
Programmation d'un Réseau de Neurones Profond à partir de zéro à l'aide du langage MQL

Introduction
Depuis que le machine learning a récemment gagné en popularité, beaucoup ont entendu parler du Deep Learning et souhaitent savoir comment l'appliquer dans le langage MQL. J'ai vu des implémentations simples de neurones artificiels avec des fonctions d'activation, mais rien qui implémente un véritable Réseau de Neurones Profonds. Dans cet article, je vais vous présenter un Deep Neural Network implémenté dans le langage MQL avec ses différentes fonctions d'activation, comme la fonction tangente hyperbolique pour les couches cachées et la fonction Softmax pour la couche de sortie. Nous passerons de la première étape à la fin pour former complètement le Deep Neural Network.
1. Fabriquer un Neurone Artificiel
Cela commence par l'unité de base d'un réseau de neurones : un seul neurone. Dans cet article, je vais me concentrer sur les différentes parties du type de neurone que nous allons utiliser dans notre réseau de neurones profonds, bien que la plus grande différence entre les types de neurones soit généralement la fonction d'activation.
1.1. Parties d'un Neurone Simple
Le neurone artificiel, vaguement modélisé à partir d'un neurone du cerveau humain, héberge simplement les calculs mathématiques. Comme nos neurones, il se déclenche lorsqu'il rencontre suffisamment de stimuli. Le neurone combine l'entrée des données avec un ensemble de coefficients, ou pondérations, qui amplifient ou atténuent cette entrée, ce qui attribue ainsi une signification aux entrées pour la tâche que l'algorithme essaie d'apprendre. Voyez chaque partie du neurone en action dans l'image suivante :

1.1.1. Entrées
L'entrée est soit un déclencheur externe de l'environnement, soit provient des sorties d'autres neurones artificiels ; il doit être évalué par le réseau. Il sert de «nourriture» au neurone et le traverse, devenant ainsi une sortie que nous pouvons interpréter grâce à l'entraînement que nous avons donné au neurone. Il peut s'agir de valeurs discrètes ou de nombres à valeur réelle.
1.1.2. Poids
Les poids sont des facteurs qui sont multipliés par les entrées qui leur correspondent, augmentant ou diminuant leur valeur, accordant plus ou moins de sens à l'entrée entrant dans le neurone et donc à la sortie qui en sort. L'objectif des algorithmes d'apprentissage des réseaux de neurones est de déterminer le "meilleur" ensemble possible de valeurs de poids pour le problème à résoudre.
1.1.3. Fonction d'Entrée Nette
Dans cette partie du neurone, les entrées et les poids convergent en un produit à résultat unique comme la somme de la multiplication de chaque entrée par son poids. Ce résultat ou cette valeur est transmis à la fonction d'activation, qui nous donne ensuite les mesures d'influence que le neurone d'entrée a sur la sortie du réseau neuronal.
1.1.4. Fonction d'Activation
La fonction d'activation mène à la sortie. Il peut y avoir plusieurs types de fonction d'activation (Sigmoid, Tan-h, Softmax, ReLU, entre autres). Elle décide si un neurone doit être activé ou non. Cet article se concentre sur les types de fonction Tan-h et Softmax.
1.1.5. Sortie
Enfin, nous avons la sortie. Elle peut être transmise à un autre neurone ou échantillonnée par l'environnement externe. Cette valeur peut être discrète ou réelle selon la fonction d'activation utilisée.
2. Construire le Réseau de Neurones
Le réseau de neurones s'inspire des méthodes de traitement de l'information des systèmes nerveux biologiques, comme le cerveau. Il est composé de couches de neurones artificiels, chaque couche étant connectée à la suivante. Par conséquent, la couche précédente sert d'entrée à la couche suivante, et ainsi de suite jusqu'à la couche de sortie. L'objectif du réseau de neurones pourrait être le regroupement par apprentissage non supervisé, la classification par apprentissage supervisé ou la régression. Dans cet article, nous allons nous intéresser à la possibilité de classer en trois états : ACHETER, VENDRE ou CONSERVER. Ci-dessous, un réseau de neurones avec une couche cachée :

3. Passage d'un Réseau de Neurones à un Réseau de Neurones Profond
Ce qui distingue un Réseau de Neurones Profond des réseaux de neurones à couche unique cachée plus courants est le nombre de couches qui composent sa profondeur. Plus de trois couches (y compris l'entrée et la sortie) sont qualifiées d'apprentissage « profond ». Profond est donc un terme technique strictement défini qui signifie plus d'une couche cachée. Plus vous avancez dans le réseau neuronal, plus il y a de caractéristiques complexes qui peuvent être reconnues par vos neurones, car elles agrègent et recombinent les caractéristiques de la couche précédente. Il rend les réseaux d'apprentissage en profondeur capables de gérer de très grands ensembles de données de grande dimension avec des milliards de paramètres qui passent par des fonctions non linéaires. Dans l'image ci-dessous, voyez un Deep Neural Network avec 3 couches cachées :

3.1. Classe de Réseau de Neurones Profond
Regardons maintenant la classe que nous allons utiliser pour créer notre réseau de neurones. Le réseau neuronal profond est encapsulé dans une classe définie par le programme nommée DeepNeuralNetwork. La méthode principale instancie un réseau de neurones à réaction 3-4-5-3 entièrement connecté. Plus tard, dans une session de formation du réseau de neurones profonds dans cet article, je montrerai quelques exemples d'entrées pour alimenter notre réseau, mais pour l'instant nous nous concentrerons sur la création du réseau. Le réseau est codé en dur pour deux couches cachées. Les réseaux de neurones à trois couches ou plus sont très rares, mais si vous souhaitez créer un réseau avec plus de couches, vous pouvez le faire facilement en utilisant la structure présentée dans cet article. Les pondérations entrée-couche-A sont stockées dans la matrice iaWeights, les pondérations couche-A-couche-B sont stockées dans la matrice abWeights et les pondérations couche-B-sortie sont stockées dans la matrice boWeights. Puisqu'un tableau multidimensionnel ne peut être statique ou dynamique que dans la première dimension - toutes les autres dimensions étant statiques - la taille de la matrice est déclarée comme une variable constante à l'aide de l'instruction "#define". J'ai supprimé toutes les instructions using sauf celle qui fait référence à l'espace de noms System de niveau supérieur pour économiser de l'espace. Vous pouvez trouver le code source complet dans les pièces jointes de l'article.
Structuration du programme :
#define SIZEI 4 #define SIZEA 5 #define SIZEB 3 //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class DeepNeuralNetwork { private: int numInput; int numHiddenA; int numHiddenB; int numOutput; double inputs[]; double iaWeights[][SIZEI]; double abWeights[][SIZEA]; double boWeights[][SIZEB]; double aBiases[]; double bBiases[]; double oBiases[]; double aOutputs[]; double bOutputs[]; double outputs[]; public: DeepNeuralNetwork(int _numInput,int _numHiddenA,int _numHiddenB,int _numOutput) {...} void SetWeights(double &weights[]) {...} void ComputeOutputs(double &xValues[],double &yValues[]) {...} double HyperTanFunction(double x) {...} void Softmax(double &oSums[],double &_softOut[]) {...} }; //+------------------------------------------------------------------+
Les deux couches cachées et la couche de sortie unique ont chacune un tableau de valeurs de biais associées, nommées aBiases, bBiases et oBiases, respectivement. Les sorties locales des couches masquées sont stockées dans des tableaux de portée de classe nommés aOutputs et bOutputs.
3.2. Calcul des sorties du réseau neuronal profond
La méthode ComputeOutputs commence par configurer des tableaux de travail pour contenir les sommes préliminaires (avant l'activation). Ensuite, elle calcule la somme préliminaire des poids multipliée par les entrées pour les nœuds de la couche A, ajoute les valeurs de biais, puis applique la fonction d'activation. Ensuite, les sorties locales de la couche B sont calculées, en utilisant les sorties de la couche A qui viennent d'être calculées comme entrées locales et enfin, les sorties finales sont calculées.
void ComputeOutputs(double &xValues[],double &yValues[]) { double aSums[] ; // les nœuds A masqués additionnent le tableau scratch double bSums[] ; // les nœuds B cachés additionnent le tableau scratch double oSums[] ; // afficher les sommes des nœuds ArrayResize(aSums,numHiddenA); ArrayFill(aSums,0,numHiddenA,0); ArrayResize(bSums,numHiddenB); ArrayFill(bSums,0,numHiddenB,0); ArrayResize(oSums,numOutput); ArrayFill(oSums,0,numOutput,0); int size=ArraySize(xValues); for(int i=0; i<size;++i) // copie les valeurs x dans les entrées this.inputs[i]=xValues[i]; for(int j=0; j<numHiddenA;++j) // calcule la somme des poids (ia) * entrées for(int i=0; i<numInput;++i) aSums[j]+=this.inputs[i]*this.iaWeights[i][j]; // note += for(int i=0; i<numHiddenA;++i) // ajoute les biais aux sommes aSums[i]+=this.aBiases[i]; for(int i=0; i<numHiddenA;++i) // applique l'activation this.aOutputs[i]=HyperTanFunction(aSums[i]); // codé en dur for(int j=0; j<numHiddenB;++j) // calcule la somme des poids de (ab) * sorties de a = entrées locales for(int i=0; i<numHiddenA;++i) bSums[j]+=aOutputs[i]*this.abWeights[i][j]; // note += for(int i=0; i<numHiddenB;++i) // ajoute les biais aux sommes de b bSums[i]+=this.bBiases[i]; for(int i=0; i<numHiddenB;++i) // applique l'activation this.bOutputs[i]=HyperTanFunction(bSums[i]); // codé en dur for(int j=0; j<numOutput;++j) // calcule la somme des (bo) poids * b sorties = entrées locales for(int i=0; i<numHiddenB;++i) oSums[j]+=bOutputs[i]*boWeights[i][j]; for(int i=0; i<numOutput;++i) // ajoute les biais aux sommes entrées-cachées oSums[i]+=oBiases[i]; double softOut[]; Softmax(oSums,softOut); // l'activation softmax effectue toutes les sorties en même temps pour plus d'efficacité ArrayCopy(outputs,softOut); ArrayCopy(yValues,this.outputs); }Dans les coulisses, le réseau de neurones utilise la fonction d'activation de tangente hyperbolique (Tan-h) lors du calcul des sorties des deux couches cachées, et la fonction d'activation Softmax lors du calcul des valeurs de sortie finales.
- Tangente hyperbolique (Tan-h) : Comme la sigmoïde logistique, la fonction Tan-h est également sigmoïde, mais génère à la place des valeurs comprises entre (-1, 1). Ainsi, les entrées fortement négatives du Tan-h seront mappées sur les sorties négatives. De plus, seules les entrées de valeur nulle sont mappées sur des sorties proches de zéro. Dans ce cas, je montrerai la formule mathématique mais aussi son implémentation dans le code source MQL.
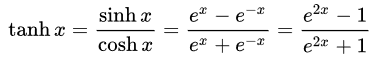
double HyperTanFunction(double x) { if(x<-20.0) return -1.0; // l'approximation est correcte à 30 décimales else if(x > 20.0) return 1.0; else return MathTanh(x); // Utilise une formule explicite pour MQL4 (1-exp(-2*x))/(1+exp(-2*x))< }
- Softmax : attribue des probabilités décimales à chaque classe dans le cas de plusieurs classes. Ces probabilités décimales doivent ajouter 1,0. Cette restriction supplémentaire permet à la formation de converger plus rapidement.

void Softmax(double &oSums[],double &_softOut[]) { // détermine que la somme max en sortie // effectue tous les noeuds en sortie en une seule fois, pour ne pas recalculer les échelles à chaque fois int size=ArraySize(oSums); double max= oSums[0]; for(int i = 0; i<size;++i) if(oSums[i]>max) max=oSums[i]; // détermine le facteur d'échelle -- somme de exp(chaque val - max) double scale=0.0; for(int i= 0; i<size;++i) scale+= MathExp(oSums[i]-max); ArrayResize(_softOut,size); for(int i=0; i<size;++i) _softOut[i]=MathExp(oSums[i]-max)/scale; }
4. Demo Expert Advisor utilisant la classe DeepNeuralNetwork
Avant de commencer à développer l'Expert Advisor, nous devons définir les données qui seront transmises à notre Deep Neural Network. Puisqu'un réseau de neurones est bon pour classer les modèles, nous allons utiliser les valeurs relatives d'une bougie japonaise comme entrée. Ces valeurs seraient la taille de l'ombre supérieure, du corps, de l'ombre inférieure et de la direction de la bougie (haussière ou baissière). Le nombre d'entrées ne doit pas nécessairement être petit mais dans ce cas, il suffira comme programme de test.
L'Expert Advisor de démo :
Un réseau de neurones de structure 4-4-5-3 nécessite un total de (4 * 4) + 4 + (4 * 5) + 5 + (5 * 3) + 3 = 63 poids et valeurs de biais.
#include <DeepNeuralNetwork.mqh> int numInput=4; int numHiddenA = 4; int numHiddenB = 5; int numOutput=3; DeepNeuralNetwork dnn(numInput,numHiddenA,numHiddenB,numOutput); //--- weight & bias values input double w0=1.0; input double w1=1.0; input double w2=1.0; input double w3=1.0; input double w4=1.0; input double w5=1.0; input double w6=1.0; input double w7=1.0; input double w8=1.0; input double w9=1.0; input double w10=1.0; input double w11=1.0; input double w12=1.0; input double w13=1.0; input double w14=1.0; input double w15=1.0; input double b0=1.0; input double b1=1.0; input double b2=1.0; input double b3=1.0; input double w40=1.0; input double w41=1.0; input double w42=1.0; input double w43=1.0; input double w44=1.0; input double w45=1.0; input double w46=1.0; input double w47=1.0; input double w48=1.0; input double w49=1.0; input double w50=1.0; input double w51=1.0; input double w52=1.0; input double w53=1.0; input double w54=1.0; input double w55=1.0; input double w56=1.0; input double w57=1.0; input double w58=1.0; input double w59=1.0; input double b4=1.0; input double b5=1.0; input double b6=1.0; input double b7=1.0; input double b8=1.0; input double w60=1.0; input double w61=1.0; input double w62=1.0; input double w63=1.0; input double w64=1.0; input double w65=1.0; input double w66=1.0; input double w67=1.0; input double w68=1.0; input double w69=1.0; input double w70=1.0; input double w71=1.0; input double w72=1.0; input double w73=1.0; input double w74=1.0; input double b9=1.0; input double b10=1.0; input double b11=1.0;
Pour les entrées de notre réseau de neurones, nous utiliserons la formule suivante pour déterminer quel pourcentage représente chaque partie de la bougie, en respectant le total de sa taille.

//+------------------------------------------------------------------+ //| Pourcentage de chaque partie de la bougie par rapport à la taille totale | //+------------------------------------------------------------------+ int CandlePatterns(double high,double low,double open,double close,double uod,double &xInputs[]) { double p100=high-low;// Taille totale de la bougie double highPer=0; double lowPer=0; double bodyPer=0; double trend=0; if(uod>0) { highPer=high-close; lowPer=open-low; bodyPer=close-open; trend=1; } else { highPer=high-open; lowPer=close-low; bodyPer=open-close; trend=0; } if(p100==0)return(-1); xInputs[0]=highPer/p100; xInputs[1]=lowPer/p100; xInputs[2]=bodyPer/p100; xInputs[3]=trend; return(1); }
Nous pouvons maintenant traiter les entrées via notre réseau de neurones :
MqlRates rates[]; ArraySetAsSeries(rates,true); int copied=CopyRates(_Symbol,0,1,5,rates); // Calcule le pourcentage de l'ombre supérieure, de l'ombre inférieure et du corps en base de somme 100% int error=CandlePatterns(rates[0].high,rates[0].low,rates[0].open,rates[0].close,rates[0].close-rates[0].open,_xValues); if(error<0)return; dnn.SetWeights(weight); double yValues[]; dnn.ComputeOutputs(_xValues,yValues);
Maintenant, l'opportunité de trading est traitée sur la base du calcul du réseau neuronal. N'oubliez pas que la fonction Softmax produira 3 sorties basées sur la somme de 100%. Les valeurs sont stockées sur le tableau "yValues" et la valeur avec un nombre supérieur à 60% sera exécutée.
//--- si la valeur de sortie du neurone est supérieure à 60% if(yValues[0]>0.6) { if(m_Position.Select(my_symbol))// vérifie s'il y a une position ouverte { if(m_Position.PositionType()==POSITION_TYPE_SELL) m_Trade.PositionClose(my_symbol);// Ferme la position opposée si elle existe if(m_Position.PositionType()==POSITION_TYPE_BUY) return; } m_Trade.Buy(lot_size,my_symbol);// ouvre une position Longue } //--- si la valeur de sortie du neurone est supérieure à 60% if(yValues[1]>0.6) { if(m_Position.Select(my_symbol))// vérifie s'il y a une position ouverte { if(m_Position.PositionType()==POSITION_TYPE_BUY) m_Trade.PositionClose(my_symbol);// Ferme la position opposée si elle existe if(m_Position.PositionType()==POSITION_TYPE_SELL) return; } m_Trade.Sell(lot_size,my_symbol);// ouvre une position Courte } if(yValues[2]>0.6) { m_Trade.PositionClose(my_symbol);//close any position }
5. Entraînement du Deep Neural Network à l'aide de l'optimisation de la stratégie
Comme vous l'avez peut-être remarqué, seul le mécanisme de feed-forward du réseau neuronal profond a été implémenté, et il n'effectue aucun entraînement. Cette tâche est réservée au testeur de stratégie. Ci-dessous, je vous montre comment entraîner le réseau de neurones. Gardez à l'esprit qu'en raison d'un grand nombre d'entrées et de la gamme de paramètres d'entraînement, il ne peut être entraîné que dans MetaTrader 5, mais une fois les valeurs d'optimisation obtenues, il peut facilement être copié dans MetaTrader 4.
La configuration du testeur de stratégie :
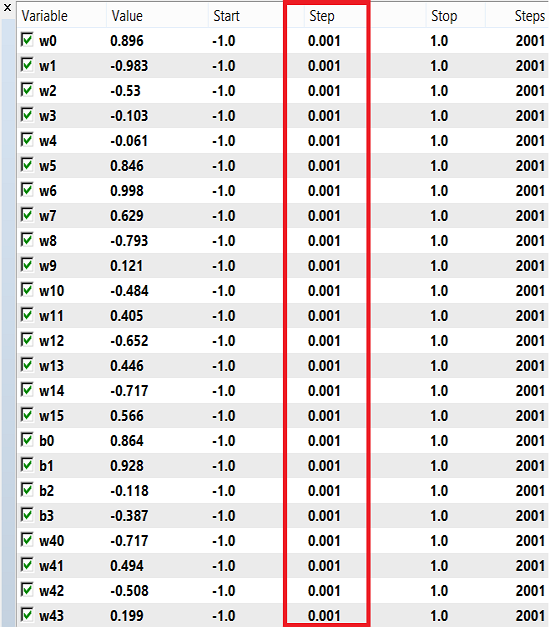
Les pondérations et les biais peuvent utiliser une plage de nombres pour la formation, de -1 à 1 et un pas de 0,1, 0,01 ou 0,001. Vous pouvez essayer ces valeurs et voir laquelle obtient le meilleur résultat. Dans mon cas, j'ai utilisé 0,001 pour l'étape comme indiqué dans l'image ci-dessous :
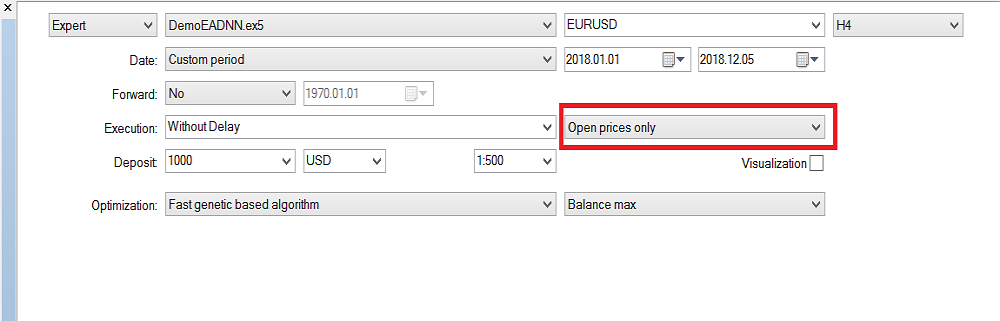
Veuillez noter que j'ai utilisé "Prix d'Ouverture uniquement" parce que j'utilise la dernière bougie fermée, donc cela ne vaut pas la peine de l'exécuter à chaque tick. Maintenant, j'ai exécuté l'optimisation sur la période H4 et l'année dernière, j'ai obtenu ce résultat sur le backtest :

Conclusion
Le code et l'explication présentés dans cet article devraient vous donner une bonne base pour comprendre les réseaux de neurones à deux couches cachées. Qu'en est-il de trois couches cachées ou plus ? Le consensus dans la littérature de recherche est que deux couches cachées suffisent pour presque tous les problèmes pratiques. Cet article décrit une approche pour développer des modèles améliorés de prédiction des taux de change à l'aide de réseaux de neurones profonds, motivés par la capacité des réseaux profonds à apprendre des caractéristiques abstraites à partir de données brutes. Les résultats préliminaires confirment que notre réseau profond produit une précision prédictive nettement supérieure à celle des modèles de base pour les marchés des changes développés.
Traduit de l’anglais par MetaQuotes Ltd.
Article original : https://www.mql5.com/en/articles/5486
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Apprenez Pourquoi et Comment Concevoir Votre Système de Trading Algorithmique
Apprenez Pourquoi et Comment Concevoir Votre Système de Trading Algorithmique
 Better Programmer (Part 07): Notes pour devenir un développeur indépendant prospère
Better Programmer (Part 07): Notes pour devenir un développeur indépendant prospère
 Développer un Expert Advisor de trading à partir de zéro
Développer un Expert Advisor de trading à partir de zéro
 Better Programmer (Part 06) : 9 habitudes qui mènent à un codage efficace
Better Programmer (Part 06) : 9 habitudes qui mènent à un codage efficace
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Avez-vous pu résoudre le problème avec des entrées dont l'échelle est supérieure à 4 fois ?
Oui, j'ai commencé à fouiller et j'ai trouvé le fond du problème. J'ai non seulement augmenté les entrées, mais aussi l'architecture : j'ai ajouté des couches, des neurones, des RNN - qui se souviennent de l'état précédent et le transmettent aux entrées, j'ai essayé de changer la fonction d'activation pour les plus célèbres, j'ai essayé toutes sortes d'entrées à partir de la rubrique "What to feed to the neural network input" - en vain.
À mon grand regret. Mais cela ne m'empêche pas de revenir de temps en temps et de tordre des réseaux neuronaux simples, y compris celui de cet auteur.
J'ai essayé LSTM, BiLSTM, CNN, CNN-BiLSTM, CNN-BiLSTM-MLP, - en vain.
Je suis moi-même stupéfait. C'est-à-dire que tous les succès sont décrits par une observation : il s'agit d'une période de calendrier chanceuse. Par exemple, 2022 pour l'eurodollar est presque exactement la même chose que 2021. Et en vous entraînant sur 2021, vous obtiendrez un forward positif sur 2022 jusqu'en novembre (ou octobre, je ne me souviens plus). Mais, dès que vous entraînez sur 2020, n'importe quel( !) réseau neuronal, alors sur 2021 il échoue proprement. Dès le premier mois ! Et si vous passez à d'autres paires de devises (généralement l'eurodollar), le comportement est également aléatoire.
Mais nous avons besoin d'un système qui soit garanti de montrer des signes de vie à terme après l'entraînement, n'est-ce pas ? Si nous partons de cette idée, c'est peine perdue. Si quelqu'un croit qu'il est une personne chanceuse et qu'après la formation d'aujourd'hui, il aura un forward rentable pour l'année ou les six mois à venir, alors bonne chance à lui).
Mais nous avons besoin d'un système qui est garanti de montrer des signes de vie sur l'avant après la formation, n'est-ce pas ? Si nous partons de cette idée, c'est peine perdue. Si quelqu'un pense qu'il a de la chance et qu'après l'entraînement d'aujourd'hui, il aura un attaquant rentable pour l'année ou les six mois à venir, alors bonne chance à lui).
Nous pouvons donc supposer que les paramètres "Graal" nécessaires de NS ont été oubliés au cours du processus de recherche ou même qu'ils étaient initialement insignifiants et n'ont pas été pris en compte par le testeur ? Peut-être le système manque-t-il de facteurs d'éventualité plutôt que de simples modèles-proportions.
Nous pouvons donc supposer que les paramètres "graal" NS nécessaires ont été oubliés au cours de leur recherche ou même qu'ils étaient initialement insignifiants et n'ont pas été pris en compte par le testeur ? Peut-être le système manque-t-il de facteurs d'éventualité plutôt que de simples modèles-proportions.
Bien sûr, il arrive que des ensembles "graal" échappent à l'optimisation ; il est presque impossible de les trouver (ligne 150 ou autre lors du tri) tant que l'on n'a pas tout vérifié. Il y en a parfois des dizaines de milliers.
Je ne comprends pas la deuxième partie de votre message.
Bien sûr, il arrive que des ensembles "graal" échappent à l'optimisation, il est presque impossible de les trouver (ligne 150 en quelque sorte lors du tri) tant qu'on n'a pas tout vérifié. Il y en a parfois des dizaines de milliers.
Je ne comprends pas la deuxième partie de votre message.
Il s'agit de l'entrée de ces données, qui sont obtenues au moment d'un certain événement, par exemple, High[0]> High[1] à ce moment-là. Si l'on considère le marché dans ce contexte, il s'agit entièrement d'un modèle axé sur les événements et corrélé à ceux-ci. Et le contrôle des éléments de chaos est déjà aux méthodes de réglage fin et d'optimisation en dehors de la "mémoire" du NS. Il est bien représenté par un indicateur intégral de la manière dont ces ajouts d'événements au code fonctionnent. Cet indicateur (critère intégré) s'améliore et s'oriente vers les passes d'optimisation les plus rentables.