
Passaggio a MQL5 Algo Forge (Parte 4): Lavorare con le Versioni e i Rilasci
Introduzione
La nostra transizione a MQL5 Algo Forge continua. Abbiamo impostato il nostro flusso di lavoro con i repository personali e ci siamo rivolti a una delle ragioni principali di questa scelta - la possibilità di utilizzare facilmente il codice fornito dalla comunità. Nella terza parte abbiamo analizzato come aggiungere una libreria pubblica da un altro repository al nostro progetto.
L'esperimento di collegamento della libreria SmartATR all'Expert Advisor SimpleCandles ha dimostrato chiaramente che la semplice clonazione non è sempre conveniente, soprattutto quando il codice richiede modifiche. Noi, invece, abbiamo seguito il flusso di lavoro corretto: abbiamo creato un fork, che è diventato la nostra copia personale del repository di qualcun altro per correggere bug e apportare modifiche, preservando l’opzione di proporre successivamente queste modifiche all'autore tramite una Pull Request.
Nonostante alcune limitazioni incontrate nell'interfaccia di MetaEditor, la combinazione con l'interfaccia web di MQL5 Algo Forge ci ha permesso di completare con successo l'intera catena di azioni, dalla clonazione al commit delle modifiche e infine al collegamento del progetto con una libreria esterna. Abbiamo quindi risolto un compito specifico ed esaminato un modello universale per l'integrazione di qualsiasi componente di terze parti.
Nell'articolo di oggi, daremo un’occhiata più da vicino alla fase di pubblicazione delle modifiche apportate al repository, un certo insieme di modifiche che formano una soluzione completa, sia che si tratti di aggiungere nuove funzionalità a un progetto o di risolvere un problema scoperto. Si tratta del processo di commit o rilascio di una nuova versione del prodotto. Vedremo come organizzare questo processo e quali capacità offre MQL5 Algo Forge.
Trovare un Ramo
Nelle parti precedenti, abbiamo consigliato di usare un ramo separato del repository per fare una serie di modifiche che riguardano un compito specifico. Tuttavia, dopo aver completato il lavoro su questo ramo, è meglio unirlo a un altro ramo (main) e poi cancellarlo. Altrimenti, il repository può trasformarsi rapidamente in una fitta boscaglia in cui anche il proprietario potrebbe facilmente perdersi. Pertanto, i rami obsoleti devono essere rimossi. A volte, però, potrebbe essere necessario riportare il codice allo stato in cui si trovava prima dell'eliminazione di un determinato ramo. Come fare?
Innanzitutto, chiariamo che un ramo è semplicemente una sequenza di commit disposti cronologicamente. Tecnicamente, un ramo è un puntatore a un commit considerato l'ultimo di una catena di commit consecutivi. Pertanto, l'eliminazione di un ramo non cancella i commit stessi. Al massimo, potrebbero essere riassegnati a un altro ramo o addirittura uniti in un unico commit sommario; in ogni caso, continuano a esistere nel repository (con rare eccezioni). Quindi, tornare allo stato "prima della cancellazione di un ramo" significa essenzialmente tornare a uno dei commit esistenti in un ramo. La domanda diventa quindi: come troviamo quel commit?
Vediamo lo stato del repository SimpleCandles dopo che sono state apportate le modifiche di cui alla Parte 3:
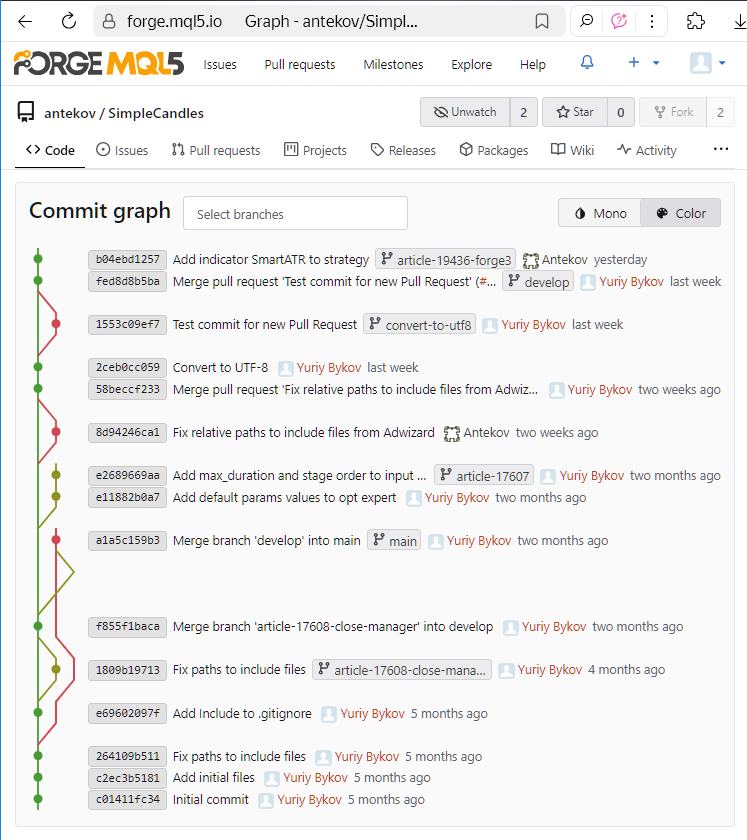
Possiamo vedere la cronologia dei commit e una visualizzazione colorata delle relazioni tra i rami sulla sinistra. Ogni commit è identificato dal suo hash (o più precisamente, da una parte di esso), cioè da un grande numero unico che lo distingue da tutti gli altri. Per abbreviare la rappresentazione, l'hash viene visualizzato in forma esadecimale (ad esempio, b04ebd1257).
Questo albero dei commit può essere visualizzato per qualsiasi repository su una pagina dedicata dell'interfaccia web di MQL5 Algo Forge. Lo screenshot mostrato è stato scattato qualche tempo fa, quindi visitando questa pagina ora si vedrà un’immagine leggermente diversa: nuovi commit saranno apparsi nell'albero e l'intreccio dei rami sarà cambiato a causa di ulteriori commit di unione.
Possiamo anche vedere i nomi dei rami accanto ad alcuni commit. Questi vengono visualizzati per i commit più recenti in ogni ramo. Nella schermata fornita, possiamo contare sei rami diversi: main, develop, convert-to-utf8, article-17608-close-manager, article-17607 e article-19436-forge3. L'ultimo è il ramo utilizzato per le modifiche apportate durante la stesura della Parte 3. Ma quando abbiamo lavorato alla Parte 2, abbiamo anche creato un ramo separato per le modifiche previste. Si chiamava article-17698-forge2 e da allora è stato cancellato, motivo per cui nessun commit porta ora il nome di questo ramo. Allora, dove possiamo trovarlo?
Se guardiamo il messaggio di commit completo per 58beccf233, viene menzionato il nome di questo ramo e viene indicato che è stato unito a develop.

Quindi, abbiamo trovato il commit desiderato, ma individuarlo in questo modo non è comodo. Inoltre, se avessimo unito i rami manualmente usando comandi da console come 'git merge' invece che tramite una Pull Request, avremmo potuto scrivere qualsiasi commento arbitrario per il commit di unione. In questo caso, trovare il commit giusto sarebbe stato ancora più difficile, perché il nome del ramo potrebbe non essere stato incluso nel messaggio.
Ora che abbiamo trovato il commit desiderato, possiamo passare ad esso, ripristinando il nostro repository locale allo stato in cui si trovava subito dopo quel commit. Per farlo, possiamo usare l'hash del commit nel comando 'git checkout'. Tuttavia, ci sono alcune sfumature. Se proviamo a passare a questo commit in MetaEditor selezionandolo dalla cronologia aperta tramite l'opzione del menu contestuale del progetto "Visualizza il registro di Git":
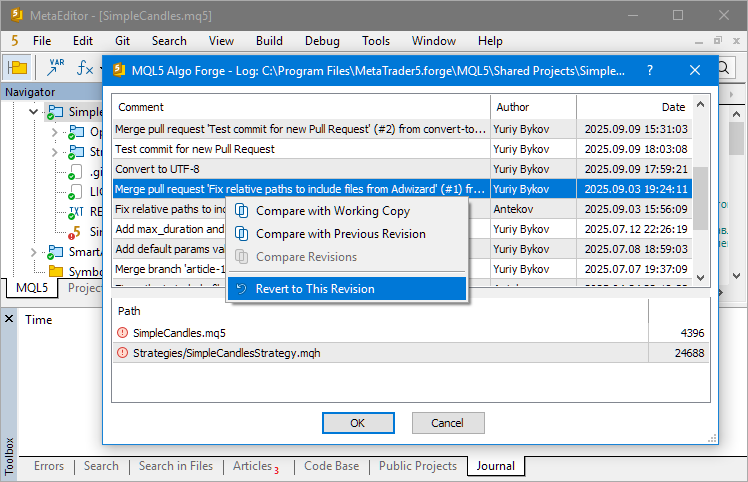
... si incontrerà un messaggio di errore:

Forse c'è una ragione per questo. Diamo un'occhiata più da vicino a ciò che sta accadendo. Inizieremo introducendo i nuovi concetti di "tag" e "puntatore HEAD".
Tag
Un tag nel sistema di controllo di versione Git è un nome aggiuntivo assegnato a un commit specifico. Si può anche pensare a un tag come a un puntatore o a un riferimento a una particolare versione del codice nel repository, poiché punta direttamente a uno specifico commit. L'uso di un tag consente di tornare in qualsiasi momento allo stato esatto del codice che corrisponde al commit taggato. I tag sono utili per contrassegnare le tappe importanti nello sviluppo di un progetto, come le versioni rilasciate, le fasi di completamento o le build stabili. Nell'interfaccia web di MQL5 Algo Forge, è possibile visualizzare tutti i tag di un repository selezionato su una pagina separata.
In Git esistono due tipi di tag: leggeri e annotati. I tag leggeri contengono solo un nome, mentre i tag annotati possono includere informazioni aggiuntive come l'autore, la data, i commenti e persino la firma. Nella maggior parte dei casi si utilizzano tag leggeri.
Per creare un tag tramite l'interfaccia web, si può aprire la pagina di qualsiasi commit (ad esempio, questo), fare clic sul pulsante "Operazioni" e selezionare "Crea tag".
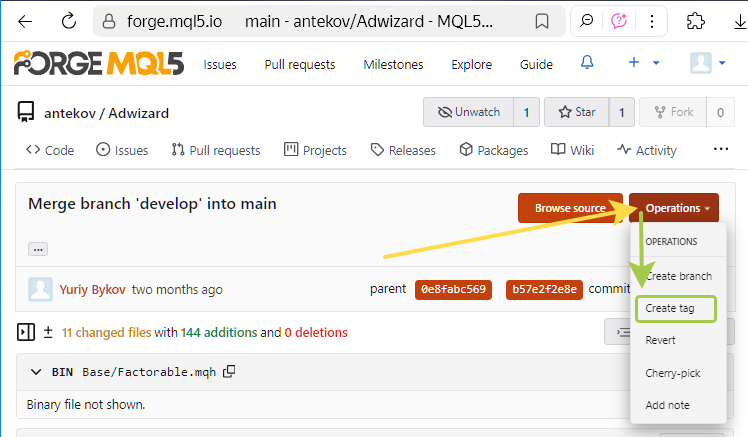
Tuttavia, torneremo alla creazione dei tag un po' più avanti.
Per creare un tag tramite i comandi della console Git, si usa il comando 'git tag'. Per creare un tag leggero, basta specificare il nome del tag:
git tag <nome-tag>
# Esempio
git tag v1.0
Per creare un tag annotato, è necessario aggiungere alcuni parametri:
git tag -a <nome-tag> -m "Descrizione del tag"
# Esempio:
git tag -a v1.0 -m "Version 1.0 release"
Oltre a contrassegnare le versioni di codice destinate alla pubblicazione o alla distribuzione (rilasci), i tag possono essere utilizzati anche per segnalare alle pipeline CI/CD di attivare azioni predefinite quando compare un commit con un determinato tag o per contrassegnare tappe significative dello sviluppo, come il completamento di funzionalità importanti o la correzione di bug critici, anche se non rappresentano una nuova versione rilasciata.
