
Passer à MQL5 Algo Forge (Partie 4) : Travailler avec les versions et les mises à jour
Introduction
Notre transition vers MQL5 Algo Forge se poursuit. Nous avons mis en place notre flux de travail avec des dépôts personnels et nous nous sommes tournés vers l'une des principales raisons de ce changement : la possibilité d'utiliser facilement le code fourni par la communauté. Dans la 3ème partie, nous avons étudié comment ajouter une bibliothèque publique d'un autre dépôt à notre propre projet.
Notre expérience de connexion de la bibliothèque SmartATR à l’Expert Advisor SimpleCandles a clairement démontré qu'un simple clonage n'est pas toujours pratique, en particulier lorsque le code nécessite des modifications. Au lieu de cela, nous avons suivi le bon flux de travail : nous avons créé un fork, qui est devenu notre copie personnelle du dépôt de quelqu'un d'autre pour corriger les bugs et apporter des modifications, tout en préservant la possibilité de proposer ultérieurement ces changements à l'auteur par le biais d'une Pull Request.
Malgré certaines limitations rencontrées dans l'interface de MetaEditor, sa combinaison avec l'interface web de MQL5 Algo Forge nous a permis de mener à bien l'ensemble de la chaîne d'actions, du clonage à la validation des modifications et, enfin, à la liaison du projet avec une bibliothèque externe. Nous avons donc résolu une tâche spécifique et examiné un modèle universel pour l'intégration de tout composant tiers.
Dans l'article d'aujourd'hui, nous allons examiner de plus près l'étape de la publication des modifications effectuées dans le dépôt, un certain ensemble de modifications qui forment une solution complète, qu'il s'agisse d'ajouter une nouvelle fonctionnalité à un projet ou de corriger un problème découvert. Il s'agit du processus d'engagement ou de lancement d'une nouvelle version d'un produit. Nous verrons comment organiser ce processus et quelles sont les possibilités offertes par MQL5 Algo Forge.
Trouver une Branche
Dans les parties précédentes, nous avons recommandé l'utilisation d'une branche distincte du dépôt pour effectuer un ensemble de modifications concernant une tâche spécifique. Cependant, après avoir terminé le travail sur une telle branche, il est préférable de la fusionner avec une autre branche (principale) et de la supprimer. Dans le cas contraire, le dépôt peut rapidement se transformer en un fourré dense où même le propriétaire peut facilement se perdre. Il convient donc de supprimer les branches obsolètes. Mais parfois, il peut être nécessaire de revenir à l'état dans lequel se trouvait le code juste avant la suppression d'une certaine branche. Comment procéder ?
Tout d'abord, précisons qu'une branche est simplement une séquence de modifications classées chronologiquement. Techniquement, une branche est un pointeur vers un commit considéré comme le dernier d'une chaîne de commits consécutifs. Par conséquent, la suppression d'une branche ne supprime pas les commits eux-mêmes. Au pire, ils peuvent être réaffectés à une autre branche ou même fusionnés en un seul commit récapitulatif ; mais dans tous les cas, ils continuent d'exister dans le dépôt (à de rares exceptions près). Ainsi, revenir à l'état "avant la suppression d'une branche" signifie essentiellement revenir à l'un des commits qui existent dans une branche. La question qui se pose alors est la suivante : comment trouver ce commit ?
Examinons l'état du dépôt SimpleCandles après les changements mentionnés dans la partie 3 :
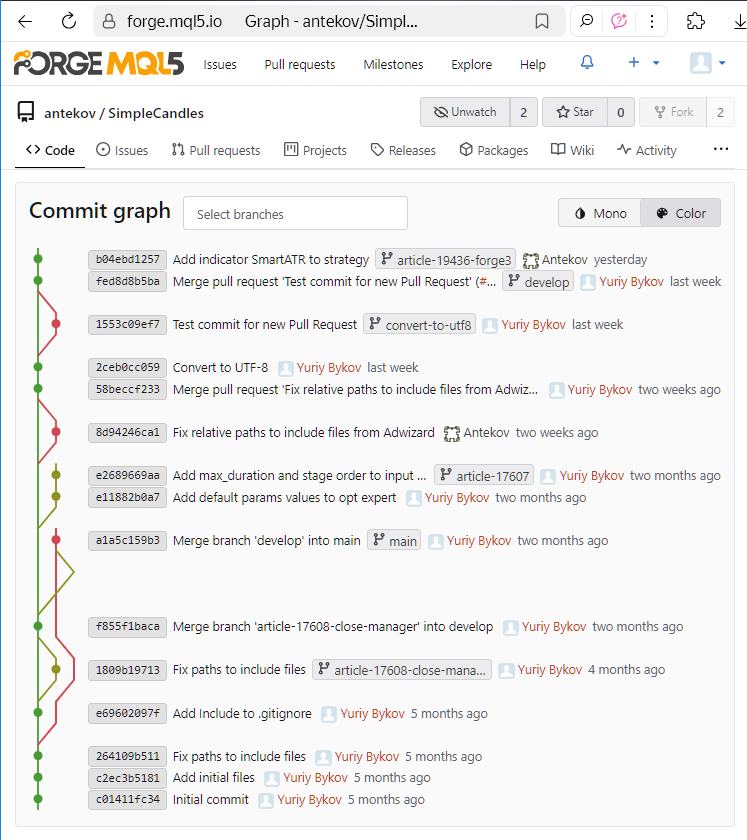
Nous pouvons voir l'historique des commits et une visualisation colorée des relations entre les branches sur la gauche. Chaque commit est identifié par son hachage (ou plus précisément, une partie de celui-ci), c'est-à-dire un grand nombre unique qui le distingue de tous les autres. Pour abréger sa représentation, le hachage est affiché sous forme hexadécimale (par exemple, b04ebd1257).
Cet arbre de commit peut être visualisé pour n'importe quel dépôt sur une page dédiée de l'interface web de MQL5 Algo Forge. La capture d'écran présentée a été réalisée il y a un certain temps. En visitant cette page maintenant, l'image sera légèrement différente : de nouveaux commits seront apparus dans l'arbre, et l'entrelacement des branches aura changé en raison de commits de fusion supplémentaires.
