
Пишем глубокую нейронную сеть с нуля на языке MQL

Введение
Машинное обучение становится все более популярным, и многие наверняка слышали о глубоком обучении. Интересно узнать, как использовать такое обучение в языке MQL. Существуют простые реализации искусственных нейронов с функциями активации, но я пока не встречал ничего, что бы реализовало настоящую глубокую нейросеть. Статья познакомит вас с глубокой нейронной сетью, написанной на MQL, и с различными функциями активации этой сети, такими как функция гиперболического тангенса для скрытых слоев и Softmax для выходного слоя. Мы будем изучать нейросеть постепенно, двигаясь от первого шага до последнего, и вместе создадим глубокую нейронную сеть.
1. Создание искусственного нейрона
Начнем с базовой единицы нейросети — нейрона. В статье мы будем рассматривать различные части того типа нейрона, которые будем использовать в нашей глубокой нейросети. Строго говоря, отличие нашего типа нейрона от других заключается в одной части — функции активации.
1.1. Части нейрона
Искусственный нейрон, смоделированный на основе биологического прототипа — нейрона человеческого мозга — просто выполняет математические вычисления. Как и наши нейроны, он срабатывает, когда сталкивается с достаточным количеством раздражителей. Нейрон комбинирует входные данные с набором коэффициентов или весов, которые либо усиливают, либо ослабляют эти входные данные. Таким образом придается значимость входным данным для задачи, которую пытается обучить алгоритм. На изображении ниже показано, как работают различные части нейрона:

1.1.1. Входные данные
Данные, подаваемые на вход нейрона, являются либо внешним триггером из окружающей среды, либо исходят от выходов других искусственных нейронов. Входные данные служат «пищей» для нейрона и проходят через него. Из них генерируются выходные данные, которые можно интерпретировать в соответствие с обучением, которое получил нейрон. Это могут быть дискретные значения или действительные числа.
1.1.2. Веса
Веса — это коэффициенты, которые увеличивают или уменьшают значения определенных данных. То есть они придают большее или меньшее значение входным данным, поступающим внутрь нейрона, и, следовательно, влияют на выходные данные. Цель алгоритмов обучения нейросети — определить «наилучший» возможный набор значений весов для решения задачи.
1.1.3. Net Input Function
В этой части нейрона входные данные и веса сводятся в одно значение. Здесь вычисляется сумма входных данных, помноженных на соответствующие веса. Далее полученный результат передается в функцию активации, которая затем измеряет и выдает влияние входных нейронов на выходные данные нейронной сети.
1.1.4. Функция активации нейрона
Функция активации дает выходные данные нейросети. Есть разные типы функций активации (Sigmoid, Tan-h, Softmax, ReLU и другие). Такая функция решает, нужно ли активировать нейрон. В этой статье мы будем работать с двумя типами функции активации: Tan-h и Softmax.
1.1.5. Выход
Последняя часть нейрона — это выход. Такой выходной сигнал можно передать на вход другому нейрону или во внешнюю среду. Это может быть дискретное или действительное значение, в зависимости от используемой функции активации.
2. Построение нейронной сети
Нейронная сеть — это парадигма обработки информации, схожая с принципами обработки информации биологическими нервными системами, такими как мозг. Она состоит из слоев искусственных нейронов, при этом каждый слой соединен со следующим. Следовательно, предыдущий слой служит входом для следующего слоя и так далее до выходного слоя. Целью нейронной сети может быть кластеризация посредством обучения без учителя, классификация через обучение с учителем или регрессию. В этой статье мы будем работать над возможностью классификации по трем состояниям: BUY (покупка), SELL (продажа) или HOLD (ожидание). Ниже показана нейросеть с одним скрытым слоем:

3. Масштабирование нейронной сети в глубокую нейросеть
Глубокую нейросеть от более распространенных сетей с одним скрытым слоем отличает количество слоев, составляющих ее глубину. Если в сети более трех слоев (включая входной и выходной), такой случай рассматривается как "глубокое обучение". Таким образом, «глубокий» — это четко определенный технический термин, означающий наличие более чем одного скрытого слоя. Чем глубже вы продвигаетесь в нейронной сети, тем более сложные характеристики могут распознать ваши нейроны, поскольку они агрегируют и рекомбинируют характеристики из предыдущего слоя. Благодаря этому сети глубокого обучения могут обрабатывать очень большие многомерные наборы данных с миллиардами параметров, которые проходят через нелинейные функции. На изображении ниже показана глубокая нейронная сеть с тремя скрытыми слоями:

3.1. Класс глубокой нейросети
Рассмотрим класс, который будем использовать для создания нашей нейронной сети. Класс глубокой нейронной сети — DeepNeuralNetwork. Основной метод создает полностью связанную нейронную сеть прямого распространения 3-4-5-3. Позже, при обучении глубокой нейросети в этой статье, я покажу несколько примеров данных, подаваемых на вход в сеть. Сейчас же остановимся только на создании сети. В классе прописана сеть с двумя скрытыми слоями. Нейронные сети с тремя и более слоями встречаются очень редко. Однако если вы хотите создать сеть с большим количеством слоев, это легко можно сделать с помощью структуры, представленной в этой статье. Веса от входа в слой A хранятся в матрице iaWeights, веса от слоя A к слою B хранятся в матрице abWeights, а веса от слоя B к выходному хранятся в матрице boWeights. Поскольку многомерный массив может быть статическим или динамическим только для первого измерения, тогда как все остальные измерения статические, размер матрицы нужно указать в объявлении матрицы через директиву "#define". Ниже я удалил все другие используемые объявления, чтобы сэкономить место. Полную версию можно посмотреть в приложенных к статье файлах.
Структура программы:
#define SIZEI 4 #define SIZEA 5 #define SIZEB 3 //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class DeepNeuralNetwork { private: int numInput; int numHiddenA; int numHiddenB; int numOutput; double inputs[]; double iaWeights[][SIZEI]; double abWeights[][SIZEA]; double boWeights[][SIZEB]; double aBiases[]; double bBiases[]; double oBiases[]; double aOutputs[]; double bOutputs[]; double outputs[]; public: DeepNeuralNetwork(int _numInput,int _numHiddenA,int _numHiddenB,int _numOutput) {...} void SetWeights(double &weights[]) {...} void ComputeOutputs(double &xValues[],double &yValues[]) {...} double HyperTanFunction(double x) {...} void Softmax(double &oSums[],double &_softOut[]) {...} }; //+------------------------------------------------------------------+
Для каждого из двух скрытых слоев и для выходного слоя есть массив связанных значений смещения, названных aBiases, bBiases и oBiases соответственно. Локальные выходы для скрытых слоев хранятся в массивах класса aOutputs и bOutputs.
3.2. Вычисление выходов глубокой нейронной сети
В начале метода ComputeOutputs создаются временные массивы для хранения предварительных значений расчетов (до активации). Затем метод вычисляет предварительную сумму входные данные для узлов слоя A, умноженных на веса, добавляет значения смещения, а потом применяет функцию активации. После этого вычисляются локальные выходы уровня B: только что вычисленные выходы из уровня A используются в качестве локальных входов в B. И, наконец, вычисляются окончательные выходные данные.
void ComputeOutputs(double &xValues[],double &yValues[]) { double aSums[]; // скрытые узлы A суммируют временный массив double bSums[]; // скрытые узлы B суммируют временный массив double oSums[]; // вывод суммы узлов ArrayResize(aSums,numHiddenA); ArrayFill(aSums,0,numHiddenA,0); ArrayResize(bSums,numHiddenB); ArrayFill(bSums,0,numHiddenB,0); ArrayResize(oSums,numOutput); ArrayFill(oSums,0,numOutput,0); int size=ArraySize(xValues); for(int i=0; i<size;++i) // копируем значения xValues на вход this.inputs[i]=xValues[i]; for(int j=0; j<numHiddenA;++j) // сумма произведений входов и весов (ia) weights * inputs for(int i=0; i<numInput;++i) aSums[j]+=this.inputs[i]*this.iaWeights[i][j]; // note += for(int i=0; i<numHiddenA;++i) // добавляем смещение полученным значениям a aSums[i]+=this.aBiases[i]; for(int i=0; i<numHiddenA;++i) // функция активации this.aOutputs[i]=HyperTanFunction(aSums[i]); // hard-coded for(int j=0; j<numHiddenB;++j) // сумма произведений весов на выходы, (ab) weights * a outputs = локальные входы for(int i=0; i<numHiddenA;++i) bSums[j]+=aOutputs[i]*this.abWeights[i][j]; // note += for(int i=0; i<numHiddenB;++i) // добавляем смещение полученным значениям b bSums[i]+=this.bBiases[i]; for(int i=0; i<numHiddenB;++i) // функция активации this.bOutputs[i]=HyperTanFunction(bSums[i]); // зашито for(int j=0; j<numOutput;++j) // сумма произведений весов на выходы, (bo) weights * b outputs = локальные входы for(int i=0; i<numHiddenB;++i) oSums[j]+=bOutputs[i]*boWeights[i][j]; for(int i=0; i<numOutput;++i) // смещение к полученным значениям oSums[i]+=oBiases[i]; double softOut[]; Softmax(oSums,softOut); // активация Softmax выводит все сразу для эффективности ArrayCopy(outputs,softOut); ArrayCopy(yValues,this.outputs); }Что происходит «за сценой»: нейронная сеть использует функцию активации гиперболического тангенса (Tan-h) при вычислении выходных сигналов двух скрытых слоев и функцию активации Softmax при вычислении окончательных выходных значений.
- Функция Tan-h (гиперболический тангенс), как и логистическая сигмоида, является сигмоидальной, но в отличие от нее выводит значения в диапазоне (-1, 1). Таким образом, сильно отрицательные входы в Tan-h приведут к отрицательным выходным сигналам. Нулевые входы приводят к выходам около нуля. Я покажу математическую формулу этой функции, а также ее реализацию в MQL.
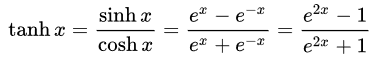
double HyperTanFunction(double x) { if(x<-20.0) return -1.0; // аппроксимация верна до 30 знаков после запятой else if(x > 20.0) return 1.0; else return MathTanh(x); // явная формула для MQL4 (1-exp(-2*x))/(1+exp(-2*x)) }
- Функция Softmax присваивает десятичные вероятности каждому классу при работе с несколькими классами. Эти десятичные вероятности в сумме должны составлять 1.0. Это дополнительное ограничение позволяет обучению сходиться быстрее.

void Softmax(double &oSums[],double &_softOut[]) { // определяем максимальную сумму выхода // выводит все узлы сразу, чтобы не приходилось каждый раз пересчитывать int size=ArraySize(oSums); double max= oSums[0]; for(int i = 0; i<size;++i) if(oSums[i]>max) max=oSums[i]; // определяем коэффициент масштабирования -- сумма exp(значение - макс.) double scale=0.0; for(int i= 0; i<size;++i) scale+= MathExp(oSums[i]-max); ArrayResize(_softOut,size); for(int i=0; i<size;++i) _softOut[i]=MathExp(oSums[i]-max)/scale; }
4. Пример советника, использующего класс DeepNeuralNetwork
Прежде чем приступить к разработке нашего советника, нужно определить, какие данные мы будем подавать на вход в нашу глубокую нейросеть. Нейросеть хорошо классифицирует паттерны, поэтому будем использовать относительные значения японской свечи в качестве входных данных. Это значения размера верхней тени, тела, нижней тени и направления (бычья или медвежья) свечи. Не обязательно так сильно ограничивать количество входных данных, но в нашем случае этого достаточно для тестовой программы.
Наш демонстрационный советник:
Для нейросети со структурой 4-4-5-3 всего нужно (4 * 4) + 4 + (4 * 5) + 5 + (5 * 3) + 3 = 63 веса и значения смещения.
#include <DeepNeuralNetwork.mqh> int numInput=4; int numHiddenA = 4; int numHiddenB = 5; int numOutput=3; DeepNeuralNetwork dnn(numInput,numHiddenA,numHiddenB,numOutput); //--- значения весов и смещения input double w0=1.0; input double w1=1.0; input double w2=1.0; input double w3=1.0; input double w4=1.0; input double w5=1.0; input double w6=1.0; input double w7=1.0; input double w8=1.0; input double w9=1.0; input double w10=1.0; input double w11=1.0; input double w12=1.0; input double w13=1.0; input double w14=1.0; input double w15=1.0; input double b0=1.0; input double b1=1.0; input double b2=1.0; input double b3=1.0; input double w40=1.0; input double w41=1.0; input double w42=1.0; input double w43=1.0; input double w44=1.0; input double w45=1.0; input double w46=1.0; input double w47=1.0; input double w48=1.0; input double w49=1.0; input double w50=1.0; input double w51=1.0; input double w52=1.0; input double w53=1.0; input double w54=1.0; input double w55=1.0; input double w56=1.0; input double w57=1.0; input double w58=1.0; input double w59=1.0; input double b4=1.0; input double b5=1.0; input double b6=1.0; input double b7=1.0; input double b8=1.0; input double w60=1.0; input double w61=1.0; input double w62=1.0; input double w63=1.0; input double w64=1.0; input double w65=1.0; input double w66=1.0; input double w67=1.0; input double w68=1.0; input double w69=1.0; input double w70=1.0; input double w71=1.0; input double w72=1.0; input double w73=1.0; input double w74=1.0; input double b9=1.0; input double b10=1.0; input double b11=1.0;
В качестве входных данных для нашей сети будем использовать следующую формулу, которая определяет, какой процент от размера свечи составляет каждая из ее частей.

//+------------------------------------------------------------------+ //| Размер части свечи в процентах от ее общего размера | //+------------------------------------------------------------------+ int CandlePatterns(double high,double low,double open,double close,double uod,double &xInputs[]) { double p100=high-low;// Общий размер свечи double highPer=0; double lowPer=0; double bodyPer=0; double trend=0; if(uod>0) { highPer=high-close; lowPer=open-low; bodyPer=close-open; trend=1; } else { highPer=high-open; lowPer=close-low; bodyPer=open-close; trend=0; } if(p100==0)return(-1); xInputs[0]=highPer/p100; xInputs[1]=lowPer/p100; xInputs[2]=bodyPer/p100; xInputs[3]=trend; return(1); }
Теперь можно подавать данные на вход нейросети:
MqlRates rates[]; ArraySetAsSeries(rates,true); int copied=CopyRates(_Symbol,0,1,5,rates); // Расчет размера верхней тени, нижней тени и тела в % от размера свечи int error=CandlePatterns(rates[0].high,rates[0].low,rates[0].open,rates[0].close,rates[0].close-rates[0].open,_xValues); if(error<0)return; dnn.SetWeights(weight); double yValues[]; dnn.ComputeOutputs(_xValues,yValues);
Далее нейросеть рассчитывает возможность для торговли на основе полученных данных. Напоминаю, что функция Softmax выдает 3 результата на основе суммы 100%. Значения хранятся в массиве yValues, сигналом будет значение выше 60%.
//--- если выходное значение нейрона больше 60% if(yValues[0]>0.6) { if(m_Position.Select(my_symbol))// проверим наличие открытых позиций { if(m_Position.PositionType()==POSITION_TYPE_SELL) m_Trade.PositionClose(my_symbol);// если есть, закроем противоположную позицию if(m_Position.PositionType()==POSITION_TYPE_BUY) return; } m_Trade.Buy(lot_size,my_symbol);// откроем длинную позицию } //--- если выходное значение нейрона больше 60% if(yValues[1]>0.6) { if(m_Position.Select(my_symbol))// проверим наличие открытых позиций { if(m_Position.PositionType()==POSITION_TYPE_BUY) m_Trade.PositionClose(my_symbol);// если есть, закроем противоположную позицию if(m_Position.PositionType()==POSITION_TYPE_SELL) return; } m_Trade.Sell(lot_size,my_symbol);// откроем короткую позицию } if(yValues[2]>0.6) { m_Trade.PositionClose(my_symbol);// закроем любую позицию }
5. Обучение глубокой нейронной сети через оптимизатор стратегий
Итак, мы реализовали механизм прямого распространения глубокой нейронной сети, но он не выполняет никакого обучения. Обучение будем проводить в тестере стратегий. Далее я покажу, как обучить нейросеть. Обратите внимание, что из-за большого количества входных данных и диапазона параметров обучение можно проводить только в MetaTrader 5. Если нужно, полученные значения оптимизации можно легко скопировать в MetaTrader 4.
Конфигурация тестера стратегий:
Диапазон для обучения весов и смещения может быть от -1 до 1 с шагом 0.1, 0.01 или 0.001. Вы можете попробовать эти значения и посмотреть, какое из них даст лучший результат. Я использовал шаг 0.001:
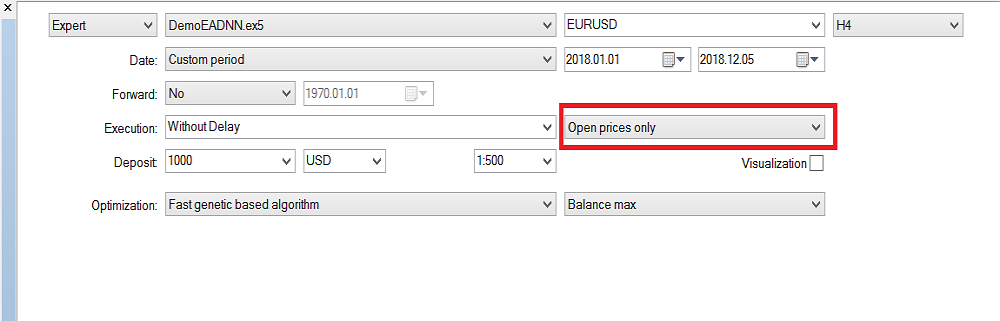
Запускается тестер в режиме "Только по ценам открытия", потому что советник работает только с закрытыми свечами и нет смысла проверять на каждом тике. Я проводил оптимизацию на таймфрейме H4. Вот такие результаты получились при тестировании на истории за последний год:

Заключение
Описание алгоритма и код, представленные в этой статье, могут послужить хорошей основой для понимания нейронных сетей с двумя скрытыми слоями. А что же с сетями, имеющими три и более скрытых слоев? В исследовательской литературе есть определенное соглашение в отношении того, что двух скрытых слоев достаточно почти для всех практических задач. В этой статье описывается подход к разработке улучшенных моделей для прогнозирования цен с использованием глубоких нейронных сетей. В основе него лежит способность глубоких сетей изучать абстрактные характеристики на основе необработанных данных. Предварительные результаты подтверждают, что наша глубокая сеть обеспечивает значительно более высокую точность прогнозов, чем базовые модели для развитых валютных рынков.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/5486
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Стать хорошим программистом (Часть 6): 9 привычек для эффективной разработки
Стать хорошим программистом (Часть 6): 9 привычек для эффективной разработки
 Стать хорошим программистом (Часть 7): как стать успешным исполнителем во Фрилансе
Стать хорошим программистом (Часть 7): как стать успешным исполнителем во Фрилансе
 Работаем со временем (Часть 2): Функции
Работаем со временем (Часть 2): Функции
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Вам удалось решить проблему с масштабированием входов более 4х?
Да, начал сам копаться и докопался. Не только увеличил входы, но и архитектуру: добавлял слои, добавлял нейроны, добавил RNN - запоминание предыдущего состояния и подавал его на входы, пробовал менять функцию активации на самые известные, перепробовал все виды входов из темы "Что подать на вход нейросети", — безрезультатно.
К великому сожалению. Но, это не мешает мне время от времени возвращаться и извращаться над простыми нейросетями, в том числе и над этой авторской.
Я пробовал LSTM, BiLSTM, CNN, CNN-BiLSTM, CNN-BiLSTM-MLP, — безрезультатно.
Сам офигел. То есть, все успехи описываются одним наблюдением: это удачный период графика. Например, 2022 год у евродоллара почти полностью повторяет 2021-ый. И, обучая на 2021, на 2022-ом до ноября (или до октября, не помню) вы получите положительный форвард. Но, как только обучите на 2020-м, любую(!) нейросеть, то на 2021-м она сливает вчистую. Прям с первого месяца! А перейдя на другие валютные пары (обычно на евродолларе), то тоже ведёт себя рандомно.
Но, нам ведь нужна система, которая гарантированно после обучения будет подавать признаки жизни на форварде? Вот если отталкиваться от этой мысли - то безрезультатно. Если же кто-то верит, что он человек фартовый и именно после сегодняшнего обучения на последнем году у него будет следующий год/полгода профитного форварда, то ему только удачи пожелать)
Но, нам ведь нужна система, которая гарантированно после обучения будет подавать признаки жизни на форварде? Вот если отталкиваться от этой мысли - то безрезультатно. Если же кто-то верит, что он человек фартовый и именно после сегодняшнего обучения на последнем году у него будет следующий год/полгода профитного форварда, то ему только удачи пожелать)
Тогда можно предположить, что нужные "граальные" параметры НС были пропущены в процессе их поиска или даже изначально незначимые и неучтённые тестером? Может системе не хватает факторов событийности, чем просто паттерны-пропорции.
Тогда можно предположить, что нужные "граальные" параметры НС были пропущены в процессе их поиска или даже изначально незначимые и неучтённые тестером? Может системе не хватает факторов событийности, чем просто паттерны-пропорции.
Конечно, иногда проскакивают "граальные" сеты при оптимизации, их невозможно практически найти (строчка 150-ая какая-нибудь при сортировке), пока все не проверишь. Иногда их десятки тысяч.
А вот вторую часть вашего поста я не понял.
Конечно, иногда проскакивают "граальные" сеты при оптимизации, их невозможно практически найти (строчка 150-ая какая-нибудь при сортировке), пока все не проверишь. Иногда их десятки тысяч.
А вот вторую часть вашего поста я не понял.
Это про подачу на вход таких данных, которые получены в момент наступления определенного события, например High[0]> High[1] в моменте. Если рынок рассматривать в таком контексте, то это целиком событийная модель и коррелирована на этом. А контроль элементов хаоса это уже к методам тонкой настройки и оптимизации вне "памяти" НС. Хорошо представляется по интегральному показателю, как работают подобные событийные добавки в код. Этот показатель (комплексный критерий) улучшается и смещается в сторону самых прибыльных проходов оптимизатора.