
Vom Einsteiger zum Experten: Statistische Validierung von Angebots- und Nachfragezonen

Inhalt:
Einführung
Die Analyse von Angebots- und Nachfragezonen ist ein Eckpfeiler des Price-Action-Trading, der auf dem zeitlosen ökonomischen Prinzip des Marktungleichgewichts beruht. Im diskretionären Handel werden diese Zonen durch visuelle Mustererkennung identifiziert – eine Fähigkeit, die durch Erfahrung verfeinert wird. Diese Abhängigkeit von subjektiven Einschätzungen stellt jedoch ein erhebliches Problem für die Reproduzierbarkeit von Ergebnissen dar und ist das Haupthindernis für eine effektive Automatisierung. Während die theoretische Logik dieser Zonen gut bekannt ist, bleibt ihre Implementierung in präzise, formal definierte Regeln schwer fassbar, da oft willkürliche numerische Schwellenwerte verwendet werden.
In diesem Artikel wird eine strukturierte Forschungsmethodik vorgestellt, um diese Lücke zu schließen. Wir beschreiben eine vollständige, reproduzierbare Pipeline, die das qualitative Konzept eines „impulsiven Ausbruchs“ aus der Zone in eine quantifizierte, statistisch validierte Handelsregel umwandelt. Unser Ansatz führt eine wichtige methodische Vereinfachung ein, indem er einzelne HTF-Kerzen als grundlegende Analyseeinheit verwendet. Auf diese Weise können wir das Wesen einer Angebots- oder Nachfragezone klar erfassen und ihr bestimmendes Merkmal messen: die Dynamik.
Durch den Einsatz einer Python-basierten Forschungsumgebung in einem Jupyter-Notebook ermitteln wir systematisch die statistische Signatur einer Zone mit hoher Wahrscheinlichkeit. Die abgeleiteten Parameter werden dann in einem MQL5 Expert Advisor kodiert, wodurch ein transparentes, evidenzbasiertes Handelsinstrument entsteht. Bei diesem Prozess geht es nicht mehr um die Frage: „Sieht das stark aus?“, sondern um die Frage: „Erfüllt es die statistisch definierten Kriterien für Stärke?“
Konzeptionelle Grundlagen: Die Anatomie eines Marktungleichgewichts
Grundprinzip: Preisungleichgewicht
Eine Angebots- oder Nachfragezone markiert ein Preisniveau, bei dem das Gleichgewicht zwischen Käufern und Verkäufern entscheidend gestört ist. Ein aggressiver Zustrom von Aufträgen von einer Seite überwältigt die andere, sodass die Preise das Gebiet schnell verlassen. Dieser schnelle Ausbruch – der impulsive Ausbruch – hinterlässt eine theoretische Konzentration von nicht ausgeführten Gegenorders. Diese Zone des Ungleichgewichts wird dann zu einem künftig relevanten Bereich, da der Kurs bei einer Rückkehr typischerweise reagiert.
Definition der strukturellen Komponenten
Durch eine Synthese der Handelsliteratur und eine umfangreiche persönliche Chartanalyse kann die Anatomie einer klassischen Zone herausgearbeitet werden:
Angebotszone: Ein Bereich, in dem der Verkaufsdruck das Kaufinteresse überwiegt. Optisch erkennt man ihn an einer Konsolidierungsbasis (eine Reihe von Kerzen mit sich überlappenden Bereichen), gefolgt von einer starken, impulsiven Abwärtskerze, die unter dem Tiefpunkt der Basis schließt.
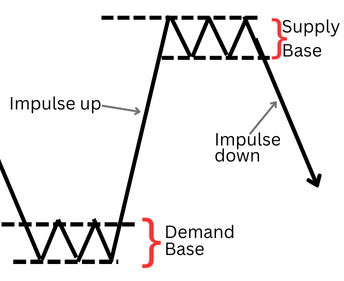
Konzepte zu Angebot und Nachfrage
Nachfragezone: Die bullische Umkehrung, bei der aggressive Käufe eine bullische, impulsive Kerze auslösen, die über dem Hoch einer Konsolidierungsbasis schließt.
Die impulsive Ausbruchskerze ist die entscheidende Komponente. Es ist die Signatur des Marktes, die das Ungleichgewicht bestätigt. Im diskretionären Trading wird die „Stärke“ visuell beurteilt, was zu Unstimmigkeiten führt. Daher wird die Größe dieser Kerze zur primären Variable für unsere quantitative Forschung.
Der komplette Lebenszyklus der Zone: Impuls, Fortsetzung und Retest
Das Verständnis des ersten Ausbruchs ist nur die erste Phase. Der gesamte Lebenszyklus einer gültigen Zone verläuft häufig in zwei Hauptbewegungen:
- Phase 1 – Anfänglicher impulsiver Ausbruch: Der Kurs bricht mit Schwung aus der Basis aus und bildet ein neues kurzfristiges Richtungsextrem.
- Phase 2 – Test und Reaktion: Der Kurs kehrt häufig in die Ursprungszone zurück und testet erneut den Bereich des Ungleichgewichts. Dieser erneute Test führt häufig zu einer zweiten, reaktiven Bewegung weg von der Zone, wenn die verbleibenden nicht ausgeführten Gegenorders auftauchen.

Nachfragezone (Konsolidierung bei A, Ausbruch bis nach B und Rückkehr in die Nachfragezone bei C)
Die folgende Abbildung zeigt einen klaren Lebenszyklus der Angebotszone, der mit den entsprechenden rückläufigen Phasen versehen ist.

Einzelkerzen-Angebotszone (S), Impuls von A nach B. Rückkehr in die Zone bei C.
In dieser Untersuchung konzentrieren wir uns auf die genaue Quantifizierung von Phase 1, dem ersten impulsiven Ausbruch. Dies ist das am klarsten definierte und messbare Ereignis, das als grundlegender Auslöser dient. Eine statistisch robuste Definition dieses Ausbruchs ermöglicht direkt die Identifizierung von Zonen mit hoher Wahrscheinlichkeit, auf denen sich Retest-Strategien zuverlässig aufbauen lassen.
Methodische Rechtfertigung: Das Modell der einzelnen Kerze mit höherem Zeithorizont
Um von visuellen Mustern zu quantifizierbaren Daten zu gelangen, gehen wir von einer zielgerichteten und robusten methodischen Prämisse aus: Der gesamte Prozess des Gleichgewichts und des Ungleichgewichts lässt sich oft effizient in der Struktur einer einzigen Kerze mit höherem Zeitrahmen (HTF) zusammenfassen.
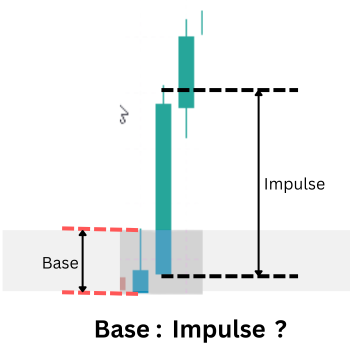
Nachfragezone einer einzelnen Kerze (kleine Basiskerze und eine große Ausbruchskerze)
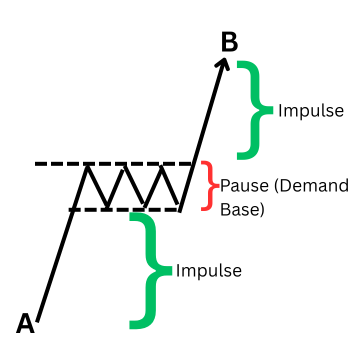
Angebot und Nachfrage finden sich auch in Fortsetzungsmustern wieder.
Konzepttreue: Eine starke, direktionale HTF-Kerze an einem Swing-Punkt ist das direkte Ergebnis des Ungleichgewichts, das wir untersuchen. Eine Analyse seiner internen Struktur im unteren Zeitrahmen würde typischerweise die klassische Sequenz einer Basis, gefolgt von einer impulsiven Bewegung, aufzeigen. Die HTF-Kerze ist die aggregierte Signatur dieser Mikrostruktur.
Vorteile für die quantitative Forschung:
- Klarheit der Signale: Sie isoliert das entscheidende Marktereignis und filtert langwierige, zweideutige Konsolidierungen heraus.
- Reduzierte parametrische Komplexität: Damit entfällt die Notwendigkeit, mehrere Parameter zur Definition einer Mehrkerzenbasis zu verwenden (z. B. Anzahl der Kerzen, zulässige Überlappung). Die Grenzen einer einzelnen Kerze (Eröffnung, Höchststand, Tiefststand, Schlussstand) sind unzweideutig.
- Fraktale Gültigkeit: Das Prinzip ist über alle Zeitrahmen hinweg einheitlich, sodass die für einen HTF (z. B. H4) durchgeführte Forschung auch auf einen niedrigeren Handelszeitrahmen (z. B. M15) angewendet werden kann.
Dieses Modell verlagert unsere Hauptmetrik vom Vergleich zweier separater Kerzen (Basis vs. Ausbruch) zur Analyse des internen Momentums einer Kerze. Wir definieren dies als das „Impulse Ratio“: (Schließen-Öffnen)/(Hoch-Tief). Ein hohes „Impulse Ratio“ (z. B. > 0,7) weist auf eine Kerze mit einem starken Richtungskörper und minimalen Dochten hin – der genaue statistische Fingerabdruck eines entscheidenden Ausbruchs.
Unsere zentrale Forschungsfrage wird daher verfeinert: Was sind die statistisch optimalen Schwellenwerte für das Impulse Ratio und die minimale absolute Größe (in Pips), die eine Zone mit hoher Wahrscheinlichkeit definieren, die eine Kerze mit höherem Zeitrahmen erzeugt?
Die Forschungs- und Implementierungspipeline
Um diese Frage zu beantworten, führen wir eine klare dreistufige Pipeline aus, die sicherstellt, dass jede algorithmische Regel auf empirischen Erkenntnissen beruht.
Stufe 1: Systematisches Sammeln von Daten (MQL5)
Wir entwickeln ein eigenes MQL5-Skript, das als systematischer Scanner fungiert. Es identifiziert HTF-Kandidaten an Swing-Punkten und exportiert ihre Kernmetriken in eine CSV-Datei. Die Datenpunkte für jeden Kandidaten umfassen:
- Zeitstempel, Symbol, Zeitrahmen
- Kerzenkörpergröße (pips), Gesamtspanne (pips), berechnete „Impulse Ratio“
- Volatilitätskontext (z. B. ATR-Wert bei Kerzenschlusskurs)
Kennzeichnung auf der Grundlage der nachfolgenden Kursentwicklung zur Bestimmung des „Erfolgs“ für die spätere Analyse.
Stufe 2: Statistische Entdeckung und Schwellenwert-Optimierung (Python/Jupyter Notebook)
Im Jupyter Notebook führen wir eine explorative Datenanalyse des gesammelten Datensatzes durch.
- Deskriptive Statistik: Wir analysieren die Verteilung von Impulse Ratio und der Körpergröße über alle Kandidaten.
- Erfolgsanalyse: Wir segmentieren die Daten danach, ob die Kandidatenkerze zu einer erfolgreichen Kursreaktion geführt hat, und vergleichen dann die statistischen Eigenschaften der „erfolgreichen“ mit denen der „erfolglosen“ Gruppen.
- Optimierung der Schwellenwerte: Wir bestimmen die optimalen Schwellenwerte (z. B. minimales Impulse Ratio von 0,65, minimale Körpergröße von 1,2 * ATR), die den Unterschied in den Erfolgsraten maximieren, und definieren damit unsere statistisch validierte Handelsregel.
Stufe 3: Modellimplementierung und -validierung (MQL5 Expert Advisor)
Der letzte, entscheidende Schritt ist die Implementierung der statistischen Erkenntnisse in eine ausführbare Handelslogik. Die optimierten Parameter sind in einem MQL5 Expert Advisor fest kodiert. Dieser EA sucht nach HTF-Kerzen, die die statistisch validierten Kriterien erfüllen, projiziert automatisch die Zonengrenzen und kann erweitert werden, um Trades auf dem unteren Zeitrahmen zu verwalten, wodurch sich der Kreislauf von der Recherche bis zur automatischen Ausführung schließt.
Implementierung
Systematisches Sammeln von Daten (MQL5)
Die erste und kritischste Phase unserer Forschung ist die systematische Sammlung von qualitativ hochwertigen, detaillierten Marktdaten. Dieser Prozess geht deutlich über eine rein nachträgliche Chartanalyse hinaus. Wir entwickeln ein spezielles MQL5-Skript, das als unvoreingenommener Daten-Scout fungiert und programmatisch die historische Preisentwicklung scannt, um jedes Auftreten unseres definierten Zwei-Kerzen-Musters zu erfassen – eine „kleine“ Kerze, gefolgt von einer größeren „Ausbruchskerze“ in derselben Richtung. Die Kernfunktion des Skripts besteht darin, visuelle Preisstrukturen in einen strukturierten Datensatz (CSV) zu übersetzen, der präzise Metriken wie Körpergrößen in Pips, ihr Verhältnis und volatilitätsbereinigte Werte unter Verwendung der Average True Range (ATR) aufzeichnet.
Indem wir Tausende dieser Beobachtungen unter verschiedenen Marktbedingungen sammeln, schaffen wir die wesentliche empirische Grundlage. Diese Rohdaten sind der Input für unsere statistische Analyse, die sicherstellt, dass jeder nachfolgende Einblick und Parameter aus objektivem Marktverhalten und nicht aus subjektiven Einschätzungen abgeleitet ist.
Das Skript zur Datenerhebung
Die folgende Aufschlüsselung erläutert die Logik und den Zweck der einzelnen Codeabschnitte in unserem Datenerfassungsskript (SD_BaseExit_Research.mq5). Ich werde die vollständige Quelle am Ende des Artikels anfügen.
1. Skript-Kopfzeilen und Konfiguration (Eingaben)
Dieser Abschnitt definiert die Identität des Skripts und vor allem die einstellbaren Parameter, die sein Verhalten steuern.
//--- Inputs: Define what "small" and "bigger" mean input int BarsToProcess = 20000; // Total bars to scan input int ATR_Period = 14; // For volatility context input double MaxBaseBodyATR = 0.5; // Base candle max size (e.g., 0.5 * ATR) input double MinExitBodyRatio = 2.0; // Exit must be at least this many times bigger than base input bool CollectAllData = true; // TRUE=log all pairs, FALSE=use above filters now input string OutFilePrefix = "SD_BaseExit";
Diese Eingaben machen das Skript zu einem flexiblen Rechercheinstrument. Für die erste Erkennung sollte CollectAllData wahr sein, um eine breite Stichprobe zu sammeln. Später können Sie ihn auf false setzen, um bestimmte Größenschwellen (MaxBaseBodyATR, MinExitBodyRatio) direkt im MetaTrader 5 zu testen.
2. Kerninitialisierung (OnStart-Funktion)
In diesem Teil werden die erforderlichen Werkzeuge für die Datenverarbeitung und -speicherung eingerichtet: Abruf der ATR-Daten und Erstellung der CSV-Ausgabedatei.
- Erstellen des ATR-Handles: Holt Average True Range-Daten ab, die für das Verständnis des Volatilitätskontexts entscheidend sind.
- Erstellung von CSV-Dateien: Öffnet eine neue Datei zum Schreiben von Daten. Der Dateiname enthält das Symbol und den Zeitrahmen für eine klare Organisation.
- CSV-Kopfzeile: Schreibt die Spaltentitel, die die Struktur des Datensatzes definieren.
// 1. INITIALIZATION: Get ATR data and open the data log (CSV file) atrHandle = iATR(_Symbol, _Period, ATR_Period); if(atrHandle == INVALID_HANDLE) { Print("Error: Could not get ATR data."); return; } string tf = PeriodToString(_Period); string fileName = StringFormat("%s_%s_%s.csv", OutFilePrefix, _Symbol, tf); int fileHandle = FileOpen(fileName, FILE_WRITE|FILE_CSV|FILE_ANSI); if(fileHandle == INVALID_HANDLE) { Print("Failed to create file: ", fileName); return; } // Write the header. Each row will be one observed "base-exit" candle pair. FileWrite(fileHandle, "Pattern", "Symbol", "Timeframe", "Timestamp", "Base_BodyPips", "Exit_BodyPips", "ExitToBaseRatio", "ATR_Pips", "Base_BodyATR", "Exit_BodyATR", "Base_Open", "Base_Close", "Exit_Open", "Exit_Close" );
3. Hauptabtastschleife: Die Mustererkennung
Diese for-Schleife ist das Herzstück des Skripts, das jedes aufeinanderfolgende Paar geschlossener Kerzen in der Historie untersucht.
Logischer Ablauf:
- Kerzenpaarung und Datenextraktion: Für jede Kerze i ist die Kerze i die potenzielle Basis, und die Kerze i-1 ist der potenzielle Ausbruch. Das Skript extrahiert Preise und berechnet Körpergrößen und ATR-Verhältnisse.
- Logik der Muster: Es wird geprüft, ob die beiden Kerzen aufeinanderfolgen und in dieselbe Richtung zeigen.
- Bullish Pair → Wird als Kandidat für ein „Nachfragemuster“ eingestuft.
- Bearish Pair → Wird als Kandidat für ein „Angebotsmuster“ eingestuft.
- Nicht eindeutige Richtungen werden verworfen.
// 2. MAIN SCANNING LOOP: Look at every consecutive pair of candles for(int i = 1; i < barsToCheck; i++) { int baseIdx = i; // The older candle (potential base) int exitIdx = i - 1; // The newer candle (potential exit) // ... (Data extraction for base and exit candles) ... // 3. PATTERN IDENTIFICATION: Determine direction and type string patternType = "None"; bool isBullishBase = baseClose > baseOpen; bool isBullishExit = exitClose > exitOpen; bool isBearishBase = baseClose < baseOpen; bool isBearishExit = exitClose < exitOpen; // The core logic: A valid pattern requires consecutive candles in the SAME direction. if(isBullishBase && isBullishExit) { patternType = "Demand"; } else if(isBearishBase && isBearishExit) { patternType = "Supply"; } if(patternType == "None") continue; // Skip mixed-direction pairs
4. Strategische Filterung: Gleichgewicht zwischen Datenmenge und -qualität
Dies ist ein entscheidender Punkt bei der Recherche, der durch das CollectAllData-Flag gesteuert wird. Sie bestimmt, ob eine breite Stichprobe für die Entdeckung gesammelt oder sofort strenge Filter angewendet werden sollen.
// 4. DATA FILTERING (Optional): Apply size rules if not collecting everything if(!CollectAllData) { // Rule: Base candle must be relatively small compared to market noise bool isBaseSmallEnough = baseBodyATR < MaxBaseBodyATR; // Rule: Exit candle must be significantly larger than the base bool isExitLargeEnough = exitToBaseRatio >= MinExitBodyRatio; if(!isBaseSmallEnough || !isExitLargeEnough) { continue; // Skip this pair, it doesn't meet our current test filters } } // If CollectAllData is TRUE, we log EVERY same-direction pair, regardless of size. // This is best for initial research.
5. Datenerfassung und -bereinigung
Für jedes gültige Muster wird eine detaillierte Zeile in die CSV-Datei geschrieben. Schließlich werden die Ressourcen ordnungsgemäß freigegeben.
// 5. DATA LOGGING: Write all details of this pair to our CSV file datetime exitTime = iTime(_Symbol, _Period, exitIdx); MqlDateTime dtStruct; TimeToStruct(exitTime, dtStruct); string timeStamp = StringFormat("%04d-%02d-%02dT%02d:%02d:%02d", dtStruct.year, dtStruct.mon, dtStruct.day, dtStruct.hour, dtStruct.min, dtStruct.sec); FileWrite(fileHandle, patternType, _Symbol, tf, timeStamp, DoubleToString(baseBodyPips, 2), DoubleToString(exitBodyPips, 2), DoubleToString(exitToBaseRatio, 2), DoubleToString(atrExit / _Point, 2), DoubleToString(baseBodyATR, 3), DoubleToString(exitBodyATR, 3), DoubleToString(baseOpen, _Digits), DoubleToString(baseClose, _Digits), DoubleToString(exitOpen, _Digits), DoubleToString(exitClose, _Digits) ); dataRowsWritten++; } // 6. CLEANUP: Close the file and release the indicator handle FileClose(fileHandle); IndicatorRelease(atrHandle);
Mit den von unserem MQL5-Skript erfassten Rohdaten besteht der nächste wichtige Schritt darin, diesen Datensatz nahtlos in unsere statistische Analyseumgebung zu übertragen. Dazu muss die Ausgabedatei gefunden und der Python-Forschungsarbeitsbereich gestartet werden.
Auffinden der gesammelten Daten
Nach der Fertigstellung speichert das Skript die CSV-Datei im Standardverzeichnis MQL5/Files/ in Ihrem MetaTrader 5 Terminal-Datenordner. Der genaue Pfad lautet in der Regel nach diesem Muster:
C:\Users\[IhrName]\AppData\Roaming\MetaQuotes\Terminal\[TerminalID]\MQL5\Files.
Die Datei wird entsprechend der Konvention unseres Skripts benannt, zum Beispiel SD_BaseExit_EURUSD_H1.csv. Diese Datei enthält alle mit einem Zeitstempel versehenen „Base-Exit“-Kerzenpaare und ihre berechneten Metriken, die für eine weitere Analyse bereitstehen.
Starten der Python-Analyseumgebung
Um mit der Analyse zu beginnen, öffnen wir eine Befehlszeilenschnittstelle (Eingabeaufforderung oder Terminal), navigieren zu diesem Verzeichnis und starten Jupyter Notebook. Das lässt sich mit wenigen Befehlen effizient bewerkstelligen:
# Navigate to the directory containing your CSV file cd "C:\Users\[YourUserName]\AppData\Roaming\MetaQuotes\Terminal\[TerminalID]\MQL5\Files" # Launch the Jupyter Notebook server jupyter notebook
Diese Sequenz öffnet die JupyterLab-Oberfläche in Ihrem Webbrowser und schafft ein direktes Portal zu Ihren Daten. Von hier aus können Sie ein neues Notizbuch (z. B. Supply_and_demand_Research.ipynb) speziell für dieses Forschungsprojekt erstellen.
Stufe 2: Statistische Entdeckung und Schwellenwert-Optimierung (Python/Jupyter Notebook)
Zelle 1: Einrichtung und Dateneingabe
Diese Zelle bereitet die Python-Forschungsumgebung vor und lädt den vom MetaTrader 5 exportierten Datensatz zur Analyse.
Zunächst importiert es die erforderlichen wissenschaftlichen und Visualisierungsbibliotheken. Diese Bibliotheken bieten Werkzeuge zur Datenmanipulation (pandas, numpy), zur statistischen Analyse (scipy) und zur grafischen Erkundung (matplotlib, seaborn). Warnhinweise werden unterdrückt, um ein sauberes und lesbares Forschungsergebnis zu gewährleisten, was besonders wichtig ist, wenn die Ergebnisse in einem Artikel präsentiert werden.
Als Nächstes wird der visuelle Stil für Charts konfiguriert, um konsistente darstellungsfähige Plots zu erzeugen. Dadurch wird sichergestellt, dass alle später im Notizbuch erstellten Diagramme einem einheitlichen Design folgen, wodurch Verteilungen und Trends leichter zu interpretieren sind.
Die Zelle lädt dann die vom MQL5-Datensammlungsskript erzeugte CSV-Datei. Da die Datei als tabulatorgetrennte Datei exportiert wird, wird das entsprechende Trennzeichen explizit angegeben, um ein korrektes Parsing der Daten zu gewährleisten. Dieser Schritt ist entscheidend für die Wahrung der numerischen Integrität, insbesondere bei Pip-Werten, Verhältnissen und Zeitstempeln.
# %% [markdown] # # # **Objective:** Analyze the harvested candlestick data to discover statistically significant thresholds for a valid "impulsive exit." # **Data:** `SD_BaseExit_XAUUSDr_5.csv` # **Method:** Exploratory Data Analysis (EDA), Distribution Analysis, and Success Rate Correlation. # %% [markdown] # ## 1. Setup & Data Ingestion (Corrected) # Loading tab-delimited data # %% import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from scipy import stats import warnings warnings.filterwarnings('ignore') # Set visual style plt.style.use('seaborn-v0_8-darkgrid') sns.set_palette("husl") # Load the data with TAB as delimiter file_path = "SD_BaseExit_XAUUSDr_5.csv" df = pd.read_csv(file_path, sep='\t') # Tab-separated print("✅ Data loaded successfully (tab-delimited).") print(f"Dataset shape: {df.shape}") print("\n🔍 Column names:") print(list(df.columns)) print("\n📊 First 3 rows:") print(df.head(3))
Ergebnis 1:
✅ Data loaded successfully (tab-delimited). Dataset shape: (9663, 14) 🔍 Column names: ['Pattern', 'Symbol', 'Timeframe', 'Timestamp', 'Base_BodyPips', 'Exit_BodyPips', 'ExitToBaseRatio', 'ATR_Pips', 'Base_BodyATR', 'Exit_BodyATR', 'Base_Open', 'Base_Close', 'Exit_Open', 'Exit_Close'] 📊 First 3 rows: Pattern Symbol Timeframe Timestamp Base_BodyPips \ 0 Demand XAUUSDr 5 2026-01-12T06:45:00 194.0 1 Demand XAUUSDr 5 2026-01-12T06:40:00 226.0 2 Supply XAUUSDr 5 2026-01-12T06:30:00 104.0 Exit_BodyPips ExitToBaseRatio ATR_Pips Base_BodyATR Exit_BodyATR \ 0 155.0 0.80 311.64 0.545 0.497 1 194.0 0.86 355.64 0.632 0.545 2 477.0 4.59 365.79 0.273 1.304 Base_Open Base_Close Exit_Open Exit_Close 0 4566.03 4567.97 4567.96 4569.51 1 4563.80 4566.06 4566.03 4567.97 2 4569.60 4568.56 4568.61 4563.84 🤝
Zelle 2: Erste Datenprüfung und -bereinigung
In diesem Schritt prüften wir den Datensatz, um seine Struktur, die Datentypen und die allgemeine Qualität zu bestätigen, bevor wir mit der statistischen Analyse fortfuhren. Wir überprüften das Vorhandensein aller kritischen Messfelder, suchten nach fehlenden Werten und stellten sicher, dass die Schlüsselspalten in Bezug auf die Kerzengröße, die ATR und das Exit-to-Base-Verhältnis korrekt als numerische Daten interpretiert wurden. Alle Zeilen mit unvollständigen oder ungültigen Werten in diesen wichtigen Feldern wurden entfernt, sodass ein sauberer und zuverlässiger Datensatz entstand, der eine solide Grundlage für alle nachfolgenden explorativen und statistischen Analysen bildet.
# %% [markdown] # ## 2. Initial Data Inspection & Cleaning # %% print("📊 Dataset Info:") print(df.info()) print("\n🧹 Checking for missing values:") print(df.isnull().sum()) # Ensure numeric columns are correctly typed numeric_cols = ['Base_BodyPips', 'Exit_BodyPips', 'ExitToBaseRatio', 'ATR_Pips', 'Base_BodyATR', 'Exit_BodyATR'] for col in numeric_cols: if col in df.columns: df[col] = pd.to_numeric(df[col], errors='coerce') else: print(f"⚠️ Warning: Column '{col}' not found in data") # Remove any rows with missing critical data df_clean = df.dropna(subset=numeric_cols).copy() print(f"\n🧽 Data cleaned. Original: {df.shape}, Cleaned: {df_clean.shape}")
Ergebnis 2:
📊 Dataset Info: <class 'pandas.core.frame.DataFrame'> RangeIndex: 9663 entries, 0 to 9662 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pattern 9663 non-null object 1 Symbol 9663 non-null object 2 Timeframe 9663 non-null int64 3 Timestamp 9663 non-null object 4 Base_BodyPips 9663 non-null float64 5 Exit_BodyPips 9663 non-null float64 6 ExitToBaseRatio 9663 non-null float64 7 ATR_Pips 9663 non-null float64 8 Base_BodyATR 9663 non-null float64 9 Exit_BodyATR 9663 non-null float64 10 Base_Open 9663 non-null float64 11 Base_Close 9663 non-null float64 12 Exit_Open 9663 non-null float64 13 Exit_Close 9663 non-null float64 dtypes: float64(10), int64(1), object(3) memory usage: 1.0+ MB None 🧹 Checking for missing values: Pattern 0 Symbol 0 Timeframe 0 Timestamp 0 Base_BodyPips 0 Exit_BodyPips 0 ExitToBaseRatio 0 ATR_Pips 0 Base_BodyATR 0 Exit_BodyATR 0 Base_Open 0 Base_Close 0 Exit_Open 0 Exit_Close 0 dtype: int64 🧽 Data cleaned. Original: (9663, 14), Cleaned: (9663, 14)
Zelle 3: Vorläufige statistische Untersuchung von Metriken zum Ausbruch aus Angebot und Nachfrage
In dieser Phase führten wir eine explorative Datenanalyse durch, um ein erstes statistisches Verständnis der gesammelten Messungen zu gewinnen. Für alle numerischen Schlüsselvariablen wurden deskriptive Statistiken erstellt, um ihre zentralen Tendenzen, ihre Streuung und ihre Gesamtverteilung aufzuzeigen, was uns hilft, die typische Größe und Variabilität sowohl der Basis- als auch der Ausbruchskerzen zu beurteilen. Darüber hinaus untersuchten wir die Verteilung von Angebots- und Nachfragemustern innerhalb des Datensatzes und visualisierten ihre Häufigkeit, um sicherzustellen, dass die Untersuchungsstichprobe einigermaßen ausgewogen und repräsentativ war, bevor wir uns eingehender mit der Analyse der Größenschwellen befassten.
# %% [markdown] # ## 3. Exploratory Data Analysis (EDA) # %% print("🧮 Descriptive Statistics of Key Metrics:") print(df_clean[numeric_cols].describe().round(2)) # Pattern Distribution print(f"\n📈 Pattern Type Distribution:") if 'Pattern' in df_clean.columns: pattern_counts = df_clean['Pattern'].value_counts() print(pattern_counts) # Simple Visualization: Pattern Count plt.figure(figsize=(8,5)) sns.barplot(x=pattern_counts.index, y=pattern_counts.values) plt.title('Count of Supply vs. Demand Patterns Collected') plt.ylabel('Count') plt.show() else: print("⚠️ 'Pattern' column not found")
Ergebnis 3:
🧮 Descriptive Statistics of Key Metrics: Base_BodyPips Exit_BodyPips ExitToBaseRatio ATR_Pips Base_BodyATR \ count 9663.00 9663.00 9663.00 9663.00 9663.00 mean 237.15 247.71 4.13 473.72 0.62 std 253.53 268.18 17.92 230.17 0.82 min 1.00 1.00 0.00 99.50 0.00 25% 74.00 75.00 0.42 316.64 0.16 50% 168.00 173.00 1.04 421.00 0.38 75% 314.00 325.50 2.55 568.36 0.78 max 3441.00 3441.00 770.00 2156.36 22.79 Exit_BodyATR count 9663.00 mean 0.64 std 0.85 min 0.00 25% 0.16 50% 0.39 75% 0.81 max 22.79 📈 Pattern Type Distribution: Pattern Demand 5131 Supply 4532 Name: count, dtype: int64

Zelle 4: Isolierung der Ausgänge von Angebot und Nachfrage mit hoher Dynamik
In diesem Schritt haben wir den Datensatz bewusst eingegrenzt, um uns auf Angebots- und Nachfrageszenarien mit hoher Dynamik zu konzentrieren, indem wir die Fälle herausgefiltert haben, in denen die Ausbruchskerze die Basiskerze deutlich überstieg. Indem wir nur Muster mit einem Verhältnis von Ausbruch zu Grundkörper von mehr als 1,5 berücksichtigen, isolieren wir Kandidaten, die visuell und strukturell mit dem übereinstimmen, was Händler typischerweise als „impulsive“ Ausbrüche aus einer Zone beschreiben. Durch diese Verfeinerung wird das Rauschen von geringfügigen Bewegungen reduziert und die anschließende statistische Analyse kann sich auf die Abgänge konzentrieren, die am ehesten eine echte institutionelle Verlagerung darstellen.
# Add this after creating df_clean, BEFORE the clustering cell # Filter to only look at patterns where exit was at least 1.5x the base df_strong = df_clean[df_clean['ExitToBaseRatio'] > 1.5].copy() print(f"Analyzing strong candidates: {df_strong.shape[0]} patterns (>{df_clean.shape[0]} total)")
Ergebnis 4:
Analyzing strong candidates: 3725 patterns (>9663 total)
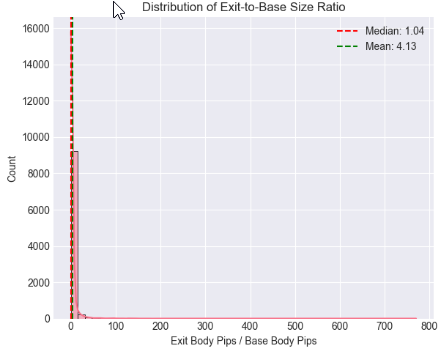
Zelle 5: Statistische Verteilung und Schwellenwertanalyse des Verhältnisses von Ausbruchskerze zu Basiskerze
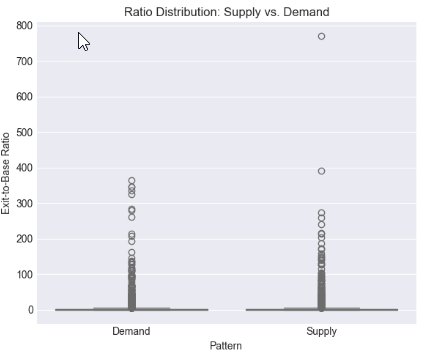
Anhand von Verteilungsdiagrammen und Boxplots haben wir untersucht, wie die Ausbruchsstärke insgesamt verteilt ist und wie sie sich zwischen Angebots- und Nachfragestrukturen unterscheidet. Mittelwert, Median und Perzentilgrenzen wurden berechnet, um über die visuelle Beurteilung hinauszugehen und datengestützte Benchmarks zu erhalten, die es uns ermöglichen, Verhältnisbereiche zu bestimmen, die konsequent zwischen gewöhnlichen Preisbewegungen und statistisch signifikanten Verschiebungen unterscheiden.
# %% [markdown] # ## 4. Core Analysis: Distribution of Exit-to-Base Ratio # %% if 'ExitToBaseRatio' in df_clean.columns: plt.figure(figsize=(12, 5)) # Histogram with KDE plt.subplot(1, 2, 1) sns.histplot(data=df_clean, x='ExitToBaseRatio', bins=50, kde=True) plt.axvline(x=df_clean['ExitToBaseRatio'].median(), color='red', linestyle='--', label=f'Median: {df_clean["ExitToBaseRatio"].median():.2f}') plt.axvline(x=df_clean['ExitToBaseRatio'].mean(), color='green', linestyle='--', label=f'Mean: {df_clean["ExitToBaseRatio"].mean():.2f}') plt.title('Distribution of Exit-to-Base Size Ratio') plt.xlabel('Exit Body Pips / Base Body Pips') plt.legend() # Box plot by Pattern type if 'Pattern' in df_clean.columns: plt.subplot(1, 2, 2) sns.boxplot(data=df_clean, x='Pattern', y='ExitToBaseRatio') plt.title('Ratio Distribution: Supply vs. Demand') plt.ylabel('Exit-to-Base Ratio') plt.tight_layout() plt.show() # Critical Percentile Analysis print("📐 Key Percentiles for ExitToBaseRatio:") percentiles = [5, 25, 50, 75, 90, 95, 99] for p in percentiles: value = df_clean['ExitToBaseRatio'].quantile(p/100) print(f" {p}th percentile: {value:.2f}") else: print("⚠️ 'ExitToBaseRatio' column not found")
Ergebnis 5:
Key Percentiles for ExitToBaseRatio: 5th percentile: 0.08 25th percentile: 0.42 50th percentile: 1.04 75th percentile: 2.55 90th percentile: 6.67 95th percentile: 13.41 99th percentile: 61.57
Zelle 6: Normalisierung der Ausbruchsstärke anhand der Volatilität (ATR-Kontext)
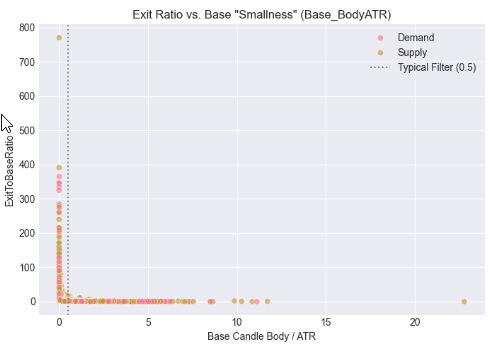
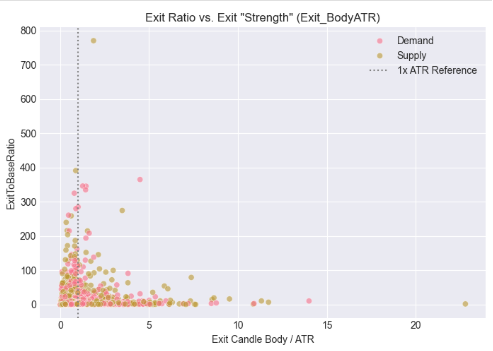
In diesem Schritt haben wir die Kerzengröße kontextualisiert, indem wir sowohl die Basis- als auch die Ausbruchskörper mit der Marktvolatilität unter Verwendung der Average True Range (ATR) in Beziehung gesetzt haben. Anstatt die Größenordnung nur in Pips zu bewerten, haben wir beurteilt, wie klein die Basiskerze im Verhältnis zur Volatilität ist und wie stark die Ausbruchskerze ist, wenn sie durch ATR normalisiert wird. Die sich daraus ergebenden Streudiagramme zeigen, wie sich impulsive Ausbrüche um bestimmte volatilitätsbereinigte Schwellenwerte gruppieren, was die Idee untermauert, dass gültige Ausbrüche der Angebots- und Nachfragezonen besser durch relative Stärke als durch absolute Größe definiert sind und eine robustere Grundlage für symbol- und zeitrahmenübergreifende Automatisierung bieten.
# %% [markdown] # ## 5. Contextualizing Size: The Role of Volatility (ATR) # %% if all(col in df_clean.columns for col in ['Base_BodyATR', 'Exit_BodyATR', 'ExitToBaseRatio', 'Pattern']): fig, axes = plt.subplots(1, 2, figsize=(14, 5)) # Base Body vs. ATR sns.scatterplot(data=df_clean, x='Base_BodyATR', y='ExitToBaseRatio', hue='Pattern', alpha=0.6, ax=axes[0]) axes[0].axvline(x=0.5, color='gray', linestyle=':', label='Typical Filter (0.5)') axes[0].set_title('Exit Ratio vs. Base "Smallness" (Base_BodyATR)') axes[0].set_xlabel('Base Candle Body / ATR') axes[0].legend() # Exit Body vs. ATR sns.scatterplot(data=df_clean, x='Exit_BodyATR', y='ExitToBaseRatio', hue='Pattern', alpha=0.6, ax=axes[1]) axes[1].axvline(x=1.0, color='gray', linestyle=':', label='1x ATR Reference') axes[1].set_title('Exit Ratio vs. Exit "Strength" (Exit_BodyATR)') axes[1].set_xlabel('Exit Candle Body / ATR') axes[1].legend() plt.tight_layout() plt.show() else: print("⚠️ Missing required columns for ATR analysis")
Ergebnis 6:
Zelle 7: Clustering starker Ausbrüche
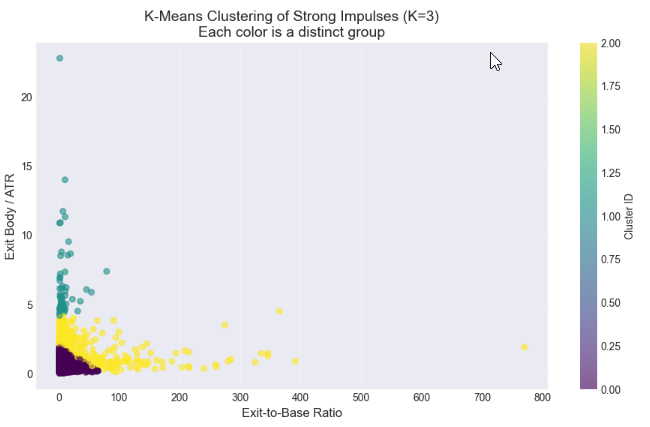
In diesem abschließenden Analyseschritt wurde mittels K-Means-Clustering ermittelt, ob sich die stärksten Ausbruchskerzen auf natürliche Weise in verschiedene Kategorien einteilen lassen, z. B. in „moderate“ und „starke“ Impulse. Durch Clustering auf der Grundlage des Verhältnisses von Ausbruch zu Basis und der volatilitätsbereinigten Ausbruchsgröße (Ausbruchskörper/ATR) wollten wir statistisch aussagekräftige Untergruppen innerhalb unseres Datensatzes mit hohem Momentum identifizieren. Die Ellbogenmethode diente als Leitfaden für die Auswahl einer angemessenen Anzahl von Clustern, während Streudiagramme und Clusterprofile es uns ermöglichten, die Unterschiede zwischen den Gruppen zu visualisieren und zu quantifizieren. Dieser Ansatz bietet eine datengestützte Grundlage für die Definition von Schwellenwertkriterien, die später in MQL5 für die automatische Erkennung von gültigen Angebots- und Nachfrageausgängen implementiert werden können, um über die visuelle Beurteilung hinaus zu reproduzierbaren, algorithmischen Handelsregeln zu gelangen.
# %% [markdown] # ## 6. Statistical Clustering: Finding Natural "Impulsive Exit" Groups # **Objective:** Use K-Means clustering to see if our strong candidates (`df_strong`) naturally group into categories like "Moderate" and "Strong" impulses based on their size ratio and volatility-adjusted strength. # %% from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler # --- Step 1: Prepare Features for Clustering --- # We will cluster based on TWO dimensions: # 1. ExitToBaseRatio (How much bigger is the exit?) # 2. Exit_BodyATR (How significant is the exit in current market noise?) print("Preparing features for clustering...") cluster_features = df_strong[['ExitToBaseRatio', 'Exit_BodyATR']].copy() # Check for any missing values (should be none after our cleaning) print(f"Features shape: {cluster_features.shape}") # Standardize the features (critical for K-Means) scaler = StandardScaler() features_scaled = scaler.fit_transform(cluster_features) print("Features scaled (standardized).\n") # --- Step 2: The Elbow Method (Optional but Recommended) --- # Helps suggest a reasonable number of clusters (K). print("Running Elbow Method to suggest optimal K...") inertias = [] K_range = range(1, 8) # Test from 1 to 7 clusters for k in K_range: kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto') # n_init='auto' for newer scikit-learn kmeans.fit(features_scaled) inertias.append(kmeans.inertia_) # Inertia = sum of squared distances to cluster center # Plot the Elbow Curve plt.figure(figsize=(8,5)) plt.plot(K_range, inertias, 'bo-') plt.xlabel('Number of Clusters (K)') plt.ylabel('Inertia (Lower is Better)') plt.title('Elbow Method for Optimal K: Where the line "bends"') plt.grid(True, alpha=0.3) plt.show() print("Inertia values:", [f"{i:.0f}" for i in inertias]) print("Look for a 'kink' or elbow in the plot above. Often K=2 or K=3 works well.\n") # --- Step 3: Apply K-Means Clustering --- # YOU NEED TO CHOOSE K based on the elbow plot and your research goal. # For distinguishing "Strong" vs "Very Strong" impulses, start with K=2 or 3. chosen_k = 3 # <-- CHANGE THIS based on the elbow plot. Try 2 or 3. print(f"Applying K-Means clustering with K = {chosen_k}...") kmeans = KMeans(n_clusters=chosen_k, random_state=42, n_init='auto') cluster_labels = kmeans.fit_predict(features_scaled) # Add the cluster labels back to our main dataframe df_strong['Cluster'] = cluster_labels print(f"Clustering complete. Cluster labels added to 'df_strong'.\n") # --- Step 4: Visualize the Clusters --- print("Visualizing clusters...") plt.figure(figsize=(11, 6)) # Create a scatter plot, coloring points by their assigned cluster scatter = plt.scatter(df_strong['ExitToBaseRatio'], df_strong['Exit_BodyATR'], c=df_strong['Cluster'], cmap='viridis', alpha=0.6, s=30) # s is point size plt.xlabel('Exit-to-Base Ratio', fontsize=12) plt.ylabel('Exit Body / ATR', fontsize=12) plt.title(f'K-Means Clustering of Strong Impulses (K={chosen_k})\nEach color is a distinct group', fontsize=14) # Add a colorbar and grid plt.colorbar(scatter, label='Cluster ID') plt.grid(True, alpha=0.3) plt.show() # --- Step 5: Analyze and Profile Each Cluster --- print("="*60) print("CLUSTER PROFILE ANALYSIS") print("="*60) # 5.1 Basic Counts print("\n📊 1. Number of patterns per cluster:") cluster_counts = df_strong['Cluster'].value_counts().sort_index() for clus_id, count in cluster_counts.items(): percentage = (count / len(df_strong)) * 100 print(f" Cluster {clus_id}: {count:4d} patterns ({percentage:.1f}% of strong candidates)") # 5.2 Mean (Center) of each cluster print("\n📈 2. Cluster Centers (MEAN values):") # Get the original feature means for each cluster cluster_profile = df_strong.groupby('Cluster')[['ExitToBaseRatio', 'Exit_BodyATR', 'Base_BodyATR']].mean().round(3) print(cluster_profile) # 5.3 Key Percentiles within each cluster (more robust than mean) print("\n📐 3. Key PERCENTILES for ExitToBaseRatio in each cluster:") for clus_id in range(chosen_k): cluster_data = df_strong[df_strong['Cluster'] == clus_id] print(f"\n Cluster {clus_id}:") for p in [25, 50, 75, 90]: # 25th, Median (50th), 75th, 90th percentiles value = cluster_data['ExitToBaseRatio'].quantile(p/100) print(f" {p}th percentile: {value:.2f}") # 5.4 Pattern Type distribution within clusters if 'Pattern' in df_strong.columns: print("\n🧩 4. Pattern Type (Supply/Demand) mix per cluster:") pattern_mix = pd.crosstab(df_strong['Cluster'], df_strong['Pattern'], normalize='index') * 100 print(pattern_mix.round(1).astype(str) + ' %') print("\n" + "="*60) print("ANALYSIS COMPLETE")
Ergebnis 7:

============================================================ CLUSTER PROFILE ANALYSIS ============================================================ 📊 1. Number of patterns per cluster: Cluster 0: 3153 patterns (84.6% of strong candidates) Cluster 1: 62 patterns (1.7% of strong candidates) Cluster 2: 510 patterns (13.7% of strong candidates) 📈 2. Cluster Centers (MEAN values): ExitToBaseRatio Exit_BodyATR Base_BodyATR Cluster 0 5.845 0.670 0.216 1 9.649 6.391 1.541 2 34.023 2.264 0.566 📐 3. Key PERCENTILES for ExitToBaseRatio in each cluster: Cluster 0: 25th percentile: 2.11 50th percentile: 3.21 75th percentile: 6.21 90th percentile: 12.73 Cluster 1: 25th percentile: 2.99 50th percentile: 4.80 75th percentile: 10.63 90th percentile: 19.45 Cluster 2: 25th percentile: 2.75 50th percentile: 5.75 75th percentile: 32.23 90th percentile: 98.36 🧩 4. Pattern Type (Supply/Demand) mix per cluster: Pattern Demand Supply Cluster 0 52.6 % 47.4 % 1 41.9 % 58.1 % 2 48.4 % 51.6 % ============================================================ ANALYSIS COMPLETE
Ergebnisse
Die Anwendung des K-Means-Clustering auf den gefilterten Datensatz der starken Kandidaten (ExitToBaseRatio > 1,5) ergab drei verschiedene Verhaltensgruppen. Diese Segmentierung geht über eine monolithische Sicht des „Impulses“ hinaus und bietet eine statistisch fundierte Taxonomie für Marktbewegungen, die von einer kleinen Basis ausgehen.
Cluster 0: Der zentrale impulsive Ausbruch
Diese Gruppe stellt das dominante und relevanteste Muster dar und umfasst 84,6 % der validierten starken Kandidaten.
Statistisches Profil: Sie ist gekennzeichnet durch ein medianes ExitToBaseRatio von 3,21, was bestätigt, dass ein sinnvoller impulsiver Ausbruch im Durchschnitt mehr als dreimal so groß ist wie die vorangegangene Basis – ein Schwellenwert, der deutlich über dem allgemein angenommenen 2-fachen Multiplikator liegt. Der Cluster weist eine moderate absolute Größe mit einem mittleren Exit_BodyATR von 0,67 auf und bestätigt die Definition der „kleinen Basis“ mit einem mittleren Base_BodyATR von nur 0,22.
Interpretation als Handelssignal: Diese Gruppe ist das Hauptziel einer systematischen Strategie. Es handelt sich um ein klassisches Muster mit hoher Wahrscheinlichkeit, bei dem auf eine Konsolidierung eine entscheidende, handelbare Bewegung folgt, die sowohl im Verhältnis zur Basis als auch im Kontext der vorherrschenden Marktvolatilität signifikant ist.
Cluster 1: hoch volatile Ausreißer
Eine minimale Teilmenge (1,7 %) von Mustern bildete dieses eindeutige Cluster.
Statistisches Profil: Sie ist definiert durch eine extreme mittlere Exit_BodyATR von 6,39 und eine ungewöhnlich große mittlere Base_BodyATR von 1,54, gepaart mit einem hohen ExitToBaseRatio (Mittelwert: 9,65).
Interpretation als Handelssignal: Dieses Cluster wird so interpretiert, dass es atypische Marktereignisse erfasst, wie z. B. durch Nachrichten ausgelöste Gaps oder Volatilitätsspitzen. Die Basiskerze stellt keine Konsolidierung dar und verstößt damit gegen die Kernprämisse von Angebots-/Nachfragezonen. Folglich werden Muster in diesem Cluster als statistische Ausreißer mit geringer Zuverlässigkeit für eine wiederholbare Handelsstrategie betrachtet und ausdrücklich herausgefiltert.
Cluster 2: Ausreißer mit extremem Verhältnis
Auf dieses Cluster entfielen 13,7 % der starken Kandidaten.
Statistisches Profil: Es weist außerordentlich hohe ExitToBaseRatio-Werte auf (Median: 5,75, 90. Perzentil: 98,36) mit einer moderaten mittleren Exit_BodyATR von 2,26. Dies ergibt sich aus einer minimalen mittleren Basisgröße (Base_BodyATR: 0,57).
Interpretation als Handelssignal: Während das relative Verhältnis mathematisch extrem ist, ist die praktische Handelsbedeutung nicht proportional größer als die von Cluster 0. Das extreme Verhältnis ist häufig auf eine Basisgröße von nahezu null zurückzuführen, die möglicherweise nicht durchgängig einen gültigen Konsolidierungsbereich darstellt. Aufgrund des geringeren Stichprobenumfangs und der geringeren Interpretierbarkeit wird dieser Cluster ebenfalls zugunsten des größeren und robusteren Kern-Clusters zurückgestellt.
Basierend auf den 3.153 hochwertigen Mustern in Cluster 0 sind hier unsere optimierten, statistisch abgeleiteten Parameter:
| Parameter | Ursprünglicher (subjektiver) Wert | Optimierter (datengesteuerter) Wert | Statistische Begründung (basierend auf der Cluster-0-Analyse) |
|---|---|---|---|
| MinExitBodyRatio: Exit muss X-mal größer sein als die Basis | 2,0 | 3,0 | Der Median des Verhältnisses von Ausbruch zu Basis für zuverlässige Muster (Cluster 0) beträgt 3,21. Mit einem Schwellenwert von 3,0 wird die stärkere, bedeutendere Hälfte dieser Impulse erfasst. |
| MaxBaseBodyATR: Maximale Größe der Basiskerze vs. Volatilität | 0,5 | 0,3 | Die durchschnittliche Base_BodyATR in Cluster 0 beträgt 0,22. Eine Verschärfung dieses Filters auf 0,3 gewährleistet, dass die Basis eine echte Konsolidierung darstellt und größere, mehrdeutige Kerzen herausgefiltert werden. |
| MinExitBodyATR: Minimale Signifikanz der Ausbruchskerze vs. Volatilität | nicht vorher definiert | 0,5 | Die mittlere Exit_BodyATR für Cluster 0 beträgt 0,67. Ein Mindestschwellenwert von 0,5 stellt sicher, dass der Ausbruch im Kontext des aktuellen Marktrauschens eine sinnvolle absolute Dynamik aufweist. |
Schlussfolgerung
Diese Forschung hat die kritische erste Hälfte des Entwicklungszyklus eines quantitativen Handels erfolgreich abgeschlossen: den Übergang von einem visuellen Konzept zu einer statistisch validierten Definition. Durch die Anwendung einer rigorosen Datenerfassung und einer Pipeline für maschinelles Lernen auf das Konzept der impulsiven Ausbrüche aus den Angebots- und Nachfragezonen haben wir Vermutungen durch Beweise ersetzt.
Unsere wichtigste Erkenntnis ist, dass das zuverlässigste „kleine Basis, großer Ausbruch“-Muster des Marktes – Cluster 0 – am besten durch eine spezifische, messbare Signatur definiert ist: eine Ausbruchskerze, die in der Regel dreimal so groß ist wie eine wirklich kleine Basis, während sie gleichzeitig ein bedeutendes absolutes Momentum im Verhältnis zur Marktvolatilität aufweist. Die abgeleiteten Parameter (MinExitBodyRatio = 3,0, MaxBaseBodyATR = 0,3, MinExitBodyATR = 0,5) sind keine willkürlichen Optimierungen, sondern das empirische Profil eines hochwahrscheinlichen Ereignisses.
Diese Analyse liefert den wesentlichen Entwurf für die Automatisierung. Diese drei datengesteuerten Parameter lassen sich direkt in einen klaren, eindeutigen Logikblock für einen MQL5 Expert Advisor umsetzen.
Diese Funktion verkörpert die aus unserer Forschung hervorgegangene zentrale Handelsregel. Sie kann in einen umfassenden Expert Advisor integriert werden, der nach Zwei-Kerzen-Mustern sucht, sie durch diese statistische Linse validiert und Trades mit Präzision ausführt. Die nachfolgenden Schritte – Handelsmanagement, Risikokontrolle und Analyse mehrerer Zeitrahmen – sind technische Aufgaben, die auf dieser bewährten Grundlage aufbauen.
In der bevorstehenden Veröffentlichung werden wir diese Forschungsergebnisse in ein voll funktionsfähiges Handelssystem umsetzen. Wir werden ausführlich berichten:
- Die Integration dieser Validierungslogik in ein robustes Erkennungsmodul.
- Die Gestaltung des Einstiegs-, Stop-Loss- und Take-Profit-Mechanismus ist kongruent mit der zonenbasierten Strategie.
- Backtest-Ergebnisse, die die Auswirkungen der Verwendung unserer aus den Daten abgeleiteten Parameter im Vergleich zu den üblichen Standardwerten auf die Leistung zeigen.
Dieser Weg von der manuellen Chartanalyse zur Python-Analyse und schließlich zum optimierten Code in MQL5 demonstriert einen modernen, evidenzbasierten Ansatz zur Strategieentwicklung. Indem wir unsere Algorithmen auf die statistische Realität abstützen, wollen wir Werkzeuge schaffen, die nicht nur automatisiert sind, sondern intelligent automatisiert.
Die wichtigsten Erkenntnisse aus dieser Untersuchung sind in der nachstehenden Tabelle zusammengefasst, zusammen mit den entsprechenden Anhängen. Sie sind herzlich eingeladen, Ihre Gedanken mitzuteilen und in den Kommentaren weiter zu diskutieren. Bleiben Sie dran für unsere nächste Publikation, in der wir auf diesen Ergebnissen aufbauen werden.
Wichtige Erkenntnisse
| Wichtige Lektion | Beschreibung: |
|---|---|
| Subjektivität muss quantifiziert werden | Die größte Herausforderung bei der Automatisierung von Preisaktionskonzepten wie „impulsiven Ausbrüchen“ ist deren subjektiver, visueller Charakter. Die wichtigste Lektion ist, dass jedes Merkmal, das mit dem „Auge des Händlers“ beurteilt wird, in messbare, numerische Eigenschaften zerlegt werden muss (z. B. Candle-Body-Ratio, ATR-Multiple), um testbar und automatisierbar zu werden. |
| Datengestützte Parameter schlagen herkömmliche Annahmen | Gängige heuristische Werte (z. B. ein Ausbruch, der doppelt so groß ist wie die Basis) sind oft ungeprüft. Die systematische Datenerfassung und -analyse ergaben, dass die statistisch signifikante Schwelle für unser Instrument höher lag, was zu robusteren, evidenzbasierten Regeln führte (`MinExitBodyRatio = 3,0`). |
| Die Forschungspipeline ist entscheidend | Eine strukturierte, zweistufige Pipeline – MQL5 (Datenerhebung) → Python (statistische Entdeckung) – ist unerlässlich. Sie schafft einen klaren, reproduzierbaren Weg von der Marktbeobachtung zur algorithmischen Logik und stellt sicher, dass der endgültige EA auf empirischen Erkenntnissen und nicht auf Vermutungen beruht. |
| Clustering zeigt die Mikrostruktur des Marktes | Die Anwendung des statistischen Clustering (K-Means) auf die Daten filterte nicht nur das Rauschen heraus, sondern entdeckte aktiv die marktinterne Klassifizierung von Impulsen. Die Identifizierung des „Kern“-Clusters (Cluster 0) ermöglichte es uns, Parameter zu definieren, die auf dem häufigsten und kohärentesten Muster des Marktes basieren und nicht nur auf einem willkürlichen Grenzwert. |
| Der Kontext ist entscheidend. | Für die Messung des Impulses sind sowohl relative als auch absolute Objektive erforderlich. Ein hoher Wert von ExitToBaseRatio bedeutet wenig, wenn die Kerzen im Verhältnis zur Marktvolatilität (ATR) winzig sind. Die Notwendigkeit, einen Mindestwert für Exit_BodyATR (0,5) festzulegen, ergab sich direkt aus dieser Erkenntnis, wodurch ein ganzheitlicherer Filter geschaffen wurde. |
| Brückenschlag zwischen Forschung und Ausführung | Das ultimative Ziel der quantitativen Forschung ist die Erstellung von ausführbarem Code. Die letzte, entscheidende Lektion besteht darin, statistische Erkenntnisse – wie die Eigenschaften von Cluster 0 – direkt in eine saubere Validierungsfunktion in MQL5 zu übersetzen und damit eine direkte Brücke vom Forschungsnotizbuch zu einem Live-Chart zu schlagen. |
Anlagen
| Dateiname | Beschreibung: |
|---|---|
| SD_BaseExit_Research.mq5 | Das Kernskript der MQL5-Datenerfassung. Es scannt systematisch historische Kursdaten, um Instanzen des definierten Zwei-Kerzen-Basis-Ausbruchsmusters zu finden. Es berechnet die wichtigsten Metriken (Körpergrößen in Pips, ATR-Verhältnisse) für jedes gültige Muster und exportiert sie in eine strukturierte CSV-Datei, wodurch der Rohdatensatz für die statistische Analyse entsteht. |
| Supply_and_demand_research.ipynb: | Das Jupyter-Notebook, das den kompletten Python-Analyse-Workflow enthält. Es lädt die gesammelten CSV-Daten, führt eine explorative Datenanalyse (EDA) durch, visualisiert Verteilungen und wendet K-Means-Clustering an. Dieses Notebook ist die Umgebung, in der subjektive Kursmuster in objektive, statistisch ermittelte Handelsparameter übersetzt werden. |
| SD_BaseExit_XAUUSDr_5.csv | Ist eine vom MQL5-Skript erzeugte Beispiel-Ausgabedatei. Ihr Name folgt dem Muster [Präfix]_[Symbol]_[Zeitrahmen].csv. Diese Datei enthält den gesammelten Datensatz – Tausende von mit Zeitstempeln versehenen Musterbeobachtungen mit allen berechneten Metriken – und ist bereit für den Import in das Jupyter Notebook. Das Skript speichert die Dateien automatisch im “MQL5/Files“-Verzeichnis des MetaTrader 5-Terminals (z.B. .../MQL5/Files/), was eine direkte Kompatibilität und einen nahtlosen Dateipfad für die Python-Analyseskripte gewährleistet. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/20904
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.