
Construindo uma rede neural profunda do zero em linguagem MQL

Introdução
Desde que o aprendizado de máquinas ganhou popularidade recentemente, muitos ouviram falar do aprendizado profundo e desejam saber como aplicá-lo em linguagem MQL. Tenho visto implementações simples de neurônios artificiais com funções de ativação, mas nada que implemente uma verdadeira rede neural profunda. Neste artigo, vou apresentar a vocês uma rede neural profunda implementada em linguagem MQL com suas diferentes funções de ativação, entre elas estão a função tangente hiperbólica para as camadas ocultas e a função Softmax para a camada de saída. Avançaremos do primeiro passo até o final para formar completamente a rede neural profunda.
1. Criando um neurônio artificial
Vamos começar com a unidade básica de toda rede neural, o neurônio. No artigo, consideraremos as várias partes do neurônio que usaremos em nossa rede neural profunda. Estritamente falando, a diferença entre o nosso tipo de neurônio e os outros reside na função de ativação.
1.1. Partes do neurônio
O neurônio artificial, modelado a partir de um protótipo biológico, como o é um neurônio do cérebro humano, simplesmente realiza cálculos matemáticos. Como nossos neurônios, ele é acionado quando encontra estímulos suficientes. O neurônio combina os dados de entrada com um conjunto de coeficientes ou pesos que reforçam ou enfraquecem esses dados de entrada. Isto dá valor aos dados de entrada para a tarefa que o algoritmo está tentando aprender. A imagem abaixo mostra como funcionam as diferentes partes de um neurônio:

1.1.1. Dados de entrada
Os dados de entrada quer seja são um desencadeador externo proveniente do ambiente ou procedem de resultados de outros neurônios artificiais. Eles devem ser avaliados pela rede. Eles servem como "alimento" para o neurônio e passam através dele, tornando-se assim um resultado que podemos interpretar graças ao treinamento que demos ao neurônio. Eles podem ser valores discretos ou números reais.
1.1.2. Pesos
Os pesos são coeficientes que aumentam ou diminuem os valores de determinados dados. Ou seja, eles dão mais ou menos importância aos dados que entram no neurônio e, portanto, afetam as os dados de saída. O objetivo dos algoritmos de aprendizado de redes neurais é determinar o “melhor” conjunto possível de pesos para resolver determinado problema.
1.1.3. Net Input Function
Nesta parte do neurônio, os dados de entrada e os pesos são reduzidos a um valor. Nesta parte do neurônio, os dados de entrada e os pesos convergem num valor único, como a soma dos dados de entrada multiplicados por seu peso. Este resultado ou valor é passado para a função de ativação, que nos dá então as medidas de influência que o neurônio de entrada tem sobre os dados de saída da rede neural.
1.1.4. Função de ativação do neurônio
A função de ativação fornece os dados de saída da rede neural. Existem diferentes tipos de funções de ativação (Sigmoid, Tan-h, Softmax, ReLU e outros). Tal função decide se o neurônio deve ser ativado. Neste artigo, trabalharemos com dois tipos de função de ativação: Tan-h e Softmax.
1.1.5. Dados de saída
A última parte do neurônio é o resultado. Tal sinal de saída pode ser transferido - como dado de entrada - para outro neurônio ou para o ambiente externo. Este valor pode ser discreto ou real, dependendo da função de ativação utilizada.
2. Construindo uma rede neural
Uma rede neural é um paradigma de processamento de informações que funciona de forma semelhante aplicado pelos sistemas nervosos biológicos, ou seja, pelo cérebro. Ela consiste em camadas de neurônios artificiais, com cada uma delas conectada à seguinte. Isso significa que a camada anterior serve como entrada para a camada seguinte e assim por diante até a camada de saída. O objetivo da rede neural pode ser o agrupamento através do aprendizado sem a necessidade de instrutores, bem como a classificação através do aprendizado supervisionado ou através de regressão. Neste artigo vamos trabalhar na hipótese de classificarmos em três estados: BUY (compra), SELL (venda) ou HOLD (pendente). Abaixo está uma rede neural com uma camada oculta:

3. Dimensionamento de uma rede neural em uma rede neural profunda
Uma rede neural profunda se distingue das redes mais comuns que possuem uma única camada oculta pelo número de camadas que constituem sua profundidade. O facto de uma rede ter mais de três camadas (incluindo entrada e saída) é considerado de "aprendizagem profunda". Portanto, "profundo" é um termo técnico bem definido que significa ter mais de uma camada oculta. Quanto mais profundo você for na rede neural, mais complexas serão as características que seus neurônios podem reconhecer, pois agregam e recombinam as características da camada anterior. Com isso, as redes de aprendizado profundo podem manipular grandes conjuntos de dados multidimensionais com bilhões de parâmetros que passam por funções não lineares. A imagem abaixo mostra uma rede neural profunda com três camadas ocultas:

3.1. Classe de rede neural profunda
Vejamos a classe que usaremos para criar nossa rede neural. Classe de rede neural profunda - DeepNeuralNetwork. O método básico cria uma rede neural de propagação frontal 3-4-5-3 totalmente acoplada. Mais tarde, ao treinar a rede neural profunda neste artigo, mostrarei alguns exemplos dos dados fornecidos para a rede. Por enquanto, vamos nos concentrar apenas na criação da rede. A classe possui uma rede com duas camadas ocultas. Redes neurais com três ou mais camadas são muito raras. Entretanto, se você quiser criar uma rede com mais camadas, você pode fazer isso facilmente usando a estrutura apresentada neste artigo. Os pesos de entrada para a camada A são armazenados na matriz iaWeights, os pesos de camada A para camada B são armazenados na matriz abWeights, e os pesos de camada B para saída são armazenados na matriz boWeights. Como uma matriz multidimensional só pode ser estática ou dinâmica na primeira dimensão - com todas as outras dimensões sendo estáticas - o tamanho da matriz é declarado como uma variável constante usando a declaração "#define". Eu removi todas as declarações, exceto a que faz referência ao espaço de nomes do sistema de nível superior para economizar espaço. Você pode encontrar o código fonte completo nos anexos do artigo.
Estrutura do programa:
#define SIZEI 4 #define SIZEA 5 #define SIZEB 3 //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class DeepNeuralNetwork { private: int numInput; int numHiddenA; int numHiddenB; int numOutput; double inputs[]; double iaWeights[][SIZEI]; double abWeights[][SIZEA]; double boWeights[][SIZEB]; double aBiases[]; double bBiases[]; double oBiases[]; double aOutputs[]; double bOutputs[]; double outputs[]; public: DeepNeuralNetwork(int _numInput,int _numHiddenA,int _numHiddenB,int _numOutput) {...} void SetWeights(double &weights[]) {...} void ComputeOutputs(double &xValues[],double &yValues[]) {...} double HyperTanFunction(double x) {...} void Softmax(double &oSums[],double &_softOut[]) {...} }; //+------------------------------------------------------------------+
As duas camadas ocultas e a camada de saída única têm, cada uma, uma matriz de valores de viés associados, denominados aBiases, bBiases e oBiases, respectivamente. As saídas locais para as camadas ocultas são armazenadas em matrizes de escopo de classe denominadas aOutputs e bOutputs.
3.2. Computando as saídas da rede neural profunda
No início do método ComputeOutputs, são criadas matrizes temporários para armazenar valores de cálculo preliminares (antes da ativação). Em seguida, o método calcula uma soma preliminar das entradas para os nós da camada A multiplicada pelos pesos, adiciona valores de compensação e, em seguida, aplica a função de ativação. Depois disso, são calculadas as saídas locais do nível B: as saídas calculadas apenas do nível A são utilizadas como entradas locais para B. E, finalmente, é calculado o resultado final.
void ComputeOutputs(double &xValues[],double &yValues[]) { double aSums[]; // hidden A nodes sums scratch array double bSums[]; // hidden B nodes sums scratch array double oSums[]; // output nodes sums ArrayResize(aSums,numHiddenA); ArrayFill(aSums,0,numHiddenA,0); ArrayResize(bSums,numHiddenB); ArrayFill(bSums,0,numHiddenB,0); ArrayResize(oSums,numOutput); ArrayFill(oSums,0,numOutput,0); int size=ArraySize(xValues); for(int i=0; i<size;++i) // copy x-values to inputs this.inputs[i]=xValues[i]; for(int j=0; j<numHiddenA;++j) // compute sum of (ia) weights * inputs for(int i=0; i<numInput;++i) aSums[j]+=this.inputs[i]*this.iaWeights[i][j]; // note += for(int i=0; i<numHiddenA;++i) // add biases to a sums aSums[i]+=this.aBiases[i]; for(int i=0; i<numHiddenA;++i) // apply activation this.aOutputs[i]=HyperTanFunction(aSums[i]); // hard-coded for(int j=0; j<numHiddenB;++j) // compute sum of (ab) weights * a outputs = local inputs for(int i=0; i<numHiddenA;++i) bSums[j]+=aOutputs[i]*this.abWeights[i][j]; // note += for(int i=0; i<numHiddenB;++i) // add biases to b sums bSums[i]+=this.bBiases[i]; for(int i=0; i<numHiddenB;++i) // apply activation this.bOutputs[i]=HyperTanFunction(bSums[i]); // hard-coded for(int j=0; j<numOutput;++j) // compute sum of (bo) weights * b outputs = local inputs for(int i=0; i<numHiddenB;++i) oSums[j]+=bOutputs[i]*boWeights[i][j]; for(int i=0; i<numOutput;++i) // add biases to input-to-hidden sums oSums[i]+=oBiases[i]; double softOut[]; Softmax(oSums,softOut); // softmax activation does all outputs at once ArrayCopy(outputs,softOut); ArrayCopy(yValues,this.outputs); }O que acontece "nos bastidores": a rede neural usa a função de ativação tangente hiperbólica (Tan-h) ao calcular as saídas das duas camadas ocultas e a função de ativação Softmax ao calcular os valores finais de saída.
- A função Tan-h (tangente hiperbólica), como o função sigmóide é sigmóide, mas, em contraste, ela produz valores na faixa (-1, 1). Assim, entradas fortemente negativas para Tan-h resultarão em saídas negativas. Entradas zero levam a saídas próximas a zero. Mostrarei a fórmula matemática para esta função, assim como sua implementação em MQL.
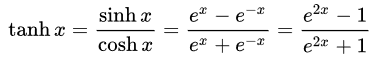
double HyperTanFunction(double x) { if(x<-20.0) return -1.0; // approximation is correct to 30 decimals else if(x > 20.0) return 1.0; else return MathTanh(x); //Use explicit formula for MQL4 (1-exp(-2*x))/(1+exp(-2*x)) }
- A função Softmax atribui probabilidades decimais a cada classe quando trabalhamos com mais de uma classe. Estas probabilidades decimais devem somar até 1,0. Esta restrição adicional permite que o aprendizado converja mais rapidamente.

void Softmax(double &oSums[],double &_softOut[]) { // determine max output sum // does all output nodes at once so scale doesn't have to be re-computed each time int size=ArraySize(oSums); double max= oSums[0]; for(int i = 0; i<size;++i) if(oSums[i]>max) max=oSums[i]; // determine scaling factor -- sum of exp(each val - max) double scale=0.0; for(int i= 0; i<size;++i) scale+= MathExp(oSums[i]-max); ArrayResize(_softOut,size); for(int i=0; i<size;++i) _softOut[i]=MathExp(oSums[i]-max)/scale; }
4. Exemplo de um EA que utiliza a classe DeepNeuralNetwork
Antes de começarmos a desenvolver nossa EA, precisamos determinar quais dados serão alimentados em nossa rede neural profunda. A rede neural é boa na classificação de padrões, por isso usaremos os valores relativos do candle como entrada. Estes são os valores para o tamanho da sombra superior, o corpo, a sombra inferior e a direção (alta ou baixa) do candle. Não é necessário limitar tanto a quantidade de dados de entrada, mas em nosso caso é o suficiente para um programa de teste.
Nosso EA de demonstração:
Uma rede neural com uma estrutura 4-4-5-3 requer apenas (4 * 4) + 4 + (4 * 5) + 5 + (5 * 3) + 3 = 63 pesos e valores de viés.
#include <DeepNeuralNetwork.mqh> int numInput=4; int numHiddenA = 4; int numHiddenB = 5; int numOutput=3; DeepNeuralNetwork dnn(numInput,numHiddenA,numHiddenB,numOutput); //--- weight & bias values input double w0=1.0; input double w1=1.0; input double w2=1.0; input double w3=1.0; input double w4=1.0; input double w5=1.0; input double w6=1.0; input double w7=1.0; input double w8=1.0; input double w9=1.0; input double w10=1.0; input double w11=1.0; input double w12=1.0; input double w13=1.0; input double w14=1.0; input double w15=1.0; input double b0=1.0; input double b1=1.0; input double b2=1.0; input double b3=1.0; input double w40=1.0; input double w41=1.0; input double w42=1.0; input double w43=1.0; input double w44=1.0; input double w45=1.0; input double w46=1.0; input double w47=1.0; input double w48=1.0; input double w49=1.0; input double w50=1.0; input double w51=1.0; input double w52=1.0; input double w53=1.0; input double w54=1.0; input double w55=1.0; input double w56=1.0; input double w57=1.0; input double w58=1.0; input double w59=1.0; input double b4=1.0; input double b5=1.0; input double b6=1.0; input double b7=1.0; input double b8=1.0; input double w60=1.0; input double w61=1.0; input double w62=1.0; input double w63=1.0; input double w64=1.0; input double w65=1.0; input double w66=1.0; input double w67=1.0; input double w68=1.0; input double w69=1.0; input double w70=1.0; input double w71=1.0; input double w72=1.0; input double w73=1.0; input double w74=1.0; input double b9=1.0; input double b10=1.0; input double b11=1.0;
Usaremos a seguinte fórmula como entrada para nossa rede, que determina qual é a porcentagem do tamanho do candle de cada uma de suas partes.

//+------------------------------------------------------------------+ //|percentage of each part of the candle respecting total size | //+------------------------------------------------------------------+ int CandlePatterns(double high,double low,double open,double close,double uod,double &xInputs[]) { double p100=high-low;//Total candle size double highPer=0; double lowPer=0; double bodyPer=0; double trend=0; if(uod>0) { highPer=high-close; lowPer=open-low; bodyPer=close-open; trend=1; } else { highPer=high-open; lowPer=close-low; bodyPer=open-close; trend=0; } if(p100==0)return(-1); xInputs[0]=highPer/p100; xInputs[1]=lowPer/p100; xInputs[2]=bodyPer/p100; xInputs[3]=trend; return(1); }
Agora podemos enviar dados para a entrada da rede neural:
MqlRates rates[]; ArraySetAsSeries(rates,true); int copied=CopyRates(_Symbol,0,1,5,rates); //Compute the percent of the upper shadow, lower shadow and body in base of sum 100% int error=CandlePatterns(rates[0].high,rates[0].low,rates[0].open,rates[0].close,rates[0].close-rates[0].open,_xValues); if(error<0)return; dnn.SetWeights(weight); double yValues[]; dnn.ComputeOutputs(_xValues,yValues);
Em seguida, a rede neural calcula a oportunidade de negociação com base nos dados recebidos. Como lembrete, a função Softmax produz 3 resultados com base em uma soma de 100%. Os valores são armazenados na matriz yValues, o sinal será um valor acima de 60%.
//--- if the output value of the neuron is mare than 60% if(yValues[0]>0.6) { if(m_Position.Select(my_symbol))//check if there is an open position { if(m_Position.PositionType()==POSITION_TYPE_SELL) m_Trade.PositionClose(my_symbol);//Close the opposite position if exists if(m_Position.PositionType()==POSITION_TYPE_BUY) return; } m_Trade.Buy(lot_size,my_symbol);//open a Long position } //--- if the output value of the neuron is mare than 60% if(yValues[1]>0.6) { if(m_Position.Select(my_symbol))//check if there is an open position { if(m_Position.PositionType()==POSITION_TYPE_BUY) m_Trade.PositionClose(my_symbol);//Close the opposite position if exists if(m_Position.PositionType()==POSITION_TYPE_SELL) return; } m_Trade.Sell(lot_size,my_symbol);//open a Short position } if(yValues[2]>0.6) { m_Trade.PositionClose(my_symbol);//close any position }
5. Treinando uma rede neural profunda por meio do otimizador de estratégia
Assim, implementamos um mecanismo de propagação direta de rede neural profunda, mas ele não realiza nenhum aprendizado. O treinamento será realizado no testador de estratégia. A seguir, mostrarei como treinar a rede neural. Observe que, devido à grande quantidade de dados de entrada e à abrangência dos parâmetros, o treinamento só pode ser feito no MetaTrader 5. Se necessário, os valores de otimização podem ser facilmente copiados para o MetaTrader 4.
Configuração do testador de estratégia:
A faixa para o treinamento de pesos e viés pode ser de -1 a 1 em passos de 0,1, 0,01 ou 0,001. Você pode experimentar estes valores e ver qual deles dá o melhor resultado. Eu usei o passo 0.001:
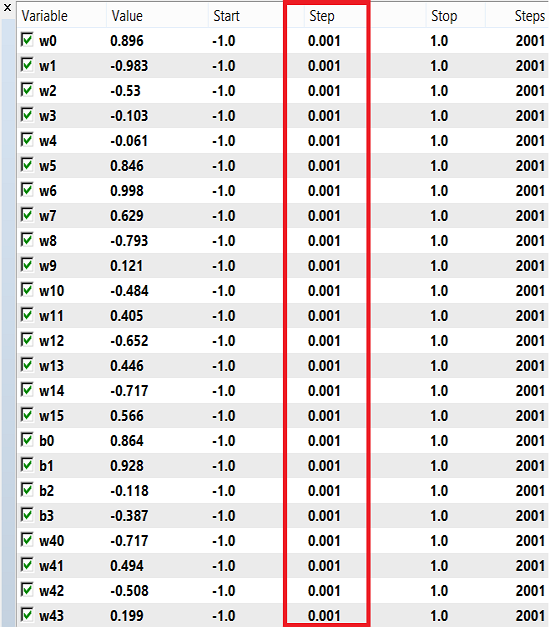
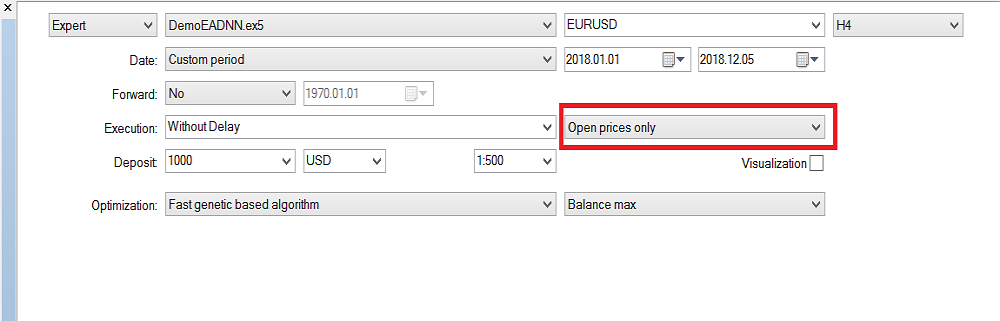
O testador é iniciado no modo "Somente preços de abertura", porque o EA funciona apenas com candles fechadas e não faz sentido verificar a cada tick. Realizei a otimização no período gráfico H4. Estes são os resultados dos testes históricos do ano passado:

Conclusão
A descrição do algoritmo e o código apresentados neste artigo podem servir como uma boa base para o entendimento de redes neurais com duas camadas ocultas. E as redes com três ou mais camadas ocultas? Existe algum consenso na literatura de pesquisa de que quase todos os problemas práticos pedem apenas duas camadas ocultas. Este artigo descreve uma abordagem para desenvolver modelos melhorados de previsão de preços usando redes neurais profundas. Tem como núcleo a capacidade de redes profundas de aprender características abstratas a partir de dados brutos. Os resultados preliminares confirmam que nossa rede profunda oferece uma precisão de previsão significativamente maior do que os modelos subjacentes para os mercados de moedas desenvolvidos.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/5486
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Deixando o gráfico mais interessante — Adicionando uma tela de fundo
Deixando o gráfico mais interessante — Adicionando uma tela de fundo
 Trabalhando com o tempo (Parte 2): funções
Trabalhando com o tempo (Parte 2): funções
 Como se tornar um bom programador (Parte 6): 9 hábitos para desenvolver de maneira produtiva
Como se tornar um bom programador (Parte 6): 9 hábitos para desenvolver de maneira produtiva
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Você conseguiu resolver o problema com entradas escalonadas mais de 4x?
Sim, comecei a investigar e cheguei ao fundo da questão. Não apenas aumentei as entradas, mas também a arquitetura: adicionei camadas, adicionei neurônios, adicionei RNN - lembrando o estado anterior e alimentando-o nas entradas, tentei alterar a função de ativação para as mais famosas, tentei todos os tipos de entradas do tópico "O que alimentar a entrada da rede neural" - sem sucesso.
Para meu grande pesar. Mas isso não me impede de voltar de tempos em tempos e distorcer redes neurais simples, inclusive a deste autor.
Tentei LSTM, BiLSTM, CNN, CNN-BiLSTM, CNN-BiLSTM-MLP, - sem sucesso.
Eu mesmo estou surpreso. Ou seja, todos os sucessos são descritos por uma observação: é um período de programação de sorte. Por exemplo, 2022 para o eurodólar é quase exatamente igual a 2021. E, treinando em 2021, você terá um avanço positivo em 2022 até novembro (ou outubro, não me lembro). Mas, assim que você treinar em 2020, qualquer rede neural(!), em 2021 ela falhará completamente. Logo no primeiro mês! E se você mudar para outros pares de moedas (geralmente eurodólares), ele também se comporta de forma aleatória.
Mas precisamos de um sistema que garanta sinais de vida no futuro após o treinamento, certo? Se começarmos com esse pensamento, ele será infrutífero. Se alguém acredita que é uma pessoa de sorte e que, após o treinamento de hoje, terá um forward lucrativo para o próximo ano ou seis meses, então boa sorte para ele).
Mas precisamos de um sistema que garanta sinais de vida no atacante após o treinamento, certo? Se partirmos desse pensamento, ele será infrutífero. Se alguém acredita que é uma pessoa de sorte e que, após o treinamento de hoje, terá um atacante lucrativo para o próximo ano ou seis meses, então boa sorte para ele).
Então, podemos supor que os parâmetros "graal" necessários do NS foram perdidos no processo de busca ou até mesmo inicialmente insignificantes e não levados em conta pelo testador? Talvez o sistema careça de fatores de eventualidade que não sejam apenas padrões-proporções.
Então podemos supor que os parâmetros necessários do "graal" NS foram perdidos no processo de busca ou até mesmo inicialmente insignificantes e não contabilizados pelo testador? Talvez o sistema careça de fatores de eventualidade que não sejam apenas padrões-proporções.
É claro que, às vezes, os conjuntos "graal" escapam durante a otimização, e é quase impossível encontrá-los (linha 150 de algum tipo durante a classificação) até que você verifique tudo. Às vezes, há dezenas de milhares deles.
Não entendi a segunda parte de sua postagem.
É claro que, às vezes, os conjuntos "grail" escapam durante a otimização, é quase impossível encontrá-los (linha 150 de algum tipo durante a classificação) até que você verifique tudo. Às vezes, há dezenas de milhares deles.
Não entendi a segunda parte de sua postagem.
Trata-se da entrada de tais dados, que são obtidos no momento de um determinado evento, por exemplo, High[0]> High[1] no momento. Se o mercado for considerado nesse contexto, ele é inteiramente um modelo orientado por eventos e correlacionado a isso. E o controle dos elementos do caos já está nos métodos de ajuste fino e otimização fora da "memória" do NS. Ele é bem representado por um indicador integral de como essas adições de eventos ao código funcionam. Esse indicador (critério integrado) melhora e se desloca em direção às passagens do otimizador mais rentáveis.