
神经网络实践:伪逆 (二)

概述
欢迎大家阅读关于神经网络的新文章。
在上一篇文章 "神经网络实践:伪逆 (一)"中,我展示了如何使用 MQL5 库中的一个函数来计算伪逆。然而,与许多其他编程语言一样,MQL5 库中的方法旨在使用矩阵或至少一些可能类似于矩阵的结构来计算伪逆。
尽管本文展示了如何执行两个矩阵的乘法,甚至是因式分解来得到任何矩阵的行列式(这对于知道矩阵是否可以求逆很重要),但我们仍然需要再实现一个因式分解。这是必要的,这样您就可以理解如何执行因子分解来获得伪逆值。这种因式分解包括生成逆矩阵。
但是转置呢?在上一篇文章中,我展示了如何执行因子分解,模拟矩阵与其转置的乘法。因此,执行这样的操作不是问题。
然而,我们尚未实现的计算,即找到矩阵的逆,我不打算详细介绍。不是因为复杂性,而是因为这些文章旨在教育而不是指导实现特定功能。因此,我决定在这篇文章中采取不同的方法。我们将使用从一开始就使用的数据深入研究伪逆的因式分解,而不是专注于计算矩阵逆所需的通用因式分解。换句话说,我们将采用一种专门的方法,而不是提出一种通用的方法。最好的部分是,与我们在创建因子分解时遵循一般逻辑(如前一篇文章所示,这些函数是通用的)相比,你会更好地理解为什么一切都是这样工作的。您将看到,如果我们以专门的方式进行计算,可以更快地执行计算。现在,让我们探索一个新的主题来更好地理解这个概念。
当我们可以专门化时,为什么要泛化?
本节的标题可能看起来有争议,或者至少对一些人来说很难理解。许多程序员更喜欢开发高度通用的解决方案,他们相信,通过创建通用实现方案,他们将拥有广泛适用且通常高效的工具。他们努力设计适用于任何情况的解决方案。然而,这种追求泛化的代价并不总是必要的。如果一种专门的方法更有效地实现了同样的目标,为什么要泛化呢?在这种情况下,泛化并不能带来任何有意义的优势。
如果你认为我在说奇怪的事情,让我们稍微讨论一下,然后你就会明白我想解释什么。让我通过一个例子来说明这一点。请考虑以下问题:
什么是计算机,为什么它包含这么多组件?为什么新的硬件创新经常取代软件解决方案?
如果你不到 40 岁或 1990 年后出生,没有研究过旧技术,我要说的话可能会让人感到惊讶。在 20 世纪 70 年代和 80 年代初,计算机与现在完全不同。让你了解一下,视频游戏完全是使用晶体管、电阻器、电容器和其他分立元件在硬件中编程的。基于软件的游戏并不存在,一切都在硬件中实现。现在,想象一下,仅仅用电子元件创建像 PONG 这样的简单游戏是多么困难。当时的工程师们技术精湛,令人难以置信。
然而,使用分立元件,如晶体管、电阻器和电容器,意味着系统运行缓慢,必须保持简单。当第一批组装套件,如 Z80 或 6502 处理器推出时,一切都开始发生变化。这些处理器(今天仍然可用)使在软件中编程计算比在硬件中实现计算更容易、更快。这标志着软件时代的到来。这与神经网络和我们目前的实现有什么关系?耐心点,亲爱的读者,我们会讲到那里的。
使用简单指令对相对复杂的任务进行编程的能力使计算机变得极其通用。许多创新始于软件,因为软件的开发和改进更快。一旦完善,某些功能可能会过渡到硬件实现,以提高效率。这种进步在 GPU 中很明显,在 GPU 中,许多最初在软件中开发的功能在整合到硬件之前会随着时间的推移进行优化。这使我们回到了本次讨论的主题。虽然泛化是可能的,但它通常会导致效率低下 — 不是在开发过程中,而是在执行过程中。通用实现通常需要额外的测试,以确保在执行过程中不会出现意外错误。另一方面,专门的方法不太容易出错,可以优化以实现更快的执行。
您可能会想知道为什么在数据库中只使用四个值时这很重要。这就是原因,亲爱的读者。我们经常开始创建一个能够处理小数据集的系统,逐渐扩展以处理更大的数据量。最终,执行时间变得低效。此时,硬件专业化变得必要,以执行之前使用软件执行的相同计算。这正是新硬件技术诞生的方式。
