
Sıfırdan bir ticaret Uzman Danışmanı geliştirme (Bölüm 15): İnternetteki verilere erişme (I)

Giriş
MetaTrader 5, bir yatırımcının isteyebileceği en çok yönlü ve eksiksiz platformdur. Diğer yanlış görüşlerin aksine, platform son derece verimli ve güçlüdür, çünkü yalnızca grafiğin basit bir gözlemi yerine bize bunun çok ötesini gerçekleştirmemizi sağlayan çok çeşitli olanaklar sunar.
Tüm bu güç, platformun günümüzde mevcut olan en güçlü dile (C/C++) neredeyse eşit bir dil (MQL5) kullanmasından kaynaklanmaktadır. Bu dilin bize sunduğu olanaklar, programlama becerisine sahip olmayan yatırımcıların anlayabileceklerinin veya gerçekleştirebileceklerinin çok ötesindedir.
Piyasalarda ticaret yaparken, küresel düzeydeki çeşitli konularla bir şekilde bağlantılı olmamız gerekmektedir. Sadece grafiğe bağlı kalamayız - doğru ticaret kararları verme konusunda bize yardımcı olabilecek ve kazanma ve kaybetme arasındaki farkı belirleyebilecek diğer değerli bilgileri de hesaba katmalıyız.
İnternet üzerinde devasa miktarda bilginin yer aldığı çok sayıda web sitesi vardır. Bilinmesi gereken, nereye bakılacağı ve bu bilgilerin en iyi şekilde nasıl kullanılacağıdır. Doğru zamanda ne kadar iyi bir şekilde bilgilenirsek, ticaretimiz de o kadar iyi olacaktır. Ancak, hangisi olursa olsun bir tarayıcı kullanıyorsanız: belirli bilgileri düzgün bir şekilde filtrelemenin çok zor olduğunu, birçok ekrana ve monitöre bakmak zorunda kalındığını ve sonunda, bilgi orada olmasına rağmen, onu kullanmanın imkansız olduğunu fark edeceksiniz.
C/C++'a çok yakın olan MQL5 sayesinde, programcılar sadece grafik üzerinde çalışmaktan çok daha fazlasını yapabilir: internetteki verileri arayabiliriz, filtreleyebiliriz, analiz edebiliriz ve böylece çoğu yatırımcıdan çok daha istikrarlı bir şekilde ticaret işlemleri gerçekleştirebiliriz, çünkü tüm bilgi işlem gücünü kendi lehimize kullanıyor olacağız.
1.0. Planlama
Planlama bölümü çok önemlidir. İlk olarak, kullanmak istediğimiz bilgileri nereden elde edeceğimizi bulmamız gerekir. Bu işlem dikkatli bir şekilde yapılmalıdır, çünkü iyi bir bilgi kaynağı bizi doğru yöne yönlendirecektir. Her yatırımcı farklı zamanlarda farklı özel verilere ihtiyaç duyabileceğinden, herkes bu adımı bireysel olarak yapmalıdır.
Seçilen kaynak ne olursa olsun, sonrasında yapılacaklar temelde herkes için aynı olacaktır. Dolayısıyla bu makale, herhangi bir harici program olmadan yalnızca MQL5’le mevcut yöntem ve araçları kullanmak isteyenler için bir çalışma materyali olarak hizmet edecektir.
Tüm sürecin nasıl işlediğini göstermek adına örnek olarak bir piyasa bilgileri web sayfasını kullanacağız. Sürecin tüm adımlarını inceleyerek her şeyi net hale getireceğiz, böylece bu yöntemi özel ihtiyaçlarınıza göre ayarlayarak isteğiniz şekilde kullanabileceksiniz.
1.0.1. Yakalama programını geliştirme
Verilerle çalışmaya başlamak için, öncelikle verileri toplamak ve etkili ve doğru bir şekilde analiz edebilmek adına küçük bir program oluşturmamız gerekiyor. Bu amaçla, aşağıda gösterilen çok basit bir program kullanacağız:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { Print(GetDataURL("https://tradingeconomics.com/stocks")); } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 750) { string headers; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; if ((handle = FileOpen("url.txt", FILE_WRITE | FILE_BIN)) != INVALID_HANDLE) { FileWriteArray(handle, charResultPage, 0, ArraySize(charResultPage)); FileClose(handle); }else return "Error saving file ..."; return "File saved successfully..."; }
Kodda vurgulanan kısımda, bilgileri almak istediğimiz siteyi belirteceğiz.
Neden tarayıcı değil de bunu kullanıyoruz? Bilgileri tarayıcıdan da yakalayabileceğimiz doğru, ancak verileri indirdikten sonra onları bulmamıza yardımcı olması için programı kullanacağız.
Ama sadece programı yazıp derlemek işe yaramaz. Yapmamız gereken başka bir şey daha vardır, aksi takdirde çalışmayacaktır.
MetaTrader platformunda, bu komut dosyasını çalıştırmadan önce, platformun söz konusu siteden verileri almasına izin vermemiz gerekir. MetaTrader platformunu her yüklemeniz gerektiğinde bunu yapmak zorunda kalmamak için, her şey yapılandırıldıktan sonra bu verilerin bir yedeğini kaydedebilirsiniz. Kaydetmeniz gereken dosya aşağıdaki yoldadır:
C:\Users\< USER NAME >\AppData\Roaming\MetaQuotes\Terminal\< CODE PERSONAL >\config\common.ini
USER NAME, işletim sistemindeki kullanıcı adınızdır. CODE PERSONAL, platformun kurulum sırasında oluşturduğu değerdir. Bu şekilde, yedekleme yapmak veya yeni bir kurulumdan sonra değiştirmek için dosyayı kolayca bulabilirsiniz. Bir ayrıntı: bu yol WINDOWS sistemine aittir.
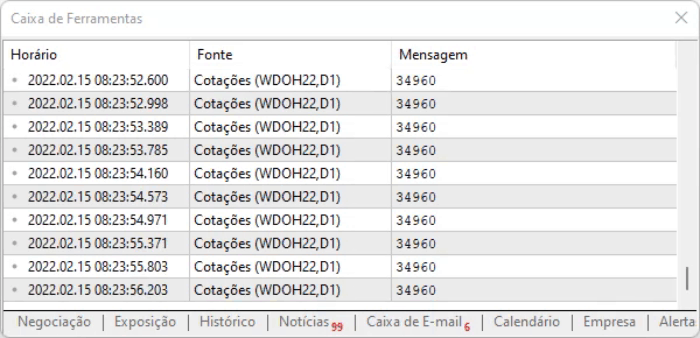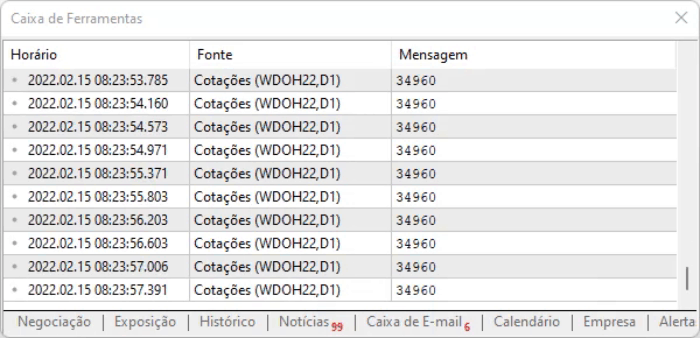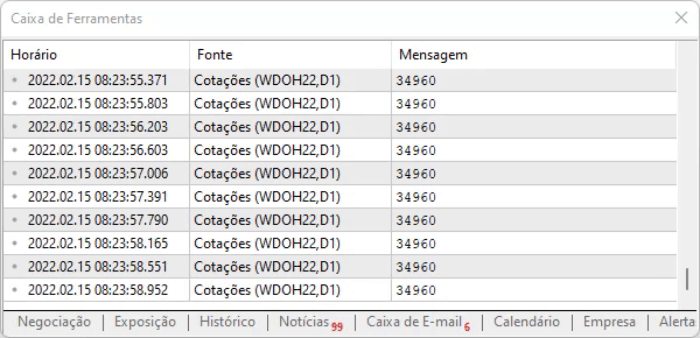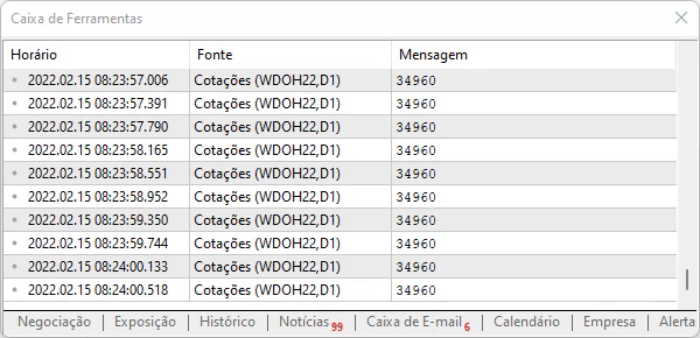
Şimdi oluşturduğumuz komut dosyasına geri dönelim. Ayarlamaları yapmadan kullanırsanız, mesaj penceresinde aşağıdaki çıktı görünecektir.
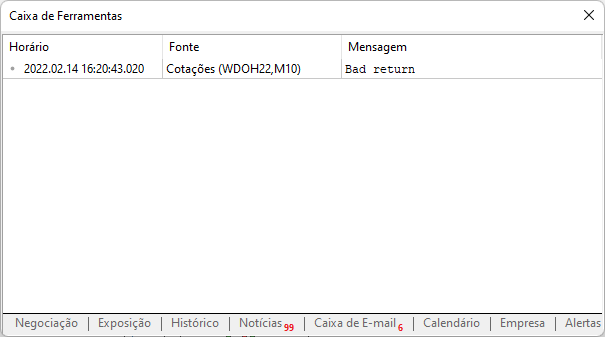
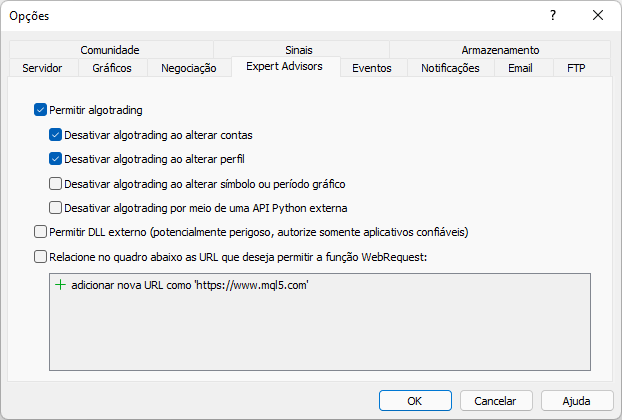
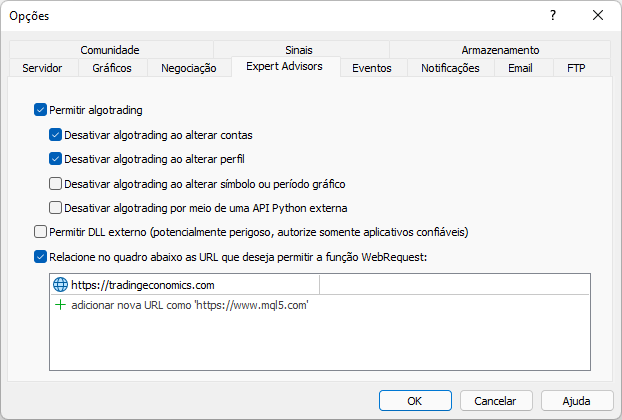
MetaTrader platformunda web sitesine izin vermediğimizde bu şekilde bir mesaj görüntülenir. İzin verme işlemi aşağıda gösterildiği gibi yapılmalıdır. Nasıl eklendiğine dikkat edin: MetaTrader işlem platformu üzerinden erişeceğimiz web sitesi adresinin kök kısmı girilmelidir.

Şimdi, aynı komut dosyasını tekrar çalıştırırsak, platform aşağıdaki çıktıyı yazacaktır:
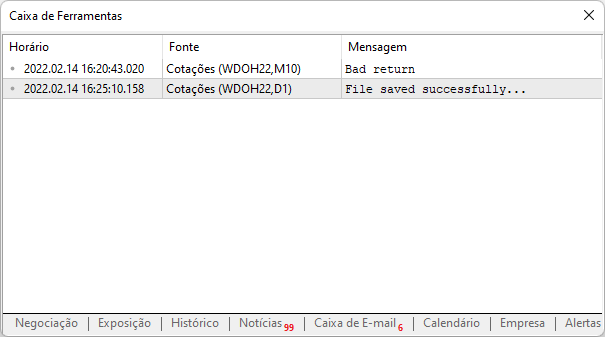
Bu, siteye başarıyla erişildiği, verilerin bilgisayara indirildiği ve artık analiz edebileceği anlamına gelir. Önemli bir ayrıntı şu ki, artık aynı siteyi platforma tekrar ekleme konusunda endişelenmemize gerek yoktur, elbette yukarıda gösterilen yoldaki dosyanın bir yedeğini oluşturmanız şartıyla.
