
开发交易算法的科学方法

介绍
在金融市场中不使用适当的交易系统来交易,很可能会让交易者的资金灰飞烟灭。无论选择哪个市场,对于一个缺乏经验的交易者来说,长期结果都是一样的。获取利润是需要一个交易系统或算法的。
有很多不同的交易系统和算法,包括一类特定的数学上的盈利算法,如套利策略,高频交易,期权策略和现货符号交易衍生品。然而,所有已知的算法都有其缺点。它们要么盈利能力低,要么对流动性和订单执行速度要求很高。这就是为什么交易者试图根据独特的逻辑开发自己的算法。
通常,大多数交易算法都利用资产价格分析来预测未来的价格。其他算法不仅使用价格分析,还使用外部数据,以及考虑基本面和新闻背景,包括对谣言的分析。
问题是很少有人确切地了解如何寻找模式,哪些是有效的,哪些不是,以及为什么。为什么,在一张图表上附加了标准指标或任何其他找到的指标,他们就不能得到一个有利可图的算法。他们试图在优化器中优化策略参数以获得利润,但实际上他们只是将策略参数调整到历史的一小部分,然后在未来一段时间内蒙受损失。优化器是一个必要且有用的工具,但它应该被用来为一个有利可图的算法寻找最佳参数,而不是试图通过调整历史数据上的参数来使一个有利可图的系统从一个亏损的系统中脱颖而出。
与其他领域不同,由于竞争激烈,市场交易的发展很差。有利可图和破坏性的想法通常是保密的,不会在网上讨论。而无利可图的想法或不产生利润的想法传播得很快。这是因为,如果一个人或一群人开发了一些真正有价值的东西,他们不需要与其他人分享他们的开发成果——他们靠自己的知识赚钱。如果他们公布了自己的基本思路,这将产生竞争对手,他们也将试图攫取流动性,而流动性远不是无限的。因此,每个人谁来到算法交易必须收集任何信息从头开始,并获得自己的经验。而理解基本规则可能需要几年的时间。
由于所有这些因素,交易中的迷信比实际操作规则要多。当谈到科学方法时,它在所有领域都是相同的,允许您在开发有利可图的算法时进步更快。因此,让我们来探讨在开发交易算法的过程中,如何坚持科学的方法,避免迷信。我们将以一个简单的交易系统为例来探讨本文中的一些想法。
搜索价格模式
一个交易算法的开发应该从一个价格模式的搜索开始,这个价格模式将在交易期间提供一个正的利润数学预期。这种模式可能源于先前提出的价格假设,也可能是偶然发现的。这两种可能性在科学中经常发生:一些发明是偶然的,而另一些是长期研究的产物。在之前的文章"价格序列离散化、随机分量与噪声"中,探讨了区块图的使用方法,并说明了其使用的原因。所以,我将使用区块图,而不是烛形图。
在我之前的叫做"什么是趋势?市场结构是基于趋势还是横盘?"的文章中,我为趋势的概念制定了一个定义,并研究了市场结构是基于趋势还是横盘。我建议你阅读这篇文章,这样你就能理解更多的思路。
分析表明,大多数市场都有趋势结构,这意味着趋势延续的概率高于反转的概率。这是因为价格序列的N步增量分布密度比每一步反转概率为50%的过程的N步增量分布密度更宽、更低。图1显示了一个示例。

图 1.
在该图中,红色表示40步过程中增量概率密度的参考分布,其中下一步的反转概率等于50%。这里使用了5000个样本。白色柱状图显示了AMD股票40步的测量值(同样,5000个样本)。计算了5000次测量的垂直步数和通过40步价格的次数;结果显示为直方图。
换言之,使用40步的5000段来计算每个段垂直通过的步数,结果显示为直方图。如果我们以AMD股票(40步)为例,价格通过0个垂直步390倍;作为参考,价格必须通过626.85倍。
这张图表显示,市场价格在40个步骤中通过零垂直步骤的频率远低于下一步反转概率为50%的过程。因此,分析图表的趋势延续概率在50%以上,因此该股有可能延续趋势。换言之,在超过10点之后,价格更可能向同一方向再移动10点,而不是反转。

图 2.
图2显示了如何计算垂直步数的示例。在这里,我们计算这40个区块(步骤)的价格垂直传递了多少区块。在上图中,价格在40步中通过了7个垂直步长。然后我们分析了另外4999个样本,每个样品40步,并测量了它们的垂直运动。测量结果显示为直方图,其中X轴显示振幅,Y轴显示振幅命中数。
对发现的模式进行分析
一旦发现一种模式,就需要对其进行分析。采用其他交易品种和区块大小尺度,以了解发现的模式是否仅适用于具有特定交易工具,还是否适用于任何尺度的所有交易工具。在这个例子中,我分析了30种货币对,在俄罗斯和美国市场交易的大量股票,十几种主要的加密货币和商品交易品种。每个交易品种都使用从一个点到数千个点的块大小的所有尺度。根据分析结论,所有交易工具在任何尺度下都倾向于具有趋势性结构,但趋势性随着尺度的增大而减弱。
我们发现了以下模式:市场可能在任何尺度上都有趋势,但在更高尺度上趋势强度减弱。这意味着,在垂直通过N个点后,价格向同一方向移动相同距离的概率超过50%。这种模式的优点是,它允许使用简单的趋势策略进行交易,即在每个向上步骤后可以打开买入头寸,在每个向下步骤后打开卖出头寸。
在此基础上,对所采用的方法进行了分析。也许这不是我们发现的模式,而是市场结构分析方法中的一个错误。在这种情况下,市场没有趋势,我们无法从上述假设中产生利润。我们需要从基础开始,了解我们发现趋势的区块是如何构建的。您可以使用在之前文章 "什么是趋势,行情结构是基于趋势还是横盘?" 中所提供的区块指标,在这种情况下,价格序列是按照每N个点的方式分配("切片")的。每当价格从之前的参考点通过了N个点后,就生成一个大小为N个点的新区块。如果区块的大小是10个点,价格的变化达到10个点的时候,就生成一个含有开盘价和收盘价的区块。然后再等待价格在一个方向上移动另外10个点,以此类推。乍一看,这似乎很简单,但区块是用1分钟烛形的收盘价建造的——这在以后会很重要。

图 3.
