
Zeitreihenvorhersage mittels exponentieller Glättung (Fortsetzung)

Einleitung
In dem Beitrag Zeitreihenvorhersage mittels exponentieller Glättung (s. Verweise/Weblinks [1]) wurden kurz einige exponentielle Glättungsmodelle vorgestellt, einer der möglichen Ansätze zur Optimierung der Modellparameter vorgeführt und letztlich ein Indikator zur Erstellung von Vorhersagen auf der Grundlage eines linearen Wachstumsmodells mit Dämpfung angelegt. In dem hier vorliegenden Beitrag wird der Versuch unternommen, die Vorhersagegenauigkeit dieses Indikators zu steigern.
Die Vorhersage von Devisenkursverläufen ist eine komplizierte Aufgabe, und eine einigermaßen zuverlässige Vorhersage für drei bis vier Schritte in die Zukunft zu bekommen, ist erst recht schwer. Nichtsdestotrotz werden wir im Weiteren wie bereits in dem zuvor veröffentlichten Beitrag auch hier Vorhersagen für 12 Schritte in die Zukunft erstellen wohl wissend, dass es kaum gelingen wird, vor einem derart breiten Horizont zufriedenstellende Ergebnisse zu erhalten. Deshalb müssen wir unsere Aufmerksamkeit in erster Linie auf die ersten Vorhersageschritte richten, für die das Zuverlässigkeitsintervall am kleinsten ist.
Eine Vorhersage für 10 bis 12 Schritte in die Zukunft dient hauptsächlich der Veranschaulichung von Verhaltensauffälligkeiten unterschiedlicher Vorhersagemodelle und -methoden. In jedem Fall helfen die Grenzen des Vertraulichkeitsintervalls bei der Beurteilung der Glaubwürdigkeit der erhaltenen Vorhersage für jeden Horizont. Das Hauptanliegen dieses Beitrages besteht darin, einige Methoden zu veranschaulichen, mit deren Hilfe versucht werden kann, den in dem älteren Artikel (s. Verweise/Weblinks [1]) vorgestellten Indikator nachzubessern.
Der zum Anlegen von Indikatoren verwendete Algorithmus für die Suche nach dem Minimum einer Funktion mit mehreren Variablen wurde in dem genannten Artikel bereits behandelt, deshalb schreiben wir ihn hier nicht noch einmal. Um diesen Beitrag nicht zu überfrachten, werden theoretische Berechnungen lediglich in minimalem Umfang aufgeführt.
1. Der Ausgangsindikator
Als Ausgangspunkt verwenden wir den Indikator IndicatorES.mq5 (siehe den Artikel [1] unter Verweise/Weblinks).
Zur Zusammenstellung des Indikators müssen sich die Dateien IndicatorES.mq5, CIndicatorES.mqh und PowellsMethod.mqh alle im selben Verzeichnis befinden. Diese Dateien sind in der gepackten Datei files2.zip am Ende dieses Beitrages enthalten.
Rufen wir uns die Ausdrücke in Erinnerung, durch die das zur Erstellung dieses Indikators verwendete Modell der exponentiellen Glättung des linearen Wachstums mit Glättung definiert wird.
![]()
![]()
![]()
mit:
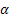 für den Glättungsparameter für den Grad der Folge, [0,1];
für den Glättungsparameter für den Grad der Folge, [0,1];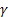 für den Glättungsparameter für den Trend, [0,1];
für den Glättungsparameter für den Trend, [0,1];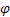 für den Dämpfungsparameter, [0,1];
für den Dämpfungsparameter, [0,1];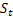 für den zum Zeitpunkt t nach Auftreten des Wertes
für den zum Zeitpunkt t nach Auftreten des Wertes 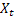 berechneten geglätteten Grad der Folge;
berechneten geglätteten Grad der Folge;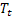 für den zum Zeitpunkt t berechneten geglätteten additiven Trend;
für den zum Zeitpunkt t berechneten geglätteten additiven Trend;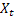 für den Wert der Folge zum Zeitpunkt t;
für den Wert der Folge zum Zeitpunkt t;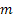 für die Anzahl der Schritte, für die die Vorhersage erfolgt;
für die Anzahl der Schritte, für die die Vorhersage erfolgt;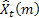 für die zum Zeitpunkt t vorgenommene Vorhersage für die m nächsten Schritte;
für die zum Zeitpunkt t vorgenommene Vorhersage für die m nächsten Schritte;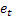 für den Fehler bei der Vorhersage für den nächsten Schritt zum Zeitpunkt t,
für den Fehler bei der Vorhersage für den nächsten Schritt zum Zeitpunkt t, 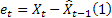 .
.
Einziger Eingangsparameter des Indikators ist der Wert, der die Länge des Intervalls, für das die Optimierung der Modellparameter sowie die Auswahl der Anfangswerte (das Untersuchungsintervall) erfolgen. Nach der Bestimmung der optimalen Werte der Modellparameter für das vorgegebene Intervall erfolgen die Berechnung und Erstellung der Vorhersage selbst sowie des Zuverlässigkeitsintervalls und der der Vorhersage des Modells für den nächsten Schritt entsprechenden Linie. Die Optimierung der Parameter und die Erstellung der Vorhersage erfolgt bei jedem Auftreten eines neuen Balkens.
Da dieser Indikator nachgebessert werden soll, verwenden wir zur Bewertung des Einflusses der von uns vorgenommenen Veränderungen die Testfolgen aus der gepackten Datei Files2.zip am Ende dieses Beitrages. In der gepackten Datei befinden sich in dem Verzeichnis \Dataset2 Dateien mit den gespeicherten Kursverläufen für EURUSD, USDCHF und USDJPY sowie den US Dollar Index DXY. Jeder davon wurde für jeweils drei Zeiträume gespeichert: M1, H1 und D1. In den Dateien sind die Eröffnungskurse „open“ gespeichert, wobei der zeitlich jeweils letzte Wert sich am Ende der Datei befindet. Jede der Dateien enthält 1.200 Elemente.
Die Vorhersagefehler werden mithilfe der Berechnung des Koeffizienten des durchschnittlichen absoluten prozentualen Fehlers (Mean Absolute Percentage Error, kurz: MAPE) ermittelt:
![]()
Wir teilen jede der zwölf Testfolgen in jeweils fünfzig einander überschneidende Abschnitte zu 80 Elementen und berechnen des Weiteren für jede von ihnen den MAPE-Wert. Den auf diese Weise gewonnenen Durchschnittswert der Berechnungen verwenden wir als Kennziffer für den Vorhersagefehler für die verglichenen Indikatoren. Ebenso berechnen wir die MAPE-Werte für die Fehler der Vorhersagen um zwei oder mehr Schritte in die Zukunft. Im Folgenden erscheinen diese Durchschnittswerte unter folgenden Bezeichnungen:
- MAPE1 für den Durchschnittswert für den Fehler bei Vorhersagen für den nächsten Schritt;
- MAPE2 für den Durchschnittswert für den Fehler bei Vorhersagen für die nächsten zwei Schritte;
- MAPE3 für den Durchschnittswert für den Fehler bei Vorhersagen für die nächsten drei Schritte;
- MAPE1-3 für den Durchschnitt aus (MAPE1+MAPE2+MAPE3)/3.
Bei der Berechnung des MAPE-Werts wird der absolute Wert des Vorhersagefehlers in jedem Schritt durch den aktuellen Wert der Folge dividiert. Um dabei die Division durch null ebenso auszuschließen wie ein negatives Ergebnis, darf die Eingangsfolge wie in unserem Fall ausschließlich positive Werte ungleich null annehmen.
Für unseren Ausgangsindikator werden die Werte dieser Berechnungen in der Tabelle 1 aufgeführt.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0,2099 | 0,2925 | 0,3564 | 0,2863 |
Tabelle 1. Berechnung der Fehler in den Vorhersagen des Ausgangsindikators
Die in der Tabelle 1 wiedergegebenen Daten wurden mithilfe des Skriptes Errors_IndicatorES.mq5 (aus der gepackten Datei files2.zip am Ende dieses Beitrags) bezogen. Zur Zusammenstellung und Ausführung des Skripts müssen die Dateien CIndicatorES.mqh und PowellsMethod.mqh sich in demselben Verzeichnis befinden wie die Datei Errors_IndicatorES.mq5, und die Eingangsfolgen in dem Verzeichnis Files\Dataset2\.
Nach der Ermittlung der Ausgangsberechnungen der Vorhersagefehler kann mit der Nachbesserung dieses Indikators begonnen werden.
2. Das Optimierungskriterium
In dem Ausgangsindikator aus dem Beitrag: Zeitreihenvorhersage mittels exponentieller Glättung wurden die Modellparameter mithilfe der Minimierung der Quadrate der Fehler bei einer Vorhersage für den nächsten Schritt festgelegt. Es liegt nahe zu vermuten, dass die optimalen Modellparameter für die Vorhersage für den nächsten Schritt nicht den das Fehlerminimum für eine Vorhersage um mehr Schritte in die Zukunft liefern. Natürlich wäre es wünschenswert, die Vorhersagefehler für 10 bis 12 Schritte in die Zukunft zu minimieren, aber für die von uns betrachteten Folgen ist es nicht möglich, für einen solchen Zeitraum ein zufriedenstellendes Vorhersageergebnis zu erzielen.
Deshalb wollen wir realistisch bleiben und verwenden bei der Optimierung der Modellparameter als erste Nachbesserung unseres Indikators die Summe der Quadrate der Fehler bei den Vorhersagen für den nächsten, die nächsten zwei und die nächsten drei Schritte. Dabei ist zu erwarten, dass es gelingt, die durchschnittliche Fehlermenge in dem Intervall der ersten drei Vorhersageschritte etwas zu senken.
Natürlich berührt diese Nachbesserung des Ausgangsindikators nicht die wesentlichen Grundsätze seiner Anlage, sie ändert lediglich das Kriterium zur Optimierung der Parameter, weshalb keine enorme Steigerung der Vorhersagegenauigkeit erwartet werden darf. Nichtsdestoweniger sollte die Anzahl der Vorhersagefehler für zwei bzw. drei Schritte in die Zukunft etwas geringer werden.
Um die Vorhersageergebnisse vergleichen zu können, wurde die Klasse CMod1 angelegt, sie entspricht der Klasse CIndicatorES aus dem vorausgehenden Artikel, lediglich mit veränderter Zielfunktion func.
Die Funktion func der Ausgangsklasse CIndicatorES:
double CIndicatorES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 sse=0; for(i=0;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(Dlen*MathLog(k1*k2*k3*sse)); }
Nach Vornahme der Modifikationen sieht die Funktion func folgendermaßen aus:
double CMod1::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95; // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*k3*err); }
Jetzt kommt bei der Berechnung der Zielfunktion die Summe der Quadrate der Fehler bei der Vorhersage für einen, zwei und drei Schritte in die Zukunft zum Einsatz.
Weiterhin wurde auf der Grundlage dieser Klasse das Skript Errors_Mod1.mq5 angelegt, das wie auch das bereits erwähnte Skript Errors_IndicatorES.mq5 die Durchführung der Berechnung der Vorhersagefehler ermöglicht. Die Dateien CMod1.mqh und Errors_Mod1.mq5 sind ebenfalls in der gepackten Datei files2.zip am Ende dieses Beitrages enthalten.
In der Tabelle 2 sind die Berechnungsergebnisse für die Vorhersagefehler für die Ausgangs- und die nachgebesserte Variante aufgeführt.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0,2099 | 0,2925 | 0,3564 | 0,2863 |
| Mod1 | 0,2144 | 0,2898 | 0,3486 | 0,2842 |
Tabelle 2. Vergleich der Vorhersagefehlerberechnungen
Unübersehbar konnten die Fehlerkoeffizienten MAPE2 und MAPE3 sowie der Durchschnittswert für MAPE1-3 bei den betrachteten Folgen tatsächlich leicht gesenkt werden. Deshalb behalten wir diese Variante bei und kommen zur weiteren Nachbesserung unseres Indikators.
3. Die Anpassung der Parameter bei der Glättung
Die Idee der Änderung der Glättungsparameter in Abhängigkeit von den jeweils aktuellen Werten der Eingangsfolge ist nicht neu und dem Wunsch geschuldet, die Glättungskoeffizienten dergestalt zu korrigieren, dass sie bei jeder Änderung der Art der Eingangsfolge optimal bleiben. Die Darstellung einiger Möglichkeiten zur Anpassung der Glättungskoeffizienten finden sich in der Literatur (s. Verweise/Weblinks [2] und [3]).
Im Vertrauen darauf, dass die Verwendung des adaptiven exponentiellen Glättungsmodells uns die Steigerung der Vorhersagegenauigkeit unseres Parameters ermöglicht, probieren wir als nächste Nachbesserung den Einsatz eines Modells mit sich dynamisch veränderndem Glättungskoeffizienten aus.
Unglücklicherweise führt die Mehrzahl der bekannten Adaptionsverfahren bei ihrer Verwendung in Vorhersagealgorithmen bei weitem nicht immer zu dem gewünschten Ergebnis. Die Auswahl der geeigneten Art der Adaption kann sich mitunter als überaus unhandliches und zeitraubendes Unterfangen erweisen, weshalb wir uns hier die in der Literatur (s. Verweise/Weblinks [4]) vorgestellten Erkenntnisse zu Nutzen machen und versuchen werden, das in einem anderen Beitrag (ebda. [5]) vorgestellte Verfahren der exponentiellen Glättung mit fließendem Übergang (Smooth Transition Exponential Smoothing. kurz: STES) umzusetzen.
Dort wird das Wesen dieses Verfahrens kurz und verständlich umrissen, weshalb wir das hier nicht wiederholen, sondern gleich den Ausdruck für unser Modell (s. den Anfang des genannten Beitrages) eingedenk der Verwendung des adaptiven Glättungskoeffizienten vorstellen werden.
![]()
![]()
![]()
![]()
Wie wir sehen, wird der Wert des Glättungsparameters "Alpha" jetzt für jeden Schritt des Algorithmus berechnet und hängt vom Quadrat des Vorhersagefehlers ab. Der Einfluss der Vorhersagefehlers auf die Größe von "Alpha" wird von den Werten der Koeffizienten „b“ und „g“ bestimmt. Im Übrigen bleiben die Ausdrücke für das verwendete Modell unverändert. Weitere Informationen zur Verwendung des STES-Verfahrens bietet der Beitrag (s. Verweise/Weblinks [6]).
Wenn in den vorhergehenden Varianten bezüglich der gegebenen Eingangsfolge nach dem optimalen Wert des Koeffizienten "Alpha" gesucht wurde, so unterliegen jetzt die beiden Adaptionskoeffizienten b und g der Optimierung, während der Wert für "Alpha" bei der Glättung der Eingangsfolge dynamisch festgelegt wird.
Diese Nachbesserung wird in Form der Klasse CMod2 umgesetzt. Die wesentlichen Änderungen betreffen (wie beim letzten Mal) im Wesentlichen die Funktion func, die jetzt wie folgt aussieht:
double CMod2::func(const double &p[]) { int i; double s,t,alp,gam,phi,sb,sg,k1,k2,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; gam=p[2]; phi=p[3]; sb=p[4]; sg=p[5]; k1=1; k2=1; if (gam>0.95){k1+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k1+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k2+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k2+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*err); }
Bei der Erstellung dieser Funktion wurden an dem Ausdruck zur Bestimmung der Größe des Koeffizienten "Alpha" einige Änderungen vorgenommen. Das ist geschehen, um den möglichen Höchst- und Tiefstwert für diesen Koeffizienten auf 0,05 bzw. 0,95 zu begrenzen.
Auf der Grundlage der Klasse CMod2 wurde das Skript Errors_Mod2.mq5 geschrieben, das wie auch schon beim letzten Mal die Berechnung der Vorhersagefehler ermöglicht. Auch die Dateien CMod2.mqh und Errors_Mod2.mq5 sind in der gepackten Datei files2.zip am Ende dieses Beitrages enthalten.
Diese Funktionen sind in der Tabelle 3 aufgeführt.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0,2099 | 0,2925 | 0,3564 | 0,2863 |
| Mod1 | 0,2144 | 0,2898 | 0,3486 | 0,2842 |
| Mod2 | 0,2145 | 0,2832 | 0,3413 | 0,2797 |
Tabelle 3. Vergleich der Vorhersagefehlerberechnungen
Aus der Tabelle 3 folgt, dass die Verwendung eines adaptiven Glättungskoeffizienten ermöglicht hat, die Vorhersagefehler für unsere Testsequenzen im Durchschnitt noch ein wenig stärker zu verringern. Demnach konnte der Fehlerkoeffizient MAPE1-3 nach zwei erfolgten Nachbesserungen um etwa 2 Prozent herabgesetzt werden.
Obwohl das Ergebnis unserer Nachbesserungen sich recht bescheiden ausnimmt, behalten wir die so gewonnene Variante bei und lassen weitere Nachbesserungen im Rahmen dieses Beitrages unberücksichtigt. Als Nächstes interessiert uns die Verwendung der Box-Cox-Transformation. Diese Umwandlung wird am häufigsten dazu eingesetzt, die Verteilungsgesetzmäßigkeit einer Ausgangsfolge an die Normalverteilung anzunähern.
In unserem Fall könnten wir sie nutzen, um die Ausgangsfolge umzuwandeln, die Vorhersage anzustellen und diese anschließend in umgekehrter Richtung umzuwandeln. Dabei ist der verwendete Transformationskoeffizient so zu wählen, dass der resultierende Vorhersagefehler minimiert wird. Ein Anwendungsbeispiel für die Box-Cox-Transformation bei der Vorhersage von Folgen findet sich in dem Beitrag (s. Verweise/Weblinks [7]).
4. Das Zuverlässigkeitsintervall der Vorhersage
Bei dem Ausgangsindikator IndicatorES.mq5 (aus dem vorhergehenden Beitrag) wurde das Zuverlässigkeitsintervall der Vorhersage anhand des für das gewählte exponentielle Glättungsmodell erstellten analytischen Ausdrucks berechnet (s. Verweise/Weblinks [8]). In unserem Fall hat sich nach der Vornahme der Anpassungen auch das von uns verwendete Modell geändert. Da der Glättungskoeffizient jetzt zu einer Variablen geworden ist, wäre der Einsatz der genannten analytischen Ausdrücke zur Ermittlung des Zuverlässigkeitsintervalls nicht mehr korrekt.
Als ergänzendes Argument zugunsten der Änderung der Art der Ermittlung des Zuverlässigkeitsintervalls könnte der Umstand dienen, dass die früher verwendeten analytischen Ausdrücke ausgehend von der Annahme der symmetrischen und „normalen“ Verteilung der Vorhersagefehler angelegt wurden. Für unsere Klasse von Folgen sind diese Bedingungen nicht erfüllt, und die Verteilung der Vorhersagefehler kann weder normal noch symmetrisch sein.
Bei dem Ausgangsindikator wurde bei der Ermittlung des Zuverlässigkeitsintervalls zunächst an der Eingangsfolge die Streuung der Fehler bei der Vorhersage für den nächsten Schritt berechnet und anschließend bereits auf deren Grundlage mithilfe analytischer Ausdrücke die Streuung für Vorhersagen um zwei, drei usw. Schritte in die Zukunft bestimmt.
Um die Verwendung analytischer Ausdrücke zu umgehen, kann die einfachste Variante genutzt werden, bei der die Streuung bei der Vorhersage um zwei, drei usw. Schritte in die Zukunft ebenso wie die Streuung der Vorhersage für den nächsten Schritt unmittelbar anhand der Eingangsfolge berechnet wird. Diese Vorgehensweise leidet allerdings an einem ganz wesentlichen Mangel: bei kurzen Eingangsfolgen weist die Berechnung des Zuverlässigkeitsintervalls eine enorme Streuung auf, und die Berechnung der Streuung und des durchschnittlichen quadrierten Fehlers lässt die Aufhebung der für die mutmaßliche Normalität der Fehler geltenden Beschränkungen nicht zu.
Als Ausweg aus dieser Situation kann hier die Anwendung des parameterlosen Bootstrapping (Resampling) (s. Verweise/Weblinks [9]) dienen. Den Grundgedanken kann man in einfache Worte fassen: erfolgt die Stichprobenentnahme aus der Ausgangsfolge zufällig mit Zurücklegen (gleichmäßige Verteilung), so legt die auf diese Weise künstlich entstehende Folge dieselbe Verteilung an den Tag wie die ursprüngliche.
Angenommen, wir haben eine Eingangsfolge mit N Elementen, dann können wir, nachdem wir eine pseudozufällige Folge mit gleichmäßiger Verteilung in dem Bereich [0,N-1] erzeugt und diese Werte bei der Stichprobenentnahme aus dem Eingangsdatenfeld als Kennziffern verwendet haben, eine künstliche Folge von erheblich größerer Länge als die Ausgangsfolge anlegen. Dabei ist die Verteilungsgesetzmäßigkeit bei der erzeugten Folge genauso (fast genauso) wie bei der ursprünglichen Folge.
Das Bootstrap-Verfahren bei der Berechnung der Zuverlässigkeitsintervalle könnte folgendermaßen aussehen:
- Für das von uns bei der Nachbesserung gewonnene exponentielle Glättungsmodell ermitteln wir anhand der Eingangsfolge die optimalen Größen für die Eingangswerte des Modells sowie für seine Koeffizienten und Adaptionskoeffizienten. Die Suche nach den optimalen Parametern erfolgt wie gehabt mithilfe eines Algorithmus, der die Suchmethode von Powell beinhaltet.
- Unter Einsatz der ermittelten optimalen Modellparameter „gehen“ wir die ursprüngliche Folge „durch“ und legen ein Datenfeld mit den Vorhersagefehlern für den nächsten Schritt an. Das Datenfeld enthält eine der Länge N der Eingangsfolge entsprechende Anzahl an Elementen;
- Wir richten die Fehler aus, indem wir ihren Durchschnittswert von jedem Element des Fehlerdatenfeldes abziehen;
- Mithilfe des Pseudozufallsfolgengenerators legen wir die Kennziffern in dem Bereich [0,N-1] an und verwenden diese zur Bildung einer künstlichen Fehlerfolge mit einer Länge von 9.999 Elementen (Resampling);
- Indem wir in die Ausdrücke zur Darstellung des von uns verwendeten Modells die Werte aus dem künstlich erzeugten Fehlerdatenfeld einfügen, legen wir ein Datenfeld mit einer 9.999 Werte umfassenden Pseudoeingangsfolge an. Mit anderen Worten, wenn früher die Werte der Eingangsfolge in die Ausdrücke für das Modell eingefügt worden sind, und dabei der Vorhersagefehler ermittelt wurde, so erfolgt die Berechnung jetzt in umgekehrter Richtung. Zu jedem Element des Datenfeldes fügen wir den Wert des Fehlers ein und berechnen damit den Eingangswert. In der Folge erhalten wir ein Datenfeld aus 9.999 Elementen, das eine Folge mit derselben Verteilungsgesetzmäßigkeit wie die Eingangsfolge enthält allerdings mit einer zur unmittelbaren Berechnung der Zuverlässigkeitsintervalle der Vorhersage ausreichenden Länge.
Des Weiteren führen wir mithilfe der von uns angelegten ausreichend langen Folge die Berechnung der Zuverlässigkeitsintervalle durch. Dazu machen wir uns den Umstand zunutze, dass beim Anlegen und anschließenden Sortieren des Vorhersagefehlerdatenfeldes in aufsteigender Folge bei einem Datenfeld mit 9.999 Werten dessen Zellen mit den Kennziffern 249 bzw. 9.749 genau die Werte enthalten werden, die den Grenzen des 95%-Zuverlässigkeitsintervalls [10] entsprechen.
Zur genaueren Bestimmung der Zuverlässigkeitsgrenzen wird eine ungerade Länge für das Datenfeld gewählt. In unserem Fall sind zur Festlegung der Grenzen der Zuverlässigkeitsintervalle der Vorhersage folgende Arbeitsschritte auszuführen:
- Unter Einsatz der oben bereits ermittelten optimalen Werte für die Modellparameter „gehen“ wir die erzeugte Folge „durch“ und legen ein Datenfeld mit 9.999 Vorhersagefehlern für den jeweils nächsten Schritt an;
- Wir ordnen das resultierende Datenfeld;
- Aus dem geordneten Fehlerdatenfeld wählen wird die Werte der Zellen mit den Kennziffern 249 und 9.749 aus, da sie die Grenzen des 95%-Zuverlässigkeitsintervalls bezeichnen;
- Wir wiederholen die ersten drei Schritte für die Fehler der Vorhersagen für zwei, drei usw. Schritte in die Zukunft.
Diese Art der Bestimmung der Zuverlässigkeitsintervalle birgt Vor- wie Nachteile.
Zu den Vorteilen kann man das Fehlen von Vermutungen bezüglich der Art der Verteilungsgesetzmäßigkeit der Vorhersagefehler zählen. Es ist absolut nicht zwingend erforderlich, dass sie normal oder symmetrisch verteilt sind. Außerdem kann diese Methode dann zum Einsatz kommen, wenn die Ableitung analytischer Ausdrücke für das verwendete Modell nicht möglich ist.
Den Schwächen müssen die dramatische Vermehrung des Umfangs der erforderlichen Berechnungen und die Empfindlichkeit ihrer Streuung gegenüber der Qualität des verwendeten Pseudozufallsfolgengenerators zugerechnet werden.
Das vorgestellte Verfahren zur Bestimmung der Zuverlässigkeitsintervalle mithilfe von Resampling und Quantilen ist recht schlicht und bietet gewiss Verbesserungsmöglichkeiten. Da in unserem Fall die Zuverlässigkeitsintervalle lediglich zur Veranschaulichung dienen, reicht die Genauigkeit dieser Methode vollkommen aus.
5. Die nachgebesserte Fassung des Indikators
Unter Einbeziehung der in diesem Beitrag vorgestellten Nachbesserungen wurde der Indikator ForecastES.mq5 entwickelt. Dabei wurde zum Resampling der Pseudozufallsfolgegenerator aus dem Artikel [11] herangezogen. Mit dem üblichen Generator MathRand() wurden etwas schlechtere Ergebnisse erzielt. Möglicherweise wegen der nicht ausreichenden Spannbreite der mit seiner Hilfe erzeugten Werte [0,32767].
Bei der Erstellung des Indikators ForecastES.mq5 müssen sich die Dateien PowellsMethod.mqh, CForeES.mqh und RNDXor128.mqh in demselben Verzeichnis wie dieser befinden. All diese Dateien sind in der gepackten Datei fore.zip enthalten.
Im Anschluss sehen wir den Programmcode des Indikators ForecastES.mq5.
//+------------------------------------------------------------------+ //| ForecastES.mq5 | //| Copyright 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg." #property link "https://www.mql5.com" #property version "1.02" #property description "Forecasting based on the exponential smoothing." #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" // Forecast #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "ConfUp" // Confidence interval #property indicator_type3 DRAW_LINE #property indicator_color3 clrCrimson #property indicator_style3 STYLE_DOT #property indicator_width3 1 #property indicator_label4 "ConfDn" // Confidence interval #property indicator_type4 DRAW_LINE #property indicator_color4 clrCrimson #property indicator_style4 STYLE_DOT #property indicator_width4 1 input int nHist=80; // History bars, nHist>=24 #include "CForeES.mqh" #include "RNDXor128.mqh" #define NFORE 12 #define NBOOT 9999 double Hist[],Fore[],Conf1[],Conf2[]; double Data[],Err[],BSDat[],Damp[NFORE],BSErr[NBOOT]; int NDat; CForeES Es; RNDXor128 Rnd; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { NDat=nHist; if(NDat<24)NDat=24; MqlRates rates[]; CopyRates(NULL,0,0,NDat,rates); // Load missing data ArrayResize(Data,NDat); ArrayResize(Err,NDat); ArrayResize(BSDat,NBOOT+NFORE); SetIndexBuffer(0,Hist,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,Fore,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFORE); SetIndexBuffer(2,Conf1,INDICATOR_DATA); // Confidence interval PlotIndexSetString(2,PLOT_LABEL,"ConfUp"); PlotIndexSetInteger(2,PLOT_SHIFT,NFORE); SetIndexBuffer(3,Conf2,INDICATOR_DATA); // Confidence interval PlotIndexSetString(3,PLOT_LABEL,"ConfDN"); PlotIndexSetInteger(3,PLOT_SHIFT,NFORE); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,j,k,start; double s,t,alp,gam,phi,sb,sg,e,f,a,a1,a2; if(rates_total<NDat){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated==rates_total)return(rates_total); // New tick but not new bar start=rates_total-NDat; //----------------------- PlotIndexSetInteger(0,PLOT_DRAW_BEGIN,rates_total-NDat); PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFORE); for(i=0;i<NDat;i++)Data[i]=open[rates_total-NDat+i]; // Input data Es.CalcPar(Data); // Optimization of parameters s=Es.GetPar(0); t=Es.GetPar(1); gam=Es.GetPar(2); phi=Es.GetPar(3); sb=Es.GetPar(4); sg=Es.GetPar(5); //---- a=phi; Damp[0]=phi; for(j=1;j<NFORE;j++){a=a*phi; Damp[j]=Damp[j-1]+a;} // Phi table //---- f=s+phi*t; for(i=0;i<NDat;i++) // History { e=Data[i]-f; Err[i]=e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); Hist[start+i]=f; // History } for(j=0;j<NFORE;j++)Fore[rates_total-NFORE+j]=s+Damp[j]*t; // Forecast //---- a=0; for(i=0;i<NDat;i++)a+=Err[i]; a/=NDat; for(i=0;i<NDat;i++)Err[i]-=a; // alignment of the array of errors //---- f=Es.GetPar(0)+phi*Es.GetPar(1); for(i=0;i<NBOOT+NFORE;i++) // Resampling { j=(int)(NDat*Rnd.Rand_01()); if(j>NDat-1)j=NDat-1; e=Err[j]; BSDat[i]=f+e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=s+phi*t; } //---- for(j=0;j<NFORE;j++) // Prediction intervals { s=Es.GetPar(0); t=Es.GetPar(1); f=s+phi*t; for(i=0,k=0;i<NBOOT;i++,k++) { BSErr[i]=BSDat[i+j]-(s+Damp[j]*t); e=BSDat[i]-f; a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); } ArraySort(BSErr); Conf1[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[249]; Conf2[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[9749]; } return(rates_total); } //-----------------------------------------------------------------------------------
Zur besseren Anschaulichkeit wurde der Programmcode des Indikators nach Möglichkeit „zeilenweise“ aufgezeichnet. Als er programmiert wurde, war keine Optimierung vorgesehen.
In den Abbildungen 1 und 2 werden die Ergebnisse der Arbeit des Indikators in zwei unterschiedlichen Anwendungsfällen wiedergegeben.

Abbildung 1. Erstes Anwendungsbeispiel für den Indikator ForecastES.mq5

Abbildung 2. Zweites Anwendungsbeispiel für den Indikator ForecastES.mq5
In der Abbildung 2 wird deutlich, dass das 95%-Zuverlässigkeitsintervall asymmetrisch ist. Das ergibt sich daraus, dass die Eingangsfolge große Ausschläge aufweist, was zu einer asymmetrischen Verteilung der Vorhersagefehler führt.
Auf den Webseiten https://www.mql4.com und https://www.mql5.com wurden bereits Extrapolationsindikatoren bereitgestellt. Wir nehmen einen davon und zwar ar_extrapolator_of_price.mq5, dessen Ergebnisse wir, nachdem wir die Werte seiner Parameter wie in Abbildung 3 dargestellt eingerichtet haben, mit den Ergebnissen des von uns entwickelten Indikators vergleichen.

Abbildung 3. Einstellungen für den Indikator ar_extrapolator_of_price.mq5
Der Vergleich der Arbeit dieser beiden Indikatoren erfolgte optisch anhand unterschiedlicher Zeiträume der Kursverläufe für die Kürzel EURUSD und USDCHF. Auf den ersten Blick stimmt die allgemeine Richtung der Vorhersage beider Indikatoren in der Mehrzahl der Fälle überein. Bei längeren Beobachtungen können jedoch erhebliche Abweichungen zutage treten. Dabei wird der Indikator ar_extrapolator_of_price.mq5 natürlich stets eine stärker unterbrochene Vorhersagelinie liefern.
In der Abbildung 4 stellen wir ein Beispiel für die gleichzeitige Arbeit der Indikatoren ForecastES.mq5 und ar_extrapolator_of_price.mq5 vor.

Abbildung 4. Vergleich der Vorhersageergebnisse
Die Vorhersagelinie des Indikators ar_extrapolator_of_price.mq5 ist in der Abbildung 4 als durchgezogene orange-rote Linie abgebildet.
Fazit
Die Ergebnisse dieses und des vorhergehenden Beitrags:
- Es wurden bei der Vorhersage von Zeitreihen verwendete exponentielle Glättungsmodelle vorgestellt;
- Ihre Umsetzung in Programmform wurde dargelegt;
- Die Fragen der Auswahl der optimalen Werte für die Modellparameter wurden kurz erörtert;
- Eine Programmumsetzung des Algorithmus für die Suche nach dem Minimum einer Funktion mit mehreren Variablen mithilfe der Powellschen Methode wurde vorgestellt;
- Ebenso Programmbeispiele für die Optimierung der Parameter des Modells für eine Vorhersage anhand der Eingangsfolge;
- Vorgeführt wurden zudem einige elementare Beispiele für die Nachbesserung von Vorhersagealgorithmen;
- Ein Verfahren zur Berechnung der Zuverlässigkeitsintervalle einer Vorhersage mittels Bootstrapping und Quantilen wurde kurz betrachtet;
- Es wurde der Indikator ForecastES.mq5 angelegt. Er führt die Vorhersage von Kursverläufen aus und beinhaltet die in dem Beitrag behandelten Verfahren und Algorithmen;
- Zum Abschluss werden einige Verknüpfungen zu relevanten Beiträgen sowie Verweise auf Zeitschriften und Bücher zu diesem Thema aufgeführt.
Hinsichtlich des letztlich resultierenden Indikators ForecastES.mq5 ist anzumerken, dass der für die Optimierung verwendete, die Methode von Powell umsetzende Algorithmus in einigen Fällen nicht in der Lage ist, das Minimum der Zielfunktion mit der vorgegebenen Genauigkeit zu bestimmen. Dabei wird die zulässige Höchstzahl an Iterationen erreicht, und im Protokoll erscheint eine entsprechende Mitteilung. Aber im Programmcode des Indikators wird diese Situation nicht verarbeitet. Zur Veranschaulichung der hier vorgestellten Algorithmen ist das vollkommen in Ordnung, aber in seriösen Programmen muss diese Situation unbedingt überprüft und irgendwie verarbeitet werden.
Als weitere Entwicklungsrichtung für den Vorhersageindikator könnte der gleichzeitige Einsatz mehrerer Vorhersagemodelle in jedem Schritt infrage kommen, wobei im Weiteren einer von diesen beispielsweise anhand des Informationskriteriums von Akaike ausgewählt oder, bei Verwendung mehrerer artverwandter Modelle, der gewichtete Durchschnittswert ihrer Vorhersageergebnisse berechnet wird. Dabei können die Gewichtungskoeffizienten entsprechend dem Vorhersagefehlerkoeffizienten des jeweiligen Modells gewählt werden.
Der Themenbereich Zeitreihenvorhersage ist dergestalt umfangreich, dass in diesen Beiträgen nicht einmal ein winziger der damit verbundenen Fragen berührt werden konnte. Es bleibt dennoch zu hoffen, dass diese Veröffentlichungen dazu beitragen konnten, das Interesse des Lesers auf die Fragen der Vorhersage zu richten und dazu anregen, auf diesem Gebiet weiterzuarbeiten.
Verweise/Weblinks:
- Zeitreihenvorhersage mittels exponentieller Glättung.
- Ju. P. Lukaschin. Adaptive Methoden zur kurzfristigen Vorhersage von Zeitreihen: Fachbuch. - Moskau: Finanzen und Statistik, 2003. 416 ff.
- S.V. Bulaschev. Statistics for Traders (Statistik für Devisenhändler) - Moskau: Sputnik +, 2003. - 245 pp.
- Everette S. Gardner Jr. Exponential Smoothing: The State of the Art – Part II. 3. Juni 2005.
- James W. Taylor, Smooth Transition Exponential Smoothing. Journal of Forecasting, 2004, Bd. 23, S. 385-394.
- James W. Taylor, Volatility Forecasting with Smooth Transition Exponential Smoothing. International Journal of Forecasting, 2004, Bd. 20, S. 273-286.
- Alysha M. De Livera. Automatic Forecasting with a Modified Exponential Smoothing State Space Framework. 28. April 2010, Abteilung für Ökonometrie und Wirtschaftsstatistik, Monash-Universität, VIC 3800 Australien.
- Rob J Hyndman et al. Prediction Intervals for Exponential Smoothing Using Two New Classes of State Space Models. 30. Januar 2003.
- The Quantile Journal. Ausgabe Nr. 3, September 2007.
- http://ru.wikipedia.org/wiki/Квантиль
- Analyse der wesentlichen Merkmale von Zeitreihen
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/346
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Erstellen von Expert-Systemen mit dem Hilfsprogramm Expert Advisor Visual Wizard
Erstellen von Expert-Systemen mit dem Hilfsprogramm Expert Advisor Visual Wizard
 Erstellung von Handelssystemen mittels Diskriminanzanalyse
Erstellung von Handelssystemen mittels Diskriminanzanalyse
 Trademinator 3: Aufstand der Handelsrobots
Trademinator 3: Aufstand der Handelsrobots
 Analyse der statistischen Eigenschaften von Indikatoren
Analyse der statistischen Eigenschaften von Indikatoren
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Victor, haben Sie nicht irgendeine Änderung der Indikatoren mit History Shift? Nicht nur für den letzten Balken. Ich würde gerne die Effizienz der von Ihnen implementierten Methoden grob einschätzen.
Nein, ich habe keine verschobenen Indikatoren gemacht.
In der Datei ForecastES.mq5 wurden die erkannten Fehler korrigiert. Die aktualisierte Datei ForecastES.mq5 befindet sich wie zuvor im Archiv Fore.zip.
Der neue Artikel Zeitreihenprognose mit Exponentialglättung (Fortsetzung) wurde veröffentlicht:
Autor: Victor
Ich habe viele Male versucht, diesen modifizierten neuen Indikator in der Code Base Sektion des MT5 zu finden, aber ich konnte ihn nicht finden.
Können Sie ihn bitte in die Code Base des MT5 einfügen, damit ich ihn einfach herunterladen und testen kann? Oder stellen Sie mir bitte den modifizierten Indikator zur Verfügung und wie ich ihn in meinen MT5 herunterladen kann?
Haben Sie das gleiche für MT4?
Wer kann mir bitte helfen?
Ich danke Ihnen
Forum zum Thema Handel, automatisierte Handelssysteme und Testen von Handelsstrategien
Diskussion des Artikels "Zeitreihenprognose mit Exponentialglättung"
newdigital, 2014.06.06 21:48
Ein furchtloser Forex-Trader werden
- Müssen Sie wissen, was als nächstes passieren wird?
- Gibt es einen besseren Weg?
- Strategien, wenn Sie wissen, dass Sie nicht wissen
"Gutes Investieren ist eine eigenartige Balance zwischen der Überzeugung, seinen Ideen zu folgen, und der Flexibilität, zu erkennen, wann man einen Fehler gemacht hat."-Michael Steinhardt
"95 % der Handelsfehler, die Sie wahrscheinlich begehen, sind auf Ihre Einstellung zurückzuführen, falsch zu liegen, Geld zu verlieren, etwas zu verpassen und Geld auf dem Tisch liegen zu lassen - die vier Handelsängste"
-Mark Douglas, Trading In the Zone
Viele Händler sind von der Idee der Vorhersage fasziniert. Die Notwendigkeit von Prognosen scheint dem erfolgreichen Handel inhärent zu sein. Schließlich muss ich doch wissen, was als Nächstes passieren wird, um Geld zu verdienen, oder? Zum Glück stimmt das nicht, und in diesem Artikel erfahren Sie, wie Sie gut handeln können, ohne zu wissen, was als Nächstes passieren wird.
Müssen Sie wissen, was als Nächstes passiert?
Es wäre zwar hilfreich zu wissen, was als Nächstes passiert, aber niemand kann es mit Sicherheit wissen. Der Grund dafür, dass Insiderhandel ein Verbrechen ist, das auf den Aktienmärkten oft getestet wird, zeigt, dass einige Händler so verzweifelt sind, die Zukunft zu kennen, dass sie bereit sind, zu betrügen und eine hohe Strafe zu zahlen, wenn sie erwischt werden. Kurz gesagt, es ist gefährlich, an eine bestimmte Zukunft zu denken, wenn Ihr Geld auf dem Spiel steht, und es ist besser, bei einem Handel an die Chancen als an die Gewissheiten zu denken.
Das Problem bei der Annahme, dass Sie wissen müssen, was die Zukunft für Ihren Handel bereithält, besteht darin, dass sich Angst einstellt, wenn etwas Unerwartetes mit Ihrem Handel geschieht. Angst ist an sich nichts Schlechtes. Die meisten Händler, die ihr Geld aufs Spiel setzen, erstarren jedoch oft und schaffen es nicht, den Handel abzuschließen.
Wenn Sie nicht wissen müssen, was als Nächstes passieren wird, was brauchen Sie dann? Die Liste ist überraschend kurz und einfach, aber noch wichtiger ist, dass Sie nicht glauben, zu wissen, was passieren wird, denn wenn Sie das tun, werden Sie wahrscheinlich einen zu hohen Hebel ansetzen und die Risiken herunterspielen, die in der Welt des Handels allgegenwärtig sind.
- Eine saubere Kante, mit der Sie sich wohl fühlen, wenn Sie einen Handel eingehen
- Ein gut definierter Invalidierungspunkt, an dem Ihr Trade-Setup nicht mehr gültig ist
- Ein potenzieller Einstiegspunkt für eine Umkehrung
- Angemessene Handelsgröße / Money Management
Gibt es einen besseren Weg?Gestern beschloss die Europäische Zentralbank, ihren Refi-Satz und den Einlagensatz zu senken. Viele Händler gingen mit Leerverkäufen in diese Sitzung, doch EURUSD deckte ~250% seiner ATR-Tagesspanne ab und schloss nahe den Höchstständen, was auf EURUSD-Stärke hindeutet. Einfach ausgedrückt: Das Ergebnis lag außerhalb des Bereichs des Möglichen für die meisten Händler, und wenn Sie short gegangen sind und von Angst ergriffen wurden, haben Sie diese Short-Position wahrscheinlich nicht geschlossen und waren ein weiteres "Opfer des Marktes", was eine andere Art ist, zu sagen, ein Opfer Ihrer eigenen Verlustängste.
Was ist also der bessere Weg? Ob Sie es glauben oder nicht, man muss sich dem Markt nähern und verstehen, wie emotional die Märkte sein können und dass es am besten ist, sich nicht auf die Richtung festzulegen, in die der Markt "gehen muss". Viele Händler halten an einem Verlustgeschäft fest, nicht zum Vorteil ihres Kontos, sondern eher um ihr Ego zu schützen. Natürlich ist es besser, sich auf den Schutz Ihres Kontos zu konzentrieren und Ihr Ego vor der Tür Ihres Handelsraums zu lassen, damit es sich nicht negativ auf Ihren Handel auswirkt.
Strategien, wenn Sie wissen, dass Sie nicht wissen
Es gibt eine Gemeinsamkeit mit Händlern, die ohne Angst handeln können. Sie bauen Verlustgeschäfte in ihren Ansatz ein. Das ist vergleichbar mit einem Gambit beim Schach und nimmt vielen Händlern den Vorteil und den starken Einfluss, den die Angst auf sie hat. Für diejenigen, die kein Schach spielen, ist ein Gambit ein Spielzug, bei dem man eine Figur von geringem Wert, z. B. einen Bauern, opfert, um einen Vorteil zu erlangen. Beim Handel könnte das Gambit Ihr erster Handel sein, der es Ihnen ermöglicht, einen besseren Eindruck von dem Vorteil zu bekommen, den Sie in dem Moment spüren, in dem der Handel eingegangen wird.
James Stanleys USD Hedge ist ein hervorragendes Beispiel für eine Strategie, die unter der Annahme funktioniert, dass ein Handel ein Verlierer sein wird. Was hat das zu bedeuten? Sie geht von einem Verlust aus und ermöglicht es Ihnen, ohne die Angst zu handeln, die so viele Händler plagt. Ein weiteres Instrument, mit dem Sie feststellen können, ob der Trend zu Ihren Gunsten oder gegen Sie verläuft, ist ein Fraktal.
Wenn Sie sich außerhalb der Welt des Handels und des Schachspiels umsehen, gibt es andere Unternehmen, die von einem Verlust ausgehen und daher in der Lage sind, mit klarem Kopf zu handeln, wenn ein Verlust eintritt. Diese Unternehmen sind Kasinos und Versicherungsgesellschaften. Beide Unternehmen gehen von einem Verlust aus und arbeiten nur im Rahmen eines kalkulierten Risikos, sie arbeiten angstfrei, und das können Sie auch, wenn Sie als Teil Ihrer Strategie von kleinen Verlusten ausgehen.
Ein weiteres großartiges Zitat von Mark Douglas:
"Je weniger ich mich darum kümmerte, ob ich falsch lag oder nicht, desto klarer wurden die Dinge, was es viel einfacher machte, in Positionen ein- und auszusteigen und meine Verluste kurz zu halten, um mich geistig für die nächste Gelegenheit bereit zu machen." -Mark Douglas
Frohes Handeln!
Die Quelle