
从头开始开发智能交易系统(第 15 部分):访问 web 上的数据(I)

概述
MetaTrader 5 是交易者希望使用的最通用、最完整的平台。 尽管有其它观点,但该平台非常有效和强大,因为它提供的机会远远不止是简单观察绘制的图表,以及当前的买卖操作。
所有这些力量都来自这样一个事实,即该平台使用的语言几乎相当于目前最强大的一种语言 — 我们正在谈论的是 C/C++。 这种语言能为我们提供的可能性远远超出了不具备编程技能的普通交易员能够执行或理解的范畴。
在市场操作期间,我们需要以某种方式与全球层面涉及的各种问题联系起来。 我们不能仅仅停留在图表上 — 重要的是要考虑到其它相关信息,这些信息不光有关联,它们可能是一个决定性因素,也是交易中决定胜负所在。
互联网上有很多网站,提供海量信息。 您需要知道的是,在哪里查找、以及如何才能最好地利用这些信息。 在正确的时间段,您得到的信息越多,交易就会越好。 然而,如果您打算使用浏览器,不管它是什么:您会发现很难出色地过滤某些信息,您不得不同时查看多面屏幕和监视器,最后,尽管信息无处不在,但您也可能没用上它。
但要感谢 MQL5,由于它非常接近 C/C++,程序员可以做的不仅仅是按原样使用图表:我们还可以在 web 上搜索、过滤、分析数据,从而能以比大多数交易者更一致的方式执行操作,因为我们能利用所有的计算能力来支持我们。
1.0. 计划
计划部分至关重要。 首先,有必要找到从哪里获取想要使用的信息。 实际上,这应该比表面上看起来更加小心,因为一个好的信息来源将为我们指明正确的方向。 每个人都应该独立完成这一步,因为每位交易者可能在不同的时间需要一些特定的数据。
无论您如何选择来源,我们接下来要做的对于每个人来说基本上都是一样的,而且本文对于那些仅希望采用 MQL5 提供的方法和工具,而不愿用到任何外部程序和工具的人来说,亦可作为学习材料。
为了勾勒整个过程,我们将利用行情信息网页来展现整个过程的工作原理。 我们将贯彻该过程的所有步骤,您也能够根据您的具体需求调整这些方法的用法。
1.0.1. 开发捕获程序
为了开始操控数据,我们需要创建一个小程序来收集数据,并能够高效准确地分析数据。 