
Trouver des modèles de paires de devises personnalisés en Python avec MetaTrader 5

Introduction à l'analyse des modèles Forex
Que voient les débutants lorsqu'ils consultent pour la première fois les graphiques des paires de devises ? De nombreuses fluctuations intra-journalières, des hausses et des baisses de la volatilité, des changements de tendance et bien d'autres choses encore. Montées, descentes, zigzags - comment s'y retrouver ? J'ai également commencé à me familiariser avec le Forex en me plongeant dans l'étude de l'analyse des modèles de prix.
Beaucoup de choses dans notre monde semblent chaotiques à première vue. Mais tout spécialiste expérimenté voit dans sa sphère personnelle des schémas et des possibilités qui semblent déroutants pour les autres. Il en va de même pour les graphiques des paires de devises. Si nous essayons de systématiser ce chaos, nous pouvons découvrir des modèles cachés qui peuvent suggérer l'évolution future des prix.
Mais comment les trouver ? Comment distinguer un motif réel d'un bruit aléatoire ? C'est ici que le plaisir commence. J'ai décidé de créer mon propre système d'analyse de modèles en utilisant Python et MetaTrader 5. Une sorte de symbiose entre les mathématiques et la programmation pour conquérir le Forex.
L'idée était d'étudier un grand nombre de données historiques à l'aide d'un algorithme qui trouverait des schémas répétitifs et évaluerait leur performance. Cela vous semble intéressant ? En réalité, la mise en œuvre s'est avérée moins simple.
Mise en place de l'environnement : installation des bibliothèques nécessaires et connexion à MetaTrader 5
Notre première tâche est donc d'installer Python. Il peut être téléchargé à partir du site officiel python.org. Veillez à cocher la case "Add Python to PATH".
L'étape suivante est celle des bibliothèques. Nous aurons besoin de quelques-unes d'entre elles. La principale est MetaTrader 5. Il y a aussi "pandas" pour travailler avec des données. Et peut-être "numpy". Ouvrez la ligne de commande et tapez
pip install MetaTrader5 pandas numpy matplotlib pytz
La première chose à faire est d'installer MetaTrader 5. Téléchargez-le sur le site officiel de votre courtier et installez-le. Rien de bien compliqué.
Nous devons maintenant trouver le chemin d'accès au terminal. En général, il s'agit de quelque chose comme "C:\Program Files\MetaTrader 5\terminal64.exe".
Ouvrez maintenant Python et tapez :
import MetaTrader5 as mt5 if not mt5.initialize(path="C:/Program Files/MetaTrader 5/terminal64.exe"): print("MetaTrader 5 initialization failed.") mt5.shutdown() else: print("MetaTrader 5 initialized successfully.")
Lancez la plateforme. Si le message d'initialisation du terminal s'affiche, c'est que tout s'est déroulé correctement.
Vous voulez vous assurer que tout fonctionne ? Essayons d'obtenir des données :
import MetaTrader5 as mt5 import pandas as pd from datetime import datetime if not mt5.initialize(): print("Oops! Something went wrong.") mt5.shutdown() eurusd_ticks = mt5.copy_ticks_from("EURUSD", datetime.now(), 10, mt5.COPY_TICKS_ALL) ticks_frame = pd.DataFrame(eurusd_ticks) print("Look at this beauty:") print(ticks_frame) mt5.shutdown()
Si vous voyez un tableau de données, félicitations ! Vous venez de faire vos premiers pas dans le monde du trading algorithmique sur le marché des changes en utilisant Python. Ce n'est pas aussi difficile qu'il n'y paraît.
Structure du code : Les fonctions de base et leur objectif
Commençons donc à analyser la structure du code. Il s'agit d'un système complet d'analyse des tendances du marché des changes.
Nous commencerons par l'élément principal du système - la fonction find_patterns. Cette fonction examine les données historiques et identifie les modèles d'une durée donnée. Après avoir trouvé les premiers modèles, nous devons évaluer leur efficacité. Cette fonction permet également de mémoriser le dernier motif pour une utilisation ultérieure.
La fonction suivante est calculate_winrate_and_frequency. Cette fonction analyse les modèles trouvés - il s'agit de la fréquence d'apparition et du taux de gain, ainsi que du tri des modèles.
La fonction process_currency_pair joue également un rôle important. Il s'agit d'un gestionnaire assez important. Elle charge les données, les examine, recherche des modèles de différentes longueurs et donne également les 300 meilleurs modèles de ventes et d'achats. Pour ce qui est du début du code, voici l'initialisation, le paramétrage, l'intervalle du graphique (TF) et la période de temps (dans mon cas, il s'agit de 1990 à 2024).
Passons maintenant à la boucle d'exécution du code principal. Les caractéristiques de l'algorithme de recherche de motifs comprennent différentes longueurs de motifs, car les motifs courts sont courants mais ne sont pas fiables, tandis que les motifs longs sont trop rares, bien qu'ils soient plus efficaces. Nous devons prendre en compte toutes les dimensions.
Obtenir des données de MetaTrader 5 : fonction copy_rates_range
Notre première fonction doit recevoir des données du terminal. Examinons le code :
import MetaTrader5 as mt5 import pandas as pd import time from datetime import datetime, timedelta import pytz # List of major currency pairs major_pairs = ['EURUSD'] # Setting up data request parameters timeframe = mt5.TIMEFRAME_H4 start_date = pd.Timestamp('1990-01-01') end_date = pd.Timestamp('2024-05-31') def process_currency_pair(symbol): max_retries = 5 retries = 0 while retries < max_retries: try: # Loading OHLC data rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) if rates is None: raise ValueError("No data received") ohlc_data = pd.DataFrame(rates) ohlc_data['time'] = pd.to_datetime(ohlc_data['time'], unit='s') break except Exception as e: print(f"Error loading data for {symbol}: {e}") retries += 1 time.sleep(2) # Wait before retrying if retries == max_retries: print(f"Failed to load data for {symbol} after {max_retries} attempts") return # Further data processing...
Que se passe-t-il dans ce code ? Tout d'abord, nous définissons nos paires de devises. Pour l'instant, nous n'avons que l'EURUSD, mais vous pouvez en ajouter d'autres. Nous définissons ensuite l'intervalle de temps. H4 est égal à 4 heures. C'est la période idéale.
Viennent ensuite les dates. De 1990 à 2024. Nous aurons besoin de nombreuses cotations historiques. Plus nous disposons de données, plus notre analyse est précise. Passons maintenant à l'essentiel : la fonction process_currency_pair. Elle charge les données à l'aide de copy_rates_range.
Qu'en résulte-t-il ? Un DataFrame avec des données historiques. Temps, ouverture, fermeture, haut, bas - tout ce qui est nécessaire au travail.
Si quelque chose ne va pas, les erreurs sont identifiées, affichées à l'écran et nous essayons à nouveau.
Traitement des séries chronologiques : Transformer les données OHLC en directions de mouvement de prix
Revenons à notre tâche principale. Nous voulons transformer les fluctuations chaotiques du marché Forex en quelque chose de plus ordonné - des tendances et des renversements. Comment procéder ? Nous transformerons les prix en directions.
Voici notre code :
# Fill missing values with the mean ohlc_data.fillna(ohlc_data.mean(), inplace=True) # Convert price movements to directions ohlc_data['direction'] = np.where(ohlc_data['close'].diff() > 0, 'up', 'down')
Que se passe-t-il ici ? Tout d'abord, nous comblons les lacunes. Les lacunes peuvent nuire considérablement au résultat final. Nous les remplissons avec des valeurs moyennes.
Et maintenant, la partie la plus intéressante. Nous créons une nouvelle colonne nommée "direction". Nous traduisons alors les données de prix en données qui simulent le comportement des tendances. Cela fonctionne de manière élémentaire :
- Si le prix de clôture actuel est plus élevé que le précédent, nous écrivons "up".
- S'il est en dessous, nous écrivons "down".
Une formulation simple, mais très efficace. Au lieu de nombres complexes, nous avons maintenant une simple séquence de "up" et de "down". Cette séquence est beaucoup plus facile à percevoir pour l'homme. Mais pourquoi en avons-nous besoin ? Ces "up" et "down" sont les éléments constitutifs de nos schémas. C'est auprès d'eux que nous obtiendrons une image complète de ce qui se passe sur le marché.
Algorithme de recherche de motifs : fonction find_patterns
Nous avons donc une séquence de "up" et de "down". Ensuite, nous rechercherons des motifs répétitifs dans cette séquence.
Voici la fonction find_patterns :
def find_patterns(data, pattern_length, direction): patterns = defaultdict(list) last_pattern = None last_winrate = None last_frequency = None for i in range(len(data) - pattern_length - 6): pattern = tuple(data['direction'][i:i+pattern_length]) if data['direction'][i+pattern_length+6] == direction: patterns[pattern].append(True) else: patterns[pattern].append(False) # Check last prices for pattern match last_pattern_tuple = tuple(data['direction'][-pattern_length:]) if last_pattern_tuple in patterns: last_winrate = np.mean(patterns[last_pattern_tuple]) * 100 last_frequency = len(patterns[last_pattern_tuple]) last_pattern = last_pattern_tuple return patterns, last_pattern, last_winrate, last_frequency
Comment cela fonctionne-t-il ?
- Nous créons le dictionnaire "patterns". Il s'agira d'une sorte de bibliothèque dans laquelle nous stockerons tous les modèles que nous trouverons.
- Ensuite, nous commençons à parcourir les données. Nous prenons un échantillon de données de la longueur du motif (qui peut être 3, 4, 5, etc. jusqu'à 25) et nous regardons ce qui se passe 6 barres après.
- Si, après 6 barres, le prix évolue dans la direction souhaitée (à la hausse pour les modèles d'achat ou à la baisse pour les modèles de vente), nous définissons True. Si ce n'est pas le cas, c'est False.
- Nous procédons ainsi pour tous les échantillons de données possibles. Nous devrions obtenir des schémas similaires : "up-up-down" - True, "down-up-up" - False et ainsi de suite.
- Ensuite, nous vérifions si l'un des modèles que nous avons rencontrés précédemment est en train de se former. Dans l'affirmative, nous calculons son taux de réussite (pourcentage d'occurrences réussies) et sa fréquence d'apparition.
C'est ainsi que nous transformons une simple séquence de "up" et de "down" en un outil de prévision assez puissant. Mais ce n'est pas tout. Ensuite, nous trierons ces modèles, sélectionnerons les plus efficaces et les analyserons.
Calcul des statistiques du modèle : WinRate et fréquence d'occurrence
Maintenant que nous disposons d'un certain nombre de modèles, nous devons sélectionner les meilleurs.
Jetons un coup d'œil à notre code :
def calculate_winrate_and_frequency(patterns): results = [] for pattern, outcomes in patterns.items(): winrate = np.mean(outcomes) * 100 frequency = len(outcomes) results.append((pattern, winrate, frequency)) results.sort(key=lambda x: x[1], reverse=True) return results
Nous prenons ici chaque modèle et ses résultats (nous les avons appelés précédemment True et False), puis nous calculons le taux de réussite - il s'agit de notre pourcentage de productivité. Si un modèle fonctionne 7 fois sur 10, son taux de réussite est de 70%. Nous comptons également la fréquence, c'est-à-dire le nombre de fois où le schéma s'est produit. Plus ils sont fréquents, plus nos statistiques sont fiables. Nous mettons tout cela dans la liste des "résultats". Et enfin, le tri. Nous plaçons les meilleurs modèles en tête de liste.
Tri des résultats : Sélection de modèles significatifs
Nous disposons maintenant de suffisamment de données. Mais nous n'aurons pas besoin de toutes. Nous devons faire le tri.
filtered_buy_results = [result for result in all_buy_results if result[2] > 20] filtered_sell_results = [result for result in all_sell_results if result[2] > 20] filtered_buy_results.sort(key=lambda x: x[1], reverse=True) top_300_buy_patterns = filtered_buy_results[:300] filtered_sell_results.sort(key=lambda x: x[1], reverse=True) top_300_sell_patterns = filtered_sell_results[:300]
Nous avons mis en place un système de tri similaire. Tout d'abord, nous trions tous les motifs qui apparaissent moins de 20 fois. Comme le montrent les statistiques, les modèles rares sont moins fiables.
Nous trions ensuite les modèles restants en fonction du taux de victoire. Les plus efficaces sont placés en début de liste. En conséquence, nous sélectionnons les 300 premiers. C'est tout ce qui devrait rester d'une multitude de motifs dont le nombre dépasse le millier.
Travailler avec différentes longueurs de motifs : de 3 à 25
Il s'agit maintenant de sélectionner les variations du modèle qui, statistiquement et régulièrement, produiront des bénéfices lors des transactions. Les options sont plus ou moins longues. Ils peuvent être constitués de 3 ou 25 mouvements de prix. Vérifions toutes les possibilités :
pattern_lengths = range(3, 25) # Pattern lengths from 3 to 25 all_buy_patterns = {} all_sell_patterns = {} for pattern_length in pattern_lengths: buy_patterns, last_buy_pattern, last_buy_winrate, last_buy_frequency = find_patterns(ohlc_data, pattern_length, 'up') sell_patterns, last_sell_pattern, last_sell_winrate, last_sell_frequency = find_patterns(ohlc_data, pattern_length, 'down') all_buy_patterns[pattern_length] = buy_patterns all_sell_patterns[pattern_length] = sell_patterns
Nous lançons notre filtre de recherche de motifs pour chaque longueur de 3 à 25. Pourquoi utiliser cette mise en œuvre ? Les motifs de moins de trois mouvements sont trop peu fiables - nous l'avons déjà mentionné. Les motifs de plus de 25 sont trop rares. Pour chaque longueur, nous recherchons des modèles d'achat et de vente.
Mais pourquoi avons-nous besoin de tant de longueurs différentes ? Les schémas courts permettent de saisir les retournements rapides du marché, alors que les schémas longs indiquent les tendances à long terme. Nous ne savons pas à l'avance ce qui sera le plus efficace, c'est pourquoi nous testons tout.
Analyse des schémas d'achat et de vente
Maintenant que nous disposons d'une sélection de motifs de différentes longueurs, il est temps de déterminer ceux qui fonctionnent réellement.
Voici notre code en action :
all_buy_results = [] for pattern_length, patterns in all_buy_patterns.items(): results = calculate_winrate_and_frequency(patterns) all_buy_results.extend(results) all_sell_results = [] for pattern_length, patterns in all_sell_patterns.items(): results = calculate_winrate_and_frequency(patterns) all_sell_results.extend(results)
Nous prenons tous les modèles - à l'achat comme à la vente - et les trions à l'aide de notre calculateur de taux de réussite et de fréquence.
Mais nous ne nous contentons pas de compter les statistiques. Nous recherchons la différence entre les schémas d'achat et de vente. Pourquoi est-ce important ? Parce que le marché peut se comporter différemment à la hausse et à la baisse. Parfois, les schémas d'achat fonctionnent mieux, alors que les schémas de vente deviennent plus fiables.
Ensuite, nous passerons à l'étape suivante en comparant des motifs de longueurs différentes entre eux. Il se peut que les schémas courts soient plus efficaces pour déterminer le point d'entrée sur le marché et que les schémas longs soient plus efficaces pour déterminer la tendance à long terme. La même chose peut se produire dans l'autre sens. C'est pourquoi nous analysons tout et n'écartons rien à l'avance.
À la fin de cette analyse, nous obtenons les premiers résultats : quels sont les schémas qui fonctionnent le mieux à l'achat, quels sont ceux qui fonctionnent le mieux à la vente, quelle est la longueur des schémas la plus efficace dans les différentes conditions du marché. Avec ces données, nous pouvons déjà effectuer une analyse des prix sur le marché Forex.
Mais n'oubliez pas que même le meilleur modèle n'est pas une garantie de succès. Le marché est plein de surprises. Notre tâche est d'augmenter les chances de succès, et c'est ce que nous faisons en analysant les modèles de tous les côtés.
Perspectives d'avenir : Prévisions basées sur des modèles récents
L'heure est venue de faire des prévisions. Jetons un coup d'œil au code de notre prédicteur :
if last_buy_pattern: print(f"\nLast buy pattern for {symbol}: {last_buy_pattern}, Winrate: {last_buy_winrate:.2f}%, Frequency: {last_buy_frequency}") print(f"Forecast: Price will likely go up.") if last_sell_pattern: print(f"\nLast sell pattern for {symbol}: {last_sell_pattern}, Winrate: {last_sell_winrate:.2f}%, Frequency: {last_sell_frequency}") print(f"Forecast: Price will likely go down.")
Nous regardons le dernier modèle qui s'est formé et essayons de prédire l'avenir et d'effectuer notre analyse de trading.
Veuillez noter que nous envisageons 2 scénarios : un schéma d'achat et un schéma de vente. Mais pourquoi ? Parce que le marché est un éternel affrontement entre haussiers et baissiers, entre acheteurs et vendeurs. Nous devons être prêts à faire face à toute éventualité.
Pour chaque motif, nous obtenons 3 paramètres clés : le motif lui-même, son taux de réussite et sa fréquence d'apparition. Le taux de réussite est particulièrement important. Si un schéma d'achat a un taux de réussite de 70%, cela signifie que 70% du temps après l'apparition de ce schéma, le prix a effectivement augmenté. Ces résultats sont plutôt bons. Mais n'oubliez pas que même 90% n'est pas une garantie. Le monde du Forex réserve toujours des surprises.
La fréquence joue également un rôle important. Un modèle fréquent est plus fiable qu'un modèle rare.
La partie la plus intéressante est notre prévision. "Le prix va probablement augmenter" ou "Le prix va probablement baisser". Ces prévisions permettent de tirer une certaine satisfaction du travail accompli. Mais n'oubliez pas que même la prévision la plus précise n'est qu'une probabilité, pas une garantie. Le marché du Forex est assez difficile à prévoir. Les nouvelles, les événements économiques, voire les tweets de personnes influentes peuvent modifier l'orientation du mouvement des prix en l'espace de quelques secondes.
Par conséquent, notre code n'est pas une panacée, mais plutôt une évaluation environnementale très intelligente. Il peut être interprété comme suit : "Regardez, sur la base des données historiques, nous avons des raisons de croire que le prix va augmenter (ou diminuer)". C'est à vous de décider si vous voulez entrer sur le marché ou non. L'application de ces prévisions est un processus réfléchi. Vous disposez d'informations sur les mouvements possibles, mais chaque étape doit encore être franchie avec sagesse, en tenant compte de la situation globale du marché.
Dessiner l'avenir : Visualiser les meilleurs modèles et prévisions
Ajoutons un peu de magie de visualisation à notre code :
import matplotlib.pyplot as plt def visualize_patterns(patterns, title, filename): patterns = patterns[:20] # Take top 20 for clarity patterns.reverse() # Reverse the list to display it correctly on the chart fig, ax = plt.subplots(figsize=(12, 8)) winrates = [p[1] for p in patterns] frequencies = [p[2] for p in patterns] labels = [' '.join(p[0]) for p in patterns] ax.barh(range(len(patterns)), winrates, align='center', color='skyblue', zorder=10) ax.set_yticks(range(len(patterns))) ax.set_yticklabels(labels) ax.invert_yaxis() # Invert the Y axis to display the best patterns on top ax.set_xlabel('Winrate (%)') ax.set_title(title) # Add occurrence frequency for i, v in enumerate(winrates): ax.text(v + 1, i, f'Freq: {frequencies[i]}', va='center') plt.tight_layout() plt.savefig(filename) plt.close() # Visualize top buy and sell patterns visualize_patterns(top_300_buy_patterns, f'Top 20 Buy Patterns for {symbol}', 'top_buy_patterns.png') visualize_patterns(top_300_sell_patterns, f'Top 20 Sell Patterns for {symbol}', 'top_sell_patterns.png') # Visualize the latest pattern and forecast def visualize_forecast(pattern, winrate, frequency, direction, symbol, filename): fig, ax = plt.subplots(figsize=(8, 6)) ax.bar(['Winrate'], [winrate], color='green' if direction == 'up' else 'red') ax.set_ylim(0, 100) ax.set_ylabel('Winrate (%)') ax.set_title(f'Forecast for {symbol}: Price will likely go {direction}') ax.text(0, winrate + 5, f'Pattern: {" ".join(pattern)}', ha='center') ax.text(0, winrate - 5, f'Frequency: {frequency}', ha='center') plt.tight_layout() plt.savefig(filename) plt.close() if last_buy_pattern: visualize_forecast(last_buy_pattern, last_buy_winrate, last_buy_frequency, 'up', symbol, 'buy_forecast.png') if last_sell_pattern: visualize_forecast(last_sell_pattern, last_sell_winrate, last_sell_frequency, 'down', symbol, 'sell_forecast.png')
Nous avons créé 2 fonctions : visualize_patterns et visualize_forecast. La première dessine un diagramme à barres horizontal informatif avec les 20 meilleurs modèles, leur taux de gain et leur fréquence d'apparition. Le second crée une représentation visuelle de nos prévisions basées sur le dernier modèle.
Pour les motifs, nous utilisons des colonnes horizontales parce que les motifs peuvent être longs et que cela les rend plus faciles à lire. Notre couleur est agréable à percevoir pour l'œil humain - le bleu ciel.
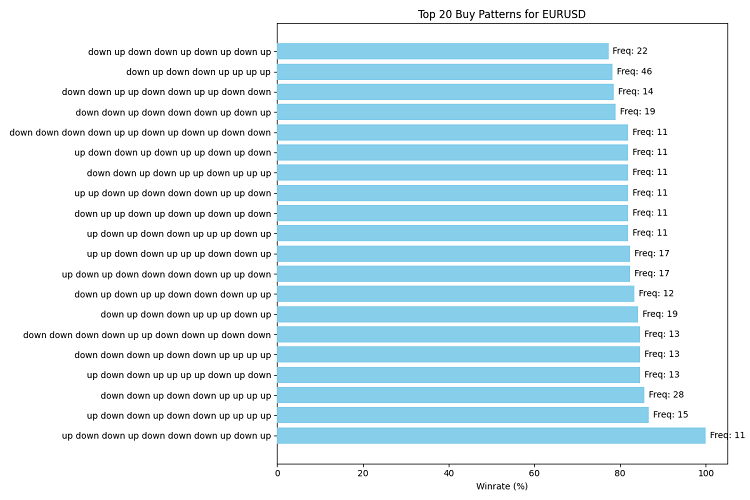
Nous sauvegardons nos chefs-d'œuvre dans des fichiers PNG.
Test et backtesting du système d'analyse des formes
Nous avons créé notre système d'analyse des modèles, mais comment savoir s'il fonctionne réellement ? Pour ce faire, nous devons le tester sur des données historiques.
Voici le code nécessaire à cette tâche :
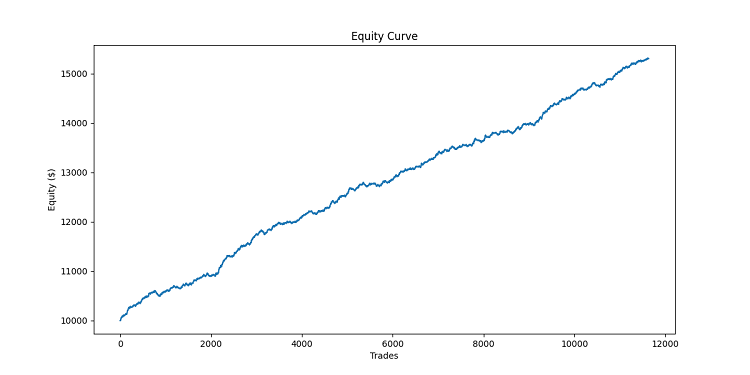
def simulate_trade(data, direction, entry_price, take_profit, stop_loss): for i, row in data.iterrows(): current_price = row['close'] if direction == "BUY": if current_price >= entry_price + take_profit: return {'profit': take_profit, 'duration': i} elif current_price <= entry_price - stop_loss: return {'profit': -stop_loss, 'duration': i} else: # SELL if current_price <= entry_price - take_profit: return {'profit': take_profit, 'duration': i} elif current_price >= entry_price + stop_loss: return {'profit': -stop_loss, 'duration': i} # If the loop ends without reaching TP or SL, close at the current price last_price = data['close'].iloc[-1] profit = (last_price - entry_price) if direction == "BUY" else (entry_price - last_price) return {'profit': profit, 'duration': len(data)} def backtest_pattern_system(data, buy_patterns, sell_patterns): equity_curve = [10000] # Initial capital $10,000 trades = [] for i in range(len(data) - max(len(p[0]) for p in buy_patterns + sell_patterns)): current_data = data.iloc[:i+1] last_pattern = tuple(current_data['direction'].iloc[-len(buy_patterns[0][0]):]) matching_buy = [p for p in buy_patterns if p[0] == last_pattern] matching_sell = [p for p in sell_patterns if p[0] == last_pattern] if matching_buy and not matching_sell: entry_price = current_data['close'].iloc[-1] take_profit = 0.001 # 10 pips stop_loss = 0.0005 # 5 pips trade_result = simulate_trade(data.iloc[i+1:], "BUY", entry_price, take_profit, stop_loss) trades.append(trade_result) equity_curve.append(equity_curve[-1] + trade_result['profit'] * 10000) # Multiply by 10000 to convert to USD elif matching_sell and not matching_buy: entry_price = current_data['close'].iloc[-1] take_profit = 0.001 # 10 pips stop_loss = 0.0005 # 5 pips trade_result = simulate_trade(data.iloc[i+1:], "SELL", entry_price, take_profit, stop_loss) trades.append(trade_result) equity_curve.append(equity_curve[-1] + trade_result['profit'] * 10000) # Multiply by 10000 to convert to USD else: equity_curve.append(equity_curve[-1]) return equity_curve, trades # Conduct a backtest equity_curve, trades = backtest_pattern_system(ohlc_data, top_300_buy_patterns, top_300_sell_patterns) # Visualizing backtest results plt.figure(figsize=(12, 6)) plt.plot(equity_curve) plt.title('Equity Curve') plt.xlabel('Trades') plt.ylabel('Equity ($)') plt.savefig('equity_curve.png') plt.close() # Calculating backtest statistics total_profit = equity_curve[-1] - equity_curve[0] win_rate = sum(1 for trade in trades if trade['profit'] > 0) / len(trades) if trades else 0 average_profit = sum(trade['profit'] for trade in trades) / len(trades) if trades else 0 print(f"\nBacktest Results:") print(f"Total Profit: ${total_profit:.2f}") print(f"Win Rate: {win_rate:.2%}") print(f"Average Profit per Trade: ${average_profit*10000:.2f}") print(f"Total Trades: {len(trades)}")
Que se passe-t-il ici ? La fonction simulate_trade est notre simulateur d'une transaction unique. Elle surveille le prix et ferme la transaction lorsque le take profit ou le stop loss est atteint.
backtest_pattern_system est une fonction plus importante. Elle parcourt les données historiques, étape par étape, jour par jour, en vérifiant si l'un de nos modèles s'est formé. Vous avez trouvé un modèle d'achat ? Ensuite, nous achetons. Vous en avez trouvé un à vendre ? Nous vendons.
Nous utilisons un take profit fixe de 100 points et un stop loss de 50 points. Nous devons fixer les limites d'un profit satisfaisant - pas trop pour ne pas risquer plus que la limite, mais suffisamment pour que le profit puisse croître.
Après chaque transaction, nous mettons à jour notre courbe d'équité. À la fin de notre travail, nous obtenons les résultats suivants : combien nous avons gagné au total, quel est le pourcentage de transactions rentables, quel est le bénéfice moyen par transaction. Et bien sûr, nous visualisons les résultats.
Mettons en œuvre la recherche de motifs en utilisant le langage MQL5. Voici notre code :
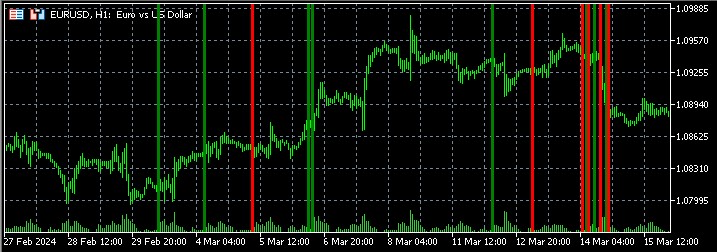
//+------------------------------------------------------------------+ //| PatternProbabilityIndicator| //| Copyright 2024 | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, Your Name Here" #property link "https://www.mql5.com" #property version "1.06" #property indicator_chart_window #property indicator_buffers 2 #property indicator_plots 2 //--- plot BuyProbability #property indicator_label1 "BuyProbability" #property indicator_type1 DRAW_LINE #property indicator_color1 clrGreen #property indicator_style1 STYLE_SOLID #property indicator_width1 2 //--- plot SellProbability #property indicator_label2 "SellProbability" #property indicator_type2 DRAW_LINE #property indicator_color2 clrRed #property indicator_style2 STYLE_SOLID #property indicator_width2 2 //--- input parameters input int InpPatternLength = 5; // Pattern Length (3-10) input int InpLookback = 1000; // Lookback Period (100-5000) input int InpForecastHorizon = 6; // Forecast Horizon (1-20) //--- indicator buffers double BuyProbabilityBuffer[]; double SellProbabilityBuffer[]; //--- global variables int g_pattern_length; int g_lookback; int g_forecast_horizon; string g_patterns[]; int g_pattern_count; int g_pattern_occurrences[]; int g_pattern_successes[]; int g_total_bars; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- validate inputs if(InpPatternLength < 3 || InpPatternLength > 10) { Print("Invalid Pattern Length. Must be between 3 and 10."); return INIT_PARAMETERS_INCORRECT; } if(InpLookback < 100 || InpLookback > 5000) { Print("Invalid Lookback Period. Must be between 100 and 5000."); return INIT_PARAMETERS_INCORRECT; } if(InpForecastHorizon < 1 || InpForecastHorizon > 20) { Print("Invalid Forecast Horizon. Must be between 1 and 20."); return INIT_PARAMETERS_INCORRECT; } //--- indicator buffers mapping SetIndexBuffer(0, BuyProbabilityBuffer, INDICATOR_DATA); SetIndexBuffer(1, SellProbabilityBuffer, INDICATOR_DATA); //--- set accuracy IndicatorSetInteger(INDICATOR_DIGITS, 2); //--- set global variables g_pattern_length = InpPatternLength; g_lookback = InpLookback; g_forecast_horizon = InpForecastHorizon; //--- generate all possible patterns if(!GeneratePatterns()) { Print("Failed to generate patterns."); return INIT_FAILED; } g_total_bars = iBars(_Symbol, PERIOD_CURRENT); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { //--- check for rates total if(rates_total <= g_lookback + g_pattern_length + g_forecast_horizon) { Print("Not enough data for calculation."); return 0; } int start = (prev_calculated > g_lookback + g_pattern_length + g_forecast_horizon) ? prev_calculated - 1 : g_lookback + g_pattern_length + g_forecast_horizon; if(ArraySize(g_pattern_occurrences) != g_pattern_count) { ArrayResize(g_pattern_occurrences, g_pattern_count); ArrayResize(g_pattern_successes, g_pattern_count); } ArrayInitialize(g_pattern_occurrences, 0); ArrayInitialize(g_pattern_successes, 0); // Pre-calculate patterns for efficiency string patterns[]; ArrayResize(patterns, rates_total); for(int i = g_pattern_length; i < rates_total; i++) { patterns[i] = ""; for(int j = 0; j < g_pattern_length; j++) { patterns[i] += (close[i-j] > close[i-j-1]) ? "U" : "D"; } } // Main calculation loop for(int i = start; i < rates_total; i++) { string current_pattern = patterns[i]; if(StringLen(current_pattern) != g_pattern_length) continue; double buy_probability = CalculateProbability(current_pattern, true, close, patterns, i); double sell_probability = CalculateProbability(current_pattern, false, close, patterns, i); BuyProbabilityBuffer[i] = buy_probability; SellProbabilityBuffer[i] = sell_probability; } // Update Comment with pattern statistics if total bars changed if(g_total_bars != iBars(_Symbol, PERIOD_CURRENT)) { g_total_bars = iBars(_Symbol, PERIOD_CURRENT); UpdatePatternStatistics(); } return(rates_total); } //+------------------------------------------------------------------+ //| Generate all possible patterns | //+------------------------------------------------------------------+ bool GeneratePatterns() { g_pattern_count = (int)MathPow(2, g_pattern_length); if(!ArrayResize(g_patterns, g_pattern_count)) { Print("Failed to resize g_patterns array."); return false; } for(int i = 0; i < g_pattern_count; i++) { string pattern = ""; for(int j = 0; j < g_pattern_length; j++) { pattern += ((i >> j) & 1) ? "U" : "D"; } g_patterns[i] = pattern; } return true; } //+------------------------------------------------------------------+ //| Calculate probability for a given pattern | //+------------------------------------------------------------------+ double CalculateProbability(const string &pattern, bool is_buy, const double &close[], const string &patterns[], int current_index) { if(StringLen(pattern) != g_pattern_length || current_index < g_lookback) { return 50.0; // Return neutral probability on error } int pattern_index = ArraySearch(g_patterns, pattern); if(pattern_index == -1) { return 50.0; } int total_occurrences = 0; int successful_predictions = 0; for(int i = g_lookback; i > g_pattern_length + g_forecast_horizon; i--) { int historical_index = current_index - i; if(historical_index < 0 || historical_index + g_pattern_length + g_forecast_horizon >= ArraySize(close)) { continue; } if(patterns[historical_index] == pattern) { total_occurrences++; g_pattern_occurrences[pattern_index]++; if(is_buy && close[historical_index + g_pattern_length + g_forecast_horizon] > close[historical_index + g_pattern_length]) { successful_predictions++; g_pattern_successes[pattern_index]++; } else if(!is_buy && close[historical_index + g_pattern_length + g_forecast_horizon] < close[historical_index + g_pattern_length]) { successful_predictions++; g_pattern_successes[pattern_index]++; } } } return (total_occurrences > 0) ? (double)successful_predictions / total_occurrences * 100 : 50; } //+------------------------------------------------------------------+ //| Update pattern statistics and display in Comment | //+------------------------------------------------------------------+ void UpdatePatternStatistics() { string comment = "Pattern Statistics:\n"; comment += "Pattern Length: " + IntegerToString(g_pattern_length) + "\n"; comment += "Lookback Period: " + IntegerToString(g_lookback) + "\n"; comment += "Forecast Horizon: " + IntegerToString(g_forecast_horizon) + "\n\n"; comment += "Top 5 Patterns:\n"; int sorted_indices[]; ArrayResize(sorted_indices, g_pattern_count); for(int i = 0; i < g_pattern_count; i++) sorted_indices[i] = i; // Use quick sort for better performance ArraySort(sorted_indices); for(int i = 0; i < 5 && i < g_pattern_count; i++) { int idx = sorted_indices[g_pattern_count - 1 - i]; // Reverse order for descending sort double win_rate = g_pattern_occurrences[idx] > 0 ? (double)g_pattern_successes[idx] / g_pattern_occurrences[idx] * 100 : 0; comment += g_patterns[idx] + ": " + "Occurrences: " + IntegerToString(g_pattern_occurrences[idx]) + ", " + "Win Rate: " + DoubleToString(win_rate, 2) + "%\n"; } Comment(comment); } //+------------------------------------------------------------------+ //| Custom function to search for a string in an array | //+------------------------------------------------------------------+ int ArraySearch(const string &arr[], string value) { for(int i = 0; i < ArraySize(arr); i++) { if(arr[i] == value) return i; } return -1; }
Voici comment cela se présente sur le graphique :
Création d'un EA pour la détection de modèles et le trading
Ensuite, j'ai vérifié les développements dans le testeur MetaTrader 5, car les tests en Python ont été concluants. Le code ci-dessous est également joint à l'article. Le code est une mise en œuvre pratique du concept d'analyse des modèles sur le marché des changes. Elle incarne l'idée que les modèles de prix historiques peuvent fournir des informations statistiquement significatives sur les mouvements futurs du marché.
Composants clés de l'EA :
- Génération de modèles : L'EA utilise une représentation binaire des mouvements de prix (à la hausse ou à la baisse), créant toutes les combinaisons possibles pour une longueur de schéma donnée.
- Analyse statistique : L'EA effectue une analyse rétrospective, évaluant la fréquence d'apparition de chaque modèle et son efficacité prédictive.
- Adaptation dynamique : L'EA met continuellement à jour les statistiques des modèles pour s'adapter aux conditions changeantes du marché.
- Prendre des décisions de trading : Sur la base des modèles d'achat et de vente les plus efficaces, l'EA ouvre, ferme ou maintient des positions.
- Paramétrage : L'EA permet de personnaliser les paramètres clés, tels que la longueur du modèle, la période d'analyse, l'horizon de prévision et le nombre minimum d'occurrences du modèle à prendre en compte.
Au total, j'ai créé 4 versions de l'EA : la première est basée sur le concept de l'article, elle ouvre des trades basés sur des modèles, et les ferme lorsqu'un nouveau modèle plus favorable dans la direction opposée est détecté. Le second est identique, mais il est multidevises : il fonctionne avec les 10 paires de devises les plus liquides, selon les statistiques de la Banque Mondiale. La troisième est identique, mais elle ferme les transactions lorsque le prix dépasse un nombre de barres supérieur à l'horizon de prévision. Le dernier est fermé par un take profit et un stop.
Voici le code pour le premier EA, le reste se trouve dans les fichiers joints :
//+------------------------------------------------------------------+ //| PatternProbabilityExpertAdvisor | //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/fr/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/fr/users/koshtenko" #property version "1.00" #include <Trade\Trade.mqh> // Include the CTrade trading class //--- input parameters input int InpPatternLength = 5; // Pattern Length (3-10) input int InpLookback = 1000; // Lookback Period (100-5000) input int InpForecastHorizon = 6; // Forecast Horizon (1-20) input double InpLotSize = 0.1; // Lot Size input int InpMinOccurrences = 30; // Minimum Pattern Occurrences //--- global variables int g_pattern_length; int g_lookback; int g_forecast_horizon; string g_patterns[]; int g_pattern_count; int g_pattern_occurrences[]; int g_pattern_successes[]; int g_total_bars; string g_best_buy_pattern = ""; string g_best_sell_pattern = ""; CTrade trade; // Use the CTrade trading class //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- validate inputs if(InpPatternLength < 3 || InpPatternLength > 10) { Print("Invalid Pattern Length. Must be between 3 and 10."); return INIT_PARAMETERS_INCORRECT; } if(InpLookback < 100 || InpLookback > 5000) { Print("Invalid Lookback Period. Must be between 100 and 5000."); return INIT_PARAMETERS_INCORRECT; } if(InpForecastHorizon < 1 || InpForecastHorizon > 20) { Print("Invalid Forecast Horizon. Must be between 1 and 20."); return INIT_PARAMETERS_INCORRECT; } //--- set global variables g_pattern_length = InpPatternLength; g_lookback = InpLookback; g_forecast_horizon = InpForecastHorizon; //--- generate all possible patterns if(!GeneratePatterns()) { Print("Failed to generate patterns."); return INIT_FAILED; } g_total_bars = iBars(_Symbol, PERIOD_CURRENT); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if(!IsNewBar()) return; UpdatePatternStatistics(); string current_pattern = GetCurrentPattern(); if(current_pattern == g_best_buy_pattern) { if(PositionSelect(_Symbol) && PositionGetInteger(POSITION_TYPE) == POSITION_TYPE_SELL) { trade.PositionClose(_Symbol); } if(!PositionSelect(_Symbol)) { trade.Buy(InpLotSize, _Symbol, 0, 0, 0, "Buy Pattern: " + current_pattern); } } else if(current_pattern == g_best_sell_pattern) { if(PositionSelect(_Symbol) && PositionGetInteger(POSITION_TYPE) == POSITION_TYPE_BUY) { trade.PositionClose(_Symbol); } if(!PositionSelect(_Symbol)) { trade.Sell(InpLotSize, _Symbol, 0, 0, 0, "Sell Pattern: " + current_pattern); } } } //+------------------------------------------------------------------+ //| Generate all possible patterns | //+------------------------------------------------------------------+ bool GeneratePatterns() { g_pattern_count = (int)MathPow(2, g_pattern_length); if(!ArrayResize(g_patterns, g_pattern_count)) { Print("Failed to resize g_patterns array."); return false; } for(int i = 0; i < g_pattern_count; i++) { string pattern = ""; for(int j = 0; j < g_pattern_length; j++) { pattern += ((i >> j) & 1) ? "U" : "D"; } g_patterns[i] = pattern; } return true; } //+------------------------------------------------------------------+ //| Update pattern statistics and find best patterns | //+------------------------------------------------------------------+ void UpdatePatternStatistics() { if(ArraySize(g_pattern_occurrences) != g_pattern_count) { ArrayResize(g_pattern_occurrences, g_pattern_count); ArrayResize(g_pattern_successes, g_pattern_count); } ArrayInitialize(g_pattern_occurrences, 0); ArrayInitialize(g_pattern_successes, 0); int total_bars = iBars(_Symbol, PERIOD_CURRENT); int start = total_bars - g_lookback; if(start < g_pattern_length + g_forecast_horizon) start = g_pattern_length + g_forecast_horizon; double close[]; ArraySetAsSeries(close, true); CopyClose(_Symbol, PERIOD_CURRENT, 0, total_bars, close); string patterns[]; ArrayResize(patterns, total_bars); ArraySetAsSeries(patterns, true); for(int i = 0; i < total_bars - g_pattern_length; i++) { patterns[i] = ""; for(int j = 0; j < g_pattern_length; j++) { patterns[i] += (close[i+j] > close[i+j+1]) ? "U" : "D"; } } for(int i = start; i >= g_pattern_length + g_forecast_horizon; i--) { string current_pattern = patterns[i]; int pattern_index = ArraySearch(g_patterns, current_pattern); if(pattern_index != -1) { g_pattern_occurrences[pattern_index]++; if(close[i-g_forecast_horizon] > close[i]) { g_pattern_successes[pattern_index]++; } } } double best_buy_win_rate = 0; double best_sell_win_rate = 0; for(int i = 0; i < g_pattern_count; i++) { if(g_pattern_occurrences[i] >= InpMinOccurrences) { double win_rate = (double)g_pattern_successes[i] / g_pattern_occurrences[i]; if(win_rate > best_buy_win_rate) { best_buy_win_rate = win_rate; g_best_buy_pattern = g_patterns[i]; } if((1 - win_rate) > best_sell_win_rate) { best_sell_win_rate = 1 - win_rate; g_best_sell_pattern = g_patterns[i]; } } } Print("Best Buy Pattern: ", g_best_buy_pattern, " (Win Rate: ", DoubleToString(best_buy_win_rate * 100, 2), "%)"); Print("Best Sell Pattern: ", g_best_sell_pattern, " (Win Rate: ", DoubleToString(best_sell_win_rate * 100, 2), "%)"); } //+------------------------------------------------------------------+ //| Get current price pattern | //+------------------------------------------------------------------+ string GetCurrentPattern() { double close[]; ArraySetAsSeries(close, true); CopyClose(_Symbol, PERIOD_CURRENT, 0, g_pattern_length + 1, close); string pattern = ""; for(int i = 0; i < g_pattern_length; i++) { pattern += (close[i] > close[i+1]) ? "U" : "D"; } return pattern; } //+------------------------------------------------------------------+ //| Custom function to search for a string in an array | //+------------------------------------------------------------------+ int ArraySearch(const string &arr[], string value) { for(int i = 0; i < ArraySize(arr); i++) { if(arr[i] == value) return i; } return -1; } //+------------------------------------------------------------------+ //| Check if it's a new bar | //+------------------------------------------------------------------+ bool IsNewBar() { static datetime last_time = 0; datetime current_time = iTime(_Symbol, PERIOD_CURRENT, 0); if(current_time != last_time) { last_time = current_time; return true; } return false; }
Quant aux résultats du test, les voici sur EURUSD :
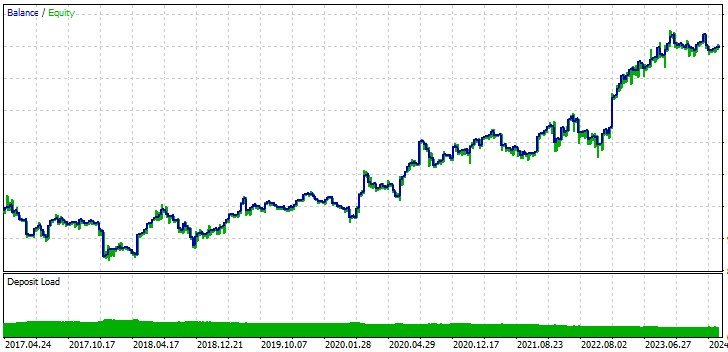
Et en détail :
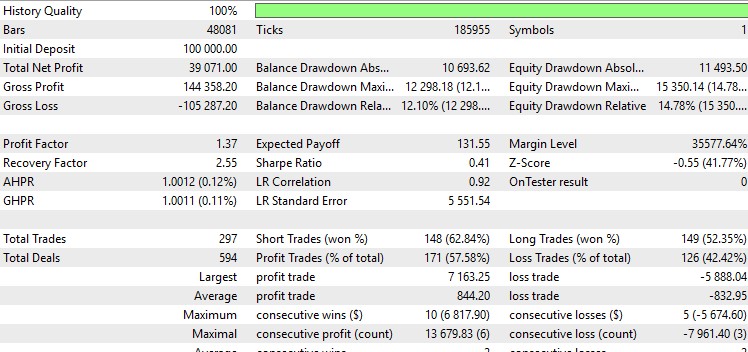
Pas mal, et les graphismes sont magnifiques. D'autres versions de l'EA se maintiennent autour de zéro ou subissent de longs drawdowns. La meilleure option ne correspond pas non plus tout à fait à mes critères. Je préfère les EA dont le facteur de profit est supérieur à 2 et le ratio de Sharpe supérieur à 1. Il m'est apparu que dans le testeur Python, il était nécessaire de prendre en compte à la fois la commission de trading, ainsi que le spread et le swap.
Améliorations possibles : Extension des périodes et ajout d'indicateurs
Poursuivons notre réflexion. Le système présente certes des résultats positifs, mais comment les améliorer et est-ce réaliste ?
Nous examinons maintenant l'horizon de 4 heures. Essayons de voir plus loin. Nous devrions ajouter un graphique journalier, hebdomadaire, voire mensuel. Grâce à cette approche, nous serons en mesure d'observer des tendances plus globales et des modèles à plus grande échelle. Développons le code pour couvrir toutes ces échelles de temps :
timeframes = [mt5.TIMEFRAME_H4, mt5.TIMEFRAME_D1, mt5.TIMEFRAME_W1, mt5.TIMEFRAME_MN1]
for tf in timeframes:
ohlc_data = get_ohlc_data(symbol, tf, start_date, end_date)
patterns = find_patterns(ohlc_data)
Plus de données, plus de bruit. Nous devons apprendre à trier ce bruit pour obtenir des données plus claires.
Élargissons l'éventail des caractéristiques analysées. Dans le monde du trading, il s'agit de l'ajout d'indicateurs techniques. Le RSI, le MACD et les bandes de Bollinger sont les outils les plus fréquemment utilisés.
def add_indicators(data): data['RSI'] = ta.RSI(data['close']) data['MACD'] = ta.MACD(data['close']).macd() data['BB_upper'], data['BB_middle'], data['BB_lower'] = ta.BBANDS(data['close']) return data ohlc_data = add_indicators(ohlc_data)
Les indicateurs peuvent nous aider à confirmer les signaux de nos modèles. Nous pouvons également rechercher des modèles sur les indicateurs.
Conclusion
Nous avons donc terminé notre travail sur la recherche et l'analyse de modèles. Nous avons créé un système qui recherche des modèles dans le chaos du marché. Nous avons appris à visualiser nos résultats, à réaliser des backtests, à planifier des améliorations futures. Mais surtout, nous avons appris à penser comme des traders analytiques. Nous ne nous contentons pas de suivre la foule, nous cherchons notre propre voie, nos propres modèles, nos propres possibilités.
N'oubliez pas que le marché est le produit de l'action de personnes vivantes. Il grandit et change. Et notre tâche est d'évoluer avec lui. Les modèles d'aujourd'hui ne fonctionneront peut-être plus demain, mais ce n'est pas une raison pour désespérer. C'est l'occasion d'apprendre, de s'adapter et de se développer. Utilisez ce système comme point de départ. Expérimentez, améliorez, créez le vôtre. Peut-être trouverez-vous ce modèle qui vous ouvrira les portes d'un trading fructueux !
Bonne chance à vous dans cette aventure passionnante ! Faites en sorte que vos modèles soient toujours rentables et que les pertes ne soient que des leçons sur le chemin de la réussite. A bientôt dans le monde du Forex !
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/15965
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Merci pour cet article, très pertinent