Discussione sull’articolo "Modelli di regressione non lineare nei mercati finanziari"
Questo è molto strano:
Было несколько забавных моментов в процессе отладки. Например, система начала выдавать серию противоречивых сигналов буквально каждые несколько минут. Купить, продать, снова купить... Классическая ошибка начинающего алгоритмического трейдера — слишком частые входы в рынок. Решение оказалось до смешного простым — добавил таймаут в 15 минут между сделками и фильтр на открытые позиции.
Risulta che i segnali contraddittori del modello sono artificialmente assottigliati in modo casuale. E se il punto di inizio del trading condizionato viene spostato di 15 minuti, otterremo operazioni in altre direzioni nello stesso intervallo di tempo?
Mi piacciono i voli di fantasia, i tentativi di affrontare la creazione di TC da diverse angolazioni insolite :)
In realtà questo è il processo della creatività, che a volte porta alla comparsa di soluzioni ingegnose.


Le previsioni stesse sembrano piuttosto a breve termine:
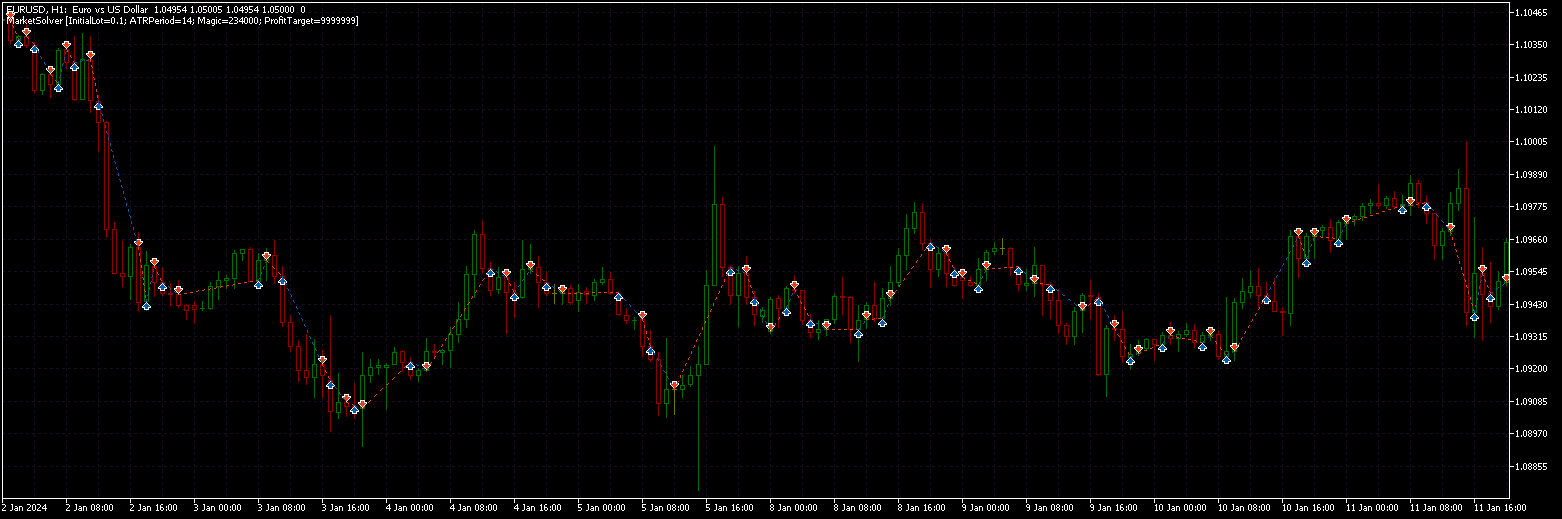
L'EA modificato è allegato (versione tester). La chiusura sul profitto è disabilitata dal parametro.
Un'altra cosa che mi ha colpito è il segnale asimmetrico (previsione >= ask -- comprare, previsione < ask (perché non bid?) -- vendere). Ma quando si mantiene una posizione per un'ora o più, probabilmente non è fondamentale.
Un'altra cosa che mi ha colpito è il segnale asimmetrico (previsione >= ask -- comprare, previsione < ask (perché non bid?) -- vendere). Ma quando si mantiene una posizione per un'ora o più, probabilmente non è fondamentale.
Avete trovato la risposta alla domanda?
Questo è il punto più importante di ogni TS, non si possono perdere i segnali, altrimenti l'intera logica crolla, o non è così in questo caso?
Forum sul trading, sui sistemi di trading automatico e sulla verifica delle strategie di trading.
Discussione dell'articolo "Modelli di regressione non lineare in borsa".
Stanislav Korotky, 2024.11.27 19:05
Questo è molto strano:
Risulta che i segnali contraddittori del modello sono artificialmente assottigliati in modo casuale. E se il punto di inizio del trading condizionale viene spostato di 15 minuti, avremo scambi in altre direzioni nello stesso intervallo di tempo?
L'articolo è interessante perché mostra chiaramente come siano necessarie poche variabili per descrivere la storia del movimento dei prezzi con una precisione sufficiente a generare profitti nel tester.
Non capisco, il testo parla di sovra-ottimizzazioni regolari, ma suggerisce un grafico con valori fissi. Oppure i coefficienti sono selezionati con una certa frequenza di finestra e memorizzati in un array multidimensionale? Non ho analizzato il codice.
Avete provato a utilizzare altri metodi per ottimizzare la formula? Andrei Dick li sta studiando a fondo, forse uno degli algoritmi da lui descritti vi permetterà di abbandonare del tutto python?
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Il nuovo articolo Modelli di regressione non lineare nei mercati finanziari è stato pubblicato:
Ho passato gli ultimi tre anni cercando di creare qualcosa che funzionasse davvero. Ho provato molte cose, dalle regressioni più semplici alle reti neurali più sofisticate. E sapete una cosa? Sono riuscito ad ottenere risultati nella classificazione, ma non ancora nella regressione.
Era sempre la stessa storia: nello storico tutto funziona alla perfezione,ma quando lo rilascio sul mercato reale, mi trovo ad affrontare delle perdite. Ricordo quanto fossi entusiasta della mia prima rete neurale convoluzionale. R² dell’1,00% sul set di training. A ciò hanno fatto seguito due settimane di trading, con una perdita del 30% del deposito. Il classico esempio di overfitting nella sua forma migliore. Ho continuato a osservare l'andamento delle previsioni basate sulla regressione, vedendo come, col passare del tempo, si allontanassero sempre più dai prezzi reali...
Ma io sono una persona testarda. Dopo un'altra perdita, ho deciso di approfondire la questione e ho iniziato a esaminare articoli scientifici. E sapete cosa ho scovato in quegli archivi impolverati? A quanto pare, il vecchio Mandelbrot già insisteva sulla natura frattale dei mercati. E tutti noi stiamo cercando di fare trading con modelli lineari! È come cercare di misurare la lunghezza di una costa con un righello: più si misura con precisione, più risulta lunga.
A un certo punto mi è venuta un'illuminazione: e se provassi a combinare l'analisi tecnica classica con le dinamiche non lineari? Non questi indicatori approssimativi, ma qualcosa di più serio - equazioni differenziali, coefficienti adattivi. Sembra complicato, ma in sostanza si tratta semplicemente di imparare a parlare la lingua del mercato.
In breve, ho preso Python, ho collegato le librerie di machine learning e ho iniziato a sperimentare. Ho deciso subito - niente fronzoli accademici, solo ciò che è realmente utile. Niente supercomputer - solo un normale portatile Acer, un VPS potentissimo e il terminale MetaTrader 5. Da tutto ciò è nato il modello di cui voglio parlarvi oggi.
Autore: Yevgeniy Koshtenko