Burada her şeyin nasıl çalıştığını anlamak ve daha detaylı bilgi edinmek için dokümantasyondaki WebRequest fonksiyonuna bakabilirsiniz. Ağ iletişim protokolünü daha da derinlemesine incelemek istiyorsanız, MQL5'te sunulan diğer ağ fonksiyonlarına da göz atmanızı tavsiye ederim. Bu tür fonksiyonları bilmek bazen sizi çok fazla sorundan kurtarabilir.
İşin ilk kısmını tamamladık - istediğimiz siteden verileri indirdik. Şimdi bir bu kadar önemli olan bir sonraki adıma geçelim.
1.0.2. Verileri arama
Bir web sitesi içerisinde MetaTrader 5 platformu tarafından yakalanacak verilerin nasıl aranacağını bilmeyenler için, bu aramanın nasıl yapıldığını hızlı bir şekilde gösterdiğim kısa bir video hazırladım.
Verileri almak istediğiniz web sitesinin kodunu ayrıştırabilmek için tarayıcınızı nasıl kullanacağınızı bilmeniz önemlidir. Tarayıcının kendisi bu görevde çok yardımcı olduğu için zor değildir. Ancak bu, genel olarak nasıl yapıldığının öğrenilmesi gereken bir şeydir. Bunu nasıl yapacağınızı anladığınızda önünüze pek çok kolaylık açılacaktır.
Ben arama için Chrome kullanacağım, ancak siz geliştirici araçlarını kullanarak web sitesinin koduna erişim sağlayan başka herhangi bir tarayıcı kullanabilirsiniz.
İlgilendiğimiz şey, aşağıda gösterilen bloktan verileri elde etmektir; bu blok, yukarıdaki videoda aradığım blokla aynıdır. Tarayıcıyı kullanarak bir şeyleri nasıl arayacağınızı bilmek gerçekten önemlidir, aksi takdirde indirilen tüm bu bilgiler arasında kaybolursunuz.
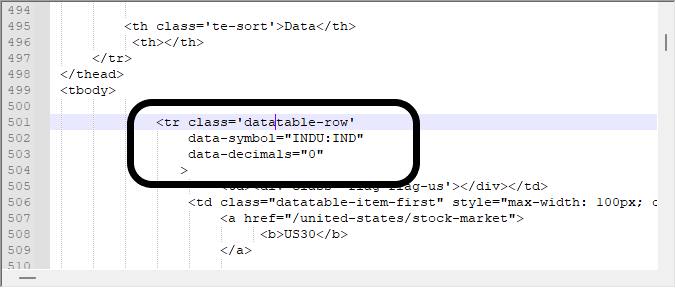
Ancak bazen verilere sadece bu şekilde bakmak yeterli olmayabilir. Tam olarak neyle uğraştığımızı bilmek için bir hex düzenleyicisine başvurmalıyız. Bazı durumlarda veri modellemenin nispeten basit olduğu doğrudur, ancak diğer durumlarda bu çok daha karmaşık olabilir - veriler görüntüler, linkler vb. içerdiğinde. Bu tür şeyler genellikle yanlış pozitif sonuçlar verdiğinden aramayı zorlaştırabilir, bu yüzden neyle uğraştığımızı bilmemiz gerekir. Aynı verileri bir hex düzenleyicisinde aradığımızda aşağıdaki değerleri elde ederiz.
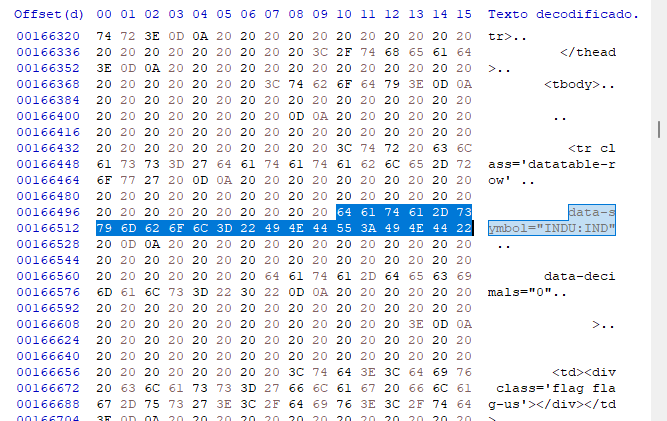
Dinamik sayfalar söz konusu olduğunda değişebilecekleri için bu ilk adımda ofsetlerle ilgilenmiyoruz, ancak hangi tür modellemenin kullanıldığını görmek istiyoruz. Bizim durumumuzda çok açıktır, hex düzenleyicisinde bulduğumuz bu tür bilgiye dayalı bir arama sistemi kullanabiliriz. Bu, ilk başta verimli bir sistem olmasa dahi, programımızla arama yapmayı biraz daha basit hale getirir. Arama veritabanımıza erişim kolaydır - girdiler kullanacağız ve CARRIAGE veya RETURN gibi aslında bize yardımcı olmaktan çok engel olan herhangi bir ek karakter kullanmayacağız. Böylece, program kodu aşağıdaki gibidir:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks")); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 100) { string headers, szInfo; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; szInfo = ""; for (int c0 = 0, c1 = ArraySize(charResultPage); c0 < c1; c0++) szInfo += CharToString(charResultPage[c0]); if ((handle = StringFind(szInfo, "data-symbol=\"INDU:IND\"", 0)) >= 0) { handle = StringFind(szInfo, "<td id=\"p\" class=\"datatable-item\">", handle); for(; charResultPage[handle] != 0x0A; handle++); for(handle++; charResultPage[handle] != 0x0A; handle++); szInfo = ""; for(handle++; charResultPage[handle] == 0x20; handle++); for(; (charResultPage[handle] != 0x0D) && (charResultPage[handle] != 0x20); handle++) szInfo += CharToString(charResultPage[handle]); } return szInfo; }
Kodun amacı sayfadaki değeri yakalamaktır. Yukarıda gösterilen yöntemin avantajı, bilgi ofset nedeniyle konum değiştirse bile, onu tüm bu komutlar arasında bulabilmemizdir. Ancak her şey ideal görünse dahi, bilgilerde küçük bir gecikme vardır, bu nedenle yukarıdaki komut dosyası yürütüldüğünde yakalanan verilerle nasıl çalışacağımızı anlamamız gerekir. Yürütme sonucu aşağıda görülebilir:
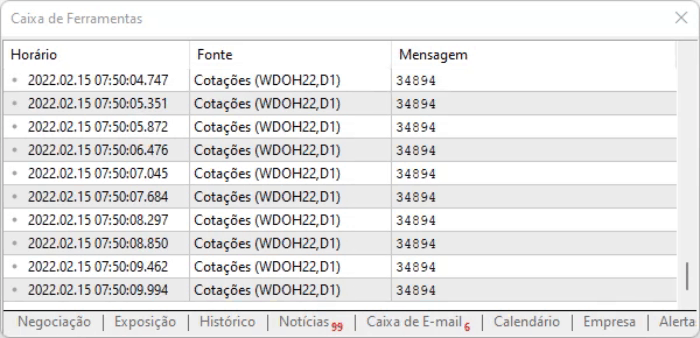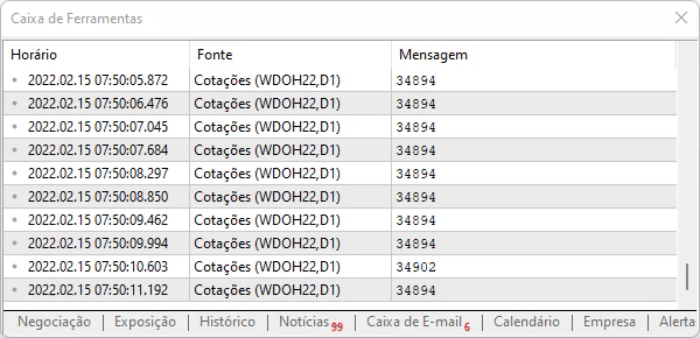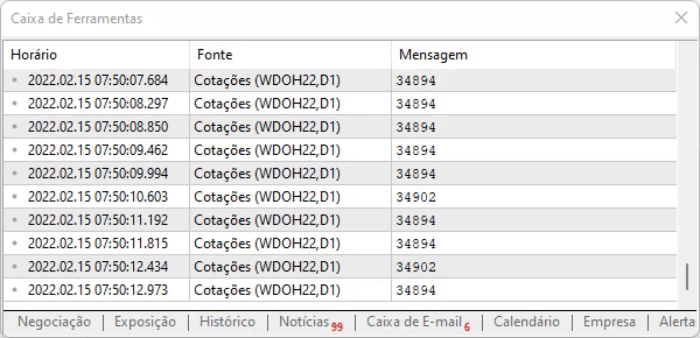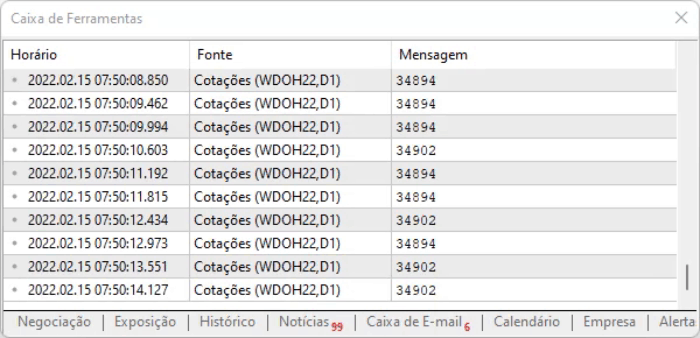
Kendi analizinizi yapmanızı ve bilgilerin nasıl kaydedildiğini görmenizi tavsiye ederim, çünkü metin biçiminde anlatılması o kadar kolay olmayan ayrıntıları bilmek önemlidir: öğrenmek için onları kendiniz pratik yapmanız gerekir.
Şimdi şunlar hakkında düşünelim. Yukarıdaki kod, yürütme açısından çok verimli değildir, çünkü söz konusu sayfada olduğu gibi, statik modellemeli, ancak dinamik içerikli bir sayfa kullanılması durumunda gerekli olmayan bazı manipülasyonlar yapar. Bu özel durumda, daha hızlı ayrıştırma yapmak ve böylece verileri daha verimli bir şekilde yakalamak için ofseti kullanabiliriz. Ancak sistemin bilgileri önbellekte birkaç saniye tutabileceğini unutmayın. Bu nedenle, yakalanan bilgiler tarayıcıda gözlemlenen bilgilerle karşılaştırıldığında güncelliğini yitirmiş olabilir. Bu durumda, bunu düzeltmek için sistemde bazı iç ayarlamalar yapmak gerekir. Ancak bu makalenin amacı bu değildir.
Yukarıdaki kodu, arama yapmak için ofset kullanan bir şeye değiştirerek aşağıdaki kodu elde ederiz:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo; }
Komut dosyasını yürütmenin sonucu aşağıdan görülebilir. Büyük bir değişiklik yoktur, sadece ofset yönteminin uygulanmasıyla hesaplama süresi azalmıştır. Böylece genel sistem performansı biraz daha iyileşmiştir.
Yukarıdaki kodun yalnızca sayfa statik modele sahip olduğu için çalıştığını lütfen unutmayın: içerik dinamik olarak değişse de tasarım değişmemektedir, bu nedenle bir hex düzenleyicisi kullanabilir, bilgilerin konumuna bakabilir, ofset değerlerini alabilir ve hemen bu konumlara gidebiliriz. Ancak ofsetlerin hala geçerli olduğundan emin olmak adına aşağıdaki satırda gerçekleştirilen basit bir sınama yaparız:
for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position";
Bu çok basit ama gerekli bir şeydir, bu sayede ofsetle yakalanan bilgilerle ilgili olarak asgari bir güvenliğe sahip oluruz. Bunu yapabilmek için, sayfayı analiz etmemiz ve verileri yakalarken ofset yöntemini kullanmanın mümkün olup olmadığını kontrol etmemiz gerekir. Eğer mümkünse, daha kısa işleme süresi avantajından yararlanabileceğiz.
1.0.3. Çözülmesi gereken bir sorun
Sistem genellikle çok iyi çalışmasına rağmen, sunucudan aşağıdaki yanıtı alabiliyoruz:
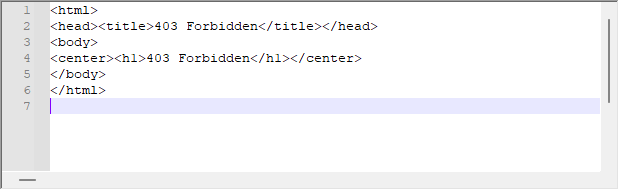
Bu, sunucunun talebimize verdiği yanıttır. WebRequest platform tarafında herhangi bir hata belirtmese de sunucu bu mesajı geri döndürebilir. Bu durumda, sorunu anlamak için geri döndürülen mesajın hearderını analiz etmeliyiz. Bu sorunu çözmek için ofset komut dosyasında küçük bir değişiklik yapıyoruz, bu aşağıda görülebilir:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "<!doctype html>", 2, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szTest, int iTest, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1 return "Bad"; for (int c0 = 0, c1 = StringLen(szTest); c0 < c1; c0++) if (szTest[c0] != charResultPage[iTest + c0]) return "Failed"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo;
Vurgulanan satır, sınamayı gerçekleştiren satırdır. Sunucudan geri döndürülen mesaj daha karmaşık olduğunda, bu sınamayı gerçekleştirmek, bize analiz ettiğimiz veriler üzerinde iyi bir güvenlik payı sağlar. Bu şekilde, sistemin önceki kodda mevcut olan ilk sınamayı geçmesi durumunda meydana gelebilecek hayalet verilerin veya bellek çöpünün analizi önlenmiş olur. Bu nadiren gerçekleşse de, gerçekleşme olasılığını hafife almamalıyız.
Aşağıda sonucun farklı olmadığını görebilirsiniz, bu da sistemin beklendiği gibi çalıştığı anlamına gelir.
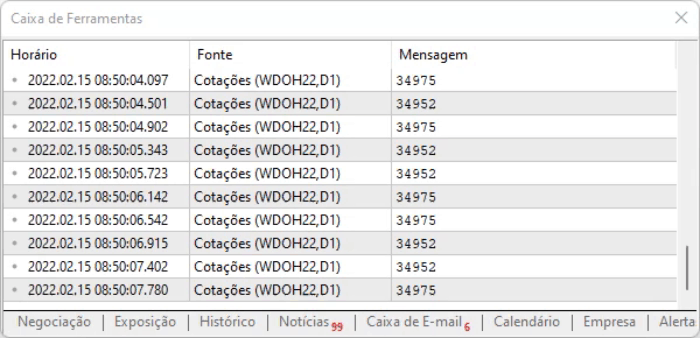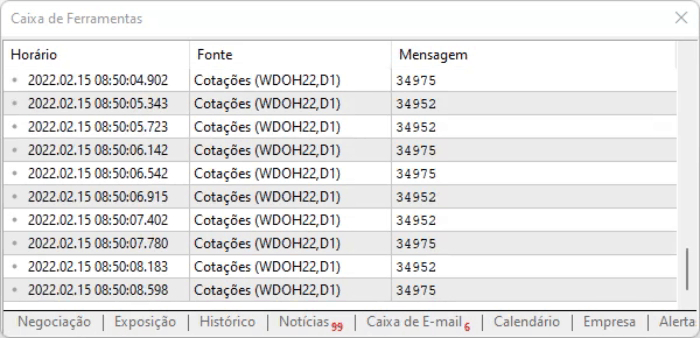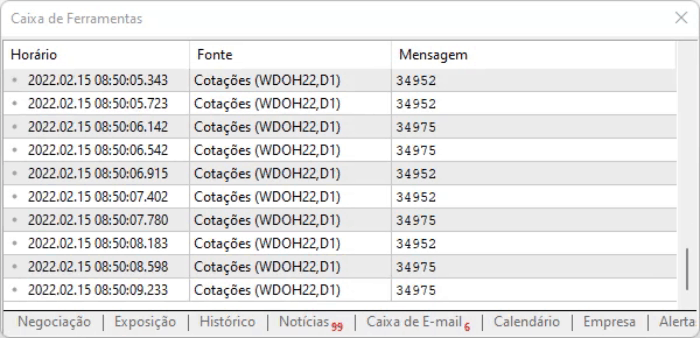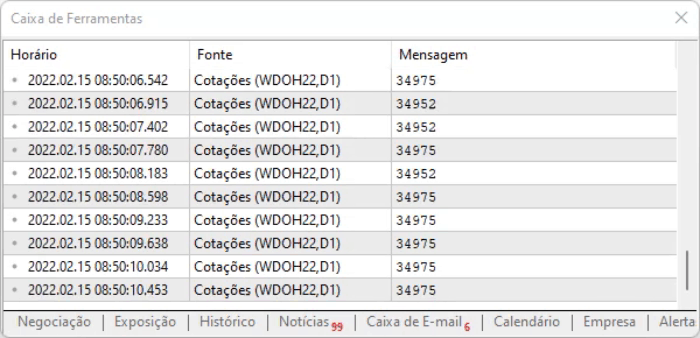
Şimdiye kadar çok bir şey yapmadık - sadece web sayfasından değerleri okuyoruz, bunun nasıl yapıldığını bilmek ve görmek oldukça ilginç olsa da şu an için ticaret açısından bize pek bir fayda sağlamıyor. Dolayısıyla, geniş bir sistemde bir anlam ifade etmesi için bir şeyler yapmamız gerekiyor. Yakalanan bu bilgileri Uzman Danışmana aktaracağız, bu şekilde daha da etkileyici şeyler yapabileceğiz ve işte bu da MetaTrader 5'i heyecan uyandıran bir platform haline getiriyor.
Sonuç
Henüz işimiz bitmedi. Bir sonraki makalede, internetten toplanan bu bilgilerin Uzman Danışmana nasıl aktarılacağını göreceğiz ve bu gerçekten etkileyici olacak: MetaTrader platformunda çok az keşfedilmiş kaynakları kullanmamız gerekecek. Dolayısıyla, bu serinin bir sonraki makalesini kaçırmayın.
Bu makalede kullanılan tüm kodlar aşağıya eklenmiştir.
MetaQuotes Ltd tarafından Portekizceden çevrilmiştir.
Orijinal makale: https://www.mql5.com/pt/articles/10430
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

 Ichimoku göstergesine dayalı bir ticaret sistemi nasıl geliştirilir?
Ichimoku göstergesine dayalı bir ticaret sistemi nasıl geliştirilir?
 Sıfırdan bir ticaret Uzman Danışmanı geliştirme (Bölüm 14): Hacim profili ekleme (II)
Sıfırdan bir ticaret Uzman Danışmanı geliştirme (Bölüm 14): Hacim profili ekleme (II)
 Williams %R göstergesine dayalı bir ticaret sistemi nasıl geliştirilir?
Williams %R göstergesine dayalı bir ticaret sistemi nasıl geliştirilir?
 Veri Bilimi ve Makine Öğrenimi (Bölüm 05): Karar Ağaçları
Veri Bilimi ve Makine Öğrenimi (Bölüm 05): Karar Ağaçları
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Kaçırdığım bir detay var mı?
Kaçırdığım bir detay var mı?
Muhtemelen EVET... makalenin tamamını okumanız ve izlemeniz gerekiyor... Makalede yer alan video da dahil olmak üzere TÜMÜNÜ, çünkü orada size bilgiyi nasıl yakaladığınızın bazı ayrıntılarını gösteriyorum ... ayrıntı, sistemin belirli bir bellek adresine gidecek ve bilgiyi aramaya devam etmeyecek şekilde optimize edilmiş olmasıdır, bu da GERÇEK ZAMANLI bir sistem kullandığımız için çok yavaş olacaktır ... ve sayfa yönetici tarafından değiştirilirse, bu adres farklı olacaktır, bu nedenle yeni adresin nerede olduğuna bakmanız gerekecektir, ancak makalede size yeni adresi nasıl bulacağınızı ayrıntılı olarak gösteriyorum .... ve bu özel durumda, adresin sistemin aradığı bilgiyi bulmayı beklediği adresten farklı olduğunu gösteren bir hata mesajının gözlemlenmesi ... Makaleyi OKUYUN ... Videoyu İZLEYİN ve içinde ne anlattığımı anlayın, bilginin nerede olduğunu belirtmek için kullanılan adresi değiştirin ve sayfadaki ve başka herhangi bir sayfadaki verileri alacaksınız .... sistem GERÇEK ZAMANLI olduğu için aramanın hızlı yapılması gerektiğini unutmayın ... eğer olmasaydı sayfayı indirebilir ve bilgileri aramak için bir döngü kullanabilirdik, ama zaman değerli ... 😁👍
İlginç bir makale, ancak sarı renkte ne anlama geldiğini anlayamıyorum?
Ve onaltılık bir sayı. Nasıl doğru konumlandırabilirim?
İlginç bir makale, ancak sarı renkte ne anlama geldiğini anlayamadım?
Ve onaltılık bir sayı. Nasıl doğru konumlandırabilirim?
0x ile başlayan değerler HEXA değerleridir, geri kalanlar normal ondalık değerlerdir. DECIMAL değerini kullanabilirsiniz, ancak bazen anlamakta zorlanıyorum. Ben genellikle ASCII değerleri kullandığım için HEXA kullanmayı tercih ediyorum. Ancak 0x0D değeri ENTER tuşunu temsil eder. Ve 0x20 ise SPACE tuşudur. Bu değerleri bulmak ve doğru şekilde konumlandırmak için dosyaya ve bir HEXADECIMAL düzenleyiciye sahip olmanız gerekir. Ardından, prosedüre değerin dosyanın neresinde olduğunu söylemek için dosyadaki değere bakmanız gerekir. Yani 172783 ve 173474 değerleri adreslerdir ya da indirilmekte olan dosya içindeki konumlardır.
Bu adresleri anlamak daha kolay olacağından, bir HEXADECIMAL EDITOR kullanmayı öğrenmeye çalışın.😁👍