如果你一直在关注硬件开发,你可能已经注意到专业技术的趋势。但这是为什么呢?这种趋势的出现是因为基于软件的解决方案最终变得比基于硬件的替代方案更不划算。在急于购买宣传为加速神经网络计算的新 GPU 之前,重要的是首先了解如何优化现有的硬件。这需要专门的计算,而不是通用的计算。因此,我们将专注于优化伪逆的计算。我决定实现一个更专业的计算,而不是创建一篇展示如何分解伪逆的通用计算的文章。虽然请注意,它不会在计算能力方面进行优化,因为它的目的是训练,它在这方面效率不高。我说的优化是指一切都将实现。在需要在专用硬件上实现因子分解的情况下,我们不会达到计算能力的最大化。这正是新设备技术出现时发生的情况。
关于具有神经网络计算能力的 GPU 和 CPU,已经有很多讨论。但这种方法真的是您所需要的吗?要回答这个问题,我们首先需要从软件的角度了解正在发生什么。现在让我们继续下一个主题,我们将看看在软件方面会实现什么。
伪逆:建议的方法
到目前为止,我希望你能理解关键点。现在让我们考虑以下内容:在我们的数据库中,每条信息都可以可视化为具有 X 和 Y 坐标的二维图。这种可视化使我们能够在数据点之间建立数学关系。从本系列开始,我们就探索了线性回归作为实现这一目标的一种手段。在之前的文章中,我解释了如何执行标量计算来找到斜率和截距,这使我们能够推导出下面所示的方程。
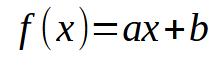
在这种情况下,所需的点是 < a > 和 < b > 值 。然而,还有另一种方法涉及矩阵分解。具体来说,我们需要实现一个伪逆。计算结果如下。
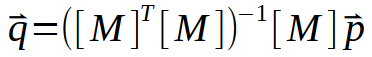
这里,常数 < a > 和 < b > 的值位于向量 < q > 中。要计算 < q >,矩阵 M 必须经过一系列分解。然而,最有趣的部分在于下图所示的过程:
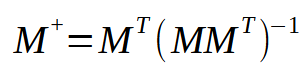
这张图片中正是我们需要实现的,它代表了在伪逆中发生的事情。请注意,得到的矩阵有一个特殊的名称:伪逆。如上图所示,它与向量 < p > 相乘,得到向量 < q >。这个向量 < q > 就是我们想要得到的结果。
在上一篇文章和本文开头,我们提到伪逆函数是在库中实现的,因此使用了矩阵。但这里我们不使用矩阵,我们使用类似的东西:数组。因此,在这一点上,我们有一个问题,其解决方案要么将数组转换为矩阵,要么为数组实现伪逆。由于我想展示计算是如何实现的,我们将选择第二种方法,即伪逆实现。相关计算如下。
01. //+------------------------------------------------------------------+ 02. matrix __PInv(const double &A[]) 03. { 04. double M[], T[4], Det; 05. 06. ArrayResize(M, A.Size() * 2); 07. M[0] = M[1] = 0; 08. M[3] = (double)A.Size(); 09. for (uint c = 0; c < M[3]; c++) 10. { 11. M[0] += (A[c] * A[c]); 12. M[2] = (M[1] += A[c]); 13. } 14. Det = (M[0] * M[3]) - (M[1] * M[2]); 15. T[0] = M[3] / Det; 16. T[1] = T[2] = -(M[1] / Det); 17. T[3] = M[0] / Det; 18. ZeroMemory(M); 19. for (uint c = 0; c < A.Size(); c++) 20. { 21. M[(c * 2) + 0] = (A[c] * T[0]) + T[1]; 22. M[(c * 2) + 1] = (A[c] * T[2]) + T[3]; 23. } 24. 25. matrix Ret; 26. Ret.Init(A.Size(), 2); 27. for (uint c = 0; c < A.Size(); c++) 28. { 29. Ret[c][0] = M[(c * 2) + 0]; 30. Ret[c][1] = M[(c * 2) + 1]; 31. } 32. 33. return Ret; 34. } 35. //+------------------------------------------------------------------+
上面展示的这个片段为我们完成了所有的工作。乍一看,它可能有点复杂,但实际上,它非常简单高效。从本质上讲,我们要处理的是一个数组,其中包含各种 "double" 型数值。虽然我们可以使用其他类型,但亲爱的读者,从现在开始,熟悉使用 "double" 型数值是非常重要的。原因很快就会清楚了。完成所有分解步骤后,我们将得到一个 double 型数值矩阵。
现在,请注意:我们正在使用的数组很简单。然而,我们将把它当作一个有两列的矩阵来处理。但这怎么可能呢?在讨论如何使用这段代码之前,让我们先了解一下。
在第6行中,我们创建了一个矩阵,其行数与数组中的元素数一样多。但它将有两列。这与数组不同,数组内部只有一列。在第 7 行和第 8 行中,我们以一种非常特别的方式初始化矩阵 M。要理解这一点,请看下面的图片。
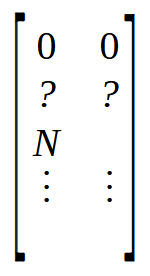
请注意,前两个位置设置为零,后面还有两个标有问号的位置,因为我们还不知道它们的确切值。随后,有一个标记为 N 的位置。这个值 N 表示数组的大小。但是为什么我们要在矩阵中放置数组的大小呢?原因很简单:访问已知位置的值比使用函数查找相同的值更快。由于矩阵开头需要四个空闲位置,因此我们将数组的大小放置在标记为 N 的位置。这就是第 7 行和第 8 行所做的。
现在,如上图所示,我们需要执行的第一步是将矩阵与其转置相乘。但在这里,我们没有矩阵,我们只有一个数组,或者更准确地说,一个向量。那么,我们如何进行乘法运算呢?其实很简单,我们使用第 9 行的循环来实现这一目标。但这个循环在做什么?乍一看,这似乎很令人困惑,但让我们通过查看下图来分解它。
![]()
数组本质上是一组值的集合,在这里从 a0 到 an 表示。如果你仔细想想,而不是把它看作一个数组,你可以把它看作是一个单列矩阵或单行矩阵,具体取决于数据的组织方式。现在,当你在一列矩阵和一行矩阵之间执行操作时,你会得到一个标量值,而不是一个矩阵。记住,伪逆的公式首先需要将矩阵与其转置相乘。然而,我们可以隐式地将上面显示的数组视为矩阵。请看下图。
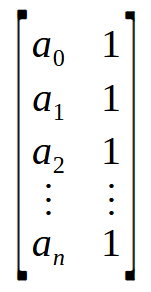
哇!现在,我们得到了所需的矩阵。通过将一个 n x 2 矩阵乘以它的转置,我们最终得到一个 2 x 2 矩阵。换句话说,我们已经成功地将一个数组,或者更准确地说,一个向量,转换成了一个 2 x 2 矩阵。这正是第 9 行中的 for 循环所做的 — 将矩阵与其转置相乘,并将结果放置在第 6 行声明的矩阵的顶部。
接下来,我们需要找到我们刚刚构造的矩阵的逆。对于 2 x 2 矩阵,计算逆的最快、最简单的方法是使用行列式。这里有一个重要的事实:我们不需要一个通用的方法来找到逆矩阵或行列式。我们也不需要一种通用的方法来将矩阵乘以它的转置。我们可以直接处理所有这些,因为我们已经将所有内容简化为一个简单的 2 x 2 矩阵,使任务变得更简单、更快。因此,为了计算行列式,我们使用第 14 行。现在,我们可以继续计算矩阵的逆。由于我们所做的选择,这种逆计算如果通用地实现会很慢,但完成得非常快。从第 15 行到第 17 行,我们生成通过阵列获得的矩阵中的逆。此时,几乎一切都准备好了。下一步是清除矩阵 M,这在第 18 行完成。现在,请注意。矩阵 T 包含逆矩阵,数组 A 包含我们想要分解为伪逆的值。剩下的就是将此二者相乘,并将结果放入矩阵 M 中。这里的关键细节是矩阵 T 是 2 x 2,而数组 A 可以被视为 n x 2 矩阵。这种乘法将产生一个包含伪逆值的 n x 2 矩阵。
