SuperTrend AI Clustering MT5
- Indikatoren
-
Minh Truong Pham
 Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
Hello, my name is Pham and I am a programmer and trader! At here, I create amazing forex indicators and expert advisors for Metatrader.
I will try:
+ Provide best tools base on my 5 years experience as a trader and 10 years as a programmer. - Version: 1.3
- Aktualisiert: 19 November 2024
- Aktivierungen: 5
Der SuperTrend AI-Indikator ist ein neuartiger Ansatz, um die Lücke zwischen der maschinellen Lernmethode K-Means-Clustering und technischen Indikatoren zu schließen. In diesem Fall wenden wir K-Means-Clustering auf den berühmten SuperTrend-Indikator an.
🔶 ANWENDUNG
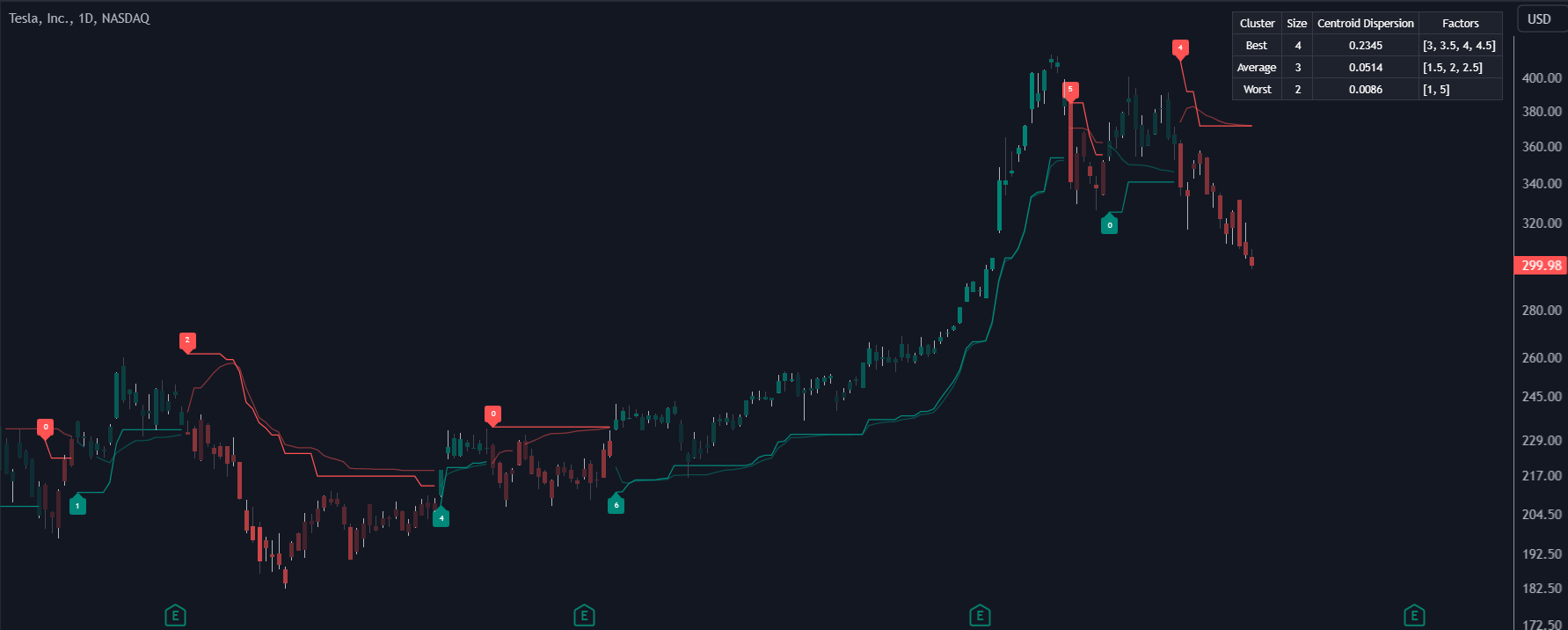
