
MQL5とデータ処理パッケージの統合(第6回):市場フィードバックとモデル適応の融合

目次
はじめに
前回の記事では、適応学習と柔軟性に焦点を当て、市場環境の変化に応じて意思決定プロセスを調整できるシステムの構築について解説しました。この段階では、アルゴリズム取引における適応性の重要性を強調しました。つまり、過去の静的なデータの挙動に依存するのではなく、変化するデータパターンに基づいてモデルのパラメータを動的に調整できる仕組みです。強化学習および適応的パラメータ化を通じて、システムは自己最適化の能力を持ち始め、エキスパートアドバイザー(EA)フレームワーク内で継続的な改善をおこなうための基盤を形成しました。
今回は、この概念をさらに発展させ、リアルタイムの市場パフォーマンスデータと学習済みモデルとの間にフィードバック駆動の学習ループを導入します。目的は、実行環境(MQL5)とデータ処理層(Jupyter Lab)を接続し、取引結果、ボラティリティの変化、異常な挙動といった要素を、モデル再学習のための能動的な入力として活用することです。この統合により、システムは単に取引を実行するだけでなく、自身のパフォーマンスから学習し、ライブ市場のリズムに応じて予測精度と意思決定の質を継続的に向上させることが可能になります。
システムの概要と理解
実装の中核となるアイデアは、取引環境(MetaTrader5)と分析環境(Jupyter Lab)の間に、継続的な学習エコシステムを構築することです。固定された事前学習済みモデルに依存するのではなく、EAが自身の取引パフォーマンスから能動的に学習し、時間とともに挙動を適応させる仕組みを目指します。つまり、利益が出たかどうかに関係なく、すべての取引が学習シグナルになります。取引結果、特徴量データ(RSI、ATR、ボラティリティ、価格構造など)、そして実行フィードバックを収集することで、EAは有益な情報をPython側に送信します。Python側では、この新しい情報を分析し、モデルのパラメータをファインチューニングに活用します。
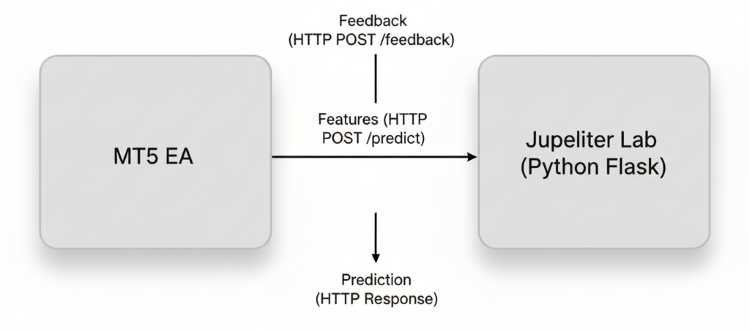
このシステムの中心にあるのは、フィードバックから適応へのループ構造です。EAは市場からリアルタイム特徴量を継続的に抽出し、それをPythonのRESTサーバーへ送信して予測を取得します。サーバーからは意思決定確率や取引バイアスが返されます。各取引が完了すると、EAはその結果(勝敗、保有時間、ドローダウンなど)を「/feedback」エンドポイント経由でサーバーへ報告します。サーバーはこれらのフィードバックサンプルを蓄積し、モデルのライブ市場での経験を反映したデータセットを構築していきます。一定期間ごとに、モデルはこのデータを用いて再学習、または重みの調整をおこないます。そして、より高精度かつ高応答性のモデルとして更新され、ONNX形式で再エクスポートされ、MQL5側での推論に再利用されます。
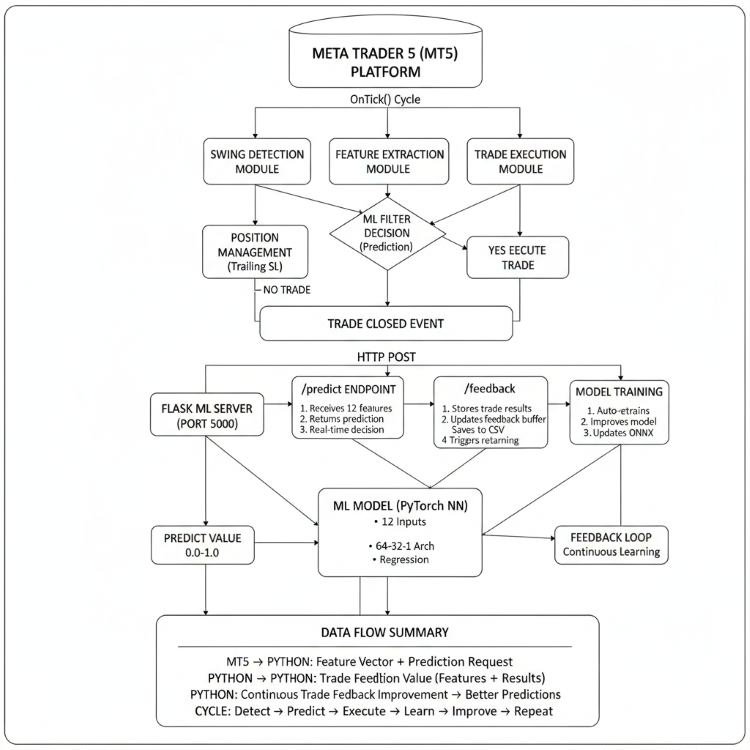
最終的に、この実装は取引システムを自己進化型アーキテクチャへと変換します。市場挙動、実行フィードバック、予測誤差のすべてが記録され、学習プロセスへ再投資されます。時間の経過とともに、このEAは収益性の高いパターンをより効率的に認識できるようになり、ボラティリティのサイクルに適応し、予測のドリフトを低減していきます。このアプローチにより、パフォーマンスの一貫性が向上し、市場とのあらゆる相互作用を通じて観察し、適応し、意思決定を洗練していく熟練トレーダーの自然な学習プロセスを再現することができます。
導入手順
from flask import Flask, request, jsonify import threading, time, os, json import torch import torch.nn as nn import torch.optim as optim import numpy as np import pandas as pd import onnx import onnxruntime as ort from sklearn.preprocessing import StandardScaler from datetime import datetime
まず、MQL5で構築された取引ロジックと適応学習モデルとの橋渡し役となるPythonバックエンド環境を構築します。軽量なREST APIフレームワークであるFlaskを使用し、MetaTrader 5とPythonモデル間でリアルタイム通信を可能にするエンドポイントを作成します。torch、onnx、onnxruntimeがディープラーニングモデルの処理を担当し、pandasとnumpyでデータ処理と特徴量の整形をおこないます。sklearnのスケーラーで入力される市場特徴量を正規化し、相場環境が変わってもモデルの安定性を保ちます。さらに、threadingとdatetimeを使ってフィードバック処理や再学習などのバックグラウンドタスクを回し、リアルタイム予測を止めない構成にします。このセットアップが、ライブ市場フィードバックとモデル適応を統合する基盤になります。取引環境内でモデルを継続的に進化させるための土台です。
app = Flask(__name__) # ---------- Config ---------- FEATURE_DIM = 12 # Must match MQL5 feature dimension RETRAIN_THRESHOLD = 100 # number of feedback samples before retrain ONNX_PATH = "live_model.onnx" MODEL_PATH = "live_model.pt" FEEDBACK_CSV = "feedback_log.csv" # ---------- Simple model ---------- class MLP(nn.Module): def __init__(self, n_in): super().__init__() self.net = nn.Sequential( nn.Linear(n_in, 64), nn.ReLU(), nn.Linear(64, 32), nn.ReLU(), nn.Linear(32, 1) # regression output (predicted expected reward) ) def forward(self, x): return self.net(x) device = torch.device("cpu") model = MLP(FEATURE_DIM).to(device) optimizer = optim.Adam(model.parameters(), lr=1e-3) loss_fn = nn.MSELoss() scaler = StandardScaler() # Initialize scaler with some default values to avoid errors try: default_features = np.zeros((100, FEATURE_DIM)) scaler.fit(default_features) print("Initialized scaler with default values") except Exception as e: print(f"Scaler initialization error: {e}") # Keep feedback in-memory buffer for quick retrain feedback_buffer = [] # list of dicts # ---------- Helpers ---------- def features_to_tensor(f): try: arr = np.array(f, dtype=float).reshape(1, -1) # Check if scaler is fitted and has the right dimension if hasattr(scaler, 'mean_') and scaler.mean_ is not None and len(scaler.mean_) == FEATURE_DIM: arr = scaler.transform(arr) else: # If scaler not properly fitted, use raw features (will be fixed during retraining) print("Scaler not properly fitted, using raw features") t = torch.tensor(arr, dtype=torch.float32) return t except Exception as e: print(f"Error in features_to_tensor: {e}") # Return zeros if there's an error return torch.zeros(1, FEATURE_DIM, dtype=torch.float32) def predict_raw(features): try: model.eval() with torch.no_grad(): t = features_to_tensor(features).to(device) out = model(t).cpu().numpy().ravel()[0] return float(out) except Exception as e: print(f"Prediction error: {e}") return 0.0
ここでは、Flaskアプリを初期化し、適応モデルの動作を制御する基本パラメータを設定します。FEATURE_DIM(特徴量次元)、RETRAIN_THRESHOLD(再学習の閾値)、モデルやフィードバックデータを保存するファイルパスなどの定数を定義します。中心となるのは、PyTorchで実装したシンプルなMLP(多層パーセプトロン)です。隠れ層は2層(64と32ニューロン)で、期待リターンや価格変動の強さを回帰的に予測するよう設計されています。AdamオプティマイザとMSELossで効率的に学習し、予測誤差を最小化します。StandardScalerは入力特徴量を標準化し、市場環境が変わってもモデル性能が安定するようにします。ダミーデータでスケーラーを事前に適合させることで、実際の市場データが揃う前の初期化エラーを防ぎます。
ヘルパー関数は、MetaTrader 5から送られてくる特徴量をモデル互換のテンソルに変換し、予測処理を安定しておこなえるようにします。features_to_tensor()関数は特徴量の形状を検証し、スケーリングを適用して、安全にPyTorchテンソルを返します。エラーが起きてもランタイムを止めません。一方、predict_raw()はネットワークの順伝播を評価モードで実行し、浮動小数点として予測値を取得します。このモジュール構造により、モデルは応答性と耐エラー性を維持しつつ、新しいフィードバックデータを取り込んで将来の再学習サイクルに柔軟に対応できます。
def save_feedback_to_csv(entry): try: # entry is a dict; features saved as JSON row = entry.copy() row["features"] = json.dumps(row["features"]) df = pd.DataFrame([row]) if not os.path.exists(FEEDBACK_CSV): df.to_csv(FEEDBACK_CSV, index=False) else: df.to_csv(FEEDBACK_CSV, mode='a', header=False, index=False) except Exception as e: print(f"Error saving feedback to CSV: {e}") def retrain_model(): global model, optimizer, scaler, feedback_buffer if len(feedback_buffer) < 10: # Minimum samples to retrain print(f"Not enough samples for retraining: {len(feedback_buffer)}") return print(f"[{datetime.utcnow().isoformat()}] Retraining model on {len(feedback_buffer)} samples...") try: # load buffer into DataFrame df = pd.DataFrame(feedback_buffer) X = np.vstack(df["features"].apply(lambda x: np.array(x)).values) y = df["reward"].astype(float).values.reshape(-1,1) # Fit scaler on current data scaler.fit(X) Xs = scaler.transform(X) Xs = torch.tensor(Xs, dtype=torch.float32) ys = torch.tensor(y, dtype=torch.float32) # small training loop model.train() epochs = 40 batch_size = min(32, len(Xs)) for ep in range(epochs): perm = torch.randperm(Xs.size(0)) for i in range(0, Xs.size(0), batch_size): idx = perm[i:i+batch_size] xb = Xs[idx] yb = ys[idx] pred = model(xb) loss = loss_fn(pred, yb) optimizer.zero_grad() loss.backward() optimizer.step() # save model to disk (torch) torch.save(model.state_dict(), MODEL_PATH) print(f"Model saved to {MODEL_PATH}") # export to ONNX dummy = torch.randn(1, FEATURE_DIM, dtype=torch.float32) model.eval() try: torch.onnx.export(model, dummy, ONNX_PATH, input_names=['input'], output_names=['output'], opset_version=11) print(f"ONNX exported to {ONNX_PATH}") except Exception as e: print("ONNX export failed:", e) # append buffer to CSV for row in feedback_buffer: save_feedback_to_csv(row) # clear buffer feedback_buffer = [] print("Retrain complete.") except Exception as e: print(f"Error during retraining: {e}") # background trainer thread that monitors buffer size def trainer_loop(): while True: try: if len(feedback_buffer) >= RETRAIN_THRESHOLD: retrain_model() except Exception as e: print("trainer error:", e) time.sleep(10) # Check every 10 seconds trainer_thread = threading.Thread(target=trainer_loop, daemon=True) trainer_thread.start()
ここでは、学習プロセスの中核となるフィードバック管理とモデル再学習システムを実装します。まず、save_feedback_to_csv()はフィードバックを記録します。抽出した特徴量、得られたリターン、追加メタデータを含む各エントリを、長期分析用のCSVログに保存します。特徴量配列はJSON文字列としてシリアライズされてから追記されるため、再読み込み時に構造を維持できます。このアプローチにより、モデルが後で再学習に使用できる取引結果の完全で継続的に成長するデータセットを維持できます。CSVファイルが存在しない場合は自動的に作成され、存在する場合は新しい行が効率的に追記され、進行中のプロセスを妨げません。
retrain_model()関数は、蓄積された市場フィードバックをモデルの学習更新に変換する役割を担います。バッファが十分なサンプル数に達すると、収集されたデータを読み込み、StandardScalerでスケーリングし、ニューラルネットワークの重みを微調整するために複数の学習エポックを実行します。学習後、モデルはPyTorch (.pt)とONNX形式の両方で保存され、MetaTrader 5がリアルタイム予測用に直接更新版にアクセスできるようになります。プロセスを自律的に保つため、trainer_loop()関数はバックグラウンドスレッドで継続的に動作し、バッファサイズを監視して閾値に達すると再学習をトリガーします。このセットアップにより、取引システムは自然に進化し、ライブフィードバックを吸収して自己再学習し、手動介入なしで推論モデルを更新することで、市場での実行における真の適応型インテリジェンスを実現します。
# ---------- Flask endpoints ---------- @app.route('/predict', methods=['POST']) def predict_endpoint(): try: payload = request.get_json(force=True) if not payload: return jsonify({"error": "No JSON data received"}), 400 features = payload.get("features") if features is None or len(features) != FEATURE_DIM: return jsonify({ "error": "bad features", "expected_dim": FEATURE_DIM, "received_dim": len(features) if features else 0 }), 400 pred = predict_raw(features) return jsonify({"prediction": pred}) except Exception as e: print(f"Prediction endpoint error: {e}") return jsonify({"error": str(e)}), 500 @app.route('/feedback', methods=['POST']) def feedback_endpoint(): try: payload = request.get_json(force=True) if not payload: return jsonify({"error": "No JSON data received"}), 400 # minimal validation; ensure reward exists if "features" not in payload or "reward" not in payload: return jsonify({"error": "need features and reward"}), 400 # Calculate reward if not provided (fallback logic) reward = payload.get("reward") if reward is None: # Try to calculate from pips_profit pips_profit = payload.get("pips_profit") if pips_profit is not None: reward = float(pips_profit) / 100.0 # Normalize else: reward = 0.0 # store in buffer entry = { "timestamp": payload.get("timestamp", datetime.utcnow().isoformat()), "symbol": payload.get("symbol", ""), "tf": payload.get("tf", ""), "features": payload["features"], "action": payload.get("action_taken", 0), "entry_price": payload.get("entry_price", 0.0), "exit_price": payload.get("exit_price", 0.0), "pips_profit": payload.get("pips_profit", 0.0), "reward": float(reward) } feedback_buffer.append(entry) # also save immediately to CSV for persistence save_feedback_to_csv(entry) return jsonify({ "status": "ok", "buffer_size": len(feedback_buffer), "reward_received": float(reward) }) except Exception as e: print(f"Feedback endpoint error: {e}") return jsonify({"error": str(e)}), 500
このセクションでは、取引システムと適応学習モデルのリアルタイム連携を管理するために、2つの重要なFlaskエンドポイント(/predictおよび/feedback)を設定します。/predictエンドポイントは、市場特徴量を含むJSONペイロードを受け取り、入力次元を検証し、モデルが生成した予測を返します。これにより、すべての予測リクエストが適切に構造化され、モデルの期待する入力形式と一貫性を保つことができます。一方、/feedbackエンドポイントは、取引後のデータ(実行したアクション、価格のエントリー、損益、得られたリターンなど)を取得します。この情報はフィードバックバッファに追加され、CSVファイルに永続化され、継続的学習の基盤を形成します。これらのエンドポイントにより、モデルが予測を提供し、市場結果から反復的に学習するフィードバック駆動型のエコシステムが構築されます。これにより、モデルの推論とパフォーマンス適応のループが閉じられます。
@app.route('/health', methods=['GET']) def health_check(): """Health check endpoint for monitoring""" return jsonify({ "status": "healthy", "timestamp": datetime.utcnow().isoformat(), "buffer_size": len(feedback_buffer), "feature_dim": FEATURE_DIM }) # optional endpoint to force retrain (admin) @app.route('/retrain', methods=['POST']) def retrain_now(): threading.Thread(target=retrain_model).start() return jsonify({"status": "retrain_started", "buffer_size": len(feedback_buffer)}) @app.route('/info', methods=['GET']) def info(): """Get information about the current model state""" return jsonify({ "feature_dim": FEATURE_DIM, "feedback_buffer_size": len(feedback_buffer), "retrain_threshold": RETRAIN_THRESHOLD, "model_path": MODEL_PATH, "scaler_fitted": hasattr(scaler, 'mean_') and scaler.mean_ is not None }) if __name__ == "__main__": print(f"Starting ML Server for MQL5 EA") print(f"Feature dimension: {FEATURE_DIM}") print(f"Retrain threshold: {RETRAIN_THRESHOLD}") print(f"Server will run on http://127.0.0.1:5000") print(f"Endpoints available:") print(f" POST /predict - Get prediction for features") print(f" POST /feedback - Send trade feedback") print(f" GET /health - Health check") print(f" GET /info - Model information") # Start the server app.run(host="127.0.0.1", port=5000, debug=False, threaded=True)実装の仕上げとして、3つのユーティリティエンドポイント(/health、/retrain、/info)を追加します。これらはモデルの稼働状況の監視、制御、および情報提供を目的としています。/healthエンドポイントは簡易診断ツールとして機能し、システムの現在の状態、タイムスタンプ、バッファサイズを報告してスムーズな運用を確認します。/retrainエンドポイントは、必要に応じて管理者が手動でモデル再学習をトリガーできるようにし、サーバーのメインプロセスを妨げないよう非同期で実行されます。最後に、/infoエンドポイントは、特徴量次元、再学習閾値、スケーラーの状態など、モデルに関する詳細なメタデータを提供し、システムの学習状況を可視化します。
MQL5での統合実装
MQL5での統合に関しては、既存の確立された戦略の一つである「Dynamic Swing Architecture」をベースに構築しました。このフレームワークはすでに市場構造の認識と適応型取引実行の強固な基盤を提供しており、次の進化ステップに最適です。ここでの焦点は、コアのスイングロジックを再確認することではなく、市場フィードバックと適応モデル学習を統合するためにおこなった更新と拡張にあります。具体的には、MQL5からのリアルタイム取引フィードバックがどのように取得され、送信され、モデルの意思決定プロセスを継続的に洗練するために活用されるかを詳しく見ていきます。これにより、モデルは変化する市場環境に応じて動的に進化できるようになります。
input group "ML Model Parameters" input string PythonHost = "127.0.0.1"; // Python server host input int PythonPort = 5000; // Python server port //--- input parameters for indicators input int InpATRPeriod = 14; input int InpRSIPeriod = 14; input int InpMomPeriod = 10; input int InpTrendLookback = 20; input int InpVolLookback = 20; //--- global handles int hATR = INVALID_HANDLE; int hRSI = INVALID_HANDLE; //--- global swing variables double g_lastSwingHigh = 0.0; double g_lastSwingLow = 0.0; bool g_lastSwingWasBullish = false;モデルの特徴量抽出をMQL5内で直接おこなうために、新しい入力グループ「ML Model Parameters」を実装しました。これにより、機械学習サーバーへの接続設定や、モデルが使用するインジケーター系特徴量の設定をシームレスにおこなえるようになります。このセクションでは、Pythonホストとポートへの接続用の入力に加え、主要なテクニカル指標の計算期間を定義するパラメータ(ATR、RSI、Momentum、Trend、Volatilityのルックバック)が導入されています。ATRとRSI用のグローバルハンドルも初期化され、EAの実行中にインジケーターのデータを効率的に計算および再利用できるようになっています。
//+------------------------------------------------------------------+ //| Extracts feature vector (double array) | //+------------------------------------------------------------------+ bool ExtractFeatures(double &features[], int dim) { if(dim != 12) { Print("ExtractFeatures: expected dim=12, got ", dim); return(false); } ArrayResize(features, dim); ArrayInitialize(features, 0.0); //--- 1. ATR (most recent) double atr_buffer[]; if(CopyBuffer(hATR, 0, 0, 1, atr_buffer) != 1) { Print("CopyBuffer ATR failed"); return(false); } double atr_value = atr_buffer[0]; //--- 2. RSI (latest) double rsi_buffer[]; if(CopyBuffer(hRSI, 0, 0, 1, rsi_buffer) != 1) { Print("CopyBuffer RSI failed"); return(false); } double rsi_value = rsi_buffer[0]; //--- 3. Distance to last swing high / low double lastSwingHigh = g_lastSwingHigh; double lastSwingLow = g_lastSwingLow; double priceNow = iClose(_Symbol, _Period, 0); double distHigh = (lastSwingHigh > 0) ? (priceNow - lastSwingHigh) : 0.0; double distLow = (lastSwingLow > 0) ? (lastSwingLow - priceNow) : 0.0; // normalize by ATR to scale double normHigh = (atr_value > 0 && lastSwingHigh > 0) ? distHigh/atr_value : 0.0; double normLow = (atr_value > 0 && lastSwingLow > 0) ? distLow/atr_value : 0.0; //--- 4. Swing strength = (high-low)/ATR double swingStrength = 0.0; if(lastSwingHigh > 0 && lastSwingLow > 0 && atr_value > 0) swingStrength = (lastSwingHigh - lastSwingLow) / atr_value; //--- 5. Swing direction: 1 for bullish, -1 for bearish int lastSwingDir = g_lastSwingWasBullish ? 1 : -1; double swingDirNorm = (double)lastSwingDir; //--- 6. Momentum: price difference over InpMomPeriod double pastClose = iClose(_Symbol, _Period, InpMomPeriod); double momentum = (priceNow - pastClose) / (atr_value > 0 ? atr_value : 1.0); //--- 7. TrendSlope: linear regression slope of last InpTrendLookback bars (close prices) double slope = 0.0; double arr[]; ArrayResize(arr, InpTrendLookback); for(int i = 0; i < InpTrendLookback; i++) arr[i] = iClose(_Symbol, _Period, i); // Calculate linear regression slope manually double sum_x = 0, sum_y = 0, sum_xy = 0, sum_xx = 0; for(int i = 0; i < InpTrendLookback; i++) { sum_x += i; sum_y += arr[i]; sum_xy += i * arr[i]; sum_xx += i * i; } double n = (double)InpTrendLookback; slope = (n * sum_xy - sum_x * sum_y) / (n * sum_xx - sum_x * sum_x); slope = slope / (atr_value > 0 ? atr_value : 1.0); //--- 8. Volume ratio: current volume / average of last InpVolLookback double volNow = iVolume(_Symbol, _Period, 0); double sumVol = 0.0; for(int i = 1; i <= InpVolLookback; i++) sumVol += iVolume(_Symbol, _Period, i); double avgVol = sumVol / InpVolLookback; double volRatio = (avgVol > 0) ? volNow / avgVol : 0.0; //--- 9 & 10. BreakAbove / BreakBelow flags double breakAbove = (lastSwingHigh > 0 && priceNow > lastSwingHigh) ? 1.0 : 0.0; double breakBelow = (lastSwingLow > 0 && priceNow < lastSwingLow) ? 1.0 : 0.0; //--- 11. TimeOfDay normalized MqlDateTime time_struct; TimeCurrent(time_struct); double hr = (double)time_struct.hour; double tod = hr / 24.0; //--- Assign features in array features[0] = normHigh; features[1] = normLow; features[2] = swingStrength; features[3] = swingDirNorm; features[4] = atr_value; features[5] = rsi_value / 100.0; // scale RSI 0-1 features[6] = momentum; features[7] = slope; features[8] = volRatio; features[9] = breakAbove; features[10] = breakBelow; features[11] = tod; return(true); }
ExtractFeatures関数は、原始的な価格データを正規化され、ATRでスケーリングされた特徴量に変換することで、12次元の包括的な市場スナップショットを作成します。この特徴量は、市場行動の複数の側面を捉えており、ボラティリティ(ATR)、モメンタム(RSIおよび価格モメンタム)、スイングのダイナミクス(直近高値および安値までの距離やスイング強度)、トレンド方向(線形回帰の傾き)、ボリューム活動(ボリューム比)、ブレイクアウトシグナル(スイングレベルの上抜け/下抜け)、そして時間的パターン(時刻)を含みます。この特徴量エンジニアリングによって、複雑な市場変動を標準化された数値ベクトルに変換し、機械学習モデルが分析可能な形式に整えています。各特徴量は一貫したスケーリングが施されており、価格距離はATRで割って異なる市場条件間でも比較可能にし、RSIは0〜1の範囲に正規化されています。これにより、MLアルゴリズムは絶対価格水準やボラティリティ環境に依存せず、取引予測のためのパターンや関係性を効率的に学習できるようになります。うことができるようになります。
//--- Converts feature array to JSON string FeaturesToJson(double &features[], int dim) { string json = "["; for(int i = 0; i < dim; i++) { json += DoubleToString(features[i], 8); if(i < dim - 1) json += ","; } json += "]"; return json; } //--- Generic HTTP POST string HttpPostJson(string url, string json_body, int &status_code) { string headers = "Content-Type: application/json\r\n"; char data[], result[]; ArrayResize(data, StringLen(json_body)); StringToCharArray(json_body, data, 0, StringLen(json_body)); int timeout = 5000; // 5 seconds string result_headers; ResetLastError(); int res = WebRequest("POST", url, headers, timeout, data, result, result_headers); status_code = res; if(res == -1) { int error_code = GetLastError(); Print("WebRequest failed. Error: ", error_code, " - ", GetLastError()); return ""; } return CharArrayToString(result); }
FeaturesToJson関数は、数値の特徴量配列をJSON文字列形式にシリアライズし、HTTP経由でPythonのMLサーバーに送信できるようにします。特徴ベクトルの各要素を順に処理し、doubleの値を小数点以下8桁で文字列に変換し、要素間にカンマを挿入しつつ、配列全体を角括弧で適切に囲むことでJSON配列を構築します。この変換は、EA内部の数値データ構造を標準化されたプラットフォーム非依存形式に変換する重要なステップであり、Python Flaskサーバーが正確な値を保持したまま容易に解析・処理できるようにします。これにより、機械学習予測の精度を維持しつつ、Web通信の規格にも適合させることができます。
HttpPostJson関数は、MetaTrader5プラットフォームとPython MLサーバー間の実際のHTTP通信を処理します。JSONデータをパッケージ化して送信し、必要なHTTPヘッダを設定してコンテンツタイプをJSONに指定し、送信用にJSON文字列を文字配列に変換します。その後、MetaTrader5のWebRequest関数を使用してPOSTリクエストを実行し、タイムアウトを5秒に設定して処理のハングを防ぎます。関数には包括的なエラー処理が組み込まれており、リクエストが失敗した場合は特定のエラーコードを捕捉して報告し、通信が確立した場合はサーバーからのレスポンスを文字列として返します。この堅牢なHTTPクライアント実装により、取引プラットフォームと機械学習バックエンド間でリアルタイムデータをシームレスに交換でき、EAが予測を受け取り、フィードバックを送信して継続的学習をおこなうための重要な通信橋が形成されます。
//--- Get model prediction from Python double GetPrediction(string host, int port, string symbol, string tf, double &features[], int dim) { string url = StringFormat("http://%s:%d/predict", host, port); string json = "{"; json += "\"symbol\":\"" + symbol + "\","; json += "\"tf\":\"" + tf + "\","; json += "\"features\":" + FeaturesToJson(features, dim); json += "}"; int code = 0; string resp = HttpPostJson(url, json, code); Print("Prediction Request - Code: ", code, ", Response: ", resp); if(code == 200 && StringFind(resp, "prediction") >= 0) { int p = StringFind(resp, "\"prediction\":"); if(p >= 0) { int start = p + StringLen("\"prediction\":"); int end = StringFind(resp, "}", start); if(end == -1) end = StringLen(resp); string val = StringSubstr(resp, start, end - start); // Remove any trailing commas or spaces StringReplace(val, ",", ""); StringReplace(val, " ", ""); StringReplace(val, "}", ""); double prediction = StringToDouble(val); Print("Parsed prediction value: ", prediction); return prediction; } } Print("Prediction failed. Code=", code, ", Response=", resp); return 0.0; } //--- Send feedback to Python bool SendFeedback(string host, int port, string symbol, string tf, double &features[], int dim, int action, double entry_price, double exit_price, double pips_profit, double reward) { string url = StringFormat("http://%s:%d/feedback", host, port); string json = "{"; json += "\"symbol\":\"" + symbol + "\","; json += "\"tf\":\"" + tf + "\","; json += "\"features\":" + FeaturesToJson(features, dim) + ","; json += "\"action_taken\":" + IntegerToString(action) + ","; json += "\"entry_price\":" + DoubleToString(entry_price, _Digits) + ","; json += "\"exit_price\":" + DoubleToString(exit_price, _Digits) + ","; json += "\"pips_profit\":" + DoubleToString(pips_profit, 4) + ","; json += "\"reward\":" + DoubleToString(reward, 6); json += "}"; int code = 0; string resp = HttpPostJson(url, json, code); if(code == 200) { Print("Feedback sent successfully. Position profit: ", pips_profit, " pips, Reward: ", reward); return true; } Print("Feedback failed. Code=", code, " Resp=", resp); return false; }
GetPrediction関数は、機械学習モデルからリアルタイムの取引シグナルを取得するための主要なインターフェースとして機能します。市場コンテキスト(銘柄および時間足)と12次元の特徴量ベクトルを含む包括的なHTTPリクエストを構築し、サーバーからのJSONレスポンスを丁寧に解析して数値予測値を抽出します。プロセス全体で堅牢なエラー処理と詳細なログ記録を実装しており、まず特徴量を含む適切にフォーマットされたJSONペイロードを作成し、/predictエンドポイントにPOSTリクエストを送信し、最後にレスポンス文字列から予測値を慎重に抽出します。文字列操作やクリーンアップをおこなうことで、さまざまなJSONフォーマットにも対応します。関数はHTTPステータスコードとサーバーの生レスポンスをログに記録することで、予測プロセスの透明性を確保し、通信失敗や予期しないレスポンス形式の場合には安全に0.0を返すフォールバック機能も備えています。
SendFeedback関数は、取引結果データをPythonサーバーに送信することで機械学習ライフサイクルを完結させます。これにより、モデルは実際の市場結果から学習し、予測精度を継続的に向上させることが可能になります。関数は、取引判断に至った元の特徴量、実際に取ったアクション(買い/売り)、エントリーおよび決済価格、ピップ換算の利益、正規化されたリターン値を含む詳細なJSONオブジェクトを構築します。これにより、教師あり学習に必要な学習データが提供されます。このフィードバックメカニズムは適応学習システムにとって非常に重要であり、MLモデルが過去の予測と実際の市場結果を関連付け、どの特徴パターンが成功する取引につながるか、失敗する取引につながるかを徐々に理解することを可能にします。結果として、蓄積された経験を通じて時間とともに精度を高める自己改善型の取引システムが構築されます。
//+------------------------------------------------------------------+ //| Calculate reward for ML feedback | //+------------------------------------------------------------------+ double CalculateReward(double profit, double pipsProfit, double volume) { // Customize this function based on your reward strategy // Simple implementation: normalize profit by volume and scale if(volume > 0) { double normalizedProfit = profit / (volume * 1000); // Adjust scaling factor as needed return normalizedProfit; } // Alternative: use pips profit directly return pipsProfit / 100.0; // Scale down pips to reasonable range } //+------------------------------------------------------------------+ //| Get historical features for a specific time | //+------------------------------------------------------------------+ bool GetHistoricalFeatures(datetime targetTime, double &features[]) { // Simplified implementation - uses current features // In production, you might want to store features when trades are opened ArrayResize(features, 12); return ExtractFeatures(features, 12); } //+------------------------------------------------------------------+ //| Track processed positions to avoid duplicates | //+------------------------------------------------------------------+ bool IsPositionProcessed(ulong positionTicket) { // Simple implementation using global variable static ulong lastProcessedTicket = 0; return (positionTicket == lastProcessedTicket); } //+------------------------------------------------------------------+ //| Mark position as processed | //+------------------------------------------------------------------+ void MarkPositionAsProcessed(ulong positionTicket) { static ulong lastProcessedTicket = 0; lastProcessedTicket = positionTicket; }このコードセクションでは、機械学習のフィードバックループを支える基本的なユーティリティ関数を実装しています。CalculateRewardは、取引結果をML学習に適した正規化リターン値に変換します。具体的には、取引量に応じた金額利益をスケーリングするか、ピップ利益をそのまま使用します。GetHistoricalFeaturesは、市場特徴量を取得する簡易的な仕組みを提供します。現在は実用的な近似として直近の特徴量を使用していますが、正確な過去データを保持するには追加のインフラが必要となります。IsPositionProcessedとMarkPositionAsProcessedは、最後に処理したポジションチケットを静的変数で管理することで、重複送信を防ぐシンプルな仕組みとして機能します。これにより、同じ取引のフィードバックがMLモデルに複数回送られることを防ぎ、学習サイクル内でデータの整合性を維持しつつ、MQL5環境の制約下でも効率的でシンプルな実装が可能になります。
ライブデモ
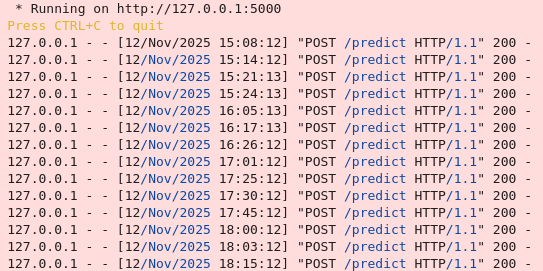
ここで、Flaskサーバーが正常に初期化され、ポート5000で稼働中です。これにより、MT5 EAからの予測リクエストを受信し、機械学習による取引シグナルを提供できる状態になっています。

以下に示すように、Jupyter Lab のモデルから MetaTrader5 に予測が送信されるようになります。
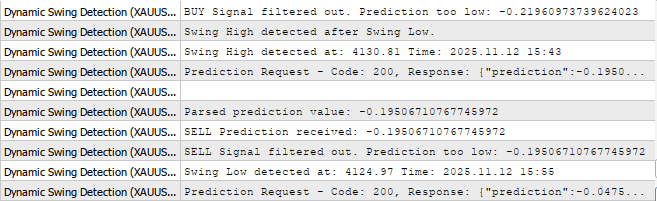
結論
市場フィードバックとモデル適応を統合することに成功し、取引EAを静的なルールベースシステムから動的で自己改善型のアルゴリズムへと変換する包括的な機械学習パイプラインを構築しました。これはいくつかの重要な統合によって実現されました。市場データを12次元の正規化特徴量に変換する堅牢な特徴量抽出システムの構築、予測リクエストのためのPython MLサーバーとのリアルタイムHTTP通信の確立、取引結果を自動的にモデルに送り返すフィードバックループの実装、そしてニューラルネットワークが新しい市場経験に基づいて継続的に再学習する適応型学習システムの設計です。統合には、適切なエラー処理、デバッグ用の詳細なログ記録、重複防止機構も組み込まれ、各取引の成功と失敗が将来の取引判断の改善に直接寄与する閉ループシステムが構築されています。
結論として、この機械学習統合により、トレーダーは成功した取引と失敗した取引の双方から学習する適応型システムを手に入れることができ、現在の市場状況に応じたより正確な市場予測を徐々に形成できます。従来の静的な取引アルゴリズムとは異なり、このシステムは実際のパフォーマンスデータに基づき意思決定を継続的に進化および改善し、より高い収益性、優れたリスク管理、一貫性の向上をもたらす可能性があります。自動化されたフィードバックループにより感情的な取引バイアスが排除され、市場データにおける複雑で非線形なパターンを認識できるモデルの能力により、従来のテクニカル分析では見逃される可能性のあるチャンスを特定できます。最終的に、各取引から学習しながら自己最適化する高度なツールをトレーダーに提供し、使用するほどに価値が高まるシステムとなります。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/20235
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索