Nous pouvons également voir les noms des branches à côté de certains commits. Ceux-ci sont affichés pour les modifications les plus récentes dans chaque branche. Dans la capture d'écran fournie, nous pouvons compter 6 branches différentes : main, develop, convert-to-utf8, article-17608-close-manager, article-17607 et article-19436-forge3. La dernière est la branche utilisée pour les modifications apportées lors de la rédaction de la partie 3. Mais lorsque nous avons travaillé sur la partie 2, nous avons également créé une branche distincte pour les changements prévus. Elle était nommée article-17698-forge2, et a depuis été supprimée, ce qui explique qu'aucun commit ne porte désormais le nom de cette branche. Alors, où peut-on le trouver ?
Si nous regardons le message complet du commit pour le 58beccf233, il mentionne le nom de cette branche et indique qu'elle a été fusionnée dans develop.

Nous avons donc trouvé le commit souhaité, mais cette façon de procéder n'est pas pratique. De plus, si nous avions fusionné les branches manuellement en utilisant des commandes de console comme 'git merge' au lieu d'une Pull Request, nous aurions pu écrire n'importe quel commentaire arbitraire pour le commit de fusion. Dans ce cas, il aurait été encore plus difficile de trouver le bon commit, car le nom de la branche aurait pu ne pas figurer du tout dans le message.
Maintenant que nous avons trouvé le commit souhaité, nous pouvons basculer vers lui, restaurant ainsi notre dépôt local dans l'état où il se trouvait juste après ce commit. Pour ce faire, nous pouvons utiliser le hash du commit dans la commande 'git checkout'. Mais il y a des nuances à apporter. Si nous essayons de passer à ce commit dans MetaEditor en le sélectionnant dans l'historique ouvert via l'option "Git Log" du menu contextuel du projet :
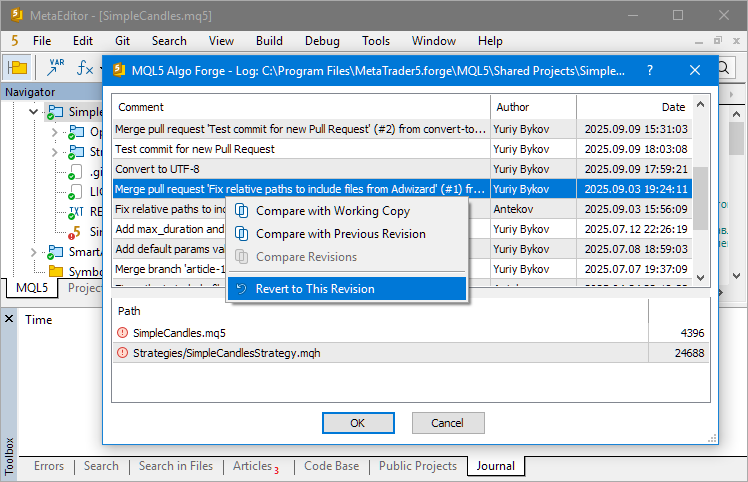
... nous obtiendrons un message d'erreur :

Il y a peut-être une raison à cela. Regardons de plus près ce qui se passe. Nous commencerons par introduire les nouveaux concepts de "tag" et de "pointeur HEAD".
Tags
Dans le système de contrôle de version Git, un tag, ou balise, est un nom supplémentaire attribué à un commit spécifique. Vous pouvez également considérer un tag comme un pointeur ou une référence à une version particulière du code dans le dépôt, puisqu'il pointe directement sur un commit spécifique. L'utilisation d'un tag vous permet de revenir à tout moment à l'état exact du code correspondant au commit taggé. Les tags sont utiles pour marquer les étapes importantes du développement d'un projet, telles que les versions, les étapes d'achèvement ou les versions stables. Dans l'interface web de MQL5 Algo Forge, vous pouvez visualiser toutes les balises d'un dépôt sélectionné sur une page page séparée.
Il existe 2 types de tags dans Git : les tags légers et les tags annotés. Les tags légers ne contiennent qu'un nom, alors que les tags annotés peuvent inclure des informations supplémentaires telles que l'auteur, la date, des commentaires et même une signature. Dans la plupart des cas, les tags légers sont utilisés.
Pour créer un tag via l'interface web, vous pouvez ouvrir la page de n'importe quel commit (par exemple, celui-ci), cliquer sur le bouton "Opérations" et sélectionner "Créer une balise".
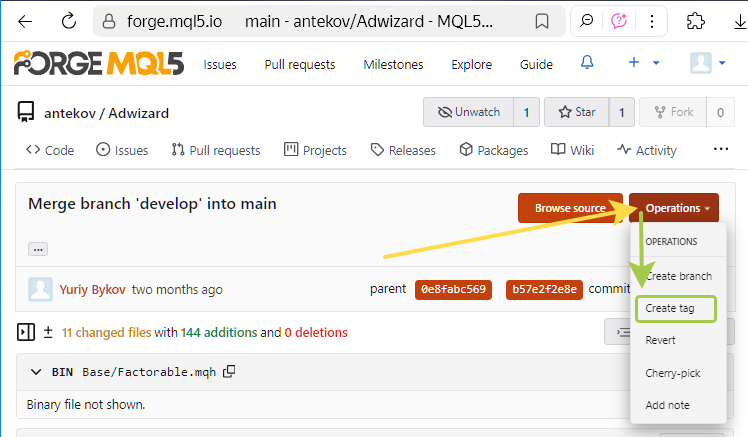
Mais nous reviendrons sur la création de tags un peu plus tard.
Pour créer un tag via les commandes de la console Git, vous utilisez la commande 'git tag'. Pour créer un tag léger, il suffit de spécifier le nom du tag :
git tag <nom du tag>
# Exemple
git tag v1.0
Pour créer un tag annoté, vous devez ajouter quelques paramètres supplémentaires :
git tag -a <nom du tag> -m "Description du tag"
# Exemple :
git tag -a v1.0 -m "Version 1.0 release"
En plus du marquage des versions de code destinées à la publication ou au déploiement (releases), les tags peuvent également être utilisés pour signaler aux pipelines de CI/CD de déclencher des actions prédéfinies lorsqu'un commit avec un certain tag apparaît, ou pour marquer des étapes de développement importantes, telles que l'achèvement de fonctionnalités majeures ou la correction de bugs critiques, même si elles ne représentent pas une nouvelle version.
Le pointeur HEAD
Après avoir parlé des tags, ou balises, il convient de mentionner un autre concept important : le pointeur HEAD. Son comportement est similaire à celui d'un tag avec un nom fixe HEAD, qui se déplace automatiquement vers le dernier commit de la branche actuellement extraite. HEAD est souvent appelé "marqueur de la branche actuelle" ou "pointeur vers la branche active". Il répond essentiellement à la question : "Où en sommes-nous dans le dépôt en ce moment ?" Mais techniquement, il ne s'agit pas d'un tag.
Physiquement, ce pointeur est stocké dans le fichier .git/HEAD du dépôt. Le contenu de HEAD peut contenir une référence symbolique (un nom de tag ou de branche) ou un hachage de commit. Lorsque l'on passe d'une branche à l'autre, le pointeur HEAD se met automatiquement à jour pour pointer sur le dernier commit de la branche en cours. Lorsqu'un nouveau commit est ajouté, Git ne crée pas seulement l'objet commit mais y place également le pointeur HEAD.
Ainsi, le nom HEAD peut être utilisé dans les commandes de la console Git à la place du hash du dernier commit ou du nom de la branche courante. En utilisant les symboles spéciaux ~ et ^, vous pouvez faire référence aux commits situés avant le dernier. Par exemple, HEAD~2 fait référence au commit deux étapes avant le commit le plus récent. Nous n'entrerons pas dans ces détails pour l'instant.
Pour la suite de la discussion, il convient également de mentionner les deux états possibles d'un dépôt. L'état normal, appelé "attached HEAD", signifie que les nouveaux commits apparaissent avant le dernier commit de la branche courante. Dans cet état, toutes les modifications sont ajoutées à la branche de manière séquentielle et sans conflit.
L'autre état, connu sous le nom de "HEAD détaché", se produit lorsque le pointeur HEAD fait référence à un commit qui n'est pas le plus récent d'une branche. Cela peut se produire, par exemple, lorsque :- vous basculez le dépôt vers un commit antérieur spécifique (par exemple, en utilisant 'git checkout <commit-hash>'),
- vous basculez en utilisant un nom de tag (par exemple, 'git checkout tags/<nom-de-la-balise>'),
- vous basculez vers une branche qui existe toujours dans le dépôt distant mais qui a été supprimée du dépôt local (par exemple, 'git checkout origin/<nom-branche>').
Cet état doit être évité dans la mesure du possible, car tout changement dans cet état qui n'est pas associé à une branche peut être perdu lors du passage à une autre branche. Toutefois, si vous n'avez pas l'intention d'apporter des changements dans cet état, il n'y a pas de mal à ce qu'il existe.
Pas de tags pour l'instant
Revenons maintenant à notre tentative de basculer notre dépôt local vers un commit spécifique qui était autrefois le dernier de la branche supprimée article-17698-forge2.
Basculer un dépôt vers un commit antérieur spécifique n'est pas quelque chose que les développeurs font habituellement dans les flux de travail Git quotidiens. Dans des circonstances normales, vous aurez rarement besoin d'effectuer ce genre d’opération. Mais si vous choisissez de le faire, le dépôt entrera dans ce que l'on appelle l'état "HEAD détaché". Dans ce cas, ce commit appartient à la branche develop, qui a déjà des commits plus récents à sa suite, donc ce n'est plus le dernier dans la branche.
Mais si nous utilisons l'interface en ligne de commande de Git pour effectuer ce changement, l'opération s'effectuera avec succès. Bien que Git nous avertisse clairement que nous sommes dans un état "detached HEAD :" :
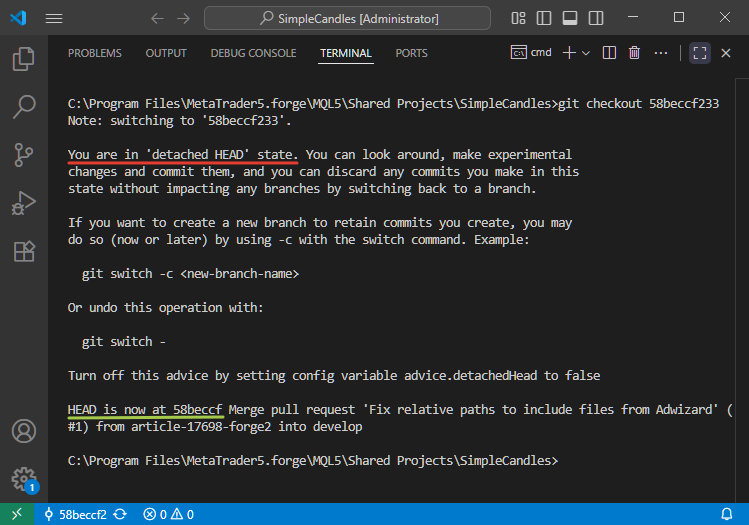
Les lecteurs attentifs peuvent remarquer que dans la dernière capture d'écran, nous sommes passés à un commit avec le hash 58beccf233, mais Git signale que le pointeur HEAD est maintenant à 58beccf. Où sont passés les trois derniers chiffres ? Tout va bien. Ils n'ont pas disparu. Git autorise simplement l'utilisation de hashs de commit raccourcis tant qu'ils restent uniques au sein du dépôt. Selon l'interface, les hashs peuvent être raccourcis entre 4 et 10 caractères.
Si vous avez besoin de voir le hash complet du commit, vous pouvez le faire en lançant la commande 'git log'. Chaque hachage complet contient 40 chiffres.
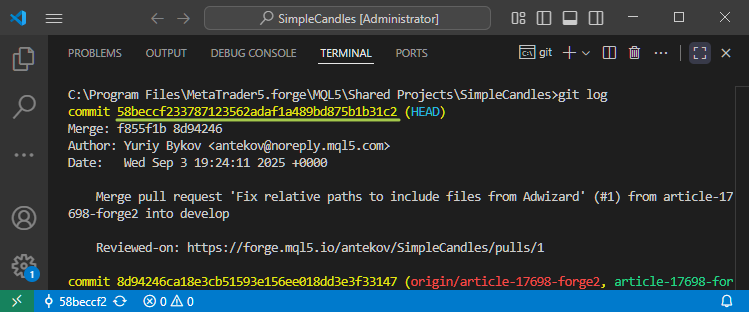
Chaque empreinte étant générée de manière aléatoire et unique, il est pratiquement garanti que même les premiers chiffres sont distincts au sein d'un dépôt. C'est pourquoi il suffit généralement de fournir un préfixe court du hash pour que Git reconnaisse exactement le commit auquel vous faites référence dans vos commandes.
Utilisation du codage UTF-8
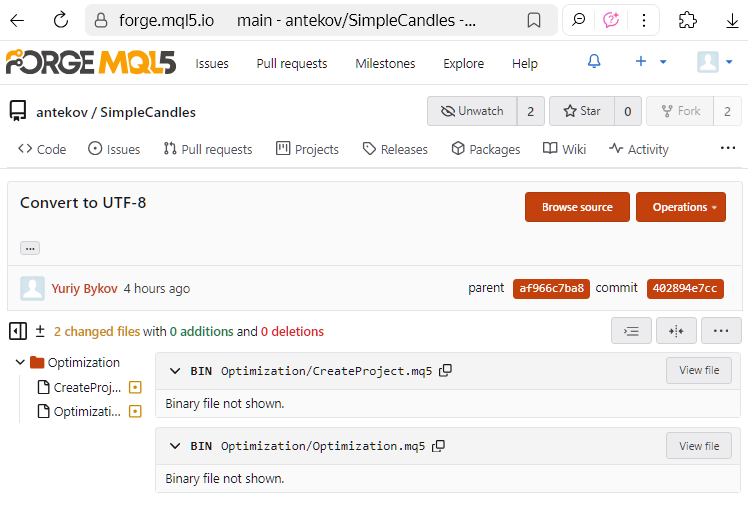
Voici un autre aspect intéressant. Dans les versions antérieures, MetaEditor utilisait l'encodage UTF-16LE pour enregistrer les fichiers de code source. Mais pour une raison quelconque, les fichiers enregistrés dans cet encodage étaient traités par Git comme des fichiers binaires et non comme des fichiers texte. Par conséquent, il était impossible de voir les lignes de code exactes qui avaient été modifiées dans un commit (même si cela fonctionnait parfaitement dans Visual Studio Code). La seule information affichée était la taille des fichiers avant et après les modifications apportées dans la livraison.
Voici à quoi cela ressemble dans l'interface web de MQL5 Algo Forge :
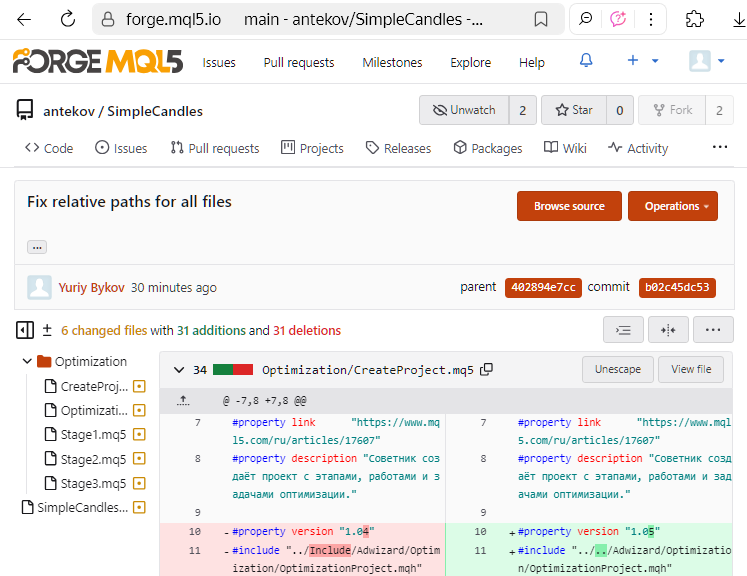
Désormais, les nouveaux fichiers créés dans MetaEditor sont enregistrés en utilisant le codage UTF-8, et même l'utilisation de caractères alphabétiques nationaux ne déclenche plus un passage automatique à UTF-16LE. Il est donc logique de convertir en UTF-8 les fichiers plus anciens, transférés dans le nouveau dépôt à partir de projets antérieurs. Après avoir effectué une telle conversion, à partir de la prochaine livraison, vous serez en mesure de voir exactement quelles lignes et quels caractères ont été modifiés. Par exemple, dans l'interface web de MQL5 Algo Forge, cela peut ressembler à ceci :
Mais ce n'était qu'une brève parenthèse. Revenons à la discussion sur la manière de publier une nouvelle version du code dans le dépôt.
Retour à la tâche principale
Ainsi, parmi les branches de notre dépôt, prêtons attention à ces deux-là : article-17608-close-manager et article-17607. Les modifications apportées dans ces branches n'ont pas encore été fusionnées dans develop, car les tâches qui leur sont associées sont encore en cours. Ces branches continueront à se développer, il est donc trop tôt pour les fusionner dans develop. Nous allons poursuivre le travail sur l'une d'entre elles (article-17607), l'amener à un point d'achèvement logique, puis la fusionner avec develop. L'état du code qui en résultera sera marqué d'un numéro de version.
Pour ce faire, nous devons d'abord préparer la branche sélectionnée à d'autres modifications, car pendant qu'elle existait, d'autres branches ont également introduit des changements. Ces changements ont déjà été fusionnés dans develop. Nous devons donc nous assurer que ces changements de la branche develop sont également incorporés dans la branche que nous avons choisie.
Il y a plusieurs façons de fusionner les changements de develop dans article-17607. Par exemple, nous pouvons créer une Pull Request via l'interface web et répéter le processus de merge/fusion décrit dans la partie précédente. Cependant, cette approche est mieux utilisée lorsque vous souhaitez fusionner un nouveau code non testé dans une branche contenant un code stable et testé. Dans notre cas, la situation est inverse : nous voulons apporter des mises à jour stables et vérifiées de develop dans une branche qui contient encore du nouveau code non vérifié. Par conséquent, il est tout à fait possible d'effectuer la fusion en utilisant les commandes de la console Git. Nous utiliserons la console et surveillerons le processus dans Visual Studio Code.
Tout d'abord, vérifions l'état actuel du dépôt. Dans le panneau de contrôle de version, nous pouvons voir l'historique des commits avec les noms des branches. La branche actuelle est article-19436-forge3, où les derniers changements ont été effectués. La sortie de la commande 'git status' est affichée dans la partie droite du terminal :
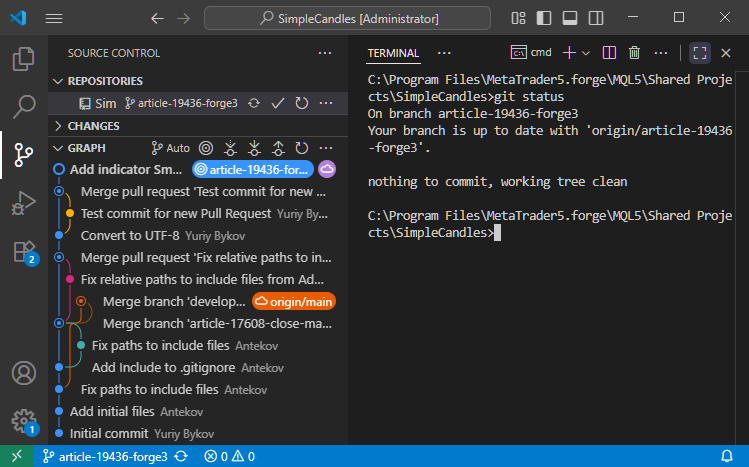
La commande confirme que notre dépôt est actuellement sur la branche article-19436-forge3 et que son état est synchronisé avec la branche correspondante dans le dépôt distant.
Ensuite, nous passons à la branche article-17607 en utilisant la commande 'git checkout article-17607' :
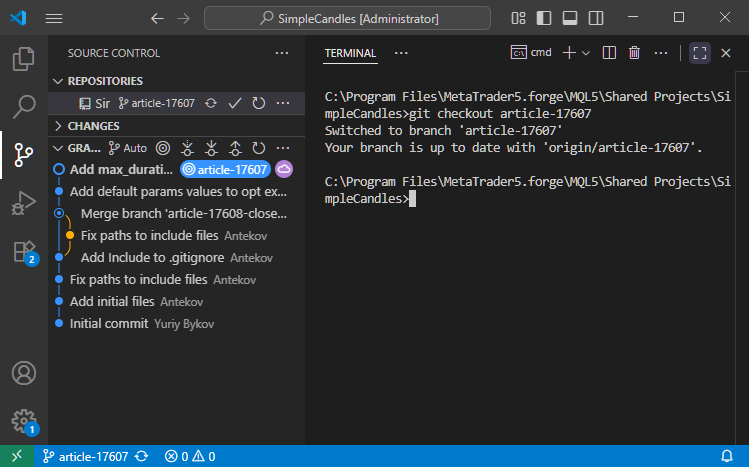
Ensuite, fusionnez-la avec develop en utilisant 'git merge develop' :
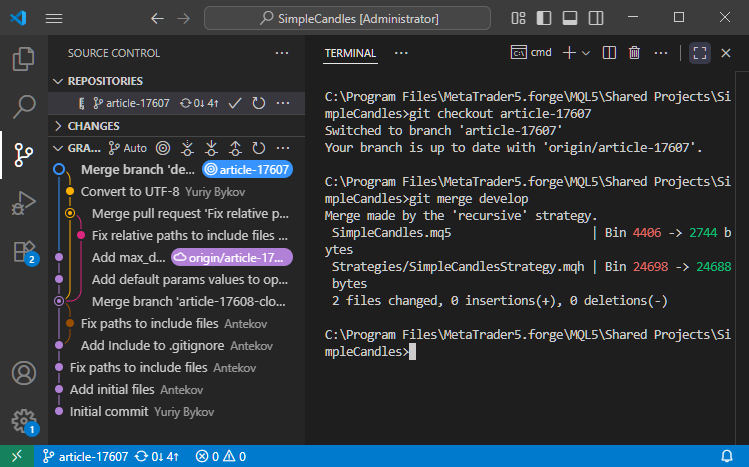
Comme les changements externes affectaient des parties du code que nous n'avions pas modifiées en travaillant sur article-17607, aucun conflit n'est apparu pendant la fusion. En conséquence, Git a créé un nouveau commit de fusion.
Maintenant, nous lançons 'git push' pour envoyer les informations mises à jour au dépôt distant :
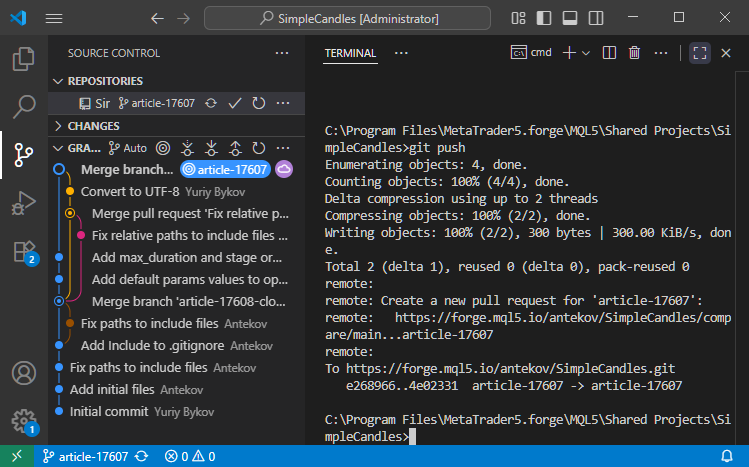
Si nous vérifions le dépôt MQL5 Algo Forge, nous verrons que nos étapes de merge ont été reflétées avec succès dans le dépôt distant :
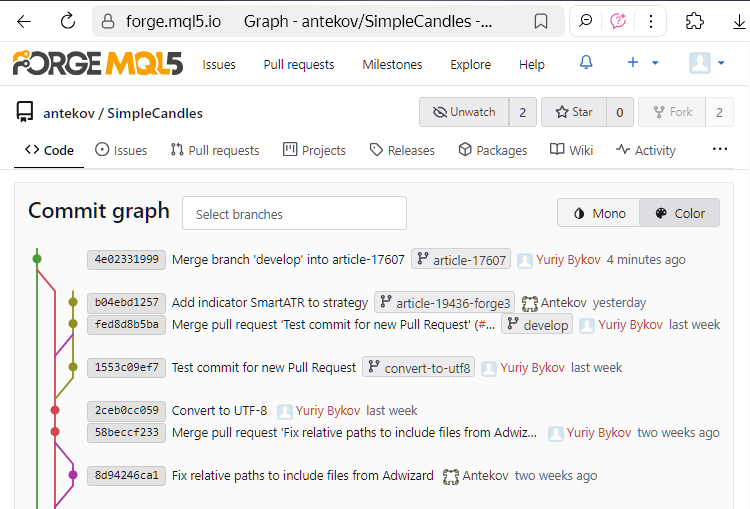
Le dernier commit montré dans la capture d'écran est le commit de fusion entre develop et article-17607.
Notez également l'extrémité libre de la branche article-19436-forge3, qui n'est encore connectée à aucune autre branche. Les changements de cette branche n'ont pas encore été fusionnés dans develop, car le travail y est toujours en cours. Nous la laisserons tel quelle pour l'instant. Le moment venu, nous y reviendrons.
La préparation de la poursuite du développement dans la branche article-17607 est ainsi achevée et nous pouvons maintenant procéder au codage proprement dit. La solution pour la tâche associée à cette branche est décrite dans un autre article. Je ne le répéterai donc pas ici. Passons plutôt à la description de la manière de finaliser et d'enregistrer l'état atteint par le code après avoir accompli la tâche.
Exécution du Merge
Avant de publier un état particulier du code, nous devons d'abord le fusionner dans la branche principale. Notre branche principale est la branche main. Toutes les mises à jour de la branche develop seront finalement intégrées à la branche main. Les modifications des branches de tâches individuelles sont fusionnées dans develop. Pour l'instant, nous ne sommes pas prêts à fusionner du nouveau code dans main, nous nous contenterons donc de fusionner des mises à jour dans develop. Pour démontrer ce mécanisme, le choix spécifique de la branche main n'est pas particulièrement important.
Examinons l'état du dépôt SimpleCandles après avoir terminé le travail sur la tâche sélectionnée :
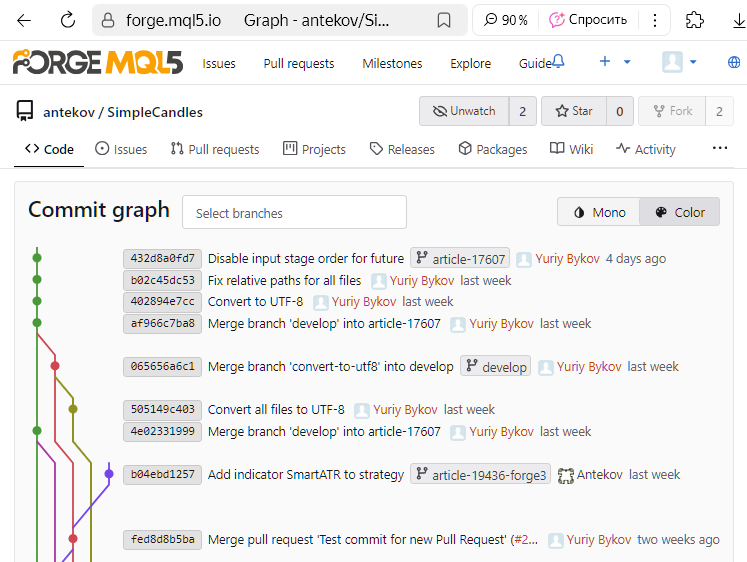
Comme indiqué, le dernier commit a été fait dans la branche article-17607. En utilisant l'interface web de MQL5 Algo Forge, nous créons une Pull Request pour fusionner cette branche dans develop, comme décrit précédemment.
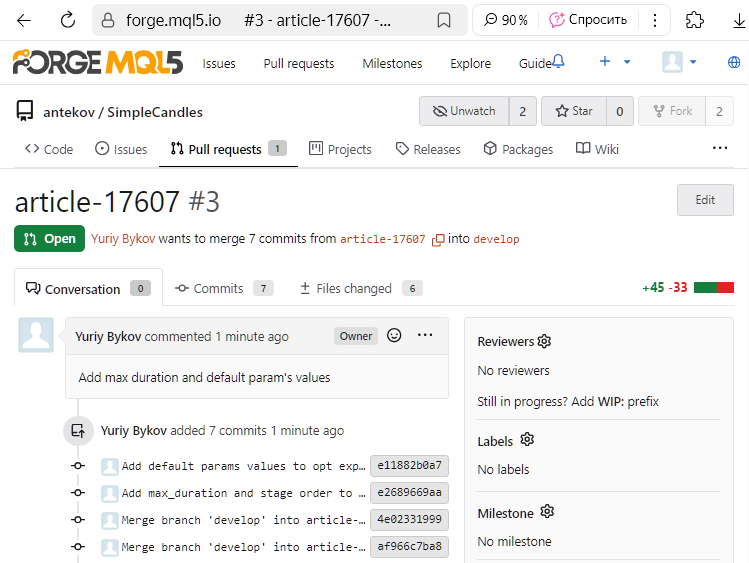
Vérifions que tout s'est déroulé comme prévu. Nous ouvrons à nouveau la page de l'historique des commits avec l'arborescence des branches :
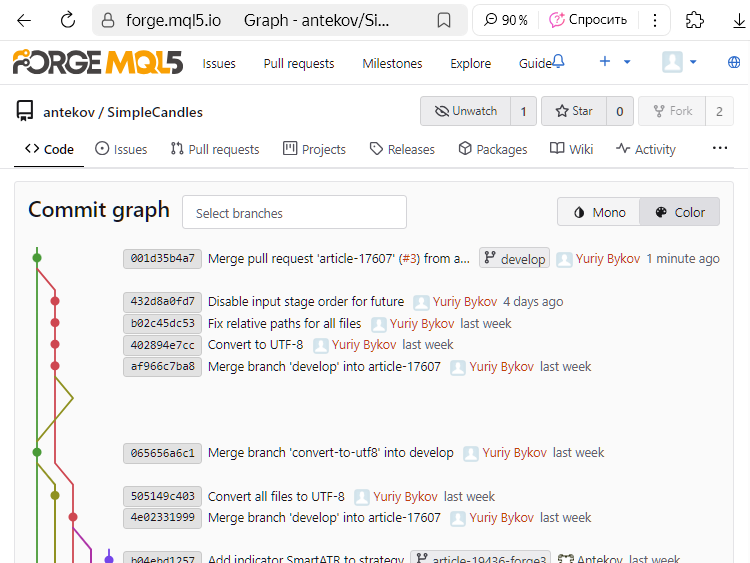
Nous pouvons voir que le commit avec le hash 432d8a0fd7 n'est plus marqué comme le dernier dans article-17607. Au lieu de cela, un nouveau commit avec le hash 001d35b4a7 apparaît comme le dernier en date dans develop. Comme ce commit enregistre la fusion de deux branches, nous l'appellerons le commit de fusion.
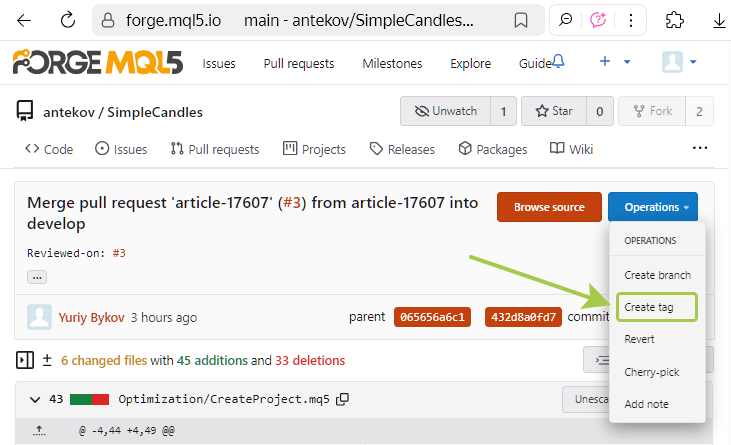
Ensuite, ouvrez la page de merge du commit et créez un nouveau tag. Plus tôt dans l'article, nous avons montré où faire cela ; il est maintenant temps de le faire :
Dans la pop-up, entrez le nom de balise "v0.1", car il s'agit d'une version encore loin de la version finale. Nous ne savons pas encore combien d'ajouts seront apportés au projet, mais nous espérons qu'il y en aura beaucoup. Par conséquent, un numéro de version aussi petit nous rappelle qu'il reste encore beaucoup de travail à accomplir. Par ailleurs, il ne semble pas que l'interface web prenne actuellement en charge la création de balises annotées.
Le tag, ou balise, a été créé avec succès et vous pouvez voir le résultat sur la page suivante :
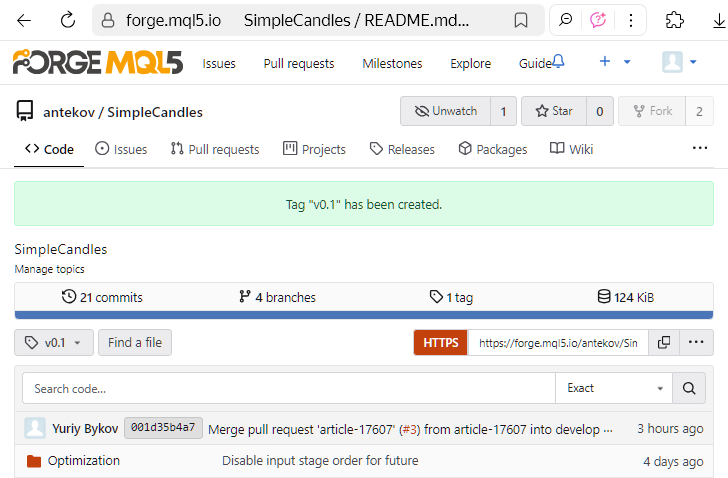
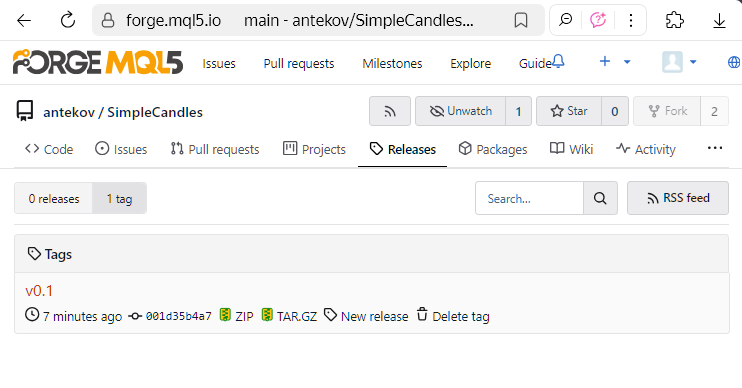
ou sur la page tags du dépôt.
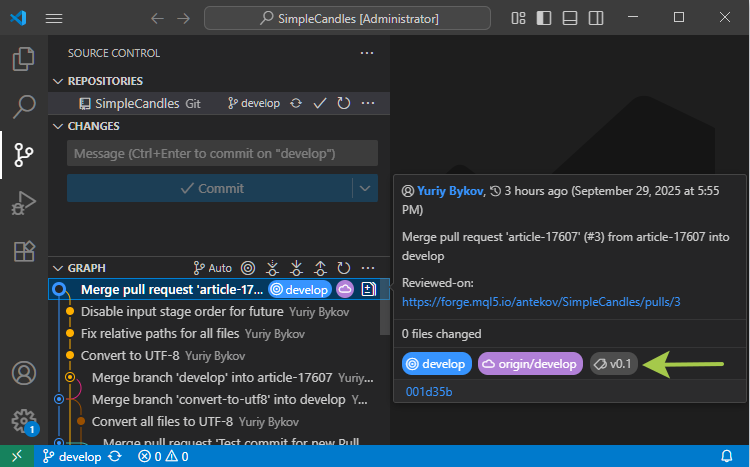
Si nous mettons à jour notre dépôt local en utilisant 'git pull', le tag nouvellement créé y apparaîtra également. Cependant, comme MetaEditor n'affiche pas actuellement les tags des dépôts, vérifions ce que cela donne dans Visual Studio Code. Si vous passez la souris sur le commit souhaité dans l'arbre des commits, une étiquette de couleur avec le nom de la balise correspondante apparaît dans la bulle d'aide :
Maintenant que le tag est créé, nous pouvons soit nous arrêter ici et utiliser son nom dans une commande 'git checkout' pour passer à l'état exact du code, soit aller plus loin et créer une version basée sur cette balise.
Création d'une Release
Une version est un mécanisme de marquage et de distribution de versions spécifiques d'un logiciel, quel que soit le langage de programmation utilisé. Les commits et les branches représentent le flux de développement, alors que les releases en sont les résultats officiels, c'est-à-dire les versions que nous voulons publier. Les principaux objectifs de l'utilisation des releases sont les suivants :
- Versioning : Nous marquons certains états du code dans le dépôt comme stables, ce qui signifie qu'ils sont exempts d'erreurs critiques (au moins apparentes) et que leur fonctionnalité a été vérifiée. Les autres utilisateurs peuvent utiliser ces versions spécifiques.
- Distribution de binaires : Les versions peuvent inclure des fichiers compilés ou empaquetés (tels que .ex5, .dll ou .zip), de sorte que les utilisateurs n'aient pas à compiler le projet eux-mêmes.
- Communication avec l'utilisateur : Une version doit inclure une description, énumérant généralement les changements, les nouvelles fonctionnalités, les bugs corrigés et d'autres informations concernant cette version. L'objectif principal de cette description est d'aider les utilisateurs à décider s'ils doivent la mettre à jour.
Une release peut être créée sur la base d'un tag existant, ou un nouveau tag peut être généré au cours du processus de création de la release. Puisque nous avons déjà un tag, nous allons créer une nouvelle version en l'utilisant. Pour cela, allez sur la page des tags du dépôt et cliquez sur "Nouvelle version" à côté du tag souhaité :

- Le nom de la version, de la branche cible et du tag (soit une branche existante, soit une nouvelle branche à créer),
- Les release notes, c'est-à-dire un résumé des nouveautés, des corrections et des problèmes connus qui ont été résolus,
- Les fichiers joints, par exemple des programmes compilés, de la documentation ou des liens vers des ressources externes.
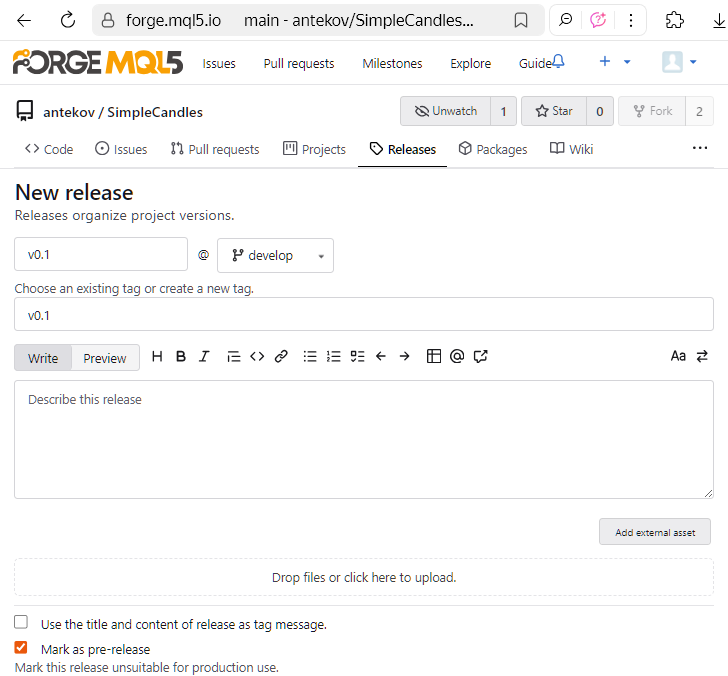
Vous pouvez enregistrer une release en tant que projet et mettre à jour ses détails ultérieurement, ou la publier immédiatement. Même si vous la publiez maintenant, vous pouvez y apporter des modifications plus tard : par exemple, vous pouvez encore ajuster la description de la release après coup. Une fois publiée, la version apparaîtra sur la page des Releases du dépôt, visible par les autres utilisateurs :
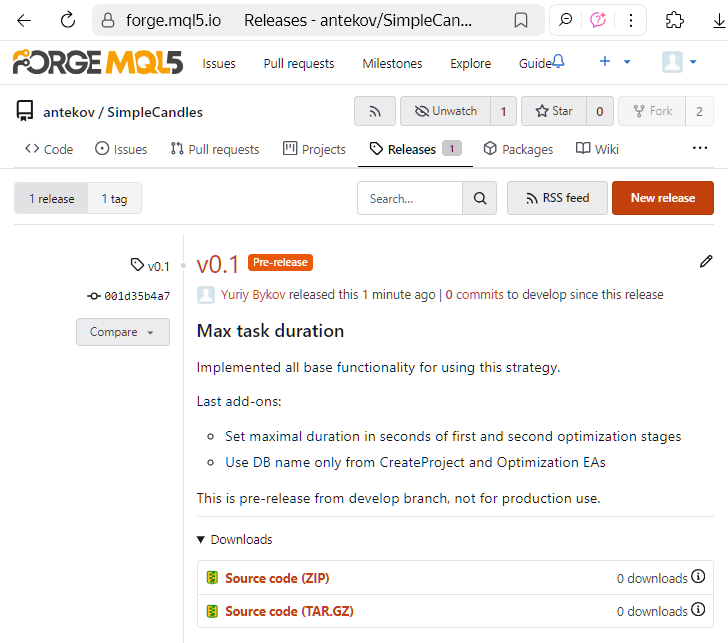
C'est tout ! La nouvelle version est maintenant en ligne et prête à être utilisée. Un peu plus tard, nous avons mis à jour le nom de la version (qui ne doit pas nécessairement correspondre au nom du tag) et ajouté un lien vers l'article susmentionné décrivant la solution mise en œuvre.
Conclusion
Arrêtons-nous un instant pour réfléchir aux progrès que nous avons accomplis. Nous ne nous sommes pas contentés d'explorer les aspects techniques du contrôle des versions. Nous avons réalisé une transformation complète, passant d'éditions éparses à un flux de travail structuré et cohérent pour la gestion du code. L'étape la plus importante que nous ayons franchie est la dernière : la publication des travaux achevés en tant que versions officielles du produit pour les utilisateurs finaux. Notre dépôt actuel ne représente peut-être pas encore un projet pleinement mature, mais nous avons posé tous les jalons nécessaires pour atteindre ce niveau.
Cette approche modifie fondamentalement notre perception du projet. Ce qui n'était autrefois qu'une collection de fichiers sources est aujourd'hui un système organisé avec un historique clair des modifications et des points de contrôle bien définis, ce qui nous permet de revenir à tout moment à un état stable. Tout le monde en profite : les développeurs et les utilisateurs des solutions finies.
En maîtrisant ces outils, nous avons élevé notre travail avec le dépôt MQL5 Algo Forge à un niveau supérieur, ouvrant la voie à des projets plus complexes et à plus grande échelle à l'avenir.
Merci de votre attention ! A la prochaine fois !
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/19623
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation