
Analisi volumetrica basata su reti neurali come chiave per i trend futuri

In un'epoca in cui il trading sta diventando sempre più automatizzato, è utile ricordare gli assiomi dei trader del passato. Uno di loro sostiene che il volume sia la chiave di tutto. In effetti, l'analisi tecnica e l'analisi volumetrica sarebbero utili e molto interessanti da inserire come caratteristiche nell'apprendimento automatico. Forse, con la giusta interpretazione, si riuscirà ad ottenere un risultato. In questo articolo, valuteremo l'approccio all'analisi del volume degli scambi e alle caratteristiche basate sul volume utilizzando l'architettura LSTM.
Il nostro sistema analizzerà le anomalie dei volumi e prevederà i futuri movimenti dei prezzi. Le caratteristiche principali del sistema che vorrei sottolineare sono il rilevamento di volumi anomali, il clustering dei volumi e l'addestramento del modello, direttamente tramite Python e MetaTrader 5
Eseguiremo inoltre backtest completi con visualizzazione dei risultati. Il modello dimostra una particolare efficienza sul timeframe orario del mercato azionario russo, come confermato dai risultati dei test sui dati storici delle azioni di Sberbank relativi all'ultimo anno. In questo articolo esaminerò in dettaglio l'architettura del sistema, i principi del suo funzionamento e i risultati pratici della sua applicazione.
Ripartizione del codice: Dai dati alle previsioni
Andiamo a fondo e cerchiamo di creare un sistema in grado di comprendere veramente le attuali dinamiche dei volumi. Cominciamo dalle cose semplici - il modo in cui riceviamo e gestiamo i dati. Da un lato, non c'è niente di complicato - basta scaricare i dati e iniziare a lavorare... Ma il diavolo, come sempre, si nasconde nei dettagli.
Fonte dei dati: approfondimento
Di seguito è riportata la nostra funzione di caricamento dei dati.
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"MT5 data request: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
Sembra piuttosto semplice. Utilizzo volutamente copy_rates_range invece del più semplice copy_rates_from. Ci occorre per non perdere i dati dei periodi nulli quando lavoriamo con strumenti a bassa liquidità.
Più avanti, iniziamo a lavorare con caratteristiche e indicatori.
Pre-elaborazione: L'arte della preparazione dei dati
Non soffermiamoci troppo sulla selezione delle caratteristiche, ma concentriamoci piuttosto su alcune delle più ovvie.
def preprocess_data(self, df): # Basic volume indicators df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # ML indicators df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
Gestire la selezione delle caratteristiche è come accordare un'orchestra. Ogni caratteristica ha il suo ruolo e il suo suono specifico nella sinfonia dei dati. Analizziamo il nostro set di base.
Il primo è il più semplice: calcoliamo una media mobile del volume. Il volume medio con un periodo di 5 intercetta le fluttuazioni più lievi, mentre quello con periodo di 20 reagisce a trend di volume molto più forti.
Potrebbe essere interessante anche il rapporto tra il volume e la sua media. Quando in seguito si verifica un brusco aumento, molto spesso segue un forte impulso di prezzo.
Analizziamo inoltre il momentum dei prezzi e dei volumi nelle ultime 24 barre.
Esiste una caratteristica ancora più interessante chiamata volatilità del volume. Chiamerei questa cosa, indicatore di nervosismo del mercato. Quando la volatilità dei volumi aumenta, può indicare ingenti afflussi di capitali nel mercato da parte di operatori importanti.
Il nostro modello tiene conto anche della correlazione tra prezzo e volume. Alla fine, guarderemo sicuramente tutti questi segnali dal vivo, visualizzando i nostri indicatori appena creati.
Collo di bottiglia nelle prestazioni
Per evitare di sovraccaricare il sistema, possiamo implementare l'elaborazione in batch dei dati e il calcolo parallelo. In altre parole, dividiamo i dati in piccole parti e li gestiamo in parallelo.
Questa semplice tecnica velocizza notevolmente l'elaborazione dei dati e contribuisce inoltre ad evitare problemi di perdita di memoria su grandi volumi di dati.
Nella prossima parte dell'articolo, parlerò della fase più interessante - come il sistema rileva i volumi anomali e cosa succede in seguito.
Alla ricerca di "cigni neri": Come riconoscere i volumi anomali?
Abbiamo tutti sentito parlare di cosa siano i volumi anomali e di come individuarli su un grafico. Forse, qualsiasi trader esperto sarebbe in grado di individuarli. Ma come possiamo integrare questa esperienza nel codice? Come formalizzare la logica di ricerca di tali volumi?
A caccia di anomalie
Dopo una serie di esperimenti, la mia ricerca in questo ambito si è orientata verso il metodo della Isolation Forest. Perché questo metodo? Certamente, i metodi classici come i z-score o i percentili possono mancare un'anomalia locale, specialmente se piccola, ma ciò che conta non sono i valori assoluti o percentuali, bensì i volumi che spiccano rispetto al resto e sono fuori dal contesto generale.
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
Certo, sarebbe meglio sperimentare con i parametri e una soluzione ancora migliore sarebbe quella di selezionare tutte le impostazioni del modello utilizzando algoritmi come BGA. Ho impostato il valore a 0.05, come raccomandato nei manuali, che corrisponde al 5% di anomalie. Ma il mercato reale è molto più rumoroso di quanto si possa immaginare. Pertanto, l'asticella si è alzata un po'. Sarà inoltre utile osservare le anomalie con i propri occhi, in relazione alle variazioni di prezzo (torneremo su questo argomento più avanti).
Clustering: Identificazione di pattern
Le anomalie da sole non bastano per fare buone previsioni. Abbiamo bisogno anche di raggruppare i volumi. Ci concentreremo sulla seguente opzione di clustering:
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
Le caratteristiche scelte per il clustering sono piuttosto semplici. Penso che sarebbe strano raggruppare solo i volumi effettivi, altrimenti a cosa servirebbe creare le nostre caratteristiche e i nostri indicatori? Tuttavia, il numero di caratteristiche, così come gli indicatori di volume, potrebbero essere migliorati.
Sono stati scelti tre cluster perché intendevo suddividere condizionatamente tutti i volumi in: volumi “di fondo o di accumulo”, volumi “di corsa e movimento” e volumi “di movimento estremo”.
Scoperte inattese
L'analisi dei dati ha rivelato diversi pattern e sequenze; ad esempio, i volumi anomali sono seguiti da un terzo gruppo di volumi, poi c'è il volume attivo, e solo dopo le quotazioni si muovono in una direzione o nell'altra.
Ciò è particolarmente evidente nelle prime ore successive all'apertura della sessione di borsa. Sarebbe utile in questo caso creare una mappa di calore dei cluster e delle relative variazioni di prezzo.
Rete neurale: Come addestrare un algoritmo a leggere il mercato
Visto che utilizzo le reti neurali da molto tempo, sarebbe ragionevole applicarne una alla nostra analisi volumetrica. Non ho ancora provato l'architettura LSTM, ma alla fine ho deciso di farlo, dopo aver visto esempi di questa architettura in altri ambiti.
Analizziamola più da vicino.
Architettura: Less is more
La semplicità è la chiave. Ho ideato un'architettura sorprendentemente semplice:
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
A prima vista, l'intera architettura appare molto primitiva, composta da soli due strati LSTM e uno strato lineare. Ma la vera forza sta nella semplicità. Perché, sfortunatamente, se costruiamo una rete più estesa con un apprendimento più profondo, incorreremo nell'overfitting. Inizialmente, ho costruito una rete molto più complessa, con tre strati LSTM, ulteriori strati completamente connessi e una complessa struttura di dropout. I risultati sono stati impressionanti... Sui dati di prova. Ma non appena la rete è entrata in contatto con il mercato reale a lungo termine, tutto è andato in fumo. In altre parole, abbiamo osservato un fenomeno di overfitting.
Lotta contro l'overfitting
L'overfitting è il problema principale delle moderne reti neurali. La rete neurale è bravissima ad individuare relazioni nei dati di test, ma si perde completamente nelle reali condizioni di mercato. Ecco come cerco di risolvere questo problema specificamente nell'architettura presentata:
- Un singolo livello non è in grado di gestire la complessità della relazione tra volume e prezzo.
- Tre strati possono trovare connessioni dove effettivamente non esistono
La dimensione dello strato nascosto viene scelta in modo standard - 64 neuroni. Potrebbe essere meglio utilizzare più neuroni. In futuro, quando presenterò una soluzione efficace per contrastare l'overfitting, potremo utilizzare un'architettura più complessa con un numero maggiore di neuroni.
Dati di input: L'arte della selezione delle caratteristiche
Analizziamo le caratteristiche di input per l'addestramento:
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
Possiamo sperimentare molto con l'insieme delle caratteristiche. Possiamo aggiungere indicatori tecnici, derivati di prezzo, derivati di volume, derivati di prezzo e di volume, tutto ciò che vogliamo. Ricorda però che un maggior numero di caratteristiche non sempre migliora la qualità delle previsioni. E ogni caratteristica apparentemente più logica potrebbe in realtà rivelarsi semplicemente rumore nei dati.
