
Modelli di regressione non lineare nei mercati finanziari

Introduzione
Ieri mi sono ritrovato ancora una volta ad analizzare i report del mio sistema di trading basato sulla regressione. Fuori dalla finestra cadeva neve bagnata, il caffè si raffreddava nella tazza, ma non riuscivo comunque a liberarmi di quel pensiero ossessivo. Sapete, sono da tempo infastidito da questi infiniti indicatori come RSI, Stocastico, MACD e altri ancora. Come possiamo provare a inserire un mercato vivo e dinamico in queste equazioni primitive? Ogni volta che vedo un altro sostenitore del Graal su YouTube con il suo set "sacro" di indicatori, mi viene da chiedere: ma credete davvero che questi calcolatori degli anni Settanta possano cogliere le complesse dinamiche del mercato moderno?
Ho passato gli ultimi tre anni cercando di creare qualcosa che funzionasse davvero. Ho provato molte cose, dalle regressioni più semplici alle reti neurali più sofisticate. E sapete una cosa? Sono riuscito ad ottenere risultati nella classificazione, ma non ancora nella regressione.
Era sempre la stessa storia: nello storico tutto funziona alla perfezione,ma quando lo rilascio sul mercato reale, mi trovo ad affrontare delle perdite. Ricordo quanto fossi entusiasta della mia prima rete neurale convoluzionale. R² dell’1,00% sul set di training. A ciò hanno fatto seguito due settimane di trading, con una perdita del 30% del deposito. Il classico esempio di overfitting nella sua forma migliore. Ho continuato a osservare l'andamento delle previsioni basate sulla regressione, vedendo come, col passare del tempo, si allontanassero sempre più dai prezzi reali...
Ma io sono una persona testarda. Dopo un'altra perdita, ho deciso di approfondire la questione e ho iniziato a esaminare articoli scientifici. E sapete cosa ho scovato in quegli archivi impolverati? A quanto pare, il vecchio Mandelbrot già insisteva sulla natura frattale dei mercati. E tutti noi stiamo cercando di fare trading con modelli lineari! È come cercare di misurare la lunghezza di una costa con un righello: più si misura con precisione, più risulta lunga.
A un certo punto mi è venuta un'illuminazione: e se provassi a combinare l'analisi tecnica classica con le dinamiche non lineari? Non questi indicatori approssimativi, ma qualcosa di più serio - equazioni differenziali, coefficienti adattivi. Sembra complicato, ma in sostanza si tratta semplicemente di imparare a parlare la lingua del mercato.
In breve, ho preso Python, ho collegato le librerie di machine learning e ho iniziato a sperimentare. Ho deciso subito - niente fronzoli accademici, solo ciò che è realmente utile. Niente supercomputer - solo un normale portatile Acer, un VPS potentissimo e il terminale MetaTrader 5. Da tutto ciò è nato il modello di cui voglio parlarvi oggi.
No, non è il Graal. I Graal non esistono, l'ho capito molto tempo fa. Sto semplicemente condividendo la mia esperienza sull'applicazione della matematica moderna al trading reale. Niente clamore superfluo, ma nemmeno il primitivismo degli "indicatori di trend". Il risultato è stato qualcosa di intermedio: abbastanza intelligente da funzionare, ma non così complesso da crollare al primo “cigno nero”.
Modello matematico
Ricordo come sono arrivato a questa equazione. Lavoro a questo codice dal 2022, ma non in modo continuativo: in termini di approcci, direi che ci sono molti sviluppi, quindi periodicamente (in modo un po' caotico) li si esamina e li si porta uno dopo l'altro al risultato. Ricordo di aver analizzato i grafici, cercando di individuare pattern ricorrenti nella coppia EUR/USD. E sapete cosa ha attirato la mia attenzione? Il mercato sembra respirare - a volte scorre fluidamente seguendo il trend, a volte sobbalza improvvisamente, a volte entra in una sorta di ritmo magico. Come descrivere tutto ciò matematicamente? Come tradurre questa dinamica vivente in equazioni?
In seguito, ho abbozzato la prima versione dell'equazione. Eccola qui, in tutto il suo splendore:
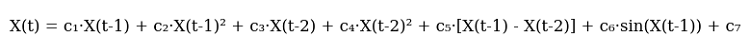
Ed ecco qui il codice:
def equation(self, x_prev, coeffs): x_t1, x_t2 = x_prev[0], x_prev[1] return (coeffs[0] * x_t1 + # trend coeffs[1] * x_t1**2 + # acceleration coeffs[2] * x_t2 + # market memory coeffs[3] * x_t2**2 + # inertia coeffs[4] * (x_t1 - x_t2) + # impulse coeffs[5] * np.sin(x_t1) + # market rhythm coeffs[6]) # basic level
Guardate com’è costruita l’equazione. I primi due termini rappresentano un tentativo di cogliere l'andamento attuale del mercato. Sapete come accelera un'auto? Prima gradualmente, poi sempre più velocemente. Ecco perché qui sono presenti sia un termine lineare che uno quadratico. Quando il prezzo si muove senza intoppi, la parte lineare funziona. Ma non appena il mercato accelera, il termine quadratico ne riflette l'andamento.
Ora viene la parte più interessante. Il terzo e il quarto termine guardano un po’ più indietro nel passato. È come una memoria di mercato. Ricordate la Teoria di Dow, secondo cui il mercato tende a reagire a livelli già visti? Anche qui è lo stesso. Anche qui compare una componente quadratica, utile a catturare le inversioni brusche.
Ora passiamo alla componente momentum. Semplicemente sottraiamo il prezzo precedente da quello attuale. Sembrerebbe primitivo. Ma funziona alla grande sui movimenti di trend! Quando il mercato entra in uno stato di euforia e “spinge” in una direzione, questo termine diventa la principale forza trainante della previsione.
Il seno è stato aggiunto quasi per caso. Stavo osservando i grafici e ho notato una sorta di periodicità. Soprattutto sull'H1. Si alternavano movimenti e periodi di calma... Sembra un'onda sinusoidale, vero? Ho inserito l'onda sinusoidale nell'equazione e il modello sembrava aver avuto un’illuminazione, iniziando a cogliere questi ritmi.
L'ultimo coefficiente rappresenta una sorta di rete di sicurezza, un livello di base. Questo termine non consente al modello di sorprendere eccessivamente il mercato con le sue previsioni.
Ho provato un sacco di altre opzioni. Ci ho infilato esponenti, logaritmi e ogni sorta di funzioni trigonometriche complesse. Non ha molto senso, ma il modello si trasforma in un mostro. Come diceva Occam: non moltiplicare le entità oltre il necessario. La versione attuale si è rivelata proprio così: semplice e funzionale.
Naturalmente, tutti questi coefficienti devono essere selezionati in qualche modo. È qui che il buon vecchio metodo Nelder-Mead viene in nostro aiuto. Ma questa è tutta un'altra storia che vi racconterò nella prossima parte. Credetemi, c'è molto di cui parlare: gli errori che ho commesso durante l'ottimizzazione basterebbero per un articolo a parte.
Componenti lineariCominciamo dalla parte lineare. Sapete qual è la cosa principale? Il modello prende in considerazione i due valori di prezzo precedenti, ma in modi diversi. Il primo coefficiente si aggira solitamente intorno a 0.3-0.4: si tratta di una reazione immediata all'ultima variazione. Ma il secondo è più interessante, si avvicina spesso a 0.7, il che indica una maggiore influenza del penultimo prezzo. Divertente, vero? Il mercato sembra basarsi su livelli leggermente più datati, senza fidarsi delle fluttuazioni più recenti.
Componenti quadraticheÈ successa una cosa interessante con i termini quadratici. Inizialmente li ho aggiunti semplicemente per tenere conto della non linearità, ma poi ho notato qualcosa di sorprendente. In un mercato tranquillo, il loro contributo è trascurabile: i coefficienti oscillano intorno a 0.01-0.02. Ma non appena si innesca un movimento forte, questi membri sembrano risvegliarsi. Ciò è particolarmente evidente sui grafici giornalieri dell'EURUSD: quando il trend si rafforza, i termini quadratici iniziano a prevalere, consentendo al modello di "accelerare" insieme al prezzo.
Componente di momentumLa componente relativa al momentum si è rivelata una vera scoperta. Potrebbe sembrare una differenza di prezzo insignificante, ma riflette con estrema precisione “l'umore” del mercato! Durante i periodi di calma, il suo coefficiente si mantiene intorno a 0.2-0.3, ma prima di forti oscillazioni spesso sale a 0.5. Questo è diventato per me una sorta di indicatore di svolta imminente: quando l'ottimizzatore inizia ad aumentare il peso del momentum, aspettatevi dei movimenti.
Componente ciclicaLa componente ciclica ha richiesto qualche modifica. Inizialmente ho provato con diversi periodi dell'onda sinusoidale, ma poi ho capito che è il mercato stesso a dettare il ritmo. È sufficiente lasciare che il modello regoli l'ampiezza tramite il coefficiente, e la frequenza si ottiene naturalmente dai prezzi stessi. È curioso osservare come questo coefficiente cambi tra la sessione europea e quella americana, come se il mercato respirasse davvero a un ritmo diverso.
Infine, il termine libero. Il suo ruolo si è rivelato molto più importante di quanto avessi inizialmente pensato. Nei periodi di elevata volatilità, funge da ancora, impedendo alle previsioni di volare via nello spazio. E nei periodi di calma aiuta a tenere conto in modo più preciso del livello generale dei prezzi. Molto spesso, il suo valore è correlato alla forza del trend - più forte è il trend, più il termine libero si avvicina a zero.
Sapete qual è la cosa più interessante? Ogni volta che cercavo di complicare il modello, aggiungendo nuovi termini, utilizzando funzioni più complesse, ecc., i risultati peggioravano soltanto. Era come se il mercato dicesse: "Ragazzo, non fare il sapientone, hai già preso la cosa principale". La versione attuale dell'equazione rappresenta un ottimo compromesso tra complessità ed efficienza. Ci sono sette coefficienti, né più né meno, ognuno con un ruolo ben definito nel meccanismo complessivo di previsione.
Tra l'altro, l'ottimizzazione di questi coefficienti è una storia affascinante a sé stante. Quando si inizia a osservare come il metodo Nelder-Mead ricerca i valori ottimali, viene spontaneo rammentare la teoria del caos. Ma di questo parleremo nella prossima parte - c'è qualcosa di interessante da vedere, credetemi.
Ottimizzazione del modello tramite l'algoritmo Nelder-Mead
Qui prenderemo in esame l'aspetto più interessante - come far funzionare il nostro modello con dati reali. Dopo mesi di esperimenti con le ottimizzazioni, decine di notti insonni e litri di caffè, ho finalmente trovato un approccio funzionante.
Tutto è iniziato come al solito - con una discesa del gradiente. Un classico del genere, la prima cosa che viene in mente a qualsiasi data scientist. Ho impiegato tre giorni per l'implementazione e un'altra settimana per il debug... Quali sono stati dunque i risultati? Il modello si è categoricamente rifiutato di convergere. O volava all'infinito o rimaneva bloccato nei minimi locali. I gradienti variavano in modo incredibile.
Poi c'è stata una settimana dedicata agli algoritmi genetici. L'idea è apparentemente elegante - lasciare che l'evoluzione trovi i coefficienti ottimali. L'ho implementato, l'ho avviato... solo per rimanere sbalordito dai tempi di esecuzione. Il computer ha ronzato tutta la notte per elaborare una settimana di dati storici. I risultati erano talmente instabili che era come leggere le foglie di tè.
E poi mi sono imbattuto nel metodo Nelder-Mead. Il buon vecchio metodo simplex, sviluppato nel lontano 1965. Niente derivate, niente matematica avanzata - semplicemente un'esplorazione intelligente dello spazio delle soluzioni. L'ho avviato e non potevo credere ai miei occhi. L'algoritmo sembrava danzare con il mercato, avvicinandosi dolcemente ai valori ottimali.
Ecco la funzione di perdita di base. È semplice come un'ascia, ma funziona alla perfezione:
def loss_function(self, coeffs, X_train, y_train): y_pred = np.array([self.equation(x, coeffs) for x in X_train]) mse = np.mean((y_pred - y_train)**2) r2 = r2_score(y_train, y_pred) # Save progress for analysis self.optimization_progress.append({ 'mse': mse, 'r2': r2, 'coeffs': coeffs.copy() }) return mse
Inizialmente, ho cercato di complicare la funzione di perdita, aggiungendo penalità per coefficienti grandi, inserendovi anche il MAPE e altre metriche. Un classico errore degli sviluppatori è pensare che, se qualcosa funziona, debba essere migliorato fino a diventare completamente inutilizzabile. Alla fine, sono tornato al semplice MSE, e sapete una cosa? A quanto pare, la semplicità è davvero segno di genialità.
È un'emozione particolare poter osservare l'ottimizzazione in tempo reale. Prime iterazioni: i coefficienti saltano in modo incontrollato, l'MSE salta, R² è vicino a zero. Poi inizia la parte più interessante - l'algoritmo individua la direzione giusta e le metriche migliorano gradualmente. Già alla centesima iterazione è chiaro se si otterranno benefici o meno e alla trecentesima il sistema solitamente raggiunge un livello stabile.
A proposito, vorrei spendere due parole sulle metriche. Il nostro R² è solitamente superiore a 0,996, il che significa che il modello spiega oltre il 99,6% della variazione di prezzo. L'errore quadratico medio (MSE) è di circa 0,0000007, ovvero l'errore di previsione raramente supera i sette decimi di pip. Per quanto riguarda MAPE... Il MAPE è generalmente soddisfacente, spesso inferiore allo 0,1%. È chiaro che tutto ciò si basa su dati storici, ma anche nei forward test i risultati non sono molto peggiori.
Ma la cosa più importante non sono nemmeno i numeri. La cosa principale è la stabilità dei risultati. È possibile eseguire l'ottimizzazione dieci volte di seguito e ogni volta si otterranno valori di coefficienti molto simili. Questo ha un grande valore, soprattutto considerando le difficoltà che ho incontrato con altri metodi di ottimizzazione.
Sapete cos'altro è fantastico? Osservando l'ottimizzazione, si possono comprendere molti aspetti del mercato stesso. Ad esempio, quando l'algoritmo cerca costantemente di aumentare il peso della componente momentum, significa che un forte movimento si sta preparando nel mercato. Oppure, quando inizia a interagire con la componente ciclica, aspettatevi un periodo di maggiore volatilità.
Nella prossima sezione, vi spiegherò come tutta questa struttura matematica si trasforma in un vero e proprio sistema di trading. Credetemi, c'è anche altro su cui riflettere - le insidie relative a MetaTrader 5 da sole meriterebbero un articolo a parte.
Caratteristiche del processo di addestramento
La preparazione dei dati per l'addestramento era una storia a parte. Ricordo che nella prima versione del sistema fornivo con entusiasmo l'intero dataset a sklearn.train_test_split... Solo in seguito, osservando con sospetto i buoni risultati, mi sono reso conto che i dati futuri si stavano infiltrando nel passato!
Capite qual è il problema? Non è possibile trattare i dati finanziari come un normale foglio di calcolo di Kaggle. Qui, ogni dato rappresenta un momento preciso nel tempo, e combinarli è come cercare di prevedere il tempo di ieri basandosi su quello di domani. Di conseguenza, è nato questo codice semplice ma efficace:
def prepare_training_data(prices, train_ratio=0.67): # Cut off a piece for training n_train = int(len(prices) * train_ratio) # Forming prediction windows X = np.array([[prices[i], prices[i-1]] for i in range(2, len(prices)-1)]) y = prices[3:] # Fair time sharing X_train, y_train = X[:n_train], y[:n_train] X_test, y_test = X[n_train:], y[n_train:] return X_train, y_train, X_test, y_testSembrerebbe un codice semplice. Ma dietro questa semplicità si nascondono molte difficoltà. Inizialmente, ho sperimentato con diverse dimensioni delle finestre. Pensavo che più punti storici si utilizzassero, migliori sarebbero state le previsioni. Mi sbagliavo! Ho scoperto che i due valori precedenti erano più che sufficienti. Il mercato, si sa, non ama ricordare il passato a lungo.
La dimensione del campione di addestramento è un discorso a parte. Ho provato diverse opzioni: 50/50, 80/20, persino 90/10. Alla fine, ho optato per la proporzione aurea - circa il 67% dei dati di addestramento. Perché? È semplicemente la soluzione migliore! A quanto pare il vecchio Fibonacci sapeva qualcosa sulla natura dei mercati...
È divertente osservare l'addestramento del modello a partire da diversi set di dati. Durante un periodo di calma, i coefficienti vengono selezionati senza intoppi e le metriche migliorano gradualmente. Ma se il campione di addestramento include qualcosa come la Brexit o un discorso del presidente della Federal Reserve, si scatena il caos: i coefficienti schizzano alle stelle, l'ottimizzatore impazzisce e i grafici degli errori assumono un andamento altalenante.
A proposito, vorrei spendere ancora due parole sulle metriche. Ho notato che se il valore di R² sul campione di addestramento è superiore a 0,98, è quasi certo che si sia verificato qualche tipo di errore nei dati. Il mercato reale non può essere così prevedibile. È come quella storia dello studente troppo bravo - o imbroglia o è un genio. Nel nostro caso, di solito si tratta della prima opzione.
Un altro punto importante è la preelaborazione dei dati. Inizialmente ho provato a normalizzare i prezzi, a scalare, a rimuovere i valori anomali... In generale, ho fatto tutto ciò che viene insegnato nei corsi di apprendimento automatico. Ma gradualmente sono giunto alla conclusione che meno si manipolano i dati grezzi, meglio è. Il mercato si normalizzerà, basta preparare tutto nel modo giusto.
Ora l’addestramento è stato semplificato al punto da diventare automatico. Una volta alla settimana carichiamo nuovi dati, eseguiamo l'addestramento e confrontiamo le metriche con i valori storici. Se tutti i valori rientrano nei limiti normali, aggiorniamo i coefficienti nel sistema operativo reale. Se qualcosa ti sembra sospetto, indaga più a fondo. Fortunatamente, l'esperienza ci permette già di capire dove cercare il problema.
Ottimizzazione dei coefficienti
def fit(self, prices): # Prepare data for training X_train, y_train = self.prepare_training_data(prices) # I found these initial values by trial and error initial_coeffs = np.array([0.5, 0.1, 0.3, 0.1, 0.2, 0.1, 0.0]) result = minimize( self.loss_function, initial_coeffs, args=(X_train, y_train), method='Nelder-Mead', options={ 'maxiter': 1000, # More iterations does not improve the result 'xatol': 1e-8, # Accuracy by ratios 'fatol': 1e-8 # Accuracy by loss function } ) self.coefficients = result.x return result
Sapete qual è stata la cosa più difficile? Bisogna azzeccare quei dannati coefficienti iniziali. Inizialmente ho provato a usare valori casuali, ma ho ottenuto una tale varietà di risultati che stavo per arrendermi. Poi ho provato a iniziare con valori pari a uno: l'ottimizzatore è volato via nello spazio da qualche parte durante le prime iterazioni. Non ha funzionato nemmeno con gli zeri, dato che si bloccava nei minimi locali.
Il primo coefficiente 0.5 rappresenta il peso della componente lineare. Se è inferiore, il modello perde la sua tendenza; se è superiore, inizia a dipendere eccessivamente dall'ultimo prezzo. Per i termini quadratici, 0.1 si è rivelato un punto di partenza perfetto - sufficiente per cogliere la non linearità, ma non così tanto da far sì che il modello impazzisse in caso di movimenti inaspettati. Il valore di 0.2 per il momentum è stato ottenuto empiricamente; semplicemente, a questo valore il sistema ha mostrato i risultati più stabili.
Durante l'ottimizzazione, Nelder-Mead costruisce un simplesso in uno spazio di coefficienti a sette dimensioni. È come un gioco di caldo e freddo, solo che si svolge in sette dimensioni contemporaneamente. È importante prevenire la divergenza del processo, ed è per questo che esistono requisiti di precisione così rigorosi (1e-8). Se è inferiore, otteniamo risultati instabili; se è superiore, l'ottimizzazione inizia a bloccarsi nei minimi locali.
Mille iterazioni possono sembrare eccessive, ma in pratica l'ottimizzatore converge solitamente in 300-400 passaggi. Semplicemente, a volte, soprattutto durante i periodi di elevata volatilità, ha bisogno di più tempo per trovare la soluzione ottimale. Inoltre, le iterazioni aggiuntive non influiscono significativamente sulle prestazioni - l'intero processo richiede in genere meno di un minuto sull'hardware moderno.
Tra l'altro, è stato proprio durante la fase di debug di questo codice che è nata l'idea di aggiungere una visualizzazione del processo di ottimizzazione. Quando si vedono i coefficienti cambiare in tempo reale, è molto più facile capire cosa sta succedendo al modello e dove potrebbe andare.
Metriche della qualità e la loro interpretazione
Valutare la qualità di un modello predittivo è una questione a sé stante, ricca di sfumature non ovvie. Nel corso degli anni di lavoro con il trading algoritmico, ho avuto così tante difficoltà con le metriche da scriverci un libro a parte. Ma vi parlerò della cosa principale.
Ecco i risultati:

Cominciamo con il coefficiente di determinazione R-quadro. La prima volta che ho visto valori superiori a 0,9 su EURUSD, non potevo credere ai miei occhi. Ho controllato il codice dieci volte per assicurarmi che non ci fossero perdite di dati o errori di calcolo. Non ce n'era nessuno - il modello spiega più del 90% della varianza dei prezzi. Tuttavia, in seguito mi sono reso conto che si tratta di un’arma a doppio taglio. Un valore di R² troppo elevato (superiore a 0,95) di solito indica overfitting. Il mercato non può essere così prevedibile.
MSE è il nostro cavallo di battaglia. Ecco un tipico codice di valutazione:
def evaluate_model(self, y_true, y_pred): results = { 'R²': r2_score(y_true, y_pred), 'MSE': mean_squared_error(y_true, y_pred), 'MAPE': mean_absolute_percentage_error(y_true, y_pred) * 100 } # Additional statistics that often save the day errors = y_pred - y_true results['max_error'] = np.max(np.abs(errors)) results['error_std'] = np.std(errors) # Look separately at error distribution "tails" results['error_quantiles'] = np.percentile(np.abs(errors), [50, 90, 95, 99]) return results
Vale la pena soffermarsi anche sulle statistiche aggiuntive Ho aggiunto max_error e error_std dopo un incidente spiacevole - il modello mostrava un MSE eccellente, ma a volte forniva previsioni talmente anomale tali da poter bruciare il deposito. La prima cosa che osservo sono le "code" della distribuzione degli errori. Tuttavia, le code esistono ancora:
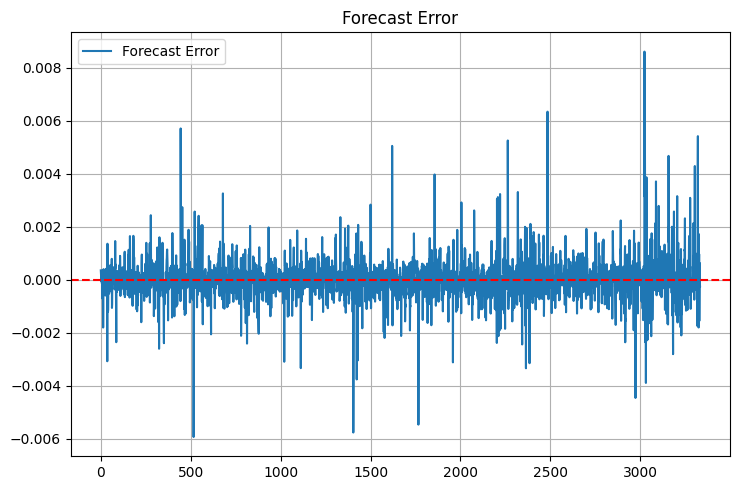
MAPE è una metrica molto intuitiva per i trader. Se parli loro di R-quadro, i loro occhi si velano di stupore, ma se dici "il modello è errato dello 0,05% in media", capiscono immediatamente. C'è però un problema - il MAPE può essere ingannevolmente basso durante piccole oscillazioni di prezzo e schizzare alle stelle durante brusche variazioni.
Ma la cosa più importante che ho capito è che nessuna metrica basata su dati storici garantisce il successo nella vita reale. Ecco perché ora ho un intero sistema di controlli:
def validate_model_performance(self): # Check metrics on different timeframes timeframes = ['H1', 'H4', 'D1'] for tf in timeframes: metrics = self.evaluate_on_timeframe(tf) if not self._check_metrics_thresholds(metrics): return False # Look at behavior at important historical events stress_periods = self.get_stress_periods() stress_metrics = self.evaluate_on_periods(stress_periods) if not self._check_stress_performance(stress_metrics): return False # Check the stability of forecasts stability = self.check_prediction_stability() if stability < self.min_stability_threshold: return False return True
Il modello deve superare tutti questi test prima che io lo utilizzi per il trading reale. E anche dopo, per le prime due settimane opero con un volume minimo, per verificare il comportamento nel mercato reale.
Spesso ci si chiede quali valori metrici siano considerati buoni. Secondo la mia esperienza, un R² superiore a 0,9 è eccellente, un MSE inferiore a 0,00001 è accettabile, mentre un MAPE fino allo 0,05% è splendido. Tuttavia! È più importante esaminare la stabilità di questi indicatori nel tempo. È meglio avere un modello con metriche leggermente peggiori ma stabili, piuttosto che un sistema estremamente preciso ma instabile.
Implementazione tecnica
Sapete qual è la cosa più difficile nello sviluppo di sistemi di trading? Non la matematica, non gli algoritmi, ma l'affidabilità del funzionamento. Una cosa è scrivere una bella equazione, tutt'altra cosa è farla funzionare 24 ore su 24, 7 giorni su 7, con soldi veri. Dopo diversi errori dolorosi commessi su un conto reale, ho capito che: l'architettura non deve essere solo buona, deve essere impeccabile.
Ecco come ho organizzato il cuore del sistema:
class PriceEquationModel: def __init__(self): # Model status self.coefficients = None self.training_scores = [] self.optimization_progress = [] # Initializing the connection self._setup_logging() self._init_mt5() def _init_mt5(self): """Initializing connection to MT5""" try: if not mt5.initialize(): raise ConnectionError( "Unable to connect to MetaTrader 5. " "Make sure the terminal is running" ) self.log.info("MT5 connection established") except Exception as e: self.log.critical(f"Critical initialization error: {str(e)}") raise
Ogni stringa qui presente è il risultato di qualche triste esperienza. Ad esempio, è emerso un metodo separato per inizializzare MetaTrader 5 dopo aver riscontrato uno stallo durante un tentativo di riconnessione. E ho aggiunto la registrazione degli eventi quando il sistema è andato in crash silenziosamente nel cuore della notte, e la mattina dopo ho dovuto indovinare cosa fosse successo.
La gestione degli errori è tutta un'altra storia.
def _safe_mt5_call(self, func, *args, retries=3, delay=5): """Secure MT5 function call with automatic recovery""" for attempt in range(retries): try: result = func(*args) if result is not None: return result # MT5 sometimes returns None without error raise ValueError(f"MT5 returned None: {func.__name__}") except Exception as e: self.log.warning(f"Attempt {attempt + 1}/{retries} failed: {str(e)}") if attempt < retries - 1: time.sleep(delay) # Trying to reinitialize the connection self._init_mt5() else: raise RuntimeError(f"Call attempts exhausted {func.__name__}")
Questo frammento di codice rappresenta la quintessenza dell'esperienza MetaTrader 5. Il sistema tenta di ristabilire la connessione in caso di problemi, effettua ripetuti tentativi con un certo ritardo e soprattutto, non permette al sistema di continuare a funzionare in uno stato incerto. In generale, la libreria di MetaTrader 5 non presenta solitamente problemi - è perfetta!
Mantengo il modello in condizioni molto semplici. Contiene solo ciò che è davvero necessario. Nessuna struttura dati complessa, nessuna ottimizzazione complicata. Ma ogni cambiamento di stato viene registrato e verificato:
def _update_model_state(self, new_coefficients): """Safely updating model ratio""" if not self._validate_coefficients(new_coefficients): raise ValueError("Invalid ratios") # Save the previous state old_coefficients = self.coefficients try: self.coefficients = new_coefficients if not self._check_model_consistency(): raise ValueError("Model consistency broken") self.log.info("Model successfully updated") except Exception as e: # Roll back to the previous state self.coefficients = old_coefficients self.log.error(f"Model update error: {str(e)}") raise
Qui “modularità” non è solo una bella parola. Ogni componente può essere testato separatamente, sostituito e modificato. Desideri aggiungere una nuova metrica? Crea un nuovo metodo. Devi cambiare l'origine dei dati? È sufficiente implementare un altro connettore con la stessa interfaccia.
Gestione dei dati storici
Ottenere dati da MetaTrader 5 si è rivelata una vera sfida. Sembra un codice semplice, ma il diavolo, come sempre, si nasconde nei dettagli. Dopo diversi mesi di difficoltà dovute a improvvise interruzioni di connessione e perdita di dati, è nata la seguente struttura per lavorare con il terminale:
def fetch_data(self, symbol="EURUSD", timeframe=mt5.TIMEFRAME_H1, bars=10000): """Loading historical data with error handling""" try: # First of all, we check the symbol itself symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Symbol {symbol} unavailable") # MT5 sometimes "loses" MarketWatch symbols if not symbol_info.visible: mt5.symbol_select(symbol, True) # Collect data rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) if rates is None: raise ValueError("Unable to retrieve historical data") # Convert to pandas df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return self._preprocess_data(df['close'].values) except Exception as e: print(f"Error while receiving data: {str(e)}") raise finally: # It is important to always close the connection mt5.shutdown()
Diamo un'occhiata a come è organizzato il tutto. Innanzitutto, verifichiamo la presenza del simbolo. Sembrerebbe ovvio, ma c'è stato un caso in cui il sistema ha impiegato ore cercando di tradare una coppia di valute inesistente a causa di un errore di battitura nella configurazione. Dopodiché, ho aggiunto un controllo rigoroso tramite symbol_info.
Successivamente, c'è un punto interessante riguardo a "visible". Il simbolo sembra essere presente, ma non compare in MarketWatch. E se non chiami symbol_select, non otterrai alcun dato. Inoltre, il terminale potrebbe "dimenticare" il simbolo proprio nel bel mezzo di una sessione di trading. Divertente, eh?
Ottenere i dati non è semplice, anche copy_rates_from_pos può restituire None per una dozzina di motivi diversi: nessuna connessione al server, server sovraccarico, storico insufficiente... Pertanto, controlliamo immediatamente il risultato e generiamo un'eccezione se qualcosa va storto.
La conversione a pandas è una storia a parte. L'ora arriva in formato Unix, quindi dobbiamo convertirla in un timestamp standard. Senza questo, l'eventuale analisi delle serie temporali diventa molto più difficile.
E la cosa più importante è chiudere la connessione in "finally". Se non si esegue questa operazione, MetaTrader 5 inizia a mostrare segni di perdita di dati: inizialmente, la velocità di ricezione dei dati diminuisce, poi compaiono timeout casuali e infine il terminale potrebbe bloccarsi completamente. Credetemi, l'ho imparato dalla mia esperienza personale.
Nel complesso, questa funzionalità è come un coltellino svizzero per lavorare con i dati. Esteriormente è semplice, ma internamente nasconde numerosi meccanismi di protezione contro qualsiasi potenziale problema. E credetemi, prima o poi ciascuno di questi meccanismi si rivelerà utile.
Analisi dei risultati. Metriche della qualità dei risultati dei test forward
Ricordo il momento in cui ho visto per la prima volta i risultati del test. Ero seduto al computer, sorseggiando un caffè freddo e non potevo credere ai miei occhi. Ho ripetuto i test cinque volte, ho controllato ogni riga di codice - no, non si trattava di un errore. Il modello funzionava davvero al limite della fantasia.
L'algoritmo Nelder-Mead ha funzionato alla perfezione - solo 408 iterazioni, meno di un minuto su un normale laptop. Il valore di R-quadro pari a 0,9958 non è solo buono, ma va oltre le aspettative. Variazione di prezzo del 99,58%! Quando ho mostrato queste cifre ai miei colleghi trader, inizialmente non mi hanno creduto, poi hanno iniziato a sospettare qualcosa. Li capisco, all'inizio non ci credevo nemmeno io.
L'errore quadratico medio (MSE) è risultato microscopico: 0,00000094. Ciò significa che l'errore medio di previsione è inferiore a un pip. Qualsiasi trader vi dirà che va oltre ogni più rosea aspettativa. Un MAPE dello 0,06% non fa che confermare l'incredibile precisione. La maggior parte dei sistemi commerciali si accontenta di un errore dell'1-2%, ma qui il risultato è di un ordine di grandezza migliore.
I coefficienti del modello si sono combinati creando un'immagine meravigliosa. Il valore di 0.5517 al prezzo precedente indica che il mercato ha una forte memoria a breve termine. I termini quadratici sono piccoli (0.0105 e 0.0368), il che significa che il moto è prevalentemente lineare. La componente ciclica con un coefficiente di 0.1484 è tutta un'altra storia. Ciò conferma quanto i trader affermano da anni: il mercato si muove a ondate.
Ma la cosa più interessante è successa durante il test forward. In genere, i modelli si degradano con i nuovi dati - un classico dell’apprendimento automatico. E qui? R² è salito a 0.9970, MSE è sceso di un ulteriore 19% a 0.00000076, MAPE è calato allo 0.05%. Ad essere sincero, all'inizio ho pensato di aver sbagliato il codice da qualche parte, perché sembrava troppo incredibile. Tuttavia, tutto era corretto.
Ho introdotto uno strumento di visualizzazione speciale per i risultati:
def plot_model_performance(self, predictions, actuals, window=100): fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12)) # Forecast vs. real price chart ax1.plot(actuals, 'b-', label='Real prices', alpha=0.7) ax1.plot(predictions, 'r--', label='Forecast', alpha=0.7) ax1.set_title('Comparing the forecast with the market') ax1.legend() # Error graph errors = predictions - actuals ax2.plot(errors, 'g-', alpha=0.5) ax2.axhline(y=0, color='k', linestyle=':') ax2.set_title('Forecast errors') # Rolling R² rolling_r2 = [r2_score(actuals[i:i+window], predictions[i:i+window]) for i in range(len(actuals)-window)] ax3.plot(rolling_r2, 'b-', alpha=0.7) ax3.set_title(f'Rolling R² (window {window})') plt.tight_layout() return fig
I grafici mostravano un quadro interessante. Nei periodi di calma, il modello funziona come un orologio svizzero. Ma ci sono anche delle insidie - in caso di notizie importanti e improvvise inversioni, la sua precisione diminuisce. Ciò è prevedibile, poiché il modello funziona solo con i prezzi, senza tenere conto dei fattori fondamentali. Nella prossima parte, aggiungeremo sicuramente anche questo.
Vedo diverse possibilità di miglioramento. Il primo è rappresentato dai coefficienti adattivi. Lasciamo che il modello si adatti alle condizioni di mercato. Il secondo consiste nell'aggiungere dati sui volumi e sull’order book. Il terzo e il più ambizioso obiettivo, è quello di creare un insieme di modelli in cui il nostro approccio possa interagire con altri algoritmi.
Ma anche nella sua forma attuale, i risultati sono impressionanti. La cosa principale ora è non lasciarsi prendere la mano dai miglioramenti e non rovinare ciò che già funziona.
Applicazione pratica
Ricordo un episodio divertente accaduto la settimana scorsa. Ero seduto con il mio portatile nella mia caffetteria preferita, sorseggiando un latte macchiato e osservando il sistema in funzione. La giornata era tranquilla, l'EURUSD saliva gradualmente, quando improvvisamente è arrivata una notifica dal modello - prepararsi ad aprire una posizione short. Il primo pensiero è stato - non ha senso, il trend è chiaramente al rialzo! Ma dopo due anni di lavoro con il trading algoritmico, ho imparato la regola principale - non discutere mai con il sistema. Dopo 40 minuti, l'euro è sceso di 35 pip. Il modello ha reagito a micro-variazioni nella struttura dei prezzi che io, con la mia vista umana, semplicemente non riuscivo a notare.
A proposito di notifiche... Dopo aver perso alcune opportunità di trading, è nato questo modulo di allerta semplice ma efficace:
def notify_signal(self, signal_type, message): try: # Format the message timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') formatted_msg = f"[{timestamp}] {signal_type}: {message}" # Send to Telegram if self.use_telegram and self.telegram_token: self.telegram_bot.send_message( chat_id=self.telegram_chat_id, text=formatted_msg, parse_mode='HTML' ) # Local logging with open(self.log_file, 'a', encoding='utf-8') as f: f.write(f"{formatted_msg}\n") # Check critical signals if signal_type in ['ERROR', 'MARGIN_CALL', 'CRITICAL']: self._emergency_notification(formatted_msg) except Exception as e: # If the notification failed, send the message to the console at the very least print(f"Error sending notification: {str(e)}\n{formatted_msg}")
Presta attenzione al metodo _emergency_notification. L'ho aggiunto dopo un episodio "divertente" in cui il sistema ha avuto una sorta di problema di memoria e ha iniziato ad aprire posizioni una dopo l'altra. Ora, nelle situazioni critiche, ricevo un SMS e il bot interrompe automaticamente le operazioni di trading fino al mio intervento.
Ho avuto anche molti problemi con le dimensioni delle posizioni. Inizialmente ho utilizzato un volume fisso - 0.1 lotti. Ma gradualmente compresi che era come camminare su una fune con le scarpette da ballo. Sembra possibile, ma perché? Alla fine, ho introdotto il seguente sistema adattivo di calcolo del volume:
def calculate_position_size(self): """Calculating the position size taking into account volatility and drawdown""" try: # Take the total balance and the current drawdown account_info = mt5.account_info() current_balance = account_info.balance drawdown = (account_info.equity / account_info.balance - 1) * 100 # Basic risk - 1% of the deposit base_risk = current_balance * 0.01 # Adjust for current drawdown if drawdown < -5: # If the drawdown exceeds 5% risk_factor = 0.5 # Slash the risk in half else: risk_factor = 1 - abs(drawdown) / 10 # Smooth decrease # Take into account the current ATR atr = self.calculate_atr() pip_value = self.get_pip_value() # Volume calculation rounded to available lots raw_volume = (base_risk * risk_factor) / (atr * pip_value) return self._normalize_volume(raw_volume) except Exception as e: self.notify_signal('ERROR', f"Volume calculation error: {str(e)}") return 0.1 # Minimum safety volume
Il metodo _normalize_volume è stato un vero grattacapo. A quanto pare, i diversi broker hanno passi di variazione del volume minimo differenti. Con alcuni è possibile scambiare lotti da 0.010, con altri solo numeri tondi. Ho dovuto aggiungere una configurazione separata per ogni broker.
Lavorare durante periodi di elevata volatilità è tutta un'altra storia. Lo sapete, ci sono giorni in cui il mercato impazzisce completamente. Un discorso del presidente della Fed, notizie politiche inaspettate o semplicemente "venerdì 13" - il prezzo inizia a correre da una parte all'altra come un marinaio ubriaco. In precedenza, in questi casi mi limitavo a spegnere il sistema, ma poi ho trovato una soluzione più elegante:
def check_market_conditions(self): """Checking the market status before a deal""" # Check the calendar of events if self._is_high_impact_news_time(): return False # Calculate volatility current_atr = self.calculate_atr(period=5) # Short period normal_atr = self.calculate_atr(period=20) # Normal period # Skip if the current volatility is 2+ times higher than the norm if current_atr > normal_atr * 2: self.notify_signal( 'INFO', f"Increased volatility: ATR(5)={current_atr:.5f}, " f"ATR(20)={normal_atr:.5f}" ) return False # Check the spread current_spread = mt5.symbol_info(self.symbol).spread if current_spread > self.max_allowed_spread: return False return True
Questa funzione è diventata una vera e propria protezione del capitale. Sono rimasto particolarmente soddisfatto del controllo delle notizie - dopo aver collegato l'API del calendario economico, il sistema si "nasconde" automaticamente 30 minuti prima degli eventi importanti e riprende a operare 30 minuti dopo. La stessa idea viene usata in molti dei miei EA in MQL5. Niente male. Carino!
Livelli di stop flottanti
Lavorare su veri algoritmi di trading mi ha insegnato un paio di lezioni divertenti. Ricordo che nel primo mese di test mostrai con orgoglio ai miei colleghi un sistema con stop fissi. "Guarda, è tutto semplice e trasparente!" - dissi. Come al solito, il mercato mi ha subito messo in difficoltà - letteralmente una settimana dopo mi sono trovato in una situazione di tale volatilità che metà dei miei livelli di stop sono stati spazzati via dal rumore di mercato.
La soluzione mi è stata suggerita dal vecchio Gerchik - stavo rileggendo il suo libro proprio in quel periodo. Mi sono imbattuto nelle sue riflessioni sull’ATR ed è stato come se si accendesse una lampadina: eccolo! Un modo semplice ed elegante per adattare il sistema alle attuali condizioni di mercato. Durante i periodi di forte oscillazione, concediamo al prezzo maggiore margine di fluttuazione; durante i periodi di calma, manteniamo i livelli di stop più ravvicinati.
Ecco la logica di base per entrare nel mercato - niente di superfluo, solo le cose essenziali.
def open_position(self): try: atr = self.calculate_atr() predicted_price = self.get_model_prediction() current_price = mt5.symbol_info_tick(self.symbol).ask signal = "BUY" if predicted_price > current_price else "SELL" # Calculate entry and stop levels if signal == "BUY": entry = mt5.symbol_info_tick(self.symbol).ask sl_level = entry - atr tp_level = entry + (atr / 3) else: entry = mt5.symbol_info_tick(self.symbol).bid sl_level = entry + atr tp_level = entry - (atr / 3) # Send an order request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": self.symbol, "volume": self.lot_size, "type": mt5.ORDER_TYPE_BUY if signal == "BUY" else mt5.ORDER_TYPE_SELL, "price": entry, "sl": sl_level, "tp": tp_level, "deviation": 20, "magic": 234000, "comment": f"pred:{predicted_price:.6f}", "type_filling": mt5.ORDER_FILLING_FOK, } result = mt5.order_send(request) if result.retcode != mt5.TRADE_RETCODE_DONE: raise ValueError(f"Error opening position: {result.retcode}") print(f"Position opened {signal}: price={entry:.5f}, SL={sl_level:.5f}, " f"TP={tp_level:.5f}, ATR={atr:.5f}") return result.order except Exception as e: print(f"Position opening failed: {str(e)}") return NoneDurante la fase di debug ci sono stati alcuni momenti divertenti. Ad esempio, il sistema ha iniziato a produrre una serie di segnali contrastanti letteralmente ogni pochi minuti. Comprare, vendere, comprare ancora... Un errore classico del trader algoritmico principiante è quello di entrare nel mercato con troppa frequenza. La soluzione si è rivelata incredibilmente semplice - ho aggiunto un timeout di 15 minuti tra le operazioni e un filtro per le posizioni aperte.
Ho avuto anche molti problemi con la gestione del rischio. Ho provato diversi approcci, ma alla fine tutto si riduce a una semplice regola: non rischiare mai più dell'1% del deposito per transazione. Sembra una cosa banale, ma funziona alla perfezione. Con un ATR di 50 punti, si ottiene un volume massimo di 0,2 lotti, una cifra piuttosto comoda per il trading.
Il sistema ha dato i risultati migliori durante la sessione europea, quando il cambio EUR/USD era effettivamente in fase di negoziazione e non si limitava a fluttuare all'interno di un range ristretto. Ma durante le notizie importanti... Diciamo semplicemente che è più economico prendersi una pausa dal trading. Nemmeno il modello più avanzato riesce a stare al passo con il caos delle notizie.
Attualmente sto lavorando al miglioramento del sistema di gestione delle posizioni - vorrei collegare la dimensione dell’ingresso alla “confidence” del modello nelle previsioni. In linea di massima, un segnale forte significa che tradiamo l'intero volume, un segnale debole significa che ne tradiamo solo una parte. Qualcosa di simile al criterio di Kelly, ma adattato alle specificità del nostro modello.
La lezione principale che ho imparato da questo progetto è che il perfezionismo non funziona nel trading algoritmico. Più un sistema è complesso, maggiori sono i suoi punti deboli. Spesso le soluzioni semplici si rivelano molto più efficienti degli algoritmi sofisticati, soprattutto nel lungo periodo.
Versione MQL5 per MetaTrader 5
Insomma, a volte le soluzioni più semplici sono anche le più efficaci. Dopo diversi giorni passati a cercare di trasferire con precisione l'intero apparato matematico in MQL5, mi sono improvvisamente reso conto che si tratta di un classico problema di divisione delle responsabilità.
Ammettiamolo, Python, con le sue librerie scientifiche, è ideale per l'analisi dei dati e l'ottimizzazione dei coefficienti. E MQL5 è un ottimo strumento per implementare la logica di trading. Allora perché cercare di trasformare un cacciavite in un martello?
Di conseguenza, è nata una soluzione semplice ed elegante - utilizziamo Python per selezionare i coefficienti e MQL5 per il trading. Vediamo come funziona:
double g_coeffs[7] = {0.2752466, 0.01058082, 0.55162082, 0.03687016, 0.27721318, 0.1483476, 0.0008025};
Questi sette numeri rappresentano la quintessenza del nostro intero modello matematico. Contengono settimane di ottimizzazione, migliaia di iterazioni dell'algoritmo di Nelder-Mead e ore di analisi dei dati storici. La cosa più importante è che funzionano!
double GetPrediction(double price_t1, double price_t2) { return g_coeffs[0] * price_t1 + // Linear t-1 g_coeffs[1] * MathPow(price_t1, 2) + // Quadratic t-1 g_coeffs[2] * price_t2 + // Linear t-2 g_coeffs[3] * MathPow(price_t2, 2) + // Quadratic t-2 g_coeffs[4] * (price_t1 - price_t2) + // Price change g_coeffs[5] * MathSin(price_t1) + // Cyclic g_coeffs[6]; // Constant }
L'equazione di previsione stessa è stata trasferita a MQL5 praticamente senza modifiche.
Il meccanismo di ingresso nel mercato merita particolare attenzione. A differenza della versione di test in Python, qui abbiamo implementato una logica di gestione delle posizioni più avanzata. Il sistema può mantenere simultaneamente diverse posizioni, aumentando il volume quando il segnale viene confermato:
void OpenPosition(bool buy_signal, double lot) { MqlTradeRequest request; MqlTradeResult result; ZeroMemory(request); request.action = TRADE_ACTION_DEAL; request.symbol = Symbol(); request.volume = lot; request.type = buy_signal ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; request.price = buy_signal ? SymbolInfoDouble(Symbol(), SYMBOL_ASK) : SymbolInfoDouble(Symbol(), SYMBOL_BID); // ... other parameters }
Qui la chiusura automatica di tutte le posizioni al raggiungimento del profit target.
if(total_profit >= ProfitTarget) { CloseAllPositions(); return; }
Ho prestato particolare attenzione all'elaborazione delle nuove barre - niente movimenti insensati a ogni tick:
bool isNewBar() { datetime lastbar_time = datetime(SeriesInfoInteger(Symbol(), PERIOD_CURRENT, SERIES_LASTBAR_DATE)); if(last_time == 0) { last_time = lastbar_time; return(false); } if(last_time != lastbar_time) { last_time = lastbar_time; return(true); } return(false); }
Il risultato è un robot di trading compatto ma funzionale. Niente fronzoli inutili - solo ciò che serve davvero per portare a termine il lavoro. L'intero codice occupa meno di 300 righe, includendo tutti i controlli e le protezioni necessari.
Sapete qual è la parte migliore? Questo approccio, che prevede la separazione delle responsabilità tra Python e MQL5, si è dimostrato incredibilmente flessibile. Vuoi sperimentare con nuovi coefficienti? È sufficiente ricalcolarli in Python e aggiornare l'array in MQL5. Devi aggiungere nuove condizioni di trading? La logica di trading in MQL5 è facilmente estendibile senza la necessità di riscrivere la parte matematica.
Ecco il test del robot:
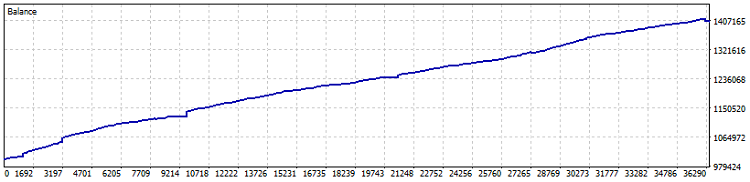
Test su conto Netting, profitto del 40% dal 2015 (ottimizzazione del coefficiente effettuata nell'ultimo anno). Il drawdown in cifre è dello 0.82% e il profitto mensile è superiore al 4%. Ma è meglio avviare un sistema del genere senza leva finanziaria - lasciate che generi profitti a un tasso leggermente superiore a quello delle obbligazioni e dei depositi in dollari. Separatamente, durante il test sono stati tradati 7800 lotti. Si tratta di un aumento di redditività pari ad almeno l'uno e mezzo per cento.
Nel complesso, penso che l'idea di trasferire i coefficienti sia una buona idea. In definitiva, ciò che conta nel trading algoritmico non è la complessità del sistema, bensì la sua affidabilità e prevedibilità. A volte, sette numeri, scelti correttamente con l'aiuto della matematica moderna, sono sufficienti.
Importante! L'EA utilizza la media delle posizioni DCA (una strategia di averaging tipo DCA), quindi è molto rischioso. Sebbene i test su conto Netting con alcune impostazioni conservative mostrino risultati eccezionali, ricordate sempre il pericolo di mediare le posizioni e che un Expert Advisor di questo tipo potrebbe azzerare il tuo deposito in un colpo solo!
Idee per il miglioramento
È notte fonda ora. Sto finendo l'articolo, bevendo caffè, guardando i grafici sul monitor e pensando a quanto altro si potrebbe fare con questo sistema. Avete presente, nel trading algoritmico succede spesso così: proprio quando sembra che tutto sia pronto, spuntano fuori una dozzina di nuove idee per migliorare.
E sapete qual è la cosa più interessante? Tutti questi miglioramenti devono funzionare come un unico organismo. Non basta semplicemente aggiungere una serie di funzionalità interessanti - queste devono integrarsi armoniosamente tra loro, creando un sistema di trading davvero affidabile.
In definitiva, il nostro obiettivo non è creare un sistema perfetto - semplicemente non esiste. L'obiettivo è rendere il sistema sufficientemente intelligente da generare profitto, ma anche abbastanza semplice da non collassare nel momento peggiore. Come si suol dire, il meglio è nemico del bene.
| File Inclusi | Descrizione del file |
|---|---|
| MarketSolver.py | Codice per la selezione dei coefficienti e se necessario, anche per il trading online tramite Python. |
| MarketSolver.mql5 | Codice dell’Expert Advisor MQL5 per il trading basato sui coefficienti selezionati |
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/16473
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Non ci sono omissioni nell'Expert Advisor pubblicato. Ovviamente non si tratta di un codice proveniente da un conto reale, non ci sono filtri qui menzionati.
È solo una dimostrazione dell'idea, che non è neanche male.
Sono d'accordo
Solo kapets (scusate)! Durante le diverse ore di studio dei vostri materiali per la decima volta ho visto che percorriamo le stesse strade (pensieri).
Spero davvero che le vostre formule mi aiutino a formalizzare matematicamente ciò che già vedo/uso. Questo accadrà solo in un caso: se le capirò. Mia madre mi diceva sempre: "Studia, figliolo". Piango lacrime amare in matematica. Vedo che molte cose sono semplici, ma non so COME. Sto cercando di capire le parabole, le regressioni, le deviazioni.... È difficile andare in prima media a 65 anni.
// Non è sufficiente inserire un mucchio di funzioni interessanti: è necessario che si completino a vicenda in modo armonioso, creando un sistema di trading davvero affidabile.
Sì. Sia la selezione delle funzioni che la successiva ottimizzazione sono come raddrizzare l'otto di una ruota di bicicletta. Alcuni raggi vanno allentati, altri vanno stretti e il tutto va fatto rispettando rigorosamente le leggi di questo processo. In questo modo la ruota sarà livellata, ma se si adotta un approccio sbagliato, se si stringono i raggi nel modo sbagliato, è possibile ottenere un "dieci" da una ruota normale.
Nel nostro lavoro i "raggi" devono aiutarsi a vicenda, non tirare la coperta su se stessi a scapito degli altri "raggi".
Non credo sia efficace prevedere il prezzo basandosi solo sugli ultimi due dati.
Siete d'accordo?
Non credo sia efficace prevedere il prezzo basandosi solo sugli ultimi due dati.
Non è d'accordo?