进一步分析后会发现两个问题:
- 烛形收盘价和区块收盘价之间的差距。图3展示了一种情形,即一个下跌区块的收盘价高于下跌烛形的收盘价时,区块收盘价与烛形收盘价之间的差距抹去了我们所计划的、跟随趋势来获取的利润。原因与我们打算使用一个简单的算法有关:在每一个增长块之后开仓买入,在每一个下跌块之后开仓卖出。由于块是在烛形关闭时形成的,因此形成的块的信号将仅在烛形关闭后生成。因此,该仓位将以更坏的价格开启,这个差距可以吃掉所有的利润,预期收益将为零。
- 佣金和点差也许市场趋势只能够抵消佣金和点差。在这种情况下,如果我们按市场价开仓/平仓,以更坏的价格开仓的损失和佣金将大于使用这种模式所能产生的所有利润。嗯,我们可以在外汇市场上用限价单来消除价差,但我们还是要付佣金。此外,限价令并不能消除外汇市场的点差。
因此,已经确定了两个问题,这会阻止您从检测到的模式中产生利润。以下内容有助于理解问题对最终利润的影响:
- 在大样本上测量特定工具趋势延续的概率-这允许获得计算预期收益的准确概率值。
- 收集区块收盘价和预期持仓开盘价之间的差值的点统计数据,并找出平均值。
- 在处理市场订单或交易外汇符号时,找出平均价差并添加佣金。
- 从得到的预期收益中减去以存款货币计算的所有间接费用,并得到系统实际预期收益的预测。
- 如果得到的预期收益保持在零以上,我们可以继续下一步。
执行上述所有步骤是正确的,但一个更有趣的解决方案是编写一个简单的交易机器人并在实践中检查这一点。至少,在本文中查看现成算法的运算结果会更有趣。我们还可能遗漏了其他一些特定的功能。现在,假设我们已经计算了一切,得到了一个正面的结果,并希望创建一个基于此模式的交易算法。所以,让我们进入下一步。
开发一个假说来解释这种模式的存在
在没有解释其本质的假设的情况下使用发现的模式是危险的。我们仍然不知道这种模式为什么存在,是否稳定。我们不知道它什么时候会消失,什么时候又会出现。当投资真正的资金进行交易时,必须能够跟踪某个模式的存在,并了解存款何时从最大值长期下降并很快恢复,以及模式何时消失,是时候停止机器人了。这正是把盈利机器人和亏损机器人区分开来的时刻。这就是为什么有必要提出一个假说来解释这种模式的存在。这一假设可以进一步转化为理论,用于调整算法的运行模式。
这种模式存在于所有被分析的工具和所有的尺度中,但在更大的尺度上趋势性降低。也许,上面提到的两个因素(价差和佣金)确实影响了这种模式。因此,我们提出两个论点:
- 块大小越大,块关闭时的相对增量越小,打开/关闭仓位时的误差越小。这是因为所有的区块都是以1分钟烛形收盘价为基础的,它们的尺寸在一定范围内相当稳定。因此,块大小越大,增量越小,工具的趋势就越小。从而减小了趋势确定方法中的误差。
- 区块大小越大,价差和佣金对市场特征的影响就越小,因为价差和佣金规模相对于价格变化变得越小。由于市场是相当有效的,它可能会对这一事实作出反应,按比例减少趋势。
这里有一个小提示:即使我们在小范围内消除了价格误差,市场确实是趋势性的,但它们的趋势只足以补偿价差和佣金。剥头皮算法的开发人员经常犯错误,因为他们不知道这个事实。他们的想法是:“我需要找一个佣金较低的经纪商,我的剥头皮机器人就会开始产生利润。如果我能减少差价和佣金的话,会有很好的效果。”但事实并非如此,因为小规模的市场趋势只能涵盖差价和佣金。如果价差和佣金较小,那么其他市场参与者就已经使用了这种模式,并将其摧毁。这并不是指所有的剥头皮算法-我只是指简单的交易机器人,不使用前端运行,市场深度和成交量分析和其他工作技术。
假设不仅分析了市场,而且所有其他市场都基于趋势。但为什么所有的市场都基于趋势呢?
让我们从一个简单的问题开始:金融市场交易的利润来自哪里?由于参与者之间互相交易(即使你在场外交易外汇),你赚的钱和损失的钱加上经纪人的佣金是一样的。交易参与者相互买卖资产,每个人都在寻求利益。这意味着买卖双方都试图从交易中获得最大的利益。同时,买方认为买是有利可图的,卖方认为卖是有利可图的。其中一个明显错了吗?当买方将资产出售给第三方时,这两个机构都可以因此获利,但迟早会有一个交易对手亏损。因此,交易是基于这样一种想法,即一个交易对手在确定利润时会犯错误。
如果您不了解外汇市场的定价,我建议您首先阅读一篇题为 "莫斯科交易所衍生品市场的外汇定价原则"的文章。如果你知道基本知识,你就更容易理解这个想法。实际上,你在哪个市场交易, 如交易所、加密货币或外汇并不重要。定价的基本原理在任何地方都是一样的。但是,交易条件和分析可能性可能不同。
为了简单起见,让我们考虑价格序列形状的边界选项。价格图可能有两种相反的情况:线性无限趋势和正弦曲线。正弦曲线很方便,因为每个人都知道何时买卖资产。一个线性上升的图表也很方便:很明显,你需要不断购买才能产生利润。但这样的图表形式是不可能的,因为高点不会有买家,低点也不会有卖家。图1显示了一个当价格图表是正弦曲线,并且有适当的市场深度时的一个假定的例子。

图 4.
因此,如果价格图表是正弦曲线,那么就不会有人愿意在市场深度较低时出售资产,因为大家都知道价格不会走低。相反,每个人都会希望以最低价格购买这样的资产。由于没有人愿意出售该资产,因此不会执行任何交易,而且价格也无法沿着这样的轨迹移动。市场将开始寻找一个均衡价格,这将是适合买方购买和卖方出售。
线性上升的图表也会出现类似的情况。既然大家都知道资产价格一直在上涨,就没人会卖,如果没人卖资产,那就没人能买了。这意味着这样的价格图也是不可能的。所以,买家必须买,卖家必须卖,才能有一张价格表。一定有人在确定收益时犯了错误。然而,由于每个参与者都寻求利润最大化,并且不想犯错误,所以图表应该比正弦图更复杂,比线性升序图更复杂。
有效市场中的价格图应该在线性图和正弦图之间的中间位置。它的结构必须足够复杂,这样买卖双方的利润就不明显了。正弦图和线性图的特点是低熵。熵必须更大,以提供执行交易的可能性。市场参与者越多,他们越“聪明”,价格图表就越倾向于最大熵。
如果你考虑香农熵,那么它在均匀分布上取最大值。市场过程不是一成不变的,而是更像一个正常的过程。然而,正态分布可以从均匀分布得到,反之亦然。此外,我们使用具有固定步长的区块。换句话说,最大熵是一个没有规律的过程的特征,在这个过程中,下一个运动的方向变化概率为50%。但我们的分析表明,市场图的方向变化概率不同于50%,这意味着存在记忆,熵不是最大值。
市场将争取最大熵,但只有当参与者数量无限(流动性非常高)或参与者无限“聪明”时,才会达到这种状态。这里的“聪明”指的是确定复杂模式的能力。“更聪明”的参与者可以识别更复杂和不太明显的模式。一个无限“聪明”的参与者可以识别和利用绝对所有的模式。使用该条件(无限多个参与者或无限聪明的参与者)是因为无限多的参与者将具有无限的计算能力,并且他们将能够使用暴力识别所有模式,即使他们不是非常“聪明”。
这个假设解释了为什么金融工具价格图表变得越来越复杂。在20世纪初,人们可以通过简单地使用MA获利。现在,随着算法交易的发展,参与者变得更加“聪明”,模式变得更加复杂,熵增加,在市场上赚钱变得更加困难。“变得更聪明”是什么意思?他们有更强大的计算能力,更快的决策能力,更快更准确地确定他们的利益的能力,以及发现更复杂模式的能力。
但我们发现了一个非常简单的模式。这可以用资本不断流入市场来解释。市场参与者并没有获得全部利润,出现了一个趋势成分。资本流入与货币创造有关。各国不断发行本国货币,保持一定的通货膨胀水平。这种货币发行可能创造了趋势成分。
从解释这种模式的假设可以得出以下结论:
- 货币的不断涌出使市场成为趋势。在这种情况下,积极开发的具有高投资吸引力的资产应该比不开发的资产和投资吸引力较弱的市场具有更强的趋势结构。
- 交易品种的趋势强度将随着时间的推移而降低,因为参与者的数量增加,参与者变得“更聪明”,资产不能无限期地发展。资产的发展率和吸引力随着时间的推移而下降,尽管每种资产都是不同的。
- 发达货币对(如EURUSD)的趋势强度应低于新兴股票,因为受欢迎的货币对吸引更多参与者进行更多交易,从而增加熵。此外,货币由银行进行交易,这些银行必须进行外汇业务,并拥有大量资源来创建“智能”交易算法,以产生额外利润。此外,EURUSD等货币对具有非常高的流动性,高流动性导致趋势性下降。
假设检验
在上一节“发展一个解释这种模式存在的假设”中,我们提出一个假设只是为了解释一种模式的存在。假设并非100%正确,可能包含不准确的地方,因为这只是算法开发过程中的一个步骤。这是一个如何在解释模式时发展逻辑推理的例子。这种做法是为了尽量避免市场迷信。例如,如果我们有这样一个模式:“如果RSI(随机振荡/MACD/Elliott波/你的变型)进入超买区域并形成一个模式,然后卖出”,那么你应该问自己:“为什么这会起作用?”以及“这起作用的根本原因是什么?”
我们将粗略地检验假设,而不深入细节,同时我们需要了解结论是否与实际数据相关。我们可以比较不同交易工具的趋势性程度。根据这一假设,积极发展的、具有投资吸引力的交易工具应比发达国家或投资吸引力较弱的交易工具具有更强的趋势性。根据第二个假设,交易一项资产的参与者越多,流动性就越高,趋势性就越差。让我们简单地检查一下这个假设。
在文章“什么是趋势?市场结构是基于趋势还是横盘?”的结尾,我们比较了几种资产的趋势程度,包括EURUSD、AMD、AAPL等。让我们以4个交易品种为例进行类似的比较:
- EURUSD 货币对作为一种资产吸引了最多的参与者,因此具有较低的投资吸引力和较高的流动性。货币的投资吸引力很低,因为存在通货膨胀:货币总是贬值,长期投资于货币无利可图。
- 苹果公司的股票(AAPL)作为最具吸引力和最具发展潜力的投资工具,被大量的个人投资者交易。该股流动性高,但明显低于EURUSD。
- Sberbank(SBER)股票的流动性明显低于APPL,在全球范围内的投资吸引力也明显低于APPL,参与者数量也相应减少。
- AMEZ 股票. 它们的投资吸引力很低,流动性也很低。

图 5a.

图 5b.

图 5c.

图 5d.
从图5可以看出,欧元兑美元的趋势性程度较低=1.068,Appl股票的趋势性程度较高=1.3,Sberbank的趋势性程度为1.168,即低于Appl,但高于EURUSD。AMEZ 股票是横盘结构,它们的趋势性程度低于 1.
可以得出以下结论:高投资吸引力增加趋势性程度,高流动性和大量参与者降低交易程度的假设与实验数据并不矛盾,这意味着该假设可以在未来使用。
开发交易算法
让我们为找到的模式开发一个交易算法。模式很简单,因此交易算法也很简单。交易将以区块为基础,这意味着M1烛形图应转换为每块N点的区块图。区块构建算法将集成到交易机器人中。交易算法将直接遵循确定预期收益的公式:
m=(P(tp)*tp)-(P(sl)*sl)
其中:
- m — 计算预期收益,
- P(tp) — 盈利交易的概率,
- P(sl) — 亏损交易的概率,
- tp — 平均获利交易大小,
- sl — 平均亏损交易大小.
其工作原理如下:
- 在另一个下降或增长的块关闭后打开一个仓位;
- 如果该区块正在下跌,则打开卖出头寸;
- 如果该区块正在上涨,则开仓买入;
- 打开仓位后,等待关闭信号。
- 当形成相反方向的区块时关闭该仓位。如果买入仓位打开,等待下跌的区块形成并平仓。在下跌的区块上平仓后,可以打开卖出头寸。因此,市场上只有一个头寸。
- 图3显示了当一个烛形和一个区块以不同的价格关闭并形成价格差的情况。这与区块生成算法的具体特点有关。所以,我们需要控制价格,以避免开启仓位时出现不利的价格。我们再加一个条件:如果烛形收盘价和区块收盘价之间的差值大于某个值,就不应该开仓——等待价格回到区块收盘价,然后开仓。
- 加上获利和止损位。如果烛形的大小明显大于区块的大小,就需要它们。因此,获利/亏损的头寸不仅在区块关闭时关闭,而且在大峰值时关闭;
- 止损(SL)价格的计算如下:区块大小(BS)乘以设置的系数(ksl);对于卖出头寸:将结果SL=Bclose(op)+BS*ksl添加到生成开仓信号的区块的收盘价(Bclose(op))。对于买入头寸:从区块收盘价中减去Sl=Bclose(op)-BS*ksl;
- TP价格计算如下:区块大小(BS)乘以设定值(ktp)的系数;对于卖出头寸:从最后一个区块的收盘价(Bclose(0))中减去结果TP=Bclose(0)-BS*ktp。对于买入头寸:将Tp=Bclose(0)+BS*ktp添加到最后一个区块收盘价。与止损相比,这里我们使用每个新区块的收盘价,并在每个新区块收盘后重新计算获利。这将有助于赚取额外的利润时,烛形明显大于区块大小出现。
- 手数管理函数。除了标准的手数管理函数外,让我们添加一个函数,该功能将根据当前区块大小更改手数大小。这将允许在区块规模增长时保持稳定的风险水平和利润。让我们介绍最小块大小(minimum BS)的概念,相对于最小块大小,手数大小将进行调整。开启仓位的手数是设置中的手数除以当前块大小与设置中最小大小的比率:lot=lot(set)/(BS/minimum BS)。
- 确定区块大小。这个函数对于算法的稳定运行非常重要。有几种可能的选择:
- 在价格格式的设置中指定的固定块大小,例如0.02;
- 自动块大小,即把它关联到当前工作时间框架内烛形的大小。烛形尺寸可从ATR指标获得。然后将当前ATR值乘以系数,得到块大小。例如,我们想根据 5*ATR 大小的区块来交易。因此,随着波动性的增加,区块大小将增长,系统将适应不断变化的市场参数。如果您想进行实验,可以从当前工作时间段或更高时间段使用ATR。
- 允许开立买入/卖出头寸。让我们添加一个函数,允许分别打开买入和卖出头寸。这将使买卖信号的单独分析成为可能。
由此产生的机器人附在下面。这个机器人有更多的功能,但我们不会在本文中探讨它。
测试交易算法
算法的操作将在我们分析的那些资产上进行测试。之前,我们预测了算法应该在哪些资产上盈利。现在,让我们检查算法如何在这些资产上工作,以检查假设的正确性。
让我们用 EURUSD 进行测试。这个交易品种有一个微弱的趋势,也许,这可能不足以涵盖佣金和价差。最后的算法操作如图6a和6b所示。

图 6a.

图 6b.
测试时间为2018年1月1日至2020年7月28日,在M1时间段内,使用真实点模式进行。参数没有得到优化,因为我想说明的是,没有必要为每个货币对优化一个完全准备好的算法。我们将改变块大小,最小块大小和手数,努力使利润大大超过佣金。
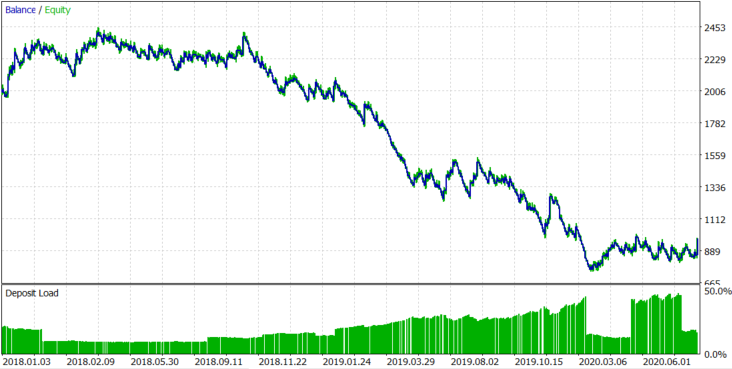
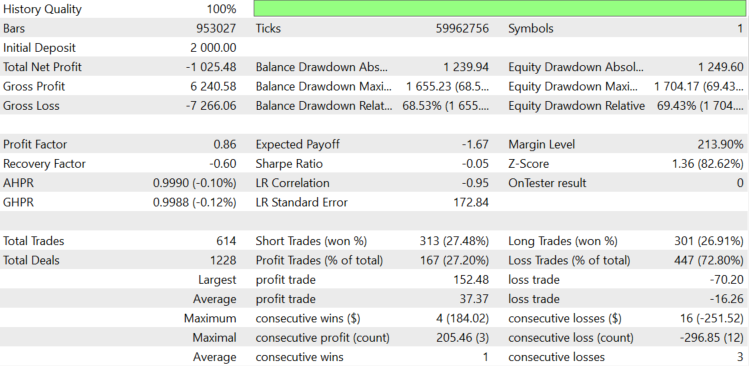
图7.
对于EURUSD,正如预期的那样,点差和价差拿走了我们本应从资产趋势中获得的所有利润。因此,预期收益为每笔交易-1.67美元。根据区块大小,手数动态变化,平均手数为0.078。让我们试着了解损失从何而来。机器人记录有关点差的信息。开盘和收盘时的平均点差为0.00008。我们支付了 $159.76 的隔夜息, 开启了 614 个仓位。所以,平均每个仓位的隔夜息是 159.76/614=$0.2602.
如果平均点差是 0.00008 而平均手数是 0.078, 1 EURUSD pip 手数为 0.078 就等于 $0.078, 所以点差使我们花费了 0.078*8=$0.624. 佣金的总计就等于 $0.624+$0.2602=$1.104。如果我们在每笔交易中都损失了佣金,那么预期的回报将是-1.104美元,但它是1.67美元,比原来多了0.566美元。在设置中,最小块大小被设置为0.002,因此平均每手0.078可以赚15.6美元。如果余额图是一个随机游走,而区块大小总是最小的,那么让我们粗略估计余额的减少。算式是 15,6*(614^0.5)=386.55$. 现在,将每笔交易的平均佣金乘以交易数量。1.104*614+386.55=$1064.406.
该值等于1064.406美元,这意味着如果头寸在正确方向打开的概率为50%,并且每个打开的头寸都支付佣金,余额图的平均回撤。实际上,我们得到了1027.45美元的亏损,接近这个价值。我们可以得出这样的结论,我们是亏损得,因为我们的算法的预期收益对于EURUSD是零。
让我们看看更具趋势的AAPL股票的结果。结果如下图8所示。
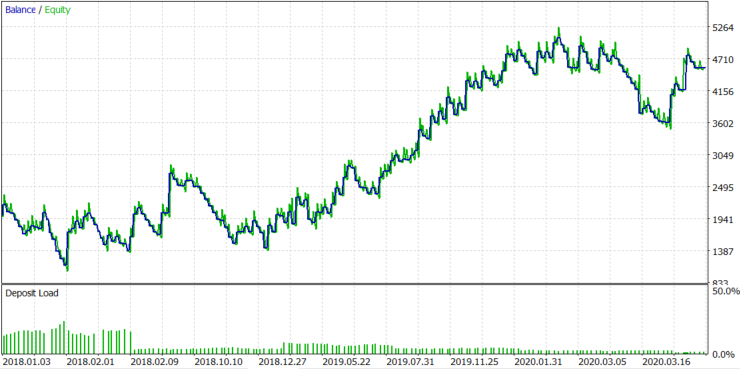
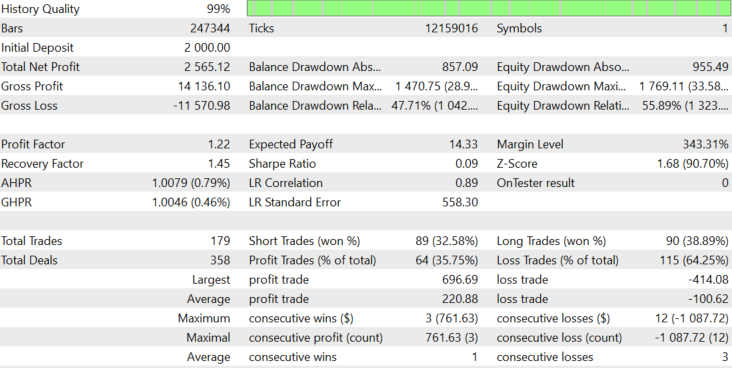
图 8.
结果稳定为正,预期收益为19.33。这是一个使用动态手数(根据块大小设置)的测试,块大小随波动性而动态变化。让我们看看如果我们不改变手数会发生什么。图8中的平均手数为39。让我们使用固定手数39并检查图9中的结果。
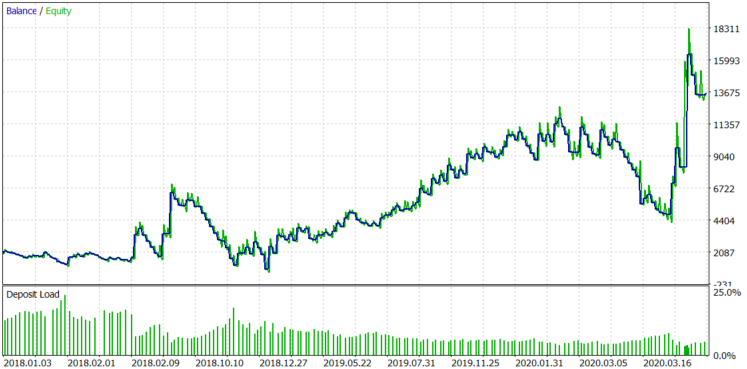
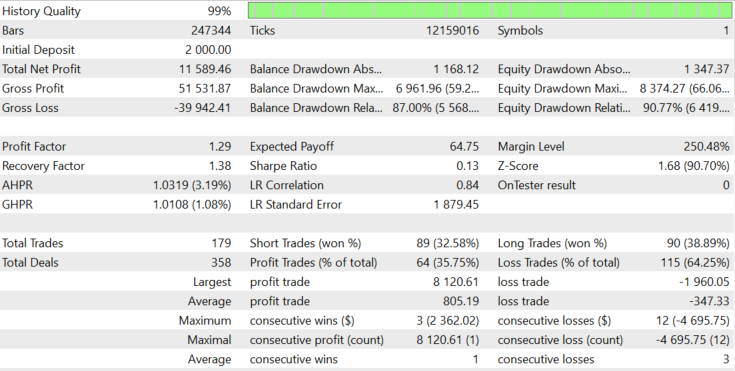
图 9.
结果并没有太大变化,除了最后一次获利交易和一些增加的资金回撤。苹果公司股票的区块规模随着时间的推移而增长,一个固定地段的较大区块可以显示出较大的利润,但减少的概率可以成比例地增加。
接下来,让我们看看如果只允许卖出头寸会发生什么。结果如图10所示。
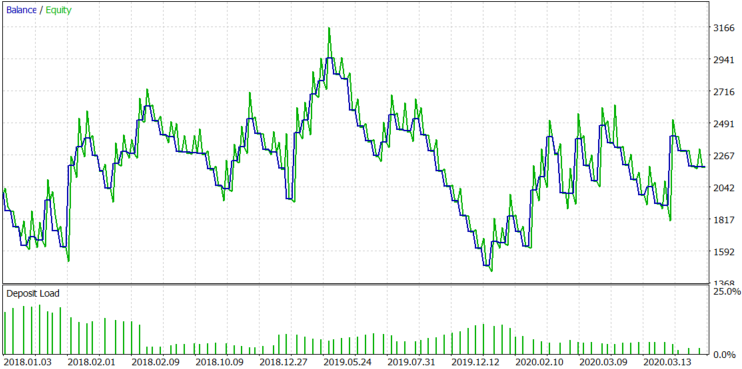
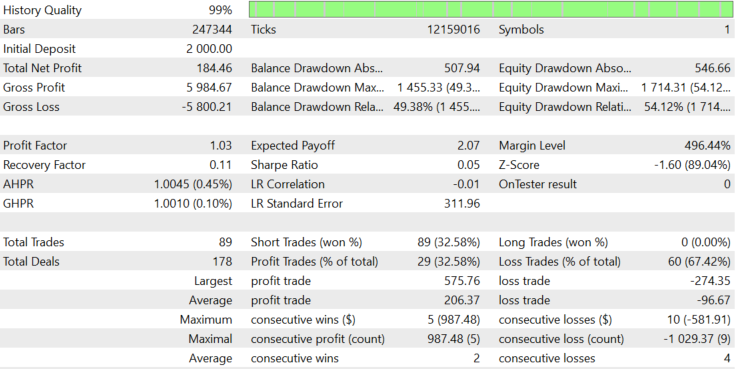
图 10.
仅售模式显示出较小的损失,但图5b显示了相对于零的分布不对称,因此这一结果是可以预期的。接下来,让我们检查只购买模式。结果如图11所示。
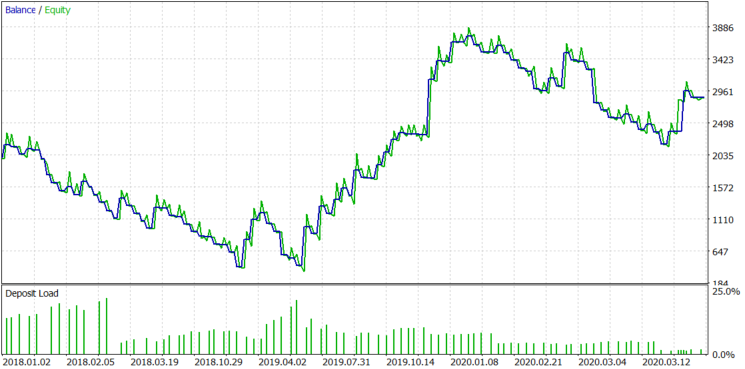
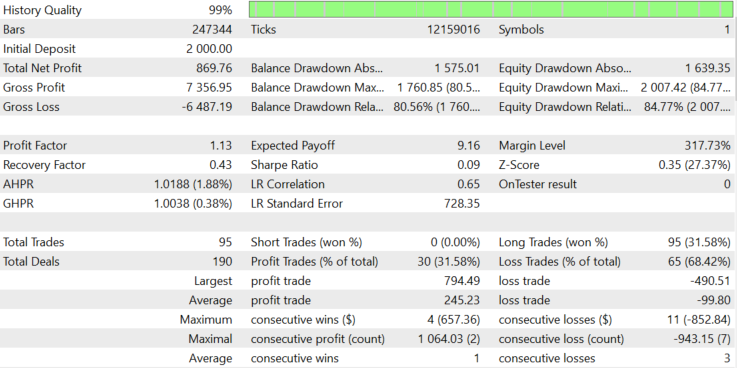
图 11.
如图11所示,只买模式显示了正面的结果,但不如买卖模式好。由于股票有交替上升和下降趋势部分,买入和卖出头寸的使用使余额图更加均衡。
让我们来看看算法是如何在其他正面发展的公司股票上工作的。让我们从 AMD 开始。测试将在2018.06.01至2020.07.28期间进行,因为经纪商提供从该日期开始的1分钟历史记录。此测试是使用动态批量与买入和卖出仓位。结果显示在图12中。
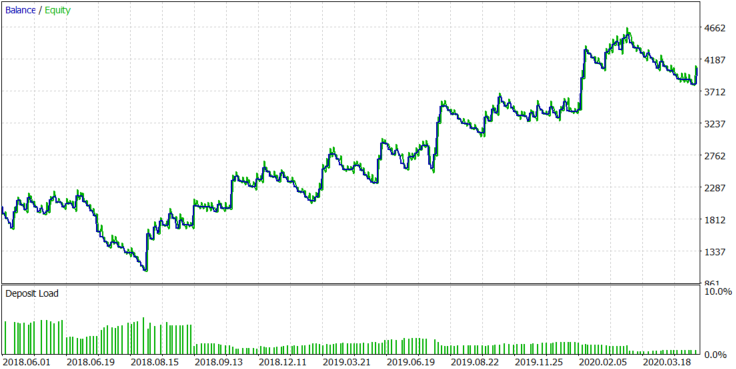
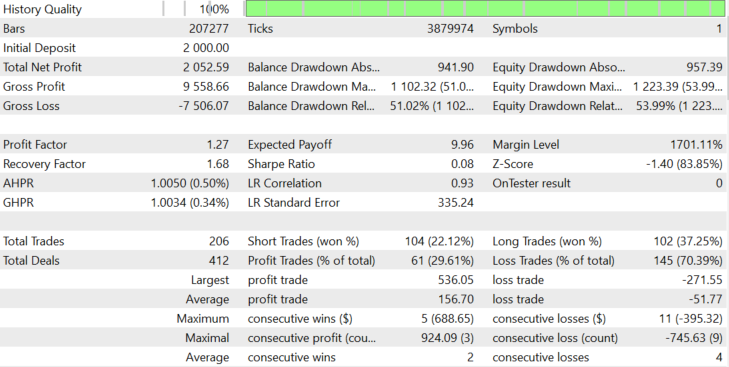
图 12.
对于AMD股票,该算法显示了一个稳定的正结果,与基于图1所示分布的假设相匹配。现在,让我们看看另一家正在积极发展的公司,特斯拉。算法显示在图13中。
图 13.
该算法对特斯拉的股票显示出稳定的结果,因为这家公司和以前的公司一样,具有很高的投资吸引力和巨大的增长潜力。
为了进行比较,让我们用俄罗斯领先企业之一的Sberbank股票来测试这个算法。显示相同的测试周期。佣金相当于Otkrytie经纪人提供的佣金=每手0.057%。测试是在没有杠杆的条件下进行的,使用了实时点模式。测试结果显示在图14中。
图 14.
尽管Sberbank不如上述资产具有吸引力,但由于流动性较低,该股仍采用如此简单的算法呈现趋势。
所有设置和测试报告都附在下面,因此您可以详细分析它们。
结论
通过分析创建的交易算法的行为可以得出以下结论:
- 所发现的模式允许我们创建一个算法,该算法能够产生利润,而无需优化每个交易工具的参数。参数是手动更改的,但是我们事先知道为什么要设置这个或那个参数。
- 通过了解参数的变化机制,我们可以制作一个全自动的算法。
- 我们清楚地知道我们使用哪种模式来产生利润,因此我们可以学习预测未来模式的增强或减弱。
- 通过使用一个假设,可以预测特定工具上是否存在某种模式。
- 市场趋势涌现假说应该得到发展,并成为描述定价规律的成熟理论。通过理论的发展,可以提高算法的稳定性、可靠性和通用性。
- 随着特定交易工具的进一步发展,这种模式将变得不那么生动。在这种情况下,一个好的解决方案是切换到新的积极发展的工具。
- 这种交易方式可以盈利,但需要改进。有必要将区块收盘价和持仓开盘价之间的差值降至最低——这种差值的出现是因为区块形成的具体情况。其中一个解决办法是转向对实时点图的分析,而不是对分钟图进行分析。
- 了解工具的平均趋势水平,就可以收集趋势度随时间变化的统计数据,并使用非线性方程对其进行近似。此外,了解趋势变化规律,可以开发一种控制偏离平均趋势的机制,以增加系统的盈利能力。
- 该算法目前的形式非常简单;它只是用来测试这个想法,但这个想法已经显示出它的可行性和潜力。因此,该算法可以在实际市场中得到有效的改进和应用。
- 股票市场比外汇市场更容易产生利润。其中一个原因是股市资产更具趋势性。但是也有些横盘的工具,例如上面的 AMEZ 例子。该算法可以进行修改,以便在此类工具上进行交易,使其工作时不期望趋势继续,而期望反转。但这是一个单独研究的主题,因为投资吸引力低的资产可能存在流动性问题。
- 该算法按市场执行交易;可以将逻辑更改为限价交易订单,以提高盈利能力。这将使逻辑复杂化,但会增加盈利能力。无论如何,还需要更多的研究和开发。
- 本文展示了应用趋势概念的一种实用方法,我在上一篇题为什么是趋势,市场结构是基于趋势还是横盘?以及文中介绍的从烛形图切换到区块图的实际应用。
价格序列离散化、随机分量与噪声.
思路以及开发的作者是Maxim Romanov, EA交易的代码是由 Sergey Chalyshev 根据先前提供的版权书写的。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/8231
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。


是的,它比 40 个街区后的价格更有用。等待的时间太长了...尤其是如果这些积木是 200-300 pts.
令人印象深刻...
关于图块:与网格非常相似。新图块有什么不同?我不建议在刻度上使用滑动条。也许只是在越过预先计算的网格水平时,在刻度线上运行 EA 的决定性部分?
它不是一个网格,区块的大小是动态的,会随着价格的变化而变化。事实证明,下一个区块的收盘价很少与前一个区块的价格重合。
是的,在这三年里,这种方法已经发生了很大变化。根据文章所述,它们是一样的。
感谢您的文章,现在很清楚市场与 SB 不同了。
感谢您的文章,现在我们终于明白, 市场毕竟不同于 SB。
我想了想其中的原因。在 200-300 点的区块中,我们可以看到 10-15 个区块后与 SB 的最大差异,即在一个方向移动 2000-4000 点后。这种价格变动很可能是由新闻形成的。
如果我们从这 10 万个例子中剔除新闻走势/区块(或者只剔除莫斯科时间 13 点到 20 点的区块,此时主要新闻发布),那么 40 个区块的结果概率很可能与 SB 更为相似。
一句话:与 SB 的主要区别之一是新闻的影响。
我想了想原因。在 200-300 点的区块中,我们可以看到 10-15 个区块后与 SB 的最大差异,即单向波动 2000-4000 点后。这种价格变动很可能是由新闻形成的。
如果我们从这 10 万个例子中剔除新闻走势/区块(或者只剔除莫斯科 13 至 20 区块,即主要新闻发布时),那么 40 个区块的结果概率很可能与 SB 更为相似。
一句话:与 SB 的主要区别之一是新闻的影响。
Maxim Romanov #:
Не в этом суть. Я нашел у рынка природную ассиметрию. У любого рынка.
是的,无论是在讨论中还是你在文章中都写道--原因就是印钞票。富人得到了更多的钱,他们把钱放在哪里呢?投资。这就是加密货币股票平均上涨的原因。
马克西姆-罗曼诺夫#:
为什么外汇交易很难赚钱?所有交易都在 0.5% 的范围内进行,市场波动性很低,不对称现象不明显。如果你印了英镑,你就必须印更多的欧元来保持平衡。关键利率等
主要货币发行国的中央银行不会在一年内让货币涨跌两次。没有或很少有位移,与 SB 的区别显然只在于新闻和其他事件引起的价格变化。在其他时候,它似乎与 SB 非常相似。