
Разработка торгового советника с нуля (Часть 15): Доступ к данным в Интернете (I)

Введение
Платформа MetaTrader 5 — самая универсальная и полная платформа, которую пользователь может только пожелать. Вопреки тому, что говорят многие неосведомленные люди, эта платформа чрезвычайно эффективна и мощна, ведь она нам дает возможности, выходящие далеко за рамки простого просмотра рисуемого графика и, таким образом, торговли, покупки или продажи определенного актива в данный момент времени.
Вся эта мощь исходит из того, что платформа использует язык, практически не уступающий самому мощному из созданных на сегодняшний день, мы говорим о C/C++, и возможности, которые предлагает нам этот язык, намного превосходят то, что простые трейдеры без навыков программирования способны выполнить или понять.
При работе на рынке, мы должны быть связаны каким-то образом с различными проблемами, связанными с глобальной средой, нельзя ограничиваться графиком, ведь мы должны быть каким-то образом связаны с различной другой информацией, которая не менее актуальна и может решать и являться разницей между выигрышем или проигрышем в сделке.
В Интернете у нас есть различные сайты и места, с огромным количеством информации, доступной для тех, кто знает, где искать и как лучше всего использовать эту информацию. И чем лучше мы информированы в течение подходящего периода, тем лучше. Однако, если вы собираетесь использовать браузер, каким бы он ни был, вы увидите, что очень сложно хорошо фильтровать определенную информацию, вынуждая вас смотреть на много экранов и мониторы, и в итоге хоть информация и есть, но воспользоваться ею невозможно.
Но благодаря MQL5, который очень близок к C/C++, программисты этого языка могут делать нечто большее, чем просто работать с помощью рисуемого графика: мы можем искать, фильтровать, анализировать данные в сети и, таким образом, выполнять операции гораздо более последовательным образом, чем большинство трейдеров, поскольку мы собираемся использовать всю вычислительную мощность в свою пользу.
1.0. Планирование
Часть планирования имеет ключевое значение. Сначала мы должны найти, откуда мы собираемся получить информацию, которую мы действительно хотим использовать, и мы должны делать это с гораздо большей осторожностью, чем кажется, поскольку хороший источник информации сориентирует нас по нужному направлению. Эту часть каждый должен применить индивидуально, поскольку каждый будет искать и нуждаться в конкретных данных в разное время.
Но, вне зависимости от этого, способ выполнения дел после выбора источника будет в основном одинаковым, поэтому данная статья может служить материалом изучения для тех, кто желает использовать метод и средства, возможные только при использовании MQL5, без какой-либо внешней программы.
Чтобы проиллюстрировать весь процесс, мы будем использовать веб-страницу с рыночной информацией, чтобы показать, как происходит процесс. Таким образом, будет ясно, как заставить всё работать, и поэтому вы сможете использовать метод, адаптируя его к вашим конкретным потребностям.
1.0.1. Разработка программы захвата
Чтобы приступить к делу, сначала нам нужно будет создать небольшую программу для сбора данных и иметь возможность спокойно и точно их проанализировать. Для этого мы будем использовать самую простую программу, показанную ниже:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { Print(GetDataURL("https://tradingeconomics.com/stocks")); } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 750) { string headers; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; if ((handle = FileOpen("url.txt", FILE_WRITE | FILE_BIN)) != INVALID_HANDLE) { FileWriteArray(handle, charResultPage, 0, ArraySize(charResultPage)); FileClose(handle); }else return "Error saving file ..."; return "File saved successfully..."; }
Эта программа очень проста, кажется, вряд ли можно сделать что-то проще.
Итак, мы делаем следующее: указываем в выделенном месте, с какого сайта мы хотим получить информацию, но почему мы используем его, а не браузер?! Совершенно верно, мы можем захватить информацию в браузере, но мы будем использовать ее, чтобы помочь нам найти информацию после загрузки данных.
Однако набирать и компилировать эту программу бесполезно, нужно делать что-то еще, иначе она не будет работать.
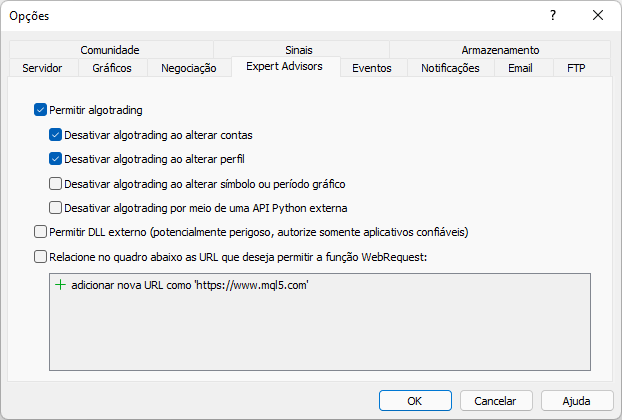
На платформе MetaTrader перед запуском этого скрипта нам нужно разрешить платформе получать данные с рассматриваемого сайта, но чтобы не делать это каждый раз, когда нам нужно установить платформу MetaTrader, вы можете после того, как все настроено, сохранять резервную копию этих данных. Файл, который мы должны сохранить, находится по следующему пути:
C:\Users\< USER NAME >\AppData\Roaming\MetaQuotes\Terminal\< CODE PERSONAL >\config\common.ini
USER NAME — это ваше имя пользователя в операционной системе, CODE PERSONAL — это значение, которое платформа создаст во время установки, таким образом будет легко найти нужный файл, чтобы сделать его резервную копию или заменить после новой установки. Только один момент: это место относится к системе WINDOWS.
Хорошо, давайте вернёмся к скрипту, который мы создали. Если вы используете его перед настройкой, вы увидите следующее в окне сообщения.
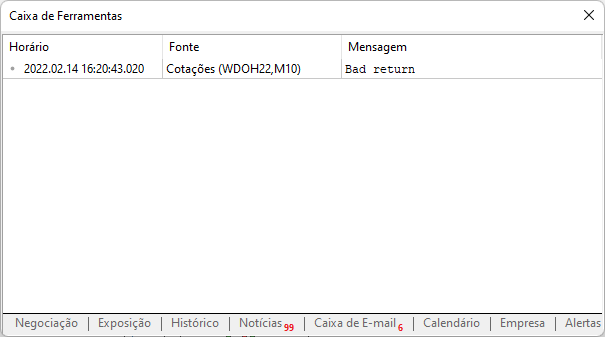
Это сообщение появилось из-за отсутствия включения сайта в платформе MetaTrader, это необходимо реализовать как показано на рисунке ниже. Внимательно наблюдайте что добавили и обратите внимание, что именно адрес корня сайта соответствует тому, который мы хотим для доступа через платформу MetaTrader.

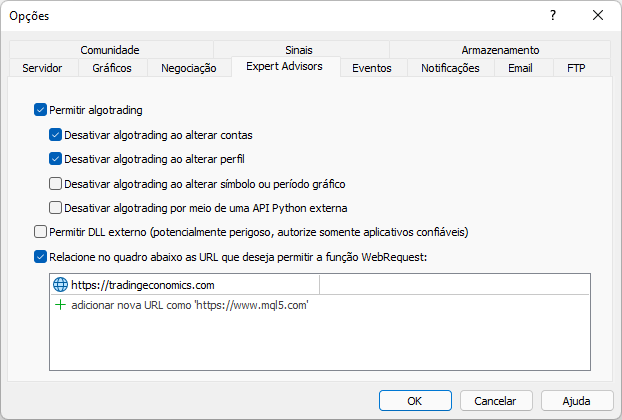
Теперь, при повторном запуске того же скрипта, мы увидим следующий результат, о котором сообщает платформа:
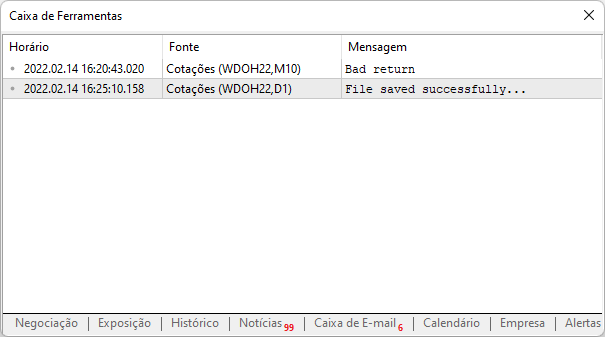
То есть доступ к сайту был осуществлен и данные были успешно загружены на наш компьютер и теперь мы можем их проанализировать. Важная деталь заключается в том, что теперь не надо беспокоиться о повторном добавлении того же сайта на платформу, при условии, конечно, что мы создаем бэкап этого файла, по указанному выше пути.
Чтобы понять как тут все будет работать и таким образом получить более подробную информацию, можно заглянуть на функцию WebRequest в документации. А если хотите глубже изучить, как работает соединение по сетевому протоколу, рекомендую взглянуть на другие сетевые функции, представленные в MQL5. Знание того, как работают такие функции, иногда может избавить от больших неприятностей.
Что ж, первая часть работы выполнена, мы добрались до загрузки данных с нужного сайта, теперь нам надо пройти следующий шаг, не менее важный.
1.0.2. Поиск данных
Для тех, кто не знает, как искать данные, собираемые платформой MetaTrader 5 на веб-сайте, мы создали короткое видео, в котором быстро показывается, как выполнить этот поиск.
Важно, чтобы вы знали, как обращаться с вашим браузером, чтобы иметь возможность анализировать код сайта, с которого вы хотите захватить данные. Это не сложно, так как сам браузер очень помогает в этой задаче, но это то, что вы должны научиться делать, и когда вы поймете, как это сделать, перед вами откроется море возможностей.
В этом случае я буду использовать Chrome для поиска, но вы можете использовать любой другой браузер, который позволит вам получить доступ к коду через инструменты разработчика.
То, что нас интересует - это получение данных из этого блока, показанного ниже, и это тот же самый блок, который я искал в видео выше. Обратите внимание, что важно знать, как правильно искать вещи с помощью браузера, иначе вы потеряетесь среди всей этой загружаемой информации.
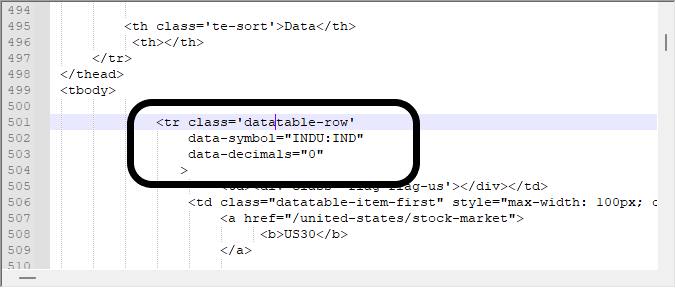
Хорошо, но в некоторых случаях просмотра данных таким образом будет недостаточно, мы должны прибегнуть к шестнадцатеричному редактору, чтобы точно знать, с чем мы имеем дело, это правда, что в некоторых случаях моделирование данных относительно просто, но в других дело довольно сложное, содержащее среди прочего изображения и ссылки, а они могут мешать поисковой системе, так как она обычно выдает ложные срабатывания. Поэтому мы должны знать, с чем имеем дело, а значит при поиске этих данных в шестнадцатеричном редакторе, мы получим следующие значения.
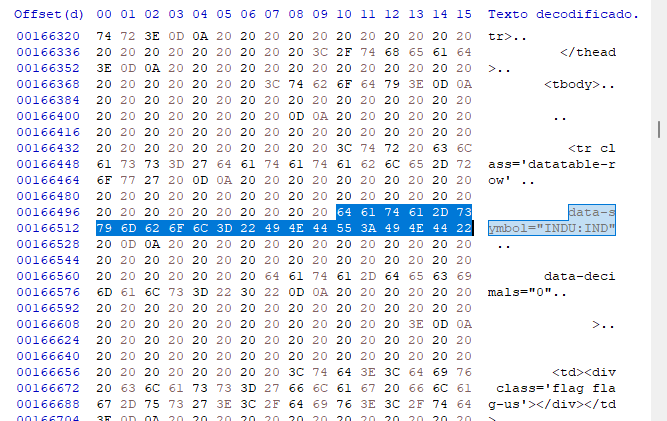
Смещения нас не интересуют в этот первый момент, поскольку они могут меняться в случае динамических страниц, но нас интересует то, какое моделирование используется, и в этом случае оно очень ясное, и мы можем использовать поисковую систему, основанную на этом типе информации, которую можно найти здесь в шестнадцатеричном редакторе. Это делает поиск по нашей программе несколько проще в реализации, хотя поначалу это система является неэффективной. Мы будем искать более простую базу данных, к которой можно получить доступ, и которую можно сообщить через ввод, то есть без символов, таких как CARRIAGE или RETURN, они нам больше мешают, чем помогают, тогда программа остается такой, как вы можете видеть ниже.
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks")); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 100) { string headers, szInfo; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; szInfo = ""; for (int c0 = 0, c1 = ArraySize(charResultPage); c0 < c1; c0++) szInfo += CharToString(charResultPage[c0]); if ((handle = StringFind(szInfo, "data-symbol=\"INDU:IND\"", 0)) >= 0) { handle = StringFind(szInfo, "<td id=\"p\" class=\"datatable-item\">", handle); for(; charResultPage[handle] != 0x0A; handle++); for(handle++; charResultPage[handle] != 0x0A; handle++); szInfo = ""; for(handle++; charResultPage[handle] == 0x20; handle++); for(; (charResultPage[handle] != 0x0D) && (charResultPage[handle] != 0x20); handle++) szInfo += CharToString(charResultPage[handle]); } return szInfo; }
Идея скрипта выше заключается в захвате значения на странице, а преимущество показанного выше метода в том, что даже если информация меняет свое положение, то есть свое смещение, у нас все равно есть возможность найти ее в среди всех этих команд, но даже если все кажется идеальным, есть небольшая задержка в информации, поэтому необходимо измерить то, как вы собираетесь работать с захваченными данными, когда выполняется скрипт выше. Результат выполнение можно увидеть далее.
Советую провести собственный анализ и посмотреть, как фиксируется информация, ведь важно знать детали, которые не так просто описать в текстовом виде: надо их увидеть, чтобы понять.
Теперь давайте подумаем о следующем. Приведенный выше скрипт не очень эффективен с точки зрения исполнения, так как он проделывает некоторые манипуляции, которые нам особо не нужны в случае использования страницы со статическим моделированием, но с динамическим содержимым, как в случае рассматриваемой страницы. В этом конкретном случае мы можем использовать смещение для более быстрого анализа и, таким образом, немного более эффективного захвата данных, если можно так сказать, но помните, что система может хранить информацию в кэше в течение нескольких секунд. Поэтому информация, которая захватывается может быть устаревшей по отношению к той же информации, наблюдаемой в браузере. В этом случае необходимо внести некоторые внутренние настройки в систему, чтобы исправить это, но это не является целью данной статьи.
Таким образом, изменив приведенный выше скрипт на что-нибудь, использующий смещение для выполнения поиска, мы получим следующий код, полностью приведенный ниже:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo; }
а результат выполнения скрипта можно увидеть в продолжении. Мы видим, что у нас нет больших изменений, это просто вопрос времени расчета, которое мы сокращаем с помощью офсетной модели и поэтому немного улучшаем общую производительность системы.
Нужно помнить следующее: предыдущий код работал только потому, что страница имела статическую модель, то есть, несмотря на то, что содержимое менялось динамически, ее дизайн не менялся, поэтому мы можем использовать шестнадцатеричный редактор, искать местонахождение информации, получить значения смещения и переходить сразу к этим позициям. Но чтобы иметь минимум уверенности в том, что смещения все же действительны, делаем простой тест в следующей строке:
for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position";
это что-то очень простое, но необходимое, чтобы у нас была минимальная безопасность в отношении информации, которая захватывается с помощью смещения. Для этого вы должны проанализировать страницу и проверить, возможно ли использовать метод смещения для выполнения захвата, но если это возможно, это будет иметь преимущество в виде более короткого времени обработки.
1.0.3. Проблема, с которой нужно справиться
Хотя система часто работает очень хорошо, может случиться так, что мы получим следующий ответ от сервера:
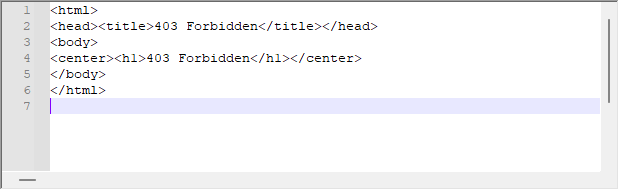
Это сообщение публикуется сервером как ответ на наш запрос, хотя функция WebRequest не указывает на какую-либо ошибку со стороны платформы, сервер возвращает это сообщение выше, поэтому мы должны проанализировать заголовок сообщения возврата, чтобы мы не были заложниками такого рода проблемы. Для решения данной проблемы вносим небольшое изменение в скрипт смещения, это видно ниже:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "<!doctype html>", 2, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szTest, int iTest, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1 return "Bad"; for (int c0 = 0, c1 = StringLen(szTest); c0 < c1; c0++) if (szTest[c0] != charResultPage[iTest + c0]) return "Failed"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo;
Выделенная строка — это именно та, которая выполняет тест, поскольку, когда возвращаемое сообщение с сервера представляет собой более сложное сообщение, простой факт выполнения этого теста уже гарантирует нам хороший запас безопасности данных, которые мы анализируем, и позволяет избежать анализ фантомных данных или мусора памяти в случае, если система проходит первый тест, который уже существовал в предыдущем коде. Хотя это случается редко, мы не должны недооценивать вероятность того, что оно случится.
Что ж, результат ничем не отличается, это можно увидеть ниже, а значит, система работает как положено.
Но пока мы мало что сделали, мы просто считываем значения с веб-страницы, и это не имеет большого применения, хотя это довольно любопытно узнавать и видеть, как это делается. Но на практике это малопригодно для тех, кто действительно хочет работать и торговать на основе информации, которую с этого момента вы собираетесь моделировать, так как значения захватываются и отображаются по-другому, поэтому мы должны сделать так, чтобы у всего этого появился какой-то смысл внутри более крупной системы. В этом случае мы собираемся взять эту информацию, полученную внутри советника, и таким образом вы сможете делать еще более впечатляющие вещи, и это действительно делает платформу MetaTrader 5 сенсационной платформой.
Заключение
На этом еще не всё заканчивается, в следующей статье мы посмотрим, как передать в советник информацию, собранную из сети, и это, безусловно, развеет наши сомнения, так как это будет нечто гораздо более интересное, так как нам придется использовать мало изученные ресурсы платформы MetaTrader. Не пропустите следующую статью из этой серии.
В приложении находятся все исходные коды, использованные в этой статье.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/10430
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Машинное обучение и Data Science (Часть 02): Логистическая регрессия
Машинное обучение и Data Science (Часть 02): Логистическая регрессия
 Разработка торгового советника с нуля (Часть 14): Добавляем Volume at Price (II)
Разработка торгового советника с нуля (Часть 14): Добавляем Volume at Price (II)
 Разработка торгового советника с нуля (Часть 16): Доступ к данным в Интернете (II)
Разработка торгового советника с нуля (Часть 16): Доступ к данным в Интернете (II)
 Индикатор CCI. Модернизация и новые возможности
Индикатор CCI. Модернизация и новые возможности
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Какие-нибудь детали я упустил?
Какие-нибудь детали я упустил?
Скорее всего ДА... вам нужно прочитать и посмотреть всю статью... ВСЮ, включая видео, которое есть в статье, потому что там я показываю некоторые детали того, как вы захватываете информацию ... детали в том, что система оптимизирована, чтобы идти по определенному адресу памяти и не продолжать искать информацию, что было бы очень медленно, так как мы используем систему REAL TIME ... и если страница будет изменена администратором, этот адрес будет другим, так что вам придется искать, где находится новый адрес, но в статье я подробно показываю, как найти новый адрес .... и, в этом конкретном случае, как увидеть сообщение об ошибке, указывающее, что адрес отличается от того, который система ожидала найти, чтобы найти информацию, которую она искала ... ПРОЧИТАЙТЕ статью... посмотрите видео и поймите, что я в нем объясняю, измените адрес, который используется для указания места нахождения информации, и вы получите данные, которые находятся на этой странице и на любой другой странице .... помните, что поиск должен быть выполнен быстро, так как система работает в режиме реального времени ... если бы это было не так, мы могли бы загрузить страницу и использовать цикл для поиска информации, но время дорого... 😁👍
Интересная статья, но я не могу понять, что означает желтый цвет?
И это шестнадцатеричное число. Как правильно его расположить?
Интересная статья, но я не могу понять, что означает желтый цвет?
И это шестнадцатеричное число. Как правильно его расположить?
Значения, начинающиеся с 0x, - это HEXA-значения, остальные - обычные десятичные значения. Вы можете использовать ДЕЦИМАЛЬНОЕ значение, но иногда мне кажется, что его трудно понять. Поскольку я обычно использую значения ASCII, я предпочитаю использовать HEXA. Но значение 0x0D представляет собой клавишу ENTER. А 0x20 - это клавиша SPACE. Чтобы найти эти значения и правильно их расположить, вам нужно иметь файл и редактор HEXADECIMAL. Затем нужно найти значение в файле, чтобы указать процедуре, где в файле находится это значение. Таким образом, значения 172783 и 173474 - это адреса, или позиции в загружаемом файле.
Попробуйте научиться пользоваться ГЕКСАДЕЦИМАЛЬНЫМ РЕДАКТОРОМ, так будет проще понять эти адреса.😁👍