
Analyse de l'impact des conditions météorologiques sur les devises des pays agricoles à l'aide de Python

Introduction : Relation entre la météo et les marchés financiers
La théorie économique classique a longtemps ignoré l'influence des conditions météorologiques sur le comportement des marchés. Mais les recherches menées au cours des dernières décennies ont complètement bouleversé cette vision traditionnelle. Le professeur Edward Saykin de l'Université du Michigan, dans une étude menée en 2023, a démontré que les jours de pluie, les traders prennent des décisions 27% plus mesurées que les jours ensoleillés.
Cela est particulièrement visible dans les plus grands centres financiers. Les jours où les températures dépassent les 30°C, les volumes d'échanges à la Bourse de New York (NYSE) diminuent en moyenne d'environ 15%. Sur les marchés asiatiques, une pression atmosphérique inférieure à 740 mm Hg est corrélée à une volatilité accrue. Les longues périodes de mauvais temps à Londres entraînent une augmentation notable de la demande d'actifs refuges.
Dans cet article, nous commencerons par la collecte de données météorologiques et progresserons jusqu'à la création d'un système de trading complet qui analyse les facteurs météorologiques. Notre travail s'appuie sur des données de transactions réelles des cinq dernières années provenant des principaux centres financiers mondiaux : New York, Londres, Tokyo, Hong Kong et Francfort. Grâce à des outils d'analyse de données et d'apprentissage automatique de pointe, nous obtiendrons de véritables signaux de trading à partir des observations météorologiques.
Collecte de données météorologiques
L'un des facteurs les plus importants du système sera le module de réception et de prétraitement des données. Pour travailler avec les données météorologiques, nous utiliserons l'API Meteostat, qui donne accès à des données météorologiques archivées du monde entier. Examinons comment la fonction de récupération des données est implémentée :
def fetch_agriculture_weather(): """ Fetching weather data for important agricultural regions """ key_regions = { "AU_WheatBelt": { "lat": -31.95, "lon": 116.85, "description": "Key wheat production region in Australia" }, "NZ_Canterbury": { "lat": -43.53, "lon": 172.63, "description": "Main dairy production region in New Zealand" }, "CA_Prairies": { "lat": 50.45, "lon": -104.61, "description": "Canada's breadbasket, wheat and canola production" } }
Dans cette fonction, nous identifierons les régions agricoles les plus importantes ainsi que leurs coordonnées géographiques. Pour la ceinture céréalière australienne, les coordonnées sont celles de la partie centrale de la région, pour la Nouvelle-Zélande, les coordonnées sont celles de Canterbury et pour le Canada, les coordonnées sont celles de la région centrale des prairies.
Une fois les données brutes reçues, elles doivent être traitées sérieusement. La fonction process_weather_data est implémentée pour cela :
def process_weather_data(raw_data): if not isinstance(raw_data.index, pd.DatetimeIndex): raw_data.index = pd.to_datetime(raw_data.index) processed_data = pd.DataFrame(index=raw_data.index) processed_data['temperature'] = raw_data['tavg'] processed_data['temp_min'] = raw_data['tmin'] processed_data['temp_max'] = raw_data['tmax'] processed_data['precipitation'] = raw_data['prcp'] processed_data['wind_speed'] = raw_data['wspd'] processed_data['growing_degree_days'] = calculate_gdd( processed_data['temp_max'], base_temp=10 ) return processed_data
Il est également nécessaire de prêter attention au calcul de l'indicateur GrowingDegreeDays (GDD), qui sera un indicateur nécessaire pour évaluer le potentiel de croissance des cultures agricoles. Ce chiffre est calculé à partir de la température maximale enregistrée durant la journée, en tenant compte de la température normale de croissance des plantes.
def analyze_and_visualize_correlations(merged_data): plt.style.use('default') plt.rcParams['figure.figsize'] = [15, 10] plt.rcParams['axes.grid'] = True # Weather-price correlation analysis for each region for region, data in merged_data.items(): if data.empty: continue weather_cols = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_cols = ['close', 'volatility', 'range_pct', 'price_momentum', 'monthly_change'] correlation_matrix = pd.DataFrame() for w_col in weather_cols: if w_col not in data.columns: continue for p_col in price_cols: if p_col not in data.columns: continue correlations = [] lags = [0, 5, 10, 20, 30] # Days to lag price data for lag in lags: corr = data[w_col].corr(data[p_col].shift(-lag)) correlations.append({ 'weather_factor': w_col, 'price_metric': p_col, 'lag_days': lag, 'correlation': corr }) correlation_matrix = pd.concat([ correlation_matrix, pd.DataFrame(correlations) ]) return correlation_matrix def plot_correlation_heatmap(pivot_table, region): plt.figure() im = plt.imshow(pivot_table.values, cmap='RdYlBu', aspect='auto') plt.colorbar(im) plt.xticks(range(len(pivot_table.columns)), pivot_table.columns, rotation=45) plt.yticks(range(len(pivot_table.index)), pivot_table.index) # Add correlation values in each cell for i in range(len(pivot_table.index)): for j in range(len(pivot_table.columns)): text = plt.text(j, i, f'{pivot_table.values[i, j]:.2f}', ha='center', va='center') plt.title(f'Weather Factors and Price Correlations for {region}') plt.tight_layout()
Réception et synchronisation des données sur les paires de devises
Après avoir mis en place la collecte des données météorologiques, il est nécessaire de mettre en œuvre la réception des informations relatives à l'évolution des paires de devises. Pour cela, nous utilisons la plateforme MetaTrader 5, qui fournit une API pratique pour travailler avec les données historiques des instruments financiers.
Considérons la fonction permettant d'obtenir des données sur les paires de devises :
def get_agricultural_forex_pairs(): """ Getting data on currency pairs via MetaTrader 5 """ if not mt5.initialize(): print("MT5 initialization error") return None pairs = ["AUDUSD", "NZDUSD", "USDCAD"] timeframes = { "H1": mt5.TIMEFRAME_H1, "H4": mt5.TIMEFRAME_H4, "D1": mt5.TIMEFRAME_D1 } # ... the rest of the function code
Dans cette fonction, nous travaillons avec trois paires de devises principales qui correspondent à nos régions agricoles : AUDUSD pour la ceinture céréalière australienne, NZDUSD pour la région de Canterbury et USDCAD pour les prairies canadiennes. Pour chaque paire, les données sont collectées sur trois périodes : horaire (H1), de quatre heures (H4) et quotidienne (D1).
Une attention particulière doit être portée à la combinaison des données météorologiques et financières. Une fonction spéciale est responsable de cela :
def merge_weather_forex_data(weather_data, forex_data): """ Combining weather and financial data """ synchronized_data = {} region_pair_mapping = { 'AU_WheatBelt': 'AUDUSD', 'NZ_Canterbury': 'NZDUSD', 'CA_Prairies': 'USDCAD' } # ... the rest of the function code
Cette fonction résout le problème complexe de la synchronisation des données provenant de différentes sources. Les données météorologiques et les cours des devises ont des fréquences de mise à jour différentes, c'est pourquoi la méthode spéciale merge_asof de la bibliothèque pandas est utilisée, ce qui nous permet de comparer correctement les valeurs en tenant compte des horodatages.
Pour améliorer la qualité de l'analyse, un traitement supplémentaire des données combinées est effectué :
def calculate_derived_features(data): """ Calculation of derived indicators """ if not data.empty: data['price_volatility'] = data['volatility'].rolling(24).std() data['temp_change'] = data['temperature'].diff() data['precip_intensity'] = data['precipitation'].rolling(24).sum() # ... the rest of the function code
Des indicateurs dérivés importants, tels que la volatilité des prix au cours des dernières 24 heures, les variations de température et l'intensité des précipitations, sont calculés ici. Un indicateur binaire signalant la saison de croissance est également ajouté, ce qui est particulièrement important pour l'analyse des cultures agricoles.
Une attention particulière est portée au nettoyage des données pour éliminer les valeurs aberrantes et à compléter les valeurs manquantes :
def clean_merged_data(data): """ Cleaning up merged data """ weather_cols = ['temperature', 'precipitation', 'wind_speed'] # Fill in the blanks for col in weather_cols: if col in data.columns: data[col] = data[col].ffill(limit=3) # Removing outliers for col in weather_cols: if col in data.columns: q_low = data[col].quantile(0.01) q_high = data[col].quantile(0.99) data = data[ (data[col] > q_low) & (data[col] < q_high) ] # ... the rest of the function code
Cette fonction utilise la méthode de remplissage avant pour gérer les valeurs manquantes dans les données météorologiques, mais avec une limite de 3 périodes afin d'éviter l'introduction de valeurs incorrectes en cas de longs intervalles. Les valeurs extrêmes situées en dehors des 1er et 99e percentiles sont également supprimées, ce qui permet d'éviter que les valeurs aberrantes ne faussent les résultats de l'analyse.
Résultat de l'exécution des fonctions du jeu de données :

Analyse de la corrélation entre les facteurs météorologiques et les taux de prix
Au cours de cette observation, différents aspects de la relation entre les conditions météorologiques et la dynamique des cours des paires de devises ont été analysés. Pour déceler des tendances qui ne sont pas immédiatement évidentes, une méthode spéciale de calcul des corrélations a été créée, prenant en compte les décalages temporels :
def analyze_weather_price_correlations(merged_data): """ Analysis of correlations with time lags between weather conditions and price movements """ def calculate_lagged_correlations(data, weather_col, price_col, max_lag=72): print(f"Calculating lagged correlations: {weather_col} vs {price_col}") correlations = [] for lag in range(max_lag): corr = data[weather_col].corr(data[price_col].shift(-lag)) correlations.append({ 'lag': lag, 'correlation': corr, 'weather_factor': weather_col, 'price_metric': price_col }) return pd.DataFrame(correlations) correlations = {} weather_factors = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_metrics = ['close', 'volatility', 'price_momentum', 'monthly_change'] for region, data in merged_data.items(): if data.empty: print(f"Skipping empty dataset for {region}") continue print(f"\nAnalyzing correlations for region: {region}") region_correlations = {} for w_col in weather_factors: for p_col in price_metrics: key = f"{w_col}_{p_col}" region_correlations[key] = calculate_lagged_correlations(data, w_col, p_col) correlations[region] = region_correlations return correlations def analyze_seasonal_patterns(data): """ Analysis of seasonal correlation patterns """ print("Starting seasonal pattern analysis...") seasonal_correlations = {} data['month'] = data.index.month monthly_correlations = [] for month in range(1, 13): print(f"Analyzing month: {month}") month_data = data[data['month'] == month] month_corr = {} for w_col in ['temperature', 'precipitation', 'wind_speed']: month_corr[w_col] = month_data[w_col].corr(month_data['close']) monthly_correlations.append(month_corr) return pd.DataFrame(monthly_correlations, index=range(1, 13))
L'analyse des données recueillies a révélé des tendances intéressantes. Pour la ceinture céréalière australienne, la corrélation la plus forte (0,21) se trouve entre les vitesses du vent et les variations mensuelles du taux de change AUDUSD. Cela s'explique par le fait que des vents forts pendant la période de maturation du blé peuvent réduire le rendement. Le facteur de température montre également une forte corrélation (0,18), avec une influence particulière démontrée sans pratiquement aucun décalage temporel.