La combinazione di 'volume_cluster' e 'is_anomaly' sembra interessante in questo caso. Singolarmente, le caratteristiche sono modeste, ma nel loro insieme risultano molto interessanti. La comparsa di volumi anomali in determinati cluster ha un effetto inusuale sulle previsioni.
Un’inattesa scoperta
Il sistema si è rivelato più efficace durante i periodi in cui le oscillazioni dei prezzi sono significative. Si dimostra inoltre efficace in momenti che la maggior parte dei trader definirebbe illeggibili, ovvero nei mercati laterali e durante le fasi di consolidamento. È in questi momenti che il sistema di analisi delle anomalie e dei cluster di volume individua ciò che è inaccessibile alla nostra vista.
Nella prossima sezione, parlerò di come questo sistema si è comportato nel trading reale e condividerò esempi specifici di segnali.
Dalle previsioni al trading: Trasformare i segnali in profitti
Qualsiasi trader algoritmico lo sa: un semplice modello di previsione non è sufficiente. Deve essere sviluppata in una strategia di trading operativa. Ma come applichiamo il nostro modello nella pratica? Cerchiamo di capirlo. Nella prossima parte dell'articolo, troverete non solo teoria, ma anche applicazioni pratiche e test su operatività reale, perfezionamento dell'algoritmo e miglioramento della lotta contro l'overfitting. Per ora, però, ci limiteremo alla consueta parte teorica della nostra ricerca.
Anatomia del segnale di trading
Nello sviluppo di una strategia di trading, uno dei punti chiave è la generazione di segnali di trading. Nella mia strategia, i segnali vengono generati sulla base delle previsioni del modello che riflettono il rendimento atteso per il periodo successivo.
def backtest_prediction_strategy(self, df, lookback=24): # Generating signals based on predictions df['signal'] = 0 signal_threshold = 0.001 # Threshold 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1
Selezione della soglia del segnale
Da un lato, possiamo impostare la soglia semplicemente al di sopra di 0. In questo caso, genereremo molti segnali, ma saranno rumorosi a causa dello spread, delle commissioni e del “rumore” del mercato. Questo approccio può generare un elevato numero di falsi segnali, con conseguenze negative sull'efficacia della strategia.
Pertanto, la decisione più ragionevole sembra essere quella di innalzare la soglia di redditività prevista allo 0,1%-0,2%. Questo ci permette di eliminare la maggior parte del rumore e di ridurre l'impatto delle commissioni, poiché i segnali verranno generati solo quando sono previste variazioni significative dei prezzi.
signal_threshold = 0.001 # Threshold 0.1%
Applicazione dei segnali tenendo conto dello scostamento
Una volta generati, i segnali vengono applicati ai prezzi tenendo conto di uno scostamento temporale di 24 periodi. Ciò ci consente di tenere conto del lasso di tempo che intercorre tra l'adozione di una decisione di trading e la sua effettiva implementazione.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Uno scostamento di 24 periodi significa che il segnale, generato al momento t , viene applicato al prezzo al momento t + 24. Questo è importante perché in realtà le decisioni di trading non possono essere implementate istantaneamente. Questo approccio consente una valutazione più realistica dell'efficacia della strategia di trading.
Calcolo della profittabilità della strategia
La profittabilità della strategia si calcola come prodotto dello scostamento del segnale e della variazione di prezzo:
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Se il segnale è uguale a 1, la redditività della strategia sarà pari alla variazione di prezzo (price_change). Se il segnale è uguale a -1, la redditività della strategia sarà pari alla variazione di prezzo negativa (-price_change). Se il segnale è uguale a 0, la redditività della strategia sarà pari a zero.
Pertanto, lo scostamento dei segnali di 24 periodi ci consente di tenere conto del ritardo tra la presa di una decisione di trading e la sua implementazione, rendendo più realistica la valutazione dell'efficacia della strategia.
La giusta misura
Dopo settimane di test, ho stabilito una soglia dello 0,1%. Ecco perché:
- A questa soglia, il sistema genera segnali con una frequenza piuttosto elevata.
- Circa il 52-63% delle operazioni sono profittevoli
- Il profitto medio per operazione è circa 2,5 volte la commissione
La scoperta più insolita è che la maggior parte dei falsi segnali può anche essere concentrata in cluster temporali. Se lo desideri, puoi considerare un filtro temporale di questo tipo, ne parleremo più avanti, nella prossima parte dell'articolo.
def apply_time_filter(self, df): # We trade only during active hours trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
Gestione del Rischio
La logica dell'acquisizione delle posizioni e la logica della gestione delle operazioni aperte (supporto alle operazioni durante il trading) costituiscono una storia a parte. Da un lato, la soluzione più ovvia sarebbe quella di utilizzare stop e take fissi, ma il mercato è troppo imprevedibile e dinamico perché i limiti di perdita e di profitto possano essere descritti dalla logica formale ordinaria.
La nostra soluzione è piuttosto semplice: utilizzare la volatilità prevista per impostare dinamicamente gli stop loss.
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
Anche questo approccio necessita di ulteriori verifiche. È inoltre possibile applicare il modello di analisi del rischio VaR per selezionare gli stop e i take profit secondo questo sistema, seppur datato ma affidabile.
Scoperte inattese
Un dato interessante emerso dalla ricerca è che una serie di segnali consecutivi può prevedere movimenti di prezzo molto significativi. I problemi sorgono anche quando la volatilità media del mercato aumenta in modo eccessivo; in tal caso, la nostra soglia non è più sufficiente per un trading efficace. Come si può notare, i periodi di drawdown sul grafico sono precisamente associati ad un'elevata volatilità... Ma per noi questo non è un problema! Nella prossima sezione risolveremo ed elimineremo questo inconveniente.
Visualizzazione e registrazione: Come evitare di annegare nei dati
È inoltre molto importante non dimenticare il sistema di logging (registrazione). In generale, tutto ciò che riguarda stampe, log, output e commenti del programma è fondamentale nella fase di debug. In questo modo è possibile individuare la fonte dei problemi nel codice in modo rapido ed efficiente.
Sistema di registrazione: I dettagli contano
Il sistema di registrazione si basa su un formato semplice ma efficace:
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG)
Cosa c'è di così difficile, potreste chiedere! Ho scoperto questo formato dopo diverse esperienze frustranti in cui non riuscivo a capire perché il sistema aprisse una posizione in un determinato momento.
Ora ogni azione del sistema lascia una traccia chiara nei registri. Mi assicuro inoltre di registrare i momenti relativi ai volumi anomali:
self.logger.info(f"Abnormal volume detected: {volume:.2f}") self.logger.debug(f"Context: cluster {cluster}, volatility {volatility:.4f}")
Abbiamo bisogno anche della visualizzazione. L'esperienza del trading manuale mi ha lasciato una forte abitudine: osservare tutto visivamente, guardando i dati nello stesso modo in cui guarderesti un grafico qualsiasi. Ecco il nostro codice di visualizzazione:
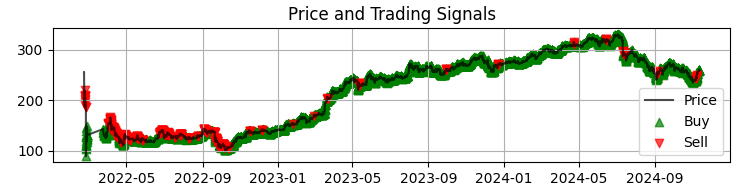
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # Price and signal chart plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Price', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Buy')
Il nostro primo grafico è il grafico più comune dei prezzi di Sber con i segnali del modello ottenuti. Integriamo inoltre i segnali evidenziando le candele che presentano volumi anomali. Questo ci aiuta a capire i momenti in cui il sistema interpreta il mercato alla perfezione, come un libro aperto.
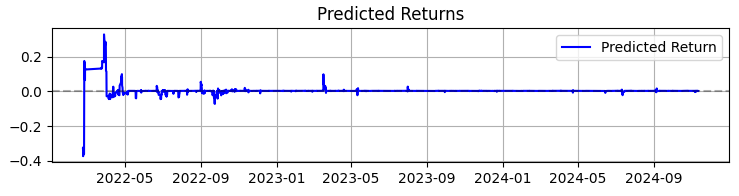
Il secondo grafico mostra il rendimento previsto. Qui possiamo vedere chiaramente che prima di forti movimenti delle quotazioni dell'asset scelto, spesso inizia una serie di previsioni molto significative. Ciò suggerisce l'idea di considerare la creazione di un sistema basato proprio su questa particolare osservazione. Certo, il numero delle transazioni diminuirà, ma non puntiamo alla quantità, bensì alla qualità, non è vero?
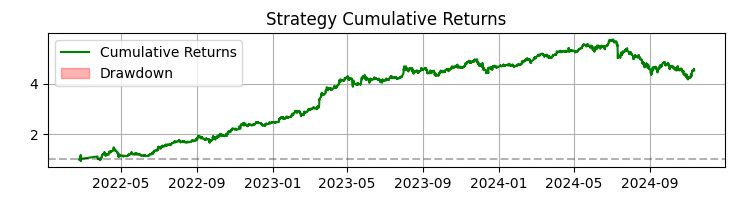
Il terzo grafico mostra il rendimento cumulativo con i periodi di drawdown evidenziati.
Dalla teoria alla pratica: Risultati e prospettive
Riassumiamo i risultati del funzionamento del sistema - non solo aridi numeri, ma scoperte che possono essere utili a chiunque sia interessato all'analisi dei volumi nel trading.
Innanzitutto, il mercato ci comunica informazioni attraverso il volume e il controvalore scambiato. Ma questa lingua è molto più complessa di quanto si possa immaginare. A mio parere, i metodi classici come il VSA stanno rapidamente diventando obsoleti, non riuscendo a tenere il passo con l'altrettanto rapido sviluppo del mercato. I pattern diventano sempre più complessi e i volumi formano schemi molto intricati, difficilmente visibili a occhio nudo.
In sintesi, in base alla mia esperienza di quasi tre anni nel campo dell’apprendimento automatico, posso riassumere brevemente che il mercato diventa ogni anno più complesso, e di conseguenza anche gli algoritmi che lo governano, in parte responsabili della formazione di trend e accumulazioni tramite il loro OrderFlow, diventano sempre più complessi. Ci attende una competizione tra modelli sempre più sofisticati, in cui si determinerà quale macchina sarà più efficiente.
Riassumendo il lavoro svolto sul sistema, vorrei condividere non solo i dati numerici, ma anche le principali scoperte che possono essere utili a chiunque si occupi di analisi volumetrica.
In oltre 365 giorni di attività sulle azioni SBER, il sistema ha mostrato risultati impressionanti:
- Rendimento Totale: 365,0% annuo (senza leva finanziaria)
- Percentuale di operazioni profittevoli: 50,73%
Ma questi numeri non sono la cosa più importante. Ancora più importante, è che il sistema si è dimostrato resiliente a diverse condizioni di mercato. Funziona altrettanto bene sia in una fase di trend che in una fase laterale, sebbene la natura dei segnali cambi sensibilmente.
Il comportamento del sistema durante i periodi di elevata volatilità si è rivelato particolarmente interessante. È proprio quando la maggior parte dei trader preferisce rimanere fuori dal mercato che la rete neurale individua i modelli più chiari nel flusso dei volumi. Forse ciò accade perché in tali momenti gli attori istituzionali lasciano "tracce" più evidenti delle loro azioni.
Cosa mi ha insegnato questo progetto- L'apprendimento automatico nel trading non è come una pillola magica. Il successo si ottiene solo con una profonda conoscenza del mercato e un'attenta progettazione delle caratteristiche.
- La semplicità è la chiave della sostenibilità. Ogni volta che cercavo di complicare il modello aggiungendo nuovi livelli o caratteristiche, il sistema diventava sempre più fragile.
- I volumi devono essere analizzati nel loro contesto. Volumi anomali o raggruppamenti di per sé significano poco. La magia inizia quando osserviamo la loro interazione con altri fattori.
E adesso?
Il sistema continua ad evolversi. Attualmente sto lavorando ad alcuni miglioramenti:
- Regolazione adattiva dei parametri in base alla fase di mercato
- Integrazione degli ordini in streaming per un'analisi più accurata
- Espansione ad altri strumenti del mercato russo
Il codice sorgente del sistema è disponibile negli allegati. Sarei lieto di ricevere suggerimenti per migliorare. Sarebbe particolarmente interessante conoscere l'esperienza di coloro che cercheranno di adattare il sistema ad altri strumenti.
Conclusioni
In conclusione, vorrei sottolineare che la scoperta più preziosa degli ultimi mesi, per me, è stata l'adattamento di approcci classici, come l'analisi volumetrica di cui abbiamo discusso oggi, a nuove tecnologie quali l'apprendimento automatico, le reti neurali e i big data.
A quanto pare, l'esperienza delle generazioni passate è ancora viva e vegeta. Il nostro compito è quello di assimilare questa esperienza, sintetizzarla e migliorarla dal punto di vista della nostra generazione di trader, utilizzando le tecnologie più recenti. E ovviamente, non possiamo restare indietro rispetto all'era moderna: l'apprendimento automatico quantistico, gli algoritmi quantistici per la previsione di prezzi e volumi, così come le caratteristiche multidimensionali per l'apprendimento automatico, ci attendono. Ho già provato ad analizzare il mercato sul supercomputer quantistico a 20 qubit di IBM. I risultati sono interessanti, ve ne parlerò sicuramente nei futuri articoli.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/16062
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.


- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso