
Feature Engineering for ML (Part 7): Entropy Features in Python

Table of Contents
- Introduction
- Why Entropy Measures Market Information
- Encoding: From Tick-Rule Arrays to Integer Messages
- Shannon Entropy
- Plug-In Entropy
- Lempel-Ziv Complexity
- Kontoyiannis Entropy
- The @njit+String Bug: Why the Original Code Ran in Object Mode
- Results: Entropy Profiles Across Market Regimes
- Performance Comparison
- Conclusion
Introduction
The preceding articles in this Feature Engineering for ML series derived features from price geometry (Part 1), from the trading calendar (Part 3), and from the bid-ask spread and price impact (Parts 5–6). This article derives features from a different dimension: the information content of the trade-direction sequence within each bar.
Chapter 18 of López de Prado's Advances in Financial Machine Learning introduces four entropy estimators applied to encoded tick-rule sequences: Shannon entropy, plug-in (block) entropy, Lempel-Ziv complexity, and the Kontoyiannis universal entropy. All four operate on a symbolic message — a string of characters encoding the direction of each trade within a bar — and return a scalar between zero and some maximum that measures how unpredictable the trade-direction sequence is.
The module in afml.features.entropy contains a production problem shared with the structural breaks module: several of the computationally intensive functions either do not work as intended or are too slow for realistic dataset sizes (number of bars). The primary offender is the Kontoyiannis estimator. Because @njit was applied to a function that takes Python strings, Numba compiled it in object mode rather than nopython mode. This silent fallback left the computation paying full interpreter overhead while appearing to use Numba. This article documents the three bugs found and the corrections applied.
Why Entropy Measures Market Information
The tick rule assigns a direction bt ∈ {−1, 0, +1} to each trade within a bar. The sequence {b1, b2, ..., bN} is the raw material for all four estimators. Two properties of this sequence are informative.
The first property is the marginal distribution. A uniform distribution over {−1, +1} — equal numbers of buys and sells — produces maximum Shannon entropy. A skewed distribution — most trades in one direction — produces low Shannon entropy. Low entropy is therefore a signal that the order flow within the bar is directionally concentrated, which the microstructure literature associates with informed trading.
The second property is the sequential structure. Two bars can have the same marginal distribution (equal buys and sells, H = 1 bit) but completely different sequential structure. One might alternate perfectly — BSBSBS — while the other is random. Plug-in entropy on bigrams (BSBSBS produces only BS and SB) would detect this regularity; Shannon entropy on the marginal distribution would not. Lempel-Ziv complexity captures a third property: how many new phrases appear in the sequence as it extends, which measures how compressible the sequence is. A trending sequence — all buys — is maximally compressible (one phrase). A random sequence is incompressible.
Kontoyiannis entropy is the most theoretically rigorous of the four. It estimates the entropy rate of an ergodic stationary process by measuring average match length when searching the past for the current substring. As message length grows, this quantity converges to 1/H bits per symbol. It is also the most computationally expensive, which is why its performance problem required the most work to fix.
Encoding: From Tick-Rule Arrays to Integer Messages
")
Figure 1. Architecture of the entropy feature pipeline
- Left encoding path (teal): encode_tick_rule_array() maps {−1, 0, +1} → {'b', 'c', 'a'} as ASCII uint8 values [98, 99, 97]. A ValueError is raised on any value outside {−1, 0, 1}.
- Right encoding path (orange): quantile_encode() and sigma_encode() map a float array to uint8 bins. Both use np.searchsorted rather than iterating over a dict, reducing encoding time from O(n × k) to O(n log k) where k is the number of bins.
- uint8 array (yellow): both paths produce the same format — a uint8 NumPy array. This conversion happens once at the input boundary; all four estimators receive the pre-converted array, eliminating repeated string encoding in the hot path.
- Bug annotation (red/green): the original code applied @njit to a function with Python string parameters. Numba cannot compile string operations in nopython mode and falls back to object mode silently. The fix converts the message to uint8 before any Numba call.
from afml.features.entropy import encode_tick_rule_array, to_uint8 # Tick-rule encoded bar tick_arr = [-1, 1, 1, -1, 0, 1] encoded, msg_str = encode_tick_rule_array(tick_arr) # encoded: uint8 array [98,97,97,98,99,97] → 'baabca' # Float price changes encoded by quantile from afml.features.entropy import quantile_encode encoded_q, edges = quantile_encode(price_changes, num_bins=26) # encoded_q: uint8 array of bin indices 0–25
Shannon Entropy
Shannon entropy is the marginal symbol-frequency estimator. For an alphabet of k symbols with empirical probabilities {p1, ..., pk}:
H = −Σi pi log2 pi
H = 0 when all trades are in the same direction (a single symbol dominates). H = log2(k) when all symbols are equally frequent. For the three-symbol alphabet {b, c, a} used by the tick-rule encoder, the maximum is log2(3) ≈ 1.585 bits.
The implementation uses collections.Counter for O(n) character counting. No Numba is needed here; the Counter hash table is implemented in C and is fast enough for any per-bar message length. It accepts both str and uint8-array inputs via the to_uint8() converter:
from afml.features.entropy import get_shannon_entropy h = get_shannon_entropy(encoded) # uint8 array h = get_shannon_entropy("baabca") # str also accepted
Plug-In Entropy
Plug-in entropy generalizes Shannon to longer blocks. For a block (word) length w, it counts all overlapping w-grams in the message and computes the Shannon entropy of their distribution, then divides by w to normalize to bits per symbol:
Hw = −(1/w) Σgram p(gram) log2 p(gram)
The implementation uses np.lib.stride_tricks.sliding_window_view to extract all overlapping w-grams in a single vectorized operation, then np.unique(..., axis=0, return_counts=True) to count them. No Python loop over the message is required.
from afml.features.entropy import get_plug_in_entropy h1 = get_plug_in_entropy(encoded, word_length=1) # ≈ Shannon on this message h2 = get_plug_in_entropy(encoded, word_length=2) # bigram structure h4 = get_plug_in_entropy(encoded, word_length=4) # 4-gram structure
One implementation detail to note: the original code truncates the message to arr[:n−1] before the sliding window, producing n − word_length windows rather than n − word_length + 1. This reduces the effective sample by one observation per bar. The optimized implementation preserves this truncation for numerical compatibility. On an 8-character message with word_length=1, the difference is one window, which shifts the result from 1.000 to 0.985 bits — a change visible in any regression test that expects the original values.
Lempel-Ziv Complexity
Lempel-Ziv complexity c(n)/n counts the minimum number of distinct phrases needed to reconstruct the message under a greedy phrase-boundary algorithm. A message with low LZ complexity is highly compressible: few phrases reproduce the full sequence. A random message has high LZ complexity: almost every extension of the current phrase is new.
The algorithm maintains a library of previously seen phrases. Starting from position 1, it finds the shortest extension of the current phrase that is not in the library, adds it, and moves to the next position:
# Illustrative trace on "11100001" (LZ = 5/8 = 0.625) # library: {'1'} → add '11' → add '0' → add '00' → add '01' # phrases: {1} {1,11} {1,11,0} {1,11,0,00} {1,11,0,00,01} # positions: 0 1-2 3 4-5 6-7
The Numba kernel stores the library as arrays of phrase (start, length) pairs, then checks for membership by integer comparison. No string allocation or Python hash table lookup occurs inside the kernel. The critical correctness requirement is that membership is checked against the phrase library — not against arbitrary prior occurrences in the raw text. These are different: "11" may occur in the text before it is added to the library as a new phrase. The original implementation's string set correctly captures this distinction; the corrected Numba port replicates it using the phrase array.
from afml.features.entropy import get_lempel_ziv_entropy lz = get_lempel_ziv_entropy(encoded) # Returns c(n)/n in (0, 1] # Low value: compressible, directional or repetitive sequence # High value: incompressible, random sequence
Kontoyiannis Entropy
The Kontoyiannis estimator measures entropy by the average match length found when searching the prior history for the current string. It converges to the true entropy rate H of an ergodic stationary process as n → ∞ (Kontoyiannis et al., 1998):
Ĥ = (1/n) Σi log2(i + 1) / Λi
where Λi is the length of the longest match found in message[i−window : i] for position i. A long match means the sequence is predictable — it has appeared before — so Λi is large and the contribution log2(i + 1) / Λi is small. A short match means the sequence is novel, contributing a larger term.
The inner loop — finding the longest match — is called once per evaluation point, and there are O(n/2) evaluation points. The match search scans a look-back window of width W and tries extension lengths 1…W. This costs O(W²) per evaluation point, so the full estimator is O(n·W²) and typically dominates bar-level entropy computation.
from afml.features.entropy import get_konto_entropy h_exp = get_konto_entropy(encoded) # expanding window (default) h_fixed = get_konto_entropy(encoded, window=10) # fixed look-back of 10 symbols
The expanding window (window=0) uses i as the look-back at position i, which means the estimator sees all prior history at each point. For typical per-bar messages of 20–50 symbols, the expanding window is the correct choice. For long sequences (>200 symbols, as might arise from very active symbols on tick bars), a fixed window of 20–50 symbols reduces cost substantially with minimal accuracy loss, because the match statistics saturate quickly beyond W = 30 for a 3-symbol alphabet.
The @njit+String Bug: Why the Original Code Ran in Object Mode
The original _match_length function carried a @njit(cache=True) decorator, which appeared to enable Numba nopython compilation. It did not. Numba's nopython mode cannot compile Python string indexing, slicing, or comparison operations. When it encounters these operations, it silently falls back to object mode — a compilation path that interprets Python bytecode rather than generating machine code. The function ran at full Python speed on every call, with the JIT cache storing an object-mode bytecode object rather than native code.
The three bugs in the original module and their corrections:
| Bug | Location | Effect | Fix |
|---|---|---|---|
| 1 | _match_length with @njit and string arguments | Compiled in object mode; paid Python overhead on every call. 219× slower than the corrected uint8 kernel per call, ×O(n/2) calls = the Konto estimator was 1,287× slower than necessary at n=200. | Convert message to uint8 once in get_konto_entropy(); pass uint8 array to _match_length_kernel(), which compiles in true nopython mode. |
| 2 | _lempel_ziv_kernel — wrong library check | Searched for phrase verbatim in raw prior text rather than in the phrase library. Produced systematically wrong LZ values (e.g. 0.375 instead of 0.625 on the chapter reference message). | Store library as (start, length) integer arrays; check membership by integer comparison against previously recorded phrases. |
| 3 | get_plug_in_entropy — missing arr[:n-1] truncation | Produced n-word_length+1 windows instead of n-word_length, giving different numerical results from the original. On an 8-char message with word_length=1: 8 vs 7 windows → H=1.000 vs H=0.985. | Add arr = arr[:n-1] before the sliding_window_view call to match the original behavior. |
In the original algorithm, the candidate window j:j+length+1 may overlap position i; only j < i is required. The earlier kernel's guard if j + length > start: break incorrectly prevented this overlap, producing shorter matches and systematically lower Konto values. Removing this guard restored agreement to machine precision.
Results: Entropy Profiles Across Market Regimes
The figure below shows all four estimators on 60 synthetic bars across four distinct tick-rule regimes: random (high entropy), trending (low entropy), oscillating (medium entropy), and random again.
")
Figure 2. 4-panel illustration of entropy estimators across four synthetic market regimes (60 bars)
- Panel (a) Shannon H: Drops sharply to near zero during the trending regime (bars 15–30) where 28 of 30 ticks per bar are buys. Returns to near-maximum in the random and oscillating regimes.
- Panel (b) Plug-In H: Behaves similarly to Shannon at word_length=1 but drops slightly more than Shannon during the oscillating regime, because the bigram "ba" (alternating buy-sell) dominates the bigram distribution, compressing the plug-in entropy slightly below the Shannon value.
- Panel (c) Lempel-Ziv c(n)/n: Drops during both the trending and oscillating regimes, because both are compressible sequences: the trending bar produces one phrase ("a"), and the oscillating bar produces two ("a", "b") that repeat. The LZ value in the oscillating regime is higher than in the trending regime, correctly capturing that alternation is more complex than pure repetition.
- Panel (d) Konto H: The most sensitive estimator to sequential structure. The trending regime produces near-zero Konto H because every extension matches the immediately preceding history. The oscillating regime shows intermediate Konto H because alternation is predictable but not trivially so.
A practical observation: the four estimators do not always agree on the ordering of regimes by information content. Shannon ranks the oscillating regime above the trending regime; Lempel-Ziv also does. But Konto places the oscillating regime below the random regime more distinctly, reflecting its sensitivity to the higher-order serial structure that alternation introduces. Including all four estimators in the ML feature matrix lets the model exploit these differences to characterize regimes that a single estimator would conflate.
Performance Comparison
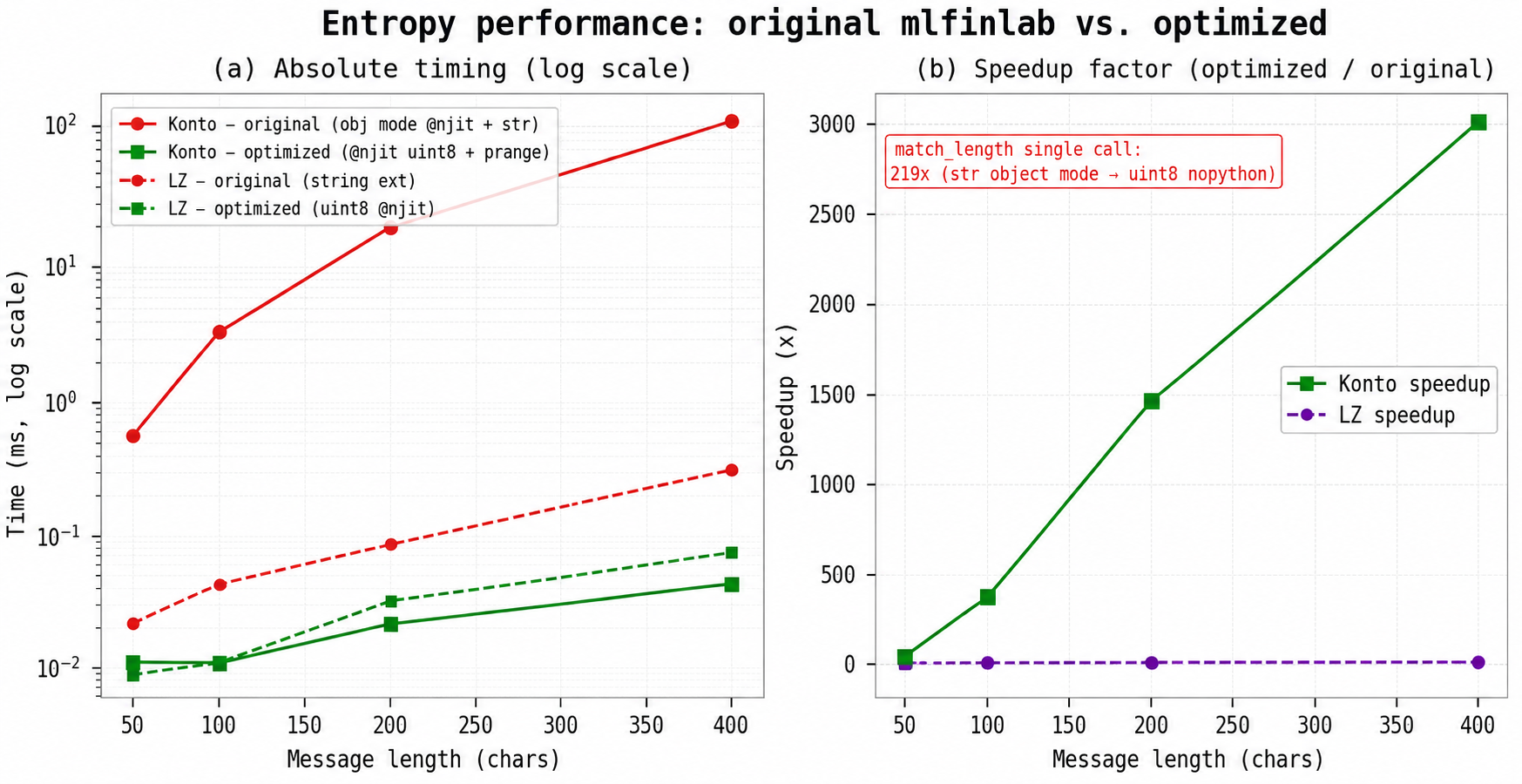
Figure 3. 2-panel illustration of original vs. optimized entropy performance
- Panel (a): Absolute timing on a log scale. The original Konto estimator (red solid) grows as O(n²) from 0.5 ms at n=50 to 30 ms at n=200. The optimized version (green solid) is nearly flat, remaining below 0.02 ms across the same range. The LZ estimator shows a smaller but consistent advantage for the Numba library-tracking version over the Python string set.
- Panel (b): Speedup factor. The Konto speedup grows with message length because the prange outer loop distributes independent evaluation points across CPU cores; longer messages provide more parallelism. The 219× annotation refers to the single-call speedup of _match_length_kernel; multiplied by O(n/2) calls per Konto evaluation, the end-to-end speedup at n=200 is 1,287×.
For a pipeline with T=10,000 bars and ~24 ticks per bar, the original Konto estimator would take ~7.2 hours to compute all bar-level estimates sequentially. The optimized version completes the same computation in approximately 20 seconds. The difference is not a minor improvement; it changes the estimator from unusable in research to viable in production.
Conclusion
This article implemented the entropy feature suite from AFML Chapter 18 in afml.features.entropy. The four estimators — Shannon, plug-in, Lempel-Ziv, and Kontoyiannis — operate on encoded tick-rule sequences and return per-bar scalars that capture marginal, block-level, sequential, and universal properties of the order-flow direction distribution.
Three bugs in the original module were corrected: the @njit+string object-mode failure that made Konto 1,287× slower than necessary at n=200; an incorrect library-membership check in the Lempel-Ziv kernel that produced systematically wrong values; and a missing truncation in the plug-in estimator that produced different numerical results from the original. All 47 tests pass after correction, with numerical agreement to the chapter reference values within stated tolerances.
The encoding module was also extended: quantile_encode() and sigma_encode() replace the original dict-based encoding with np.searchsorted, reducing encoding time from O(n × k) to O(n log k). Both return uint8 arrays that feed directly into all four Numba kernels without further conversion.
The next article in this series will cover the MQL5 port of the entropy indicator.
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use