为此目的,我们将用到一个非常简单的程序,如下所示:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { Print(GetDataURL("https://tradingeconomics.com/stocks")); } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 750) { string headers; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; if ((handle = FileOpen("url.txt", FILE_WRITE | FILE_BIN)) != INVALID_HANDLE) { FileWriteArray(handle, charResultPage, 0, ArraySize(charResultPage)); FileClose(handle); }else return "Error saving file ..."; return "File saved successfully..."; }
这个程序极其简单,真是再简单不过了。
我们做了以下工作:在高亮显示的部分中,我们指出了我们希望从其接收信息的站点。 为什么我们使用它,而非浏览器? 好了,我们确实可以在浏览器中捕获信息,但我们是要下载数据后,再从其中帮助搜索信息。
但是仅仅键入和编译这个程序是没有用的。 您还应该做些别的事,否则它就不会工作。
在 MetaTrader 平台中,在运行此脚本之前,我们需要授权平台从所需站点接收数据。 为了避免每次需要安装 MetaTrader 平台时都这样做,您可以在一切设置完毕后保存此数据的备份副本。 文件应保存在以下路径:
C:\Users\< USER NAME >\AppData\Roaming\MetaQuotes\Terminal\< CODE PERSONAL >\config\common.ini
USER NAME 是您的操作系统中的用户名。 CODE PERSONAL 是平台在安装过程中创造的识别码。 因此,您可以轻松找到文件进行备份,或在新安装后进行替换。 只有一点:这个地方归属于 WINDOWS 系统。
现在我们回到我们创建的脚本。 如果您在没有预先设置的情况下使用它,您就会在消息框中看到以下内容。
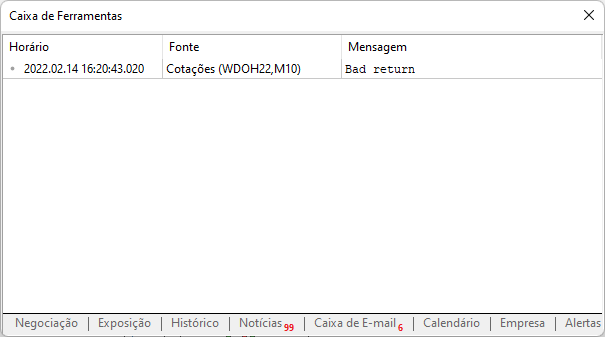
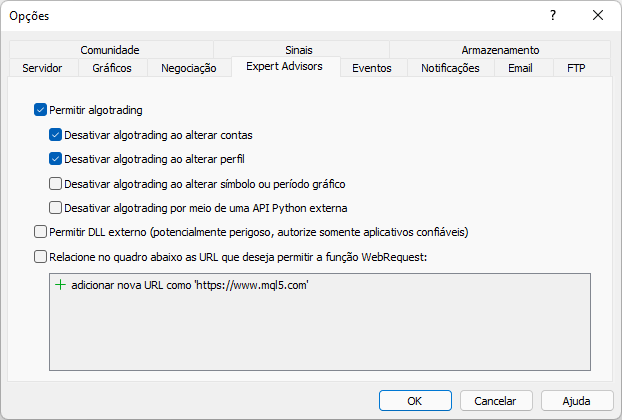
显示此消息是因为我们尚未授权 MetaTrader 平台访问该网站。 该如下图所示实施设置。 注意添加的内容。 请注意,这是我们授权 MetaTrader 交易平台可以访问的站点根地址。

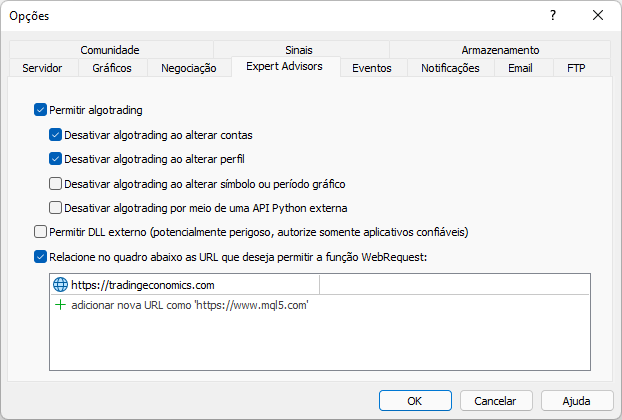
现在,如果我们再次运行相同的脚本,我们将看到平台报告的以下输出:
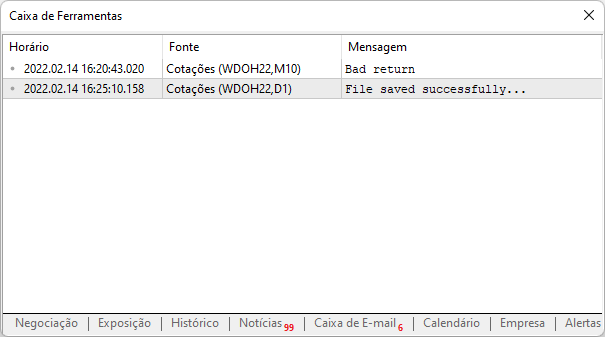
这意味着该网站已成功访问,数据已下载到您的计算机,现在您就可以对其进行分析。 一个重要的细节是,现在我们不必担心再次反复将同一个站点添加到平台,当然,前提是您按照上面显示的路径创建该文件,并备份。
为了理解这里的一切是如何工作的,并获得更详细的信息,您可以查看文档中的 WebRequest 函数。 如果您想更深入地研究网络通信协议,我建议您看看 MQL5 中介绍的其它网络函数。 了解这些函数有时可以为您节省很多麻烦。
我们已经完成了工作的第一部分 — 我们可以从所需的网站下载数据。 现在我们需要进入下一步,这一步同样重要。
1.0.2. 数据搜索
对于那些不知道如何从 MetaTrader 5 平台捕获的网站数据中搜索关键信息的人,我制作了一个短视频,在其中我快速演示了如何处理这类的搜索。
重要的是,您要知道如何使用浏览器解析您想从中获取数据的网站的代码。 这并不难,因为浏览器本身在这项任务中帮助很大。 但这是您必须学会做的事情。 一旦您明白了如何去做,您就会有有更多机会。
我将使用 Chrome 进行搜索,但您可以使用任何其它浏览器,并用开发人员工具访问代码。
我们感兴趣的是从下面显示的模块中获取数据,这与我在上面的视频中查找的模块相同。 知道如何使用浏览器查找东西真的很重要,否则您会迷失在所有这些下载的信息当中。
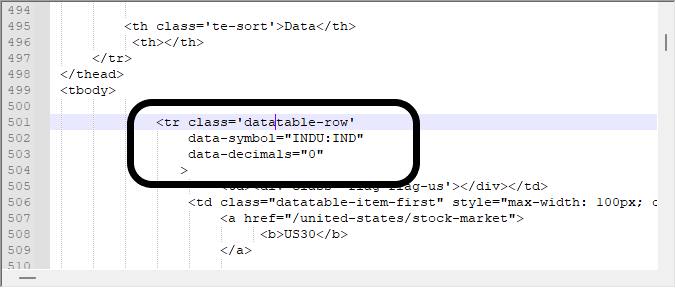
但在某些情况下,仅仅以这种方式查看数据可能是不够的。 我们必须求助于十六进制编辑器来准确了解我们正在处理的内容。 的确,在某些情况下,数据建模相对简单,但在其它情况下,这可能要复杂得多 — 当数据包含图像、链接和其它内容时。 这样的事情会令搜索变得困难,因为它们通常会提供误报,所以我们需要知道我们在处理什么。 在十六进制编辑器中查找相同的数据,我们得到以下数值。
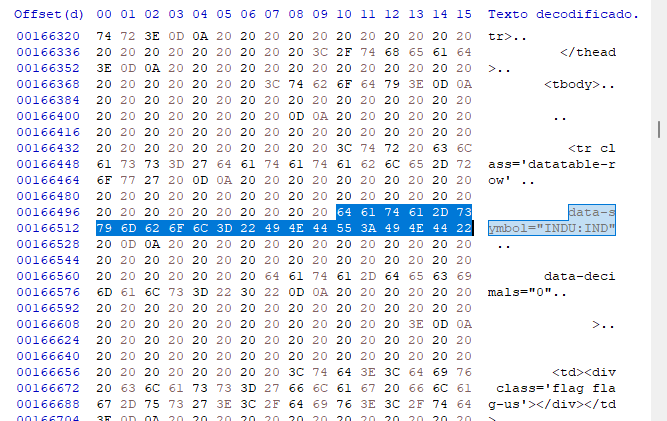
在这第一步中,我们对偏移量不感兴趣,因为它们在动态页面的情况下可能会发生变化,但我们感兴趣的是查看用到了哪种建模类型。 在这种情况下,这是非常清晰的,利用十六进制编辑器找到信息的类型,据此我们就可以用一个搜索系统来处理。 这会令我们的程序搜索实现稍微简单一些,即使它在第一时刻,还不是一个有效的系统。 我们的搜索数据库更容易访问 — 我们将使用输入,不会用到任何额外的字符,如回车或回车,这对我们的阻碍实际上大于帮助。 因此,程序代码如下。