Il puntatore HEAD
Dopo aver parlato dei tag, vale la pena menzionare un altro concetto importante: il puntatore HEAD. Il suo comportamento è simile a quello di un tag con nome fisso HEAD, che si sposta automaticamente all'ultimo commit nel ramo attualmente controllato. HEAD è spesso indicato come "marcatore del ramo corrente" o "puntatore al ramo attivo". Risponde essenzialmente alla domanda: "A che punto del repository siamo in questo momento?". Tuttavia, non è tecnicamente un tag.
Fisicamente, questo puntatore è memorizzato nel file .git/HEAD del repository. Il contenuto di HEAD può contenere sia un riferimento simbolico (un tag o un nome di ramo) o un hash di commit. Quando si passa da un ramo all'altro, il puntatore HEAD si aggiorna automaticamente per puntare all'ultimo commit nel ramo corrente. Quando viene aggiunto un nuovo commit, Git non solo crea l'oggetto commit, ma sposta anche il puntatore HEAD su di esso.
Pertanto, il nome HEAD può essere usato nei comandi della console Git al posto dell'hash dell'ultimo commit o del nome del ramo corrente. Utilizzando i simboli speciali ~ e ^, è possibile fare riferimento ai commit precedenti a quello più recente. Per esempio, HEAD~2 si riferisce al commit di due passi prima del commit più recente. Non ci addentreremo ora in questi dettagli.
Per una discussione più approfondita, dovremmo menzionare i due possibili stati in cui può trovarsi un repository. Lo stato normale, chiamato "attached HEAD", significa che i nuovi commit appariranno prima dell'ultimo commit nel ramo corrente. In questo stato, tutte le modifiche vengono aggiunte al ramo in modo sequenziale e senza conflitti.
L'altro stato, noto come "HEAD detached", si verifica quando il puntatore HEAD si riferisce a un commit che non è l'ultimo di nessun ramo. Questo può accadere, ad esempio, quando:- si passa il repository ad uno specifico commit più vecchio (ad esempio, usando 'git checkout <commit-hash>'),
- per nome del tag (ad esempio, 'git checkout tags/<nome-tag>'),
- passare ad un ramo che esiste ancora nel repository remoto, ma che è stato rimosso dal repository locale (per esempio, "git checkout origin/<nome del ramo>").
Questo stato dovrebbe essere evitato ogni volta che è possibile, poiché qualsiasi modifica in questo stato non associata ad alcun ramo può essere persa quando si passa a un altro ramo. Tuttavia, se non avete intenzione di apportare cambiamenti in questo stato, va bene averlo.
Nessun Tag Finora
Torniamo ora al nostro tentativo di passare il nostro repository locale a uno specifico commit che una volta era l'ultimo del ramo cancellato article-17698-forge2.
Passare un repository a uno specifico vecchio commit non è qualcosa che gli sviluppatori fanno di solito nei flussi di lavoro Git di tutti i giorni. In circostanze normali, raramente sarà necessario eseguire questa operazione. Tuttavia, se si sceglie di farlo, il repository entrerà nel cosiddetto stato di "detached HEAD". In questo caso, quel commit appartiene al ramo develop, che ha già dei commit più recenti che lo seguono, quindi non è più l'ultimo del ramo.
Tuttavia, se utilizziamo l'interfaccia a riga di comando di Git per eseguire questo passaggio, l'operazione verrà completata con successo. Anche se Git ci avvisa chiaramente di trovarci in uno stato di "detached HEAD":
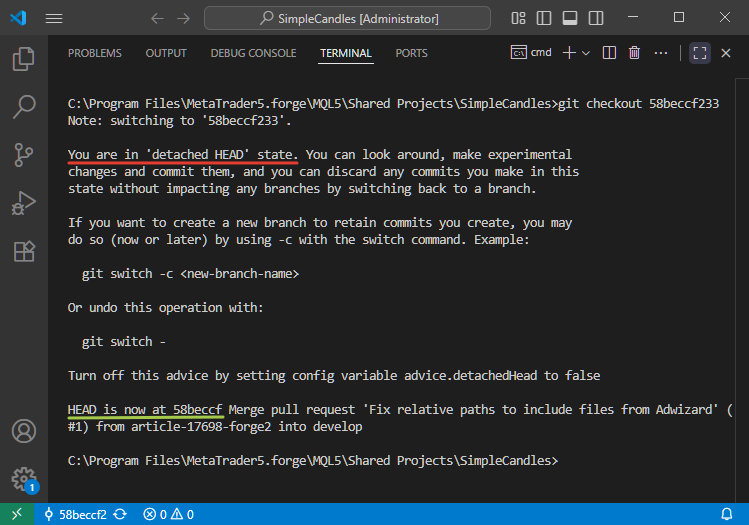
I lettori più attenti noteranno che nell'ultima schermata siamo passati a un commit con l'hash 58beccf233, ma Git riporta che il puntatore HEAD è ora a 58beccf. Dove sono finite le ultime tre cifre? Nulla di sbagliato. Non sono scomparsi. Git consente semplicemente l'uso di hash di commit abbreviati, purché rimangano unici all'interno del repository. A seconda dell'interfaccia, è possibile che gli hash vengano accorciati a un numero di caratteri compreso tra 4 e 10.
Se avete bisogno di vedere l'hash completo dei commit, potete farlo eseguendo il comando 'git log'. Ogni hash di commit completo contiene 40 cifre.
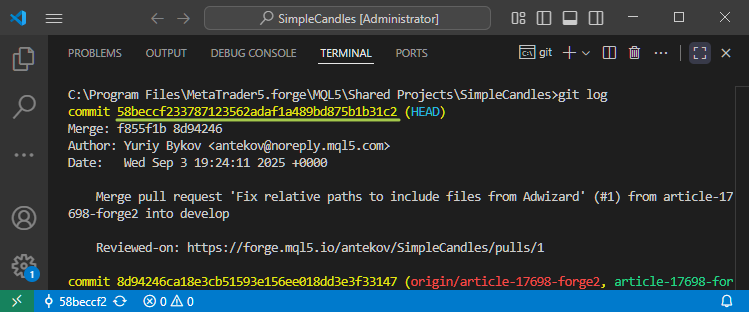
Poiché ogni hash è generato in modo casuale e univoco, anche le prime cifre sono quasi garantite come distinte all'interno di un repository. Ecco perché fornire solo un breve prefisso dell'hash è di solito sufficiente perché Git riconosca esattamente il commit a cui ci si riferisce nei comandi.