Benutzer können den SuperTrend AI Trailing Stop ähnlich wie den regulären SuperTrend-Indikator interpretieren. Die Verwendung höherer Minimum/Maximum-Faktoren führt zu längerfristigen Signalen. (Abbildung 1)
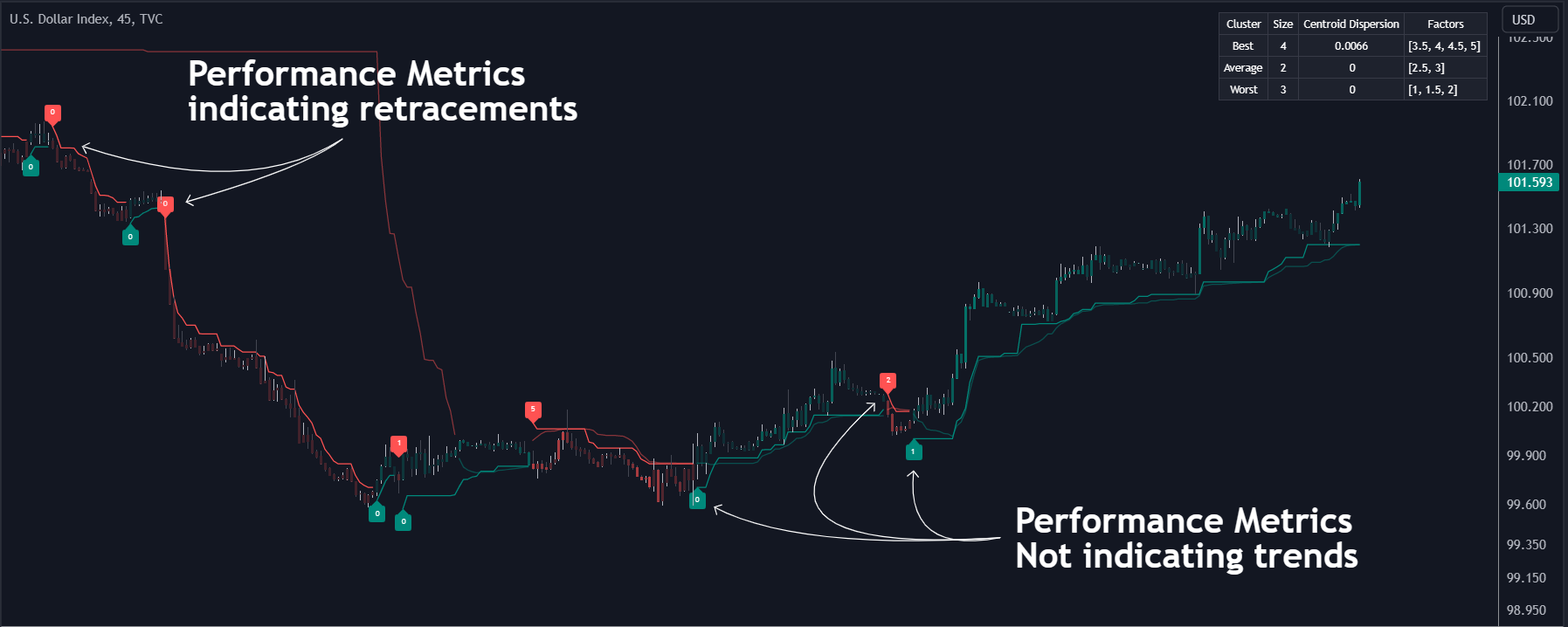
Die für jedes Signal angezeigten Leistungskennzahlen ermöglichen eine tiefere Interpretation des Indikators. Höhere Werte deuten darauf hin, dass sich der Markt eher in Richtung des Trends bewegt, während Signale mit niedrigeren Werten wie 1 oder 0 auf Rücksetzer hindeuten können. (Abbildung 2)
In der obigen Abbildung sehen wir deutlichere Beispiele für die Leistungskennzahlen von Signalen, die auf Trends hindeuten. Allerdings können diese Leistungskennzahlen nicht jedes Signal zuverlässig vorhersagen. (Abbildung 3)
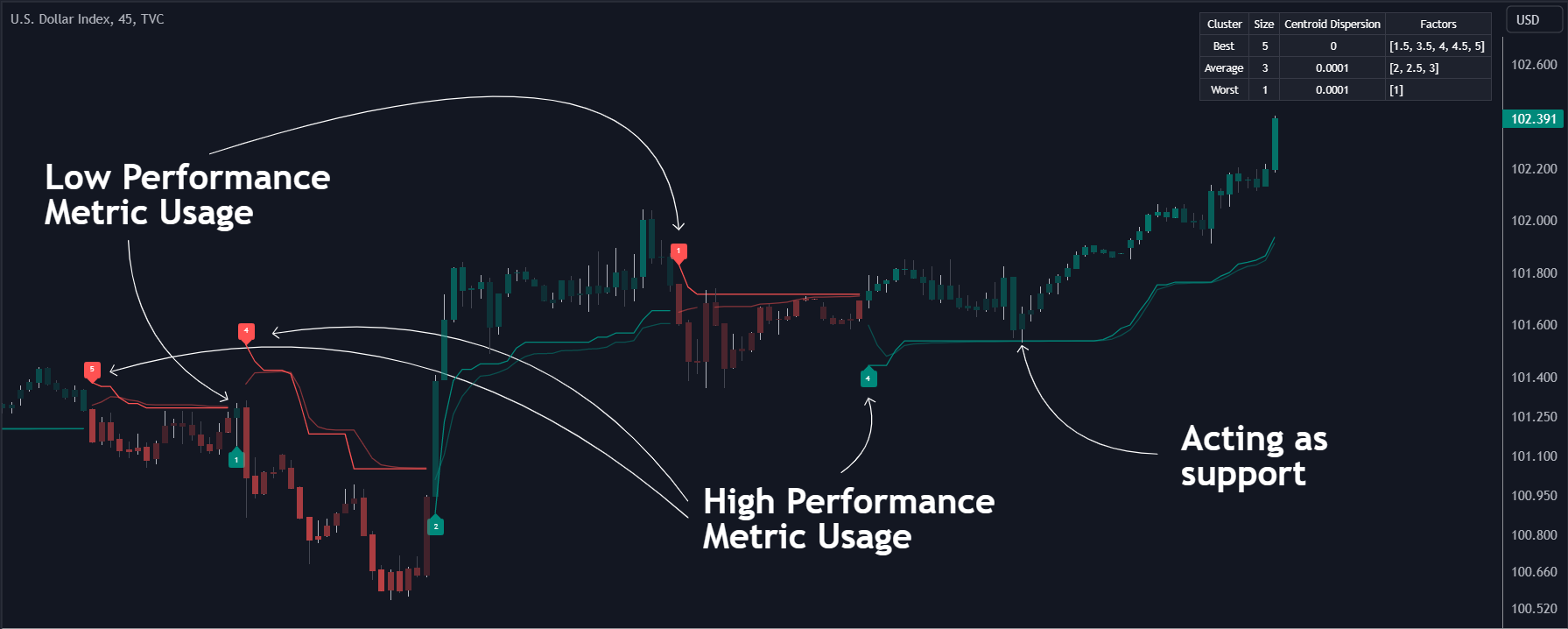
In der obigen Abbildung ist zu erkennen, dass der Trailing-Stop und sein adaptiver gleitender Durchschnitt auch als Unterstützung und Widerstand fungieren können. Durch die Verwendung höherer Werte für die Performance-Memory-Einstellung kann der Benutzer einen längerfristigen adaptiven gleitenden Durchschnitt des zurückgegebenen Trailing-Stops erhalten.
🔶 DETAILS
🔹 K-Means Clustering (Bild 4)
Es gibt verschiedene Methoden, um Cluster in Daten zu finden. Die in diesem Skript verwendete Methode ist dasK-Means-Clustering, eine einfache iterative, nicht überwachte Clustering-Methode, die eine vom Benutzer festgelegte Anzahl von Clustern findet.
Einenaive Form des K-Means-Algorithmus würde die folgenden Schritte durchführen, umK Cluster zu finden:
- (1) Bestimmen Sie die Anzahl (K) der zu erkennenden Cluster.
- (2) Setzen Sie unsere K Zentren (Clusterzentren) mit Zufallswerten ein.
- (3) Schleife über die Datenpunkte und Bestimmung des nächstgelegenen Schwerpunkts von jedem Datenpunkt, dann Zuordnung dieses Datenpunkts zum Schwerpunkt.
- (4) Aktualisieren Sie die Zentroide, indem Sie den Durchschnitt der Datenpunkte bilden, die einem bestimmten Zentroid zugeordnet sind.
- Wiederholen Sie die Schritte 3 bis 4 bis zur Konvergenz, d. h. bis sich die Schwerpunkte nicht mehr ändern.
Um die Funktionsweise von K-Means grafisch zu erläutern, nehmen wir das Beispiel eines eindimensionalen Datensatzes (das ist die in unserem Skript verwendete Dimension) mit zwei offensichtlichen Clustern: (Abbildung 5)
Dies ist natürlich ein einfaches Szenario, daKim Allgemeinen höher ist , ebenso wie die Menge der Datenpunkte. Beachten Sie, dass diese Methode sehr empfindlich auf die Initialisierung der Zentren reagieren kann, weshalb sie im Allgemeinen mehrfach ausgeführt wird, wobei der Durchlauf, der die besten Zentren liefert, beibehalten wird.🔹 Adaptive SuperTrend Factor Using K-Means
Der vorgeschlagene Indikator basiert auf der folgenden Hypothese:
Bei mehreren Instanzen eines Indikators mit unterschiedlichen Einstellungen ist die optimale Einstellung zum Zeitpunktt durch die beste Instanz mit der Einstellung s (t) gegeben.
Die Berechnung des Indikators mit der besten Einstellung zum Zeitpunktt würde einen Indikator ergeben, dessen Merkmale sich aufgrund seiner Leistung anpassen. Was aber, wenn die Einstellung der besten Instanz und der zweitbesten Instanz des Indikators stark voneinander abweichen, ohne dass ein großer Unterschied in der Leistung besteht?
Auch wenn dieser spezielle Fall selten ist, so ist es doch nicht ungewöhnlich, dass die Leistung für eine Gruppe spezifischer Einstellungen ähnlich sein kann (dies könnte in einer Heatmap zur Parameteroptimierung beobachtet werden), dann kann das Herausfiltern wünschenswerter Einstellungen, um nur die beste zu verwenden, zu streng erscheinen. Wir können daher unsere erste Hypothese umformulieren:
Bei mehreren Instanzen eines Indikators mit unterschiedlichen Einstellungen ist eine optimale Einstellungswahl zum Zeitpunktt durch den Durchschnitt der leistungsstärksten Instanzen mit den Einstellungen s (t) gegeben.
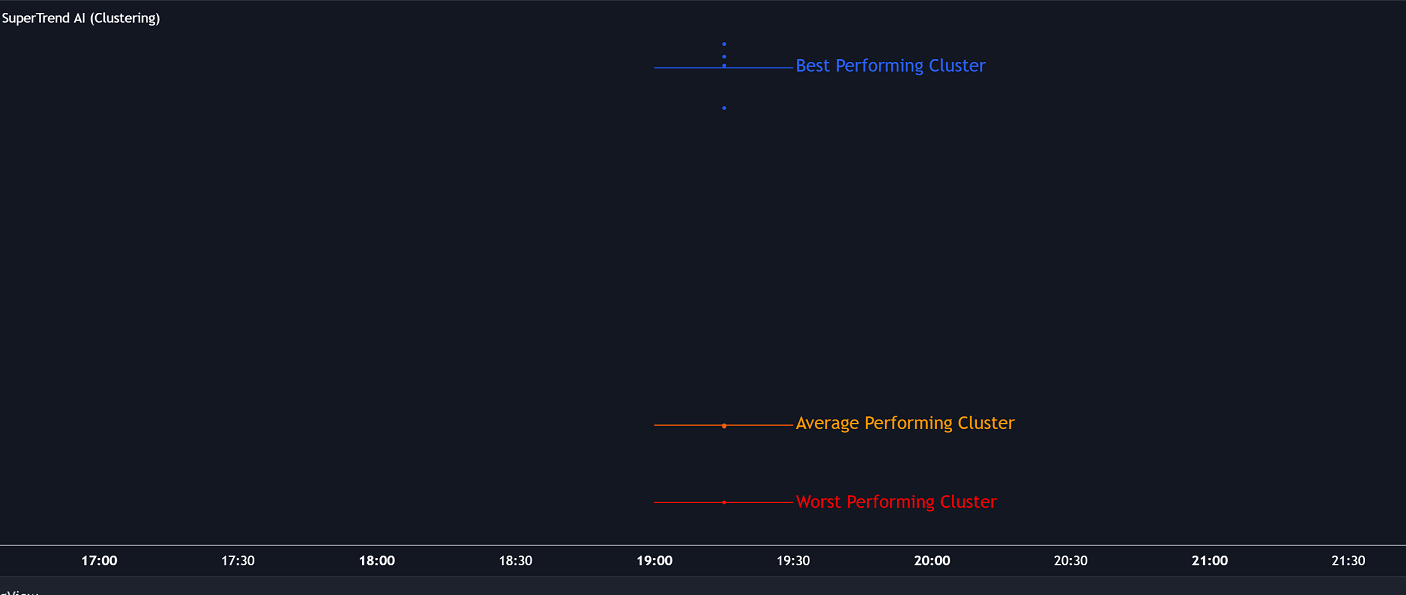
Die Suche nach dieser Gruppe von Instanzen mit der besten Leistung könnte mit der zuvor beschriebenen K-Means-Clustermethode erfolgen, wobei drei Gruppen von Interesse (K = 3) angenommen werden, die als schlechteste Leistung, durchschnittliche Leistung und beste Leistung definiert sind.
Wir erhalten zunächst ein Analogon der Leistung P (t, Faktor), das wie folgt beschrieben wird :
P(t, factor) = P(t-1, factor) + α * (∆C(t) × S(t-1, factor) - P(t-1, factor))wobei 1 > α > 0, das Leistungsgedächtnis, das das Ausmaß bestimmt, in dem ältere Eingaben die aktuelle Ausgabe beeinflussen. C(t) ist der Schlusskurs und S (t, Faktor) ist die SuperTrend-Signalerzeugungsfunktion mit multiplikativem Faktor.
Wir führen diese Leistungsfunktion für mehrere Faktoreinstellungen ausund führen ein K-Means-Clustering auf den mehreren erhaltenen Leistungen durch, um den leistungsstärksten Cluster zu erhalten. Für eine schnellere Konvergenz der Zentroide verwenden wir Quartile der erzielten Leistungen. (Abbildung 6)
Beachten Sie, dass wir dem Benutzer die Freiheit geben, den endgültigen Faktor aus dem besten, durchschnittlichen oder schlechtesten Cluster für experimentelle Zwecke zu erhalten.
🔶 EINSTELLUNGEN
- ATR-Länge: ATR-Periode, die für die Berechnung der SuperTrends verwendet wird.
- Faktorbereich: Bestimmen Sie die minimalen und maximalen Faktorwerte für die Berechnung der SuperTrends.
- Schritt: Inkremente des Faktorbereichs.
- Leistungsspeicher: Legen Sie fest, inwieweit sich ältere Eingaben auf die aktuelle Ausgabe auswirken, wobei höhere Werte längerfristige Leistungsmessungen ergeben.
- Von Cluster: Legt fest, welcher Cluster verwendet wird, um den endgültigen Faktor zu erhalten.
🔹 O ptimierung
Diese Gruppe von Einstellungen wirkt sich auf die Laufzeitleistung des Skripts aus.
- Maximale Iterationsschritte: Maximale Anzahl von Iterationen, die für die Suche nach den Schwerpunkten zulässig sind. Zu niedrige Werte können zu einer besseren Ladezeit des Skripts, aber zu einer schlechteren Clusterbildung führen.
- Berechnung der historischen Balken (Rückblick): Berechnungsfenster des Skripts (in Balken). Höhere Werte als 500 können zu einer langsamen Leistung führen. Getestet bei 300 für beste Ergebnisse.