
您应当知道的 MQL5 向导技术(第 22 部分):条件化生成式对抗网络(cGAN)
概述
条件化生成式对抗网络(cGAN)是一种 GAN,允许在其生成式网络中自定义输入数据类型。阅读分享链接主题可见,GAN 是一对神经网络;一个生成器和一个判别器。两者都接受训练或彼此相互训练,生成器不断改进,不断生成目标输出,而判别器则依据来自生成器的鉴别数据(又名假数据)受训。
这样应用在图像分析中很典型,其中生成器网络用来生成图像,判别器网络辨别作为输入投喂的图像是否由生成器网络编造、亦或是真实的。给判别器穿插投喂生成器的图像、和真实图像,开启彼此相互训练,就像在任何网络里一样,反向传播会相应地调整判别器的权重。另一方面,在非条件化、或典型设置中,生成器被随机投喂输入数据,且无论怎样,都应该生成尽可能逼真的图像。
在条件化 GAN 设置(cGAN)中,我们进行了轻微修改,往生成网络投喂某种类型的数据作为输入,而非随机数据。这在有些状况下适用或很实用,其中我们投喂给判别器的数据类型是成对的、或分为两部分,且判别器网络的目标是告知输入数据对是有效的、亦或编造的。
GAN 和 cGAN 的大多数应用体现在图像识别或处理,但在本文中,我们探讨如何围绕它们构建一个非常简单的金融时间序列预测模型。如标题中所述,我们将采用 cGAN,与 GAN 对垒。为了概括这两者之间的区别,我们可参考下面的两个图表:
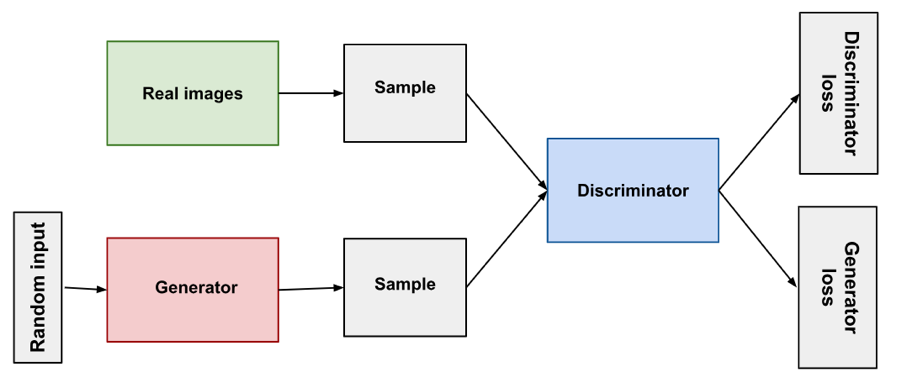
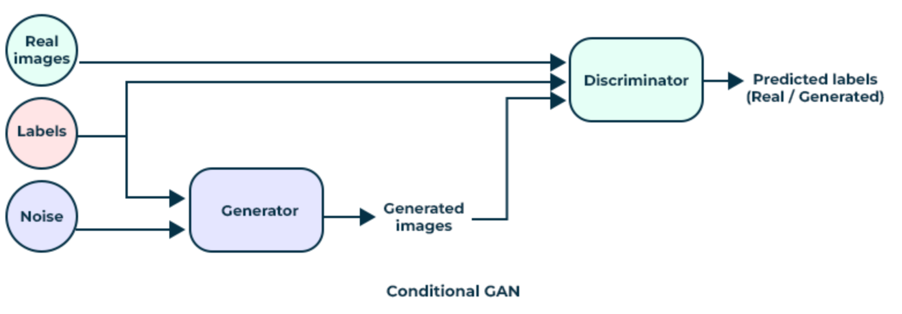
这两张图像的源链接在上面分享,要点是设置,生成器网络的输出被馈送到鉴别器网络,以便测试或验证。GANs 是对抗性的,因为生成器经训练后可以更好地愚弄判别器,而判别器经训练后可以更擅于从真实、或非生成器网络数据中鉴别生成器输出。不过,这两种设置之间的主要区别在于,依据 GAN,生成器网络获取随机输入数据,并用其生成判别器无法从真实数据中言明的数据。对于我们预测金融时间序列的目的,其适用性和用途必然有限。
然而,对于 cGAN来说,图中所谓的噪声本质上是独立的数据、或生成器试图为其生成标签的数据(在我们的适应情况下)。我们没有如上图所示将标签输入生成器网络,但是判别器网络接收噪声(或独立数据)、及其各自标签的数据配对,然后尝试告知该配对是否来自真实数据,或分配给独立数据的标签来自生成器。
对于金融时间序列预测 cGAN 有什么益处?嗯,正如他们所说,事实胜于雄辩,这就是为什么我们将在本文末尾进行一些测试作为实证,然而在图像识别方面,GANs 肯定具有一定的影响力,尽管由于计算消耗,它们的表现不如 CNNs 或 ViTs。不过,据报道,它们在图像合成和增强方面表现颇佳。
设置环境
为了构建我们的 cGAN 模型,我们将使用这篇文章中讲述的多层感知器网络作为基类。该基类包含了我们启动和运行 cGAN 所需的所有“工具和函数库”,因为生成器网络和判别器网络都简单地被视为多层感知器的实例。该基类只有 2 个主要函数;前馈方法 'Forward()',和反向传播函数 'Backward()'。当然,还有接受网络设置的类构造函数,以及一些允许将训练后的权重保存到文件的内务方法,再加上一些设置训练目标和读取前馈结果的其它函数。
尽管这个 cGAN 用到了我们典型的多层感知器基类,但我们需要进行一些特定于 GAN 的更改,譬如在生成式网络执行其反向传播、或学习的方式。损失生成器的计算来自以下公式:
−log(D(G(z∣y)∣y))
其中:
- D() 是判别器输出函数
- G() 是生成器输出函数
- z 是独立数据
- y 是依赖项、或标签、或预测数据
故此,这个损失生成器值,典型为矢量形式,具体取决于输出大小,将在开始反向传播时,充当每个前向通验的误差值权重。我们在网络类中进行这些更改,如下所示:
//+------------------------------------------------------------------+ //| Backward pass through the neural network to update weights | //| and biases using gradient descent | //+------------------------------------------------------------------+ void Cgan::Backward(vector<double> &DiscriminatorOutput, double LearningRate = 0.05) { if(target.Size() != output.Size()) { printf(__FUNCSIG__ + " Target & output size should match. "); return; } if(ArraySize(weights) != hidden_layers + 1) { printf(__FUNCSIG__ + " weights matrix array size should be: " + IntegerToString(hidden_layers + 1)); return; } ... // Update output layer weights and biases vector _output_error = -1.0*MathLog(DiscriminatorOutput)*(target - output);//solo modification for GAN Back(_output_error, LearningRate); }
我们的 'Backward()' 函数被重载作为一个变体,典型情况下取判别器输出作为输入,然后这两个重载函数都调用一个 'Back()' 函数,其本质上含有我们在旧的反向传播函数中的大部分代码,在此引入是为了减少重复性。这种加权的作用是确保在训练生成器时,我们不仅能更好地预测下一个收盘价变化,而且我们还能“更好地”欺骗判别器相信生成器数据是真实的。与此同时,判别器正在“朝相反的方向”进行训练,尝试更好地区分生成器数据和真实数据。
对比之下,如果我们要在第三方应用中实现此设置,则在 Python 中使用 TensorFlow 定义类似的网络,将需要使用单独的命令、或代码行来添加每个层。当然,这个 Python 选项提供了更多自定义,这是我们的基类未提供的,但作为在 MQL5 环境中运行 cGAN 的原型工具,它不应该是首选。更不用说,使用 Python 及其任何神经网络库都需要配备“适配器”,例如 ONNX、或等效的自定义实现,允许导出训练结果,并反回 MQL5。模型在开发中训练一次,然后部署,或处于脱机态(未部署)时定期训练,这种设计确实有其优势。
在某些场景下,如神经网络训练需要实况、或部署期间完成时,与 Python 进出的许多“适配器”可能会变得很笨拙,尽管这仅是可能。
设计自定义信号类
正如我们在本系列中所看到的,信号类拥有初始化、验证和评估市场条件的标准函数。此外,可以添加无限数量的函数来自定义信号,无论是搭配自定义指标、亦或 MQL5 函数库中已有的经典指标的组合。由于我们正在构建一个基于多层感知器的 cGAN,因此我们将从额外数量的函数开始,类似于我们在之前文章中采用的函数,其也用在我们的感知器基类。
这些函数将是 'GetOutput()'、'Setoutput()' 和 'Norm()' 函数。它们在此的角色与我们之前文章里非常相似,因为 get 函数是负责判定市场状况的锚点函数,而 set 函数如前一样,在每次训练通验后写入网络权重,而 norm 函数则扮演关键角色,在投喂前馈之前归一化我们的输入数据。
我们为 cGAN 自定义信号类引入了 3 个新的附加函数,这些函数要做的,是把生成器网络的处理,从判别器网络分开。
生成式网络的架构被任意选择为有 7 层,其中是一个输入层、5 个隐藏层、和一个输出层。这一点的正确判定,可按我们在上述这篇文章中研究的神经架构搜索来做到,但就我们的目的而言,这些假设足以验证 cGAN。这些网络设置在 'settings' 数组中定义,我们用它来初始化网络类的实例,我们将其命名为 'GEN'。
我们的生成式网络将以收盘价的先前变化作为输入,并将收盘价的单个预测变化作为输出。这与我们在参考文献中视察神经架构搜索时的实现没有太大区别。输出预测是收盘价变化,后随 4 个变化作为输入。
故此,这 4 个先前变化与预测值的配对,打造成判别器网络的输入数据,这一点我们稍后再看。我们用到的网络基类由 softplus 执行激活,这是固定的。由于提供了完整的源代码,读者可以轻松地将其自定义它,与其设置相适应。因此,我们的信号类唯一采用的可调整参数是学习率、训练局次的数量、和训练数据集的大小。它们分别被分配了名称 'm_learning_rate'、'm_epochs' 和 'm_train_set' 。在 GetOutput 函数内,这就是我们如何加载网络的输入数据、前馈、及依据每根新柱线训练网络:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CSignalCGAN::GetOutput(double &GenOut, bool &DisOut) { GenOut = 0.0; DisOut = false; for(int i = m_epochs; i >= 0; i--) { for(int ii = m_train_set; ii >= 0; ii--) { vector _in, _out; vector _in_new, _out_new, _in_old, _out_old; _in_new.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, __GEN_INPUTS); _in_old.CopyRates(m_symbol.Name(), m_period, 8, ii + 1 + 1, __GEN_INPUTS); _in = Norm(_in_new, _in_old); GEN.Set(_in); GEN.Forward(); if(ii > 0)// train { _out_new.CopyRates(m_symbol.Name(), m_period, 8, ii, __GEN_OUTPUTS); _out_old.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, __GEN_OUTPUTS); _out = Norm(_out_new, _out_old); ... } else if(ii == 0 && i == 0) { ... } } } }
我们的 GAN 是条件化的,因为生成器网络的输入并非随机的,而判别器网络的输入是双叠的,捕获发至生成器的输入、及其输出。因此,判别器网络的角色是判定其输入数据是否来自 5 个连续收盘价变化的实时序列序列,或者它是生成器网络的数据输入、及其输出的配对。换言之,它分别判定其输入数据是“真实”还是“假造”。
这意味着判别器网络的输出非常简单,布尔值足矣。输入数据既可完全来自市场(true),亦或部分由生成器魔改而来(false)。我们分别用 1 和 0 表示,从训练后的测试运行中,返回的值是介于 0.0 和 1.0 之间的浮点数。是故,为了训练我们的判别器网络,我们将向其交替投喂真实收盘价变化的 5 个数据点(即 5 个连续的变化),和另外 5 个收盘价变化,这其中只有 4 个是真实的,而第 5 个则是生成器网络的预测。真实数据训练部分由 'R' 函数处理,其代码如下:
//+------------------------------------------------------------------+ //| Process Real Data in Discriminator | //+------------------------------------------------------------------+ void CSignalCGAN::R(vector &IN, vector &OUT) { vector _out_r, _out_real, _in_real; _out_r.Copy(OUT); _in_real.Copy(IN); Sum(_in_real, _out_r); DIS.Set(_in_real); DIS.Forward(); _out_real.Resize(__DIS_OUTPUTS); _out_real.Fill(1.0); DIS.Get(_out_real); DIS.Backward(m_learning_rate); }
训练假造数据是经由 'F' 函数,其代码也在此处给出:
//+------------------------------------------------------------------+ //| Process Fake Data in Discriminator | //+------------------------------------------------------------------+ void CSignalCGAN::F(vector &IN, vector &OUT) { vector _out_f, _out_fake, _in_fake; _out_f.Copy(OUT); _in_fake.Copy(IN); Sum(_in_fake, _out_f); DIS.Set(_in_fake); DIS.Forward(); _out_fake.Resize(__DIS_OUTPUTS); _out_fake.Fill(0.0); DIS.Get(_out_fake); DIS.Backward(m_learning_rate); }
这两个函数在 GetOutput 函数中调用,如下所示:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CSignalCGAN::GetOutput(double &GenOut, bool &DisOut) { GenOut = 0.0; DisOut = false; for(int i = m_epochs; i >= 0; i--) { for(int ii = m_train_set; ii >= 0; ii--) { ... if(ii > 0)// train { _out_new.CopyRates(m_symbol.Name(), m_period, 8, ii, __GEN_OUTPUTS); _out_old.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, __GEN_OUTPUTS); _out = Norm(_out_new, _out_old); // int _dis_sort = MathRand()%2; if(_dis_sort == 0) { F(_in, GEN.output); GEN.Get(_out); GEN.Backward(DIS.output, m_learning_rate); R(_in, _out); } else if(_dis_sort == 1) { R(_in, _out); GEN.Get(_out); GEN.Backward(DIS.output, m_learning_rate); F(_in, GEN.output); } } else if(ii == 0 && i == 0) { GenOut = GEN.output[0]; DisOut = (((DIS.output[0] >= 0.5 && GenOut >= 0.5)||(DIS.output[0] < 0.5 && GenOut < 0.5)) ? true : false); } } } }
我们调用 'Sum' 函数将 4 个收盘价变化、与下一个收盘价变化配对,这是我们对获得真实数据感兴趣;或者我们对获取“假造”数据感兴趣,则与生成器的预测配对。故此,经后续训练后,正如人们对任何感知器所期望的那样,生成器变得更擅长做出预测,然后我们能够用这些预测来评估市场条件。但是我们之后如何依据判别器的训练效果行事呢?
是以,首先如上所述,训练有助于锐化生成器网络权重,也因为我们使用损失生成器权重来调整生成器网络反向传播所用的损失值。其次,在网络经过训练、并部署之后,判别器仍可用来验证生成器预测。如果它无法告知它们是否来自生成器,那么它就确认了我们的生成器网络已经很擅长其工作。
集成 cGAN 与 MQL5 信号类
为了在信号类中完成这项工作,我们需要对做多和做空条件函数进行编码,以便调用返回 2 个对象的 'GetOutput()' 函数。收盘价的估测变化由双精度变量 'GenOut' 和布尔变量 'DisOut' 捕获,其示意收盘预测的变化是否能够愚弄判别器网络。读者可以自由尝试仅使用生成器输出来判定市场条件的设置,因其通常是在图像生成的情况,这是 GAN 最常见的用途。不过,判别器网络检查这些预测的作用,是评估条件的一个额外安全步骤,这就是为何将其包含在此的原因。
网络输入值都被归一化在 -1.0 到 +1.0 的范围内,按同样方式,对于大多数情况,我们期待输出也在类似的范围内。这意味着我们的生成器会给我们一个收盘价变化的预测百分比。由于它们是百分比,我们可将它们乘以 100,得到不超过 100 的值。这个值的符号,无论是正、亦或是负,分别示意我们应该做多、或是做空。故此,为了处理条件,并获得 0 – 100 范围内的整数输出,正如我们的做多和做空条件函数所期望的那样,我们的做多条件函数如下所示:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalCGAN::LongCondition(void) { int result = 0; double _gen_out = 0.0; bool _dis_out = false; GetOutput(_gen_out, _dis_out); _gen_out *= 100.0; if(_dis_out && _gen_out > 50.0) { result = int(_gen_out); } //printf(__FUNCSIG__ + " generator output is: %.5f, which is backed by discriminator as: %s", _gen_out, string(_dis_out)); return(result); }
做空的条件非常相似,当然,不同之处在于预测百分比需要为负数,因其结果能赋予一个非零值,且该值是乘以 100 后的预测百分比绝对量。
测试和验证
如果我们执行测试是由 MQL5 向导组装的智能系统来运行(指南在这里和这里),我们在其中一次运行中会得到以下结果:


处理信号,并得以运行,我们把判别器网络的训练顺序随机化,即有时我们先用真实数据训练,有时我们先用假造数据训练。从测试来看,这令判别器网络的学习不会一边倒,譬如总是只做多或做空,因为严格的测试顺序会令判别器网络行事偏颇。如上所述,典型的 GAN 用法不需要判别器网络验证,我们于此择其以用,纯粹是出于孜孜以求。
由于增加了验证,我们不容易在每次测试运行中复现结果,尤其在于我们的网络架构非常小,因为我们只用了 5 个隐藏层,每个隐藏层的大小仅为 5。如果某人的目标是通过判别器网络的验证检查来获得更一致的结果,那么他应当训练拥有 5 到 25 个隐藏层的网络,其中每个隐藏层的大小可能不会小于 100。层尺寸大于层数是导致生成更可靠网络结果的关键因素。
即便,若我们舍弃这个判别器网络验证,那么我们的网络应会产生较少波动的测试结果,尽管性能会有一些问题。一种折衷方案是添加一个额外的输入参数,允许用户选择是否开启鉴别器网络验证。
结束语
总而言之,我们已经看到了如何基于条件化生成式对抗网络(cGAN)开发自定义信号类,其能组装到一个智能系统里,这要归功于 MQL5 向导。cGAN 是 GAN 的改编版,因为它在训练生成器网络时使用非随机数据,而判别器数据的输入数据在我们的例子中是该生成器网络输入数据与生成器输出数据的配对,如前所述。神经网络在训练中会学习加权,故此,每当训练过程完成时,最好记录网络的这些权重。我们尚未研究或探讨本文所执行的测试运行得到的益处。
此外,我们尚未探讨采用不同网络训练制度的潜在益处和权衡。举例,在本文中,我们在每根新柱现上训练网络,旨在令网络和交易系统具有更大的灵活性和适应性,从而适应可能不断变化的市场条件,然而,反对且与其对立的一个或许可信的论点是,若始终在每根新柱线上训练网络,则它无必要地依据噪音训练;对比之,训练每 6 个月进行一次,故此只有市场的关键“长期”层面被当作训练数据点,这样能带来更可持续的结果。
甚而,这个一直很重要的神经架构搜索先决条件问题被“略过”了,因为它不是我们的主要意向,然而,正如任何熟悉网络的人都知道的那样,这是神经网络性能的一个非常敏感的层面,在训练和最终部署任何网络之前需要一些努力。故此,即便很重要,但这 3 个关键方面尚未得到妥善解决,这意味着强烈建议读者在认定它们具有交易价值之前,将它们当作开发和深化 cGAN 类的起点。如常,这不是投资建议,对于本文中分享的任何内容、及所有思路,在进一步使用之前,读者应谨慎行事。祝您狩猎愉快。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/15029
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。