
MLP (многослойный перцептрон) внутри советника MQL5: Обучение на истории без Python и без файлов весов

Обучаемый внутри советника MLP: нейросеть без Python и без файлов весов
Вы пишете советник под MQL5 и хотите добавить ML-фильтр направления, но схема "обучили в Python → выгрузили веса → подключили файл" постоянно создаёт технические риски: рассинхрон нормализации, потерю или неправильную версию весов, несовпадение логики признаков между офлайном и терминалом. В итоге фильтр может вести себя нестабильно, а отладка превращается в поиск различий между двумя кодовыми базами.
Задача этой статьи намеренно прикладная: не построить "большую нейромодель", а получить компактный MLP-gate, который обучается на истории текущего символа и таймфрейма, периодически переобучается и работает только на закрытых барах. Такой фильтр не заменяет полноценный исследовательский ML-пайплайн, но решает конкретную инженерную проблему советника: убрать внешние зависимости и сделать обучение, признаки, нормализацию и инференс частью одного .mq5.
Ранее в проекте MLP обучали офлайн в Python, экспортировали файл весов и загружали его в советник. Такая схема работала, но регулярно порождала операционные ошибки: разные скейлеры, разные версии признаков, забытые файлы в MQL5\Files и сложную диагностику, когда поведение в тестере не совпадало с ожиданиями от Python-модели. Здесь предлагается другой подход: обучать небольшой MLP прямо в самом советнике на истории того же инструмента, где он будет применяться.
Целевой результат статьи — один самодостаточный GridSurvivor_MLP.mq5: на новом баре он собирает обучающую выборку, формирует признаки и метки без утечек, обучает MLP с ReLU + softmax, пишет в лог валидационную диагностику, переобучается каждые N баров и использует прогноз сети как последний gate после дивергенции и HTF-фильтра. Критерий готовности простой: сеть обучается без внешних файлов, инференс идёт строго на shift=1, а поведение при неготовой модели управляется InpMlpFailOpen.
У обучения в терминале есть три важных преимущества для торгового робота:
- Нет рассинхрона нормализации. Признаки вычисляются одной и той же функцией и при обучении, и при инференсе. Самая коварная ошибка прошлого подхода — разные скейлеры в Python и MQL5 — здесь устраняется на уровне архитектуры.
- Адаптация к инструменту и режиму. Сеть учится на реальной истории конкретного символа и ТФ, а не на абстрактном датасете. При запуске на GBPUSD она видит характер GBPUSD, при переобучении раз в N баров — подстраивается под смену рыночного режима.
- Самодостаточность. Советник распространяется одним файлом. Нет внешних зависимостей, которые можно потерять, перепутать по версии или забыть положить в MQL5\Files.
Плата за это — обучение в терминале требует процессорного времени. Кроме того, маленькая сеть на коротких признаках не выучит того, что могла бы выучить большая модель на богатом датасете в Python. Это осознанный размен: для роли адаптивного фильтра входа цельность, повторяемость и простота сопровождения важнее максимального потолка качества.
Что предсказывает сеть и как она встроена в gate
MLP здесь не является самостоятельной торговой системой. Его роль уже и практичнее: быть последним фильтром входа, который отвечает на один вопрос — подтверждает ли локальная статистика рынка направление кандидата, найденного базовой логикой советника. Поэтому вся цепочка принятия решения выглядит так: дивергенция RSI находит кандидат BUY/SELL, HTF-фильтр проверяет старший контекст, а MLP-gate пропускает сделку только при достаточном совпадении прогноза сети с направлением кандидата.
Сеть — это классификатор двух классов: "вниз" и "вверх". На вход подаётся вектор признаков, описывающих состояние рынка на закрытом баре; на выходе через softmax получаются две вероятности — P(down) и P(up) на горизонт InpMlpHorizon баров вперёд. Их разность P(up) − P(down) — это направленная уверенность сети: положительная означает ожидание роста, отрицательная — ожидание падения.
Связка "метка → горизонт → порог gate" принципиальна. Метка учит сеть различать, куда цена ушла через InpMlpHorizon баров, а InpMlpThreshold задаёт минимальную величину преимущества одного класса над другим. Если разность вероятностей мала, модель не даёт достаточно сильного мнения, и кандидат лучше отклонить.
Дивергенция RSI по-прежнему генерирует кандидата с направлением dir (+1 для BUY, −1 для SELL). MLP-gate пропускает кандидата только если сеть согласна с этим направлением достаточно уверенно:
bool ok = (dir == 1) ? (conf >= InpMlpThreshold)
: (conf <= -InpMlpThreshold);
BUY-кандидат проходит при прогнозе роста с уверенностью не ниже порога; SELL-кандидат — при прогнозе падения. Если дивергенция указывает вверх, а сеть уверенно ждёт падения — сигнал отклоняется. Получается двойное подтверждение: формальный паттерн и обученная оценка направления должны совпасть. Порядок фильтров остаётся прежним: дивергенция → HTF-фильтр → MLP. MLP стоит последним, потому что он дороже остальных проверок и должен срабатывать только для уже найденного кандидата, а не на каждом промежуточном условии.
Обратите внимание: направление кандидата dir в признаки не входит. Сеть оценивает рынок беспристрастно, предсказывая собственное направление, а согласование с dir происходит уже снаружи, в gate. Это честнее, чем подавать dir на вход: иначе сеть могла бы научиться просто повторять сторону кандидата.
Признаки
Восемь признаков, каждый вычислим на произвольном сдвиге shift (это критично: обучение пробегает историю по разным барам) и нормирован к масштабу порядка единицы:
| # | Признак | Формула | Смысл |
|---|---|---|---|
| 0 | Уровень RSI | rsi[shift] / 50 − 1 | Перепроданность/перекупленность |
| 1 | Короткий наклон RSI | (rsi₀ − rsi₃) / 10 | Скорость импульса |
| 2 | Длинный наклон RSI | (rsi₀ − rsi₆) / 10 | Среднесрочная динамика |
| 3 | Дистанция до EMA(50) | (close − EMA) / ATR | Положение относительно тренда |
| 4 | Режим волатильности | ATR / (close · 0.001) | Спокойно или бурно |
| 5 | Час (sin) | sin(2π·h / 24) | Сессия, циклически |
| 6 | Час (cos) | cos(2π·h / 24) | Сессия, циклически |
| 7 | Импульс | (close₀ − close₆) / ATR | Сила движения в ATR |
Для признака дистанции до тренда используется EMA(50) текущего таймфрейма, а не старшего (в отличие от HTF-фильтра входа). Причина техническая: буфер индикатора со старшего ТФ индексируется барами старшего ТФ, и обращаться к нему по сдвигу текущего ТФ при пробеге истории — прямой путь к рассогласованию. EMA текущего ТФ читается корректно на любом shift через CopyBuffer.
//+------------------------------------------------------------------+ //| Сбор вектора признаков на сдвиге shift (8 значений). | //| Считается одинаково при обучении и при инференсе → нет | //| рассинхрона нормализации. | //+------------------------------------------------------------------+ bool MlpFeatures(int shift, double &f[]) { double rsi[]; ArraySetAsSeries(rsi,true); if(CopyBuffer(g_rsiHandle,0,shift,7,rsi)<7) return(false); double atr[]; ArraySetAsSeries(atr,true); // Для ATR берём значение на shift и соседний элемент, чтобы расчёт был корректным. if(CopyBuffer(g_atrHandle,0,shift,2,atr)<2 || atr[0]<=0.0) return(false); double cl[]; ArraySetAsSeries(cl,true); if(CopyClose(_Symbol,_Period,shift,7,cl)<7) return(false); double ema[]; ArraySetAsSeries(ema,true); if(CopyBuffer(g_featMaHandle,0,shift,1,ema)<1) return(false); datetime bt = iTime(_Symbol,_Period,shift); MqlDateTime mt; TimeToStruct(bt,mt); double ang = 2.0*M_PI*mt.hour/24.0; ArrayResize(f,MLP_NIN); f[0] = rsi[0]/50.0 - 1.0; // уровень RSI f[1] = (rsi[0]-rsi[3])/10.0; // короткий наклон RSI f[2] = (rsi[0]-rsi[6])/10.0; // длинный наклон RSI f[3] = (cl[0]-ema[0])/atr[0]; // дистанция до EMA в ATR f[4] = atr[0]/(cl[0]*0.001); // режим волатильности f[5] = MathSin(ang); // час (циклически) f[6] = MathCos(ang); f[7] = (cl[0]-cl[6])/atr[0]; // импульс, нормированный ATR return(true); }
Метка
Метка для бара — направление будущего движения. Если через InpMlpHorizon баров цена выше — класс 1 (вверх), если ниже — класс 0 (вниз). Будущий бар в series-индексации — это shift − Horizon (более новый), и при shift > Horizon он уже закрыт, так что заглядывания в будущее нет: на момент обучения исход известен из истории. Параметр InpLabelMinPts отсекает бары с движением меньше заданного — это шумовой фильтр, чтобы сеть не училась на дрожании цены вокруг нуля.
//+------------------------------------------------------------------+ //| Формирование метки для обучающего примера на баре shift. | //| Возвращает 1, если через InpMlpHorizon баров цена выше, | //| иначе 0. Отсекает шум через InpLabelMinPts. | //+------------------------------------------------------------------+ bool MlpLabel(int shift, int &label) { if(shift < InpMlpHorizon+1) return(false); double cn[],cf[]; if(CopyClose(_Symbol,_Period,shift,1,cn)<1) return(false); if(CopyClose(_Symbol,_Period,shift-InpMlpHorizon,1,cf)<1) return(false); double move=(cf[0]-cn[0])/_Point; if(InpLabelMinPts>0.0 && MathAbs(move)<InpLabelMinPts) return(false); label = (move>0.0) ? 1 : 0; return(true); }
Сеть, которая учится: класс CMlpNet
В отличие от инференс-движка из прошлого варианта, эта сеть умеет обучаться. Архитектура: вход → один скрытый слой с ReLU → softmax-выход на два класса. Веса хранятся плоскими массивами в порядке row-major: W1[j·nIn + i] — вес связи входа i с нейроном j скрытого слоя, W2[k·nHid + j] — вес связи нейрона j с выходом k. Инициализация — метод He со стандартным отклонением sqrt(2/n_in), правильным для ReLU.
Прямой проход: скрытый слой считает взвешенные суммы, применяет ReLU, выходной слой даёт логиты, softmax превращает их в вероятности.
//+------------------------------------------------------------------+ //| Прямой проход: вход x → вероятности классов probs. | //| Сохраняет z1 и h для обратного распространения. | //+------------------------------------------------------------------+ void Forward(const double &x[], double &probs[]) { for(int j=0;j<m_nHid;j++) { double z=m_b1[j]; for(int i=0;i<m_nIn;i++) z+=m_W1[j*m_nIn+i]*x[i]; m_z1[j]=z; m_h[j]=ReLU(z); } ArrayResize(probs,m_nOut); for(int k=0;k<m_nOut;k++) { double z=m_b2[k]; for(int j=0;j<m_nHid;j++) z+=m_W2[k*m_nHid+j]*m_h[j]; probs[k]=z; } Softmax(probs,m_nOut); }
Обучение — один шаг SGD: forward, затем обратное распространение градиента кросс-энтропии. Для пары softmax + кросс-энтропия градиент на выходе упрощается до probs[k] − target[k], что и используется ниже. Дальше градиент проходит назад через ReLU скрытого слоя, и веса обновляются по правилу W ← W − lr · grad.
//+------------------------------------------------------------------+ //| Один шаг SGD: forward + backprop + обновление весов. | //| Вычисляет градиенты и обновляет W1, b1, W2, b2. | //+------------------------------------------------------------------+ void Step(const double &x[], int label) { double probs[]; Forward(x,probs); //--- градиент на выходе (softmax + cross-entropy) double dOut[]; ArrayResize(dOut,m_nOut); for(int k=0;k<m_nOut;k++) dOut[k]=probs[k]-(k==label?1.0:0.0); //--- градиент скрытого слоя (через ReLU) double dH[]; ArrayResize(dH,m_nHid); for(int j=0;j<m_nHid;j++) { double g=0.0; for(int k=0;k<m_nOut;k++) g+=dOut[k]*m_W2[k*m_nHid+j]; dH[j]=g*dReLU(m_z1[j]); } //--- обновление выходного слоя for(int k=0;k<m_nOut;k++) { for(int j=0;j<m_nHid;j++) m_W2[k*m_nHid+j]-=m_lr*dOut[k]*m_h[j]; m_b2[k]-=m_lr*dOut[k]; } //--- обновление скрытого слоя for(int j=0;j<m_nHid;j++) { for(int i=0;i<m_nIn;i++) m_W1[j*m_nIn+i]-=m_lr*dH[j]*x[i]; m_b1[j]-=m_lr*dH[j]; } }
Полный цикл обучения прогоняет заданное число эпох, каждую эпоху перемешивая порядок примеров перетасовкой Фишера–Йетса. Перемешивание важно: без него SGD "дрейфует" по хронологическому порядку и хуже сходится.
//+------------------------------------------------------------------+ //| Полный цикл обучения на выборке X/Y. | //| Перемешивает примеры каждой эпохи для устойчивой сходимости. | //+------------------------------------------------------------------+ void Train(const double &X[], const int &Y[], int n, int nIn, int epochs) { Reset(); int idx[]; ArrayResize(idx,n); for(int i=0;i<n;i++) idx[i]=i; for(int ep=0;ep<epochs;ep++) { //--- перетасовка Фишера–Йетса for(int i=n-1;i>0;i--) { int j=MathRand()%(i+1); int t=idx[i]; idx[i]=idx[j]; idx[j]=t; } for(int i=0;i<n;i++) { double xi[]; ArrayResize(xi,nIn); int row=idx[i]*nIn; for(int f=0;f<nIn;f++) xi[f]=X[row+f]; Step(xi,Y[idx[i]]); } } m_ready=true; }
Корректность алгоритма проверена отдельной репликацией кода. На синтетической задаче с заведомо выучиваемой зависимостью сеть достигает около 96% точности на обучающей выборке. Это подтверждает, что row-major раскладка весов W1[j·nIn+i] / W2[k·nHid+j] согласована между прямым и обратным проходом.
Сбор выборки и обучение на истории
Функция TrainModel собирает обучающий набор, пробегая историю от свежих закрытых баров к старым, для каждого бара считая признаки и метку. Дальше — лёгкая оценка качества: 20% самых новых баров отводятся под валидацию, на 80% старых обучается временная сеть, и на отложенных барах считается точность. Это диагностика — она пишется в лог и помогает понять, несёт ли сеть полезный сигнал. После оценки обучается финальная сеть на всей выборке.
//+------------------------------------------------------------------+ //| Сбор обучающей выборки, валидация и обучение финальной сети. | //| 20% новых баров — валидация, 80% старых — обучение. | //+------------------------------------------------------------------+ void TrainModel() { int fromShift = InpMlpHorizon+1; int toShift = MathMin(Bars(_Symbol,_Period)-60, InpMlpHorizon+InpMlpLookback); if(toShift <= fromShift+12) return; double X[]; int Y[]; ArrayResize(X, InpMlpLookback*MLP_NIN); ArrayResize(Y, InpMlpLookback); int cnt=0; for(int shift=fromShift; shift<=toShift && cnt<InpMlpLookback; shift++) { double f[]; int lab; if(!MlpFeatures(shift,f)) continue; if(!MlpLabel(shift,lab)) continue; for(int k=0;k<MLP_NIN;k++) X[cnt*MLP_NIN+k]=f[k]; Y[cnt]=lab; cnt++; } if(cnt<80) { Print("GS MLP: мало примеров: ",cnt); return; } ArrayResize(X,cnt*MLP_NIN); ArrayResize(Y,cnt); // ... быстрая валидация на 20% новых баров (см. полный код) ... //--- финальная сеть на всей выборке if(g_mlp!=NULL) delete g_mlp; g_mlp=new CMlpNet(); g_mlp.Init(MLP_NIN,InpMlpHidden,2,InpMlpLR); g_mlp.Train(X,Y,cnt,MLP_NIN,InpMlpEpochs); g_mlpTrained=true; g_barsSinceTrain=0; }
Это отличается от Markov-индикатора. Там признаки строились из обученной матрицы переходов, поэтому при разбиении на train/val нужно было строить матрицу только по train-барам; иначе переходы из валидационного периода "протекали" в признаки. В нашем случае признаки чисто локальные — это показания RSI, ATR, EMA на одном баре, не зависящие ни от какой подгоняемой по выборке статистики. Поэтому утечки через общий объект нет, и валидация остаётся честной без дополнительных ухищрений. Сеть при этом всё равно не видит меток валидационных баров — она обучается только на train-строках.
Интеграция в советник
Минимальный практический объём интеграции состоит из четырёх частей: добавить параметры MLP, создать дескриптор EMA для признаков, запускать TrainModel на новом баре и вызвать MlpAccepts(dir) после HTF-фильтра в CheckSignal. Всё остальное — детали реализации сети и диагностики.
Важно, что MLP не должен менять старую торговую логику напрямую. Он только принимает или отклоняет уже сформированный кандидат. Это упрощает отладку: если кандидат появился, но сделка не открылась, в логах можно отдельно проверить дивергенцию, HTF-фильтр, готовность сети, значение conf и порог InpMlpThreshold.
Новая группа параметров управляет и сетью, и обучением:
input group "=== MLP-фильтр (обучается в MQL5) ===" input bool InpUseMlp = true; // Включить MLP-фильтр input int InpMlpHidden = 24; // Нейронов в скрытом слое input double InpMlpLR = 0.01; // Скорость обучения input int InpMlpEpochs = 300; // Эпох обучения input int InpMlpLookback = 2000; // Баров истории для обучения input int InpMlpHorizon = 12; // Горизонт метки (баров вперёд) input double InpMlpThreshold = 0.20; // Порог уверенности |P(up)-P(dn)| input int InpRetrainBars = 250; // Переобучать каждые N новых баров input double InpLabelMinPts = 0.0; // Мин. движение для метки (0=выкл) input bool InpMlpFailOpen = false; // Торговать, если сеть не обучена
В OnInit добавляется инициализация генератора случайных чисел для весов и дескриптор EMA для признаков:
MathSrand((int)TimeCurrent()); // инициализация генератора для весов ... g_featMaHandle = iMA(_Symbol, _Period, 50, 0, MODE_EMA, PRICE_CLOSE);
Обучение запускается лениво — на новом баре, а не в OnInit. Причина практическая: в OnInit история может быть ещё не прогружена, и CopyBuffer вернёт мало данных. На новом баре данные гарантированно есть. Здесь же реализовано переобучение по расписанию:
//--- обучение/переобучение сети на новом баре if(InpUseMlp && g_isNewBar) if(!g_mlpTrained || (++g_barsSinceTrain >= InpRetrainBars)) TrainModel();
И сам gate в CheckSignal — одна строка после HTF-фильтра, как и раньше:
//+------------------------------------------------------------------+ //| Проверка MLP-фильтра: согласован ли прогноз сети с dir. | //| Возвращает true, если уверенность сети выше порога и совпадает | //| с направлением кандидата. | //+------------------------------------------------------------------+ bool MlpAccepts(int dir) { if(!InpUseMlp) return(true); if(!g_mlpTrained || g_mlp==NULL) return(InpMlpFailOpen); double f[]; if(!MlpFeatures(1,f)) return(InpMlpFailOpen); // последний закрытый бар double pr[]; g_mlp.Forward(f,pr); double conf = pr[1]-pr[0]; // + = вверх, - = вниз bool ok = (dir==1) ? (conf>= InpMlpThreshold) : (conf<=-InpMlpThreshold); return(ok); }
Параметры
Эти параметры — минимальная панель управления MLP-gate. Через них включается фильтр, задаётся размер сети, глубина истории, частота переобучения, горизонт метки, порог уверенности и безопасное поведение при неготовой модели.
| Параметр | По умолчанию | Комментарий |
|---|---|---|
| InpUseMlp | true | Главный переключатель MLP-фильтра |
| InpMlpHidden | 24 | 8 признаков → 16–32 нейронов достаточно; больше = риск переобучения |
| InpMlpLR | 0.01 | Выше → быстрее, но риск расхождения; ниже → стабильнее |
| InpMlpEpochs | 300 | Главный рычаг скорости и стоимости обучения |
| InpMlpLookback | 2000 | Меньше → свежее, но меньше данных; больше → устойчивее, но тяжелее |
| InpMlpHorizon | 12 | Горизонт метки; согласуйте его с логикой TP/ожидаемой отработки сетки |
| InpMlpThreshold | 0.20 | Порог |P(up)-P(down)|; выше → строже отбор, меньше входов |
| InpRetrainBars | 250 | Чаще → адаптивнее, но дороже по CPU |
| InpLabelMinPts | 0.0 | Шумовой фильтр меток; помогает не учить сеть на микродвижениях |
| InpMlpFailOpen | false | false = не торговать без обученной сети; это безопаснее для боевого режима |
Подводные камни обучения в терминале
Стоимость прогона в оптимизаторе. Сеть переобучается каждые InpRetrainBars баров, и каждое обучение — это InpMlpEpochs проходов по выборке. В Strategy Tester при оптимизации это умножается на число комбинаций параметров. Если прогон тормозит — увеличьте InpRetrainBars, уменьшите InpMlpEpochs или InpMlpLookback. Для боевой торговли скорость не важна (одно обучение раз в сотни баров), для массовой оптимизации — важна очень.
Детерминизм. He-инициализация использует MathRand. Без контроля зерна два прогона на одних данных могут дать чуть разные веса и разные сделки. MathSrand фиксирует последовательность случайных чисел внутри конкретного запуска; для строгого повторения теста можно заменить TimeCurrent() на постоянный seed, а для статистически устойчивой оценки — прогонять несколько сессий с разными зёрнами и смотреть на разброс, а не на один удачный прогон.
Заглядывание в будущее. В индикаторах это частая ошибка: признак на баре вычисляется с использованием будущих баров. В нашем советнике признаки берутся строго на закрытых барах (инференс — на shift=1), а метка при обучении смотрит вперёд только в уже прошедшей истории. На "живом" крае графика будущего нет, и оно не используется. Это разделение нужно держать в голове при любой модификации признаков.
Дисбаланс классов. Если на инструменте за период обучения движений вверх и вниз сильно неравное число, сеть будет смещена к частому классу. Шумовой фильтр InpLabelMinPts частично это лечит, отсекая мелкие движения; при сильном дисбалансе стоит добавить взвешивание классов в Step.
Быстрая проверка на бэктесте
После включения MLP-gate результат нужно смотреть не только по прибыли, но и по поведению просадки, числу сделок, доле отклонённых кандидатов и стабильности на разных участках истории. В одном из тестов система держится вполне неплохо — и защита в виде риск-менеджера вовремя закрывает проблемные серии сделок:
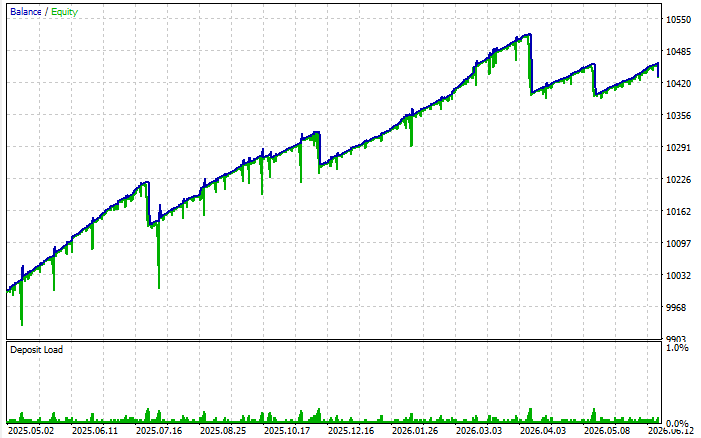
Вот подробная статистика:
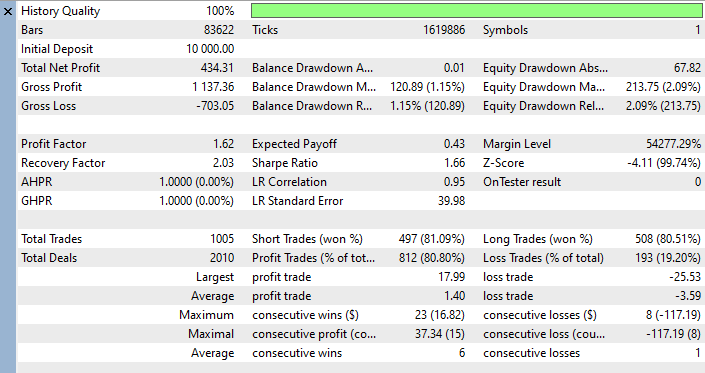
В этом прогоне при прибыли 4,34% за год и один месяц система не допустила просадки выше 1,15%, а 80% сделок были прибыльными. Это не доказательство универсального качества модели, а пример первичной проверки: дальше такие результаты нужно подтверждать на других периодах, символах, спредах, зернах и параметрах переобучения.
Проверка перед включением MLP-gate
Перед тем как оптимизировать или включать фильтр в боевую торговлю, полезно пройти короткий чек-лист. Он нужен не для красоты, а чтобы убедиться, что статья действительно доводит читателя из точки А — хаотичного Python/MQL5-пайплайна — в точку Б: один проверяемый модуль внутри советника.
- Советник компилируется как один .mq5 и не требует внешнего файла весов.
- В логах есть количество обучающих примеров и accuracy на отложенном хвосте истории.
- Инференс в боевом режиме выполняется строго на закрытом баре shift=1.
- Метки формируются только по уже прошедшей истории и не попадают в признаки.
- Порядок фильтров в CheckSignal сохраняется: дивергенция → HTF-фильтр → MLP.
- При неготовой сети поведение явно управляется InpMlpFailOpen.
- При сильном дисбалансе классов проверяется распределение меток, регулируется InpLabelMinPts или добавляется взвешивание классов.
- Для статистики выполняется несколько прогонов с разными seed, а не один красивый результат.
Куда расширять
Слой нормализации внутри сети. Сейчас признаки нормированы вручную формулами. Можно вычислять среднее и СКО по обучающей выборке прямо в TrainModel, сохранять их в полях сети и применять в Forward — тогда можно подавать признаки в естественных единицах, а сеть сама приведёт их к нужному масштабу.
Регрессия вместо классификации. Заменить softmax-классификатор на линейный выход и обучать предсказывать ожидаемое движение в ATR. Тогда выход станет не только фильтром, но и регулятором: на сильных сетапах увеличивать InpMaxLevels или лот.
Второй скрытый слой или dropout. Для более богатого набора признаков добавить второй ReLU-слой. Dropout при обучении снизит переобучение, что особенно полезно при частом переобучении на коротком окне.
ONNX для тяжёлых моделей. Если задача перерастёт возможности самописного обучения в терминале (большие сети, свёртки, рекуррентность), правильный путь — обучать офлайн и запускать через нативный OnnxRun. Самописный CMlpNet остаётся идеальным для маленьких адаптивных сетей, где ценны нулевые зависимости и обучение на лету.
Ансамбль с дивергенцией как взвешенный голос. Вместо жёсткого gate комбинировать уверенность MLP, согласие HTF и силу дивергенции в одну взвешенную оценку, и от неё уже принимать решение и о входе, и о размере позиции.
Что в итоге
В результате MLP "переехал" внутрь советника: GridSurvivor теперь — один самодостаточный файл, который на новых барах собирает признаки и метки по истории текущего символа/ТФ, валидирует выборку, обучает MLP (ReLU + softmax) SGD-шагами и периодически переобучается. Прогноз сети используется как последний фильтр: дивергенция предлагает кандидат, HTF-фильтр проверяет контекст, а MLP подтверждает направление по правилу |P(up)−P(down)| ≥ Threshold; при неготовности модели поведение контролируется параметром InpMlpFailOpen.
Главный результат не в том, что маленькая сеть стала "умнее" большой офлайн-модели. Главный результат — исчезла целая категория операционных ошибок: несовпадение скейлеров, потерянные веса, разные версии признаков и расхождение логики между Python и MQL5. Обучение и инференс теперь выполняются в одном коде, на одних данных и с одной функцией признаков.
Критерий завершённости простой: советник компилируется как один .mq5 без внешних файлов весов, в логах есть метрики валидации, инференс идёт строго на shift=1, а gate реально включён в контур принятия решений после дивергенции и HTF-фильтра. Если модель не обучена, поведение не должно быть случайным — его обязан контролировать InpMlpFailOpen.
Ограничения остаются: обучение в терминале затратнее по CPU, а малая сеть на коротких признаках не заменит богатые офлайн-модели. Для дальнейшего развития возможны встроенная нормализация, регрессия вместо классификации, дополнительный скрытый слой, dropout или тяжёлое офлайн-обучение с запуском через ONNX. Но для роли адаптивного gate и надёжного рабочего модуля цельность, прозрачность и отсутствие внешних зависимостей важнее максимального потолка качества.
| Название файла | Описание файла |
|---|---|
| GridSurvivor_MLP.mq5 | Советник с MLP, который обучается прямо в MQL5 (один файл, без Python и без файла весов) |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования