
一からの取引エキスパートアドバイザーの開発(第15部):Web上のデータにアクセスする(I)

はじめに
MetaTrader 5は、トレーダーが望むことのできる最も多用途で完全なプラットフォームです。他の意見もありますが、このプラットフォームは非常に効果的で強力で、現在の時間の売買操作の機会を提供し、プロットされたチャートの単なる観察をはるかに超えています。
この力は、このプラットフォームが、現在最もパワフルな言語とほぼ同等の言語、つまりC/C++を使用していることに由来しています。この言語が与えてくれる可能性は、プログラミングスキルを持たない一般のトレーダーが実行したり理解したりする能力をはるかに超えています。
市場での操作においては、グローバルに展開されるさまざまな問題と何らかの形でつながっている必要があります。チャートに固執することはできません。他の関連情報を考慮に入れることが重要です。これらの情報はチャート同様に有用で、取引の勝敗を分ける決定的な要因となる可能性があります。
Web上にはたくさんのサイトや場所があり、膨大な量の情報が掲載されています。知るべきことは、どこを調べて、この情報をどのように使用するのが最善かということです。また、より適切な時期に情報を得ることができれば、取引により有利になります。ただし、ブラウザを使おうとすると、それが何であれ、特定の情報をうまくフィルタリングすることが非常に難しく、多数の画面とモニターを確認せざるを得ず、結局、情報があってもそれを使うことができないことに気がつくと思います。
しかし、C/C++に非常に近いMQL5のおかげで、プログラマーはそのままチャートで作業する以上のことができます。Web上のデータを検索、フィルタリング、分析し、有利にすべての計算能力を使用しているため、ほとんどのトレーダーよりもはるかに一貫した方法で操作を実行することができます。
1.0.計画
重要なのは計画の部分です。まず、使いたい情報をどこで手に入れるのかを見つけることが必要です。良い情報源は正しい方向を示してくれるため、これは実は案外慎重におこなううべきことです。必要なデータはトレーダーごとに異なるため、この手順は各自でおこなう必要があります。
どのソースを選んでも次にやることは基本的にみんな同じなので、この記事は、外部プログラムを使わずにMQL5だけを使って、その手法やツールを使いたい人の勉強材料になると思います。
市場情報のWebページを使って全体の流れを説明します。この方法のすべての手順を説明するので、読者は特定のニーズに合わせてこの方法を使用することができるようになります。
1.0.1.キャプチャプログラムの開発
データを扱うには、データを収集し、効率的かつ正確に分析できるようにするための小さなプログラムを作成する必要があります。そのために、以下に示す非常に簡単なプログラムを使用します。
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { Print(GetDataURL("https://tradingeconomics.com/stocks")); } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 750) { string headers; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; if ((handle = FileOpen("url.txt", FILE_WRITE | FILE_BIN)) != INVALID_HANDLE) { FileWriteArray(handle, charResultPage, 0, ArraySize(charResultPage)); FileClose(handle); }else return "Error saving file ..."; return "File saved successfully..."; }
このプログラムは極めて簡単で、これ以上ないくらいに簡単です。
ハイライト表示された部分には、情報の受け取りを希望するサイトを示します。なぜ、ブラウザではなくそれを使っているのでしょうか。確かにブラウザで情報を取り込むこともできますが、データをダウンロードした後の情報検索に役立てようと思っています。
しかし、このプログラムを入力してコンパイルするだけでは意味がありません。他にやるべきことがあり、やらなければうまくいきません。
MetaTraderプラットフォームでは、このスクリプトを実行する前に、プラットフォームが目的のサイトからデータを受信することを許可する必要があります。MetaTraderプラットフォームをインストールする必要があるたびにこの操作をおこなわないようにするには、すべてが設定された後、このデータのバックアッ コピーを保存することができます。ファイルは、以下のパスに保存します。
C:\Users\< USER NAME >\AppData\Roaming\MetaQuotes\Terminal\< CODE PERSONAL >\config\common.ini
USER NAMEは、オペレーティングシステムでのユーザー名です。CODE PERSONALは、インストール時にプラットフォームが作成する値です。このようにして、バックアップや新規インストール後の置き換えに必要なファイルを簡単に見つけることができます。ただ一点、この場所はWINDOWSシステムのものです。
では、作成したスクリプトに戻りましょう。事前の設定をせずに使用すると、メッセージボックスに以下のように表示されます。
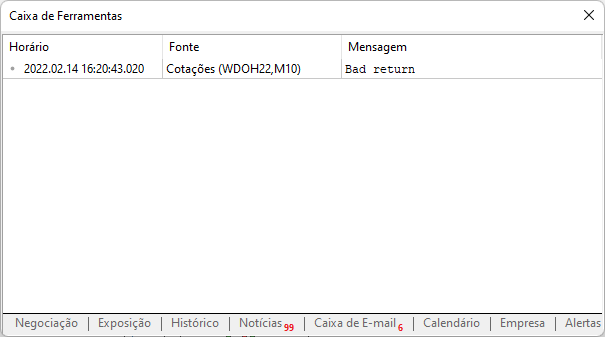
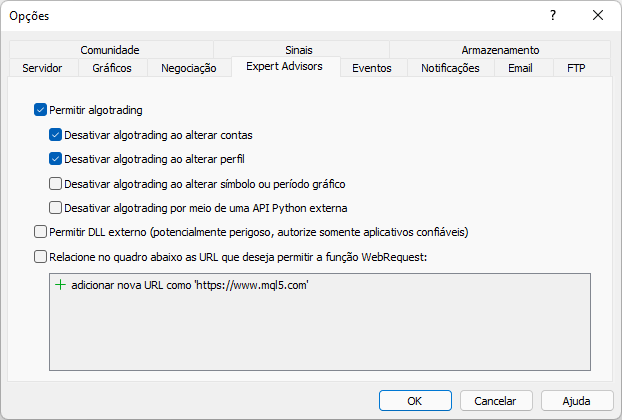
このメッセージは、MetaTraderプラットフォームでWebサイトを許可していないために表示されました。下図のように実装する必要があります。何が追加されたのかに注目してください。MetaTrader取引プラットフォームを介してアクセスするサイトルートアドレスです。

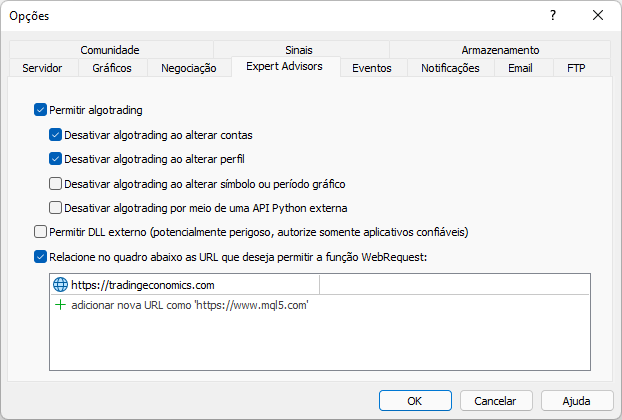
ここで、もう一度同じスクリプトを実行すると、プラットフォームから次のような出力が報告されます。
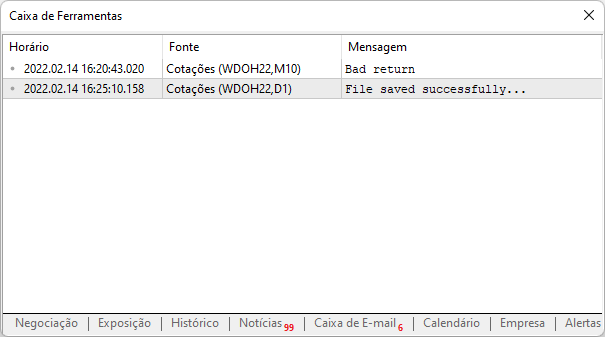
サイトへのアクセスが成功し、データがコンピュータにダウンロードされ、これから分析できるということです。もちろん、このファイルのバックアップを上記のパスに作成しておくことが前提です。
ここですべてがどのように動作するのかを理解し、より詳細な情報を得るには、ドキュメントのWebRequest関数をご覧ください。ネットワーク通信プロトコルをさらに深く掘り下げたい場合は、MQL5で紹介されている他のネットワーク関数をご覧になることをお勧めします。このような関数を知っておくことは、時に大きなトラブルを回避することにつながります。
目的のサイトからデータをダウンロードするところまで、最初の部分を完了させました。さて、次の手順を説明しますが、これは同じくらい重要です。
1.0.2.データ検索
MetaTrader 5プラットフォームで取得するデータをWebサイト内で検索する方法がわからない方のために、短いビデオを作成し、この検索の進め方を簡単に説明します。
データを取得したいWebサイトのコードを解析するために、ブラウザの使い方を知っておくことが重要です。この作業には、ブラウザ自体が大いに役立つので、難しいことではありません。ただし、それは必ず身につけなければならないことで、やり方が分かれば、いろいろな可能性が広がります。
検索にはChromeを使いますが、開発者ツールを使ってコードにアクセスできる他のブラウザを使ってもかまいません。
このブロックは、上のビデオで探していたブロックと同じものです。ブラウザを使った探し方は本当に重要で、そうでないとダウンロードした情報の中で迷子になってしまいます。
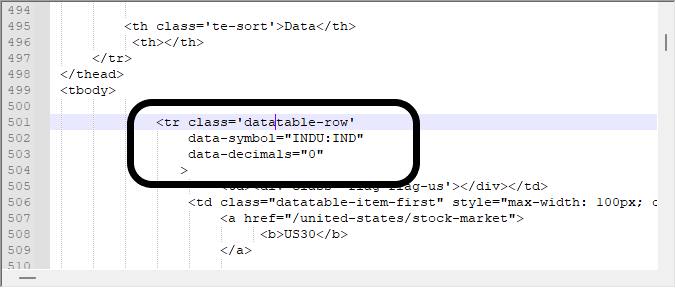
ただし、このようにデータを見るだけでは十分でない場合もあります。正確に把握するためには、バイナリエディタに頼らざるを得ません。確かにデータモデリングは比較的単純な場合もありますが、データに画像やリンクなどが含まれる場合は、もっと複雑になることもあります。このようなことは、通常、誤検知をもたらして検索を困難にする可能性があるため、何を扱っているかを知る必要があります。同じデータをバイナリエディタで見てみると、次のような値が得られます。
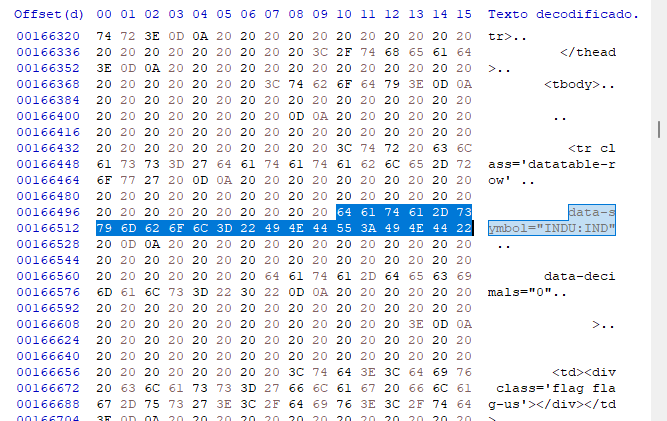
動的ページの場合はオフセットが変化する可能性があるため、この最初の手順ではオフセットには関心がありません。関心があるのはどのようなモデリングが使用されているかを確認することです。この場合、これは非常に明確で、この種の情報を基にした検索システムをバイナリエディタで使用することができます。このため、このプログラムによる検索は、この最初の瞬間には効率的なシステムではないにしても、実装が若干簡単になります。私たちの検索データベースは、より簡単にアクセスすることができます。入力を使用し、CARRIAGEやRETURNなど、実際には役立つよりも妨げとなる追加文字は一切使用しません。プログラムコードは次のようになります。
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks")); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 100) { string headers, szInfo; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; szInfo = ""; for (int c0 = 0, c1 = ArraySize(charResultPage); c0 < c1; c0++) szInfo += CharToString(charResultPage[c0]); if ((handle = StringFind(szInfo, "data-symbol=\"INDU:IND\"", 0)) >= 0) { handle = StringFind(szInfo, "<td id=\"p\" class=\"datatable-item\">", handle); for(; charResultPage[handle] != 0x0A; handle++); for(handle++; charResultPage[handle] != 0x0A; handle++); szInfo = ""; for(handle++; charResultPage[handle] == 0x20; handle++); for(; (charResultPage[handle] != 0x0D) && (charResultPage[handle] != 0x20); handle++) szInfo += CharToString(charResultPage[handle]); } return szInfo; }
スクリプトのアイデアは、ページ上の値をキャプチャすることです。この方法の利点は、オフセットによって情報の位置が変わっても、それらのコマンドの中から情報を見つけることができるということです。ただし、すべてが理想的に見えても、情報にはわずかな遅れがあるので、上記のスクリプトを実行したときに、取り込んだデータをどのように扱うかを測定しておく必要があります。実行結果は以下のようになります。
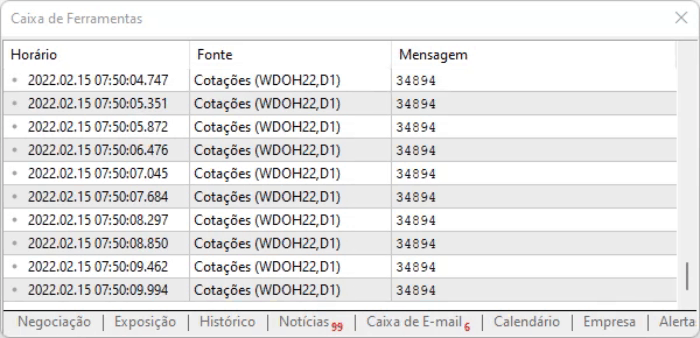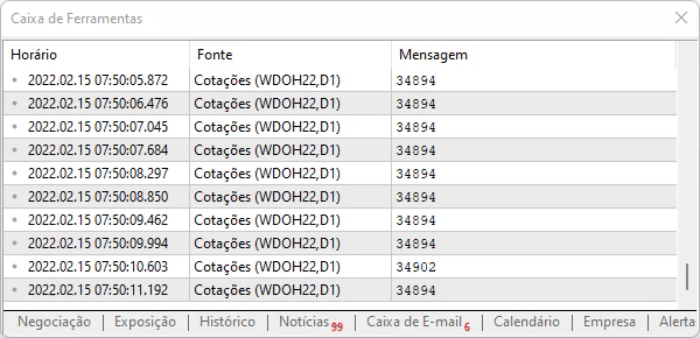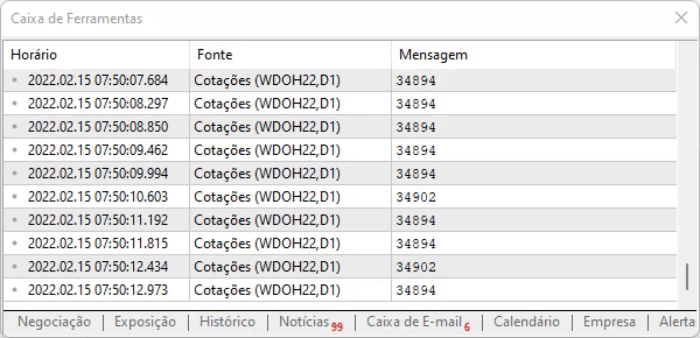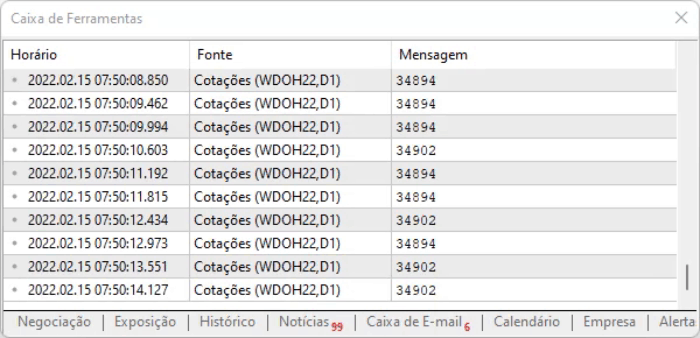
文字で表現しにくい部分は、実際に見てみないと分からないので、ご自分で分析して情報がどのように記録されているかを確認することをお勧めします。
では、次について考えてみましょう。上記のスクリプトは、静的なモデルを持つページを使用する場合には実際には必要のない操作をおこなうため、実行効率はあまり良くはありませんが、私たちが検討しているページのような動的コンテンツのために使用されます。この特殊なケースでは、オフセットを使ってより速く解析し、その結果、データを取り込む効率を少し向上ことができます。ただし、システムがキャッシュに情報を保持できるのは数秒であるため、ブラウザで観測したデータと比較すると、取り込んでいる情報が古くなっていることがあります。この場合、システム内部の調整で解決する必要がありますが、これはこの記事の目的ではありません。
そこで、上記のスクリプトをオフセットを使って検索をおこなうものに変更すると、コードが以下のようになります。
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo; }
さらにスクリプトの実行結果を確認できます。難しい変更はなく、オフセットモデルを適用することで計算時間が短縮されるだけです。これらにより、システム全体のパフォーマンスが若干向上されます。
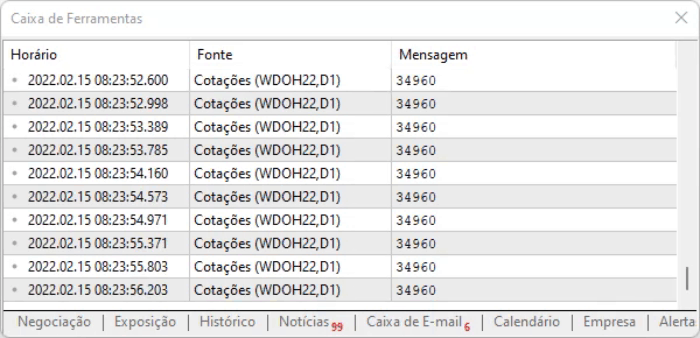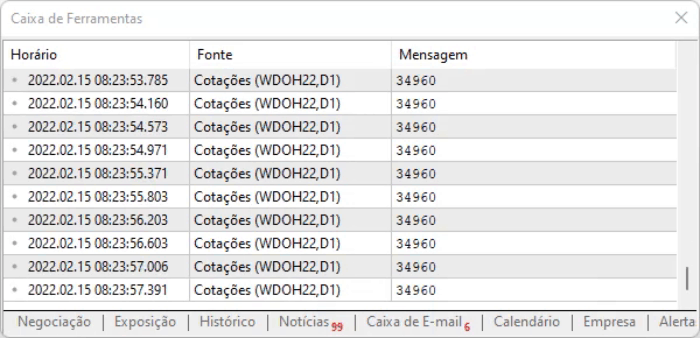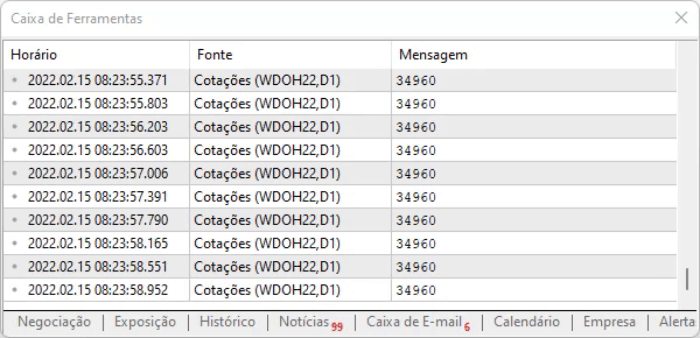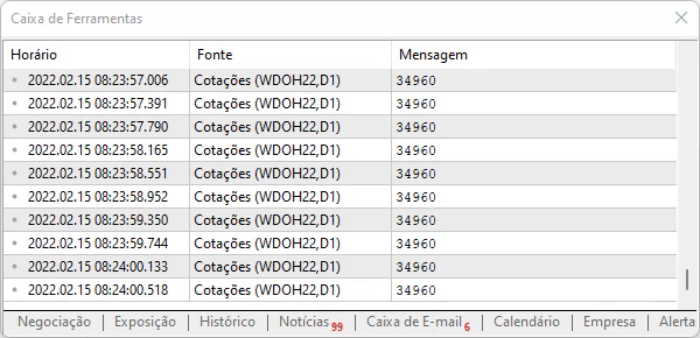
上記のコードは、ページが静的なモデルであったために動作しただけです。コンテンツは動的に変化しますが、デザインは変化しないので、バイナリエディタを使って情報の位置を調べ、オフセット値を取得し、その位置にすぐに移動することができます。しかし、オフセットがまだ有効であることをある程度保証するために、次の行で簡単なテストを実行します。
for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position";
これは非常にシンプルなことですが、オフセットに基づいて取得される情報に関して最低限のセキュリティを確保するために必要なことです。そのためには、ページを解析して、オフセット方式でデータを取り込むことが可能かどうかを確認する必要があります。可能であれば、処理時間を短縮できるメリットを受けられます。
1.0.3.解決すべき課題
このシステムは非常にうまく動作することが多いのですが、サーバーから次のような応答が返ってくることがあります。
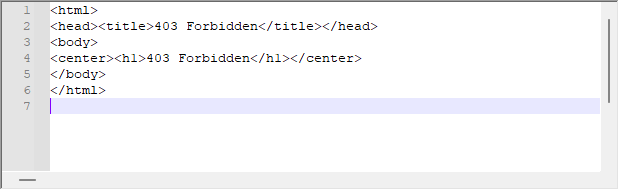
これは要求に対するサーバーの応答です。WebRequestがプラットフォーム側でエラーを示さない場合でも、サーバーはこのメッセージを返すことがあり、この場合、リターンメッセージのヘッダーを解析して問題を理解する必要があります。この問題を解決するためには、以下のようにオフセットスクリプトを少し変更する必要があります。
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "<!doctype html>", 2, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szTest, int iTest, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1 return "Bad"; for (int c0 = 0, c1 = StringLen(szTest); c0 < c1; c0++) if (szTest[c0] != charResultPage[iTest + c0]) return "Failed"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo;
ハイライト表示された行ではテストを実行します。サーバーから返されたメッセージがより複雑な場合、このテストを実行するという事実だけで、システムが以前のコードにすでに存在していた最初のテストに合格した場合、ファントムデータやメモリガベージの分析を回避して、分析しているデータに十分な安全性が既に保証されるためです。めったにないことではありますが、その可能性を過小評価してはなりません。
以下のように、結果に違いがないことから、期待通りに動作していることがわかります。
今のところ、大したことはしていません。Webページから値を読み取るだけで、あまり役に立ちませんが、どのようにおこなわれているかを知り、見ることは非常に興味深いことです。ただし、実際に今この瞬間からモデルしている情報を、別の方法で捉えて見せて、それを元に取引したい人にとっては、あまり意味のないことだと思います。より広いシステムの中で何らかの意味を持つように、何かをしなければなりませんが、私たちはこの取得した情報をEAに取り込みます。こうすることで、さらに素晴らしいことができるようになります。それがMetaTrader 5をセンセーショナルなプラットフォームにしているのです。
結論
まだこれで終わりではありません。次回は、Web上で収集した情報をEAに取り込む方法を紹介します。これは非常に印象的です。MetaTraderプラットフォーム内でほとんど調査されていないリソースを使用することになります。それでは、次回の連載をお見逃しなく。
この記事で使用されているすべてのコードは以下に添付されています。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/10430
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 ニューラルネットワークが簡単に(第14部):データクラスタリング
ニューラルネットワークが簡単に(第14部):データクラスタリング
 データサイエンスと機械学習(第03回):行列回帰
データサイエンスと機械学習(第03回):行列回帰
 ビデオ:シンプルな自動取引 – MQL5でシンプルなエキスパートアドバイザーを作成する方法
ビデオ:シンプルな自動取引 – MQL5でシンプルなエキスパートアドバイザーを作成する方法
 パラボリックSARによる取引システムの設計方法を学ぶ
パラボリックSARによる取引システムの設計方法を学ぶ
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
私が見逃した詳細は?
私が見逃した詳細は?
おそらくある。記事全体を読んで見る必要がある.記事の中にあるビデオも含めて、全部だ。そこで、どうやって情報を取得するのか、その詳細を紹介している。ページが管理者によって変更された場合、このアドレスは異なるものになるので、新しいアドレスがどこにあるのかを探す必要がある。記事を読むビデオを見て、私が説明していることを理解し、情報がどこにあるかを示すために使用されているアドレスを変更すれば、そのページにあるデータを他のどのページからも得ることができる。そうでなければ、ページをダウンロードし、ループを使って情報を検索することもできるが、時間は貴重だ.😁👍
興味深い記事だが、黄色の意味が理解できない?
16進数だし。どうすれば正しく配置できるのでしょうか?
興味深い記事だが、黄色の意味が理解できない。
16進数だし。どうすれば正しく配置できるのでしょうか?
0xで始まる値はHEXA値で、それ以外は普通の10進数です。DECIMAL値を使うこともできますが、分かりにくいと感じることがあります。私は通常ASCII値を使うので、HEXAを使う方が好きです。しかし、0x0Dという値はENTERキーを表している。そして0x20はSPACEキーである。これらの値を見つけ、正しく配置するには、ファイルとHEXADECIMALエディターが必要です。そして、ファイルの中の値を調べて、その値がファイルのどこにあるかをプロシージャに伝える必要があります。つまり、172783と173474という値は、アドレス、つまりダウンロードされるファイル内の位置です。
HEXADECIMAL EDITORの使い方を覚えておくと、これらのアドレスを理解しやすくなりますよ😁👍。