该分解在第 19 行的循环中执行。在第 21 行和第 22 行,我们将值放入矩阵 M 中。瞧,我们得到了伪逆的结果。我在这里描述的过程可以移植到 OpenCL 块中,使用 GPU 功能为非常大的数据库计算线性回归。在某些情况下,使用 CPU 会导致计算需要几分钟,但将任务发送到 GPU 会使其更快。这就是我在本文前面提到的优化。
现在我们只需要将数组 M 的结果放入矩阵中。这在第 25 至 31 行完成的。你在 M 中发现的已经代表了预期的结果。在附件中,我将提供代码,以便您了解所有内容的工作原理,并将其与上一篇文章中显示的内容进行比较。然而,并非一切都是完美的。请注意,我没有在这个函数中执行任何测试。这是因为,虽然该函数是教育性的,但我们的目标是使其类似于可以在硬件中实现的功能。在这种情况下,测试将以不同的方式进行,从而节省我们的处理时间。
现在,这并没有回答一个关键问题:这个 PInv(伪反)函数为何能如此快速地生成线性回归结果?为了回答这个问题,让我们继续下一个主题。
最高速度
在上一节中,我们看到了如何基于数组执行伪逆的计算。然而,我们可以进一步加快这一进程。我们可以返回线性回归值,而不是只返回伪逆。为此,我们需要对上一节中的代码进行一些微调。这些变化将足以让我们使用 GPU 或专用 CPU 的全速来找到线性方程的因子。所寻求的系数是斜率和交点。更新的片段可以在下面看到。
01. //+------------------------------------------------------------------+ 02. void Straight_Function(const double &Infos[], double &Ret[]) 03. { 04. double M[], T[4], Det; 05. uint n = (uint)(Infos.Size() / 2); 06. 07. if (!ArrayIsDynamic(Ret)) 08. { 09. Print("Response array must be of the dynamic type..."); 10. Det = (1 / MathAbs(0)); 11. } 12. ArrayResize(M, Infos.Size()); 13. M[0] = M[1] = 0; 14. M[3] = (double)(n); 15. for (uint c = 0; c < n; c++) 16. { 17. M[0] += (Infos[c * 2] * Infos[c * 2]); 18. M[2] = (M[1] += Infos[c * 2]); 19. } 20. Det = (M[0] * M[3]) - (M[1] * M[2]); 21. T[0] = M[3] / Det; 22. T[1] = T[2] = -(M[1] / Det); 23. T[3] = M[0] / Det; 24. ZeroMemory(M); 25. for (uint c = 0; c < n; c++) 26. { 27. M[(c * 2) + 0] = (Infos[c * 2] * T[0]) + T[1]; 28. M[(c * 2) + 1] = (Infos[c * 2] * T[2]) + T[3]; 29. } 30. ArrayResize(Ret, 2); 31. ZeroMemory(Ret); 32. for (uint c = 0; c < n; c++) 33. { 34. Ret[0] += (Infos[(c * 2) + 1] * M[(c * 2) + 0]); 35. Ret[1] += (Infos[(c * 2) + 1] * M[(c * 2) + 1]); 36. } 37. } 38. //+------------------------------------------------------------------+
请注意,在上面的代码中,检查已经在运行。此检查验证返回的数组是否为动态类型。否则,应用程序将需要关闭,关闭出现在第 10 行。在上一篇文章中,我解释了这一行的意义(如有必要,请参阅以获取更多详细信息)。除此之外,大部分代码继续以与上一节中讨论的方式大致相同的方式运行,直到第 30 行,在那里事情朝着不同的方向发展。但让我们退一步,看看这段代码,你可能会发现它很不寻常,特别是转置与矩阵相乘的方式,或者更确切地说,是数组,以及逆矩阵如何与原始矩阵相乘来计算伪逆。
我们在这个片段中看到的是什么意思?看似非常复杂的东西,其实不过是一个 "点矩阵"。为了更好地理解,请参考下图。
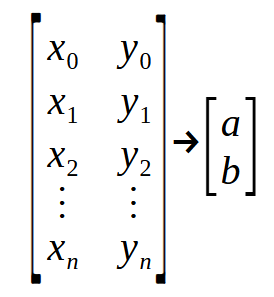
请注意,我们有一个 "矩阵" 进入,另一个 "矩阵" 离开。在第 2 行的声明中,参数 Infos 代表图像中显示的第一个矩阵,而 Ret 代表第二个矩阵。< a > 和 < b > 的值是我们试图确定以构建直线方程的系数。现在,请密切关注:左边矩阵的每一行代表图形上的一个点。偶数索引值对应于前面讨论的函数中使用的值。同时,奇数索引值表示本文开头提到的公式中的向量。即向量 < p >。
本主题开头讨论的此函数获取图上的所有点并返回线性回归方程。为了实现这一点,我们必须以某种方式分离数据,方法是组织偶数和奇数值。这就是为什么代码看起来与上一节中的代码如此不同。然而,它们以相同的方式工作,至少在第 30 行之前是这样。此时,我们执行了前面代码中没有看到的操作。这里,我们取存储在矩阵 M 中的伪逆的结果,并将其乘以 Infos 参数的奇数索引位置中的向量。这将生成 Ret 向量,该向量由定义直线方程或线性回归所需的常数组成。
如果使用上一篇文章中 PInv 函数返回的值执行相同的操作,您将得到与此片段中显示的结果相同的结果。唯一的区别是,这种特定的实现方式被设计为适合基于硬件的执行,例如在专用的神经网络计算单元中。这可能会导致新技术被集成到处理器中,使制造商能够声称给定的处理器或电路具有内置的人工智能或神经网络功能。然而,这不是革命性的或开创性的。它只是涉及在硬件中实现以前在软件中执行的东西,将通用系统转换为专用系统。
最后的探讨
亲爱的读者和爱好者们,到目前为止,我们已经讨论了所有关于神经网络和人工智能的知识。然而,到目前为止,我们还没有讨论神经网络本身,而是讨论单个神经元的使用和构造,因为我们只进行了一次计算。在神经网络中,相同的计算会被执行多次,但规模更大。即使这对你来说不是显而易见的,神经网络也只是图架构的实现,其中每个节点代表一个神经元或线性回归函数。根据计算结果,遵循某些途径。
我明白,这种观点可能看起来并不鼓舞人心,甚至微不足道。但这就是现实。神经网络没有什么神奇或梦幻的,无论媒体或不知情的人如何描述它们。机器所做的一切只不过是简单的数学计算。如果你理解这些计算,你就会理解神经网络。此外,您将深入了解如何模拟生物体的行为。这并不是因为生物体是有机机器,尽管在某些情况下,我们可以说它们是。不过,这是后话了。
尊敬的读者,我希望你通过理解单个神经元的概念,在最简单的层面上掌握神经网络的本质,这正是我们迄今为止所探索的。
在接下来的文章中,我将指导您将单个神经元组织成一个小网络,使其能够学习一些东西。我故意避免将这些概念应用于金融市场,所以不要指望将来从我身上看到这些。我的目标是帮助你理解、学习,并能够通过自己的经验解释神经网络是什么以及它是如何学习的。要做到这一点,你需要尝试一个足够简单易懂的系统。
所以,请继续关注这个主题的延续。我会想出一些令人兴奋的东西和你分享,一些真正值得探索的东西。同时,随附的材料包含了开始研究单个神经元如何工作所需的代码。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/13733
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
