
Developing a trading Expert Advisor from scratch (Part 15): Accessing data on the web (I)

Introduction
MetaTrader 5 is the most versatile and complete platform a trader could wish for. Despite other opinions, the platform is extremely effective and powerful, as it provides the opportunities that go far beyond a simple observation of plotted chart, with current-time buying and selling operations.
All this power comes from the fact that the platform uses a language that is almost equal to the most powerful one currently existing - we are talking about C/C ++. The possibilities that this language offers us are far beyond what ordinary traders without programming skills are capable of performing or understanding.
During operations in the market, we need to be somehow connected to various issues involved at the global level. We cannot just stick to the chart — it is important to take into accounts other related information which is no less relevant information which can be a decisive factor and a difference between win and lose in a trade.
There are a lot of websites and places on the web, featuring a huge amount information. What you need to know is where to look and how best to use this information. And the better you are informed during the right period, the better it is for trading. However, if you are going to use a browser, whatever it is: you will find that it is very difficult to filter certain information well, that you are forced to look at many screens and monitors, and in the end, although the information is there, it is impossible to use it.
But thanks to MQL5, which is very close to C/C++, programmers can do more than just work with a chart as is: we can search, filter, analyze data on the web and thus perform operations in a much more consistent way, than most traders because we are going to use all the computing power in our favor.
1.0. Planning
The planning part is crucial. First, it is necessary to find where you are going to get the information that you want to use. This should actually be done with much more care than it may seem, since a good source of information will point us in the right direction. Everyone should do this step individually since every trader may need some specific data at different times.
Regardless of the source you choose, what we will do next will be basically the same for everyone, so this article can serve as a study material for those who wish to use the method and tools that are available by using only MQL5, without any external program.
To illustrate the whole process, we will use a market information web page to show how the whole thing works. We will go through all steps of the process, and you will be able to use this method adjusting it to your specific needs.
1.0.1. Developing a capture program
To start working with the data, we need to create a small program to collect data and to be able to analyze it efficiently and accurately. For this purpose, we will use a very simple program shown below:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { Print(GetDataURL("https://tradingeconomics.com/stocks")); } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 750) { string headers; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; if ((handle = FileOpen("url.txt", FILE_WRITE | FILE_BIN)) != INVALID_HANDLE) { FileWriteArray(handle, charResultPage, 0, ArraySize(charResultPage)); FileClose(handle); }else return "Error saving file ..."; return "File saved successfully..."; }
This program is extremely simple, nothing could be simpler.
We do the following: in the highlighted part, we indicate the site from which we want to receive information. Why are we using it and not the browser? Well, it's true that we can capture information in the browser, but we will use it to help find information after downloading the data.
But it's no use just typing and compiling this program. There is something else you should do, otherwise it won't work.
In the MetaTrader platform, before running this script, we need to allow the platform to receive data from the desired site. To avoid doing this every time you need to install the MetaTrader platform, you can save a backup copy of this data after everything is set up. The file should be saved at the following path:
C:\Users\< USER NAME >\AppData\Roaming\MetaQuotes\Terminal\< CODE PERSONAL >\config\common.ini
USER NAME is your user name in the operating system. CODE PERSONAL is the value which the platform creates during installation. Thus, you can easily find the file to make a backup or to replace after a new installation. Just one point: this place belongs to the WINDOWS system.
Now let's get back to the script we have created. If you use it without a prior setup, you will see the following in the message box.
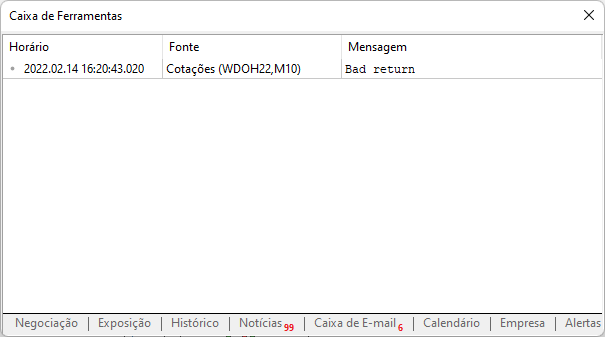
This message was displayed because we didn't allow the website in the MetaTrader platform. This should be implemented as shown in the figure below. Pay attention to what has been added. Notice that it is the site root address which we are going to access via the MetaTrader trading platform.
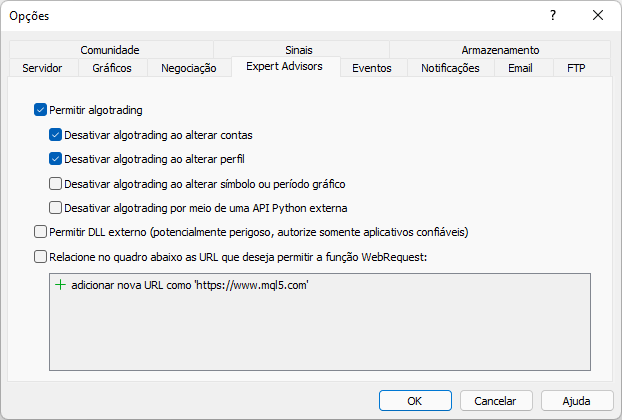

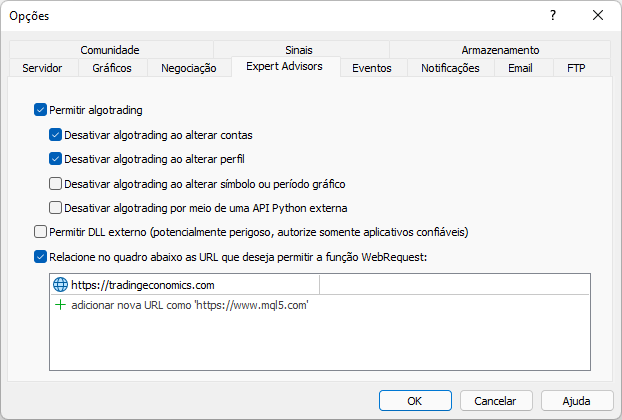
Now, if we run the same script again, we will see the following output reported by the platform:
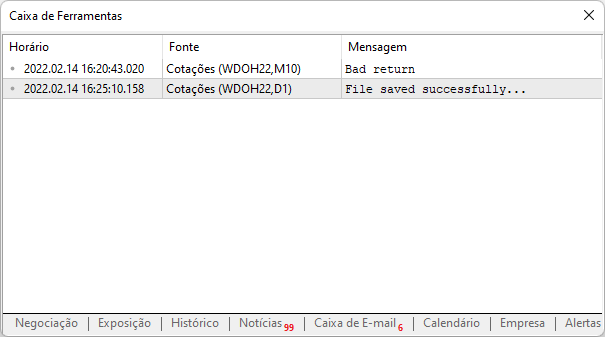
It means that the site was successfully accessed, the data was downloaded to your computer and now you can analyze it. An important detail is that now we don't have to worry about adding the same site to the platform again, of course provided that you create a backup of this file at the path shown above.
To understand how everything will work here and to get more detailed information, you can look at the WebRequest function in the documentation. If you want to delve even deeper into the network communication protocol, I recommend taking a look at other network functions, presented in MQL5. Knowing such functions can sometimes save you a lot of trouble.
We have completed the first part of the work is done — we got to downloading data from the desired site. Now we need to go through the next step, which is no less important.
1.0.2. Data search
For those who don't know how to search for the data to be captured by the MetaTrader 5 platform within a website, I made a short video, where I quickly demonstrate how to proceed with this search.
It is important that you know how to use your browser to parse the code of the website from which you want to get the data. It is not difficult, since the browser itself helps a lot in this task. But it is something that you must learn to do. Once you understand how to do it, a lot of possibilities will open up to you.
I will be using Chrome for search, but you can use any other browser which provides access to the code using developer tools.
We are interested in is obtaining data from this block shown below, which is the same block I was looking for in the video above. It is really important to know how to look for things using the browser, otherwise you would be lost in all this downloaded information.
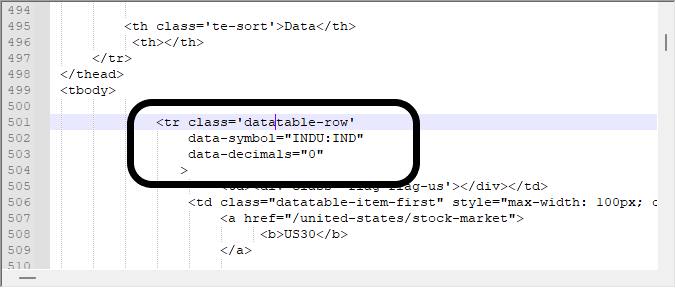
But in some cases, just looking at the data in this way may not be enough. We have to resort to a hex editor to know exactly what we are dealing with. It is true that in some cases the data modeling is relatively simple, but in other cases this can be much more complex - when data contains images, links and other things. Such things can make search difficult as they usually provide false positives, so we need to know what we are dealing with. Looking for the same data in a hex editor, we get the following values.
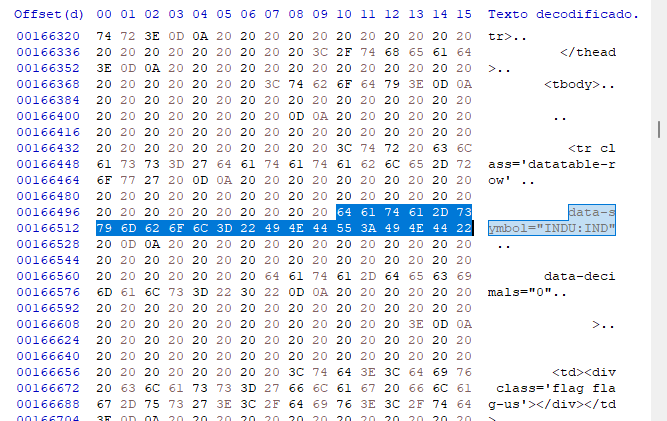
We are not interested in the offsets at this first step since they can change in cases of dynamic pages, but we are interested to see which kind of modeling is used. In this case it is very clear, and we can use a search system based on this type of information found here in hex editor. This makes search by our program slightly simpler to implement, even if it is not an efficient system at this first moment. Our search database is easier to access - we will use inputs and will not use any additional characters, such as CARRIAGE or RETURN, which actually hinder us more than help. So, the program code is as follows.
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks")); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 100) { string headers, szInfo; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; szInfo = ""; for (int c0 = 0, c1 = ArraySize(charResultPage); c0 < c1; c0++) szInfo += CharToString(charResultPage[c0]); if ((handle = StringFind(szInfo, "data-symbol=\"INDU:IND\"", 0)) >= 0) { handle = StringFind(szInfo, "<td id=\"p\" class=\"datatable-item\">", handle); for(; charResultPage[handle] != 0x0A; handle++); for(handle++; charResultPage[handle] != 0x0A; handle++); szInfo = ""; for(handle++; charResultPage[handle] == 0x20; handle++); for(; (charResultPage[handle] != 0x0D) && (charResultPage[handle] != 0x20); handle++) szInfo += CharToString(charResultPage[handle]); } return szInfo; }
The idea of the script is to capture the value on the page. The advantage of the method shown above is that even if the information changes position due to an offset, we can still find it among all those commands. But even if everything seems ideal, there is a small delay in the information, so it is necessary to measure how you will work with the captured data, when the above script is executed. The execution result can be seen below.
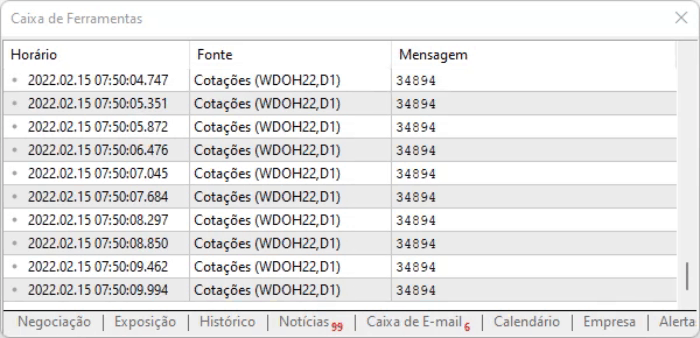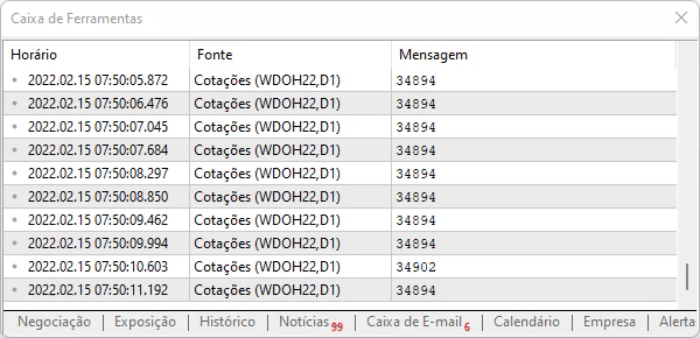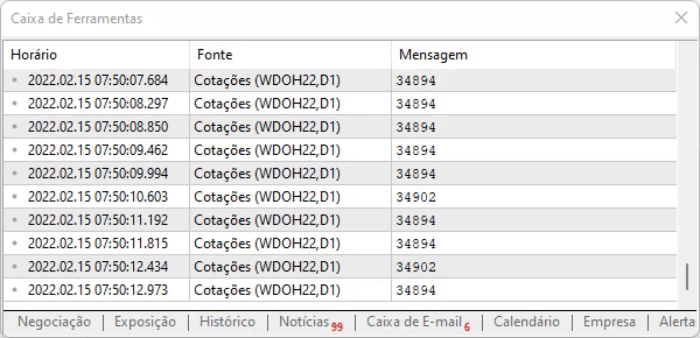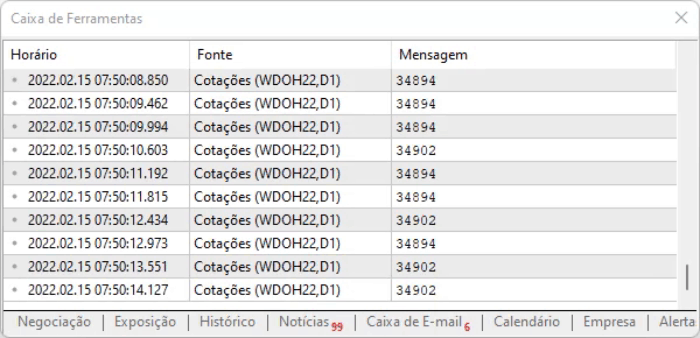
I advise you to conduct your own analysis and see how the information is recorded, because it is important to know the details that are not so easy to describe in text form: you need to see them in order to understand.
Now let's think about the following. The script above is not very efficient in terms of execution, since it does some manipulations that in fact are not necessary when using a page with a static model. But it is used with dynamic content, as in the case of the page we are considering. In this particular case, we can use the offset to parse faster and thus to capture data a bit more efficiently. But remember that the system can keep information in cache for a few seconds. Therefore, the information being captured can be out of date compared with data observed in the browser. In this case, it is necessary to make some internal adjustments in the system to fix this. But this is not the purpose of this article.
So, by modifying the script above to something that uses an offset to do the search, we get the following code, which is shown in full below:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo; }
The script execution result can be seen further. There are no bog changes, while it is just a matter of calculation time which is reduced by applying the offset model. All this slightly improves the overall system performance.
Please note that the code above only worked because the page had a static model: , although the content changed dynamically, its design didn't change, so we can use a hex editor, look up the location of the information, get the offset values, and navigate right away to these positions. But to have some guarantee that the offsets are still valid, we do a simple test which is performed in the following line:
for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position";
This is something very simple, but necessary so that we have a minimum of security regarding the information that is being captured based on the offset. To do this, we need to analyze the page and check if it is possible to use the offset method to capture data. If it is possible, you will benefit from a lower processing time.
1.0.3. A problem to solve
Although the system often works very well, it may happen that we receive the following response from the server:
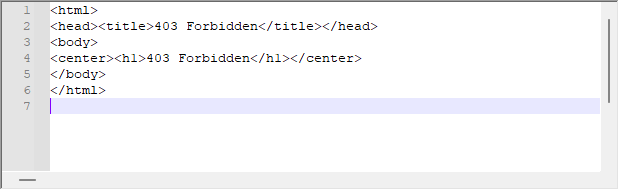
This is the server response to our request. Even though WebRequest does not indicate any error on the platform side, the server can return this message. In this case we should analyze the header of the return message to understand the problem. To solve this problem, it is necessary to make small changes in the offset script, which can be seen below:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "<!doctype html>", 2, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szTest, int iTest, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1 return "Bad"; for (int c0 = 0, c1 = StringLen(szTest); c0 < c1; c0++) if (szTest[c0] != charResultPage[iTest + c0]) return "Failed"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo;
The test is performed in the highlighted line is the one that performs the test, since when message returned from the server is more complex, the mere fact of performing this test already guarantees us a good safety margin on the data we're analyzing, avoiding the analysis of phantom data or memory garbage, if the system passes the first test that already existed in the previous code. Although this rarely happens, we should not underestimate the likelihood that it will happen.
You can see below that the result is no different, which means the system is working as expected.
So far we haven't done much - we're just reading values from a web page, and it's not of much use, although it's quite interesting to know and see how it's done. However, it's not very useful for those who actually want to trade based on the information, which from this moment on you will be modeling, as you capture it and show it in another way. So, we have to do something so that it makes some sense within a broader system. However, we will take this captured information into an EA, in this way we will be able to do even more impressive things and that makes MetaTrader 5 a sensational platform.
Conclusion
Well, this is not yet the end. In the next article, I will show how to take this information collected on the WEB into the EA, and this will really be impressive: we will have to use very little-explored resources within the MetaTrader platform. So, don't miss the next article in this series.
All the codes used in the article are attached below.
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/10430
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

 Learn how to design a trading system by Standard Deviation
Learn how to design a trading system by Standard Deviation
 Developing a trading Expert Advisor from scratch (Part 14): Adding Volume At Price (II)
Developing a trading Expert Advisor from scratch (Part 14): Adding Volume At Price (II)
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
any details I missed?
any details I missed?
Probably YES... you need to read and watch the whole article ... ALL of it, including the video that's in the article, because there I show you some details of how you capture the information ... the detail is that the system is optimised to go to a particular memory address and not keep looking for the information, which would be very slow, since we're using a REAL TIME system ... and if the page is modified by the administrator, this address will be different, so you'll have to search where the new address is, but in the article I show you in detail how to find the new address .... and, in this specific case, how to see an error message indicating that the address is different from the one the system expected to find the information it was looking for ... READ the article ... WATCH the video and understand what I am explaining in it, change the address that is used to indicate where the information is and you will get the data that is on the page and from any other page .... remember the search has to be done quickly since the system is REAL TIME ... if it wasn't we could download the page and use a loop to search for the information, but time is precious ... 😁👍
Interesting article, but I can't understand what it means in yellow?
And it's a hexadecimal number. How do I position it correctly?
Interesting article, but I can't understand what it means in yellow?
And it's a hexadecimal number. How do I position it correctly?
The values starting with 0x are HEXA values, the rest are ordinary decimal values. You can use the DECIMAL value, but I find it difficult to understand at times. As I usually use ASCII values, I prefer to use HEXA. But the value 0x0D represents the ENTER key. And 0x20 is the SPACE key. To find these values, and position them correctly, you need to have the file and a HEXADECIMAL editor. Then you need to look up the value in the file to tell the procedure where in the file the value is. So the values 172783 and 173474 are addresses, or positions within the file being downloaded.
Try to learn how to use a HEXADECIMAL EDITOR, as it will be easier to understand these addresses.😁👍