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks")); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 100) { string headers, szInfo; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; szInfo = ""; for (int c0 = 0, c1 = ArraySize(charResultPage); c0 < c1; c0++) szInfo += CharToString(charResultPage[c0]); if ((handle = StringFind(szInfo, "data-symbol=\"INDU:IND\"", 0)) >= 0) { handle = StringFind(szInfo, "<td id=\"p\" class=\"datatable-item\">", handle); for(; charResultPage[handle] != 0x0A; handle++); for(handle++; charResultPage[handle] != 0x0A; handle++); szInfo = ""; for(handle++; charResultPage[handle] == 0x20; handle++); for(; (charResultPage[handle] != 0x0D) && (charResultPage[handle] != 0x20); handle++) szInfo += CharToString(charResultPage[handle]); } return szInfo; }
脚本的思路就是捕捉页面上的值。 上述方法的优点是,即使信息由于偏移而改变位置,我们仍然可以在所有这些命令中找到它。 但是,即使一切看起来都很理想,信息也会有一点延迟,因此有必要衡量在执行上述脚本时,您将如何处理捕获的数据。 执行结果如下所示。
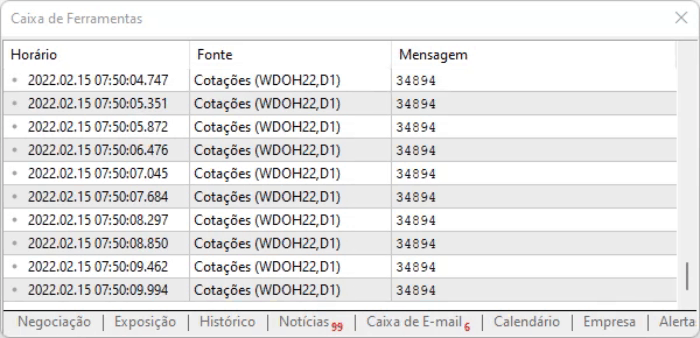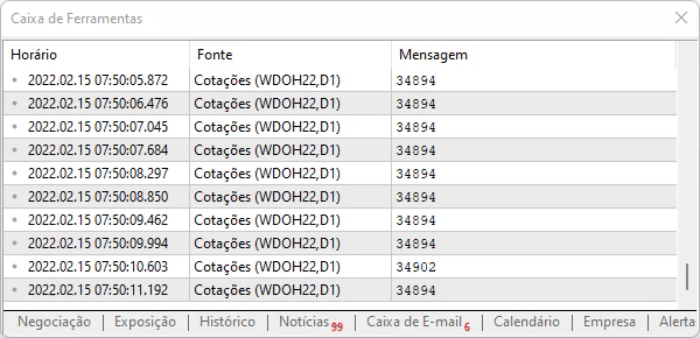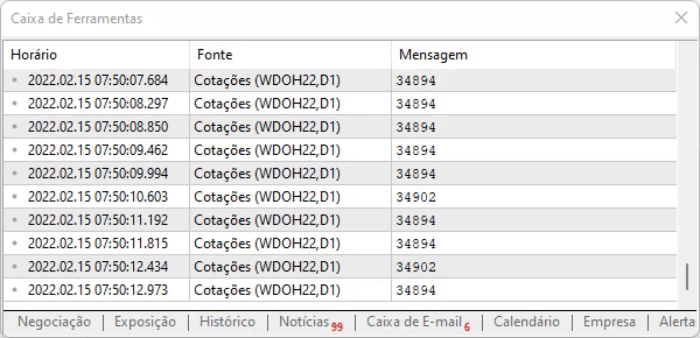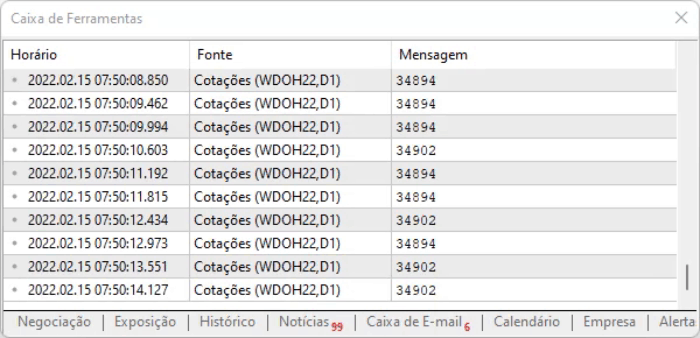
我建议您自行进行分析,看看信息是如何记录的。因为了解那些不太容易用文字形式描述的细节很重要:您需要亲眼所见才能理解。
现在,我们来思考以下内容。 上面的脚本在执行方面不是很有效,因为它执行的一些操作,实际上对于静态模型的页面,并无必要。 但它将会与动态内容一起使用,就像我们正在考虑的页面一样。 在这种特殊情况下,我们可以依据偏移量更快地解析数据,从而更有效地捕捉数据。 但请记住,系统可以将信息保存在缓存中几秒钟。 因此,与浏览器中观察到的数据相比,正在捕捉的信息可能已过时。 在这种情况下,必须在系统中进行一些内部调整,从而解决此问题。 但这并非本文的目的。
因此,通过将上面的脚本修改为依据偏移量进行搜索,我们得到以下代码,如下所示:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo; }
可以进一步查看脚本执行结果。 没有太大的变化,但这只是一个计算时间问题,依据偏移模型可以减少计算时间。 所有这些都略微提高了系统的整体性能。
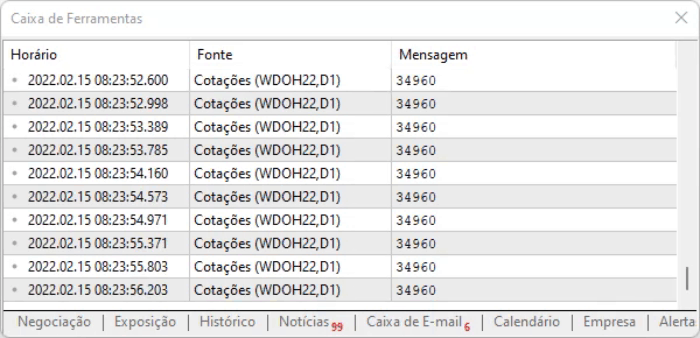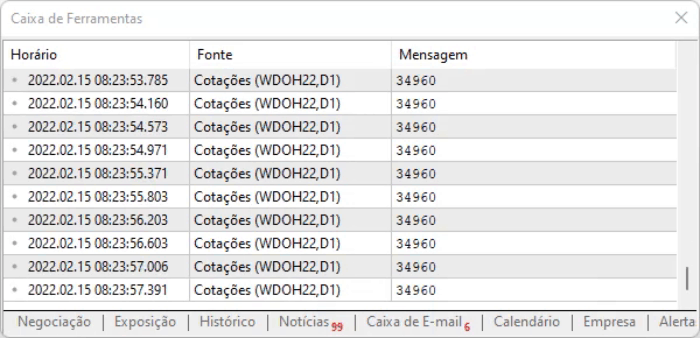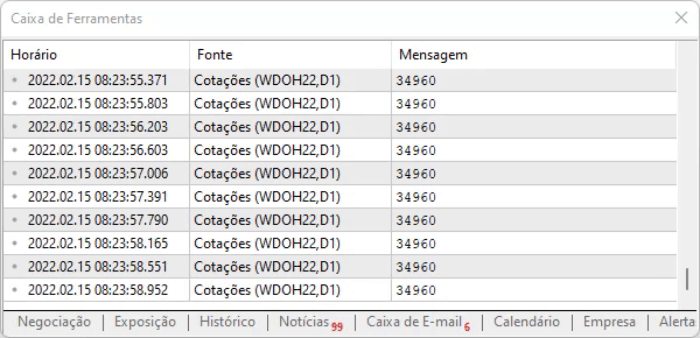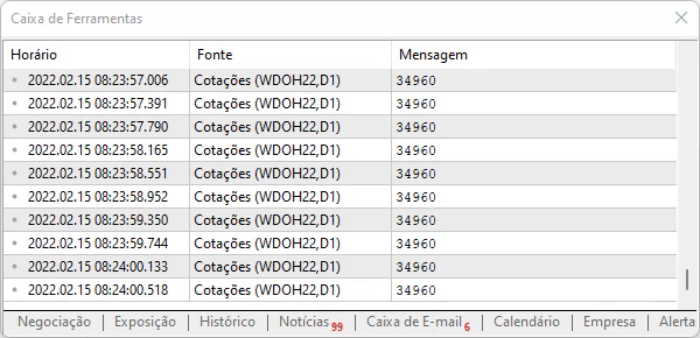
请注意,上面的代码之所以能工作,是因为页面有一个静态模型:虽然内容是动态更新的,但其设计没有更改,因此我们可以使用十六进制编辑器,查找信息的位置,获得偏移值,然后立即定位到这些位置。 但为了在一定程度上保证偏移仍然有效,我们进行了一个简单的测试,该测试在以下行中执行:
for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position";
这是一件非常简单,但并无必要的事情,如此我们对基于偏移量捕捉的信息具有最低的安全性。 为此,我们需要分析页面,并检查是否可以依据偏移量方法来捕捉数据。 如果可能,您会从较低的处理时间里受益。
1.0.3. 要解决的问题
虽然系统通常运行良好,但我们可能会从服务器收到以下响应:
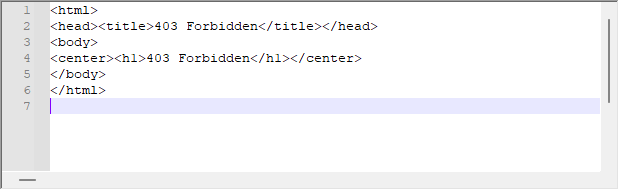
这是服务器对我们请求的响应。 即使 WebRequest 没有指出平台端的任何错误,服务器也可以返回此消息。 在这种情况下,我们应该分析返回消息的标头,来了解问题本质。 为了解决这个问题,有必要对偏移脚本进行略微的更改,如下所示:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "<!doctype html>", 2, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szTest, int iTest, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1 return "Bad"; for (int c0 = 0, c1 = StringLen(szTest); c0 < c1; c0++) if (szTest[c0] != charResultPage[iTest + c0]) return "Failed"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo;
在高亮显示的代码行即为要执行的测试之一,因为当从服务器返回的消息更复杂时,如果系统通过了前面代码中的第一个测试,那么执行此测试就能保证我们在分析的数据上有一个良好的安全裕度,避免了对虚拟数据或内存垃圾的分析。 尽管这种情况很罕见,但我们不应低估其发生的可能性。
您可以在下面看到,结果没有什么不同,这意味着系统正在按预期工作。
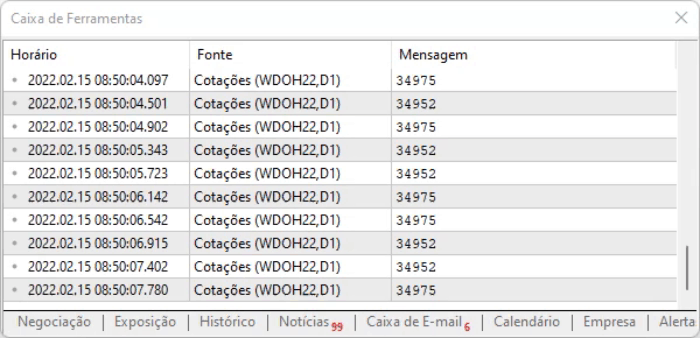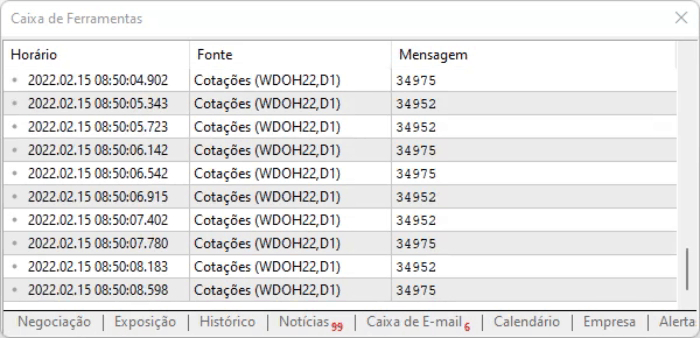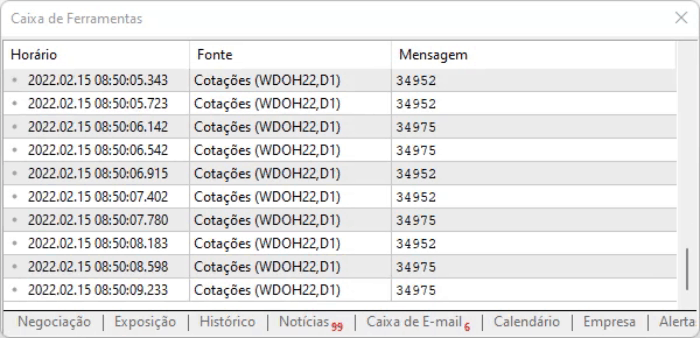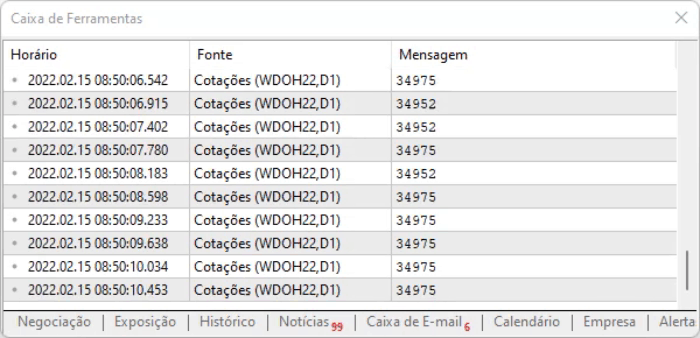
到目前为止,我们还没有做太多的工作 — 我们只是从一个网页上读取数据,它并无多大用处,尽管了解和观察它是如何完成的很有趣。 然而,对于那些真正想要基于信息进行交易的人来说,这用处不大,从现在起,当您捕获信息并以另一种方式显示它时,您将对其进行建模。 因此,我们必须采取一些措施,令其在更广泛的体系中具有一定的意义。 然而,我们将把这些捕捉到的信息带入 EA,这样我们将能够做更多令人印象深刻的事情,这令 MetaTrader 5 成为一个轰动的平台。
结束语
好了,这还没有结束。 在下一篇文章中,我将展示如何把从 WEB 上收集到的这些信息引入 EA,这将给人留下深刻的印象:我们将会用到在 MetaTrader 平台中很少曝光的资源。 因此,不要错过本系列的下一篇文章。
本文中用到的所有代码附在文后。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/10430
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 神经网络变得轻松(第十四部分):数据聚类
神经网络变得轻松(第十四部分):数据聚类
 学习如何基于抛物线 SAR 设计交易系统
学习如何基于抛物线 SAR 设计交易系统
 视频:简单自动交易 — 如何利用 MQL5 创建简单的智能交易系统
视频:简单自动交易 — 如何利用 MQL5 创建简单的智能交易系统

我错过了哪些细节?
我错过了哪些细节?
可能有...你需要阅读和观看整篇文章...所有内容,包括文章中的视频,因为我在视频中向你展示了如何捕获信息的一些细节......细节在于,系统经过优化,可以转到一个特定的内存地址,而不会一直查找信息,因为这样会非常慢,因为我们使用的是实时系统......如果页面被管理员修改,这个地址就会不一样,所以你必须搜索新的地址,但在文章中,我将详细告诉你如何找到新地址 ....,以及在这种特殊情况下,如何看到错误信息,表明该地址与系统预期查找信息的地址不同......阅读文章 ...观看视频并理解我在视频中解释的内容,更改用于指示信息位置的地址,您将获得该页面上的数据,以及来自任何其他页面的数据 ....,记住搜索必须快速完成,因为系统是实时的...如果不是实时的,我们可以下载页面并使用循环来搜索信息,但时间是宝贵的......😁👍
文章很有意思,但我不明白黄色是什么意思?
而且是十六进制数字。如何正确定位?
这篇文章很有意思,但我不明白黄色是什么意思?
而且是十六进制数字。如何正确定位?
以 0x 开始的值是十六进制值,其余的是普通十进制值。您可以使用十进制值,但我觉得有时很难理解。因为我通常使用 ASCII 值,所以我更喜欢使用 HEXA 值。但 0x0D 代表 ENTER 键。而 0x20 代表空格键。要找到这些值并正确定位,你需要有文件和 HEXADECIMAL 编辑器。然后需要查找文件中的值,告诉程序该值在文件的哪个位置。因此,值 172783 和 173474 是地址,或者说是下载文件中的位置。
尝试学习如何使用 HEXADECIMAL 编辑器,这样会更容易理解这些地址。