
Integrate Your Own LLM into EA (Part 3): Training Your Own LLM with CPU

Introduction
Dear friends, long time no see!
You might be a bit surprised to see this title, but you read it correctly, we are indeed going to do this!
In the previous article of this series, we discussed the basic environment setup for running large language models and ran a simple LLM instance using llama.cpp in WSL. The most exciting part is that even without a powerful GPU, you can still run the example purely with a CPU! This series of tutorials will lower the hardware requirements as much as possible, striving to ensure that readers can try and verify the examples without being hindered by hardware issues. Of course, in our model training part, we will also introduce branches for different hardware platforms, including a pure CPU version and a version that supports AMD graphics card accelerated computing, believing that everyone will be able to try without hardware limitations.
Of course, you might wonder: Can models trained with a CPU be useful? What’s the significance of such models? Indeed, if you want to train a model with complex functions or to solve complex tasks using a CPU, it’s quite difficult, but it’s still possible to use it to implement some specific and relatively simple functions.
In this article, we will cover how to train a large language model with a CPU and create a financial dataset required for training large language models. This may involve knowledge mentioned in my other articles, which I will not repeat here. If readers wish to delve deeper, please read my related articles, where relevant links will be provided.
Table of contents:
- Introduction
- About Large Language Model Datasets
- Creating the Dataset
- Data Processing
- Training Our Large Language Model
- Conclusion
- References
About Large Language Model Datasets
We know that at this stage, almost all large language models are based on Transformers. We won’t delve into the principles of Transformers in this article, but interested readers can refer to the official documentation for understanding. We only need to know that the methods for processing related datasets have been integrated into some mature libraries, such as 'Transformers' and 'tiktoken', and these data processing models can be conveniently found in the 'Transformers' library or 'tiktoken' library.1. Tokenizer
The tokenizer segmentation algorithm is the most basic component of NLP language models. Based on the tokenizer, text can be converted into a list of independent tokens, which can then be transformed into input vectors that computers can understand. In the tokenizer, we use pre-trained models for text normalization, pre-segmentation, segmentation based on the segmentation model, post-processing, and more. As mentioned before, the tokenizer also integrates various pre-trained models (such as GPT, GPT-2, GPT-J, GPT-Neo, RoBERTa, BART, LLaMA, AlBERT, T5, mBART, XLNet, etc.), and we can conveniently choose different pre-trained models to process data (of course, you can also train your own segmentation model).
2. Different Tokenizers Have Different Uses and Purposes:
- Encoder models: Main models include ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa, suitable for tasks that require understanding complete sentences, such as sentence classification, named entity recognition (and more generally, word classification), and extractive question answering.
- Decoder models: Main models include 'CTRL', 'GPT', 'GPT-2', Transformer XL. The pre-training of decoder models usually revolves around predicting the next word in a sentence. These models are best suited for tasks involving text generation.
- Encoder-decoder models: Main models include 'BART',' T5', 'Marian', 'mBART'. These models are most suitable for tasks revolving around generating new sentences based on given inputs, such as summarization, translation, or generative question answering.
To enable the model to recognize the beginning and end of sequences, we generally add special symbols when using the tokenizer for segmentation, such as [CLS], [SEP], etc. In this article, we will use ['<|endoftext|>'] as the sequence terminator.
Creating the Dataset
When training our own models, creating the dataset is often the biggest challenge, because there are plenty of tutorials on how to train a model with an existing dataset, but very few tell you how to create your own dataset. So, you might easily train a model, but have no idea how to create a dataset based on your own ideas. For this part, you can refer to my series of articles at "Data label for timeseries mining"(It includes 6 articles, including "Data label for time series mining(Part 1):Make a dataset with trend markers through the EA operation chart".), which I hope will give you some inspiration. Of course, you can also apply this knowledge to the training of large language models.
Now, let’s get back to our topic. We are still obtaining data from the MetaTrader5 client, and then processing the data. Considering we are running on a CPU, and given the performance of most PCs to date, we define our sequence length not too large. Otherwise, it would be too slow to run, resulting in a poor testing experience. Please note that the examples in this article are for demonstration purposes on how to train with a CPU, so the dataset creation and model training are just examples and the results may not be ideal. If you want better results, you might need to prepare a larger dataset or one that is more suited to the task expectations and perform additional data processing. You might also need to adjust the model parameters accordingly, but these topics will not be covered in this basic example.It's time to start creating the dataset step by step:
1. Defining Global Variables
Mainly used to define file paths.
DATA_DIR = os.path.dirname(__file__)
data_file = os.path.join(DATA_DIR, "llm_data.csv")2. Obtaining Data from the Client
Due to the limitations of training on a CPU, we will obtain data for a single currency pair with a length of 2500 data points as our initial data.
mt_data_len=2500 sr_len=60 if not mt.initialize(): print("mt initialize failed!") else: sbs=mt.symbols_get(group='*micro*') if sbs is not None: # for i in [mt.TIMEFRAME_M5,mt.TIMEFRAME_M15,mt.TIMEFRAME_H1,mt.TIMEFRAME_D1]:
Note:
We used the function 'mt.symbols_get(group='*micro*')' to get the currency pairs in our client, because my account is a micro account, so I used group='*micro*' to find currency pairs with "micro". If you are using a standard account, you need to remove this condition.otherwise, you won’t find any currency pairs. Of course, you can modify "micro" to match the currency pairs you’re interested in, such as using "GBP" to match all currency pairs with the British pound.
3. Splitting the Data
Considering the computational capabilities of a CPU, we will only take the "close" column from the quotes and start from index 0, taking every 60 quotes as a sequence and discarding sequences that are less than 60 in length. This way, we have simply created a collection of sequences, each 60 quotes in length. Of course, the length can be changed according to your personal CPU’s computing power. In principle, the longer the sequence, the better the potential effect. In the code, we used two for loops to control the selection of periods and varieties, which can easily add more periods and more currency pairs, and the dataset can be adjusted at any time as needed.
for i in [mt.TIMEFRAME_M5,]: xy=None # xy_list=[] ct=0 for j in sbs: if ct>0: break print(j.name) d_=mt.copy_rates_from_pos(j.name,i,0,mt_data_len) df_d=pd.DataFrame(d_) cl_d=df_d['close'] k=0 while k+1: if mt_data_len-k>=sr_len: cl_ds=cl_d[k:k+sr_len].tolist() if xy is None: xy=pd.DataFrame([cl_ds]) # xy_list=[cl_ds] else: xy.loc[len(xy)]=cl_ds # xy_list.append(cl_ds) k+=1 else: break ct+=1 mt.shutdown()
Note:
- We used the variable "ct" to control how many currency pairs’ data to get.
- "k" is used to control the data index offset to obtain sequence data. If the data sequence length is less than the length defined in the "sr_len" variable, it will stop adding sequences to the dataset "xy".
4. Writing the Processed Data to a File
Of course, this is just an optional step, you can also proceed with data processing without saving the file. However, since we will continue to use this data in the future and there’s no need to obtain it repeatedly, it is still recommended to save it.
xy.to_csv(data_file)At this point, our own dataset is complete. We will encapsulate this part of the code into a function for easy calling.
def get_data(): mt_data_len=2500 sr_len=60 if not mt.initialize(): print("mt initialize failed!") else: sbs=mt.symbols_get(group='*micro*') if sbs is not None: # for i in [mt.TIMEFRAME_M5,mt.TIMEFRAME_M15,mt.TIMEFRAME_H1,mt.TIMEFRAME_D1]: for i in [mt.TIMEFRAME_M5,]: xy=None # xy_list=[] ct=0 for j in sbs: if ct>0: break print(j.name) d_=mt.copy_rates_from_pos(j.name,i,0,mt_data_len) df_d=pd.DataFrame(d_) cl_d=df_d['close'] k=0 while k+1: if mt_data_len-k>=sr_len: cl_ds=cl_d[k:k+sr_len].tolist() if xy is None: xy=pd.DataFrame([cl_ds]) # xy_list=[cl_ds] else: xy.loc[len(xy)]=cl_ds # xy_list.append(cl_ds) k+=1 else: break ct+=1 mt.shutdown() # print(len(xy)," ",len(xy_list)) xy.to_csv(data_file) # xy.to_json(f'llm_data.json') return xyNote: As mentioned, the creation of the dataset in this article is just an example. You can completely change the parameters inside according to your own ideas and test them.
Data Processing
We have already mentioned tokenizers and now possess a dataset, the next step is to process the data using a tokenizer. In the example, we will use the tiktoken library and choose the pre-trained model "gpt2" to encode our dataset.1. Reading the Data
There are two methods to obtain the data we’ve created: one is to read the saved file, and the other is to directly use the return value of the get_data() function.
It’s important to note that if we read the saved file, we need to remove the extra first row and column added during the saving and reading process, while using the function’s return value does not require this.data=get_data() # data=pd.read_csv(data_file) # data=data.iloc[1:,1:]We will default to using the function’s return value to obtain the data.
2. Defining Variables
Here, we need to instantiate the tokenizer and define special tokens. As mentioned earlier, this article uses "<|endoftext|>" as the start and end of the sequence.
enc = tiktoken.get_encoding("gpt2") encode = lambda s: enc.encode_ordinary(s) eot = enc._special_tokens['<|endoftext|>'] train_tokens=[] val_tokens=[] val_cut=len(data)//10
Note:
The "val_cut" is used to split the training dataset and the validation set. If you want to change the ratio of the training set to the validation set, you can change the number 10 to a value you think is appropriate. In this example, 10% of the total length of the data is used as the validation set.
3. Defining the Function to Write to a Bin File
Before the final data processing, we need to define the function to write the processed data into a bin file.
def data_to_file(path, tks): header = np.zeros(256, dtype=np.int32) header[0] = 20240520 header[1] = 1 header[2] = len(tks) toks_np = np.array(tks, dtype=np.uint16) with open(path, "wb") as f: f.write(header.tobytes()) f.write(toks_np.tobytes())
This function itself is not difficult, but it’s important to note the value "header[0]=20240520", which may be used in the subsequent training of the large model. During the loading of data for training the large model, this value will be checked, and if it doesn’t match, an error will occur. This needs special attention!
4. Tokenizing the Data
First, we use a for loop to traverse each row of the dataset to get each sequence, with the variable "i" receiving the row number of the sequence and "r" receiving the sequence.
for i,r in data.iterrows():At this point, 'r' stores the data in Series format. We need to convert it to a list format first, then the list format into a string sequence, styled as "x,x,x,x,…". Of course, we could directly use f'{ser}' to convert the sequence into a string wrapped list style "[x,x,x,x,x,…]", but that seems a bit odd, so let’s stick with the "x,x,x,x,x,…" style. ser=r.tolist() ser= ''.join(str(elem) for elem in ser)
Next, we encode the sequence, storing the first 10% of the dataset into val_tokens and the remainder into train_tokens, and call the data_to_file() function to write them into their respective bin files:
tokens = encode(ser) if i< val_cut: val_tokens.append(eot) val_tokens.extend(tokens) enc_f = os.path.join(DATA_DIR, "val_data.bin") data_to_file(enc_f, val_tokens) else: train_tokens.append(eot) train_tokens.extend(tokens) enc_f = os.path.join(DATA_DIR, "train_data.bin") data_to_file(enc_f, train_tokens)Now, we have completed the process of tokenizing the data. The entire process from data acquisition to tokenization is concluded, and we will write this content into a file named "data_enc.py". The complete code for the entire file:
import MetaTrader5 as mt import pandas as pd import numpy as np import os import tiktoken DATA_DIR = os.path.dirname(__file__) data_file = os.path.join(DATA_DIR, "llm_data.csv") def get_data(): mt_data_len=2500 sr_len=60 if not mt.initialize(): print("mt initialize failed!") else: sbs=mt.symbols_get(group='*micro*') if sbs is not None: # for i in [mt.TIMEFRAME_M5,mt.TIMEFRAME_M15,mt.TIMEFRAME_H1,mt.TIMEFRAME_D1]: for i in [mt.TIMEFRAME_M5,]: xy=None # xy_list=[] ct=0 for j in sbs: if ct>0: break print(j.name) d_=mt.copy_rates_from_pos(j.name,i,0,mt_data_len) df_d=pd.DataFrame(d_) cl_d=df_d['close'] k=0 while k+1: if mt_data_len-k>=sr_len: cl_ds=cl_d[k:k+sr_len].tolist() if xy is None: xy=pd.DataFrame([cl_ds]) # xy_list=[cl_ds] else: xy.loc[len(xy)]=cl_ds # xy_list.append(cl_ds) k+=1 else: break ct+=1 mt.shutdown() # print(len(xy)," ",len(xy_list)) xy.to_csv(data_file) # xy.to_json(f'llm_data.json') return xy def data_to_file(path, tks): header = np.zeros(256, dtype=np.int32) header[0] = 20240520 header[1] = 1 header[2] = len(tks) toks_np = np.array(tks, dtype=np.uint16) with open(path, "wb") as f: f.write(header.tobytes()) f.write(toks_np.tobytes()) if __name__=="__main__": data=get_data() # data=pd.read_csv(data_file) # data=data.iloc[1:,1:] enc = tiktoken.get_encoding("gpt2") encode = lambda s: enc.encode_ordinary(s) eot = enc._special_tokens['<|endoftext|>'] train_tokens=[] val_tokens=[] val_cut=len(data)//10 for i,r in data.iterrows(): ser=r.tolist() ser=''.join(str(elem) for elem in ser) # ser = ser.strip() tokens = encode(ser) if i< val_cut: val_tokens.append(eot) val_tokens.extend(tokens) enc_f = os.path.join(DATA_DIR, "val_data.bin") data_to_file(enc_f, val_tokens) else: train_tokens.append(eot) train_tokens.extend(tokens) enc_f = os.path.join(DATA_DIR, "train_data.bin") data_to_file(enc_f, train_tokens) print(f"tain:{len(train_tokens)}",f"val:{len(val_tokens)}")Next, we will train our large model. Let’s go!
