
L'analyse des réseaux neuronaux volumétriques comme clé des tendances futures

À une époque où toutes les transactions de trading sont de plus en plus automatisées, il est utile de se souvenir des principes des traders d'antan. L'un d'eux affirme que le volume est la clé de tout. En effet, l'analyse technique et l'analyse des volumes seraient utiles et très intéressantes à intégrer comme caractéristiques dans l'apprentissage automatique. Peut-être qu'avec la bonne interprétation, cela nous donnera un résultat. Dans cet article, nous évaluerons l'approche d'analyse du volume des transactions et des caractéristiques basées sur le volume à l'aide de l'architecture LSTM.
Notre système analysera les anomalies de volume et prédira les mouvements de prix futurs. Les principales caractéristiques du système que je souhaite souligner sont la détection des volumes anormaux, le regroupement des volumes et l'entraînement du modèle directement via le bundle Python + MetaTrader 5.
Nous procéderons également à des backtests complets avec visualisation des résultats. Le modèle démontre une efficacité particulière sur l'échelle de temps horaire du marché boursier russe, ce que confirment les résultats des tests effectués sur les données historiques des actions de Sberbank au cours de l'année écoulée. Dans cet article, j'examinerai en détail l'architecture du système, les principes de son fonctionnement et les résultats pratiques de son application.
Décomposition du code : Des données aux prédictions
Approfondissons le sujet et essayons de créer un système qui permette de comprendre réellement ce qui se passe actuellement avec les volumes. Commençons par des choses simples : la manière dont nous recevons et traitons les données. D'un côté, rien de compliqué : télécharger les données et travailler... Mais comme toujours, le diable se cache dans les détails.
Source des données : creuser davantage
Vous trouverez ci-dessous notre fonction de chargement de données.
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"MT5 data request: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
Elle semble assez simple. J'utilise délibérément copy_rates_range au lieu du plus simple copy_rates_from. Nous en avons besoin pour ne pas perdre de périodes nulles lors de la manipulation d'instruments illiquides.
Par la suite, nous commençons à travailler avec des fonctionnalités et des indicateurs.
Prétraitement : L'art de la préparation des données
Ne perdons pas de temps à choisir les fonctionnalités, concentrons-nous plutôt sur quelques-unes des plus évidentes.
def preprocess_data(self, df): # Basic volume indicators df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # ML indicators df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
La sélection des fonctionnalités s'apparente à l'accordage d'un orchestre. Chaque fonctionnalité a son propre rôle et sa propre sonorité spécifique dans la symphonie des données. Examinons notre ensemble de base.
La première méthode est la plus simple : nous calculons une moyenne mobile du volume. Le volume moyen avec une période de 5 capte les fluctuations les plus infimes, tandis que la période de 20 réagit à des tendances de volume beaucoup plus marquées.
Le rapport entre le volume et sa moyenne pourrait également être intéressant. Lorsqu'une hausse brutale se profile à l'avenir, une forte impulsion de prix se produit très souvent.
Nous examinons également la dynamique des prix et des volumes sur les 24 dernières barres.
Il existe une caractéristique encore plus intéressante appelée volatilité des volumes. Je qualifierais cela d'indicateur de la nervosité des marchés. Une augmentation de la volatilité des volumes peut indiquer d'importantes injections de capitaux sur le marché de la part d'acteurs majeurs.
La corrélation entre le prix et le volume est également prise en compte par notre modèle. Au final, nous examinerons assurément tous ces signes en direct, en visualisant nos nouveaux indicateurs.
Goulot d'étranglement des performances
Pour éviter de surcharger le système, nous pouvons mettre en œuvre le traitement par lots des données et le calcul parallèle. Autrement dit, nous divisons les données en petits morceaux et les traitons en parallèle.
Cette technique simple accélère considérablement le traitement des données et permet également d'éviter les problèmes de fuites de mémoire sur de grands volumes de données.
Dans la prochaine partie de l'article, j'aborderai la partie la plus intéressante : comment le système détecte les volumes anormaux et ce qui se passe ensuite.
À la recherche des « cygnes noirs » : Comment reconnaître les volumes anormaux ?
Nous avons tous entendu parler de ce que sont les volumes anormaux et comment les visualiser sur un graphique. Un trader expérimenté pourrait sans doute les repérer. Mais comment intégrer cette expérience dans le code ? Comment formaliser la logique de recherche de tels volumes ?
À la recherche d'anomalies
Après une série d'expériences, mes recherches dans ce domaine se sont orientées vers la méthode de la forêt isolée. Pourquoi cette méthode ? Les méthodes classiques comme les scores z ou les scores percentiles peuvent passer à côté d'une anomalie locale, même minime, mais ce qui importe, ce ne sont pas les valeurs absolues ou en pourcentage, mais les volumes qui se démarquent des autres et qui sortent du contexte général.
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
Bien sûr, il serait préférable de jouer avec les paramètres, et une solution encore meilleure consisterait à sélectionner tous les paramètres du modèle à l'aide d'algorithmes comme le BGA. J'ai fixé la valeur à 0,05, la valeur recommandée dans les manuels, ce qui correspond à 5% d'anomalies. Mais le marché réel est beaucoup plus bruyant qu'on ne l'imagine. Par conséquent, la barre a été légèrement relevée. Il sera également utile de constater les anomalies par vous-même, en les regroupant avec les mouvements de prix (nous reviendrons sur ce sujet plus loin).
Regroupement : Trouver des modèles
Les anomalies ne suffisent pas à elles seules pour établir de bonnes prévisions. Nous avons également besoin d'un regroupement des volumes. Nous nous concentrerons sur l'option de regroupement suivante :
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
Les caractéristiques choisies pour le regroupement sont assez simples. Il me semblerait étrange de ne regrouper que les volumes eux-mêmes, sinon pourquoi créerions-nous nos caractéristiques et nos indicateurs ? Cependant, le nombre de fonctionnalités, ainsi que les indicateurs de volume, pourraient être améliorés.
Trois groupes ont été choisis car je diviserais conditionnellement tous les volumes en volumes de « fond ou d'accumulation », volumes de « course et de mouvement » et volumes de « mouvement extrême ».
Découvertes inattendues
Le traitement des données a permis de dégager plusieurs schémas et séquences ; par exemple, les volumes anormaux sont suivis d’un troisième groupe de volumes, puis vient le volume actif, et ce n’est qu’après cela que les valeurs évoluent dans une direction ou une autre.
Cela est particulièrement évident durant les premières heures suivant l'ouverture de la séance boursière. Il serait utile ici de créer une carte thermique des clusters et de leurs variations de prix associées.
Réseau de neurones : Comment entraîner une machine à lire le marché
Étant donné que j'utilise les réseaux neuronaux depuis longtemps, il serait raisonnable d'appliquer un réseau de neurones à notre analyse volumétrique. Je n'avais pas encore testé l'architecture LSTM, mais j'ai finalement décidé de l'essayer après avoir vu des exemples de cette architecture dans d'autres domaines.
Examinons cela de plus près.
Architecture : Moins, c'est plus
La simplicité est préférable. J'ai conçu une architecture étonnamment simple :
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
À première vue, l'architecture globale paraît très primitive, avec seulement deux couches LTSM et une couche linéaire. Mais le pouvoir réside dans la simplicité. Car, malheureusement, si nous construisons un réseau plus étendu avec un apprentissage plus profond, nous allons tomber dans le sur-apprentissage. Au départ, j'avais construit un réseau beaucoup plus complexe, avec trois couches LSTM, des couches entièrement connectées supplémentaires et une structure de dropout complexe. Les résultats étaient impressionnants... Sur des données de test. Mais dès que le réseau s'est confronté au véritable marché à long terme, tout s'est effondré. Autrement dit, nous avons observé un sur-apprentissage.
Lutte contre le sur-entraînement
Le sur-apprentissage est le plus gros problème des réseaux neuronaux modernes. Le réseau neuronal excelle à apprendre à trouver des relations dans des zones de données de test, mais il est complètement perdu dans les conditions réelles du marché. Voici comment je tente de résoudre ce problème spécifiquement dans l'architecture présentée :
- Une seule couche ne peut pas gérer la complexité de la relation entre le volume et le prix
- Trois couches peuvent trouver des connexions là où il n'y en a pas.
La taille de la couche cachée est choisie de manière standard : 64 neurones. Il serait peut-être préférable d'utiliser davantage de neurones. À l'avenir, lorsque je présenterai une solution fonctionnelle pour lutter contre le sur-apprentissage, nous pourrons utiliser une architecture plus complexe avec davantage de neurones.
Données d'entrée : L'art de la sélection des caractéristiques
Examinons les caractéristiques d'entrée pour l'entraînement :
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
Nous pouvons expérimenter beaucoup avec cet ensemble de fonctionnalités. Nous pouvons ajouter des indicateurs techniques, des dérivés de prix, des dérivés de volume, des dérivés de prix et de volume, tout ce que nous voulons. Mais n'oubliez pas que l'ajout de fonctionnalités n'améliorera pas toujours la qualité des prévisions. Et chaque caractéristique apparemment la plus logique peut en réalité s'avérer n'être qu'un simple bruit dans les données.
La combinaison de 'volume_cluster' et 'is_anomaly' semble intéressante ici. Prises individuellement, ces caractéristiques sont modestes, mais leur synergie les rend très intéressantes. Lorsque des volumes anormaux apparaissent dans certains groupes, cela a un effet inhabituel sur les prévisions.
Découverte inattendue
Le système s'est avéré le plus efficace durant les périodes de fortes variations de prix. Il se montre également très performant dans des moments que la plupart des traders qualifieraient d'imprévisibles, c'est-à-dire sur des marchés latéraux et pendant les phases de consolidation. C’est à ces moments-là que le système d’analyse des anomalies et des regroupements de volumes perçoit ce qui est inaccessible à notre vision.
Dans la section suivante, je parlerai des performances de ce système en situation réelle de trading et je partagerai des exemples précis de signaux.
Des prévisions aux transactions : Transformer les signaux en profits
Tout trader algorithmique le sait : un simple modèle de prévision ne suffit pas. Il faut le transformer en une stratégie de trading opérationnelle. Mais comment appliquer notre modèle en pratique ? Essayons de comprendre cela. Dans la prochaine partie de l'article, vous trouverez non seulement de la théorie aride, mais aussi de la pratique concrète, avec de véritables tests de trading, le renforcement de l'algorithme, l'amélioration de la lutte contre le sur-apprentissage. Mais pour l'instant, nous nous contenterons de la partie théorique habituelle de notre recherche.
Anatomie des signaux de trading
Lors de l'élaboration d'une stratégie de trading, l'un des points clés est la génération de signaux de trading. Dans ma stratégie, les signaux sont générés sur la base de prédictions de modèles qui reflètent le rendement attendu pour la période suivante.
def backtest_prediction_strategy(self, df, lookback=24): # Generating signals based on predictions df['signal'] = 0 signal_threshold = 0.001 # Threshold 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1
Sélection du seuil de signal
D'une part, on peut fixer le seuil simplement au-dessus de 0. Dans ce cas, nous générerons de nombreux signaux, mais ils seront bruités en raison de la dispersion, des commissions et du bruit du marché. Cette approche peut générer un grand nombre de faux signaux, ce qui nuira à l'efficacité de la stratégie.
Par conséquent, la décision la plus raisonnable semble être de relever le seuil de rentabilité prévisionnelle à 0,1% - 0,2%. Cela nous permet d'éliminer la majeure partie du bruit et de réduire l'impact des commissions, puisque les signaux ne seront générés que lorsqu'il y aura des variations de prix importantes prévues.
signal_threshold = 0.001 # Threshold 0.1%
Application des signaux en tenant compte du décalage
Une fois les signaux générés, ils sont appliqués aux prix en tenant compte d'un décalage de 24 périodes. Cela nous permet de prendre en compte le délai entre la prise d'une décision de trading et sa mise en œuvre.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Un décalage de 24 périodes signifie que le signal, généré au moment t , est appliqué au prix au moment t + 24 . C'est important car, en réalité, les décisions de trading ne peuvent pas être mises en œuvre instantanément. Cette approche permet une évaluation plus réaliste de l'efficacité de la stratégie de trading.
Calcul de la rentabilité de la stratégie
La rentabilité de la stratégie est calculée comme le produit du signal décalé et de la variation de prix :
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Si le signal est égal à 1. La rentabilité de la stratégie sera égale à la variation de prix (price_change). Si le signal est égal à -1, la rentabilité de la stratégie sera égale à la variation de prix négative (-price_change). Si le signal est égal à 0, la rentabilité de la stratégie sera nulle.
Ainsi, le décalage des signaux de 24 périodes nous permet de prendre en compte le délai entre la prise d'une décision de trading et sa mise en œuvre, ce qui rend l'évaluation de l'efficacité de la stratégie plus réaliste.
Juste milieu
Après des semaines de tests, j'ai opté pour un seuil de 0,1%. Voici pourquoi :
- À ce seuil, le système génère des signaux assez fréquemment
- Environ 52 à 63% des transactions sont rentables
- Le profit moyen par transaction est d'environ 2,5 fois la commission.
La découverte la plus surprenante est que la plupart des faux signaux peuvent également être concentrés dans des groupes de temps. Si vous le souhaitez, vous pouvez envisager un tel filtre temporel, et nous l'examinerons plus tard, dans la prochaine partie de l'article.
def apply_time_filter(self, df): # We trade only during active hours trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
Gestion des risques
La logique d'acquisition de positions et la logique de gestion des opérations en cours (soutien aux opérations pendant le trading) constituent une histoire distincte. D'une part, la solution la plus évidente consiste à utiliser des ordres stop et take fixes, mais le marché est trop imprévisible et dynamique pour que les limites de perte et de profit puissent être décrites par une logique formelle ordinaire.
Notre solution est assez simple : utiliser la volatilité prévue pour définir dynamiquement les stops :
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
Cette approche doit également être testée plus en profondeur. Il est également possible d'appliquer le modèle d'analyse des risques VaR pour sélectionner les stops et les take selon ce système ancien, mais toujours aussi efficace.
Découvertes inattendues
Un résultat intéressant est que des séries de signaux consécutifs peuvent prédire des mouvements très importants. Des problèmes surviennent également lorsque la volatilité moyenne du marché augmente très fortement, auquel cas notre seuil n'est plus suffisant pour un trading efficace. Si vous observez attentivement, les périodes de repli sur le graphique sont précisément associées à une forte volatilité... Mais pour nous, ce n'est pas un problème ! Nous allons résoudre et éliminer ce problème dans la section suivante.
Visualisation et journalisation : Comment éviter de se noyer sous les données
Il est également très important de ne pas oublier le système de journalisation. De manière générale, tout ce qui concerne les impressions, les journaux, les sorties et les commentaires du programme est essentiel lors de la phase de débogage. Vous pourrez ainsi trouver très rapidement et efficacement la source des problèmes dans votre code.
Système de journalisation : Les détails comptent
Le système de journalisation repose sur un format simple mais efficace :
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG)
Qu'y a-t-il de si difficile là-dedans, pourriez-vous demander ? J'ai découvert ce format après plusieurs expériences douloureuses où je ne comprenais pas pourquoi le système ouvrait une position à un moment précis.
Désormais, chaque action du système laisse une trace claire dans les journaux. Je veille également à consigner les moments liés à des volumes anormaux :
self.logger.info(f"Abnormal volume detected: {volume:.2f}") self.logger.debug(f"Context: cluster {cluster}, volatility {volatility:.4f}")
Nous avons également besoin de visualisation. L'expérience du trading manuel a laissé une forte habitude : celle de tout observer visuellement, d'analyser les données comme on analyse un graphique ordinaire. Voici notre code de visualisation :
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # Price and signal chart plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Price', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Buy')
Notre premier graphique est le graphique le plus courant des prix du Sber avec les signaux du modèle obtenus. Nous complétons également les signaux en mettant en évidence les bougies présentant des volumes anormaux. Cela nous aide à comprendre les moments où le système lit parfaitement le marché, comme un livre ouvert.
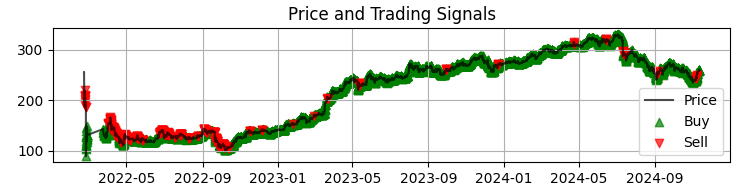
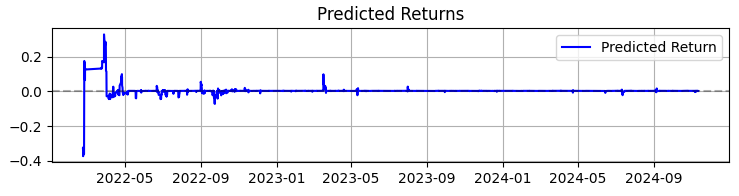
Le deuxième graphique représente le rendement prévu. On constate ici clairement qu'avant de forts mouvements des cours de l'actif choisi, une série de prévisions très fiables se met souvent en place. Cela suggère donc d'envisager la création d'un système basé uniquement sur cette observation. Bien sûr, le nombre de transactions va diminuer, mais nous ne recherchons pas la quantité, nous visons la qualité, n'est-ce pas ?
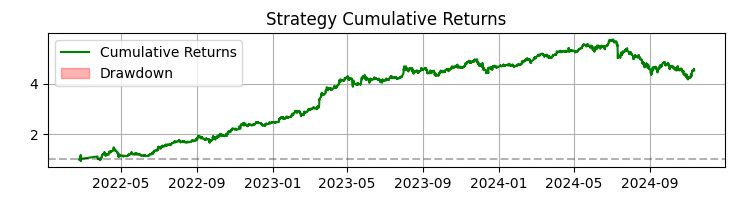
Le troisième graphique représente le rendement cumulé, les pertes étant mises en évidence.
De la théorie à la pratique : Résultats et perspectives
Résumons les résultats du fonctionnement du système : non pas de simples chiffres bruts, mais des découvertes qui peuvent aider tous ceux qui s’intéressent à l’analyse des volumes en trading.
Tout d'abord, le marché nous parle concrètement à travers le volume et le chiffre d'affaires des transactions. Mais ce langage est bien plus complexe que vous ne l'imaginez. À mon avis, les méthodes classiques comme le VSA deviennent rapidement obsolètes, ne parvenant pas à suivre le rythme du développement tout aussi rapide du marché. Les motifs deviennent plus complexes et les volumes forment des figures très compliquées, à peine visibles à l'œil nu.
Globalement, après près de 3 ans d'expérience dans l'apprentissage automatique, je peux seulement résumer brièvement que le marché devient de plus en plus complexe chaque année, et que les algorithmes qui y opèrent, en formant en partie des tendances et des accumulations grâce à leur OrderFlow, deviennent eux aussi plus complexes. La bataille des réseaux neuronaux nous attend – la bataille des machines pour le marché, qui déterminera quelle machine sera la plus efficace.
Pour résumer le travail effectué sur ce système, je souhaite partager non seulement les chiffres, mais aussi les principales découvertes qui peuvent être utiles à tous ceux qui travaillent dans le domaine de l'analyse volumique.
Sur une période de 365 jours concernant les actions SBER, le système a affiché des résultats impressionnants :
- Rendement total : 365,0% par an (sans effet de levier)
- Part des transactions rentables : 50,73%
Mais ces chiffres ne sont pas le plus important. Plus important encore, le système a démontré sa résilience face à diverses conditions de marché. Cela fonctionne tout aussi bien dans une tendance que dans un mouvement latéral, même si la nature des signaux change sensiblement.
Le comportement du système pendant les périodes de forte volatilité s'est avéré particulièrement intéressant. C’est précisément lorsque la plupart des traders préfèrent rester en dehors du marché que le réseau neuronal repère les tendances les plus claires dans les flux de volumes. C’est peut-être parce qu’à de tels moments, les acteurs institutionnels laissent des « traces » plus évidentes de leurs actions.
Ce que ce projet m'a appris- L'apprentissage automatique en trading n'est pas une solution miracle. Le succès ne s'obtient qu'avec une compréhension approfondie du marché et une conception soignée des fonctionnalités.
- La simplicité est la clé de la durabilité. Chaque fois que j'essayais de complexifier le modèle en ajoutant de nouvelles couches ou fonctionnalités, le système devenait de plus en plus fragile.
- Les volumes doivent être analysés dans leur contexte. Des volumes ou des regroupements anormaux, pris isolément, ne signifient pas grand-chose. La magie opère lorsque nous examinons leur interaction avec d'autres facteurs.
Quelle est la prochaine étape ?
Le système continue d'évoluer. Je travaille actuellement sur quelques améliorations :
- Ajustement adaptatif des paramètres en fonction de la phase du marché
- Intégration des ordres en flux continu pour une analyse plus précise
- Extension à d'autres instruments du marché russe
Le code source du système est disponible en pièces jointes. Je serais ravi de recevoir des suggestions d'amélioration. Il serait particulièrement intéressant d'entendre le témoignage de ceux qui tenteront d'adapter le système à d'autres outils.
Conclusion
En conclusion, je tiens à souligner que la découverte la plus précieuse de ces derniers mois a été pour moi l'adaptation des approches classiques, telles que l'analyse volumétrique dont nous avons parlé aujourd'hui, aux nouvelles technologies comme l'apprentissage automatique, les réseaux neuronaux et le big data.
Il s'avère que l'expérience des générations passées est bel et bien vivante. Notre tâche consiste à assimiler cette expérience, à la synthétiser et à l'améliorer du point de vue de notre génération de traders, en utilisant les technologies les plus récentes. Et bien sûr, nous ne pouvons pas rester à la traîne de l'ère moderne : l'apprentissage automatique quantique, les algorithmes quantiques de prévision des prix et des volumes, ainsi que les caractéristiques multidimensionnelles pour l'apprentissage automatique sont en avance sur nous. J'ai déjà tenté d'analyser le marché du superordinateur quantique 20 qubits d'IBM. Les résultats sont intéressants, je vous en parlerai certainement dans de futurs articles.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/16062
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.


- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation