
初心者からエキスパートへ:サプライ&デマンドゾーンの統計的検証

内容
はじめに
サプライ&デマンドゾーンの分析は、市場の不均衡という普遍的な経済原理に基づいた、プライスアクショントレードの中核的概念です。裁量トレーダーにとって、これらのゾーンは視覚的なパターン認識によって特定されますが、このスキルは経験により習得されます。しかし、この主観的判断への依存は再現性の問題を生み、これが自動化の大きな障壁となります。ゾーンの理論的ロジックは確立されているものの、それを正確な計算ルールへと変換することは困難であり、しばしば恣意的な数値閾値に依存することになります。
本記事では、このギャップを埋めるための体系的なリサーチ手法を提示します。「インパルシブ・エグジット(impulsive exit)」という定性的概念を、定量化され統計的裏付けのある取引ルールへと変換する再現可能なパイプラインを示します。本アプローチでは重要な簡略化として、単一の上位時間足(HTF)ローソク足を分析の基本単位として使用します。これにより、サプライまたはデマンドゾーンの本質を明確に捉え、その特徴であるモメンタムを測定可能にします。
PythonベースのJupyter Notebook環境を用いることで、勝率の高いゾーンの統計的特徴を体系的に導出します。その後、得られたパラメータはMQL5のエキスパートアドバイザー(EA)に実装され、透明性のあるエビデンスベースの取引ツールが構築されます。このプロセスにより、「見た目が強いか?」という問いから、「統計的に定義された強度条件を満たしているか?」という問いへと移行します。
概念的基礎:市場不均衡の構造
コア原理:価格の不均衡
サプライまたはデマンドゾーンは、買い手と売り手の均衡が決定的に崩壊した価格レベルを示します。一方の側からの攻撃的な注文の流入が他方を圧倒し、価格は勢いを伴ってその領域から離脱します。この急激な離脱(インパルシブ・エグジット)は、反対サイドの未約定注文が理論上集中して残る領域を形成します。その後、価格はこの不均衡領域へ再訪する傾向があり、その際に反応を示しやすくなります。
構造要素の定義
取引文献および実チャート分析を統合すると、ゾーンの構造は以下のように整理できます。
サプライゾーンとは、売り圧力が買い圧力を上回る価格領域を指します。視覚的には、レンジ状のベース(複数ローソク足が重なり合うコンソリデーション)を形成した後、ベースの安値を明確に下抜ける強い陰線のインパルスによって特徴づけられます。
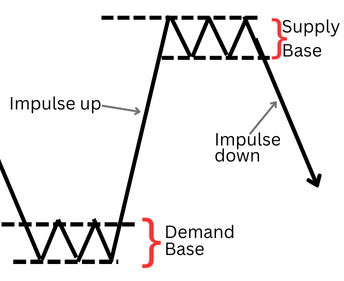
サプライ&デマンドの概念
デマンドゾーンはその逆構造であり、強い買い圧力が売り圧力を圧倒し、コンソリデーション・ベースの高値を上抜ける強い陽線のインパルスによって形成される領域です。
インパルシブ・エグジット・キャンドルは本研究における最も重要な構成要素です。これは市場不均衡を示す特徴的なサインとして機能します。裁量取引においては、このローソク足の「強さ」は視覚的に評価されるため、トレーダー間で一貫性に欠けるという問題があります。そのため、本研究ではこのローソク足の大きさおよび構造を主要な定量変数として扱います。
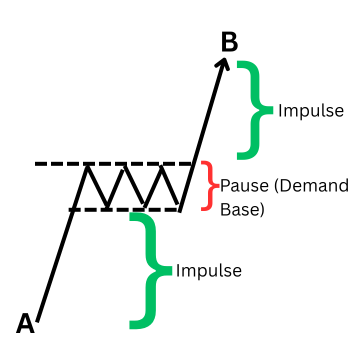
ゾーンの完全なライフサイクル:インパルス、継続、リテスト
初期エグジットの理解は、あくまで最初のフェーズにすぎません。有効なサプライ&デマンドゾーンは、初期形成後に以下の2つの主要フェーズを経て展開することが多いです。
- フェーズ1 - 初期インパルシブ・エグジット:価格は勢いを伴ってベースから離脱し、新たな短期的方向性の極値を形成します。
- フェーズ2 - リテストと反応:価格はしばしばゾーンの起点へ戻り、不均衡が生じた領域をリテストします。このリテストでは、未約定注文が残る領域に価格が到達することで、ゾーンから再び離れる第2の反応的な値動きが発生することがよくあります。

デマンドゾーン(Aでのコンソリデーション、Bへのエグジット、Cでのデマンドゾーンへの回帰)
以下の図は、対応する弱気フェーズを注釈付きで示した、典型的なサプライゾーンのライフサイクルを表しています。

単一ローソク足サプライゾーン(S)、AからBへのエグジット・インパルス、Cでのゾーンへの回帰
本研究では、フェーズ1である「初期インパルシブ・エグジット」の定量化に焦点を絞ります。これは最も明確に定義可能であり、かつ測定可能な市場イベントであるため、ゾーン形成を判断する基礎的なトリガーとして機能します。また、このエグジットを統計的に頑健な形で定義することにより、高確率なゾーンを客観的に識別できるようになります。その結果として、リテストを利用した取引戦略を、信頼性の高い基盤の上に構築することが可能になります。
方法論的正当性:上位時間足の単一ローソク足
視覚的なパターン認識から定量化可能なデータ分析へ移行するため、本研究では、焦点を絞った堅牢な方法論的前提を採用します。それは、均衡と不均衡の形成プロセス全体は、多くの場合、単一の上位時間足(HTF, Higher Timeframe)ローソク足の構造の中に効率的に集約されているという考え方です。
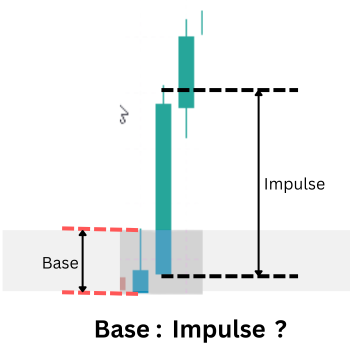
単一ローソク足によるデマンドセットアップ(小さなベースローソク足と大きなエグジットローソク足)
サプライおよびデマンドは継続型セットアップの中にも見出すことができる
概念的一貫性:スイングポイントで出現する強い方向性を持つHTFローソク足は、本研究で対象とする市場の不均衡が生み出した直接的な結果です。その内部構造を下位時間足で分析すると、多くの場合、ベース形成の後にインパルシブな値動きが続くという、サプライ&デマンドの古典的なシーケンスが確認できます。言い換えれば、HTFローソク足は、このような下位時間足のマイクロ構造を集約したシグネチャであると捉えることができます。
定量的研究における利点
- シグナルの明確さ:このアプローチは、市場における決定的なイベントのみを抽出し、長期間にわたる曖昧なコンソリデーションを分析対象から排除します。
- パラメータ複雑さの軽減:複数ローソク足から構成されるベースを定義するための多数のパラメータ(例:ベースを構成するローソク足の本数や、許容する重なり幅など)が不要になります。単一ローソク足の境界は、始値(Open)、高値(High)、安値(Low)、終値(Close)によって明確に定義されるため、解釈の余地がありません。
- フラクタル構造との整合性:この原理は時間足を問わず一貫して成立します。そのため、H4などの上位時間足で実施した研究結果を、M15などの実際の執行時間足へ適用することが可能です。
このモデルでは、中心となる評価指標を変更します。従来のように2本のローソク足(ベースとエグジット)を比較するのではなく、単一ローソク足の内部モメンタムを分析対象とします。本研究では、この指標をインパルス比と定義します。インパルス比が高い値(例えば0.7超)を示す場合、そのローソク足は大きな実体と小さなヒゲを持つ強い方向性を備えていることを意味します。これは、決定的なエグジットを特徴づける統計的特徴そのものです。
したがって、本研究の中心的な研究課題は次のように整理されます。「高確率でゾーンを形成する上位時間足ローソク足を定義するうえで、インパルス比および最小絶対サイズ(pips)の統計的に最適な閾値はいくつなのか。」
研究と実施のパイプライン
この問いに答えるために、本研究では明確な3段階のパイプラインを実行します。これにより、すべてのアルゴリズムルールが実証的根拠に基づいて構築されることを保証します。
ステージ1:体系的データ収集(MQL5)
まず、体系的なスキャナーとして機能するカスタムMQL5スクリプトを開発します。このスクリプトは、スイングポイントに出現する候補HTFローソク足を検出し、その主要なメトリクスをCSVファイルへ出力します。各候補ローソク足について収集するデータは以下のとおりです。
- タイムスタンプ、銘柄、時間足
- ローソク足実体サイズ(ピップ)、値幅(ピップ)、計算されたインパルス比
- ボラティリティ環境情報(例:ローソク足確定時点におけるATR値)
後続のプライスアクションに基づくラベリング(後の分析で「成功」を判定するためのラベル)
ステージ2:統計的発見と閾値最適化(Python/Jupyter Notebook)
続いて、Jupyter Notebook上で収集したデータセットに対する探索的データ解析(EDA)を実施します。
- 記述統計:すべての候補ローソク足を対象として、インパルス比および実体サイズの分布を分析します。
- 成功分析:候補ローソク足がその後の価格反応において成功したかどうかに基づいてデータを分類します。そのうえで、「成功グループ」と「失敗グループ」の統計的特性を比較し、それぞれの特徴を明らかにします。
- 閾値最適化:成功と失敗を最も明確に分離できる閾値を探索します。たとえば、最小インパルス比:0.65、最小実体サイズ:1.2 × ATRといった条件を評価しながら、最も優位性の高いパラメータを特定します。このプロセスを通じて、統計的に検証された取引ルールを定義します。
ステージ3:モデルの実装と検証(MQL5エキスパートアドバイザー)
最後の、そして最も重要なステップは、統計分析によって得られた知見を実行可能な取引ロジックへ変換することです。最適化されたパラメータは、MQL5エキスパートアドバイザー(EA)にハードコードされます。このEAは、統計的に検証された条件を満たすHTFローソク足をスキャンし、ゾーンの境界を自動的に描画します。さらに、この仕組みは下位時間足における取引管理へ拡張することも可能です。これにより、リサーチから自動売買の実行までを一貫して結び付ける、完全な研究・実装サイクルが完成します。
実装
体系的データ収集(MQL5)
本研究において最初であり、最も重要なフェーズは、高品質かつ詳細なマーケットデータを体系的に収集することです。このプロセスは、過去チャートを目視で振り返る従来の分析手法から大きく前進したアプローチです。私たちは専用のMQL5スクリプトを開発し、バイアスなくデータを収集するツールとして機能させます。このスクリプトは過去の価格データをプログラムによって走査し、事前に定義した2本のローソク足パターン、すなわち、「小さなベースローソク足」に続いて同方向へ進むより大きな「エグジットローソク足」が出現するパターンを漏れなく検出します。このスクリプトの主な役割は、視覚的なプライスアクションの構造を構造化されたデータセット(CSV)へ変換することです。その際、実体サイズ(pips)、両ローソク足のサイズ比率、さらにATR (Average True Range)を用いて正規化したボラティリティ調整済み指標などを記録します。
異なる市場環境において数千件規模のサンプルを収集することで、統計分析に必要となる実証的基盤を構築します。この生データは後続の統計分析における入力データとなり、その後に得られるすべての知見やパラメータが、主観的判断ではなく客観的な市場挙動に基づいて導出されることを保証します。
データ収集スクリプト
以下では、データ収集スクリプト(SD_BaseExit_Research.mq5)の各コードセクションについて、その目的とロジックを解説します。スクリプトの完全なソースコードは記事の最後に添付します。
1. スクリプトヘッダおよび設定項目(Inputs)
このセクションでは、スクリプトの基本情報を定義するとともに、より重要な要素として、スクリプトの動作を制御する各種パラメータを入力パラメータとして定義します。
//--- Inputs: Define what "small" and "bigger" mean input int BarsToProcess = 20000; // Total bars to scan input int ATR_Period = 14; // For volatility context input double MaxBaseBodyATR = 0.5; // Base candle max size (e.g., 0.5 * ATR) input double MinExitBodyRatio = 2.0; // Exit must be at least this many times bigger than base input bool CollectAllData = true; // TRUE=log all pairs, FALSE=use above filters now input string OutFilePrefix = "SD_BaseExit";
これらの入力パラメータにより、本スクリプトは柔軟性の高いリサーチツールとして機能します。初期段階の探索的分析では、CollectAllDataをtrueに設定し、できるだけ広範なサンプルを収集することが推奨されます。その後、分析によって有望な条件が見えてきた段階では、CollectAllDataをfalseに設定することで、MaxBaseBodyATRやMinExitBodyRatioといった閾値を直接指定し、MetaTrader 5上で特定条件を検証することができます。
2. 初期化処理の中核(OnStart関数)
このセクションでは、データ収集および保存に必要となる基本的な準備処理を実行します。具体的には、ATRデータの取得準備と、出力先となるCSVファイルの作成を行います。
- ATRハンドルの作成:ATRデータを取得します。これはボラティリティ環境を把握するうえで重要です。
- CSVファイルの作成:データを書き込むための新しいファイルを開きます。ファイル名にはシンボル名と時間足が含まれており、データを整理しやすくしています。
- CSVヘッダー行:列名を書き込み、データセットの構造を定義します。
// 1. INITIALIZATION: Get ATR data and open the data log (CSV file) atrHandle = iATR(_Symbol, _Period, ATR_Period); if(atrHandle == INVALID_HANDLE) { Print("Error: Could not get ATR data."); return; } string tf = PeriodToString(_Period); string fileName = StringFormat("%s_%s_%s.csv", OutFilePrefix, _Symbol, tf); int fileHandle = FileOpen(fileName, FILE_WRITE|FILE_CSV|FILE_ANSI); if(fileHandle == INVALID_HANDLE) { Print("Failed to create file: ", fileName); return; } // Write the header. Each row will be one observed "base-exit" candle pair. FileWrite(fileHandle, "Pattern", "Symbol", "Timeframe", "Timestamp", "Base_BodyPips", "Exit_BodyPips", "ExitToBaseRatio", "ATR_Pips", "Base_BodyATR", "Exit_BodyATR", "Base_Open", "Base_Close", "Exit_Open", "Exit_Close" );
3. メインスキャンループ:パターン検出エンジン
このforループはスクリプトの中核部分であり、履歴データ内の連続する確定済みローソク足のペアを順番に検証します。
処理フロー:
- ローソク足ペアの生成とデータ抽出:各バーiに対して、ローソク足iをベース候補、ローソク足 i-1 をエグジット候補として扱います。スクリプトは価格データを取得し、実体サイズやATR比率を計算します。
- パターン判定ロジック:2本のローソク足が連続しており、かつ同じ方向を向いているかを判定します。
- 陽線ペア → 「デマンド」パターン候補として分類
- 陰線ペア → 「サプライ」パターン候補として分類
- 方向が一致しないペアは対象外として除外されます。
// 2. MAIN SCANNING LOOP: Look at every consecutive pair of candles for(int i = 1; i < barsToCheck; i++) { int baseIdx = i; // The older candle (potential base) int exitIdx = i - 1; // The newer candle (potential exit) // ... (Data extraction for base and exit candles) ... // 3. PATTERN IDENTIFICATION: Determine direction and type string patternType = "None"; bool isBullishBase = baseClose > baseOpen; bool isBullishExit = exitClose > exitOpen; bool isBearishBase = baseClose < baseOpen; bool isBearishExit = exitClose < exitOpen; // The core logic: A valid pattern requires consecutive candles in the SAME direction. if(isBullishBase && isBullishExit) { patternType = "Demand"; } else if(isBearishBase && isBearishExit) { patternType = "Supply"; } if(patternType == "None") continue; // Skip mixed-direction pairs
4. 戦略的フィルタリング:データ量とデータ品質のバランス
これは研究プロセスにおける重要な意思決定ポイントであり、CollectAllDataフラグによって制御されます。この設定は、探索的分析のために幅広いサンプルを収集するか、あるいは最初から厳格なフィルタ条件を適用するかを決定します。
// 4. DATA FILTERING (Optional): Apply size rules if not collecting everything if(!CollectAllData) { // Rule: Base candle must be relatively small compared to market noise bool isBaseSmallEnough = baseBodyATR < MaxBaseBodyATR; // Rule: Exit candle must be significantly larger than the base bool isExitLargeEnough = exitToBaseRatio >= MinExitBodyRatio; if(!isBaseSmallEnough || !isExitLargeEnough) { continue; // Skip this pair, it doesn't meet our current test filters } } // If CollectAllData is TRUE, we log EVERY same-direction pair, regardless of size. // This is best for initial research.
5. データロギングとクリーンアップ
有効なパターンが検出されるたびに、その詳細情報を含む1行がCSVファイルへ書き込まれます。最後に、使用したリソースは適切に解放されます。
// 5. DATA LOGGING: Write all details of this pair to our CSV file datetime exitTime = iTime(_Symbol, _Period, exitIdx); MqlDateTime dtStruct; TimeToStruct(exitTime, dtStruct); string timeStamp = StringFormat("%04d-%02d-%02dT%02d:%02d:%02d", dtStruct.year, dtStruct.mon, dtStruct.day, dtStruct.hour, dtStruct.min, dtStruct.sec); FileWrite(fileHandle, patternType, _Symbol, tf, timeStamp, DoubleToString(baseBodyPips, 2), DoubleToString(exitBodyPips, 2), DoubleToString(exitToBaseRatio, 2), DoubleToString(atrExit / _Point, 2), DoubleToString(baseBodyATR, 3), DoubleToString(exitBodyATR, 3), DoubleToString(baseOpen, _Digits), DoubleToString(baseClose, _Digits), DoubleToString(exitOpen, _Digits), DoubleToString(exitClose, _Digits) ); dataRowsWritten++; } // 6. CLEANUP: Close the file and release the indicator handle FileClose(fileHandle); IndicatorRelease(atrHandle);
MQL5スクリプトによって生データを収集した後、次の重要なステップは、このデータセットを統計分析環境へシームレスに移行することです。このプロセスでは、出力されたデータファイルを特定し、Pythonによるリサーチ環境を起動します。
収集したデータの保存場所
処理が完了すると、スクリプトはCSVファイルをMetaTrader 5のデータフォルダ内にある標準のMQL5/Files/ディレクトリへ保存します。保存先のパスは通常、以下の形式になります。
C:\Users\[YourUserName]\AppData\Roaming\MetaQuotes\Terminal\[TerminalID]\MQL5\Files.
ファイル名はスクリプトで定義した命名規則に従って生成されます(例: SD_BaseExit_EURUSD_H1.csv)このファイルには、検出されたすべての「Base-Exit」ローソク足ペアと、それぞれに対して計算された各種メトリクスがタイムスタンプ付きで保存されています。
Python分析環境の起動
分析を開始するには、コマンドラインインターフェース(コマンドプロンプトまたはターミナル)を開き、対象ディレクトリへ移動した後、Jupyter Notebookを起動します。この作業は、いくつかのコマンドを実行するだけで効率的におこなうことができます。
# Navigate to the directory containing your CSV file cd "C:\Users\[YourUserName]\AppData\Roaming\MetaQuotes\Terminal\[TerminalID]\MQL5\Files" # Launch the Jupyter Notebook server jupyter notebook
この一連の操作により、JupyterLabのインターフェースがWebブラウザ上に起動され、データへの直接的なアクセス環境が構築されます。ここから新規Notebook(例:Supply_and_demand_Research.ipynb)を作成し、本リサーチ専用の分析環境として使用します。
ステージ2:統計的発見と閾値最適化(Python/Jupyter Notebook)
セル1:セットアップとデータ取得
このセルでは、Pythonによるリサーチ環境を初期化し、MetaTrader 5から出力されたデータセットを読み込んで分析可能な状態にします。
まず、必要となる科学計算および可視化ライブラリをインポートします。これらのライブラリはデータ操作(pandas, numpy)、統計解析(scipy)、グラフ可視化(matplotlib, seaborn)に使用されます。また、出力をクリーンかつ読みやすく保つために、警告メッセージは抑制されます。これは特に記事として結果を提示する際に重要です。
次に、チャートのビジュアルスタイルを設定し、統一された品質のプロットを生成できるようにします。これにより、以降の分析で作成されるすべてのグラフが一貫したテーマを持ち、分布や傾向がより明確に解釈可能になります。
その後、MQL5データ収集スクリプトによって生成されたCSVファイルを読み込みます。このファイルはタブ区切り形式でエクスポートされているため、正しくデータを解析するために適切な区切り文字を明示的に指定します。このステップは、特にpips値・比率・タイムスタンプといった数値データの整合性を維持するうえで極めて重要です。
# %% [markdown] # # # **Objective:** Analyze the harvested candlestick data to discover statistically significant thresholds for a valid "impulsive exit." # **Data:** `SD_BaseExit_XAUUSDr_5.csv` # **Method:** Exploratory Data Analysis (EDA), Distribution Analysis, and Success Rate Correlation. # %% [markdown] # ## 1. Setup & Data Ingestion (Corrected) # Loading tab-delimited data # %% import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from scipy import stats import warnings warnings.filterwarnings('ignore') # Set visual style plt.style.use('seaborn-v0_8-darkgrid') sns.set_palette("husl") # Load the data with TAB as delimiter file_path = "SD_BaseExit_XAUUSDr_5.csv" df = pd.read_csv(file_path, sep='\t') # Tab-separated print("✅ Data loaded successfully (tab-delimited).") print(f"Dataset shape: {df.shape}") print("\n🔍 Column names:") print(list(df.columns)) print("\n📊 First 3 rows:") print(df.head(3))
結果1:
✅ Data loaded successfully (tab-delimited). Dataset shape: (9663, 14) 🔍 Column names: ['Pattern', 'Symbol', 'Timeframe', 'Timestamp', 'Base_BodyPips', 'Exit_BodyPips', 'ExitToBaseRatio', 'ATR_Pips', 'Base_BodyATR', 'Exit_BodyATR', 'Base_Open', 'Base_Close', 'Exit_Open', 'Exit_Close'] 📊 First 3 rows: Pattern Symbol Timeframe Timestamp Base_BodyPips \ 0 Demand XAUUSDr 5 2026-01-12T06:45:00 194.0 1 Demand XAUUSDr 5 2026-01-12T06:40:00 226.0 2 Supply XAUUSDr 5 2026-01-12T06:30:00 104.0 Exit_BodyPips ExitToBaseRatio ATR_Pips Base_BodyATR Exit_BodyATR \ 0 155.0 0.80 311.64 0.545 0.497 1 194.0 0.86 355.64 0.632 0.545 2 477.0 4.59 365.79 0.273 1.304 Base_Open Base_Close Exit_Open Exit_Close 0 4566.03 4567.97 4567.96 4569.51 1 4563.80 4566.06 4566.03 4567.97 2 4569.60 4568.56 4568.61 4563.84 🤝
セル2:初期データの確認およびクリーニング
このステップでは、統計解析へ進む前に、データセットの構造、データ型、全体的な品質を確認します。まず、すべての重要な計測フィールドが正しく存在していることを検証します。また、欠損値の有無をチェックし、データの完全性を確認します。次に、ローソク足のサイズ、ATR、エグジット対ベース比率といった主要列が数値型として正しく解釈されていることを確認します。最後に、これらの重要フィールドにおいて不完全または無効な値を含む行を削除します。この処理により、クリーンで信頼性の高いデータセットが生成され、以降の探索的分析および統計解析の堅牢な基盤となります。
# %% [markdown] # ## 2. Initial Data Inspection & Cleaning # %% print("📊 Dataset Info:") print(df.info()) print("\n🧹 Checking for missing values:") print(df.isnull().sum()) # Ensure numeric columns are correctly typed numeric_cols = ['Base_BodyPips', 'Exit_BodyPips', 'ExitToBaseRatio', 'ATR_Pips', 'Base_BodyATR', 'Exit_BodyATR'] for col in numeric_cols: if col in df.columns: df[col] = pd.to_numeric(df[col], errors='coerce') else: print(f"⚠️ Warning: Column '{col}' not found in data") # Remove any rows with missing critical data df_clean = df.dropna(subset=numeric_cols).copy() print(f"\n🧽 Data cleaned. Original: {df.shape}, Cleaned: {df_clean.shape}")
結果2:
📊 Dataset Info: <class 'pandas.core.frame.DataFrame'> RangeIndex: 9663 entries, 0 to 9662 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pattern 9663 non-null object 1 Symbol 9663 non-null object 2 Timeframe 9663 non-null int64 3 Timestamp 9663 non-null object 4 Base_BodyPips 9663 non-null float64 5 Exit_BodyPips 9663 non-null float64 6 ExitToBaseRatio 9663 non-null float64 7 ATR_Pips 9663 non-null float64 8 Base_BodyATR 9663 non-null float64 9 Exit_BodyATR 9663 non-null float64 10 Base_Open 9663 non-null float64 11 Base_Close 9663 non-null float64 12 Exit_Open 9663 non-null float64 13 Exit_Close 9663 non-null float64 dtypes: float64(10), int64(1), object(3) memory usage: 1.0+ MB None 🧹 Checking for missing values: Pattern 0 Symbol 0 Timeframe 0 Timestamp 0 Base_BodyPips 0 Exit_BodyPips 0 ExitToBaseRatio 0 ATR_Pips 0 Base_BodyATR 0 Exit_BodyATR 0 Base_Open 0 Base_Close 0 Exit_Open 0 Exit_Close 0 dtype: int64 🧽 Data cleaned. Original: (9663, 14), Cleaned: (9663, 14)
セル3:サプライ&デマンド・エグジット指標の初期統計探索
この段階では、収集された測定データに対してEDAを実施し、初期的な統計的理解を得ます。まず、すべての主要な数値変数に対して記述統計を算出し、中心傾向、ばらつき、および全体的な分布を確認します。これにより、ベースおよびエグジットローソク足それぞれの典型的なサイズと変動性を評価します。次に、データセット内におけるサプライおよびデマンドパターンの分布を確認し、その出現頻度を可視化します。この分析により、研究サンプルが特定の方向に偏っていないか、また統計的に十分にバランスの取れた構成になっているかを検証します。
# %% [markdown] # ## 3. Exploratory Data Analysis (EDA) # %% print("🧮 Descriptive Statistics of Key Metrics:") print(df_clean[numeric_cols].describe().round(2)) # Pattern Distribution print(f"\n📈 Pattern Type Distribution:") if 'Pattern' in df_clean.columns: pattern_counts = df_clean['Pattern'].value_counts() print(pattern_counts) # Simple Visualization: Pattern Count plt.figure(figsize=(8,5)) sns.barplot(x=pattern_counts.index, y=pattern_counts.values) plt.title('Count of Supply vs. Demand Patterns Collected') plt.ylabel('Count') plt.show() else: print("⚠️ 'Pattern' column not found")
結果3:
🧮 Descriptive Statistics of Key Metrics: Base_BodyPips Exit_BodyPips ExitToBaseRatio ATR_Pips Base_BodyATR \ count 9663.00 9663.00 9663.00 9663.00 9663.00 mean 237.15 247.71 4.13 473.72 0.62 std 253.53 268.18 17.92 230.17 0.82 min 1.00 1.00 0.00 99.50 0.00 25% 74.00 75.00 0.42 316.64 0.16 50% 168.00 173.00 1.04 421.00 0.38 75% 314.00 325.50 2.55 568.36 0.78 max 3441.00 3441.00 770.00 2156.36 22.79 Exit_BodyATR count 9663.00 mean 0.64 std 0.85 min 0.00 25% 0.16 50% 0.39 75% 0.81 max 22.79 📈 Pattern Type Distribution: Pattern Demand 5131 Supply 4532 Name: count, dtype: int64

セル4:高モメンタムのサプライ・デマンド・エグジットの抽出
このステップでは、データセットを意図的に絞り込み、強いモメンタムを伴うサプライおよびデマンドのシナリオに焦点を当てます。具体的には、エグジットローソク足の実体がベースローソク足の実体を大きく上回るケースのみをフィルタリングします。エグジット対ベースの実体比率が 1.5を超えるパターンのみを保持することで、トレーダーが一般的に「インパルシブ(impulsive)」と表現するゾーン離脱に構造的・視覚的に一致する候補を抽出します。このフィルタリングにより、わずかな価格変動によるノイズを排除し、分析対象を純粋な高モメンタム・エグジットに限定します。その結果、後続の統計解析では、機関投資家レベルのディスプレイスメント(流動性移動)を示す可能性が高いケースに集中することが可能になります。
# Add this after creating df_clean, BEFORE the clustering cell # Filter to only look at patterns where exit was at least 1.5x the base df_strong = df_clean[df_clean['ExitToBaseRatio'] > 1.5].copy() print(f"Analyzing strong candidates: {df_strong.shape[0]} patterns (>{df_clean.shape[0]} total)")
結果4:
Analyzing strong candidates: 3725 patterns (>9663 total)
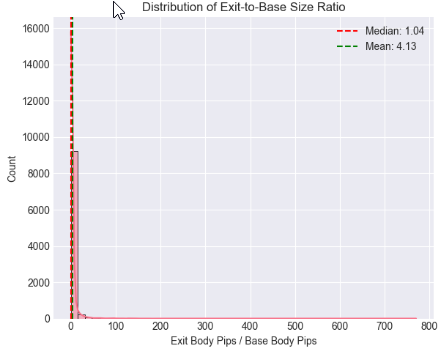
セル5: エグジット対ベース比率の統計分布および閾値分析
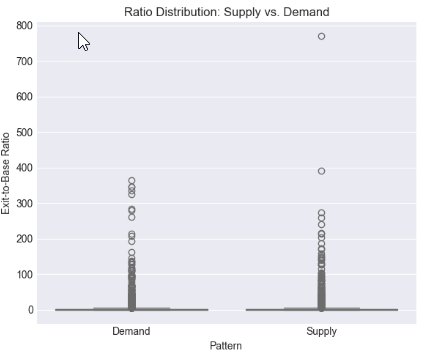
このステップでは、分布プロットおよびボックスプロットを用いて、エグジット強度が全体としてどのように分布しているか、またサプライ構造とデマンド構造の間でどのような違いがあるかを評価します。平均値、中央値、およびパーセンタイル境界を算出することで、視覚的判断を超えたデータ駆動型のベンチマークを確立します。これにより、通常の価格変動と統計的に有意なディスプレイスメント(価格の構造的移動)を一貫して区別できる比率レンジを特定することが可能になります。
# %% [markdown] # ## 4. Core Analysis: Distribution of Exit-to-Base Ratio # %% if 'ExitToBaseRatio' in df_clean.columns: plt.figure(figsize=(12, 5)) # Histogram with KDE plt.subplot(1, 2, 1) sns.histplot(data=df_clean, x='ExitToBaseRatio', bins=50, kde=True) plt.axvline(x=df_clean['ExitToBaseRatio'].median(), color='red', linestyle='--', label=f'Median: {df_clean["ExitToBaseRatio"].median():.2f}') plt.axvline(x=df_clean['ExitToBaseRatio'].mean(), color='green', linestyle='--', label=f'Mean: {df_clean["ExitToBaseRatio"].mean():.2f}') plt.title('Distribution of Exit-to-Base Size Ratio') plt.xlabel('Exit Body Pips / Base Body Pips') plt.legend() # Box plot by Pattern type if 'Pattern' in df_clean.columns: plt.subplot(1, 2, 2) sns.boxplot(data=df_clean, x='Pattern', y='ExitToBaseRatio') plt.title('Ratio Distribution: Supply vs. Demand') plt.ylabel('Exit-to-Base Ratio') plt.tight_layout() plt.show() # Critical Percentile Analysis print("📐 Key Percentiles for ExitToBaseRatio:") percentiles = [5, 25, 50, 75, 90, 95, 99] for p in percentiles: value = df_clean['ExitToBaseRatio'].quantile(p/100) print(f" {p}th percentile: {value:.2f}") else: print("⚠️ 'ExitToBaseRatio' column not found")
結果5:
Key Percentiles for ExitToBaseRatio: 5th percentile: 0.08 25th percentile: 0.42 50th percentile: 1.04 75th percentile: 2.55 90th percentile: 6.67 95th percentile: 13.41 99th percentile: 61.57
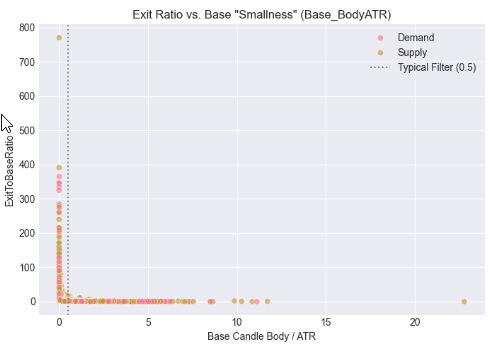
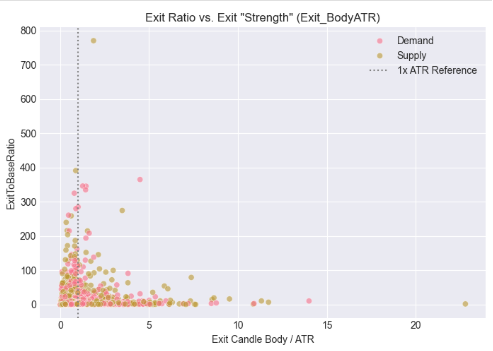
セル6: ボラティリティ(ATRコンテキスト)によるエグジット強度の正規化
このステップでは、ローソク足サイズを市場ボラティリティの観点から補正するため、ベースおよびエグジットの実体をATRと関連付けて分析します。単純なpipsベースの絶対値評価ではなく、ベースローソク足の相対的な小ささ、およびエグジットローソク足のATR基準での強度を評価します。その結果として得られる散布図は、インパルシブ・エグジットが特定のボラティリティ調整済み閾値付近にクラスタを形成することを示します。この観察は、有効なサプライ・デマンドの離脱を絶対的なサイズではなく相対的な強度によって定義する方が適切であるという仮説を支持します。さらにこのアプローチは、銘柄間および時間足間での一貫性を持つ自動売買ロジック構築に対して、より堅牢な基盤を提供します。
# %% [markdown] # ## 5. Contextualizing Size: The Role of Volatility (ATR) # %% if all(col in df_clean.columns for col in ['Base_BodyATR', 'Exit_BodyATR', 'ExitToBaseRatio', 'Pattern']): fig, axes = plt.subplots(1, 2, figsize=(14, 5)) # Base Body vs. ATR sns.scatterplot(data=df_clean, x='Base_BodyATR', y='ExitToBaseRatio', hue='Pattern', alpha=0.6, ax=axes[0]) axes[0].axvline(x=0.5, color='gray', linestyle=':', label='Typical Filter (0.5)') axes[0].set_title('Exit Ratio vs. Base "Smallness" (Base_BodyATR)') axes[0].set_xlabel('Base Candle Body / ATR') axes[0].legend() # Exit Body vs. ATR sns.scatterplot(data=df_clean, x='Exit_BodyATR', y='ExitToBaseRatio', hue='Pattern', alpha=0.6, ax=axes[1]) axes[1].axvline(x=1.0, color='gray', linestyle=':', label='1x ATR Reference') axes[1].set_title('Exit Ratio vs. Exit "Strength" (Exit_BodyATR)') axes[1].set_xlabel('Exit Candle Body / ATR') axes[1].legend() plt.tight_layout() plt.show() else: print("⚠️ Missing required columns for ATR analysis")
結果6:
セル7:強いエグジットのクラスタリング
この最終分析ステップでは、k平均法クラスタリングを用いて、最も強いエグジットローソク足が「中程度(moderate)」や「強い(strong)」インパルスといった異なるカテゴリに自然に分かれるかどうかを検証します。クラスタリングでは、エグジット対ベース比率(exit-to-base ratio)とボラティリティ調整済みエグジットサイズ(exit body / ATR)の2つの特徴量を使用します。本分析の目的は、高モメンタムデータセットの内部に存在する統計的に意味のあるサブグループを特定することです。クラスタ数の決定にはエルボー法(Elbow Method)を使用し、適切なクラスタ数を推定します。また、散布図およびクラスタごとのプロファイル分析を通じて、各グループ間の差異を可視化し定量化します。このアプローチにより、視覚的判断に依存しない、再現可能なデータ駆動型の閾値設計が可能になります。さらに、この結果は後続のMQL5実装において、有効なサプライ&デマンド、エグジットを自動検出するための基準値として直接利用可能です。これにより、裁量的な判断から脱却し、アルゴリズム化された取引ルールへと移行する基盤が構築されます。
# %% [markdown] # ## 6. Statistical Clustering: Finding Natural "Impulsive Exit" Groups # **Objective:** Use K-Means clustering to see if our strong candidates (`df_strong`) naturally group into categories like "Moderate" and "Strong" impulses based on their size ratio and volatility-adjusted strength. # %% from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler # --- Step 1: Prepare Features for Clustering --- # We will cluster based on TWO dimensions: # 1. ExitToBaseRatio (How much bigger is the exit?) # 2. Exit_BodyATR (How significant is the exit in current market noise?) print("Preparing features for clustering...") cluster_features = df_strong[['ExitToBaseRatio', 'Exit_BodyATR']].copy() # Check for any missing values (should be none after our cleaning) print(f"Features shape: {cluster_features.shape}") # Standardize the features (critical for K-Means) scaler = StandardScaler() features_scaled = scaler.fit_transform(cluster_features) print("Features scaled (standardized).\n") # --- Step 2: The Elbow Method (Optional but Recommended) --- # Helps suggest a reasonable number of clusters (K). print("Running Elbow Method to suggest optimal K...") inertias = [] K_range = range(1, 8) # Test from 1 to 7 clusters for k in K_range: kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto') # n_init='auto' for newer scikit-learn kmeans.fit(features_scaled) inertias.append(kmeans.inertia_) # Inertia = sum of squared distances to cluster center # Plot the Elbow Curve plt.figure(figsize=(8,5)) plt.plot(K_range, inertias, 'bo-') plt.xlabel('Number of Clusters (K)') plt.ylabel('Inertia (Lower is Better)') plt.title('Elbow Method for Optimal K: Where the line "bends"') plt.grid(True, alpha=0.3) plt.show() print("Inertia values:", [f"{i:.0f}" for i in inertias]) print("Look for a 'kink' or elbow in the plot above. Often K=2 or K=3 works well.\n") # --- Step 3: Apply K-Means Clustering --- # YOU NEED TO CHOOSE K based on the elbow plot and your research goal. # For distinguishing "Strong" vs "Very Strong" impulses, start with K=2 or 3. chosen_k = 3 # <-- CHANGE THIS based on the elbow plot. Try 2 or 3. print(f"Applying K-Means clustering with K = {chosen_k}...") kmeans = KMeans(n_clusters=chosen_k, random_state=42, n_init='auto') cluster_labels = kmeans.fit_predict(features_scaled) # Add the cluster labels back to our main dataframe df_strong['Cluster'] = cluster_labels print(f"Clustering complete. Cluster labels added to 'df_strong'.\n") # --- Step 4: Visualize the Clusters --- print("Visualizing clusters...") plt.figure(figsize=(11, 6)) # Create a scatter plot, coloring points by their assigned cluster scatter = plt.scatter(df_strong['ExitToBaseRatio'], df_strong['Exit_BodyATR'], c=df_strong['Cluster'], cmap='viridis', alpha=0.6, s=30) # s is point size plt.xlabel('Exit-to-Base Ratio', fontsize=12) plt.ylabel('Exit Body / ATR', fontsize=12) plt.title(f'K-Means Clustering of Strong Impulses (K={chosen_k})\nEach color is a distinct group', fontsize=14) # Add a colorbar and grid plt.colorbar(scatter, label='Cluster ID') plt.grid(True, alpha=0.3) plt.show() # --- Step 5: Analyze and Profile Each Cluster --- print("="*60) print("CLUSTER PROFILE ANALYSIS") print("="*60) # 5.1 Basic Counts print("\n📊 1. Number of patterns per cluster:") cluster_counts = df_strong['Cluster'].value_counts().sort_index() for clus_id, count in cluster_counts.items(): percentage = (count / len(df_strong)) * 100 print(f" Cluster {clus_id}: {count:4d} patterns ({percentage:.1f}% of strong candidates)") # 5.2 Mean (Center) of each cluster print("\n📈 2. Cluster Centers (MEAN values):") # Get the original feature means for each cluster cluster_profile = df_strong.groupby('Cluster')[['ExitToBaseRatio', 'Exit_BodyATR', 'Base_BodyATR']].mean().round(3) print(cluster_profile) # 5.3 Key Percentiles within each cluster (more robust than mean) print("\n📐 3. Key PERCENTILES for ExitToBaseRatio in each cluster:") for clus_id in range(chosen_k): cluster_data = df_strong[df_strong['Cluster'] == clus_id] print(f"\n Cluster {clus_id}:") for p in [25, 50, 75, 90]: # 25th, Median (50th), 75th, 90th percentiles value = cluster_data['ExitToBaseRatio'].quantile(p/100) print(f" {p}th percentile: {value:.2f}") # 5.4 Pattern Type distribution within clusters if 'Pattern' in df_strong.columns: print("\n🧩 4. Pattern Type (Supply/Demand) mix per cluster:") pattern_mix = pd.crosstab(df_strong['Cluster'], df_strong['Pattern'], normalize='index') * 100 print(pattern_mix.round(1).astype(str) + ' %') print("\n" + "="*60) print("ANALYSIS COMPLETE")
結果7:

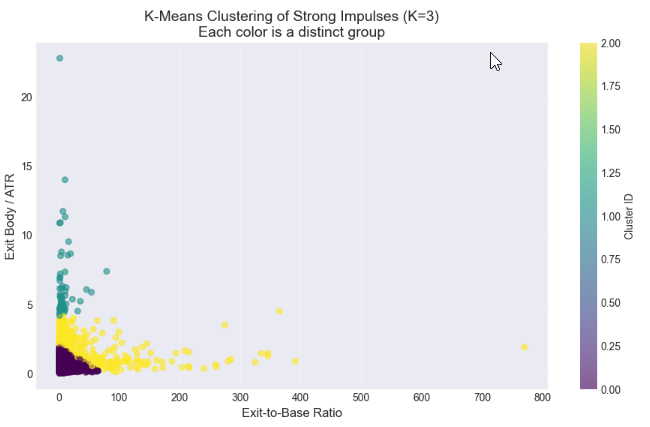
============================================================ CLUSTER PROFILE ANALYSIS ============================================================ 📊 1. Number of patterns per cluster: Cluster 0: 3153 patterns (84.6% of strong candidates) Cluster 1: 62 patterns (1.7% of strong candidates) Cluster 2: 510 patterns (13.7% of strong candidates) 📈 2. Cluster Centers (MEAN values): ExitToBaseRatio Exit_BodyATR Base_BodyATR Cluster 0 5.845 0.670 0.216 1 9.649 6.391 1.541 2 34.023 2.264 0.566 📐 3. Key PERCENTILES for ExitToBaseRatio in each cluster: Cluster 0: 25th percentile: 2.11 50th percentile: 3.21 75th percentile: 6.21 90th percentile: 12.73 Cluster 1: 25th percentile: 2.99 50th percentile: 4.80 75th percentile: 10.63 90th percentile: 19.45 Cluster 2: 25th percentile: 2.75 50th percentile: 5.75 75th percentile: 32.23 90th percentile: 98.36 🧩 4. Pattern Type (Supply/Demand) mix per cluster: Pattern Demand Supply Cluster 0 52.6 % 47.4 % 1 41.9 % 58.1 % 2 48.4 % 51.6 % ============================================================ ANALYSIS COMPLETE
結果
強い候補(ExitToBaseRatio > 1.5)に対してk平均法クラスタリングを適用した結果、3つの明確な行動グループが確認されました。このセグメンテーションは、「インパルス」を単一の概念として扱う従来の見方を超え、市場の小さなベースから発生する値動きに対する統計的に裏付けられた分類体系を提供します。
クラスタ0:コア・インパルシブ・エグジット
このクラスタは最も支配的かつ重要なパターンであり、検証済みの強い候補の84.6%を占めます。
統計的プロファイル:このクラスタは、ExitToBaseRatioの中央値が 3.21 であることが特徴です。これは、有意なインパルシブ・エグジットが平均的にベースの3倍以上のサイズを持つことを示しており、一般的に想定される「2倍ルール」を明確に上回ります。このクラスタは、平均Exit_BodyATRが0.67と中程度の絶対サイズを示し、平均Base_BodyATRがわずか0.22であることから、定義上の「小さなベース」であることを確認しています。
取引シグナルとしての解釈:このクラスタはシステマティック戦略の主要ターゲットとなります。これは典型的な「小さなベース → 大きなエグジット」という高確率パターンであり、コンソリデーションの後に、ベースおよび市場ボラティリティの両方に対して有意な決定的値動きが発生する構造を示しています。
クラスタ1:高ボラティリティ異常
このクラスタは全体のわずか1.7%を占める小規模グループです。
統計的プロファイル:これは、極端に高い平均Exit_BodyATR 6.39 と異常に高い平均Base_BodyATR 1.54 と、高い ExitToBaseRatio(平均:9.65)で定義されます。
取引シグナルとしての解釈:このクラスタは、ニュース起因のギャップや急激なボラティリティスパイクなどの非定常市場イベントを捉えていると解釈されます。この場合、ベースローソク足は「コンソリデーション」としての性質を満たしておらず、サプライ&デマンド構造の前提条件を破っています。そのため、このクラスタは再現性のある取引戦略には不向きな統計的アウトライアとして扱われ、明示的に除外されます。
クラスタ2:極端比率アウトライア
このクラスタは全体の13.7%を占めます。
統計的プロファイル:非常に高いExitToBaseRatio値 (中央値:5.75、90パーセンタイル:98.36)で、平均Exit_BodyATRは2.26と中程度でした。これは、最小平均ベースサイズ(Base_BodyATR:0.57)から生じています。
取引シグナルとしての解釈:相対的な比率は数学的には極端ですが、実際の取引上の重要性はクラスタ0と比べて比例的に大きいわけではありません。この極端な比率は、ベースサイズがほぼゼロに近いことに起因している場合が多く、必ずしも有効な保ち合い領域を一貫して示しているとは限りません。サンプルサイズが小さく、解釈可能性も低いため、このクラスタも、より堅牢でサンプル数の多いコアクラスタを優先して評価するために優先度を下げています。
クラスタ0の3,153件の高品質パターンに基づき、以下は最適化された統計的パラメータです。
| パラメータ | 元の(主観的)値 | 最適化後(データ駆動)値 | 統計的根拠(クラスタ0分析に基づく) |
|---|---|---|---|
| MinExitBodyRatio: エグジットはベースの何倍以上である必要があるか | 2.0 | 3.0 | 信頼性の高いパターン(クラスタ0)におけるExit-to-Base比の中央値は3.21であり、3.0という閾値はより強く重要なインパルスの上位半分を捉えるためです。 |
| MaxBaseBodyATR: ボディサイズ(ATR比)上限 | 0.5 | 0.3 | クラスタ0のBase_BodyATRの平均は0.22であり、閾値を0.3に引き下げることで真のコンソリデーションをより厳密に抽出し、曖昧な大きめのローソク足を除外できます。 |
| MinExitBodyATR: エグジットの最低ATR強度(未定義) | 未定義 | 0.5 | クラスタ0のExit_BodyATR平均は0.67であり、0.5以上とすることで、市場ノイズに対して意味のあるモメンタムを持つエグジットのみを対象とします。 |
結論
この研究は、定量的取引開発サイクルの重要な前半部分、すなわち視覚的な概念から統計的に検証された定義への移行を成功裏に完了しました。サプライとデマンドに基づくインパルス・エグジットという概念に対して、厳密なデータ収集と機械学習のパイプラインを適用することで、勘や推測をデータに基づく根拠へと置き換えました。
私たちの主要な発見は、市場における最も信頼性の高い「小さなベースから大きなエグジット」パターン、すなわちクラスタ0が、明確かつ測定可能な特徴によって定義されるという点です。それは、通常ベースの約3倍の大きさを持つエグジット・ローソク足であり、同時に市場のボラティリティに対して意味のある絶対的モメンタムも備えているというものです。導出されたパラメータ(MinExitBodyRatio = 3.0、MaxBaseBodyATR = 0.3、MinExitBodyATR = 0.5)は、恣意的な最適化ではなく、高確率イベントの経験的なプロファイルです。
この分析は、自動化に向けた本質的な設計図を提供します。これら3つのデータ駆動型パラメータは、MQL5のエキスパートアドバイザーにおける明確で曖昧さのないロジックブロックへと直接変換可能です。
この関数は、本研究から生まれたコアとなる取引ルールを体現するものです。これは、2本のローソク足パターンをスキャンし、この統計的な基準で検証し、精密に取引をおこなう包括的なエキスパートアドバイザーへ統合することができます。その後のステップ(取引管理、リスク制御、マルチタイムフレーム分析の追加)は、この実証された基盤の上に構築されるエンジニアリング作業です。
今後の発表では、これらの研究成果を完全に機能する取引システムへと変換します。具体的には以下を詳述する予定です。
- この検証ロジックを堅牢なスキャニングエンジンへ統合する方法
- ゾーンベース戦略と整合したエントリー、ストップロス、テイクプロフィット機構の設計
- 既存のデフォルト値と比較した場合の、データ導出パラメータによるパフォーマンス影響を示すバックテスト結果
手動チャート分析からPythonによる解析、そして最終的にMQL5での最適化コードへと至るこのプロセスは、現代的でエビデンスに基づいた戦略開発アプローチを示しています。アルゴリズムを統計的現実に基づかせることで、私たちは単なる自動化ではなく、「知的に最適化された自動化」ツールの構築を目指しています。
本研究から得られた主要な知見は、下の表と添付資料にまとめられています。コメント欄でのご意見やさらなる議論も歓迎します。次回の発表では、これらの成果を基にしたシステム構築について解説しますので、ぜひご期待ください。
重要な学び
| 重要な学び | 説明 |
|---|---|
| 主観性は定量化されなければならない | 「インパルス的エグジット」のような価格アクション概念を自動化する上での核心的課題は、それらが主観的かつ視覚的な性質を持つ点である。重要な教訓は、トレーダーの目によって評価されるあらゆる特性を、検証および自動化可能な数値的指標(例:ローソク足のボディ比率、ATR倍率)へと分解する必要があるということである。 |
| データ駆動型パラメータは従来の常識に勝る | 一般的な経験則(例:エグジットはベースの2倍など)は未検証である場合が多い。体系的なデータ収集と分析の結果、対象銘柄における統計的に有意な閾値はそれより高いことが判明し、より堅牢でエビデンスに基づくルール(MinExitBodyRatio = 3.0)へとつながった。 |
| リサーチパイプラインの重要性 | MQL5(データ収集)→Python(統計解析)という二段階の構造化パイプラインは不可欠である。このプロセスにより、市場観察からアルゴリズムロジックへの明確かつ再現可能な経路が形成され、最終的なEAが推測ではなく実証データに基づくものとなる。 |
| クラスタリングは市場の微細構造を明らかにする | k平均法クラスタリングを適用することで、単なるノイズ除去にとどまらず、市場内部に存在するインパルスの分類構造が明らかになった。「コア」クラスタ(クラスタ0)を特定することで、任意の閾値ではなく、市場において最も頻出かつ一貫性のあるパターンに基づいたパラメータ定義が可能となった。 |
| コンテキストが重要である | モメンタムの評価には相対的視点と絶対的視点の両方が必要である。ExitToBaseRatioが高くても、ローソク足自体がATRに対して極小であれば意味を持たない。この洞察から、最低限のExit_BodyATR (0.5)を定義する必要が導かれ、より包括的なフィルタが構築された。 |
| リサーチと実運用の橋渡し | 定量分析の最終目標は実行可能なコードの生成である。最も重要な教訓は、クラスタ0の特性のような統計的知見をMQL5の検証関数へ直接変換し、リサーチノートとライブチャートを直結させることである。 |
添付ファイル
| ファイル名 | 説明 |
|---|---|
| SD_BaseExit_Research.mq5 | MQL5で記述されたデータ収集用コアスクリプト。定義された2本足(ベース→エグジット)パターンを過去データから体系的にスキャンし、各パターンのローソク足サイズやATR比などの主要指標を算出します。その後、構造化されたCSVファイルとして出力し、統計解析用の生データセットを生成します。 |
| Supply_and_demand_research.ipynb | Pythonによる完全な分析ワークフローを含むJupyter Notebook。収集されたCSVデータを読み込み、EDAを実施し、分布の可視化およびk平均法クラスタリングを適用する。本ノートブックは、主観的な価格パターンを客観的な統計パラメータへと変換する中核環境である。 |
| SD_BaseExit_XAUUSDr_5.csv | MQL5スクリプトによって生成されたサンプル出力ファイル。そのファイル名は[接頭辞]_[銘柄名]_[時間足].csv というパターンに従います。このファイルには、収集されたデータセット(タイムスタンプ付きの数千件のパターン観測データと、計算されたすべての指標)が含まれており、Jupyter Notebookにインポートする準備ができています。このスクリプトは、ファイルをMetaTrader 5ターミナルの「MQL5/Files」ディレクトリ(例:.../MQL5/Files/)に自動的に保存するため、Python分析スクリプトとの直接的な互換性とシームレスなファイルパスが確保されます。 |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/20904
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索