Utilizzo della codifica UTF-8
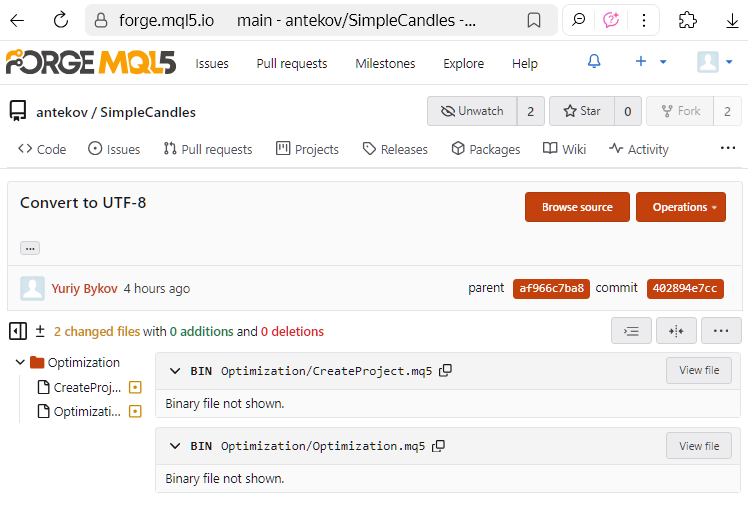
Ecco un altro aspetto interessante. Nelle versioni precedenti, MetaEditor utilizzava la codifica UTF-16LE per salvare i file di codice sorgente. Tuttavia, per qualche motivo, i file salvati con questa codifica venivano trattati da Git come file binari anziché di testo. Di conseguenza, era impossibile visualizzare le righe esatte di codice modificate in un commit (anche se questo funzionava bene in Visual Studio Code). Le uniche informazioni visualizzate erano le dimensioni dei file prima e dopo le modifiche apportate all'interno del commit.
Ecco come appariva nell'interfaccia web di MQL5 Algo Forge:
Ora i nuovi file creati in MetaEditor vengono salvati con la codifica UTF-8 e anche l'uso dei caratteri dell'alfabeto nazionale non comporta più il passaggio automatico a UTF-16LE. Per questo motivo, ha senso convertire in UTF-8 i file più vecchi, trasferiti nel nuovo repository da progetti precedenti. Dopo aver eseguito tale conversione, a partire dal commit successivo, sarà possibile vedere esattamente quali righe e caratteri sono stati modificati. Ad esempio, nell'interfaccia web di MQL5 Algo Forge, l'aspetto potrebbe essere il seguente:
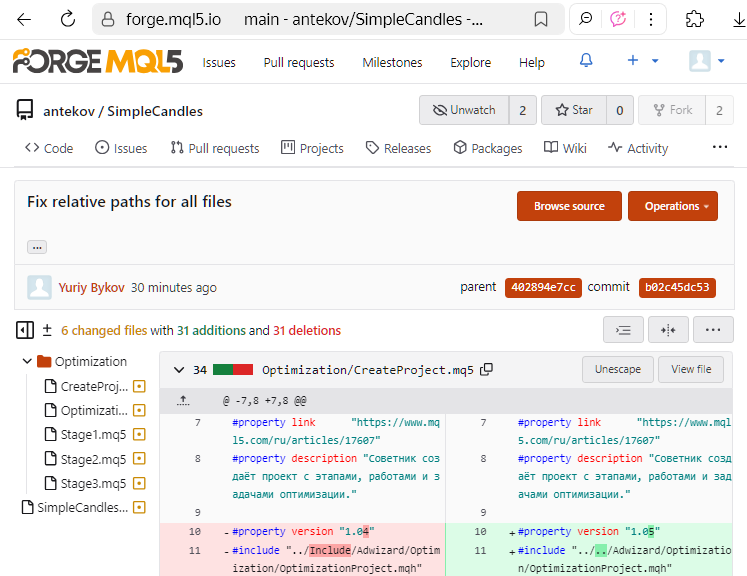
Ma questa è stata una breve digressione. Torniamo alla discussione su come pubblicare una nuova versione di codice nel repository.
Ritorno all’Attività Principale
Quindi, tra i rami del nostro repository, prestiamo attenzione a questi due: article-17608-close-manager e article-17607. Le modifiche apportate in questi rami non sono ancora state unite in develop, poiché i compiti ad essi associati sono ancora in corso. Questi rami continueranno a svilupparsi, quindi è troppo presto per unirli a develop. Continueremo a lavorare su uno di essi (articolo-17607), lo porteremo a un punto logico di completamento e poi lo uniremo con develop. Lo stato risultante del codice sarà contrassegnato da un numero di versione.
Per fare questo, dobbiamo prima preparare il ramo selezionato per ulteriori modifiche, perché mentre esisteva, anche altri rami hanno introdotto cambiamenti. Queste modifiche sono già state unite in develop. Pertanto, dobbiamo assicurarci che questi aggiornamenti da develop siano incorporati anche nel ramo da noi scelto.
Ci sono diversi modi per unire le modifiche apportate da develop in article-17607. Ad esempio, possiamo creare una Pull Request tramite l'interfaccia web e ripetere il processo di unione descritto nella parte precedente. Tuttavia, questo approccio è più adatto quando si vuole unire codice nuovo e non testato in un ramo contenente codice stabile e testato. Nel nostro caso, la situazione è opposta: vogliamo portare aggiornamenti stabili e verificati da develop in un ramo che contiene ancora codice nuovo e non controllato. Pertanto, è perfettamente possibile eseguire l'unione utilizzando i comandi della console Git. Utilizzeremo la console e monitoreremo il processo in Visual Studio Code.
Per prima cosa, controlliamo lo stato attuale del repository. Nel pannello di controllo della versione, possiamo vedere la cronologia dei commit con i nomi dei rami. Il ramo attuale è article-19436-forge3, dove sono state apportate le ultime modifiche. Sul lato destro del terminale viene mostrato l'output del comando 'git status':
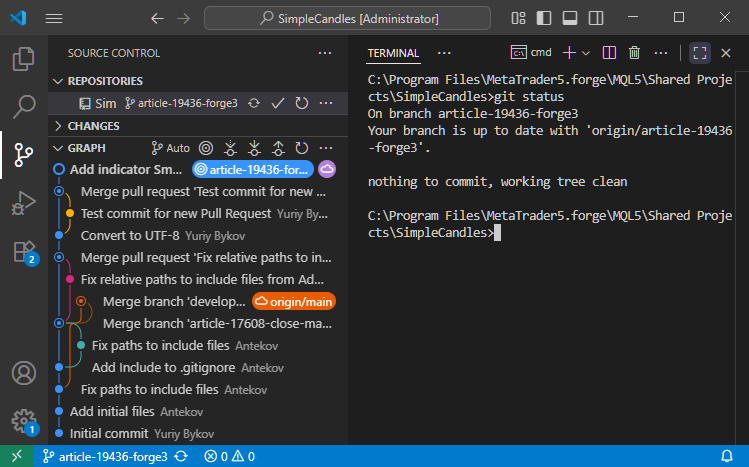
Il comando conferma che il nostro repository è attualmente sul ramo article-19436-forge3 e che il suo stato è sincronizzato con il ramo corrispondente nel repository remoto.
Quindi, passiamo al ramo article-17607 usando il comando 'git checkout article-17607':
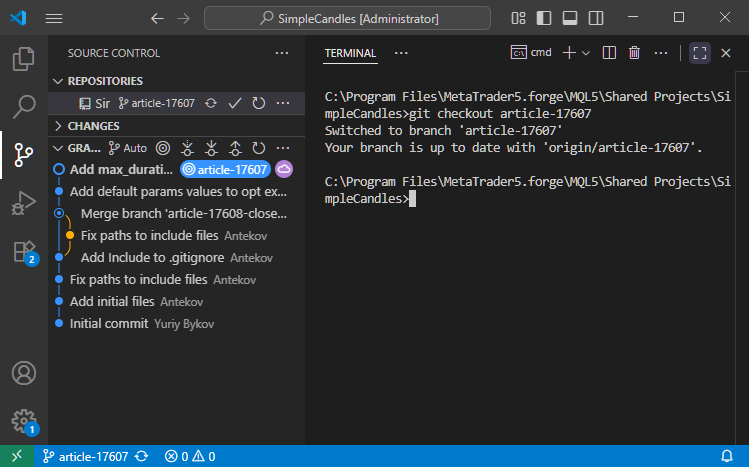
Poi unirlo a develop usando 'git merge develop':
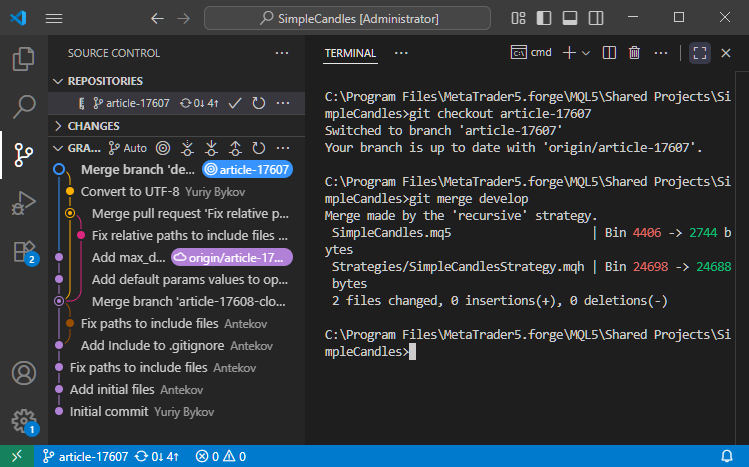
Poiché le modifiche esterne hanno interessato parti del codice che non abbiamo modificato durante il lavoro su article-17607, non sono sorti conflitti durante la fusione. Di conseguenza, Git ha creato un nuovo commit di unione.
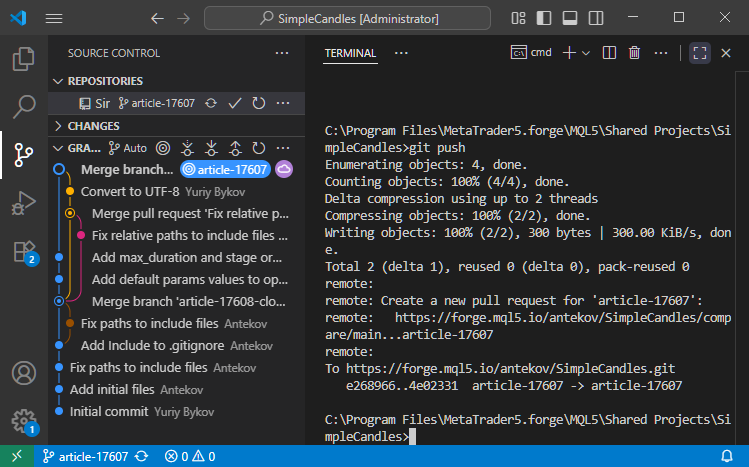
Ora eseguiamo 'git push' per inviare le informazioni aggiornate al repository remoto:
Se controlliamo il repository MQL5 Algo Forge, vedremo che i nostri passaggi di unione si sono riflessi con successo nel repository remoto:
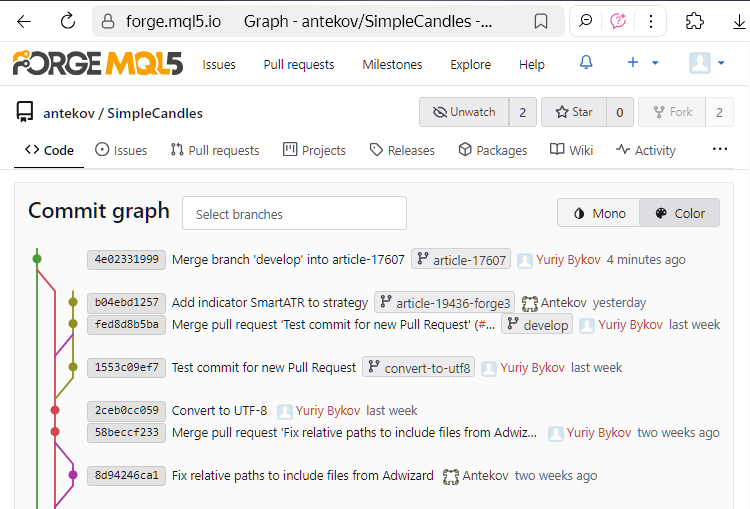
L'ultimo commit mostrato nella schermata è il commit di unione tra develop e article-17607.
Notare anche l'estremità libera del ramo article-19436-forge3, che non è ancora collegato a nessun altro ramo. Le modifiche di questo ramo non sono ancora state unite a develop, perché il lavoro è ancora in corso. Per ora lo lasciamo così com'è. Quando sarà il momento, ci torneremo.
Questo completa la preparazione per il proseguimento dello sviluppo dell'article-17607 e possiamo ora procedere con il lavoro di codifica vero e proprio. La soluzione per il compito associato a questo ramo è descritta in un altro articolo. Quindi, non lo ripeterò qui. Passiamo invece a descrivere come finalizzare e registrare lo stato raggiunto del codice dopo aver completato l'attività.
Esecuzione dell'Unione
Prima di pubblicare un particolare stato del codice, dobbiamo prima unirlo al ramo principale. Il nostro ramo principale è il main. Tutti gli aggiornamenti del ramo develop confluiranno alla fine nel ramo main. Le modifiche dalle attività dei singoli rami vengono unite in develop. Per ora non siamo pronti a unire il nuovo codice in main, quindi ci limiteremo a unire gli aggiornamenti in develop. Per dimostrare questo meccanismo, la scelta specifica del ramo principale non è particolarmente importante.
Vediamo lo stato del repository SimpleCandles dopo aver terminato il lavoro sull'attività selezionata:
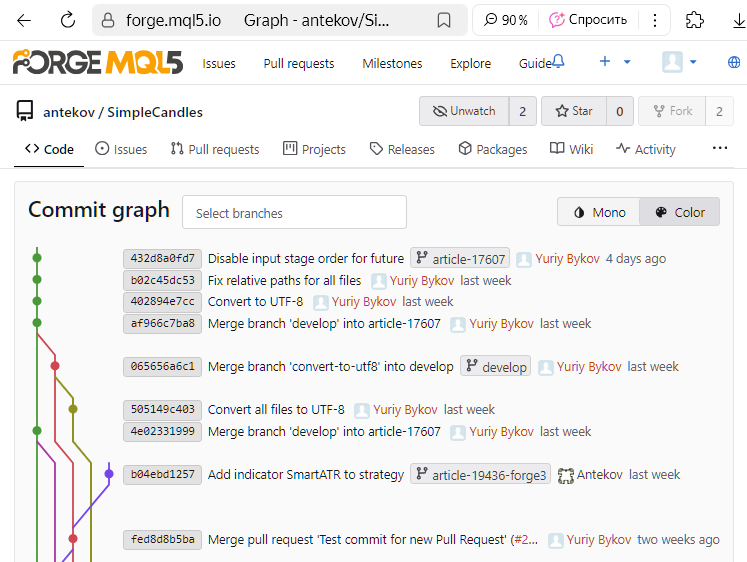
Come mostrato, l'ultimo commit è stato fatto nel ramo article-17607. Utilizzando l'interfaccia web di MQL5 Algo Forge, creiamo una Pull Request per unire questo ramo a quello di develop, come descritto in precedenza.
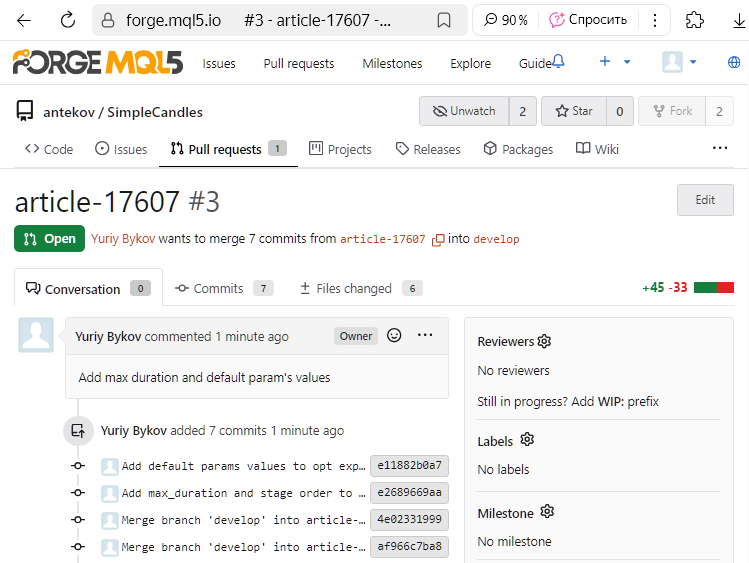
Verifichiamo che tutto sia andato come previsto. Apriamo di nuovo la pagina della cronologia dei commit con la vista ad albero dei rami:
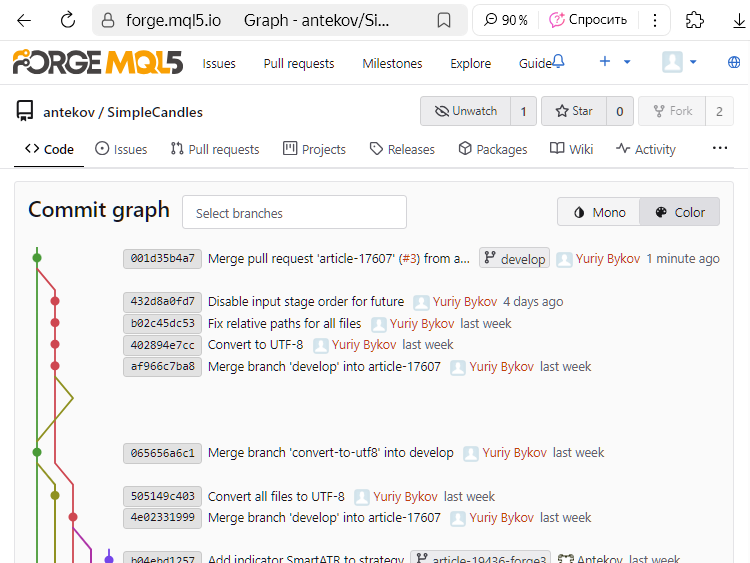
Possiamo vedere che il commit con hash 432d8a0fd7 non è più contrassegnato come ultimo in article-17607. Invece, un nuovo commit con hash 001d35b4a7 appare come l'ultimo in develop. Poiché questo commit registra la fusione di due rami, lo chiameremo merge commit.
Quindi, aprire la pagina merge commit e creare un nuovo tag. All'inizio dell'articolo abbiamo mostrato dove farlo; ora è il momento di farlo davvero:
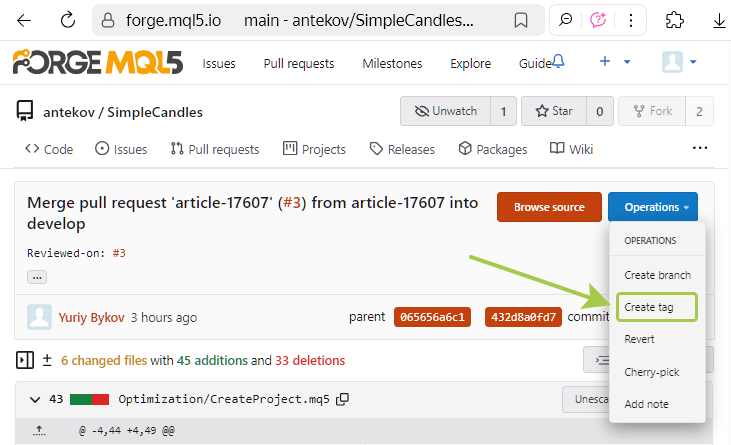
Nella finestra a comparsa, inserire il nome del tag "v0.1", poiché è ancora lontano dalla versione finale. Non sappiamo ancora quante altre aggiunte verranno fatte al progetto, ma speriamo che siano parecchie. Pertanto, un numero di versione così piccolo serve a ricordarci che c'è ancora molto lavoro da fare. Tra l'altro, sembra che l'interfaccia web non supporti attualmente la creazione di tag annotati.
Il tag è stato creato con successo e il risultato è visibile nella pagina seguente:
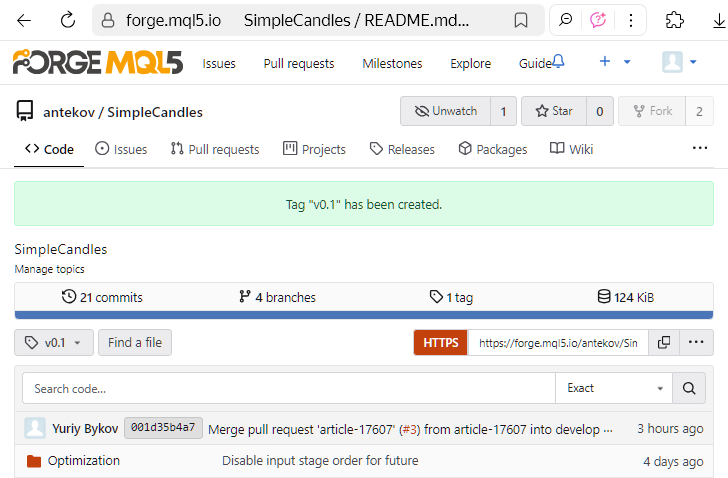
o sulla pagina tag dedicata, del repository.
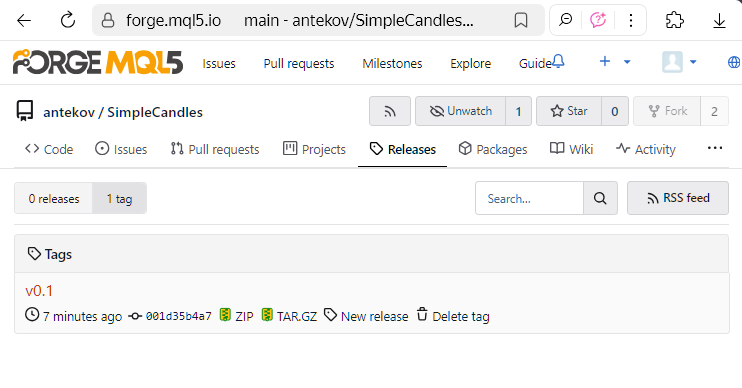
Se aggiorniamo il nostro repository locale usando 'git pull', il tag appena creato apparirà anche lì. Tuttavia, poiché MetaEditor attualmente non visualizza i tag del repository, controlliamo come appaiono in Visual Studio Code. Se si passa il mouse sul commit desiderato nell'albero dei commit, nel suggerimento appare un'etichetta colorata con il nome del tag correlato:
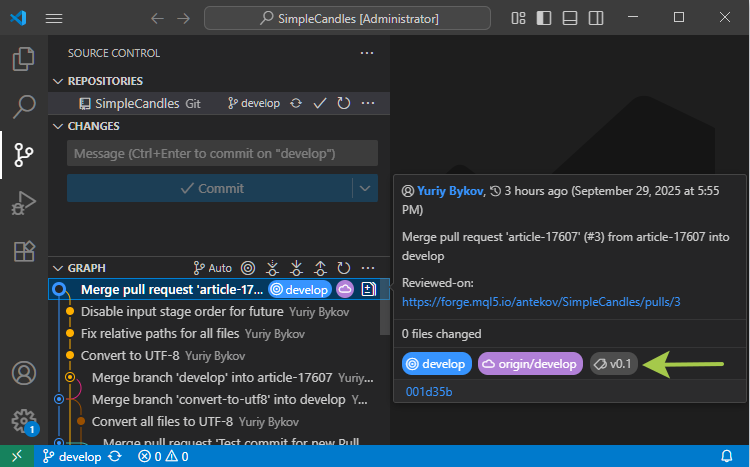
Ora che il tag è stato creato, possiamo fermarci qui e usare il suo nome in un comando 'git checkout' per passare a quello stato di codice esatto o andare oltre e creare un rilascio basato su di esso.
Creazione di un Rilascio (Release)
Una release è un meccanismo per contrassegnare e distribuire versioni specifiche di software, indipendentemente dal linguaggio di programmazione utilizzato. I commit e i rami rappresentano il flusso di sviluppo, mentre i rilasci sono i risultati ufficiali, cioè le versioni che vogliamo pubblicare. Gli scopi principali dell'utilizzo dei rilasci sono i seguenti:
- Versioni. Segniamo particolari stati del codice nel repository come stabili, ovvero privi di errori critici (almeno apparenti) e con funzionalità verificate. Altri utenti possono utilizzare queste versioni specifiche.
- Distribuzione dei binari. I rilasci possono includere file compilati o pacchettizzati (come .ex5, .dll o .zip), in modo che gli utenti non debbano compilare il progetto da soli.
- Comunicazione all'utente. Una release dovrebbe includere una descrizione, che in genere elenca le modifiche, le nuove funzionalità, i bug risolti e altre informazioni rilevanti su quella versione. L'obiettivo principale di questa descrizione è aiutare gli utenti a decidere se aggiornarsi o meno.
Un rilascio può essere creato sulla base di un tag esistente, oppure può essere generato un nuovo tag durante il processo di creazione del rilascio. Poiché abbiamo già un tag, creeremo una nuovo rilascio utilizzandolo. Per farlo, andare alla pagina dei tag del repository e fare clic su "Nuovo rilascio" accanto al tag desiderato:

- Nome del rilascio, ramo di destinazione e tag (uno esistente o uno nuovo da creare),
- Note di rilascio, ovvero un riepilogo delle novità, delle correzioni e dei problemi noti risolti,
- File allegati, ad esempio programmi compilati, documentazione o collegamenti a risorse esterne.
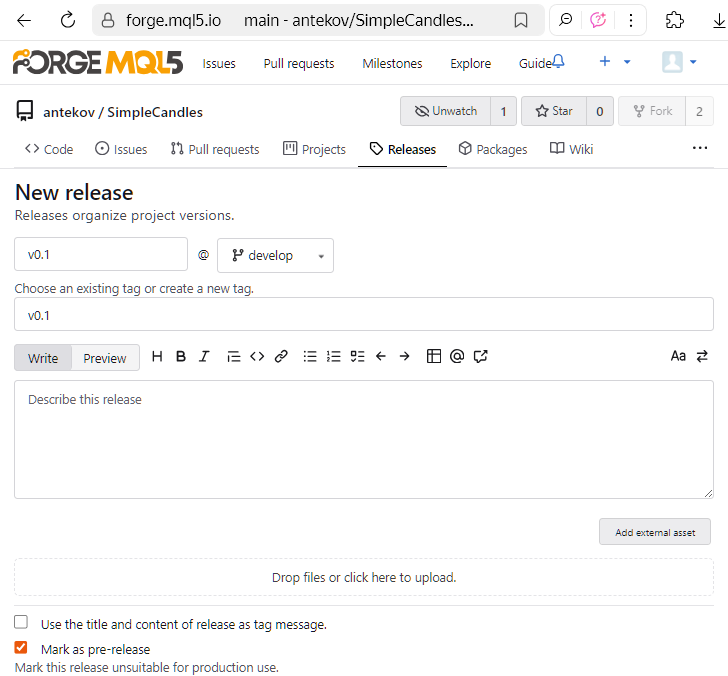
È possibile salvare un rilascio come bozza e aggiornarne i dettagli in seguito, oppure pubblicarlo subito. Anche se la pubblicazione avviene ora, è possibile apportare modifiche in seguito: ad esempio, è possibile modificare la descrizione del rilascio in un secondo momento. Una volta pubblicato, il rilascio apparirà nella pagina Rilasci del repository, visibile agli altri utenti:
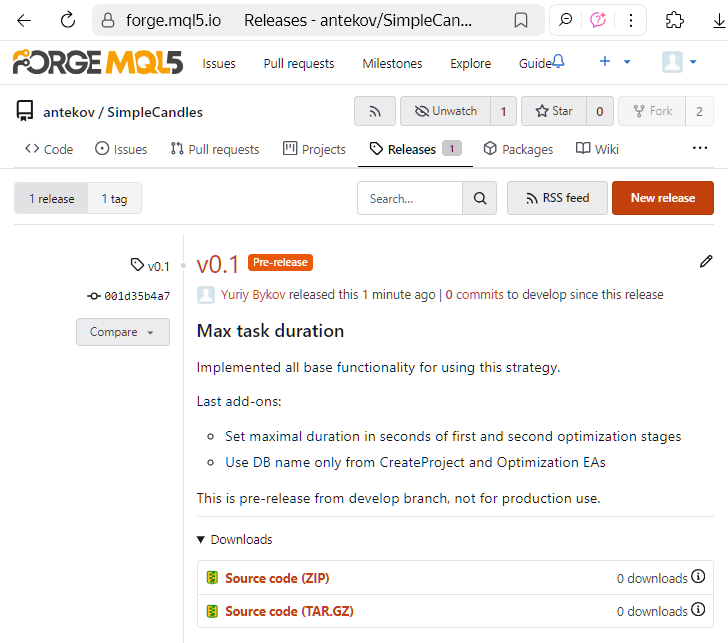
Questo è tutto! La nuova versione è ora disponibile e pronta all'uso. Poco dopo, abbiamo aggiornato il nome del rilascio (che non deve necessariamente corrispondere al nome del tag) e aggiunto un link all'articolo sopra citato che descrive la soluzione implementata.
Conclusioni
Fermiamoci un attimo a riflettere sui progressi compiuti. Non ci siamo limitati a esplorare gli aspetti tecnici del controllo di versione. Abbiamo completato una trasformazione completa, passando da modifiche sparse a un flusso di lavoro strutturato e coerente per la gestione del codice. Il traguardo più importante che abbiamo raggiunto è il passo finale: rilasciare il lavoro completato come versione ufficiale del prodotto per gli utenti finali. Il nostro repository attuale potrebbe non rappresentare ancora un progetto completamente maturo, ma abbiamo gettato le fondamenta per raggiungere quel livello.
Questo approccio cambia radicalmente la percezione del progetto. Quello che una volta era un insieme di file sorgenti è ora un sistema organizzato con una chiara cronologia delle modifiche e punti di controllo ben definiti, che ci permettono di tornare a qualsiasi stato stabile in qualsiasi momento. Questo va a vantaggio di tutti: sia degli sviluppatori che degli utenti delle soluzioni finali.
Padroneggiando questi strumenti, abbiamo elevato il nostro lavoro con il repository MQL5 Algo Forge a un nuovo livello, aprendo le porte a progetti più complessi e su larga scala in futuro.
Grazie per l'attenzione! Alla prossima!
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/19623
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso