
Simulación de mercado (Parte 18): Iniciando SQL (I)

Introducción
En el artículo anterior, Simulación de mercado (Parte 17): Sockets (XI), finalicé la demostración de una implementación que permite el intercambio de información entre MetaTrader 5 y Excel. Aunque no profundicé mucho en cómo hacer para que Excel controle MetaTrader 5, esto se debe a que, al hacerlo, hay que proceder con el debido cuidado. Al ser algo totalmente dependiente de lo que cada uno piensa o espera hacer, solo dejé algunas referencias al final del artículo para que te hagas una idea de cómo realizar las cosas.
Da igual si vamos a usar uno u otro programa de SQL, ya sea MySQL, SQL Server, SQLite, OpenSQL o cualquier otro. Todos tienen algo en común. Ese algo en común es el lenguaje SQL. Aunque no vayas a usar una WorkBench, podrás manipular o trabajar con una base de datos directamente en MetaEditor o a través de MQL5 para hacer cosas en MetaTrader 5, pero necesitarás tener conocimientos de SQL. Existen muchos libros orientados a explicar el tema, así como diversos tutoriales disponibles en Internet. Lo único que necesitas es entender algunos conceptos y aprender a usar tu lenguaje de programación para poder comunicarte con SQL.
Sin embargo, existen algunas limitaciones que deberás conocer antes de empezar a utilizar SQL. No podrás estudiar SQL si ni siquiera consigues crear una base de datos. Este es el punto de partida que debes aprender y comprender, querido lector.
Comenzando a trabajar con bases de datos
Existen algunas formas muy básicas de utilizar SQL. La primera es escribir los comandos directamente en un prompt. Otra forma es usar una WorkBench o un programa similar, como MetaEditor. Otra forma consiste en añadir comandos SQL a un programa escrito en MQL5. Al ejecutar dicho programa en MetaTrader 5, se accede a la base de datos. Por último, existe una forma básica adicional que consiste en usar sockets para comunicarse con el servidor SQL. Todas estas formas básicas están ampliamente disponibles en todos los sistemas de bases de datos que utilizan SQL. Por lo tanto, todo lo que se mostrará y explicará podrá usarse en cualquier sistema compatible. No te quedes con la idea de que no se puede hacer esto o aquello. Si usas SQL puro y nativo, podrás hacerlo.
Pero hay un detalle al que debes prestar atención. Cada programa que utiliza SQL, ya sea OpenSQL, MySQL, SQLite, SQL Server u otro, puede tener comandos dirigidos específicamente a ese programa. Si utilizas esos comandos, no podrás ejecutar las mismas acciones en otro programa SQL.
Otra cosa: durante estos primeros momentos, todo se hará usando la WorkBench de MySQL. El motivo lo explicaré más adelante.
Dados estos avisos, veamos el comando más básico: crear una base de datos vacía. No sirve de nada crear cualquier archivo y cambiarle la extensión a .DB, ya que el sistema no lo reconocerá como una base de datos. Es necesario usar un comando para ello. Dicho comando es muy sencillo. Pero antes de ver cualquier comando, veamos otra cosa.
Es muy común, y casi se considera una buena práctica en la programación SQL, utilizar las palabras reservadas en mayúsculas. Sin embargo, para SQL esto no marca ninguna diferencia. Si durante la escritura te olvidas de poner los comandos en mayúsculas, no te preocupes; solo tendrás que usar el punto que se muestra en la imagen de abajo. Esto convertirá todo el código o las palabras reservadas de SQL en mayúsculas.

Los primeros comandos en SQL
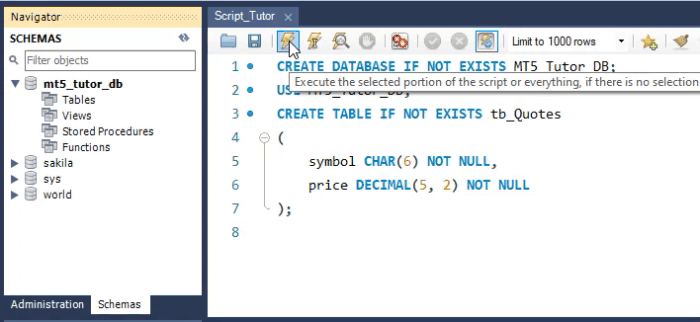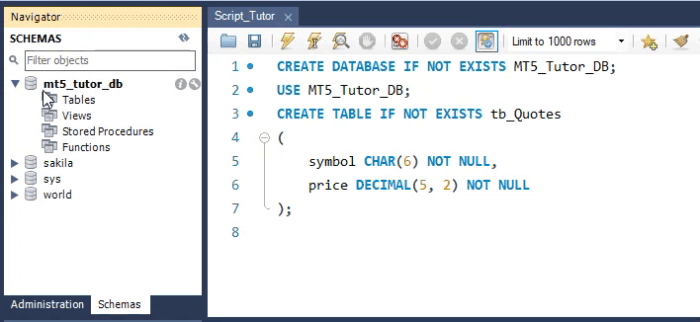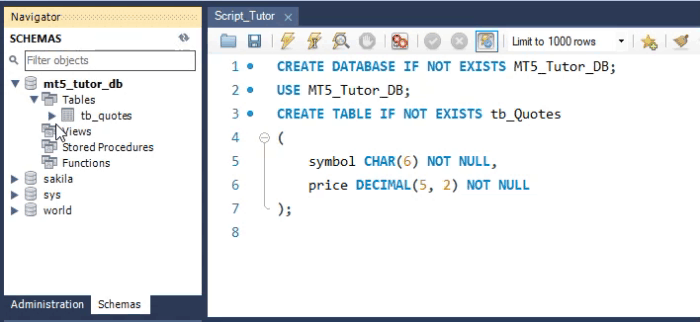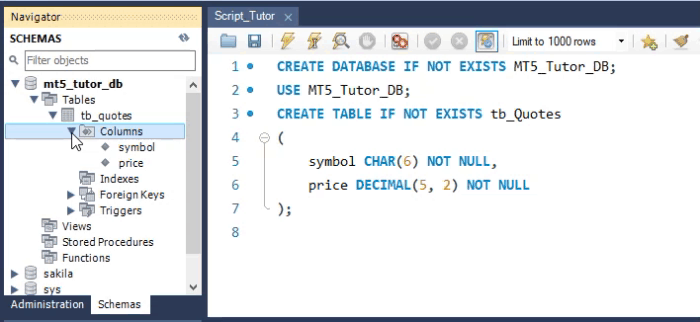
Ahora sí, podemos empezar a ver los comandos. El primer comando que debemos aprender es CREATE DATABASE. En la imagen de abajo puedes ver cómo se presenta realmente.

El texto en azul y en negrita es el código SQL, mientras que el texto en negro es el nombre de la base de datos. Este es el primer comando que deberás usar. Después de escribir este comando, podrás hacer clic en uno de los iconos de rayo que se ven encima del código. Cada uno de estos rayos funciona de una manera diferente. Como estamos empezando, haz clic en el que está en el extremo izquierdo. Pero es bueno que intentes entender para qué sirve cada uno y cómo funciona, ya que esto te ayudará mucho, sobre todo cuando vayas a depurar un script. Hablaré sobre esto en breve. Ahora, presta atención a algo. Si quieres crear la base de datos directamente en MetaEditor mediante SQL, tendrás que hacer algo diferente. En este caso, deberás seleccionar la opción que se muestra en la imagen de abajo.

Al hacerlo, MetaEditor te pedirá que indiques la ubicación y el nombre del archivo de la base de datos que se va a crear. Es bastante sencillo. También podemos crear el archivo de base de datos usando un código escrito en MQL5. Pero esto se verá más adelante, ya que es mejor que tengamos algo más de material para crear realmente las cosas directamente con MQL5 u otro lenguaje que vayas a usar para trabajar con SQL. No obstante, si utilizas sockets en un código MQL5 y te conectas al servidor SQL, podrás enviar el comando mostrado en la WorkBench y obtendrás el mismo resultado. Es decir, la creación de la base de datos.
Sin embargo, este es un tema para otra ocasión. Por ahora, vamos a hacer las cosas de la manera más simple y directa: usando MetaEditor, una WorkBench o incluso el prompt. No obstante, en el prompt realmente debes entender cómo se mostrarán las cosas. Pero esto es solo una cuestión de acostumbrarse al prompt.
Sin embargo, como la idea aquí es ser lo más didáctico posible, vamos a usar únicamente MetaEditor y la WorkBench.
Muy bien, al hacer las cosas en MetaEditor, al final obtendrás algo parecido a la imagen de abajo. Como puedes ver, en este caso he cambiado el nombre de las bases de datos para diferenciarlas de las de la WorkBench.

En este punto, el MetaEditor ya estará listo para continuar. Sin embargo, en lo que respecta a la WorkBench, todavía no podemos pasar al siguiente paso. Necesitamos algunos pasos adicionales. Para entender qué será necesario hacer, haz clic en el punto destacado de la imagen de abajo después de ejecutar el comando del script.

Usar cualquiera de estos dos puntos dará el mismo resultado. Ahora fíjate en la imagen de abajo: el archivo que se usará como base de datos se ha creado. Pero fíjate que no está seleccionado para recibir nuevos comandos SQL.

Siempre que vayas a realizar alguna acción en una base de datos, debes seleccionarla. Una de las formas de hacerlo es utilizar un comando SQL. Este comando es «USE». Puedes verlo justo abajo.

Ahora hay un detalle importante en el uso de la WorkBench. Si estás usando el prompt para realizar las acciones, en este momento solo tendrás que escribir el contenido de la línea dos. Y podrás continuar con el siguiente paso. Sin embargo, en la WorkBench, el proceso es un poco diferente. Observa que he destacado dos de los iconos de rayo. Ahora veremos cómo funciona. Cuando creamos un script para SQL, a menudo escribimos varios comandos. El motivo de usar un script es la documentación. Sin embargo, al usar un script, debes tener en cuenta algunas cosas más. El primero es el siguiente: si el script se ejecuta en un solo paso, no tendrás problemas. Sin embargo, si vas a ejecutar el mismo script poco a poco, tendrás problemas si intentas ejecutarlo desde el principio. Por esta razón, muchas personas abandonan el estudio de SQL, ya que no logran hacer frente a los problemas que van surgiendo.
Muy bien. Lo que queremos es que se ejecute la línea dos. Para ello, tenemos tres alternativas. La primera es seleccionar la línea dos y presionar el botón destacado que está a la izquierda. La segunda alternativa es colocar el cursor de texto en la línea dos y presionar el botón destacado que está a la derecha. Observa que este tiene un icono de cursor junto a él. De este modo, solo se ejecuta la línea en la que se encuentra el cursor.
Y existe una tercera alternativa. Esta se usa sobre todo cuando se quiere forzar la ejecución del código desde el principio, incluso si ya se ha ejecutado parcialmente. Para ello, necesitaremos crear una prueba aquí, en SQL. Si el código intenta ejecutarse desde el principio, se producirá un error en la primera línea. ¿Cómo es posible? El motivo es que SQL intentará volver a crear el archivo de la base de datos. Y este intento fallará porque el archivo ya existe. Por tanto, el resto del código no se ejecutará. Puedes probarlo haciendo clic en el icono de la izquierda sin seleccionar ninguna línea.
Como muchas veces podremos estar trabajando con un script en el que la base de datos ya existe, pero queremos modificar algo en ella, realizar el cambio en el propio script implica que eliminar la base de datos es una alternativa que debe descartarse. Para resolverlo, podemos comentar la primera línea añadiendo un doble guion, como se muestra en la imagen de abajo, o hacer algo un poco diferente.

Como se puede ver en la imagen anterior, hay dos formas de hacer comentarios en un código SQL. La primera es la que se muestra en la imagen: la línea uno ahora se entiende como un comentario. Esta forma es útil cuando se desea comentar una sola línea. Sin embargo, también se pueden comentar varias líneas al mismo tiempo. Para ello, basta con usar la misma forma que en MQL5, es decir, barra y asterisco.
Está bien, pero aunque la solución anterior sea plausible, en realidad no funciona cuando el código SQL es largo y contiene muchas partes que pueden fallar porque ya existen en la base de datos. Por lo tanto, necesitamos una solución más elegante. Esta solución se puede ver en la imagen de abajo.

Observa que en la primera línea tenemos un comando diferente. Sin embargo, este comando garantiza que el script se ejecute correctamente y de la forma esperada. Esto se debe a que, si el archivo de la base de datos no existe, se creará. Pero, si ya existe, SQL no lo verá como un error, ya que estamos comprobando si el archivo existe o no. Este tipo de construcción con el comando IF es bastante común en SQL, especialmente en scripts que se van a usar y reutilizar varias veces a lo largo de la vida de una base de datos. Al final de la ejecución, obtendremos como resultado lo que se muestra en la imagen. Es decir, nuestro archivo de base de datos habrá sido seleccionado para recibir nuevas instrucciones.
Verás que todo es muy sencillo y práctico. Todo lo que necesitas es entender qué hace cada instrucción o comando. No pierdas tu tiempo memorizando comandos y más comandos con sus combinaciones. Entiende qué hace cada uno y úsalos según necesites. Muy bien, a partir de este momento estamos en el mismo nivel que el que se había alcanzado dentro de MetaEditor. Por tanto, el siguiente comando que veremos se podrá usar tanto en MetaEditor como en WorkBench. Se trata de un comando un poco más complicado que los que hemos visto hasta ahora. Pero recuerda que el conocimiento se va acumulando, no dispersando.
Creando una tabla
Este comando para crear una tabla es uno de los que más usarás, especialmente durante la fase de aprendizaje. Su objetivo es crear una tabla que luego recibirá los datos mediante otro comando. Sin embargo, a diferencia de los comandos anteriores, a partir de este punto nos encontraremos con algunos contratiempos que pueden resultar confusos al principio. Pero no hay motivo para preocuparse: todo es cuestión de costumbre y estudio, y acabarás entendiendo cómo utilizar este comando.
Todo el problema se debe a un único motivo. A partir de ahora, tendrás que empezar a pensar en cómo se modelarán los datos que se colocarán en la tabla antes de crearla. Esta parte es, sin duda, la que más cuesta al principio del aprendizaje de SQL. El motivo es justamente el hecho de que necesitarás tener una noción de lo que se hará antes de hacerlo. No sirve de nada planificar mil cosas y no planificar adecuadamente el tipo de dato que se colocará en la tabla. El orden en el que se colocarán los datos importa poco, pero la correcta selección del tipo de dato importa mucho. Si eliges el tipo incorrecto, terminarás creando una tabla que luego se volverá inadecuada para nuevos datos.
Sin embargo, si intentas crear algo demasiado genérico, terminarás consumiendo muchos más recursos y espacio de los necesarios. Por esta razón, te sugiero que estudies primero los tipos de datos disponibles. Hazlo antes de intentar desarrollar bases de datos con un propósito específico. Al final de este artículo, dejaré algunas referencias para que sepas por dónde empezar.
Comienza por ahí, aunque solo sea un punto de partida. Deberás buscar más información sobre este tema. Por suerte, hay muchas personas dispuestas a explicar en detalle cada uno de los tipos. Así que no esperes a que te den la solución.
Para simplificar y solo a efectos de demostración del comando, supongamos el siguiente escenario: deseas crear y mantener un histórico de cotizaciones de algunos símbolos de la B3 (Bolsa de Brasil). La forma más fácil de hacerlo, como se muestra a continuación, es utilizar la WorkBench.
Aunque nuestro código SQL ocupe muchas líneas para crear la tabla, debes entender que, en realidad, esto sería solo una línea. El resultado es lo que se ve en el área de esquemas de la WorkBench. Sin embargo, a pesar de que esta tabla se haya creado y pueda recibir valores, no es adecuada en algunos casos. El motivo lo explicaré más adelante. Pero antes de conocer el motivo, veamos cómo se crearía la misma tabla en MetaEditor. Esto se puede ver en la imagen de abajo.

Como puedes ver, el comando es exactamente el mismo, por lo que el resultado también lo será. Prácticamente todos los comandos que podemos ejecutar en la WorkBench también se pueden ejecutar en MetaEditor. Y funcionarán. Pero observa que dije «prácticamente todos los comandos» y no que todos los comandos se ejecutarán. Existe un comando del que hablaré en breve que se puede ejecutar en SQL, pero no a través de MetaEditor. Sin embargo, vayamos con calma.
En primer lugar, vamos a entender por qué esta tabla que hemos creado no es tan adecuada para determinados escenarios. El primer motivo es la propia modelización. ¿Cómo es posible? ¿No debería mostrar el valor de la cotización? Sí, pero quizá no hayas entendido algo. Queremos el valor de la cotización, pero también queremos mantener un histórico de esa cotización y este modelo no resuelve el problema. Pues solo nos garantiza la cotización en sí. Incluso si intentas crear un histórico, esta modelación no será suficiente.
Necesitamos más cosas. Por ejemplo, la fecha o la hora, dependiendo de cada caso. Supongamos que solo necesitamos el precio de cierre del día. Todos los días tendremos una nueva entrada de datos en la tabla. Por tanto, este mismo código que hemos visto antes tendrá que modificarse.
Tal vez te estés preguntando: «¿Por qué no hiciste esto desde el principio? ¿Por qué hacerlo ahora, después de que la tabla ya se ha creado?» Lo hice a propósito para mostrarte cómo agregar nuevas columnas a la tabla. Como mencioné antes, no importa el orden en el que se crean las cosas. SQL se encargará de que queden adecuadamente dentro de la base de datos. Pero, volviendo al comando que se debe ejecutar, es justo el que se muestra en la animación de abajo.

Si ejecutamos este mismo comando de la línea ocho en MetaEditor, obtendremos el mismo resultado que se ve en la imagen: la creación de una nueva columna que contendrá datos relacionados con la fecha en la que se obtuvo la cotización. Esto se puede observar justo debajo:
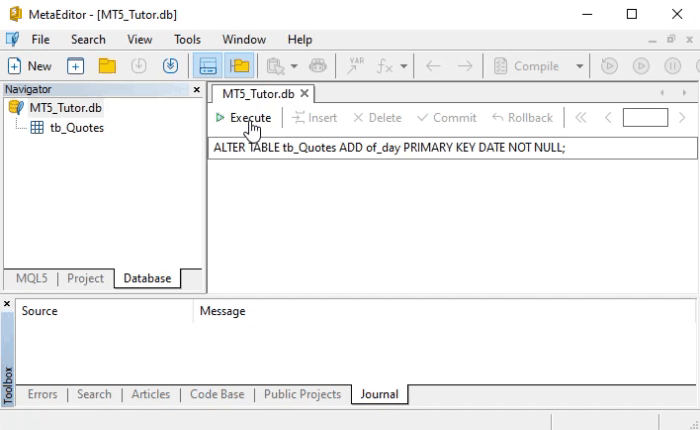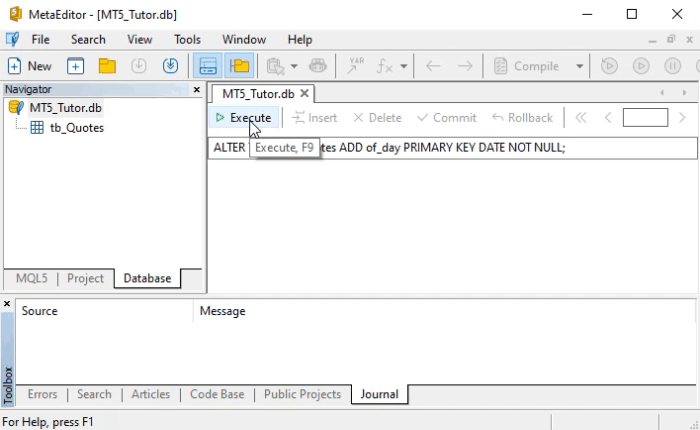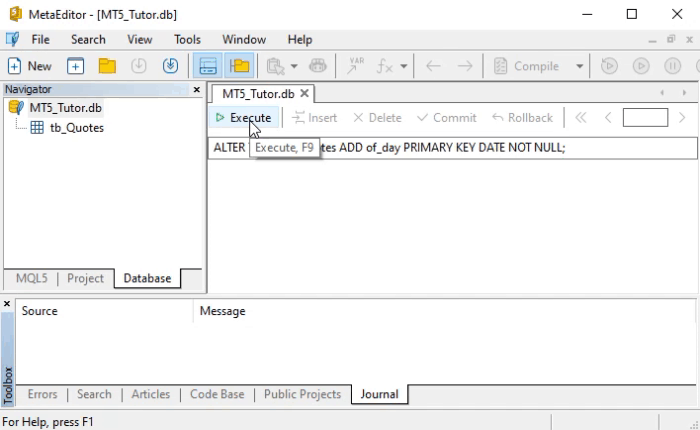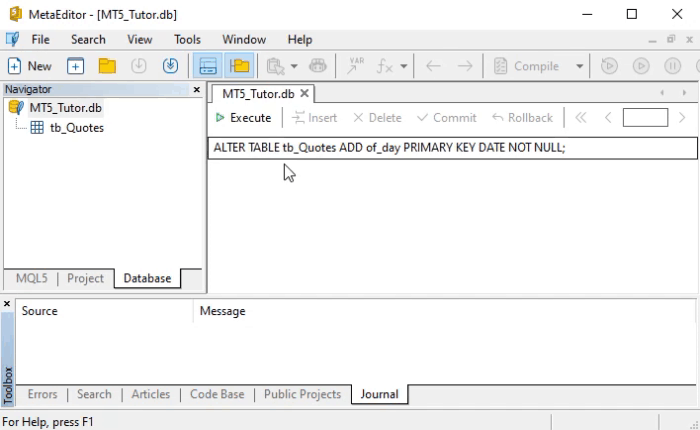
Después de hacer lo que se muestra arriba, ejecuta el comando que se muestra abajo para obtener el mismo resultado en la WorkBench.

En cuanto a los valores que se colocarán en estos campos y a la forma en que deberán prepararse, será tema para otro momento. Esto se debe a que insertar nuevos valores o eliminar valores de una base de datos es algo que debe hacerse con cierto cuidado. Recuerda: no querrás estar realizando muchos cambios en la base de datos en lo que respecta a eliminar o agregar cosas. Si no lo haces de manera planificada, terminarás convirtiendo la base de datos en algo insostenible a largo plazo. Lo ideal es agregar o eliminar cosas de manera muy planificada y usar la base de datos, básicamente, para consultas.
Pensando antes de actuar
A lo largo del artículo se menciona que, aunque esta base de datos tan simple funcione, no es ideal. Esto se debe a que, dependiendo de lo que pretendas hacer con ella, podría estar mejor optimizada en cuanto al uso del espacio. Pero puedes pensar lo siguiente: ¿por qué debo preocuparme por el espacio? Si comienza a faltar espacio, adquiero una nueva unidad de disco. Es una opción, pero no resolvería el problema. El problema radica en la forma en que se utiliza la base de datos o en cómo se dimensionó.
Lo que diré aquí es solo una pequeña idea de lo que realmente es el problema. Si tienes más experiencia en el uso de bases de datos, sabrás que la cuestión es mucho más profunda. De hecho, existen cursos especialmente orientados a personas que desean y llegan a convertirse en profesionales en este campo. Pero no entraré en demasiados detalles, ya que el asunto es mucho más amplio de lo que podría abordar en uno o dos artículos.
Quiero mostrarte, querido lector, que no sirve de nada estudiar únicamente programación SQL o ver un tutorial u otro sobre bases de datos. Y salir por ahí diciendo que sabes trabajar con ellas. Este tipo de afirmaciones solo se pueden hacer después de muchos años trabajando en el sector. Y, aun así, difícilmente verás a alguien que lo afirme con total convicción.
Y el motivo es el siguiente: las bases de datos son un nicho bastante amplio y con muchísimos aspectos estudiados. Y cada caso es un caso. No existe, de hecho, una solución genérica.
Vamos a analizar uno de los problemas de este sencillo script de ocho líneas que crea una base de datos destinada a albergar el histórico de cotizaciones de los símbolos negociados en la B3 (Bolsa de Brasil). El primer problema es que en el área donde podemos almacenar el precio solo podemos introducir valores de 0,00 a 999,99. Es decir, algunos símbolos no podrán almacenarse en esta tabla. Esto se debe a que el valor de cotización de dichos símbolos es diferente de lo que la tabla espera. Podrías resolverlo agregando otra columna para cubrir esas lagunas. Sin embargo, esto haría que una de las dos columnas, ya fuera la del código o la que se crearía, ocupara espacio innecesario en la base de datos.
El segundo problema es que el valor de registro que almacena la fecha de la cotización utiliza el formato ISO 8601. ¿Y qué importancia tiene esto en la base de datos? Bien, para responder a esta pregunta, primero debes responder a otra: ¿desde cuándo hasta cuándo añadiré cotizaciones a la tabla? Dependiendo de la respuesta, podrías usar un formato diferente. Así ocuparías menos espacio y mejorarías el rendimiento general de la base de datos.
Para entenderlo, piensa que un año tiene 365 días, pero no todos los días hay negociación en la bolsa de valores. Pero supongamos que hubiera negociación todos los días. Así, si utilizaras un valor, por ejemplo, SmallInt, que en este caso es un valor con signo, podrías contar de 0 a 32767. Esto permitiría cubrir un total de poco más de 89 años. Si usaras el mismo tipo de dato, pero sin signo, es decir, que puede ir de 0 a 65535, podrías cubrir un total de poco más de 179 años. Y, aun así, estarías usando únicamente dos bytes, en lugar de todos los bytes que utiliza el formato ISO 8601. Solo piensa en la cantidad de datos que supondría la diferencia entre 179 años de cotización diaria.
El tercer problema es similar al anterior. Este problema también afecta al coste en bytes, pero esta vez el campo de registro es diferente. En este caso, se trata del nombre del símbolo. Este problema es aún más complicado que el anterior. El motivo es que, de vez en cuando, algunos símbolos cambian de nombre. Sin embargo, si consideras que el hecho de que un símbolo cambie de nombre no implica que la empresa que representa cambie su comportamiento, entonces el cambio de nombre de un símbolo no hará que su histórico también cambie.
Muy bien. Cualquiera que sea el mercado, tendrá un número limitado de símbolos negociados. Entre estos símbolos, solo algunos podrán llamarte la atención hasta el punto de que quieras un histórico de cotización. Entonces, ¿por qué usar 6 bytes si podemos usar 1 byte para representar un símbolo? Esto se debe a que ese 1 byte nos permitirá representar 255 símbolos.
Ahora, volvamos al problema anterior. Piensa en la cantidad de bytes que se ahorrarán a largo plazo. Y eso sin contar con que, si el símbolo cambia de nombre, solo será necesario modificar un registro de la base de datos, y no todo el histórico de cotizaciones, para colocar el nuevo nombre.
Consideraciones finales
En este artículo, intenté mostrar cómo se crea una base de datos simple y sencilla de la forma más simple y accesible posible. Mostré que prácticamente todas las instrucciones que se pueden usar en WorkBench también se pueden usar en MetaEditor para obtener los mismos resultados. Sin embargo, hay una instrucción que no se puede usar en MetaEditor. Esta instrucción no se demostró en este artículo, al igual que la forma de insertar datos y realizar consultas en la base de datos.
No obstante, como este tema es muy amplio, te sugiero que lo estudies mediante investigaciones en Internet, un curso o libros sobre el tema. De todos modos, aquí mostraré algunos comandos más para que tengamos un material mínimo con el que usar SQL en MQL5. Así que, en el próximo artículo, veremos un poco más sobre SQL.
Referencias:
| Archivo | Descripción |
|---|---|
| Experts\Expert Advisor.mq5 | Demuestra la interacción entre Chart Trade y el Asesor Experto (es necesario el Mouse Study para la interacción) |
| Indicators\Chart Trade.mq5 | Crea la ventana para configurar la orden a ser enviada (es necesario el Mouse Study para la interacción) |
| Indicators\Market Replay.mq5 | Crea los controles para la interacción con el servicio de reproducción/simulador (es necesario el Mouse Study para la interacción) |
| Indicators\Mouse Study.mq5 | Permite la interacción entre los controles gráficos y el usuario (necesario tanto para operar el sistema de repetición como en el mercado real) |
| Services\Market Replay.mq5 | Crea y mantiene el servicio de reproducción y simulación de mercado (archivo principal de todo el sistema) |
| Code VS C++\Servidor.cpp | Crea y mantiene un socket servidor desarrollado en C++ (versión Mini Chat) |
| Code in Python\Server.py | Crea y mantiene un socket en Python para la comunicación entre MetaTrader 5 y Excel |
| Indicators\Mini Chat.mq5 | Permite implementar un minichat mediante un indicador (requiere el uso de un servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar un minichat mediante un Asesor Experto (requiere el uso de un servidor para funcionar) |
| Scripts\SQLite.mq5 | Demuestra el uso de un script SQL mediante MQL5 |
| Files\Script 01.sql | Demuestra la creación de una tabla simple, con clave foránea |
| Files\Script 02.sql | Demuestra la adición de valores en una tabla |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/12926
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso