
Integration von MQL5 mit Datenverarbeitungspaketen (Teil 6): Zusammenführung von Markt-Feedback und Modellanpassung

Inhaltsverzeichnis
- Einführung
- Überblick und Verständnis des Systems
- Die ersten Schritte
- Alles zusammen auf MQL5
- Live-Demo
- Schlussfolgerung
Einführung
In der vorangegangenen Diskussion haben wir uns mit adaptivem Lernen und Flexibilität beschäftigt, wobei wir uns auf den Aufbau eines Systems konzentrierten, das in der Lage ist, seine Entscheidungsprozesse als Reaktion auf veränderte Marktbedingungen anzupassen. In dieser Phase wurde die Bedeutung der Anpassungsfähigkeit des algorithmischen Handels hervorgehoben, die es dem Modell ermöglicht, seine Parameter auf der Grundlage sich entwickelnder Datenmuster dynamisch zu ändern, anstatt sich auf statische historische Verhaltensweisen zu verlassen. Durch Verstärkungslernen und adaptive Parametrisierung begann das System, die Fähigkeit zur Selbstoptimierung zu zeigen, was die Grundlage für eine kontinuierliche Verbesserung im Rahmen des Expert Advisor bildet.
In diesem Teil entwickeln wir dieses Konzept weiter, indem wir eine rückkopplungsgesteuerte Lernschleife zwischen der Echtzeit-Marktperformance und dem trainierten Modell einführen. Ziel ist es, eine Brücke zwischen der Ausführungsumgebung (MQL5) und der Datenverarbeitungsschicht (Jupyter Lab) zu schlagen, sodass Handelsergebnisse, Volatilitätsverschiebungen und Verhaltensanomalien zu aktiven Komponenten der Modellumschulung werden. Diese Integration ermöglicht es dem System nicht nur, Handelsgeschäfte auszuführen, sondern auch aus seiner eigenen Leistung zu lernen und die Vorhersagegenauigkeit und Entscheidungsqualität als Reaktion auf den Rhythmus des Live-Marktes kontinuierlich zu verbessern.
Überblick und Verständnis des Systems
Die Kernidee hinter dieser Implementierung ist es, ein kontinuierliches Lernökosystem zwischen der Handelsumgebung (MetaTrader5) und der analytischen Umgebung (Jupyter Lab) zu schaffen. Anstatt sich auf ein festes, vorab trainiertes Modell zu verlassen, soll der Expert Advisor aktiv aus seiner Handelsleistung lernen und sein Verhalten im Laufe der Zeit anpassen. Das bedeutet, dass jeder Handel, ob profitabel oder nicht, zu einem Lernsignal wird. Durch das Sammeln von Handelsergebnissen, Merkmalsdaten (wie RSI, ATR, Volatilität und Preisstruktur) und Ausführungsfeedback liefert der EA wertvolle Erkenntnisse, die an die Python-Seite zurückgesendet werden, wo das Modell diese neuen Informationen analysieren und zur Feinabstimmung seiner Parameter nutzen kann.
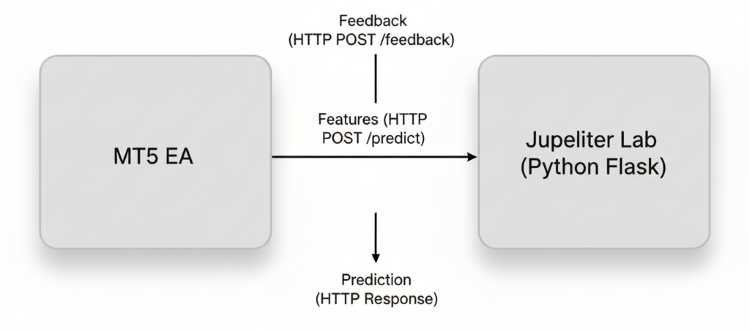
Das Herzstück dieses Systems ist die Schleife Feedback-zu-Anpassung. Der EA extrahiert kontinuierlich Echtzeit-Merkmale aus dem Markt, sendet sie zur Vorhersage an den Python-REST-Server und erhält im Gegenzug eine Entscheidungswahrscheinlichkeit oder eine Handelsverzerrung. Nach Abschluss eines jeden Handels meldet der EA die Ergebnisse (Gewinn/Verlust, Dauer, Drawdown usw.) über den Endpunkt /feedback an den Server zurück. Der Server fasst diese Rückmeldungen zu einem wachsenden Datensatz zusammen, der die Live-Markterfahrung des Modells darstellt. In regelmäßigen Abständen nutzt das Modell diese Daten, um seine Gewichte neu zu trainieren oder anzupassen und so eine genauere und reaktionsfähigere Version zu erzeugen, die später für die MQL5-Inferenz wieder nach ONNX exportiert wird.
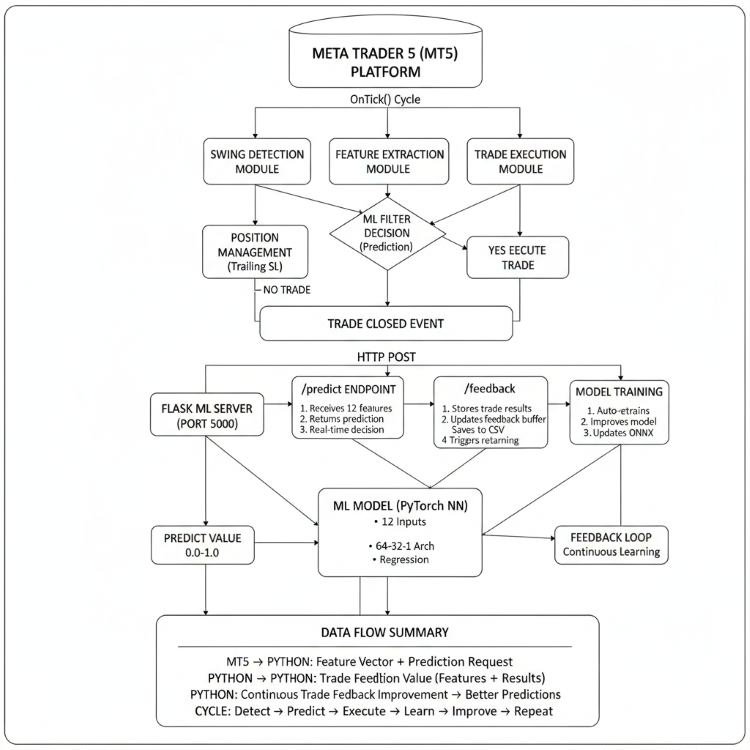
Letztlich verwandelt diese Implementierung das Handelssystem in eine sich selbst entwickelnde Architektur. Die Integration stellt sicher, dass Marktverhalten, Ausführungsfeedback und Prognosefehler erfasst und in den Lernprozess reinvestiert werden. Mit der Zeit wird der EA immer effizienter bei der Erkennung profitabler Strukturen, der Anpassung an Volatilitätszyklen und der Verringerung der Vorhersagedrift. Dieser Ansatz verbessert die Leistungskonsistenz und ahmt den natürlichen Lernprozess erfahrener Händler nach – sie beobachten, passen sich an und verfeinern ihre Entscheidungen mit jeder Marktinteraktion.
Erste Schritte
from flask import Flask, request, jsonify import threading, time, os, json import torch import torch.nn as nn import torch.optim as optim import numpy as np import pandas as pd import onnx import onnxruntime as ort from sklearn.preprocessing import StandardScaler from datetime import datetime
Wir beginnen mit der Einrichtung der Python-Backend-Umgebung, die als Brücke zwischen der Handelslogik in MQL5 und dem adaptiven Lernmodell dienen wird. Mit Flask als leichtgewichtigem REST-API-Framework erstellen wir Endpunkte, die eine Echtzeitkommunikation zwischen MetaTrader5 und unserem Python-Modell ermöglichen. Die wesentlichen Bibliotheken, wie torch, onnx und onnxruntime, behandeln Deep-Learning-Modelloperationen, während pandas und numpy die Datenverarbeitung und Merkmalsstrukturierung übernehmen. Der sklearn scaler sorgt für eine konsistente Normalisierung der eingehenden Marktmerkmale und gewährleistet so die Stabilität des Modells bei unterschiedlichen Marktbedingungen. Darüber hinaus werden Threading und Datetime verwendet, um Hintergrundaufgaben wie die Verarbeitung von Rückmeldungen und Umschulungen zu planen, ohne die Echtzeitvorhersagen zu unterbrechen. Dieser Aufbau bildet die Grundlage für die Verbindung von Live-Markt-Feedback und Modellanpassung und ermöglicht eine kontinuierliche Weiterentwicklung des Handelsmodells direkt aus der Handelsumgebung heraus.
app = Flask(__name__) # ---------- Config ---------- FEATURE_DIM = 12 # Must match MQL5 feature dimension RETRAIN_THRESHOLD = 100 # number of feedback samples before retrain ONNX_PATH = "live_model.onnx" MODEL_PATH = "live_model.pt" FEEDBACK_CSV = "feedback_log.csv" # ---------- Simple model ---------- class MLP(nn.Module): def __init__(self, n_in): super().__init__() self.net = nn.Sequential( nn.Linear(n_in, 64), nn.ReLU(), nn.Linear(64, 32), nn.ReLU(), nn.Linear(32, 1) # regression output (predicted expected reward) ) def forward(self, x): return self.net(x) device = torch.device("cpu") model = MLP(FEATURE_DIM).to(device) optimizer = optim.Adam(model.parameters(), lr=1e-3) loss_fn = nn.MSELoss() scaler = StandardScaler() # Initialize scaler with some default values to avoid errors try: default_features = np.zeros((100, FEATURE_DIM)) scaler.fit(default_features) print("Initialized scaler with default values") except Exception as e: print(f"Scaler initialization error: {e}") # Keep feedback in-memory buffer for quick retrain feedback_buffer = [] # list of dicts # ---------- Helpers ---------- def features_to_tensor(f): try: arr = np.array(f, dtype=float).reshape(1, -1) # Check if scaler is fitted and has the right dimension if hasattr(scaler, 'mean_') and scaler.mean_ is not None and len(scaler.mean_) == FEATURE_DIM: arr = scaler.transform(arr) else: # If scaler not properly fitted, use raw features (will be fixed during retraining) print("Scaler not properly fitted, using raw features") t = torch.tensor(arr, dtype=torch.float32) return t except Exception as e: print(f"Error in features_to_tensor: {e}") # Return zeros if there's an error return torch.zeros(1, FEATURE_DIM, dtype=torch.float32) def predict_raw(features): try: model.eval() with torch.no_grad(): t = features_to_tensor(features).to(device) out = model(t).cpu().numpy().ravel()[0] return float(out) except Exception as e: print(f"Prediction error: {e}") return 0.0
In diesem Abschnitt initialisieren wir die Flask-Anwendung und konfigurieren die wesentlichen Parameter, die die Funktionsweise unseres adaptiven Modells bestimmen. Wir definieren Konstanten wie die Merkmalsdimension (FEATURE_DIM), den Schwellenwert für die Nachschulung (RETRAIN_THRESHOLD) und die Dateipfade für die Speicherung der Modell- und Feedbackdaten. Das Herzstück dieses Aufbaus ist ein einfaches mehrschichtiges Perzeptron (MLP), das in PyTorch implementiert ist – ein leichtgewichtiges neuronales Netzwerk mit zwei versteckten Schichten (64 und 32 Neuronen), das für die regressionsbasierte Vorhersage der erwarteten Belohnung oder der Stärke der Kursbewegung entwickelt wurde. Der Adam-Optimierer und die MSELoss-Funktion werden verwendet, um effizient zu trainieren und Vorhersagefehler zu minimieren, während der StandardScaler sicherstellt, dass alle Eingabemerkmale für eine konsistente Modellleistung über verschiedene Marktzustände hinweg standardisiert sind. Durch die Vorabanpassung des Skalierers mit Dummy-Daten verhindern wir Initialisierungsfehler, bevor echte Marktdaten verfügbar sind.
Die Hilfsfunktionen übernehmen die Umwandlung der von MetaTrader5 eingehenden Merkmale in modellkompatible Tensoren und gewährleisten eine robuste Ausführung der Vorhersage. Die Funktion features_to_tensor() validiert Feature-Formen, wendet Skalierung an, falls vorhanden, und gibt sicher einen PyTorch-Tensor zurück, selbst wenn Fehler auftreten, um Laufzeitunterbrechungen zu vermeiden. In der Zwischenzeit führt predict_raw() die Vorwärtspropagation durch das Netzwerk im Evaluierungsmodus aus und ruft die numerische Ausgabe als Fließkomma-Vorhersage ab. Diese modulare Struktur ermöglicht es dem Modell, reaktionsschnell und fehlertolerant zu bleiben und gleichzeitig die Flexibilität zu bewahren, neue Feedback-Daten für zukünftige Umschulungszyklen zu integrieren.
def save_feedback_to_csv(entry): try: # entry is a dict; features saved as JSON row = entry.copy() row["features"] = json.dumps(row["features"]) df = pd.DataFrame([row]) if not os.path.exists(FEEDBACK_CSV): df.to_csv(FEEDBACK_CSV, index=False) else: df.to_csv(FEEDBACK_CSV, mode='a', header=False, index=False) except Exception as e: print(f"Error saving feedback to CSV: {e}") def retrain_model(): global model, optimizer, scaler, feedback_buffer if len(feedback_buffer) < 10: # Minimum samples to retrain print(f"Not enough samples for retraining: {len(feedback_buffer)}") return print(f"[{datetime.utcnow().isoformat()}] Retraining model on {len(feedback_buffer)} samples...") try: # load buffer into DataFrame df = pd.DataFrame(feedback_buffer) X = np.vstack(df["features"].apply(lambda x: np.array(x)).values) y = df["reward"].astype(float).values.reshape(-1,1) # Fit scaler on current data scaler.fit(X) Xs = scaler.transform(X) Xs = torch.tensor(Xs, dtype=torch.float32) ys = torch.tensor(y, dtype=torch.float32) # small training loop model.train() epochs = 40 batch_size = min(32, len(Xs)) for ep in range(epochs): perm = torch.randperm(Xs.size(0)) for i in range(0, Xs.size(0), batch_size): idx = perm[i:i+batch_size] xb = Xs[idx] yb = ys[idx] pred = model(xb) loss = loss_fn(pred, yb) optimizer.zero_grad() loss.backward() optimizer.step() # save model to disk (torch) torch.save(model.state_dict(), MODEL_PATH) print(f"Model saved to {MODEL_PATH}") # export to ONNX dummy = torch.randn(1, FEATURE_DIM, dtype=torch.float32) model.eval() try: torch.onnx.export(model, dummy, ONNX_PATH, input_names=['input'], output_names=['output'], opset_version=11) print(f"ONNX exported to {ONNX_PATH}") except Exception as e: print("ONNX export failed:", e) # append buffer to CSV for row in feedback_buffer: save_feedback_to_csv(row) # clear buffer feedback_buffer = [] print("Retrain complete.") except Exception as e: print(f"Error during retraining: {e}") # background trainer thread that monitors buffer size def trainer_loop(): while True: try: if len(feedback_buffer) >= RETRAIN_THRESHOLD: retrain_model() except Exception as e: print("trainer error:", e) time.sleep(10) # Check every 10 seconds trainer_thread = threading.Thread(target=trainer_loop, daemon=True) trainer_thread.start()
Hier implementieren wir das Feedback-Management- und Modellumschulungssystem, das als adaptiver Kern des Lernprozesses fungiert. Die Funktion save_feedback_to_csv() speichert die Feedback-Einträge – die jeweils die extrahierten Merkmale, die resultierende Belohnung und alle zusätzlichen Metadaten enthalten – in einem dauerhaften CSV-Protokoll zur Langzeitanalyse. Um Flexibilität zu gewährleisten, werden die Feature-Arrays als JSON-Strings serialisiert, bevor sie an die Datei angehängt werden, sodass ihre Struktur für ein späteres erneutes Laden erhalten bleibt. Dieser Ansatz ermöglicht es uns, einen vollständigen und ständig wachsenden Datensatz von Handelsergebnissen zu erhalten, den das Modell später für ein erneutes Training verwenden kann. Falls die CSV-Datei nicht existiert, wird sie automatisch erstellt; andernfalls werden neue Zeilen effizient angefügt, ohne laufende Prozesse zu unterbrechen.
Die Funktion retrain_model() ist für die Umwandlung des akkumulierten Marktfeedbacks in Lernupdates für das Modell zuständig. Sobald der Puffer eine ausreichende Anzahl von Stichproben erreicht hat, werden die gesammelten Daten geladen, mit dem StandardScaler skaliert und mehrere Trainingsepochen zur Feinabstimmung der Gewichte des neuronalen Netzes durchgeführt. Nach dem Training wird das Modell sowohl im Format von PyTorch (.pt) als auch im ONNX gespeichert, sodass MetaTrader5 für Echtzeit-Vorhersagen direkt auf die aktualisierte Version zugreifen kann. Um den Prozess autonom zu halten, läuft die Funktion trainer_loop() kontinuierlich in einem Hintergrund-Thread, überwacht die Puffergröße und löst ein erneutes Training aus, sobald der Schwellenwert erreicht ist. So wird sichergestellt, dass sich das Handelssystem auf natürliche Weise weiterentwickelt, indem es Live-Feedback aufnimmt, sich selbst neu trainiert und sein Inferenzmodell ohne manuelle Eingriffe aktualisiert. So wird eine echte adaptive Intelligenz bei der Marktausführung erreicht.
# ---------- Flask endpoints ---------- @app.route('/predict', methods=['POST']) def predict_endpoint(): try: payload = request.get_json(force=True) if not payload: return jsonify({"error": "No JSON data received"}), 400 features = payload.get("features") if features is None or len(features) != FEATURE_DIM: return jsonify({ "error": "bad features", "expected_dim": FEATURE_DIM, "received_dim": len(features) if features else 0 }), 400 pred = predict_raw(features) return jsonify({"prediction": pred}) except Exception as e: print(f"Prediction endpoint error: {e}") return jsonify({"error": str(e)}), 500 @app.route('/feedback', methods=['POST']) def feedback_endpoint(): try: payload = request.get_json(force=True) if not payload: return jsonify({"error": "No JSON data received"}), 400 # minimal validation; ensure reward exists if "features" not in payload or "reward" not in payload: return jsonify({"error": "need features and reward"}), 400 # Calculate reward if not provided (fallback logic) reward = payload.get("reward") if reward is None: # Try to calculate from pips_profit pips_profit = payload.get("pips_profit") if pips_profit is not None: reward = float(pips_profit) / 100.0 # Normalize else: reward = 0.0 # store in buffer entry = { "timestamp": payload.get("timestamp", datetime.utcnow().isoformat()), "symbol": payload.get("symbol", ""), "tf": payload.get("tf", ""), "features": payload["features"], "action": payload.get("action_taken", 0), "entry_price": payload.get("entry_price", 0.0), "exit_price": payload.get("exit_price", 0.0), "pips_profit": payload.get("pips_profit", 0.0), "reward": float(reward) } feedback_buffer.append(entry) # also save immediately to CSV for persistence save_feedback_to_csv(entry) return jsonify({ "status": "ok", "buffer_size": len(feedback_buffer), "reward_received": float(reward) }) except Exception as e: print(f"Feedback endpoint error: {e}") return jsonify({"error": str(e)}), 500
In diesem Abschnitt richten wir zwei wichtige Flask-Endpunkte ein – /predict und /feedback – um die Echtzeit-Interaktion zwischen dem Handelssystem und dem adaptiven Lernmodell zu verwalten. Der Endpunkt /predict verarbeitet eingehende JSON-Payloads mit Marktmerkmalen, validiert die Eingabedimensionen und gibt die vom Modell generierten Vorhersagen zurück. Dadurch wird sichergestellt, dass jede Vorhersageanforderung gut strukturiert ist und mit dem erwarteten Eingabeformat des Modells übereinstimmt. Der Endpunkt /Feedback hingegen erfasst Nachhandelsdaten wie getätigte Aktionen, Kurseinträge, Gewinne oder Verluste und die daraus resultierenden Belohnungen. Diese Informationen werden dann an den Feedback-Puffer angehängt und in einer CSV-Datei gespeichert, die die Grundlage für kontinuierliches Lernen bildet. Zusammen bilden diese Endpunkte ein Feedback-gesteuertes Ökosystem, in dem das Modell Vorhersagen liefert und iterativ aus den Marktergebnissen lernt – so schließt sich der Kreis zwischen Modellableitung und Leistungsanpassung.
@app.route('/health', methods=['GET']) def health_check(): """Health check endpoint for monitoring""" return jsonify({ "status": "healthy", "timestamp": datetime.utcnow().isoformat(), "buffer_size": len(feedback_buffer), "feature_dim": FEATURE_DIM }) # optional endpoint to force retrain (admin) @app.route('/retrain', methods=['POST']) def retrain_now(): threading.Thread(target=retrain_model).start() return jsonify({"status": "retrain_started", "buffer_size": len(feedback_buffer)}) @app.route('/info', methods=['GET']) def info(): """Get information about the current model state""" return jsonify({ "feature_dim": FEATURE_DIM, "feedback_buffer_size": len(feedback_buffer), "retrain_threshold": RETRAIN_THRESHOLD, "model_path": MODEL_PATH, "scaler_fitted": hasattr(scaler, 'mean_') and scaler.mean_ is not None }) if __name__ == "__main__": print(f"Starting ML Server for MQL5 EA") print(f"Feature dimension: {FEATURE_DIM}") print(f"Retrain threshold: {RETRAIN_THRESHOLD}") print(f"Server will run on http://127.0.0.1:5000") print(f"Endpoints available:") print(f" POST /predict - Get prediction for features") print(f" POST /feedback - Send trade feedback") print(f" GET /health - Health check") print(f" GET /info - Model information") # Start the server app.run(host="127.0.0.1", port=5000, debug=False, threaded=True)Zum Abschluss der Implementierung fügen wir drei Dienstprogramm-Endpunkte hinzu: /health, /retrain und /info, die die Überwachung, Steuerung und den Einblick in den Betriebszustand des Modells ermöglichen. Der /health-Endpunkt dient als schnelles Diagnosewerkzeug, das den aktuellen Status des Systems, den Zeitstempel und die Puffergröße meldet, um einen reibungslosen Betrieb zu gewährleisten. Mit dem Endpunkt /retrain können Administratoren bei Bedarf manuell eine Modellumschulung auslösen, die asynchron ausgeführt wird, um den Hauptprozess des Servers nicht zu unterbrechen. Schließlich liefert der Endpunkt /info detaillierte Metadaten über das Modell, einschließlich der Merkmalsdimensionen, des Retrain-Schwellenwerts und des Skalierungsstatus, und bietet so Transparenz über den Lernstatus des Systems.
Alles zusammen auf MQL5
Für unsere Integration in MQL5 haben wir uns entschieden, auf einer unserer bestehenden und gut etablierten Strategien aufzubauen – der Dynamic Swing Architecture. Dieser Rahmen bietet bereits eine solide Grundlage für die Erkennung von Marktstrukturen und die adaptive Handelsausführung und ist damit der perfekte Kandidat für unseren nächsten Evolutionsschritt. Daher konzentrieren wir uns in diesem Teil auf die Aktualisierungen und Verbesserungen, die speziell für die Integration des Konzepts der Zusammenführung von Marktfeedback und adaptivem Modelllernen vorgenommen wurden. Anstatt die zentrale Swing-Logik zu überarbeiten, werden wir tiefer in die Art und Weise eintauchen, wie das Echtzeit-Handelsfeedback von MQL5 erfasst, übertragen und genutzt wird, um den Entscheidungsprozess des Modells kontinuierlich zu verfeinern und es in die Lage zu versetzen, sich als Reaktion auf veränderte Marktbedingungen dynamisch weiterzuentwickeln.
input group "ML Model Parameters" input string PythonHost = "127.0.0.1"; // Python server host input int PythonPort = 5000; // Python server port //--- input parameters for indicators input int InpATRPeriod = 14; input int InpRSIPeriod = 14; input int InpMomPeriod = 10; input int InpTrendLookback = 20; input int InpVolLookback = 20; //--- global handles int hATR = INVALID_HANDLE; int hRSI = INVALID_HANDLE; //--- global swing variables double g_lastSwingHigh = 0.0; double g_lastSwingLow = 0.0; bool g_lastSwingWasBullish = false;Um die Merkmalsextraktion unseres Modells direkt in MQL5 zu unterstützen, haben wir eine neue Eingabegruppe mit dem Titel ML Model Parameters“ implementiert, die eine nahtlose Konfiguration sowohl der Verbindung zum Machine Learning Server als auch der vom Modell verwendeten indikatorbasierten Merkmale ermöglicht. In diesem Abschnitt werden die Eingaben für die Verbindung mit dem Python-Host und -Port sowie die Parameter vorgestellt, die die Berechnungszeiträume für die wichtigsten technischen Indikatoren – ATR, RSI, Momentum, Trend und Volatilitätsrückblicke – festlegen. Entsprechende globale Handles für ATR und RSI wurden initialisiert, um eine effiziente Berechnung und Wiederverwendung von Indikatordaten während der gesamten Ausführung des Expert Advisors zu gewährleisten.
//+------------------------------------------------------------------+ //| Extracts feature vector (double array) | //+------------------------------------------------------------------+ bool ExtractFeatures(double &features[], int dim) { if(dim != 12) { Print("ExtractFeatures: expected dim=12, got ", dim); return(false); } ArrayResize(features, dim); ArrayInitialize(features, 0.0); //--- 1. ATR (most recent) double atr_buffer[]; if(CopyBuffer(hATR, 0, 0, 1, atr_buffer) != 1) { Print("CopyBuffer ATR failed"); return(false); } double atr_value = atr_buffer[0]; //--- 2. RSI (latest) double rsi_buffer[]; if(CopyBuffer(hRSI, 0, 0, 1, rsi_buffer) != 1) { Print("CopyBuffer RSI failed"); return(false); } double rsi_value = rsi_buffer[0]; //--- 3. Distance to last swing high / low double lastSwingHigh = g_lastSwingHigh; double lastSwingLow = g_lastSwingLow; double priceNow = iClose(_Symbol, _Period, 0); double distHigh = (lastSwingHigh > 0) ? (priceNow - lastSwingHigh) : 0.0; double distLow = (lastSwingLow > 0) ? (lastSwingLow - priceNow) : 0.0; // normalize by ATR to scale double normHigh = (atr_value > 0 && lastSwingHigh > 0) ? distHigh/atr_value : 0.0; double normLow = (atr_value > 0 && lastSwingLow > 0) ? distLow/atr_value : 0.0; //--- 4. Swing strength = (high-low)/ATR double swingStrength = 0.0; if(lastSwingHigh > 0 && lastSwingLow > 0 && atr_value > 0) swingStrength = (lastSwingHigh - lastSwingLow) / atr_value; //--- 5. Swing direction: 1 for bullish, -1 for bearish int lastSwingDir = g_lastSwingWasBullish ? 1 : -1; double swingDirNorm = (double)lastSwingDir; //--- 6. Momentum: price difference over InpMomPeriod double pastClose = iClose(_Symbol, _Period, InpMomPeriod); double momentum = (priceNow - pastClose) / (atr_value > 0 ? atr_value : 1.0); //--- 7. TrendSlope: linear regression slope of last InpTrendLookback bars (close prices) double slope = 0.0; double arr[]; ArrayResize(arr, InpTrendLookback); for(int i = 0; i < InpTrendLookback; i++) arr[i] = iClose(_Symbol, _Period, i); // Calculate linear regression slope manually double sum_x = 0, sum_y = 0, sum_xy = 0, sum_xx = 0; for(int i = 0; i < InpTrendLookback; i++) { sum_x += i; sum_y += arr[i]; sum_xy += i * arr[i]; sum_xx += i * i; } double n = (double)InpTrendLookback; slope = (n * sum_xy - sum_x * sum_y) / (n * sum_xx - sum_x * sum_x); slope = slope / (atr_value > 0 ? atr_value : 1.0); //--- 8. Volume ratio: current volume / average of last InpVolLookback double volNow = iVolume(_Symbol, _Period, 0); double sumVol = 0.0; for(int i = 1; i <= InpVolLookback; i++) sumVol += iVolume(_Symbol, _Period, i); double avgVol = sumVol / InpVolLookback; double volRatio = (avgVol > 0) ? volNow / avgVol : 0.0; //--- 9 & 10. BreakAbove / BreakBelow flags double breakAbove = (lastSwingHigh > 0 && priceNow > lastSwingHigh) ? 1.0 : 0.0; double breakBelow = (lastSwingLow > 0 && priceNow < lastSwingLow) ? 1.0 : 0.0; //--- 11. TimeOfDay normalized MqlDateTime time_struct; TimeCurrent(time_struct); double hr = (double)time_struct.hour; double tod = hr / 24.0; //--- Assign features in array features[0] = normHigh; features[1] = normLow; features[2] = swingStrength; features[3] = swingDirNorm; features[4] = atr_value; features[5] = rsi_value / 100.0; // scale RSI 0-1 features[6] = momentum; features[7] = slope; features[8] = volRatio; features[9] = breakAbove; features[10] = breakBelow; features[11] = tod; return(true); }
Die Funktion ExtractFeatures erstellt einen umfassenden 12-dimensionalen Markt-Snapshot, indem sie rohe Kursdaten in normalisierte, ATR-skalierte Merkmale umwandelt, die mehrere Aspekte des Marktverhaltens erfassen, einschließlich Volatilität (ATR), Momentum (RSI und Kursmomentum), Swing-Dynamik (Abstand zu den jüngsten Hochs/Tiefs und Swing-Stärke), Trendrichtung (lineare Regressionsneigung), Volumenaktivität (Volumenverhältnis), Ausbruchssignale (Ausbruch über/unter Swing-Levels) und zeitliche Muster (Tageszeit). Dieses Feature-Engineering-Verfahren wandelt komplexe Marktbewegungen in einen standardisierten numerischen Vektor um, den das maschinelle Lernmodell analysieren kann. Dabei wird jedes Merkmal sorgfältig normalisiert, um eine konsistente Skalierung zu gewährleisten, wie z. B. die Teilung der Preisabstände durch die ATR, um sie über verschiedene Marktbedingungen hinweg vergleichbar zu machen, und die Skalierung des RSI auf eine Spanne von 0 bis 1, sodass der ML-Algorithmus unabhängig von absoluten Preisniveaus oder Volatilitätsregimen effektiv Muster und Beziehungen für die Erstellung von Handelsvorhersagen lernen kann.
//--- Converts feature array to JSON string FeaturesToJson(double &features[], int dim) { string json = "["; for(int i = 0; i < dim; i++) { json += DoubleToString(features[i], 8); if(i < dim - 1) json += ","; } json += "]"; return json; } //--- Generic HTTP POST string HttpPostJson(string url, string json_body, int &status_code) { string headers = "Content-Type: application/json\r\n"; char data[], result[]; ArrayResize(data, StringLen(json_body)); StringToCharArray(json_body, data, 0, StringLen(json_body)); int timeout = 5000; // 5 seconds string result_headers; ResetLastError(); int res = WebRequest("POST", url, headers, timeout, data, result, result_headers); status_code = res; if(res == -1) { int error_code = GetLastError(); Print("WebRequest failed. Error: ", error_code, " - ", GetLastError()); return ""; } return CharArrayToString(result); }
Die Funktion FeaturesToJson serialisiert das numerische Feature-Array in ein JSON-String-Format, das über HTTP an den Python ML-Server übertragen werden kann. Es konstruiert ein JSON-Array, indem es jedes Element des Merkmalsvektors durchläuft, die Werte mit doppelter Genauigkeit in eine String-Darstellung mit 8 Dezimalstellen Genauigkeit umwandelt und sie mit Kommas zwischen den Elementen richtig formatiert, während es sicherstellt, dass das Array richtig in eckige Klammern eingeschlossen ist. Diese Umwandlung ist von entscheidender Bedeutung, da sie die interne numerische Datenstruktur des EA in ein standardisiertes, plattformunabhängiges Format konvertiert, das der Python-Flask-Server leicht analysieren und verarbeiten kann. Dabei werden die präzisen numerischen Werte beibehalten, die für genaue Vorhersagen im Rahmen des maschinellen Lernens benötigt werden, während gleichzeitig die Webkommunikationsstandards eingehalten werden.
Die Funktion HttpPostJson übernimmt die eigentliche HTTP-Kommunikation zwischen der MetaTrader5-Plattform und dem Python ML-Server, indem sie die JSON-Daten verpackt und versendet. Es richtet die erforderlichen HTTP-Header ein, um den JSON-Inhaltstyp zu spezifizieren, konvertiert die JSON-Zeichenfolge in ein Zeichenarray für die Übertragung und verwendet die WebRequest-Funktion von MetaTrader5, um eine POST-Anfrage mit einer 5-Sekunden-Zeitüberschreitung durchzuführen, um ein Hängenbleiben zu verhindern. Die Funktion umfasst eine umfassende Fehlerbehandlung, die spezifische Fehlercodes erfasst und meldet, wenn Anfragen fehlschlagen, während die Antwort des Servers als String zurückgegeben wird, wenn die Kommunikation hergestellt wurde. Diese robuste HTTP-Client-Implementierung ermöglicht einen nahtlosen Echtzeit-Datenaustausch zwischen der Handelsplattform und dem Backend für maschinelles Lernen und bildet die entscheidende Kommunikationsbrücke, die es dem EA ermöglicht, Vorhersagen zu erhalten und Feedback für kontinuierliches Lernen zu senden.
//--- Get model prediction from Python double GetPrediction(string host, int port, string symbol, string tf, double &features[], int dim) { string url = StringFormat("http://%s:%d/predict", host, port); string json = "{"; json += "\"symbol\":\"" + symbol + "\","; json += "\"tf\":\"" + tf + "\","; json += "\"features\":" + FeaturesToJson(features, dim); json += "}"; int code = 0; string resp = HttpPostJson(url, json, code); Print("Prediction Request - Code: ", code, ", Response: ", resp); if(code == 200 && StringFind(resp, "prediction") >= 0) { int p = StringFind(resp, "\"prediction\":"); if(p >= 0) { int start = p + StringLen("\"prediction\":"); int end = StringFind(resp, "}", start); if(end == -1) end = StringLen(resp); string val = StringSubstr(resp, start, end - start); // Remove any trailing commas or spaces StringReplace(val, ",", ""); StringReplace(val, " ", ""); StringReplace(val, "}", ""); double prediction = StringToDouble(val); Print("Parsed prediction value: ", prediction); return prediction; } } Print("Prediction failed. Code=", code, ", Response=", resp); return 0.0; } //--- Send feedback to Python bool SendFeedback(string host, int port, string symbol, string tf, double &features[], int dim, int action, double entry_price, double exit_price, double pips_profit, double reward) { string url = StringFormat("http://%s:%d/feedback", host, port); string json = "{"; json += "\"symbol\":\"" + symbol + "\","; json += "\"tf\":\"" + tf + "\","; json += "\"features\":" + FeaturesToJson(features, dim) + ","; json += "\"action_taken\":" + IntegerToString(action) + ","; json += "\"entry_price\":" + DoubleToString(entry_price, _Digits) + ","; json += "\"exit_price\":" + DoubleToString(exit_price, _Digits) + ","; json += "\"pips_profit\":" + DoubleToString(pips_profit, 4) + ","; json += "\"reward\":" + DoubleToString(reward, 6); json += "}"; int code = 0; string resp = HttpPostJson(url, json, code); if(code == 200) { Print("Feedback sent successfully. Position profit: ", pips_profit, " pips, Reward: ", reward); return true; } Print("Feedback failed. Code=", code, " Resp=", resp); return false; }
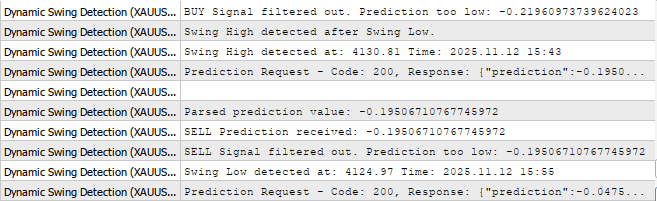
Die Funktion GetPrediction dient als primäre Schnittstelle für den Erhalt von Echtzeit-Handelssignalen aus dem maschinellen Lernmodell, indem sie eine umfassende HTTP-Anfrage erstellt, die sowohl den Marktkontext (Symbol und Zeitrahmen) als auch den 12-dimensionalen Merkmalsvektor enthält, und dann die JSON-Antwort des Servers sorgfältig parst, um den numerischen Prognosewert zu extrahieren. Sie implementiert eine robuste Fehlerbehandlung und eine detaillierte Protokollierung während des gesamten Prozesses – zunächst durch die Erstellung einer ordnungsgemäß formatierten JSON-Nutzlast, die die Merkmale enthält, dann durch die POST-Anforderung an den /predict-Endpunkt und schließlich durch die sorgfältige Extraktion des Vorhersagewerts aus der Antwortzeichenfolge durch Zeichenmanipulation und Bereinigung, um verschiedene JSON-Formatierungsszenarien zu handhaben. Die Funktion liefert umfassende Debugging-Informationen, indem sie sowohl den HTTP-Statuscode als auch die rohe Serverantwort protokolliert und so für Transparenz im Vorhersageprozess sorgt, während sie sicher 0,0 als Fallback-Wert zurückgibt, wenn die Kommunikation fehlschlägt oder das Antwortformat unerwartet ist.
Die SendFeedback-Funktion vervollständigt den Lebenszyklus des maschinellen Lernens, indem sie Daten über Handelsergebnisse an den Python-Server zurücksendet, sodass das Modell aus den tatsächlichen Marktergebnissen lernen und seine Prognosen kontinuierlich verbessern kann. Es konstruiert ein detailliertes JSON-Objekt, das den kompletten Handelskontext enthält – einschließlich der ursprünglichen Merkmale, die zu der Handelsentscheidung geführt haben, der spezifischen Aktion (Kauf/Verkauf), der Einstiegs- und Ausstiegskurse, des berechneten Gewinns in Pips und des normalisierten Belohnungswerts – was die notwendigen Trainingsdaten für das überwachte Lernen liefert. Dieser Feedback-Mechanismus ist für das adaptive Lernsystem von entscheidender Bedeutung, da er es dem ML-Modell ermöglicht, seine früheren Vorhersagen mit den tatsächlichen Marktergebnissen zu korrelieren und so schrittweise sein Verständnis dafür zu verfeinern, welche Merkmalsmuster zu erfolgreichen und welche zu erfolglosen Handelsgeschäften führen, wodurch ein sich selbst verbesserndes Handelssystem entsteht, das mit der Zeit durch die gesammelte Erfahrung immer genauer wird.
//+------------------------------------------------------------------+ //| Calculate reward for ML feedback | //+------------------------------------------------------------------+ double CalculateReward(double profit, double pipsProfit, double volume) { // Customize this function based on your reward strategy // Simple implementation: normalize profit by volume and scale if(volume > 0) { double normalizedProfit = profit / (volume * 1000); // Adjust scaling factor as needed return normalizedProfit; } // Alternative: use pips profit directly return pipsProfit / 100.0; // Scale down pips to reasonable range } //+------------------------------------------------------------------+ //| Get historical features for a specific time | //+------------------------------------------------------------------+ bool GetHistoricalFeatures(datetime targetTime, double &features[]) { // Simplified implementation - uses current features // In production, you might want to store features when trades are opened ArrayResize(features, 12); return ExtractFeatures(features, 12); } //+------------------------------------------------------------------+ //| Track processed positions to avoid duplicates | //+------------------------------------------------------------------+ bool IsPositionProcessed(ulong positionTicket) { // Simple implementation using global variable static ulong lastProcessedTicket = 0; return (positionTicket == lastProcessedTicket); } //+------------------------------------------------------------------+ //| Mark position as processed | //+------------------------------------------------------------------+ void MarkPositionAsProcessed(ulong positionTicket) { static ulong lastProcessedTicket = 0; lastProcessedTicket = positionTicket; }In diesem Abschnitt des Codes werden wichtige Dienstfunktionen implementiert, die die Rückkopplungsschleife des maschinellen Lernens unterstützen: CalculateReward wandelt rohe Handelsergebnisse in normalisierte Belohnungswerte um, die für das ML-Training geeignet sind, indem entweder der monetäre Gewinn durch das Handelsvolumen skaliert wird oder der Pip-Gewinn direkt verwendet wird; GetHistoricalFeatures bietet einen vereinfachten Mechanismus zum Abrufen von Marktmerkmalen – derzeit werden aktuelle Merkmale als praktische Annäherung verwendet, da die Speicherung exakter historischer Merkmale eine erhebliche zusätzliche Infrastruktur erfordern würde; und die Funktionen IsPositionProcessed/MarkPositionAsProcessed arbeiten zusammen als ein grundlegendes System zur Vermeidung von Duplikaten, das eine statische Variable verwendet, um das letzte verarbeitete Positionsticket zu verfolgen, wodurch sichergestellt wird, dass das Feedback jedes Handels trotz mehrfacher Überprüfungen nur einmal an das ML-Modell gesendet wird, wodurch die Datenintegrität im Lernzyklus aufrechterhalten wird, während die Implementierung innerhalb der Beschränkungen der MQL5-Umgebung einfach und effizient bleibt.
Live-Demo
Hier wurde der Flask-Server erfolgreich initialisiert und läuft nun auf Port 5000. Er ist bereit, Vorhersageanfragen von Ihrem MT5 EA zu empfangen und durch maschinelles Lernen gesteuerte Handelssignale zu liefern.

Wir erhalten jetzt Vorhersagen vom Modell auf Jupyter Lab zum MetaTrader5, wie Sie unten sehen können.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass es uns gelungen ist, Marktfeedback mit Modellanpassung zu verbinden, indem wir eine umfassende Pipeline für maschinelles Lernen implementiert haben, die den Handels-EA von einem statischen, regelbasierten System in einen dynamischen, sich selbst verbessernden Algorithmus verwandelt. Dies wurde durch mehrere wichtige Integrationen erreicht: die Entwicklung eines robusten Systems zur Merkmalsextraktion, das Marktdaten in 12 normalisierte Dimensionen umwandelt, die Einrichtung einer Echtzeit-HTTP-Kommunikation mit einem Python-ML-Server für Vorhersageanfragen, die Implementierung einer Feedback-Schleife, die Handelsergebnisse automatisch an das Modell zurücksendet, und die Entwicklung eines adaptiven Lernsystems, bei dem das neuronale Netz kontinuierlich auf neue Markterfahrungen umlernt. Die Integration umfasst eine angemessene Fehlerbehandlung, eine detaillierte Protokollierung für die Fehlersuche und Mechanismen zur Vermeidung von Duplikaten, sodass ein geschlossenes System entsteht, bei dem der Erfolg oder Misserfolg eines jeden Handels direkt zur Verfeinerung künftiger Handelsentscheidungen durch überwachtes Lernen beiträgt.
Zusammenfassend lässt sich sagen, dass diese Integration des maschinellen Lernens die Fähigkeiten der Händler erheblich verbessern wird, indem ein lernfähiges System geschaffen wird, das sowohl aus erfolgreichen als auch aus erfolglosen Handelsgeschäften lernt und nach und nach genauere, auf die aktuellen Marktbedingungen zugeschnittene Marktprognosen entwickelt. Im Gegensatz zu herkömmlichen statischen Handelsalgorithmen entwickelt sich dieses System kontinuierlich weiter und verbessert seine Entscheidungsfindung auf der Grundlage tatsächlicher Leistungsdaten, was im Laufe der Zeit zu höherer Rentabilität, besserem Risikomanagement und größerer Konsistenz führen kann. Die automatisierte Rückkopplungsschleife eliminiert emotionale Handelsvorurteile, während die Fähigkeit des Modells, komplexe, nichtlineare Muster in den Marktdaten zu erkennen, Gelegenheiten aufzeigen kann, die von der konventionellen technischen Analyse übersehen werden könnten, und den Händlern letztendlich ein hochentwickeltes, sich selbst optimierendes Instrument an die Hand gibt, das mit jeder Handelsentscheidung, die es trifft und aus der es lernt, wertvoller wird.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/20235
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.