Note:
- The first time you use the tiktoken library for tokenization, it will connect to the internet to download the corresponding pre-trained model from huggingface, so make sure your network can access huggingface. If you cannot access it, please prepare magic in advance! Of course, you can also use a pre-prepared local model for tokenize, but this article will not discuss this part.
- Generally, large model data processing requires padding and mask processing of the data. Since our dataset is small and each sequence is of fixed length, we did not do so. But if you want to create a large and complex dataset, please carefully consider the selection and cleaning of data. This step is very important and greatly affects the quality of the model. Also, our dataset processing may be a bit rough, but it is sufficient for a demonstration example.
- The function of the tokenizer itself is to convert text into a list of numbers, and our data itself is numerical, so why tokenize? Personally, I believe the approach to processing depends on the final model task planning. The functions and tasks designed by the model determine the data processing method.
Training Our Large Language Model
Initially, this might seem like the most complex part, but with the help of the open-source project llm.c on GitHub, we only need to use its training files. The comments within all the files are very detailed, providing explanations for nearly every step, so there is no need for separate analysis or interpretation of the code in this article.1. Preparation Before Starting Training
llm.c project URL: https://github.com/karpathy/llm.c.
The example code platform in this article is the WSL environment deployed on Windows as previously introduced, using miniconda for the Python interpreter environment, with Python version 3.11.5.
Before starting the training, please use git clone to download the llm.c project and ensure that the libraries required by the project’s requirements.txt are installed, and that "make" is installed in WSL.
git clone https://github.com/karpathy/llm.c.git
cd llm.c
pip install -r requirements.txt2. Training Our Model
First, open the MetaTrader5 client on Windows to obtain data, and locate the position of the file data_enc.py (note that this file must also be placed in the Windows environment, I have not tested whether data can be obtained under WSL), and run the command "python data_enc.py".
python data_enc.pyAfter the script runs, we will generate two files in the same directory, "train_data.bin" and "val_data.bin", which we need to copy into the WSL file system. Of course, since WSL can completely read the contents of the Windows file system, copying the files is not a mandatory step.
After obtaining the data, we also need to run the "train_gpt2.py" file in the root directory of the llm.c project. There are two options for reference:
- Directly modify the default value of "--input_bin" in line 397 of "train_gpt2.py" to replace it with the path of our data file, such as "dev/data/mt5/val_data.bin", and then run "python train_gpt2.py".
- Directly add parameters in the command line to locate our data file, for example, "python train_gpt2.py --input_bin dev/data/mt5/val_data.bin".
We chose to run this file with arguments on the command line.
python train_gpt2.py --input_bin dev/data/mt5/val_data.binRunning results:

Ah ha, it turns out to be this: "<|endoftext|>40% of the remaining 80% of the remaining 20% of the remaining 40". This test output seems a bit unexpectedly strange! But it should not stop us from moving forward, so we continue!
As a matter of fact, the "train_gpt2.py" file does not completely train our model, its task is to take a batch from our dataset to initialize the model and will save four ".bin" format files:
- Model parameter files are saved in "float32" and "bfloat16" formats (files are "gpt2_124M.bin" and "gpt2_124M_bf16.bin", respectively);
- Tokenizer file, named "gpt2_tokenizer.bin";
- File for debugging C, "gpt2_124M_debug_state.bin".
During the script run, a few steps of inference will be performed and results outputted, which serves as a preliminary test of the model. The other code in the file will not be interpreted further in this article, as the source code provides very detailed comments, allowing readers to clearly understand the entire process.
After running the "train_gpt2.py" script, we need to compile the training code. But before compiling, we also need to modify the data reading path in the source code "train_gpt2.c" for training on the CPU. Around line 1041 of this C file, there are two constants defined, "const char* train_tokens" and "const char* val_tokens", and we need to change their values to our own "train_data.bin" and "val_data.bin" paths. For example, after my modification:
const char* train_tokens = "dev/data/mt5/train_data.bin"; const char* val_tokens = "dev/data/mt5/val_data.bin";
Please remember not to forget the ";" at the end of the statement, which is different from Python syntax! Similarly, I do not want to interpret too much of the source code of this file, as the author’s source code contains detailed comments, making it easy to understand the entire training process.
After modifying the source code, run "make train_gpt2" directly in the command line. If you have not installed the CUDA acceleration computing library, then this command will directly compile the training source code into a program that can run on the CPU.
As shown in the figure:
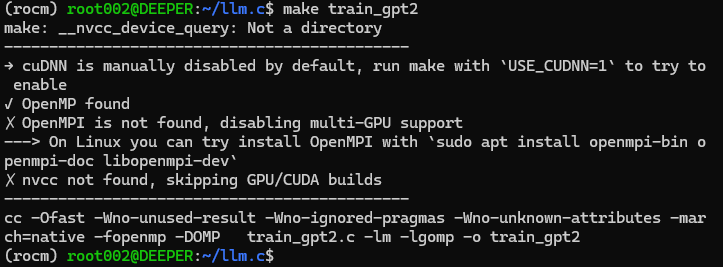
If you have successfully compiled the training program, we can now officially start training our large language model. Directly run the command "OMP_NUM_THREADS=10 ./train_gpt2" in the command line, where the "OMP_NUM_THREADS" parameter specifies the number of threads you use. Please set an appropriate value according to the total number of threads supported by your hardware device.
Running results:

The test output during this training process is:
```
generating: --- 30.605360.605540.605590.605510.605650.605510.605650.60550.605550.605540.605590.605540.605590.606107<|endoftext|>0.605640.60 --- ```
Now, looking back at the original data, the values in my own "llm_data.csv" file are as shown:

Let’s compare. The original values are mostly around 0.6, so it seems that the output lacks separators. As mentioned earlier, our data format is "x,x,x,x,…", but the output looks like "xxxxxxx…". However, I don’t think this is a problem because our idea has been validated, the large model trained simply can output the results we want! This path is feasible, and the minor issues can be resolved by optimizing the encoding and decoding process.
Since this is just a demonstration example, we have not mentioned saving the model or testing trading strategies in the client. Moreover, the model trained on the CPU does not need to be saved and tested due to precision issues. I think if you want the model to be truly usable, you may need to establish a scientific process and put in more effort. For example, designing datasets for specific tasks, formulating appropriate trading strategies, designing and training an encoder and decoder model that meets the requirements of the task, setting model hyperparameters, etc. All these require a lot of practice to complete, and it’s unlikely to be clearly explained in a few articles, so this process still requires readers to explore on their own. This article only provides you with more possibilities.
Of course, this also raises a question of how to use our trained language model in trading strategies or testing. The simplest example is that we can run the large model inference service in a Python environment, and then send service requests through the trading strategy EA via socket, with the inference service calculating the results and returning them to the EA. This part of the content is detailed in my " Data label for time series mining (Part 5):Apply and Test in EA Using Socket " article, and interested readers can try it out. This article will not discuss the related content again!
The data processing script file and the obtained data file are attached at the end of the article, and the processed bin format file is not included in the attachment because the bin format upload is not supported!
Note:
In the mnt directory under the WSL root, you can find all the drive letters of our Windows, and you can locate the files in Windows under the corresponding drive letter from WSL, such as "/mnt/g/Program Files". It should be noted that if the name of the Windows folder contains spaces, as in the example, we cannot enter this folder directly with "cd /mnt/g/Program Files", we need to use quotes to wrap the folder name with space characters, "cd /mnt/g/'Program Files'" is the correct method.
Conclusion
It’s incredible, we have successfully trained our own large language model using only a CPU!
But don’t get too excited too soon, this article only demonstrates how to train our own large language model with a CPU using a simple example, and it is obviously constrained by hardware conditions. The model trained with a CPU may have a single function and not perform as well, but it is undeniable that it can also be a choice for implementing specific strategies in quantitative trading.
In the next article, we will introduce how to use graphics cards to accelerate the training of our model. If you are using an AMD graphics card, you might be annoyed to find that AMD acceleration is not supported in various common libraries (of course, I’m talking about the current stage, that is, when the author wrote this article. From a long-term perspective, I still believe that AMD’s AI ecosystem will become better in the near future! Or an AI ecosystem like "llama.cpp" that supports all platforms will become more popular!), so in line with the original intention of covering all platforms as much as possible, we will discuss how to use AMD graphics cards to accelerate the training of our large language model in the next article! I may not discuss how to use NVIDIA graphics cards for accelerated computing, because I am currently using the AMD platform, but if you can use AMD for accelerated training, there is no need to go the extra mile with NVIDIA, which has a better AI ecosystem, right?
See you in our next article!
References
llm.c: https://github.com/karpathy/llm.c.gitWarning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use