
您应当知道的 MQL5 向导技术(第 12 部分):牛顿多项式
概述
时间序列分析不仅在支持基本面分析方面扮演着重要角色,并且在像外汇这样流动性很强的市场中,它也成为决定如何在市场中定位的主要驱动力。传统的技术指标往往远远滞后于市场,这令它们不受大多数交易者的青睐,导致替代品的兴起,其中最主要的大概就是目前盛行的神经网络。但是多项式插值呢?
嗯,它们具有一些优势,主要是因为它们易于理解和实现,因为它们以一个简单的方程式就明确表述了过去的观察与未来预测之间的关系。这有助于理解过去的数据如何影响未来的价值,进而导致针对所研究时间序列行为发展出广泛的概念和可能的理论。
此外,对线性和二次关系的适配性令它们能够灵活地应用于各种时间序列,并且对于交易者可能更适宜,能够应对不同的市场类型(例如,区段与趋势、或波动与平静市场)
甚而,典型情况下它们非计算密集型,并且比之神经网络等替代方式相对轻量级。事实上,本文中验证的模型具有零存储需求,您或许会说某类神经网络,取决于其架构,在每次阶段性训练后,要存储大量最优权重和偏差。
故此,正式的牛顿插值多项式 N(x) 如方程定义:

其中,在序列中所有 x j 都是唯一的,a j 是差商之和,而 n j (x) 是 x 基准系数的乘积和,正式的表示如下:

差商和基准系数公式可以很容易地独立查找,不过我们尝试于此尽可能非正式地解读它们的定义。
差商是一个重复的除法过程,它在每个指数处设置 x 的系数,直到穷尽所提供数据集中所有 x 指数。为了概括这一点,我们研究下面的三个数据点示例:
(1,2), (3,4), 和 (5,6)
对于差商,所有用到的 x 值都需要是唯一的。所提供数据点的数量推断出所推导的牛顿式多项式中 x 的最高指数。举例,如果我们只有 2 个点,那么我们的方程就简化为线性的,其形式为:
y = mx + c.
意即我们的最高指数是一。因此,对于我们的三点示例,最高指数是 2,意味着我们需要为所推导多项式得到 3 个不同的系数。
按部就班获取这 3 个系数中的每一个,迭代过程直至我们到达第三个系数。上面分享的链接中有公式,但理解这一点的最好方式大概就是使用如下所示的表格:
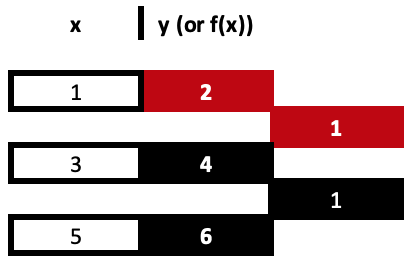
故此,我们差商的第一列是通过 y 值与各自 x 值的变化除以差值得到的。记住,所有 x 值都需要是唯一的。这些计算十分简单明了,不过它们很容易按上面所示的表格追从,更胜分享链接中引用的典型公式。两种方式都会得到相同的结果。
= (4 - 2) / (3 - 1)
给出我们的第一个系数 1。
= (6 - 4) / (5 - 3)
给出我们类似的第二个系数。系数以红色高亮显示。
从我们的 3 个数据点示例中,得到的最终值是刚刚计算出 y 差值,其 x 作为分母
这将是 x 序列中的两个极值,因为它们的差值将是除数,因此我们的表格将按如下方式完成:

在上面的完整表格中,我们有 3 个派生值,但其中只有 2 个用于获取系数。因此,这导致我们得出“基准多项式”的乘积和。尽管听起来很花哨,但实际上它甚至比差商还要直接。故此,为了概述这一点,基于我们从上表中导出的系数,这三个点的方程式为:
y = 2 + 1*(x – 1) + 0*(x – 1)*(x – 3)
由这得到:
y = x + 1
所加括号是构成基准多项式的全部。x n 值只是每个采样数据点的相应 x 值。现在回到系数,您会注意到,作为一项规则,我们只取表格顶部的值作为括号里的数值前缀,且当我们向右推进缩短表格列时,顶部值充当较长括号序列的前缀,直到所供数据点全部考察完毕。如前所述,数据点插值越多,x 的指数就越多,因此我们的派生表中的列就越多。
在转到实现之前,我们再举一个好玩的例子。假设我们有 7 个证券价格数据点,其中 x 值只是价格柱索引,如下所示:
| 0 | 1.25590 |
| 1 | 1.26370 |
| 2 | 1.25890 |
| 3 | 1.25395 |
| 4 | 1.25785 |
| 5 | 1.26565 |
| 6 | 1.26175 |
我们的表格传播系数值将扩展到 8 列,如下所示:

参考红色高亮显示系数,因此其公式如下:
y = 1.2559 + 0.0078*(x – 0) – 0.0063*(x – 0)*(x – 1) + …
很明显,给定的 7 个数据点,这个方程的指数级上升到 6,理论上,它的关键功能应当是通过在方程中输入新的 x 索引来预测下一个值。如果采样数据“设置为序列”,则下一个索引将为 -1,否则为 8。
MQL5 实现
利用 MQL5 实现这一点,可以通过最少的编码来达成,然而值得一提的是,我尚未遇到能让这些思路运行起来的函数库,例如来自现成的类实例。
若要做到这一点,我们需要做基础的两件事。首先,我们需要一个函数,遵照我们的方程来计算给定采样数据集的 x 系数。其次,我们还需要一个函数,依据得出的 x 值,按我们的方程处理预测值。这听起来很直截了当,但考虑到我们希望以可伸展方式执行此操作,这就需要在处理步骤中留意一些注意事项。
那么,在我们投入之前,“可伸展方式”意味着什么?我所指的函数,可以使用差商针对未预先确定规模的数据集得出系数。这也许听起来很明显,但如果我们参考我们的前 3 个数据点示例,获取系数的 MQL5 实现给出如下。
下面的清单包含获取样本数据内两个对的差商的方程,迭代该过程直至获得最后一个值。现在,如果我们有一个 4 个数据点的样本,那么在等式里插值需要一个不同的函数,因为比之上面 3 点示例中所示的步骤,我们要执行的步骤更多。
故此,如果我们有一个可伸展的函数,它将能够处理 n 个大小的数据集,并输出 n-1 个系数。这是由以下清单达成的:
//+------------------------------------------------------------------+ //| INPUT PARAMETERS | //| X - vector with x values of sampled data | //| Y - vector with y values of sampled data | //| OUTPUT PARAMETERS | //| W - vector with coefficients. | | //+------------------------------------------------------------------+ void Cnewton::Set(vector &W, vector &X, vector &Y) { vector _w[]; ArrayResize(_w, int(X.Size() - 1)); int _x_scale = 1; int _y_scale = int(X.Size() - 1); for(int i = 0; i < int(X.Size() - 1); i++) { _w[i].Init(_y_scale); for(int ii = 0; ii < _y_scale; ii++) { if(X[ii + _x_scale] != X[ii]) { if(i == 0) { _w[i][ii] = (Y[ii + 1] - Y[ii]) / (X[ii + _x_scale] - X[ii]); } else if(i > 0) { _w[i][ii] = (_w[i - 1][ii + 1] - _w[i - 1][ii]) / (X[ii + _x_scale] - X[ii]); } } else { printf(__FUNCSIG__ + " ERR!, identical X value: " + DoubleToString(X[ii + _x_scale]) + ", at: " + IntegerToString(ii + _x_scale) + ", and: " + IntegerToString(ii)); return; } } _x_scale++; _y_scale--; W[i + 1] = _w[i][0]; if(_y_scale <= 0) { break; } } }