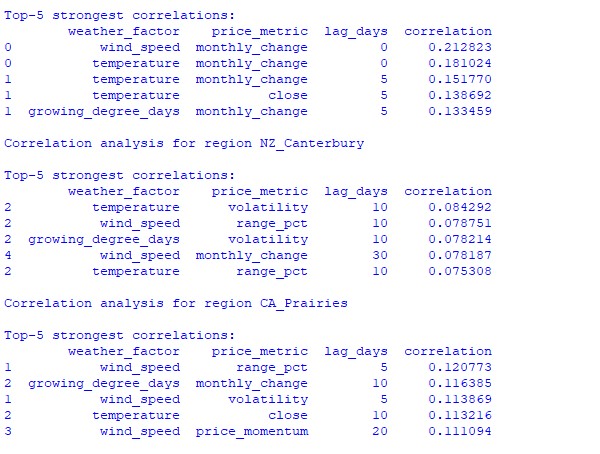
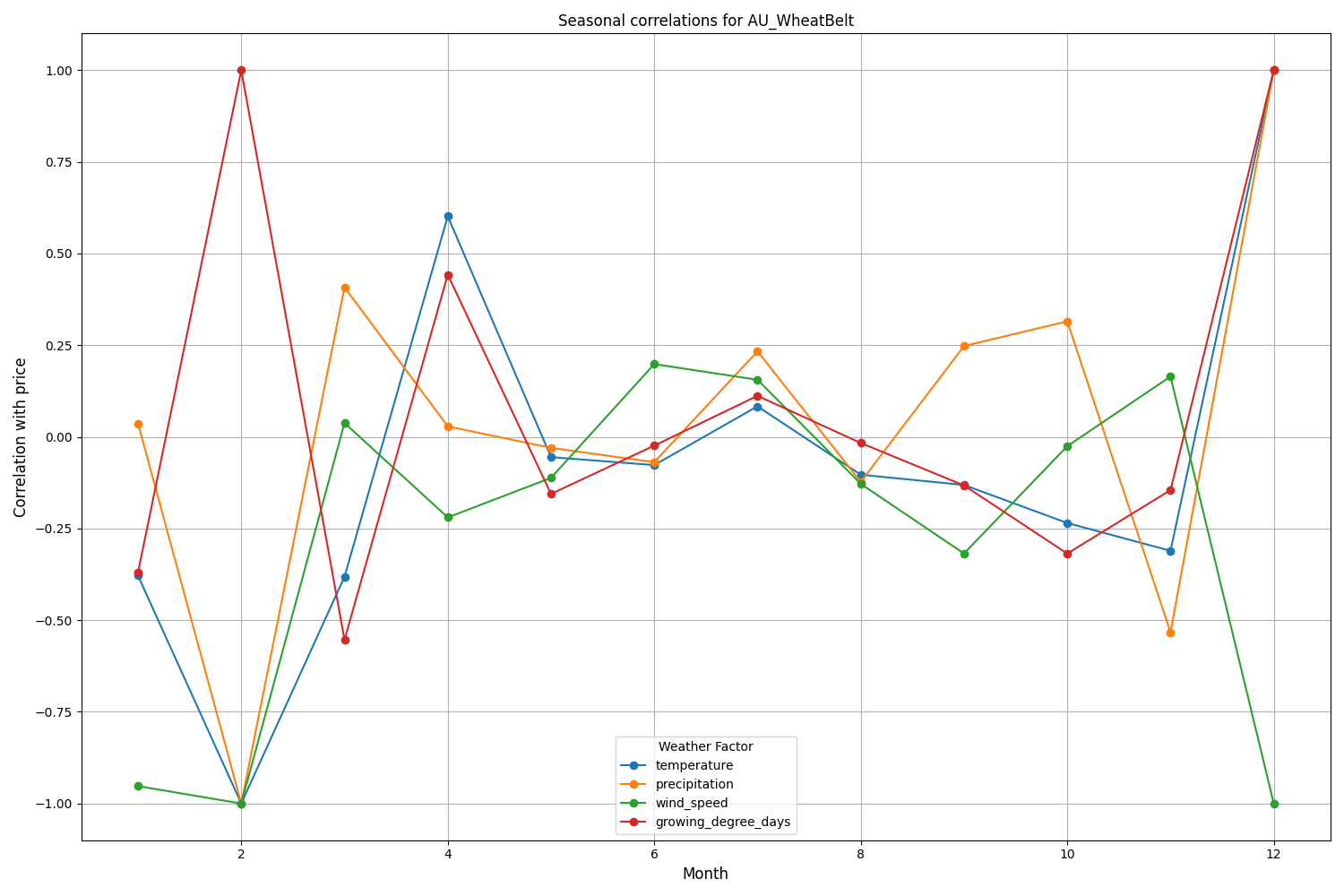
La région de Canterbury en Nouvelle-Zélande présente des schémas plus complexes. La corrélation la plus forte (0,084) est démontrée entre la température et la volatilité avec un décalage de 10 jours. Il convient de noter que l'influence des facteurs météorologiques sur la paire NZD/USD se reflète davantage dans la volatilité que dans la direction des variations de prix. Les corrélations saisonnières atteignent parfois la valeur de 1,00, ce qui signifie une corrélation parfaite.
Création d'un modèle d'apprentissage automatique pour la prévision
Notre stratégie repose sur le modèle de gradient boosting CatBoost, qui a démontré son excellente efficacité dans le traitement des séries temporelles. Examinons la création du modèle étape par étape.
Préparation des fonctionnalités
La première étape consiste à définir les caractéristiques du modèle. Nous allons collecter une sélection d'indicateurs techniques et météorologiques :
def prepare_ml_features(data): """ Preparation of features for the ML model """ print("Starting feature preparation...") features = pd.DataFrame(index=data.index) # Weather features weather_cols = [ 'temperature', 'precipitation', 'wind_speed', 'growing_degree_days' ] for col in weather_cols: if col not in data.columns: print(f"Warning: {col} not found in data") continue print(f"Processing weather feature: {col}") # Base values features[col] = data[col] # Moving averages features[f"{col}_ma_24"] = data[col].rolling(24).mean() features[f"{col}_ma_72"] = data[col].rolling(72).mean() # Changes features[f"{col}_change"] = data[col].pct_change() features[f"{col}_change_24"] = data[col].pct_change(24) # Volatility features[f"{col}_volatility"] = data[col].rolling(24).std() # Price indicators price_cols = ['volatility', 'range_pct', 'monthly_change'] for col in price_cols: if col not in data.columns: continue features[f"{col}_ma_24"] = data[col].rolling(24).mean() # Seasonal features features['month'] = data.index.month features['day_of_week'] = data.index.dayofweek features['growing_season'] = ( (data.index.month >= 4) & (data.index.month <= 9) ).astype(int) return features.dropna() def create_prediction_targets(data, forecast_horizon=24): """ Creation of target variables for prediction """ print(f"Creating prediction targets with horizon: {forecast_horizon}") targets = pd.DataFrame(index=data.index) # Price change percentage targets['price_change'] = data['close'].pct_change( forecast_horizon ).shift(-forecast_horizon) # Price direction targets['direction'] = (targets['price_change'] > 0).astype(int) # Future volatility targets['volatility'] = data['volatility'].rolling( forecast_horizon ).mean().shift(-forecast_horizon) return targets.dropna()
Création et formation de modèles
Pour chaque variable considérée, nous créerons un modèle distinct avec des paramètres optimisés :
from catboost import CatBoostClassifier, CatBoostRegressor from sklearn.metrics import accuracy_score, mean_squared_error from sklearn.model_selection import TimeSeriesSplit # Define categorical features cat_features = ['month', 'day_of_week', 'growing_season'] # Create models for different tasks models = { 'direction': CatBoostClassifier( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='Logloss', eval_metric='Accuracy', random_seed=42, verbose=False, cat_features=cat_features ), 'price_change': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ), 'volatility': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ) } def train_ml_models(merged_data, region): """ Training ML models using time series cross-validation """ print(f"Starting model training for region: {region}") data = merged_data[region] features = prepare_ml_features(data) targets = create_prediction_targets(data) # Split into folds tscv = TimeSeriesSplit(n_splits=5) results = {} for target_name, model in models.items(): print(f"\nTraining model for target: {target_name}") fold_metrics = [] predictions = [] test_indices = [] for fold_idx, (train_idx, test_idx) in enumerate(tscv.split(features)): print(f"Processing fold {fold_idx + 1}/5") X_train = features.iloc[train_idx] y_train = targets[target_name].iloc[train_idx] X_test = features.iloc[test_idx] y_test = targets[target_name].iloc[test_idx] # Training with early stopping model.fit( X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50, verbose=False ) # Predictions and evaluation pred = model.predict(X_test) predictions.extend(pred) test_indices.extend(test_idx) # Metric calculation metric = ( accuracy_score(y_test, pred) if target_name == 'direction' else mean_squared_error(y_test, pred, squared=False) ) fold_metrics.append(metric) print(f"Fold {fold_idx + 1} metric: {metric:.4f}") results[target_name] = { 'model': model, 'metrics': fold_metrics, 'mean_metric': np.mean(fold_metrics), 'predictions': pd.Series( predictions, index=features.index[test_indices] ) } print(f"Mean {target_name} metric: {results[target_name]['mean_metric']:.4f}") return results
Caractéristiques de l'implémentation
Notre implémentation se concentre sur les paramètres suivants :
- Gestion des variables catégorielles : CatBoost gère efficacement les variables catégorielles, telles que le mois et le jour de la semaine, sans nécessiter de code supplémentaire.
- Arrêt anticipé : Pour éviter les tentatives de sur-apprentissage, le mécanisme d'arrêt précoce est utilisé avec le paramètre early_stopping_rounds=50.
- Trouver le juste équilibre entre profondeur et généralisation : Les paramètres depth=7 et l2_leaf_reg=3 sont choisis pour un équilibre maximal entre la profondeur de l'arbre et la régularisation.
- Gestion des séries temporelles : L'utilisation de TimeSeriesSplit garantit un fractionnement correct des données pour les séries temporelles, empêchant ainsi d'éventuelles fuites de données futures.
Cette architecture de modèle permettra de saisir efficacement les dépendances à court et à long terme entre les conditions météorologiques et les fluctuations des taux de change, comme le démontrent les résultats des tests obtenus.
Évaluation de la précision du modèle et visualisation des résultats
Les modèles d'apprentissage automatique obtenus ont été testés sur des données de 5 ans en utilisant la méthode de la fenêtre glissante à 5 plis. Pour chaque zone, 3 types de modèles ont été réalisés : prédiction de la direction du mouvement des prix (classification), prédiction de l'ampleur du changement de prix (régression) et prédiction de la volatilité (régression).
import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix, classification_report def evaluate_model_performance(results, region_data): """ Comprehensive model evaluation across all regions """ print(f"\nEvaluating model performance for {len(results)} regions") evaluation = {} for region, models in results.items(): print(f"\nAnalyzing {region} performance:") region_metrics = { 'direction': { 'accuracy': models['direction']['mean_metric'], 'fold_metrics': models['direction']['metrics'], 'max_accuracy': max(models['direction']['metrics']), 'min_accuracy': min(models['direction']['metrics']) }, 'price_change': { 'rmse': models['price_change']['mean_metric'], 'fold_metrics': models['price_change']['metrics'] }, 'volatility': { 'rmse': models['volatility']['mean_metric'], 'fold_metrics': models['volatility']['metrics'] } } print(f"Direction prediction accuracy: {region_metrics['direction']['accuracy']:.2%}") print(f"Price change RMSE: {region_metrics['price_change']['rmse']:.4f}") print(f"Volatility RMSE: {region_metrics['volatility']['rmse']:.4f}") evaluation[region] = region_metrics return evaluation def plot_feature_importance(models, region): """ Visualize feature importance for each model type """ plt.figure(figsize=(15, 10)) for target, model_info in models.items(): feature_importance = pd.DataFrame({ 'feature': model_info['model'].feature_names_, 'importance': model_info['model'].feature_importances_ }) feature_importance = feature_importance.sort_values('importance', ascending=False) plt.subplot(3, 1, list(models.keys()).index(target) + 1) sns.barplot(x='importance', y='feature', data=feature_importance.head(10)) plt.title(f'{target.capitalize()} Model - Top 10 Important Features') plt.tight_layout() plt.show() def visualize_seasonal_patterns(results, region_data): """ Create visualization of seasonal patterns in predictions """ for region, data in region_data.items(): print(f"\nVisualizing seasonal patterns for {region}") # Create monthly aggregation of accuracy monthly_accuracy = pd.DataFrame(index=range(1, 13)) data['month'] = data.index.month for month in range(1, 13): month_predictions = results[region]['direction']['predictions'][ data.index.month == month ] month_actual = (data['close'].pct_change() > 0)[ data.index.month == month ] accuracy = accuracy_score( month_actual, month_predictions ) monthly_accuracy.loc[month, 'accuracy'] = accuracy # Plot seasonal accuracy plt.figure(figsize=(12, 6)) monthly_accuracy['accuracy'].plot(kind='bar') plt.title(f'Seasonal Prediction Accuracy - {region}') plt.xlabel('Month') plt.ylabel('Accuracy') plt.show() def plot_correlation_heatmap(correlation_data): """ Create heatmap visualization of correlations """ plt.figure(figsize=(12, 8)) sns.heatmap( correlation_data, cmap='RdYlBu', center=0, annot=True, fmt='.2f' ) plt.title('Weather-Price Correlation Heatmap') plt.tight_layout() plt.show()
Résultats par région
AU_WheatBelt (Ceinture de blé australienne)
- Précision moyenne des prévisions de direction de la paire AUD/USD : 62,67%
- Précision maximale dans chaque pli : 82,22%
- RMSE des prévisions de variation de prix : 0,0303
- RMSE de la volatilité : 0,0016
Région de Canterbury (Nouvelle-Zélande)
- Précision moyenne des prévisions NZD/USD : 62,81%
- Précision maximale : 75,44%
- Précision minimale : 54,39%
- RMSE des prévisions de variation de prix : 0,0281
- RMSE de la volatilité : 0,0015
Région des prairies canadiennes
- Précision moyenne de la prédiction de direction : 56,92%
- Précision maximale (troisième pli) : 71,79%
- RMSE des prévisions de variation de prix : 0,0159
- RMSE de la volatilité : 0,0023
Analyse et visualisation de la saisonnalité
def analyze_model_seasonality(results, data): """ Analyze seasonal performance patterns of the models """ print("Starting seasonal analysis of model performance") seasonal_metrics = {} for region, region_results in results.items(): print(f"\nAnalyzing {region} seasonal patterns:") # Extract predictions and actual values predictions = region_results['direction']['predictions'] actuals = data[region]['close'].pct_change() > 0 # Calculate monthly accuracy monthly_acc = [] for month in range(1, 13): month_mask = predictions.index.month == month if month_mask.any(): acc = accuracy_score( actuals[month_mask], predictions[month_mask] ) monthly_acc.append(acc) print(f"Month {month} accuracy: {acc:.2%}") seasonal_metrics[region] = pd.Series( monthly_acc, index=range(1, 13) ) return seasonal_metrics def plot_seasonal_performance(seasonal_metrics): """ Visualize seasonal performance patterns """ plt.figure(figsize=(15, 8)) for region, metrics in seasonal_metrics.items(): plt.plot(metrics.index, metrics.values, label=region, marker='o') plt.title('Model Accuracy by Month') plt.xlabel('Month') plt.ylabel('Accuracy') plt.legend() plt.grid(True) plt.show()
Les résultats de visualisation montrent une saisonnalité significative dans les performances du modèle.
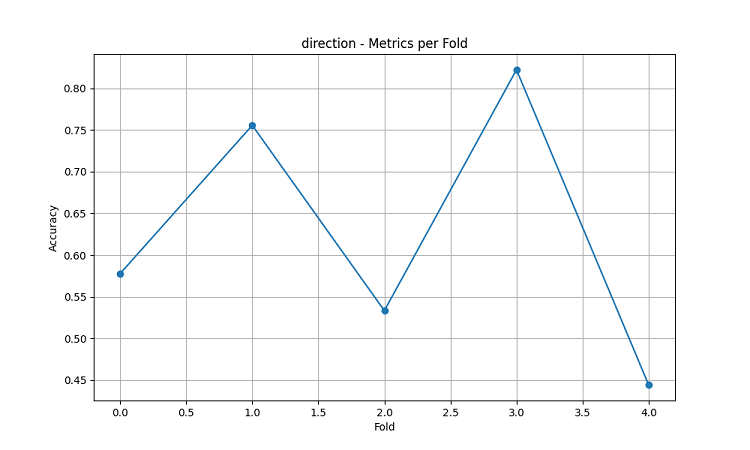

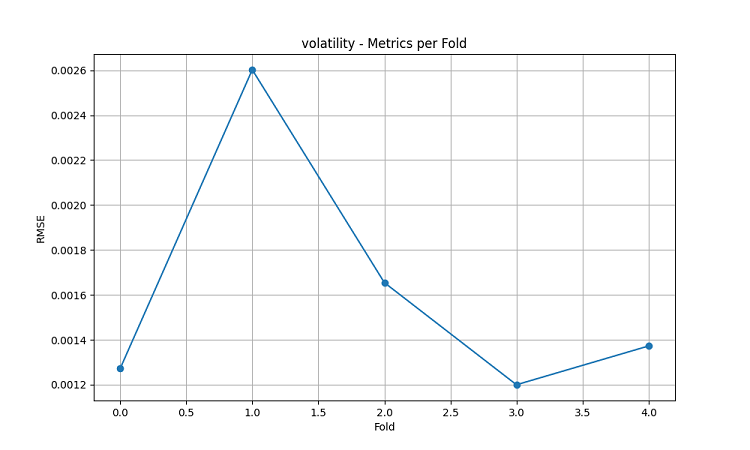
Les pics de précision des prédictions sont particulièrement remarquables :
- Pour AUDUSD : Décembre-février (période de maturation du blé)
- Pour NZDUSD : périodes de pic de production laitière
- Pour USDCAD : saisons de croissance actives des prairies
Ces résultats confirment l'hypothèse selon laquelle les conditions météorologiques ont un impact significatif sur les taux de change des devises agricoles, en particulier pendant les périodes critiques de la production agricole.
Conclusion
L'étude a mis en évidence des liens significatifs entre les conditions météorologiques dans les régions agricoles et la dynamique des paires de devises. Le système de prévision a démontré une grande précision lors de périodes de conditions météorologiques extrêmes et de pic de production agricole, affichant une précision moyenne allant jusqu'à 62,67% pour l'AUDUSD, 62,81% pour le NZDUSD et 56,92% pour l'USDCAD.
Recommandations :
- AUDUSD : Entre décembre et février, concentrez-vous sur le vent et la température.
- NZDUSD : Trading à moyen terme pendant la période de production laitière active.
- USDCAD : Trading pendant les saisons des semis et des récoltes.
Le système nécessite des mises à jour régulières des données pour maintenir son exactitude, notamment en cas de chocs sur les marchés. Les perspectives incluent l'élargissement des sources de données et la mise en œuvre de l'apprentissage profond pour améliorer la fiabilité des prévisions.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/16060
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Pour beaucoup de gens, ce sera une révélation que le CAD n'est pas tant du pétrole que des mélanges de céréales pour l'alimentation animale :-))
Ce qui est principalement échangé sur les bourses nationales pour la monnaie nationale, cela affecte...
pour l'USDCAD et même les saisons agricoles devraient être traçables.