
Programamos una red neuronal profunda desde cero usando el lenguaje MQL

Introducción
Como el aprendizaje automático ha ganado popularidad recientemente, muchos ya habrán oído hablar del aprendizaje profundo y desearán saber cómo aplicarlo en el lenguaje MQL. He visto implementaciones sencillas de neuronas artificiales con funciones de activación, pero nada que implemente una red neuronal profunda real. En este artículo, les presentaré una Red Neuronal Profunda implementada en el lenguaje MQL con sus diferentes funciones de activación, como la función tangente hiperbólica para las capas ocultas y la función Softmax para la capa de salida. Iremos moviéndonos poco a poco desde el primer paso hasta el final para formar completamente una Red Neural Profunda.
1. Creando una neurona artificial
Comenzaremos por la unidad básica de la red neuronal: una neurona individual. En este artículo nos concentraremos en las diferentes partes del tipo de neurona que vamos a emplear en nuestra Red Neural Profunda, si bien la mayor diferencia entre tipos de neuronas suele ser la función de activación.
1.1. Partes de una neurona individual
La neurona artificial, modelada vagamente a partir de una neurona en el cerebro humano, se encarga simplemente de alojar cálculos matemáticos. Al igual que nuestras neuronas, esta se activa al encontrar estímulos suficientes. La neurona combina la entrada de los datos con un conjunto de coeficientes, o pesos, que amplifican o amortiguan esa información, lo cual asigna importancia a las entradas para la tarea que el algoritmo está intentando aprender. En la siguiente imagen, podemos echar un vistazo a cada parte de la neurona en acción:

1.1.1. Entradas
La entrada supone un disparador externo del entorno, o bien proviene de salidas de otras neuronas artificiales, y debe ser evaluado por la red. Asimismo, sirve como "alimento" para la neurona y atraviesa esta, convirtiéndose así en una salida que podemos interpretar gracias al entrenamiento que ha recibido la neurona por nuestra parte. Puede tratarse de valores discretos o números reales.
1.1.2. Pesos
Los pesos son factores que se multiplican por las entradas que les corresponden, aumentando o disminuyendo su valor, ofreciendo mayor o menor significado a la entrada que llega a la neurona y, por consiguiente, a la salida que sale de esta. El objetivo de los algoritmos de entrenamiento de las redes neuronales es definir el "mejor" conjunto posible de valores de peso para resolver el problema.
1.1.3. Función de entrada de red
En esta parte de la neurona, las entradas y los pesos convergen en un producto de resultado único conseguido como la suma de la multiplicación de cada entrada por su peso. Este resultado o valor se transmite mediante la función de activación, que luego nos proporciona las medidas de influencia que la neurona de entrada tiene sobre la salida de la red neuronal.
1.1.4. Función de activación
La función de activación lleva hacia la salida. Pueden existir varios tipos de función de activación (Sigmoid, Tan-h, Softmax, ReLU, entre otras). Esta decide si se debe activar una neurona o no. En este artículo, nos centraremos en los tipos de función Tan-h y Softmax.
1.1.5. Salida
Finalmente, tenemos la salida. Puede transmitirse a otra neurona o muestrearse utilizando el entorno externo. Dependiendo de la función de activación usada, este valor puede ser discreto o real.
2. Construyendo la red neuronal
La red neuronal se inspira en los métodos de procesamiento de información de los sistemas nerviosos biológicos, como el cerebro, y se compone de capas de neuronas artificiales: cada capa está conectada a la siguiente. Por consiguiente, la capa anterior actúa como entrada a la capa siguiente, y así sucesivamente hasta la capa de salida. El objetivo de la red neuronal podría ser la clusterización usando el aprendizaje no supervisado, la clasificación mediante el aprendizaje supervisado o la regresión. En este artículo, nos centraremos en la capacidad de clasificar en tres estados: COMPRAR, VENDER o MANTENER. A continuación, mostramos una red neuronal con una capa oculta:

3. Escalando de una red neuronal a una red neuronal profunda
Lo que distingue a una red neuronal profunda de las redes neuronales de capa oculta única más frecuentes es el número de capas que componen su profundidad. Un número superior a tres capas (incluidas la entrada y la salida) se califica como aprendizaje "profundo". Profundo, por consiguiente, es un término técnico estrictamente definido que indica más de una capa oculta. Cuanto más avanzamos en la red neuronal, más complejas serán las características que pueden reconocer sus neuronas, ya que se añaden y recombinan características de la capa anterior. Esto hace que las redes de aprendizaje profundo sean capaces de gestionar conjuntos de datos muy grandes y de grandes dimensiones, con miles de millones de parámetros que pasan por funciones no lineales. En la imagen a continuación, podemos ver una red neuronal profunda con 3 capas ocultas:

3.1. Clase de red neuronal profunda
Ahora, echemos un vistazo a la clase que usaremos para crear nuestra red neuronal. La red neuronal profunda está encapsulada en una clase definida de forma programática, denominada DeepNeuralNetwork. El método principal crea una instancia de una red neuronal de propagación hacia delante 3-4-5-3 completamente conectada. Más adelante, en una sesión de entrenamiento de la red neuronal profunda en este artículo, mostraremos algunos ejemplos de entradas para alimentar nuestra red, pero por ahora nos concentraremos en crear la red. La red es de codificación fija para dos capas ocultas. Las redes neuronales con tres o más capas son muy raras, pero si queremos crear una red con más capas, podremos hacerlo fácilmente usando la estructura presentada en este artículo. Los pesos de la entrada a la capa A se guardan en la matriz iaWeights, los pesos de la capa A a la capa B se guardan en la matriz abWeights y los pesos de la capa B a la salida se guardan en la matriz boWeights. Como una matriz multidimensional solo puede ser estática o dinámica en la primera dimensión, y todas las demás dimensiones son estáticas, el tamaño de la matriz se declarará como una variable constante usando la instrucción "#define". Hemos eliminado todas las declaraciones de uso salvo la que hace referencia al espacio de nombres del sistema de nivel superior, para así ahorrar espacio. Podrá encontrar el código fuente completo en los archivos adjuntos al artículo.
Estructura del programa:
#define SIZEI 4 #define SIZEA 5 #define SIZEB 3 //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class DeepNeuralNetwork { private: int numInput; int numHiddenA; int numHiddenB; int numOutput; double inputs[]; double iaWeights[][SIZEI]; double abWeights[][SIZEA]; double boWeights[][SIZEB]; double aBiases[]; double bBiases[]; double oBiases[]; double aOutputs[]; double bOutputs[]; double outputs[]; public: DeepNeuralNetwork(int _numInput,int _numHiddenA,int _numHiddenB,int _numOutput) {...} void SetWeights(double &weights[]) {...} void ComputeOutputs(double &xValues[],double &yValues[]) {...} double HyperTanFunction(double x) {...} void Softmax(double &oSums[],double &_softOut[]) {...} }; //+------------------------------------------------------------------+
Las dos capas ocultas y la capa de salida única tienen (cada una de ellas) una matriz de valores de bias asociados, denominados aBiases, bBiases y oBiases, respectivamente. Las salidas locales para las capas ocultas se guardan en matrices de alcance de clase denominadas aOutputs y bOutputs.
3.2. Calculando las salidas de las redes neuronales profundas
El método ComputeOutputs comienza configurando las matrices reutilizables para contener sumas preliminares (antes de la activación). Después calcula la suma preliminar de pesos multiplicada por las entradas para los nodos de la capa A, suma los valores de bias y luego aplica la función de activación. A continuación, se calculan las salidas locales de la capa B, usando para ello las salidas de la capa A recién calculadas como entradas locales y, por último, se calculan las salidas finales.
void ComputeOutputs(double &xValues[],double &yValues[]) { double aSums[]; // hidden A nodes sums scratch array double bSums[]; // hidden B nodes sums scratch array double oSums[]; // output nodes sums ArrayResize(aSums,numHiddenA); ArrayFill(aSums,0,numHiddenA,0); ArrayResize(bSums,numHiddenB); ArrayFill(bSums,0,numHiddenB,0); ArrayResize(oSums,numOutput); ArrayFill(oSums,0,numOutput,0); int size=ArraySize(xValues); for(int i=0; i<size;++i) // copy x-values to inputs this.inputs[i]=xValues[i]; for(int j=0; j<numHiddenA;++j) // compute sum of (ia) weights * inputs for(int i=0; i<numInput;++i) aSums[j]+=this.inputs[i]*this.iaWeights[i][j]; // note += for(int i=0; i<numHiddenA;++i) // add biases to a sums aSums[i]+=this.aBiases[i]; for(int i=0; i<numHiddenA;++i) // apply activation this.aOutputs[i]=HyperTanFunction(aSums[i]); // hard-coded for(int j=0; j<numHiddenB;++j) // compute sum of (ab) weights * a outputs = local inputs for(int i=0; i<numHiddenA;++i) bSums[j]+=aOutputs[i]*this.abWeights[i][j]; // note += for(int i=0; i<numHiddenB;++i) // add biases to b sums bSums[i]+=this.bBiases[i]; for(int i=0; i<numHiddenB;++i) // apply activation this.bOutputs[i]=HyperTanFunction(bSums[i]); // hard-coded for(int j=0; j<numOutput;++j) // compute sum of (bo) weights * b outputs = local inputs for(int i=0; i<numHiddenB;++i) oSums[j]+=bOutputs[i]*boWeights[i][j]; for(int i=0; i<numOutput;++i) // add biases to input-to-hidden sums oSums[i]+=oBiases[i]; double softOut[]; Softmax(oSums,softOut); // softmax activation does all outputs at once for efficiency ArrayCopy(outputs,softOut); ArrayCopy(yValues,this.outputs); }En segundo plano, la red neuronal usa la función de activación de tangente hiperbólica (Tan-h) al calcular las salidas de las dos capas ocultas, y la función de activación Softmax para calcular los valores de salida finales.
- Tangente hiperbólica (Tan-h): al igual que el sigmoide logístico, la función Tan-h también es sigmoidea, pero en cambio genera valores que oscilan en el rango (-1, 1). Por consiguiente, las entradas fuertemente negativas a la Tan-h se correlacionarán con salidas negativas. Además, solo las entradas de valor cero se asignarán a salidas cercanas a cero. En dicho caso, mostraremos la fórmula matemática, pero también su implementación en el código fuente de MQL.
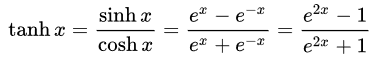
double HyperTanFunction(double x) { if(x<-20.0) return -1.0; // approximation is correct to 30 decimals else if(x > 20.0) return 1.0; else return MathTanh(x); //Use explicit formula for MQL4 (1-exp(-2*x))/(1+exp(-2*x)) }
- Softmax: asigna probabilidades decimales a cada clase en el caso de clases múltiples. Dichas probabilidades decimales deberán sumar 1.0. Esta limitación adicional permite que el entrenamiento converja más rápido.

void Softmax(double &oSums[],double &_softOut[]) { // determine max output sum // does all output nodes at once so scale doesn't have to be re-computed each time int size=ArraySize(oSums); double max= oSums[0]; for(int i = 0; i<size;++i) if(oSums[i]>max) max=oSums[i]; // determine scaling factor -- sum of exp(each val - max) double scale=0.0; for(int i= 0; i<size;++i) scale+= MathExp(oSums[i]-max); ArrayResize(_softOut,size); for(int i=0; i<size;++i) _softOut[i]=MathExp(oSums[i]-max)/scale; }
4. Asesor experto de demostración con uso de la clase DeepNeuralNetwork
Antes de comenzar a desarrollar el asesor, deberemos definir los datos que suministraremos a nuestra Red Neuronal Profunda. Como las redes neuronales son buenas para clasificar patrones, usaremos los valores relativos de una vela japonesa como entrada. Estos valores serían el tamaño de la sombra superior, el cuerpo, la sombra inferior y la dirección de la vela (alcista o bajista). El número de entradas no debe ser necesariamente pequeño, pero en este caso bastará como programa de prueba.
El asesor experto de demostración:
Una estructura de red neuronal 4-4-5-3 necesitará un total de (4 * 4) + 4 + (4 * 5) + 5 + (5 * 3) + 3 = 63 pesos y valores de bias.
#include <DeepNeuralNetwork.mqh> int numInput=4; int numHiddenA = 4; int numHiddenB = 5; int numOutput=3; DeepNeuralNetwork dnn(numInput,numHiddenA,numHiddenB,numOutput); //--- weight & bias values input double w0=1.0; input double w1=1.0; input double w2=1.0; input double w3=1.0; input double w4=1.0; input double w5=1.0; input double w6=1.0; input double w7=1.0; input double w8=1.0; input double w9=1.0; input double w10=1.0; input double w11=1.0; input double w12=1.0; input double w13=1.0; input double w14=1.0; input double w15=1.0; input double b0=1.0; input double b1=1.0; input double b2=1.0; input double b3=1.0; input double w40=1.0; input double w41=1.0; input double w42=1.0; input double w43=1.0; input double w44=1.0; input double w45=1.0; input double w46=1.0; input double w47=1.0; input double w48=1.0; input double w49=1.0; input double w50=1.0; input double w51=1.0; input double w52=1.0; input double w53=1.0; input double w54=1.0; input double w55=1.0; input double w56=1.0; input double w57=1.0; input double w58=1.0; input double w59=1.0; input double b4=1.0; input double b5=1.0; input double b6=1.0; input double b7=1.0; input double b8=1.0; input double w60=1.0; input double w61=1.0; input double w62=1.0; input double w63=1.0; input double w64=1.0; input double w65=1.0; input double w66=1.0; input double w67=1.0; input double w68=1.0; input double w69=1.0; input double w70=1.0; input double w71=1.0; input double w72=1.0; input double w73=1.0; input double w74=1.0; input double b9=1.0; input double b10=1.0; input double b11=1.0;
Para las entradas de nuestra red neuronal usaremos la siguiente fórmula para determinar qué porcentaje representa cada parte de la vela, respetando el total de su tamaño.

//+------------------------------------------------------------------+ //|percentage of each part of the candle respecting total size | //+------------------------------------------------------------------+ int CandlePatterns(double high,double low,double open,double close,double uod,double &xInputs[]) { double p100=high-low;//Total candle size double highPer=0; double lowPer=0; double bodyPer=0; double trend=0; if(uod>0) { highPer=high-close; lowPer=open-low; bodyPer=close-open; trend=1; } else { highPer=high-open; lowPer=close-low; bodyPer=open-close; trend=0; } if(p100==0)return(-1); xInputs[0]=highPer/p100; xInputs[1]=lowPer/p100; xInputs[2]=bodyPer/p100; xInputs[3]=trend; return(1); }
Ahora podemos procesar las entradas a través de nuestra red neuronal:
MqlRates rates[]; ArraySetAsSeries(rates,true); int copied=CopyRates(_Symbol,0,1,5,rates); //Compute the percent of the upper shadow, lower shadow and body in base of sum 100% int error=CandlePatterns(rates[0].high,rates[0].low,rates[0].open,rates[0].close,rates[0].close-rates[0].open,_xValues); if(error<0)return; dnn.SetWeights(weight); double yValues[]; dnn.ComputeOutputs(_xValues,yValues);
Ahora, la oportunidad comercial es procesada según el cálculo de la red neuronal. Recuerde, la función Softmax producirá 3 salidas basadas en la suma de 100%. Los valores se guardan en la matriz "yValues"; después se ejecutará el valor con un número superior al 60%.
//--- if the output value of the neuron is mare than 60% if(yValues[0]>0.6) { if(m_Position.Select(my_symbol))//check if there is an open position { if(m_Position.PositionType()==POSITION_TYPE_SELL) m_Trade.PositionClose(my_symbol);//Close the opposite position if exists if(m_Position.PositionType()==POSITION_TYPE_BUY) return; } m_Trade.Buy(lot_size,my_symbol);//open a Long position } //--- if the output value of the neuron is mare than 60% if(yValues[1]>0.6) { if(m_Position.Select(my_symbol))//check if there is an open position { if(m_Position.PositionType()==POSITION_TYPE_BUY) m_Trade.PositionClose(my_symbol);//Close the opposite position if exists if(m_Position.PositionType()==POSITION_TYPE_SELL) return; } m_Trade.Sell(lot_size,my_symbol);//open a Short position } if(yValues[2]>0.6) { m_Trade.PositionClose(my_symbol);//close any position }
5. Entrenando la Red Neuronal Profunda mediante la optimización de estrategias
Como habrá notado, solo hemos implementado el mecanismo de propagación hacia delante en la red neuronal profunda, y este no realiza ningún entrenamiento. Hemos reservado dicha tarea para el simulador de estrategias. A continuación, vamos a mostrar cómo entrenar la red neuronal. Tenga en cuenta que, debido al gran número de entradas y al rango de parámetros de entrenamiento, solo podremos realizar el entrenamiento en Metatrader 5, pero una vez que obtengamos los valores de optimización, todo se podrá copiar fácilmente a Metatrader 4.
Configuración del simulador de estrategias:
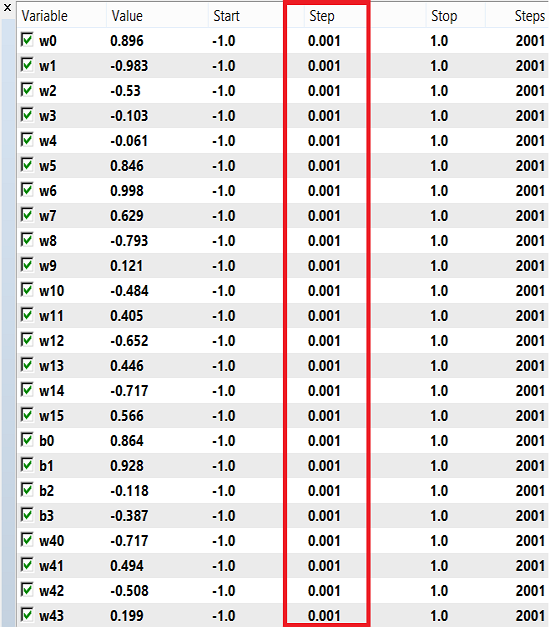
Los pesos y el bias pueden usar un rango de números para el entrenamiento que va de -1 a 1, y un salto de 0.1, 0.01 o 0.001. Podemos probar estos valores y ver cuál obtiene el mejor resultado. En nuestro caso, hemos usado un salto de 0.001, como se muestra en la imagen a continuación:
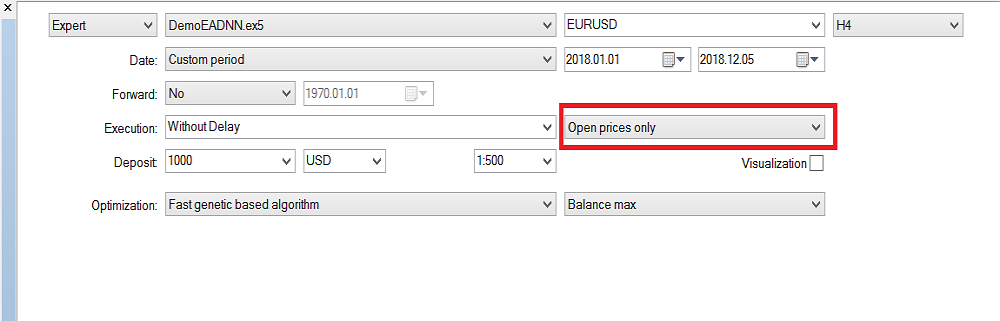
Tenga en cuenta que hemos usado "Solo Precios Abiertos" porque estamos utilizando la última vela cerrada, así que no merece la pena ejecutarla en cada tic. Hemos estado ejecutando la optimización en el marco temporal H4, y durante el último año hemos obtenido estos resultados en el backtest:

Conclusión
El código y la explicación presentados en este artículo deberían proporcionarle una buena base para comprender las redes neuronales con dos capas ocultas. ¿Y si tienen tres o más capas ocultas? El consenso en la literatura de investigación es que dos capas ocultas resultan suficientes para casi todos los problemas prácticos. Este artículo describe un enfoque capaz de desarrollar modelos mejorados para la predicción del tipo de cambio usando Redes Neuronales Profundas, motivado por la capacidad de las redes profundas de aprender características abstractas partiendo de datos sin procesar. Los resultados preliminares confirman que nuestra red profunda genera una precisión predictiva sustancialmente superior a la mostrada por los modelos de referencia para los mercados de divisas desarrollados.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/5486
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Cómo ser un mejor programador (parte 07): Apuntes para convertirse en un desarrollador freelance exitoso
Cómo ser un mejor programador (parte 07): Apuntes para convertirse en un desarrollador freelance exitoso
 Cómo ser un mejor programador (parte 06): 9 hábitos que conducen a una codificación eficaz
Cómo ser un mejor programador (parte 06): 9 hábitos que conducen a una codificación eficaz
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
¿Pudiste resolver el problema con entradas escaladas a más de 4x?
Sí, empecé a husmear y llegué al fondo del asunto. No sólo aumenté las entradas, sino también la arquitectura: añadí capas, añadí neuronas, añadí RNN - recordando el estado anterior y alimentándolo a las entradas, probé a cambiar la función de activación por las más famosas, probé todo tipo de entradas del tema "Qué alimentar a la entrada de la red neuronal" - en vano.
Muy a mi pesar. Pero, eso no me impide volver de vez en cuando y retorcer redes neuronales simples, incluyendo la de este autor.
Probé LSTM, BiLSTM, CNN, CNN-BiLSTM, CNN-BiLSTM-MLP, - en vano.
Yo mismo estoy sorprendido. Es decir, todos los éxitos se describen con una observación: es un periodo de calendario afortunado. Por ejemplo, 2022 para el Eurodólar es casi exactamente igual que 2021. Y entrenando en 2021, obtendrás un forward positivo en 2022 hasta noviembre (u octubre, no recuerdo). Pero, en cuanto entrenas sobre 2020, cualquier(!) red neuronal, luego sobre 2021 falla limpiamente. Desde el primer mes. Y si cambias a otros pares de divisas (normalmente eurodólar), también se comporta aleatoriamente.
Pero necesitamos un sistema que tenga garantizado dar señales de vida en el futuro tras el entrenamiento, ¿no? Si partimos de este pensamiento, es infructuoso. Si alguien cree que es una persona con suerte y después del entrenamiento de hoy tendrá un forward rentable para el próximo año o seis meses, pues buena suerte para él).
Pero, necesitamos un sistema que garantice señales de vida en el delantero después del entrenamiento, ¿no? Si partimos de ese pensamiento, es infructuoso. Si alguien cree que es una persona con suerte y que después del entrenamiento de hoy tendrá un delantero rentable para el próximo año o seis meses, pues que tenga suerte).
Entonces, ¿podemos suponer que los parámetros "graales" necesarios de NS se pasaron por alto en el proceso de su búsqueda o incluso inicialmente insignificantes y no fueron tenidos en cuenta por el probador? Tal vez el sistema carece de factores de eventualidad que sólo patrones-proporciones.
Entonces, ¿podemos suponer que los parámetros "graales" necesarios de NS se pasaron por alto en el proceso de su búsqueda o incluso fueron inicialmente insignificantes y no fueron tenidos en cuenta por el probador? Tal vez el sistema carece de factores de eventualidad que sólo patrones-proporciones.
Por supuesto, a veces los conjuntos "grial" se cuelan durante la optimización, es casi imposible encontrarlos (línea 150 de algún tipo durante la clasificación) hasta que se comprueba todo. A veces hay decenas de miles de ellos.
No entiendo la segunda parte de tu post.
Por supuesto, a veces los conjuntos "grial" se cuelan durante la optimización, es casi imposible encontrarlos (línea 150 de algún tipo durante la clasificación) hasta que lo compruebas todo. A veces hay decenas de miles de ellos.
No entiendo la segunda parte de tu post.
Se trata de la entrada de tales datos, que se obtiene en el momento de un determinado evento, por ejemplo, High[0]> High[1] en el momento. Si el mercado se considera en tal contexto, es totalmente un modelo impulsado por eventos y correlacionado en eso. Y el control de los elementos de caos ya está a los métodos de ajuste fino y optimización fuera de la "memoria" NS. Está bien representado por un indicador integral cómo funcionan tales adiciones de eventos al código. Este indicador (criterio integrado) mejora y se desplaza hacia los pases más rentables del optimizador.