该函数运作时,用到两个嵌套的 for 循环,以及两个跟踪 x 和 y 值索引的整数。这也许不是实现它的最有效方式,但在缺乏实现它的标准库情况下,它能起作用,我鼓励探索它,甚至根据个人的用例对其进行改进。
给定 x 输入和我们所有的方程系数,处理下一个 y 的函数也分享如下:
//+------------------------------------------------------------------+ //| INPUT PARAMETERS | //| W - vector with pre-computed coefficients | //| X - vector with x values of sampled data | //| XX - query x value with unknown y | //| OUTPUT PARAMETERS | //| YY - solution for unknown y. | //+------------------------------------------------------------------+ void Cnewton::Get(vector &W, vector &X, double &XX, double &YY) { YY = W[0]; for(int i = 1; i < int(W.Size()); i++) { double _y = W[i]; for(int ii = 0; ii < i; ii++) { _y *= (XX - X[ii]); } YY += _y; } }
这也比我们之前的函数更直接了当,尽管它也有一个嵌套循环,我们所做的只是跟踪我们在 set 函数中获得的系数,并将它们分配给相应的牛顿基准多项式。
应用:
其应用范围很广,至于本文,我们将研究如何将其用作信号、尾随停止方法、和资金管理方法。开始编写代码之前,通常最好准备一个包含两个实现内插的函数的捆绑类,其代码清单如上。对于这样的类,我们将有如下所示接口:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Cnewton { private: public: Cnewton(); ~Cnewton(); void Set(vector &W, vector &X, vector &Y); void Get(vector &W, vector &X, double &XX, double &YY); };
信号
MQL5 函数库中提供的标准智能交易信号类文件一如既往地作为某些人开发自定义实现的健康指南。在我们的案例中,为了生成多项式的输入样本数据,第一个明显选择应是原始证券收盘价。为了生成基于收盘价的多项式,我们首先分别取价格柱线索引和实际收盘价来填充 x 和 y 向量。这两个向量是我们的 'set' 函数的关键输入,它负责获取系数。附注,我们只是在信号中使用 x 的价格柱线索引,但可以使用替代方案,诸如交易日或交易周中的时段,当然,前提是这些数据样本中没有重复项,即它们都只出现一次,例如,如果您的交易日有 4 个时段,那么您只能提供不超过 4 个的数据点,且时段索引 0、1、2 和 3 在数据集内仅能出现一次。
填充 x 和 y 向量后,调用 'set' 函数应能为我们的多项式方程提供初期系数。如果我们配以这些系数及下一个 x 值运行这个方程,调用 'get' 函数后我们会得到下一个 y 值的预测。由于我们在 set 函数中输入的 y 值是收盘价,我们的愿望是获得下一个收盘价。下面分享该段代码:
double _xx = -1.0;//m_length + 1.0, double _yy = 0.0; __N.Get(_w, _xx, _yy);
除了获取下一个预测的收盘价外,EA 信号类的检查开仓函数典型情况下会输出一个 0 – 100 范围内的整数,作为买入或卖出信号强度的标志。因此,在我们的案例中,我们需要找到一条途径,把预计收盘价表示为适合该范围的简单整数。
为了获得这种常规化,预计收盘价变化表达成当前(最高价 - 最低价)范围的百分比。然后,该百分比表达成 0 – 100 范围内的整数。这意味着“检查开多头”函数中的负收盘价变化将自动归零,“检查开空头”函数中的正预测变化也将自动归零。
m_high.Refresh(-1); m_low.Refresh(-1); m_close.Refresh(-1); int _i = StartIndex(); double _h = m_high.GetData(m_high.MaxIndex(_i,m_length)); double _l = m_low.GetData(m_low.MinIndex(_i,m_length)); double _c = m_close.GetData(0); // if(_yy > _c) { _result = int(round(((_yy - _c) / (fmax(_h, fmax(_yy, _c)) - fmin(fmin(_yy, _c), _l))) * 100.0)); }
在通过多项式方程进行预测时,我们唯一用到的变量是回溯期的长度(其设置为采样数据大小)。该变量标记为 'm_length'。如果我们仅针对此参数运行优化,涵盖 2023 年、H1 时间帧、品种 EURJPY 的数据,我们将得到以下报告。


涵盖全年的完整运行为我们给出如下净值图:

尾随停止
除了 EA 信号类之外,我们还可以经由向导拼装一款智能系统,选择一种设置和调整持仓尾随停止的方法。标准库中提供了利用抛物线 Sar,和移动平均线的方法,总体上,它们的数量比信号库中的数量要少得多。如果我们通过添加一个使用牛顿多项式的类来改善这个计数,那么按理我们的采样数据必须是价格柱线范围。
因此,如果我们在预测下一个收盘价时遵循上述相同的步骤,主要变化是 y 向量的数据,在本例中现在将是价格柱线范围,那么我们的源码将如下所示:
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for long position. | //+------------------------------------------------------------------+ bool CTrailingNP::CheckTrailingStopLong(CPositionInfo *position, double &sl, double &tp) { //--- check ... //--- m_high.Refresh(-1); m_low.Refresh(-1); vector _x, _y; _x.Init(m_length); _y.Init(m_length); for(int i = 0; i < m_length; i++) { _x[i] = i; _y[i] = (m_high.GetData(StartIndex()+i)-m_low.GetData(StartIndex()+i)); } vector _w; _w.Init(m_length); _w[0] = _y[0]; __N.Set(_w, _x, _y); double _xx = -1.0; double _yy = 0.0; __N.Get(_w, _x, _xx, _yy); //--- ... //--- return(sl != EMPTY_VALUE); }
然后使用该预测柱线范围的一部分来设置持仓停止的大小。所用比例是一个可优化的参数 'm_stop_level',在设置新的停止之前,我们将最小停止距离添加到该增量,从而避免任何经纪商报错。该常规化由以下代码捕获:
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for long position. | //+------------------------------------------------------------------+ bool CTrailingNP::CheckTrailingStopLong(CPositionInfo *position, double &sl, double &tp) { //--- check ... //--- sl = EMPTY_VALUE; tp = EMPTY_VALUE; delta = (m_stop_level * _yy) + (m_symbol.Point() * m_symbol.StopsLevel()); //--- if(price - base > delta) { sl = price - delta; } //--- return(sl != EMPTY_VALUE); }
如果我们经由 MQL5 向导拼装一款智能系统,使用标准库的动量震荡器 EA 信号类,并尝试仅针对理想的多项式长度进行优化,对于与上述相同的品种、时间帧、和 1 年区间,我们得到以下报告作为我们的最佳案例:


结果充其量只是乏善可陈。有趣的是,如果出于对照,我们运行相同的 EA,但使用基于移动平均线的尾随停止,我们得到“更佳”成果,如以下报告所示:


这些更佳成果可以归因于优化了更多的参数,而不仅仅是我们对多项式的优化,事实上,与不同的智能信号配对可能会产生完全不同的结果。尽管如此,出于对照实验目的,这些报告可以作为一份指南,展现牛顿多项式在管理持仓停止方面的潜力。
资金管理
最后,我们研究牛顿多项式如何有助于调仓,这由标记为 “CExpertMoney” 的第三方内置向导类处理。那么如何做呢。我们的多项式可以帮助解决这个问题吗?当然,为了取得最佳用法,可以采取许多方向,不过我们将研究把柱线范围的变化视为波动性指标,从而指导我们如何调整固定保证金持仓规模。我们的简单论点是,如果我们预测价格柱线范围会增加,那么我们会按比例减少我们的持仓规模,然而若它没有增加,那么我们什么都不做。由于预计波动性下降,我们不会有所增长。
我们的源代码可以帮助我们解决这个问题,如下所示,其中与我们上述内容类似的部分都被裁剪掉了。
//+------------------------------------------------------------------+ //| Optimizing lot size for open. | //+------------------------------------------------------------------+ double CMoneySizeOptimized::Optimize(double lots) { double lot = lots; //--- 0 factor means no optimization if(m_decrease_factor > 0) { m_high.Refresh(-1); m_low.Refresh(-1); vector _x, _y; _x.Init(m_length); _y.Init(m_length); for(int i = 0; i < m_length; i++) { _x[i] = i; _y[i] = (m_high.GetData(StartIndex() + i) - m_low.GetData(StartIndex() + i)) - (m_high.GetData(StartIndex() + i + 1) - m_low.GetData(StartIndex() + i + 1)); } vector _w; _w.Init(m_length); _w[0] = _y[0]; __N.Set(_w, _x, _y); double _xx = -1.0; double _yy = 0.0; __N.Get(_w, _x, _xx, _yy); //--- if(_yy > 0.0) { double _range = (m_high.GetData(StartIndex()) - m_low.GetData(StartIndex())); _range += (m_decrease_factor*m_symbol.Point()); _range += _yy; lot = NormalizeDouble(lot*(1.0-(_yy/_range)), 2); } } //--- normalize and check limits ... //--- return(lot); }
再一次,如果我们仅针对多项式回溯周期运行优化,并采用我们尾随停止 EA相同的信号类、依据同一品种、涵盖同一区间的时间帧内,我们得到以下报告:


该智能系统未在向导中选择尾随停止方法,本质上使用来自动量振荡器的原始信号,如果预测到波动性,则仅有的变化就是降低持仓规模。
作为对照,我们在 EA 里使用内置的 “规模优化” 资金管理类、采用类似信号、且无尾随停止。该 EA 允许仅调整构成分母的递减因子,并按智能系统所遭受的损亏损按比例降低持仓规模。如果我们采用最佳设置执行测试,我们将得到以下报告。


与我们采用牛顿多项式进行资金管理相比,结果显然相形见绌,正如我们在尾随类中看到的那样,其本身并非指责持仓规模优化系统,但出于我们的比较目的,它可能意味着我们基于牛顿多项式实线的资金管理方式,是更好的选择。
结束语
总之,我们已经查看了牛顿多项式,这是一种从一组几个数据点推导出多项式方程的方法。这个多项式,以及上一篇文章中研究过的数字墙,或者前面的约束玻尔兹曼机,它代表了思路的概述,这些思路能以超出本系列所研究的方式运用。
有一种新兴的思想流派认为,支持者在分析市场时坚持久经考验的方法,这些文章并不反对这一点,但鉴于我们所处的情况是从比特币到股票、债券,甚至大宗商品,一切都在很大程度上是相关的,这会是系统性事件的预兆吗?在轻松赚钱的时代,很容易忽视优势,因此这些系列可以被视为倡导新的、且通常不受欢迎的方式的一种手段,这些可在我们涉足未知领域时提供一些急需的保险。
言归正传,牛顿多项式确实存在局限性,如上面的测试报告所示,这主要是因为它们无法过滤掉白噪声,这意味着它们在与其它解决该问题的指标配合时有潜力更好地运作。MQL5 向导允许将多个信号配对到单一智能交易系统中,因此可以使用一个过滤器、甚至多个过滤器来获得更好的智能交易信号。尾随类和资金管理模块不允许这样做,故要进行更多测试,从而找出哪些尾随和资金管理类与该信号更般配。
故此,无法过滤白噪声可归因于多项式倾向于过度拟合采样数据,这是由捕获所有摆动,取代处理底层形态造成的。这往往涉及记忆噪声,它确实会导致样本外数据的性能不佳。金融时间序列往往还具有不断变化的统计属性(均值、方差、等等)、及非线性动态,其中价格的急剧变化可能是常态。牛顿多项式基于平滑多项式曲线,难以捕捉如此复杂局面。最后,它们无法整合财经情绪和基本面,这确实意味着它们应该与上述相应的财经指标配对。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/14273
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
谢谢你,斯蒂芬,非常有趣的主题,写得很好。下载中是否应该有Cnewton.mqh?我在 SignalWZ_12.mqh 中找不到 Cnewton.mqh,这三个示例中似乎都提到了它。
感谢斯蒂芬的想法,我现在正在寻找使用牛顿多项式的其他方法,非常感谢。