。本文体现了在一定程度上提升该预测指标准确性的一次尝试。
预测货币报价甚至提前三四步进行极为可靠的预测,实施起来都比较复杂。然而,在本系列的前一篇文章中,我们会提前 12 步进行预测,并清楚认识到无法在如此长的范围内获得满意结果。因此,置信区间最窄的前几步预测应给予最大关注。
提前 10 到 12 步进行预测主要是为了说明不同模型与预测方法的行为特征。在任何情况下,针对任何范围获得的预测准确度都可以利用置信区间限制进行评估。本文的首要目的就是说明一些有助于升级文章 [1] 中所述指标的方法。
由于前文已经介绍了查找若干变量函数最小值(该值用于生成指标之用)的相应算法,这里就不再赘述。为了简便起见,我们尽量减少理论方面的内容。
1. 初始指标
IndicatorES.mq5 指标(参见文章 [1])会被用作一个起始点。
为了编译指标,我们需要用到同一目录下的 IndicatorES.mq5、CIndicatorES.mqh 和 PowellsMethod.mqh。这些文件都可以在本文末尾的 files2.zip 档案中找到。
我们来刷新定义了该指标制定过程中所用指数平滑模型的方程,即呈线性衰减的增长模型。
![]()
![]()
![]()
其中:
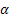 - 序列级别的平滑参数,[0,1];
- 序列级别的平滑参数,[0,1];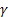 - 趋势的平滑参数,[0,1];
- 趋势的平滑参数,[0,1];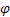 – 衰减参数,[0,1];
– 衰减参数,[0,1];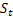 – 观测到
– 观测到 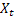 后,于时间 t 处计算得出的平滑序列级别;
后,于时间 t 处计算得出的平滑序列级别;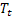 – 于时间 t 处计算得出的平滑加法趋势;
– 于时间 t 处计算得出的平滑加法趋势;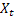 – 时间 t 处的序列值;
– 时间 t 处的序列值;
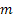 – 所做预测的提前步数;
– 所做预测的提前步数;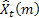 – 于时间 t 处所做的提前 m 步预测;
– 于时间 t 处所做的提前 m 步预测;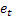 – 于时间 t 处所做的提前一步预测误差,
– 于时间 t 处所做的提前一步预测误差,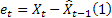 。
。
该指标唯一的输入参数就是用于确定区间长度的值,将根据该值来优化模型参数以及选择初始值(研究区间)。确定某给定区间模型参数的最优值及所需的计算后,就会生成预测、置信区间以及与提前一步预测相对应的线条。每个新柱处的参数都会被优化,并会做出相应预测。
由于要更新所述指标,所以我们会利用本文末尾处 Files2.zip 档案中的测试序列来评估变化结果。档案目录 \Dataset2 中的文件包含已保存的 EURUSD、USDCHF、USDJPY 报价及美元指数 DXY。其中每一个都针对 M1、H1 与 D1 三种时间框架予以提供。在文件中保存 "open" 值时,应让最新值位于文件末尾。每个文件都包含 1200 个元素。
预测误差将通过计算“平均绝对百分比误差” (MAPE) 系数进行评估
![]()
我们将 12 个测试序列中的每个序列都划分为 50 个重叠区间,每个区间都包含 80 个元素,并计算其中每个元素的 MAPE 值。通过这种方式获取的评估平均值,将会被用作与对比指标相关的一个预测误差指数。提前两步和三步预测误差的 MAPE 值,也以同样的方式进行计算。此类平均估算值还会进一步表示如下:
- MAPE1 – 提前一步预测误差的平均估算值;
- MAPE2 – 提前两步预测误差的平均估算值;
- MAPE3 – 提前三步预测误差的平均估算值;
- MAPE1-3 – 平均值 (MAPE1+MAPE2+MAPE3)/3。
计算 MAPE 值时,每一步都会用绝对预测误差值除以序列的当前值。为在此过程中避免被零除或得到负值,要求输入序列仅取非零正值,就像在本例中一样。
初始指标的估算值如表 1 所示。
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicatorES |
0.2099 |
0.2925 |
0.3564 |
0.2863 |
表 1. 初始指标预测误差估算值
表 1 中所示数据是利用 Errors_IndicatorES.mq5 脚本(来自本文末尾的 files2.zip 档案)获取的。要编译并运行此脚本,则 CIndicatorES.mqh 和 PowellsMethod.mqh 必须与 Errors_IndicatorES.mq5 同处一个目录下,且输入序列位于 Files\Dataset2\ 目录下。
获取预测误差的初始估算值后,现在就可以继续升级研究中的指标了。
2. 优化准则
《使用指数平滑法进行时间序列预测》文中所述的初始指标中的模型参数,均通过提前一步对预测误差平方和进行最小化的方法进行确定。针对提前一步预测进行优化的模型参数可能不会产生提前多步预测的最小误差,这似乎比较符合逻辑。当然,最好能够将提前 10 到 12 步预测的误差降至最低,但要在给定的研究序列范围内获得满意的预测结果,却是不可能完成的任务。
从现实来看,在优化模型参数时,我们会使用提前一、二、三步预测误差的平方和,将其用于指标的第一次升级。误差的平均数量可能有望在预测前三步的范围内实现某种程度上的降低。
显而易见,初始指标的此类升级并不涉及其主体结构原理,而只是更改参数优化准则而已。因此,我们不能指望预测精确度能提高数倍,尽管提前两步和三步预测误差的数量应当下降一点。
为了对比预测结果,我们创建了 CMod1 类,其类似于前文提到的带有修改目标函数 func 的 CIndicatorES 类。
初始 CIndicatorES 类的 func 函数:
double CIndicatorES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 sse=0; for(i=0;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(Dlen*MathLog(k1*k2*k3*sse)); }
经过一些修改之后,func 函数的现状如下:
double CMod1::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95; // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*k3*err); }
现在,计算该对象函数时就会用到提前一、二、三步预测误差的平方和。
而且,基于此类开发的 Errors_Mod1.mq5 脚本允许估算预测误差,这类似于曾经提到过的 Errors_IndicatorES.mq5 脚本功能。CMod1.mqh 与 Errors_Mod1.mq5 均位于本文末尾的 files2.zip 档案中。
表 2 显示了初始及升级版的预测误差估算值。
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicatorES |
0.2099 |
0.2925 |
0.3564 |
0.2863 |
| Mod1 |
0.2144 |
0.2898 |
0.3486 |
0.2842 |
表 2. 预测误差估算值的对比
可以看出,误差系数 MAPE2 和 MAPE3 以及平均值 MAPE1-3 确实要比研究中的序列略低一些。所以,我们保存了这一版本,并继续进一步修改我们的指标。
3. 平滑过程中的参数调整
根据输入序列的当前值更改平滑参数,这一想法并不新颖,也并非原创,其目的是希望能调整平滑系数,以便其在给定的输入序列性质发生变化时仍保持最佳状态。调整平滑系数的一些方式会在参考文献 [2]、[3] 中进行说明。
为了进一步升级该指标,我们会使用平滑系数呈动态变化的模型,希望使用自适应指数平滑模型来实现指标预测精确度的提升。
遗憾的是,如果在预测算法中使用该模型,则大多数自适应方法都无法始终获得理想结果。选取适当的自适应方法可能过于繁琐且耗时,因此在本例中我们会利用参考文献 [4] 中提供的研究结果,并采用文章 [5] 中讲到的“平滑转换的指数平滑” (STES)。
由于指定文章中已明确说明该方法的实质内容,所以我们暂时无需理会,而只需直接转到模型的方程(请参阅指定文章的开头),同时考虑到自适应平滑系数的使用即可。
![]()
![]()
![]()
![]()
现在可以看出,平滑系数 alpha 的值会在算法中的每一步计算得出,具体取决于平方预测误差。b 与 g 系数的值会确定预测误差对 alpha 值所造成的影响。而在所有其他方面,所用模型的方程仍保留未变。与 STES 法使用相关的更多详情请参见文章 [6]。
在之前的版本中,我们必须确定整个给定序列 alpha 系数的最优值,而现在则有 b 和 g 两个自适应系数可待优化,且 alpha 值会在平滑输入序列的过程中被动态确定。
该升级以 CMod2 类的形式进行。重大变化(像上次一样)主要与 func 函数相关,其现状如下所示。
double CMod2::func(const double &p[]) { int i; double s,t,alp,gam,phi,sb,sg,k1,k2,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; gam=p[2]; phi=p[3]; sb=p[4]; sg=p[5]; k1=1; k2=1; if (gam>0.95){k1+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k1+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k2+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k2+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*err); }
开发此函数时,定义 alpha 系数值的方程也会稍做修改。这样做是为了分别在 0.05 与 0.95 处对最大与最小允许值进行限制。
为了像之前一样评估预测错误,要基于 CMod2 类来编写 Errors_Mod2.mq5 脚本。CMod2.mqh 与 Errors_Mod2.mq5 均位于本文末尾的 files2.zip 档案中。
脚本结果如表 3 所示。
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicatorES |
0.2099 |
0.2925 |
0.3564 |
0.2863 |
| Mod1 |
0.2144 |
0.2898 |
0.3486 |
0.2842 |
| Mod2 |
0.2145 |
0.2832 |
0.3413 |
0.2797 |
表 3. 预测误差估算值的对比
如表 3 所示,使用自适应平滑系数后一般都允许进一步略微减少测试序列的预测误差。因此,在两次升级之后,我们便设法将误差系数 MAPE1-3 降低了约两个百分点。
尽管升级结果不太明显,但我们仍坚持将其作为最终版本,并将进一步的升级留到本文之外再行讨论。在下一步中尝试使用博克斯-卡克斯转换会很不错。该转换方法主要用于让初始序列分布接近正态分布。
在本例中可以使用该转换方法来转换初始序列、计算预测并反向转换预测。这种方法用到了转换系数,其选择应以结果预测误差最小为原则。在预测序列中使用博克斯-卡克斯转换的示例请参见文章 [7]。
4. 预测置信区间
初始 IndicatorES.mq5 指标(前文提到过)中的预测置信区间,是根据选定指数平滑模型 [8] 的解析式计算得出的。本例所做的变更已导致研究中模型发生了变化。由于存在变量平滑系数,便不适合再使用上述分析表达式来估算置信区间了。
之前使用的分析表达式均基于预测误差为对称正态分布这一假设推算得出,而这是更改置信区间评估法的又一原因。由于我们的序列类未能满足这些要求,所以预测误差分布可能并非正态或对称的。
估算初始指标中的置信区间时,提前一步预测误差方差应从输入序列的开头开始计算,接下来再利用解析式并根据获得的提前一步预测误差方差值来计算提前两步、三步及更多步预测的方差。
为避免使用解析式,还可采用一种简单方法,即直接通过输入序列和提前一步预测方差来计算提前两步、三步及更多步预测的方差。但该方法存在一个明显缺陷:在短输入序列中,置信区间估算值会相当分散,而且在计算方差和均方误差时还不允许解除对于预期误差正态性的限制。
在使用非参数自助法(重新采样) [9] 的过程中可以发现针对这种情况的解决方案。这一想法的核心内容非常简单:如果以随机方式(均匀分布)替换通过初始序列进行采样的做法,则如此生成的伪序列的分布情况会与初始序列的分布情况相同。
假设我们有一个 N 成员的输入序列;通过在 [0,N-1] 的范围内生成一个均匀分布的伪随机序列,并在由初始数组采样时将这些值作为索引,就可以生成一个明显长于初始序列的伪序列。也就是说,生成序列的分布情况会与初始序列的分布情况相同(几乎相同)。
估算置信区间的自助法流程如下所示:
- 通过指数平滑模型中的输入序列来确定该模型的参数、系数和自适应系数的最优初始值,而该模型是在修改后得出的。最优参数还是像以前一样,通过采用使用鲍威尔搜索法的算法进行确定;
- 利用确定的最优模型参数从头到尾过一遍初始序列,并创建一个由提前一步预测误差组成的数组。数组元素的数量将等于输入序列长度 N;
- 从误差数组的每个元素中减去其中的平均值以调整误差;
- 利用伪随机序列生成器生成 [0,N-1] 范围内的索引,并用它们构建一个 9999 个元素长度(重新采样后)的伪误差序列;
- 将来自人工生成误差数组的值插入到定义当前使用模型的方程中,从而创建一个包含 9999 个伪输入序列值的数组。换言之,之前我们必须将输入序列值插入到模型方程中,并据此计算预测误差,但现在却在进行逆运算。对于数组中的每个元素而言,都要插入其误差值才能计算出输入值。结果我们得到一个 9999 个元素的数组,其包含序列的分布情况与输入序列的分布情况相同,而通过其长度足以直接估算预测置信区间。
接下来再利用所生成的足够长度的序列来估算置信区间。为此,我们会利用以下情况:如果生成的预测误差数组按升序排列,则索引为 249 与 9749 的单元格中的值就会对应 95% 置信区间 [10] 的限制值,这些单元格位于包含 9999 个值的数组中。
要对预测区间进行更为精确的估算,则数组长度应为奇数。在本例中,预测置信区间的限制值通过以下方式进行估算:
- 利用前文确定的最优模型参数从头到尾过一遍所生成的序列,并创建一个由 9999 个提前一步预测误差组成的数组。
- 对所创建的数组进行排序;
- 从排序的误差数组中选择索引为 249 和 9749 (代表 95% 置信区间的限制值)的值;
- 针对提前两步、三步及更多步预测误差重复步骤 1、步骤 2 和步骤 3。
使用这种方法来估算置信区间有利也有弊。
其优势之一是无需对预测误差分布的性质进行假设。此类误差无需呈正态或对称分布。此外,如果无法从使用中的模型得出解析式,就可能用到此方法。
所需计算范围明显扩大、以及对于所用伪随机序列生成器的质量评估存在依赖性,这些都可视为劣势 。
所提议的利用重新采样和分位数评估置信区间的方法相当原始,必须通过一定的方式予以改进。但是,在这种情况下,由于置信区间仅用于可视评估,所以上述方法提供的精确度似乎已经足够。
5. 指标的修改版本
在考虑到本文所述升级的情况下,ForecastES.mq5 指标得以建立。重新采样方面,我们使用了之前在文章 [11] 中提到的伪随机序列生成器。标准 MathRand() 生成器生成的结果稍差一些,这可能是因为其生成的 [0,32767] 的值范围不够宽。
编译 ForecastES.mq5 指标时,PowellsMethod.mqh、CForeES.mqh 和 RNDXor128.mqh 都要与其位于同一目录下。上述所有文件均见于 fore.zip 档案中。
以下是 ForecastES.mq5 指标的源代码。
//+------------------------------------------------------------------+ //| ForecastES.mq5 | //| Copyright 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg." #property link "https://www.mql5.com" #property version "1.02" #property description "Forecasting based on the exponential smoothing." #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" // Forecast #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "ConfUp" // Confidence interval #property indicator_type3 DRAW_LINE #property indicator_color3 clrCrimson #property indicator_style3 STYLE_DOT #property indicator_width3 1 #property indicator_label4 "ConfDn" // Confidence interval #property indicator_type4 DRAW_LINE #property indicator_color4 clrCrimson #property indicator_style4 STYLE_DOT #property indicator_width4 1 input int nHist=80; // History bars, nHist>=24 #include "CForeES.mqh" #include "RNDXor128.mqh" #define NFORE 12 #define NBOOT 9999 double Hist[],Fore[],Conf1[],Conf2[]; double Data[],Err[],BSDat[],Damp[NFORE],BSErr[NBOOT]; int NDat; CForeES Es; RNDXor128 Rnd; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { NDat=nHist; if(NDat<24)NDat=24; MqlRates rates[]; CopyRates(NULL,0,0,NDat,rates); // Load missing data ArrayResize(Data,NDat); ArrayResize(Err,NDat); ArrayResize(BSDat,NBOOT+NFORE); SetIndexBuffer(0,Hist,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,Fore,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFORE); SetIndexBuffer(2,Conf1,INDICATOR_DATA); // Confidence interval PlotIndexSetString(2,PLOT_LABEL,"ConfUp"); PlotIndexSetInteger(2,PLOT_SHIFT,NFORE); SetIndexBuffer(3,Conf2,INDICATOR_DATA); // Confidence interval PlotIndexSetString(3,PLOT_LABEL,"ConfDN"); PlotIndexSetInteger(3,PLOT_SHIFT,NFORE); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,j,k,start; double s,t,alp,gam,phi,sb,sg,e,f,a,a1,a2; if(rates_total<NDat){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated==rates_total)return(rates_total); // New tick but not new bar start=rates_total-NDat; //----------------------- PlotIndexSetInteger(0,PLOT_DRAW_BEGIN,rates_total-NDat); PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFORE); for(i=0;i<NDat;i++)Data[i]=open[rates_total-NDat+i]; // Input data Es.CalcPar(Data); // Optimization of parameters s=Es.GetPar(0); t=Es.GetPar(1); gam=Es.GetPar(2); phi=Es.GetPar(3); sb=Es.GetPar(4); sg=Es.GetPar(5); //---- a=phi; Damp[0]=phi; for(j=1;j<NFORE;j++){a=a*phi; Damp[j]=Damp[j-1]+a;} // Phi table //---- f=s+phi*t; for(i=0;i<NDat;i++) // History { e=Data[i]-f; Err[i]=e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); Hist[start+i]=f; // History } for(j=0;j<NFORE;j++)Fore[rates_total-NFORE+j]=s+Damp[j]*t; // Forecast //---- a=0; for(i=0;i<NDat;i++)a+=Err[i]; a/=NDat; for(i=0;i<NDat;i++)Err[i]-=a; // alignment of the array of errors //---- f=Es.GetPar(0)+phi*Es.GetPar(1); for(i=0;i<NBOOT+NFORE;i++) // Resampling { j=(int)(NDat*Rnd.Rand_01()); if(j>NDat-1)j=NDat-1; e=Err[j]; BSDat[i]=f+e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=s+phi*t; } //---- for(j=0;j<NFORE;j++) // Prediction intervals { s=Es.GetPar(0); t=Es.GetPar(1); f=s+phi*t; for(i=0,k=0;i<NBOOT;i++,k++) { BSErr[i]=BSDat[i+j]-(s+Damp[j]*t); e=BSDat[i]-f; a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); } ArraySort(BSErr); Conf1[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[249]; Conf2[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[9749]; } return(rates_total); } //-----------------------------------------------------------------------------------
为方便演示,应尽可能将该指标作为一个直线代码执行。编写其代码时无意对其进行优化。
图 1 与图 2 显示了该指标在两种不同情况下的运行结果。

图 1. ForecastES.mq5 指标首次运行示例

图 2. ForecastES.mq5 指标第二次运行示例
由图 2 清楚可见,95% 的预测置信区间为非对称。这是因为输入序列中包含了相当数量的离群值(由于预测误差的非对称分布而导致)。
网站 www.mql4.com 和 www.mql5.com 之前提供了外推指标。我们取其中一个指标 - ar_extrapolator_of_price.mq5,并如图 3 所示设置其参数值,以将其结果与利用所制定指标获得的结果进行对比。

图 3。ar_extrapolator_of_price.mq5 指标的设置
这两个指标的运行情况,是在不同时间框架上就 EURUSD 与 USDCHF 进行直观比较的。表面看来,似乎大多数情况下两个指标的预测方向都会保持一致。不过,经过长时间观察发现,其中一个指标可能会遭遇严重分歧。也就是说,ar_extrapolator_of_price.mq5 始终都会生成一条断点更多的预测线。
图 4 显示了 ForecastES.mq5 与 ar_extrapolator_of_price.mq5 指标同时运行的一个示例。

图 4. 预测结果的对比
通过 ar_extrapolator_of_price.mq5 指标生成的预测在图 4 中显示为一条桔红色实线。
总结
本文与前文的相关结果汇总如下:
- 介绍了时间序列预测中使用的指数平滑模型;
- 提出了针对模型实施的编程解决方案;
- 让您快速了解最优初始值和模型参数选择的相关问题;
- 可通过编程来实现算法,以便使用鲍威尔方法查找一个多变量函数的最小值;
- 提出了编程解决方案,专门针对采用输入序列的预测模型参数优化;
- 说明了预测算法升级的一些简单示例;
- 简要讲述了利用自助法与分位数评估预测置信区间的一种方法;
- 建立了 ForecastES.mq5 预测指标,其包含了文中所述的所有方法与算法;
- 提供了与本主题相关的一些文章、杂志与书籍的链接。
关于作为结果的 ForecastES.mq5 指标,要注意的是,在某些情况下采用鲍威尔方法的优化算法并不能根据给定的精确度确定目标函数的最小值。基于这种情形,会达到可允许的最大迭代次数,而且日志中也会出现一条相关消息。不过,在指标代码中并未以任何方式处理这种情形,而这种情形完全可以用于说明本文所述的算法。然而,如果对应用要求比较严格,则要通过某种方式监控和处理此类实例。
如要进一步开发和强化该预测指标,建议在每一步同时使用多个不同的预测模型,目的在于利用阿凯克信息论准则等进一步选择其中一个模型。或者,如果使用了本质上类似的多个模型,则应计算其预测结果的加权平均值。在这种情况下,可根据每个模型的预测误差系数来选择加权系数。
预测时间序列这一主题的涵盖范围非常广泛,但遗憾的是,这些文章也只是粗浅介绍了一些相关问题而已。希望这些出版物有助于吸引读者关注该领域的预测及今后工作等方面的问题。
参考文献
- "Time Series Forecasting Using Exponential Smoothing".
- Yu. P. Lukashin. Adaptive Methods for Short-Term Forecasting of Time Series:Textbook.- М.:Finansy i Statistika, 2003.-416 pp.
- S.V. Bulashev. Statistics for Traders.- М.:Kompania Sputnik +, 2003. - 245 pp.
- Everette S. Gardner Jr., Exponential Smoothing:The State of the Art – Part II.June 3, 2005.
- James W. Taylor, Smooth Transition Exponential Smoothing.Journal of Forecasting, 2004, Vol. 23, pp. 385-394.
- James W. Taylor, Volatility Forecasting with Smooth Transition Exponential Smoothing.International Journal of Forecasting, 2004, Vol. 20, pp. 273-286.
- Alysha M De Livera.Automatic Forecasting with a Modified Exponential Smoothing State Space Framework.28 April 2010, Department of Econometrics and Business Statistics, Monash University, VIC 3800 Australia.
- Rob J Hyndman et al.Prediction Intervals for Exponential Smoothing Using Two New Classes of State Space Models.30 January 2003.
- The Quantile Journal. issue No. 3, September 2007.
- http://ru.wikipedia.org/wiki/Квантиль
- "Analysis of the Main Characteristics of Time Series".
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/346
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 使用 EA 交易可视向导创建 EA 交易
使用 EA 交易可视向导创建 EA 交易
 创建 EA 交易优化的自定义标准
创建 EA 交易优化的自定义标准
 Trademinator 3:交易机器的崛起
Trademinator 3:交易机器的崛起
 在 MetaTrader 5 中使用自组织特征映射(Kohonen 映射)
在 MetaTrader 5 中使用自组织特征映射(Kohonen 映射)
Victor,你没有修改过带历史转变的指标吗?不仅是最后一栏。我想大致估算一下您所采用方法的效率。
不,我没有做过移位指标。
ForecastES.mq5 文件中检测到的错误已得到纠正。更新后的ForecastES.mq5 文件和以前一样位于Fore.zip 压缩包 中。
新文章《使用指数平滑法进行时间序列预测(续)》出版:
作者:Victor:维克托
我曾多次尝试在 MT5 的代码库中搜索这个修改后的新指标,但都没有找到。
能否请您将其添加到 MT5 的代码库中,以便我可以轻松下载并测试?或者请提供修改后的指标以及如何将其下载到我的 MT5 中?
MT4 也有这样的指标吗?
请提供帮助。
谢谢
关于交易、自动交易系统和测试交易策略的论坛
讨论文章 "使用指数平滑法进行时间序列预测
newdigital, 2014.06.06 21:48
成为一名无畏的外汇交易者
- 你必须知道接下来会发生什么吗?
- 有更好的方法吗?
- 当你知道自己不知道时的策略
"好的投资是一种奇特的平衡,既要有遵循自己想法的信念,又要有认识到自己错误的灵活性"。-Michael Steinhardt
"你有可能犯的 95% 的交易错误都源于你对错误、亏损、错过和把钱留在桌上这四种交易恐惧的态度"
-Mark Douglas,《Trading In the Zone》
许多交易者都迷恋预测的想法。预测似乎是成功交易与生俱来的需要。毕竟,你的理由是,我必须知道接下来会发生什么才能赚钱,对吗?值得庆幸的是,这种想法并不正确,本文将分析如何在不知道下一步会发生什么的情况下做好交易。
你一定要知道下一步会发生什么吗?
虽然知道接下来会发生什么会有所帮助,但没有人可以确定。内幕交易是一种犯罪,在股票市场上经常受到检验,其原因可以帮助你了解到,有些交易者非常渴望知道未来,以至于不惜作弊,一旦被抓,就要支付高额罚款。简而言之,当你的资金岌岌可危时,考虑确定的未来是非常危险的,在进行交易时,最好考虑边缘而不是确定性。
,认为自己必须知道交易的未来是什么,问题在于,当你的交易出现与你的预期不符的不利情况时,恐惧感就会油然而生。恐惧本身并不是坏事。然而,大多数交易者在资金岌岌可危的情况下,往往会陷入僵局,无法完成交易。
如果你不需要知道接下来会发生什么,那么你需要什么呢?这个清单出奇地简短,但更重要的是,你不要以为自己知道会发生什么,因为如果你知道,你就可能会过度利用杠杆,淡化交易世界中无处不在的风险。
。
- 让你放心进入交易的干净边缘
- 一个定义明确的无效点,你的交易设置不再是
- 潜在的反转进入点
- 适当的交易规模/资金管理
有更好的方法吗?昨天,欧洲央行决定下调再融资利率和存款利率。许多交易者在这次会议上做空,但欧元兑美元覆盖了其每日 ATR 区间的约 250%,并在高点附近收盘,表明欧元兑美元走强。简而言之,结果超出了大多数交易者的可能性范围,如果你做空并受到恐惧的打击,你很可能没有平仓,成为另一个 "市场的受害者",也就是你自己害怕亏损的受害者。
那么什么是更好的方法呢?信不信由你,那就是接近市场,了解市场有多么情绪化,最好不要被市场 "必须走 "的方向所束缚。许多交易者会坚持亏损的交易,这不是为了账户的利益,而是为了保护自己的自尊心。当然,更好的交易之道是专注于保护账户净值,把自负留在交易室门口,以免它对你的交易产生负面影响。
当您知道自己不了解
时的策略
能够无所畏惧地进行交易的交易者有一个共同点。他们将亏损交易融入自己的方法中。这类似于国际象棋中的赌局,它消除了恐惧对许多交易者的影响。对于不懂国际象棋的人来说,"赌博 "是一种为了获得优势而牺牲低价值棋子(如棋子)的玩法。在交易中,赌局可能是你的第一笔交易,它能让你在进入交易的那一刻更好地体验你所感受到的优势。
詹姆斯-斯坦利(James Stanley)的 "美元对冲"(USD Hedge)就是一个很好的例子,它是在假设有一笔交易会亏损的前提下实施的策略。这有什么意义呢?它预先假定了亏损,让你在交易时不会产生困扰许多交易者的恐惧。分形是另一个可以帮助你确定趋势是对你有利还是对你不利的工具。
如果你把目光投向交易和国际象棋之外的世界,还有其他一些行业,它们也会预设亏损,因此在亏损来临时能够头脑清醒地采取行动。这些企业就是赌场和保险公司。这两种行业都假定会有亏损,并且只按照计算好的风险行事,它们的运作没有恐惧,如果你把小亏损假定为你策略的一部分,你也能做到这一点。
马克-道格拉斯的另一句名言
"我越不在意自己是否错了,事情就越清晰,这让我更容易进出头寸,减少损失,让自己有足够的精神去抓住下一个机会"。马克-道格拉斯
快乐交易!
来源